使用KD原因
遇到問題:從產業發展的角度來看工業化將逐漸過渡到智能化,邊緣計算逐漸興起預示著 AI 將逐漸與小型化智能化的設備深度融合,這也要求模型更加的便捷、高效、輕量以適應這些設備的部署。
解決方案:知識蒸餾技術
知識蒸餾的關鍵點
如果回歸機器學習最最基礎的理論,我們可以很清楚地意識到一點(而這一點往往在我們深入研究機器學習之后被忽略): 機器學習最根本的目的在于訓練出在某個問題上泛化能力強的模型。
泛化能力強: 在某問題的所有數據上都能很好地反應輸入和輸出之間的關系,無論是訓練數據,還是測試數據,還是任何屬于該問題的未知數據。
而現實中,由于我們不可能收集到某問題的所有數據來作為訓練數據,并且新數據總是在源源不斷的產生,因此我們只能退而求其次,訓練目標變成在已有的訓練數據集上建模輸入和輸出之間的關系。由于訓練數據集是對真實數據分布情況的采樣,訓練數據集上的最優解往往會多少偏離真正的最優解(這里的討論不考慮模型容量)。
而在知識蒸餾時,由于我們已經有了一個泛化能力較強的Net-T,我們在利用Net-T來蒸餾訓練Net-S時,可以直接讓Net-S去學習Net-T的泛化能力。
一個很直白且高效的遷移泛化能力的方法就是:使用softmax層輸出的類別的概率來作為“soft target”。
KD的訓練過程和傳統的訓練過程的對比
傳統training過程(hard targets): 對ground truth求極大似然
KD的training過程(soft targets): 用large model的class probabilities作為soft targets
KD的訓練過程為什么更有效?
softmax層的輸出,除了正例之外,負標簽也帶有大量的信息,比如某些負標簽對應的概率遠遠大于其他負標簽。而在傳統的訓練過程(hard target)中,所有負標簽都被統一對待。也就是說,KD的訓練方式使得每個樣本給Net-S帶來的信息量大于傳統的訓練方式。
【舉個例子】
在手寫體數字識別任務MNIST中,輸出類別有10個。

假設某個輸入的“2”更加形似"3",softmax的輸出值中"3"對應的概率為0.1,而其他負標簽對應的值都很小,而另一個"2"更加形似"7","7"對應的概率為0.1。這兩個"2"對應的hard target的值是相同的,但是它們的soft target卻是不同的,由此我們可見soft target蘊含著比hard target多的信息。并且soft target分布的熵相對高時,其soft target蘊含的知識就更豐富。

這就解釋了為什么通過蒸餾的方法訓練出的Net-S相比使用完全相同的模型結構和訓練數據只使用hard target的訓練方法得到的模型,擁有更好的泛化能力。 下圖為知識蒸餾的通用形式。
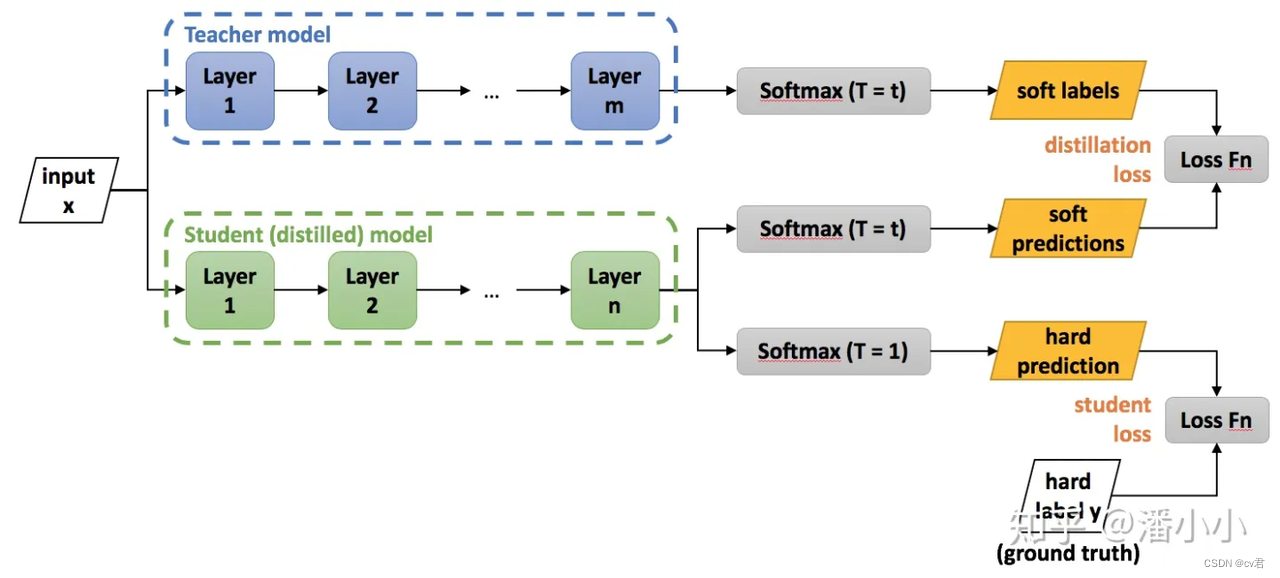
知識傳遞形式
原始知識蒸餾(Vanilla Knowledge Distillation)僅僅是從教師模型輸出的軟目標中學習出輕量級的學生模型。
然而,當教師模型變得更深時,僅僅學習軟目標是不夠的。
因此,我們不僅需要獲取教師模型輸出的知識,還需要學習隱含在教師模型中的其它知識,比如有輸出特征知識、中間特征知識、關系特征知識和結構特征知識。
標簽知識是神經網絡對樣本數據最終的預測輸出中包含的潛在信息,這也是目前蒸餾過程中最簡單、應用最多的方式。
標簽知識(輸出特征知識)通常指的是教師模型的最后一層特征,主要包括邏輯單元和軟目標的知識。標簽知識(輸出特征知識)知識蒸餾的主要思想是促使學生能夠學習到教師模型的最終預測,以達到和教師模型一樣的預測性能。
原始知識蒸餾是針對分類任務來提出的僅包含類間相似性的軟目標知識,然而其它任務(如目標檢測)網絡最后一層特征輸出中還可能包含有目標定位的信息。
