目錄
- 第二門課: 改善深層神經網絡:超參數調試、正 則 化 以 及 優 化 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)
- 第二周:優化算法 (Optimization algorithms)
- 2.9 學習率衰減(Learning rate decay)
第二門課: 改善深層神經網絡:超參數調試、正 則 化 以 及 優 化 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)
第二周:優化算法 (Optimization algorithms)
2.9 學習率衰減(Learning rate decay)
加快學習算法的一個辦法就是隨時間慢慢減少學習率,我們將之稱為學習率衰減,我們來看看如何做到,首先通過一個例子看看,為什么要計算學習率衰減。
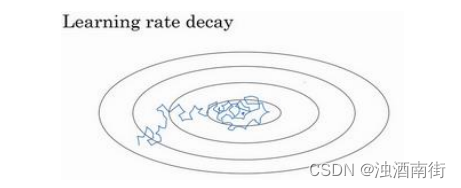
假設你要使用 mini-batch 梯度下降法,mini-batch 數量不大,大概 64 或者 128 個樣本,在迭代過程中會有噪音(藍色線),下降朝向這里的最小值,但是不會精確地收斂,所以你的算法最后在附近擺動,并不會真正收斂,因為你用的 α \alpha α是固定值,不同的 mini-batch 中有噪音。
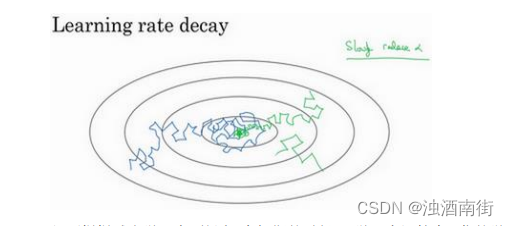
但要慢慢減少學習率 α \alpha α的話,在初期的時候, α \alpha α學習率還較大,你的學習還是相對較快,但隨著 α \alpha α變小,你的步伐也會變慢變小,所以最后你的曲線(綠色線)會在最小值附近的一小塊區域里擺動,而不是在訓練過程中,大幅度在最小值附近擺動。
所以慢慢減少𝑎的本質在于,在學習初期,你能承受較大的步伐,但當開始收斂的時候,小一些的學習率能讓你步伐小一些。
你可以這樣做到學習率衰減,記得一代要遍歷一次數據,如果你有以下這樣的訓練集:

你應該拆分成不同的 mini-batch,第一次遍歷訓練集叫做第一代。第二次就是第二代,依此類推,你可以將 α \alpha α學習率設為 α = 1 1 + d e c a y ? r a t e ? e p o c h ? n u m α 0 \alpha = \frac{1}{1+{decay-rate} ? {epoch-num}} \alpha_0 α=1+decay?rate?epoch?num1?α0?(decay-rate稱為衰減率,epoch-num 為代數, α 0 \alpha_0 α0?為初始學習率),注意這個衰減率是另一個你需要調整的超參數。
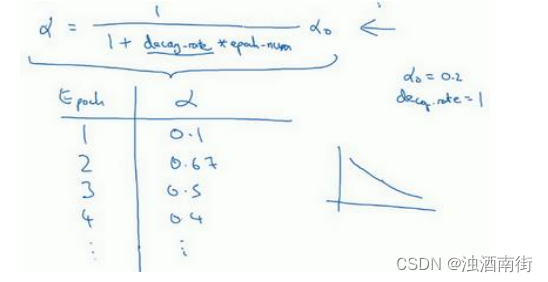
這里有一個具體例子,如果你計算了幾代,也就是遍歷了幾次,如果𝑎0為 0.2,衰減率decay-rate 為 1,那么在第一代中,𝑎 =11+1𝑎0 = 0.1,這是在代入這個公式計算 α = 1 1 + d e c a y ? r a t e ? e p o c h ? n u m α 0 \alpha =\frac{1}{1+{decay-rate} ? {epoch-num}} \alpha_0 α=1+decay?rate?epoch?num1?α0?,
此時衰減率是 1 而代數是 1。在第二代學習率為 0.67,第三代變成 0.5,第四代為 0.4 等等,你可以自己多計算幾個數據。要理解,作為代數函數,根據上述公式,你的學習率呈遞減趨勢。如果你想用學習率衰減,要做的是要去嘗試不同的值,包括超參數 α 0 \alpha_0 α0?,以及超參數衰退率,找到合適的值,除了這個學習率衰減的公式,人們還會用其它的公式。

比如,這個叫做指數衰減,其中 α \alpha α相當于一個小于 1 的值,如 α = 0.9 5 e p o c h ? n u m α 0 \alpha = 0.95 ^{epoch?num} \alpha_0 α=0.95epoch?numα0?,所以你的學習率呈指數下降。
人們用到的其它公式有 α e p o c h ? n u m α 0 \frac{\alpha}{\sqrt{epoch?num}}\alpha_0 epoch?num?α?α0? 或者 α = k t α 0 \alpha =\frac{k}{\sqrt{t}} \alpha_0 α=t?k?α0?(𝑡為 mini-batch 的數字)。
有時人們也會用一個離散下降的學習率,也就是某個步驟有某個學習率,一會之后,學習率減少了一半,一會兒減少一半,一會兒又一半,這就是離散下降(discrete stair cease)的意思。
到現在,我們講了一些公式,看學習率𝑎究竟如何隨時間變化。人們有時候還會做一件事,手動衰減。如果你一次只訓練一個模型,如果你要花上數小時或數天來訓練,有些人的確會這么做,看看自己的模型訓練,耗上數日,然后他們覺得,學習速率變慢了,我把𝑎調小一點。手動控制𝑎當然有用,時復一時,日復一日地手動調整𝑎,只有模型數量小的時候有用,但有時候人們也會這么做。
所以現在你有了多個選擇來控制學習率𝑎。你可能會想,好多超參數,究竟我應該做哪一個選擇,我覺得,現在擔心為時過早。下一周,我們會講到,如何系統選擇超參數。對我而言,學習率衰減并不是我嘗試的要點,設定一個固定的𝑎,然后好好調整,會有很大的影響,學習率衰減的確大有裨益,有時候可以加快訓練,但它并不是我會率先嘗試的內容,但下周我們將涉及超參數調整,你能學到更多系統的辦法來管理所有的超參數,以及如何高效搜索超參數。
這就是學習率衰減,最后我還要講講神經網絡中的局部最優以及鞍點,所以能更好理解在訓練神經網絡過程中,你的算法正在解決的優化問題,下個視頻我們就好好聊聊這些問題。












![[解決方法]echarts地圖/圖表縮放,側邊欄導致樣式自適應問題](http://pic.xiahunao.cn/[解決方法]echarts地圖/圖表縮放,側邊欄導致樣式自適應問題)


)

)