換句話說,不同任務教師模型的最后一層輸出特征是不一樣的。因此,本文根據任務的不同對輸 出特征知識分別進行歸納和分析,如表 1 所示。

Hinton 等人最早提出的知識蒸餾方法就屬于目標分類的標簽知識(輸出特征知識)。由于經過“蒸餾溫度”調節后的軟標簽中具有很多不確定信息,通常的研究認為這其中反映了樣本間的相似度或干擾性、樣本預測的難度,因此標簽知識又被稱為“暗知識”。
-
為了有效地解決基于聚類的算法中的偽標簽噪聲的問題,Ge等人[45]利用“同步平均教學”的蒸餾框架進行偽標簽優化,核心思想是利用更為魯棒的“軟”標簽對偽標簽進行在線優化。
-
MLP[46]提出了基于元學習(Meta - learning)自適應生成目標分布的方法,用于教師和學生模型的偽標簽學習過程.利用一個篩選網絡從目標檢測模型預測的偽標簽中區分出正例和負例,將正例用于下一階段的半監督自訓練過程,可以有效提升標簽數據的利用率[43]。
-
Xie等人[4]利用有監督訓練學生模型自身,在自蒸餾訓練中額外地引入無標簽噪聲數據產生偽標簽,將ImageNet的Top-1識別結果提高了約1%.對于標簽知識蒸餾方法本身,已經有非常多的變體和應用,主要是從改進蒸餾過程、挖掘標簽信息、去除干擾等方面,提升學生模型的性能.
-
Gao等人[47]實現了一種簡單的逐階段的標簽蒸餾訓練過程,在梯度下降訓練過程中,每次只更新學生網絡的一個模塊,從前至后直到全部更新完成。
-
根據Mirzadeh等人[48]的研究發現,并不是教師模型性能越高對于學生模型的學習越有利,當教師-學生模型之間的差距過大時,會導致學生難以從教師模型獲得提升.為此,他們提出使用輔助教師策略來逐漸縮小教師和學生之間的學習差距,取得更好的蒸餾效果.
-
同樣是為了縮小教師 - 學生之間的學習差距,Yang等人[49]則提出利用教師模型在每個訓練周期更新的中間模型產生的標簽知識指導學生模型.為了充分挖掘標簽信息、去除干擾,Müller等人[50]采用了子類別蒸餾方法,將原標簽分組合并參與軟標簽蒸餾學習;
-
文獻[51]則研究了蒸餾損失函數對犔2范數和歸一化的軟標簽的作用,提出使用球面空間度量蒸餾的方法去除范數的影響;
-
Zhang等人[52]關注了樣本權重的影響,通過預測不確定性自適應分配樣本權重,改善蒸餾過程;
-
Wu等人[53]提出了同伴協同蒸餾,通過訓練多個分支網絡并將其他訓練較強教師的 logits 知識轉移給同伴,有利于模型的穩定和提高蒸餾的質量。
最早使用教師模型中間特征知識的是 FitNets[27],其主要思想是促使學生的隱含層能預測出與教師隱含層相近的輸出。

知識傳遞方式中有同構蒸餾和異構蒸餾,主要就是區分 是否:教師和學生模型的架構相似或屬于同一系列的、層與層(Layer -to - Layer)或塊與塊(Block - to - Block)之間一一對應;不過通過這幾年的實驗來看,這并沒有什么區別
不同知識傳遞形式的效果
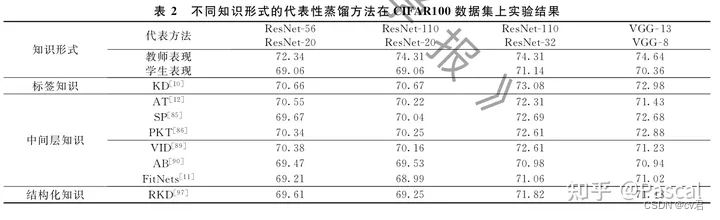

如圖所示,不同的知識傳遞形式,相比是有差異的,使用經典的KD標簽知識是還不錯的;使用特征間的,有較多都不如開山鼻祖KD;不過近期又有更多優化,比如使用互信息與對比學習的方法;
溫度的特點
在回答這個問題之前,先討論一下溫度T的特點
-
原始的softmax函數是 𝑇=1 時的特例, 𝑇<1 時,概率分布比原始更“陡峭”, 𝑇1 時,概率分布比原始更“平緩”。
-
溫度越高,softmax上各個值的分布就越平均(思考極端情況: (i) 𝑇=∞ , 此時softmax的值是平均分布的;(ii) 𝑇→0,此時softmax的值就相當于 𝑎𝑟𝑔𝑚𝑎𝑥 , 即最大的概率處的值趨近于1,而其他值趨近于0)
-
不管溫度T怎么取值,Soft target都有忽略相對較小的 𝑝𝑖 攜帶的信息的傾向
溫度代表了什么,如何選取合適的溫度?
溫度的高低改變的是Net-S訓練過程中對負標簽的關注程度: 溫度較低時,對負標簽的關注,尤其是那些顯著低于平均值的負標簽的關注較少;而溫度較高時,負標簽相關的值會相對增大,Net-S會相對多地關注到負標簽。
實際上,負標簽中包含一定的信息,尤其是那些值顯著高于平均值的負標簽。但由于Net-T的訓練過程決定了負標簽部分比較noisy,并且負標簽的值越低,其信息就越不可靠。因此溫度的選取比較empirical,本質上就是在下面兩件事之中取舍:
-
從有部分信息量的負標簽中學習 --> 溫度要高一些
-
防止受負標簽中噪聲的影響 -->溫度要低一些
總的來說,T的選擇和Net-S的大小有關,Net-S參數量比較小的時候,相對比較低的溫度就可以了(因為參數量小的模型不能capture all knowledge,所以可以適當忽略掉一些負標簽的信息)
CRD 對比學習
首先 CRD是2020年提出的新模式的蒸餾方法,使用對比學習,在這年對比了12個KD方法都是最好的,其中,CRD+KD兩個方法合在一起更好,相當于兩個維度的知識傳遞的監督,在2023年有基于CRD實現的CRCD,效果好一點,方案是差不多的;
知識提煉(KD)將知識從一個深度學習模型(教師)轉移到另一個深度學習模型(學生)。Hinton等人(2015)最初提出的目標是將教師和學生輸出之間的KL差異最小化。當輸出是一個分布,例如類上的概率質量函數時,該公式具有直觀意義。然而,我們通常希望傳遞有關representation的知識。例如,在“跨模態蒸餾”問題中,我們可能希望將圖像處理網絡的表示轉移到聲音(Aytar等人,2016)或深度(Gupta等人,2016)處理網絡,這樣圖像的深度特征和相關的聲音或深度特征高度相關。在這種情況下,KL發散是不確定的。
表征知識是結構化的——維度表現出復雜的相互依賴性。最初的KD目標(Hinton等人,2015年)將所有維度視為獨立的,以輸入為條件。讓yT成為老師的輸出,yS成為學生的輸出。那么原始的KD目標函數ψ具有全因子形式:. 這種帶因素的目標不足以傳遞結構知識,即輸出維度i和j之間的依賴關系。這與圖像生成中的情況類似,在圖像生成中,由于輸出維度之間的獨立性假設,L2目標會產生模糊的結果。
為了克服這個問題,我們想要一個目標,捕捉相關性和高階輸出依賴性。為了實現這一點,在本文中,我們利用了對比目標家族(Gutmann&Hyv?rinen,2010;Oord等人,2018;Arora等人,2019;Hjelm等人,2018)。近年來,這些目標函數已成功地用于密度估計和表征學習,尤其是在自我監督環境中。在這里,我們讓他們適應從一個深層網絡到另一個深層網絡的知識蒸餾任務。我們表明,致力于研究表現空間很重要,類似于最近的工作,如Zagoruyko和Komodakis(2016a);Remero等人(2014年)。然而,請注意,這些工作中使用的損失函數并沒有明確嘗試捕捉表征空間中的相關性或高階相關性。
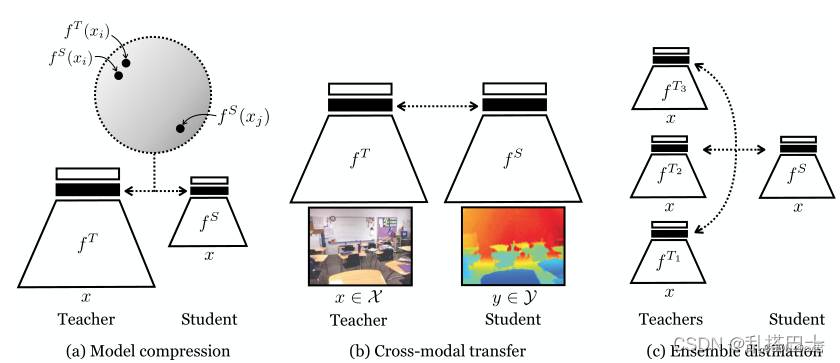
圖1:我們考慮的三種提取設置:(a)壓縮模型,(b)將知識從一種模式(例如RGB)轉移到另一種模式(例如深度),(c)將網絡集合提取到單個網絡中。對比目標鼓勵教師和學生將相同的輸入映射到接近的表示(在某些度量空間中),并將不同的輸入映射到遙遠的表示,如陰影圈所示。
我們的目標是最大化教師和學生之間的互信息的下限。我們發現,這會在多個知識轉移任務中產生更好的表現。我們推測,這是因為對比目標能更好地傳遞教師表征中的所有信息,而不僅僅是傳遞關于條件獨立輸出類概率的知識。有些令人驚訝的是,對比目標甚至改善了最初提出的提取類概率知識的任務的結果,例如,將大型CIFAR100網絡壓縮為性能幾乎相同的較小網絡。我們認為這是因為不同類別概率之間的相關性包含有用的信息,可以規范學習問題。我們的論文在兩個主要獨立發展的文獻之間建立了聯系:知識蒸餾和表征學習。這種聯系使我們能夠利用表征學習的強大方法,顯著提高知識蒸餾的SOTA。
我們的貢獻是:
1.基于對比的目標,用于在深度網絡之間傳遞知識。
2.模型壓縮、跨模態傳輸和整體蒸餾的應用。
3.對標12種最新蒸餾方法;CRD優于所有其他方法,例如,與原始KD相比,平均相對改善57%(Hinton等人,2015),令人驚訝的是,后者的表現次之。
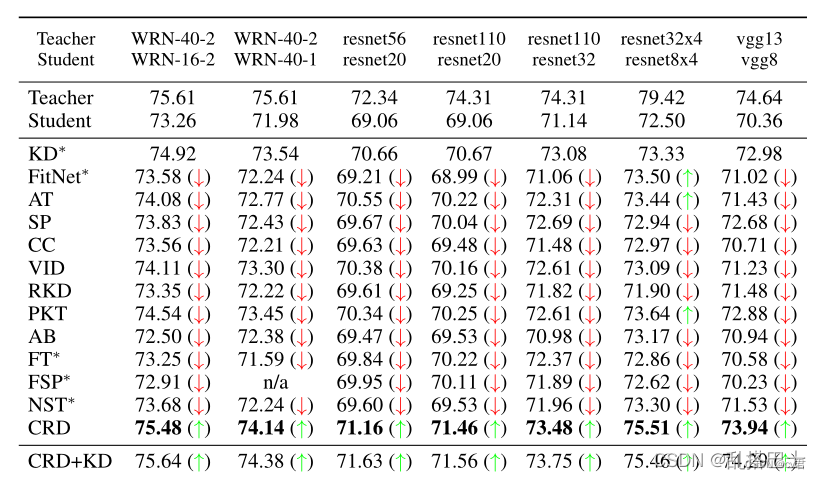
這是近幾年的得分,有使用crd結合其他損失的,可以在一些任務中得到較好表現,不同任務表現不一致,
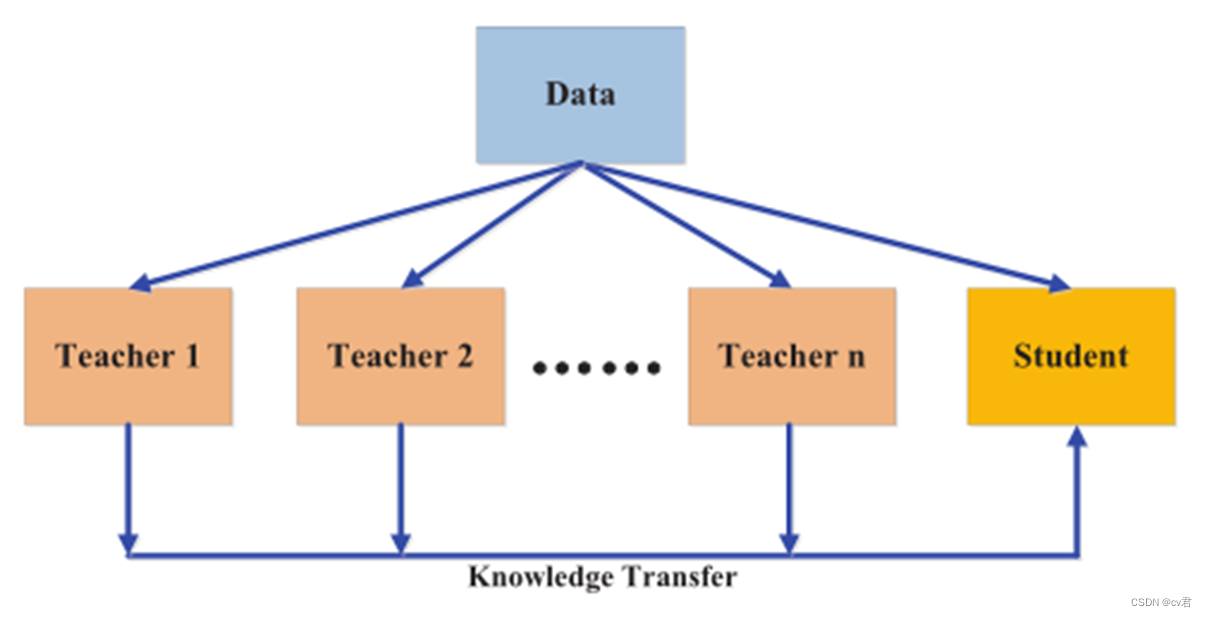
多教師蒸餾
多教師蒸餾(Multi-Teacher Distillation)是一種知識蒸餾的方法,它通過同時蒸餾多個教師網絡的知識來提升學生網絡的性能。相比于傳統的單一教師蒸餾,多教師蒸餾可以利用不同教師網絡的多樣性和豐富性,從而獲得更全面的知識傳遞。
在多教師蒸餾中,通常包括一個學生網絡(Student Network)和多個教師網絡(Teacher Networks)。每個教師網絡都是一個獨立的模型,具有不同的架構或參數初始化。學生網絡通過同時學習多個教師網絡的知識來提高自己的性能。
多教師蒸餾的核心思想是將不同教師網絡的預測結果作為輔助目標來訓練學生網絡。具體而言,多教師蒸餾包括以下步驟:
1、教師網絡的訓練:針對不同的教師網絡,使用標準的監督學習方法進行訓練,以獲得具有豐富知識的教師模型。
2、教師網絡的預測:使用已訓練好的教師網絡對輸入樣本進行預測,得到多個教師網絡的預測結果。
3、學生網絡的訓練:將教師網絡的預測結果作為輔助目標,與真實標簽一起用于訓練學生網絡。通過最小化學生網絡的預測與教師網絡預測之間的差異,將教師網絡的知識傳遞給學生網絡。
4、蒸餾損失函數的定義:通常使用交叉熵損失函數來衡量學生網絡的分類性能。同時,為了傳遞教師網絡的知識,可以定義額外的輔助目標損失,如平均軟標簽損失(Mean Soft Labels Loss)或特定的蒸餾損失函數。
通過多教師蒸餾,學生網絡能夠從多個教師網絡中獲得更豐富的知識,并綜合各個教師網絡的預測結果來提高自己的性能。多教師蒸餾可以增強模型的泛化能力,減少過擬合問題,并在復雜任務中取得更好的性能表現。
好,接下來我們從源碼分析;
蒸餾算法源碼分析
KD
鏈接:https://arxiv.org/pdf/1503.02531.pd3f
發表:NIPS14
class DistillKL(nn.Module):"""Distilling the Knowledge in a Neural Network"""def __init__(self, T):super(DistillKL, self).__init__()self.T = T #教師模型指導學生模型的程度(蒸餾溫度),值越大,指導程度越高def forward(self, y_s, y_t):p_s = F.log_softmax(y_s/self.T, dim=1)p_t = F.softmax(y_t/self.T, dim=1)#下面就是對兩個模型的預測值,做KL散度的分布分析,如果偏差越大,則kl散度算出來的值越大。#p_t表示教師模型的目標值#p_s表示學生模型的預測值loss = F.kl_div(p_s, p_t, size_average=False) * (self.T**2) / y_s.shape[0]return loss核心就是一個kl_div函數,用于計算學生網絡和教師網絡的分布差異。輸入為學生和教師模型的分類輸出,經過溫度可控的軟化之后進行KL散度計算,簡單直接粗暴有效;
FitNet
全稱:Fitnets: hints for thin deep nets
鏈接:https://arxiv.org/pdf/1412.6550.pdf
發表:ICLR 15 Poster
很容易理解,方法使用特征間信息,對中間層進行蒸餾的開山之作,通過將學生網絡的feature map擴展到與教師網絡的feature map相同尺寸以后,使用均方誤差MSE Loss來衡量兩者差異
(1)大模型訓練,小模型隨機初始化
(2)將大模型特征提取器的第H層作為hint,從第一層到第H層的參數對應圖(a)中Whint,,選擇小模型特征提取器的第G層作為guided,從第一層到第G層對應圖(a)中Wguided
(3)兩者feature map大小可能不匹配,引入卷積層調整器(Wr)對guided層進行調整,對應圖(b)
(4)優化均方損失函數
(5)對預訓練好的小模型進行進一步知識蒸餾,對應圖
class HintLoss(nn.Module):"""Fitnets: hints for thin deep nets, ICLR 2015"""def __init__(self):super(HintLoss, self).__init__()self.crit = nn.MSELoss() # 在這個類中,初始化函數中使用了nn.MSELoss(),即均方誤差損失函數,
用于度量學生網絡和教師網絡之間的均方誤差'''
在前向傳播函數中,接收學生網絡的中間層表示f_s和教師網絡的中間層表示f_t作為輸入。
然后使用均方誤差損失函數計算它們之間的差異,得到"hint"損失。
'''def forward(self, f_s, f_t):loss = self.crit(f_s, f_t)return lossclass ConvReg(nn.Module):"""Convolutional regression for FitNet 用來對齊T-S某層feature map的特征尺寸 可學"""def __init__(self, s_shape, t_shape, use_relu=True):super(ConvReg, self).__init__()self.use_relu = use_relus_N, s_C, s_H, s_W = s_shapet_N, t_C, t_H, t_W = t_shapeif s_H == 2 * t_H:self.conv = nn.Conv2d(s_C, t_C, kernel_size=3, stride=2, padding=1)elif s_H * 2 == t_H:self.conv = nn.ConvTranspose2d(s_C, t_C, kernel_size=4, stride=2, padding=1)elif s_H >= t_H:self.conv = nn.Conv2d(s_C, t_C, kernel_size=(1+s_H-t_H, 1+s_W-t_W))else:raise NotImplemented('student size {}, teacher size {}'.format(s_H, t_H))self.bn = nn.BatchNorm2d(t_C)self.relu = nn.ReLU(inplace=True)def forward(self, x):x = self.conv(x)if self.use_relu:return self.relu(self.bn(x))else:return self.bn(x)損失計算時,就先使用guided 網絡處理完,送進fitloss算一次mse即可;
Fitloss 使用的特征維度做監督,效果沒有kd好,可能是由于mse或者特征的提取選擇不好,可以考慮多使用幾個維度的特征監督;
PKT:Probabilistic Knowledge Transfer
全稱:Probabilistic Knowledge Transfer for deep representation learning
鏈接:https://arxiv.org/abs/1803.10837
發表:CoRR18
提出一種概率知識轉移方法,引入了互信息來進行建模。該方法具有可跨模態知識轉移、無需考慮任務類型、可將手工特征融入網絡等的優點。
class PKT(nn.Module):"""Probabilistic Knowledge Transfer for deep representation learningCode from author: https://github.com/passalis/probabilistic_kt"""def __init__(self):super(PKT, self).__init__()def forward(self, f_s, f_t):return self.cosine_similarity_loss(f_s, f_t)@staticmethoddef cosine_similarity_loss(output_net, target_net, eps=0.0000001):# Normalize each vector by its normoutput_net_norm = torch.sqrt(torch.sum(output_net ** 2, dim=1, keepdim=True))output_net = output_net / (output_net_norm + eps)output_net[output_net != output_net] = 0target_net_norm = torch.sqrt(torch.sum(target_net ** 2, dim=1, keepdim=True))target_net = target_net / (target_net_norm + eps)target_net[target_net != target_net] = 0# Calculate the cosine similaritymodel_similarity = torch.mm(output_net, output_net.transpose(0, 1))target_similarity = torch.mm(target_net, target_net.transpose(0, 1))# Scale cosine similarity to 0..1model_similarity = (model_similarity + 1.0) / 2.0target_similarity = (target_similarity + 1.0) / 2.0# Transform them into probabilitiesmodel_similarity = model_similarity / torch.sum(model_similarity, dim=1, keepdim=True)target_similarity = target_similarity / torch.sum(target_similarity, dim=1, keepdim=True)# Calculate the KL-divergenceloss = torch.mean(target_similarity * torch.log((target_similarity + eps) / (model_similarity + eps)))return loss這和PKT方法效果比KD好一些,主要是使用了概率傳遞學習先將教師和學生的網絡輸出進行標準化,再將輸出的特征信息使用矩陣乘法、概率化方法映射到另一個空間,最后進行KL散度計算,就是在KD的基礎上,將網絡輸出進行非線性映射成一個更簡單的空間,監督這個空間下的S-T KL散度
CRD: Contrastive Representation Distillation
全稱:Contrastive Representation Distillation
鏈接:https://arxiv.org/abs/1910.10699v2
發表:ICLR20
將對比學習引入知識蒸餾中,其目標修正為:學習一個表征,讓正樣本對的教師網絡與學生網絡盡可能接近,負樣本對教師網絡與學生網絡盡可能遠離。
構建的對比學習問題表示如下:
整體的蒸餾Loss表示如下:
實現如下:https://github.com/HobbitLong/RepDistiller
class ContrastLoss(nn.Module):"""contrastive loss, corresponding to Eq (18)"""def __init__(self, n_data):super(ContrastLoss, self).__init__()self.n_data = n_datadef forward(self, x):bsz = x.shape[0]m = x.size(1) - 1# noise distributionPn = 1 / float(self.n_data)# loss for positive pairP_pos = x.select(1, 0)log_D1 = torch.div(P_pos, P_pos.add(m * Pn + eps)).log_()# loss for K negative pairP_neg = x.narrow(1, 1, m)log_D0 = torch.div(P_neg.clone().fill_(m * Pn), P_neg.add(m * Pn + eps)).log_()loss = - (log_D1.sum(0) + log_D0.view(-1, 1).sum(0)) / bszreturn lossclass CRDLoss(nn.Module):"""CRD Loss functionincludes two symmetric parts:(a) using teacher as anchor, choose positive and negatives over the student side(b) using student as anchor, choose positive and negatives over the teacher sideArgs:opt.s_dim: the dimension of student's featureopt.t_dim: the dimension of teacher's featureopt.feat_dim: the dimension of the projection spaceopt.nce_k: number of negatives paired with each positiveopt.nce_t: the temperatureopt.nce_m: the momentum for updating the memory bufferopt.n_data: the number of samples in the training set, therefor the memory buffer is: opt.n_data x opt.feat_dim"""def __init__(self, opt):super(CRDLoss, self).__init__()self.embed_s = Embed(opt.s_dim, opt.feat_dim)self.embed_t = Embed(opt.t_dim, opt.feat_dim)self.contrast = ContrastMemory(opt.feat_dim, opt.n_data, opt.nce_k, opt.nce_t, opt.nce_m)self.criterion_t = ContrastLoss(opt.n_data)self.criterion_s = ContrastLoss(opt.n_data)def forward(self, f_s, f_t, idx, contrast_idx=None):"""Args:f_s: the feature of student network, size [batch_size, s_dim]f_t: the feature of teacher network, size [batch_size, t_dim]idx: the indices of these positive samples in the dataset, size [batch_size]contrast_idx: the indices of negative samples, size [batch_size, nce_k]Returns:The contrastive loss"""f_s = self.embed_s(f_s)f_t = self.embed_t(f_t)out_s, out_t = self.contrast(f_s, f_t, idx, contrast_idx)s_loss = self.criterion_s(out_s)t_loss = self.criterion_t(out_t)loss = s_loss + t_lossreturn loss他會在訓練過程中,使用contrast-memory 來記憶網絡的負樣本,在網絡訓練中互信息監督;效果不錯;
超分等生成任務與蒸餾
眾所周知,圖像/視頻超分 (SR) 是工業界非常具有應用場景的應用,但能夠生產具有良好視覺效果的重建圖像的SR模型的參數量和運算量都非常巨大,比如業界公認的優秀baseline模型EDSR,EDVR等的算力需求高達幾百,幾千GFLOPs。而業界真正需求的輕量化模型,尤其是可以部署于移動端設備的實時模型,其算力限制可能嚴苛到小于10GFlops。
在high-level CV tasks上得到廣泛應用和驗證的模型剪枝、c餾方法應用到超分任務上,即將一個訓練好的大模型進行裁剪,或者用性能較強的教師大模型蒸餾原本較弱的學生小模型,使裁剪/蒸餾后的小模型能夠取得相比普通訓練方式更好,甚至接近原先大模型的性能。這里的challenge在于,直接的遷移應用這些算法,在超分任務上無法得到有效的性能提升,甚至可能導致非常嚴重的performance degradation.
-
SRKD:它將最基本的知識蒸餾直接應用到圖像超分中,整體思想分類網絡中的蒸餾方式基本一致,整體來看屬于應用形式;
-
FAKD:它在常規知識蒸餾的基礎上引入了特征關聯機制,進一步提升被蒸餾所得學生網絡的性能,相比直接應用有了一定程度的提升;
-
PISR:它則是利用了廣義蒸餾的思想進行超分網絡的蒸餾,通過充分利用訓練過程中HR信息的可獲取性進一步提升學生網絡的性能。

上圖給出了SRKD的蒸餾示意圖,它采用了最基本的知識蒸餾思想對老師網絡與學生網絡的不同階段特征進行蒸餾。考慮到老師網絡與學生網絡的通道數可能是不相同的,SRKD則是對中間特征的統計信息進行監督。該文考慮了如下四種統計信息:
owards Compact Single Image Super-Resolution via Contrastive Self-distillation
鏈接:
code:GitHub - Booooooooooo/CSD: Towards Compact Single Image Super-Resolution via Contrastive Self-distillation, IJCAI21
發表:IJCAI21
團隊:Yonsei University
1.背景
卷積神經網絡在超分任務上取得了很好的成果,但是依然存在著參數繁重、顯存占用大、計算量大的問題,為了解決這些問題,作者提出利用對比自蒸餾實現超分模型的壓縮和加速。
我們的目標是同時壓縮和加速SR模型。我們提出了一個簡單的自蒸餾框架,其中學生網絡通過在每層使用教師的部分通道從教師(目標)網絡中分離出來。我們將這種學生網絡稱為信道分割超分辨率網絡(CSSRNet)。教師網絡和學生網絡共同訓練,形成兩個計算方式不同的SR模型。根據設備中計算資源的不同,我們可以動態分配這兩種模型,即在資源有限的設備中,如果超過所需的計算開銷,則選擇CSSR-Net,否則選擇教師模型.
主要貢獻
作者提出的對比自蒸餾(CSD)框架可以作為一種通用的方法來同時壓縮和加速超分網絡,在落地應用中的運行時間也十分友好。
自蒸餾被引用進超分領域來實現模型的加速和壓縮,同時作者提出利用對比學習進行有效的知識遷移,從而 進一步的提高學生網絡的模型性能。
在Urban100數據集上,加速后的EDSR+可以實現4倍的壓縮比例和1.77倍的速度提高,帶來的性能損失僅為0.13 dB PSNR。
2.方法
我們的CSD包括兩個部分:CSSR-Net和對比損失(CL)。首先,我們描述了CSSR-Net。然后,我們給出了構造CSSR-Net的上界和下界的正則表達式。
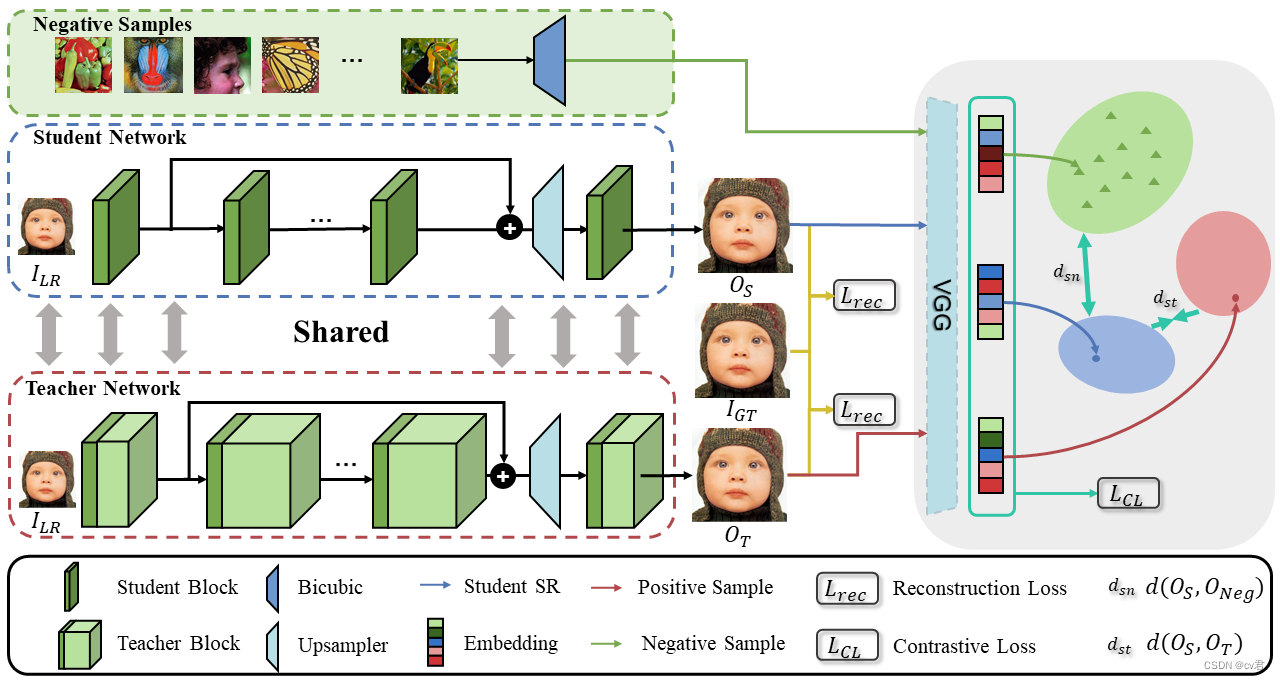
最后,給出了CSD方案的總體損失函數,并用一種新的優化策略對其進行了求解。
總結
回顧
近年來,知識蒸餾(Knowledge Distillation)方法在深度學習領域中備受關注,它是一種模型壓縮技術,旨在將一個復雜的模型(通常被稱為教師模型)的知識轉移到一個簡化的模型(通常被稱為學生模型)中,從而使學生模型能夠在保持性能的同時具有更小的模型尺寸和計算成本。
一些近年來的知識蒸餾方法和拓展包括:
-
Teacher-Student Architecture: 最常見的知識蒸餾方法之一是使用教師模型和學生模型之間的監督信號。教師模型通常是一個大型、復雜的模型,而學生模型則是一個較小、簡化的模型。通過讓學生模型學習教師模型的輸出,學生模型可以在學習到教師模型的知識的同時獲得更好的泛化性能。
-
Soft Target Training: 傳統的監督學習使用的是硬標簽(one-hot編碼),即只有正確類別的概率為1,其余為0。而軟目標訓練則使用教師模型的輸出概率分布作為目標。這種方法能夠提供更豐富的信息,使得學生模型可以學習到更多的知識。
-
Attention Mechanisms: 在知識蒸餾中引入注意力機制可以幫助學生模型更好地關注教師模型的重要信息,從而提高模型性能。
-
Self-Distillation: 自蒸餾是一種方法,其中學生模型在訓練過程中不僅要學習來自教師模型的知識,還要學習自身的輸出。這種方法可以進一步提高學生模型的性能,同時減少對教師模型的依賴。
-
Multi-Teacher Distillation: 多教師蒸餾是一種將多個教師模型的知識融合到學生模型中的方法。每個教師模型可能具有不同的視角或專長,通過結合它們的知識,學生模型可以獲得更全面和魯棒的學習。
未來
隨著深度學習模型的不斷發展和復雜化,未來的知識蒸餾方法可能會涉及更復雜的模型結構。這可能包括對于更深、更寬的神經網絡架構的探索,以及對于更復雜的模型組合和蒸餾技術的研究。例如,結合Transformer模型的自注意力機制與知識蒸餾技術可能會帶來更加高效的模型壓縮和知識傳遞方式。
其次,未來的知識蒸餾方法可能會更加注重模型的智能化和個性化。這意味著,蒸餾過程將更加關注于學生模型的個性化需求和特征提取,以及對于不同學習任務和場景的適應性。這可能會涉及到更加精細的目標函數設計、更加智能化的蒸餾策略以及更加靈活的模型結構。
目前有的蒸餾方法效果提升不大,知識蒸餾還有很大提升空間,因為網絡中有大量的參數,而實際使用到的很少,所以可以在蒸餾方法上優化,將特征提取和知識傳遞做得更通用,或者更準確,甚至像大模型的預訓練與微調一樣,或者是自監督蒸餾,或者是自動地結合上剪枝量化,感知量化等等方法。
reference
1、crd https://arxiv.org/abs/1910.1069
2、crd code https://github.com/HobbitLong/RepDistiller
3、cls kd https://blog.csdn.net/akaweige/article/details/131520764
4、sr kd https://zhuanlan.zhihu.com/p/346422123
5、cls kd https://zhuanlan.zhihu.com/p/102038521









![[解決方法]echarts地圖/圖表縮放,側邊欄導致樣式自適應問題](http://pic.xiahunao.cn/[解決方法]echarts地圖/圖表縮放,側邊欄導致樣式自適應問題)


)

)




