1.哨兵機制原理
? ? ?1.1.三個定時任務
????????Sentinel 維護著三個定時任務以監測 Redis 節點及其它 Sentinel 節點的狀態
? ? ? ? 1)info 任務:每個 Sentinel 節點每 10 秒就會向 Redis 集群中的每個節點發送 info 命令,以獲得最新的 Redis 拓撲結構
? ? ? ? 2)心跳任務:每個Sentinel節點每1秒就會向所有Redis節點及其它Sentinel節點發送一條ping命令, 以檢測這些節點的存活狀態。該任務是判斷節點在線狀態的重要依據
? ? ? ? 3)發布/訂閱任務:啟動后,每個 Sentinel 節點每 2 秒就會向每個 Redis 節點發布一條_ _sentinel_ _:hello 主 題的信息,該信息是當前 Sentinel 對每個 Redis 節點在線狀態的判斷結果及當前 Sentinel 節 點信息。當 Sentinel 節點接收到_ _sentinel_ _:hello 主題信息后,就會讀取并解析這些信息,然后如果發現有新的 Sentinel 節點加入,則記錄下新加入 Sentinel 節點信息,并與其建立連接;如果發現有 Sentinel Leader 選舉的選票信息,則執行 Leader 選舉過程;匯總其它 Sentinel 節點對當前 Redis 節點在線狀態的判斷結果,作為 Redis 節點客觀下 線的判斷依據
? ? ?1.2.Redis 節點下線判斷
????????對于每個 Redis 節點在線狀態的監控是由 Sentinel 完成的
? ? ? ? 1)主觀下線:每個 Sentinel 節點每秒就會向每個 Redis 節點發送 ping 心跳檢測,如果 Sentinel 在 down-after-milliseconds 時間內沒有收到某 Redis 節點的回復,則 Sentinel 節點就會對該 Redis 節點做出“下線狀態”的判斷。這個判斷僅僅是當前 Sentinel 節點的“一家之言”,所以稱 為主觀下線
? ? ? ? 2)客觀下線:當 Sentinel 主觀下線的節點是 master 時,該 Sentinel 節點會向每個其它 Sentinel 節點發 送 sentinel is-master-down-by-addr 命令,以詢問其對 master 在線狀態的判斷結果。這些 Sentinel 節點在收到命令后會向這個發問 Sentinel 節點響應 0(在線)或 1(下線)。當 Sentinel 收到超過 quorum 個下線判斷后,就會對 master 做出客觀下線判斷
? ? ?1.3.Sentinel Leader 選舉
????????當 Sentinel 節點對 master 做出客觀下線判斷后會由 Sentinel Leader 來完成后續的故障轉移,Sentinel 集群的 Leader 選舉是通過 Raft 算法實現
????????每個選舉參與者都具有當選 Leader 的資格,當其完成了“客觀下線”判斷后,就會立 即“毛遂自薦”推選自己做 Leader,然后將自己的提案發送給所有參與者。其它參與者在收到提案后,只要自己手中的選票沒有投出去,其就會立即通過該提案并將同意結果反饋給提案者,后續再過來的提案會由于該參與者沒有了選票而被拒絕。當提案者收到了同意反饋數量大于等于 max(quorum,sentinelNum/2+1)時,該提案者當選 Leader
????????在網絡沒有問題的前提下,基本就是誰先做出了“客觀下線”判斷,誰就會首先發起 Sentinel Leader 的選舉,誰就會得到大多數參與者的支持,誰就會當選 Leader;Sentinel Leader 選舉會在次故障轉移發生之前進行;故障轉移結束后 Sentinel 不再維護這種 Leader-Follower 關系,即 Leader 不再存在
? ? ?1.4.master 選擇算法
????????在進行故障轉移時,Sentinel Leader 需要從所有 Redis 的 Slave 節點中選擇出新的 Master。 其選擇算法為:
? ? ? ? 1)過濾掉所有主觀下線的,或心跳沒有響應 Sentinel 的,或 replica-priority 值為 0 的 Redis 節點
? ? ? ? 2)在剩余 Redis 節點中選擇出 replica-priority 最小的的節點列表。如果只有一個節點,則直接返回,否則繼續
? ? ? ? 3)從優先級相同的節點列表中選擇復制偏移量最大的節點。如果只有一個節點,則直接返 回,否則繼續
? ? ? ? 4)從復制偏移值量相同的節點列表中選擇動態 ID 最小的節點返回
? ? ?1.5.故障轉移過程
? ? ? ? 1)Sentinel Leader 根據 master 選擇算法選擇出一個 slave 節點作為新的 master
? ? ? ? 2)Sentinel Leader 向新 master 節點發送 slaveof no one 指令,使其晉升為 master
? ? ? ? 3)Sentinel Leader 向新 master 發送 info replication 指令,獲取到 master 的動態 ID
? ? ? ? 4)Sentinel Leader 向其余 Redis 節點發送消息,以告知它們新 master 的動態 ID
? ? ? ? 5)Sentinel Leader 向其余 Redis 節點發送 slaveof 指令,使它們成為新 master 的 slave
? ? ? ? 6)Sentinel Leader 從所有 slave 節點中每次選擇出 parallel-syncs 個 slave 從新 master 同步數 據,直至所有 slave 全部同步完畢,故障轉移完畢
? ? ?1.6.節點上線
? ? ? ? 1)原 Redis 節點上線:無論是原下線的 master 節點還是原下線的 slave 節點,只要是原 Redis 集群中的節點上 線,只需啟動 Redis 即可。因為每個 Sentinel 中都保存有原來其監控的所有 Redis 節點列表, Sentinel 會定時查看這些 Redis 節點是否恢復。如果查看到其已經恢復,則會命其從當前 master 進行數據同步。如果是原 master 上線,在新 master 晉升后 Sentinel Leader 會立即先將原 master 節點更新為 slave,然后才會定時查看其是否恢復
? ? ? ? 2)新 Redis 節點上線:如果需要在 Redis 集群中添加一個新的節點,其未曾出現在 Redis 集群中,則上線操作 只能手工完成。即添加者在添加之前必須知道當前 master 是誰,然后在新節點啟動后運行 slaveof 命令加入集群
? ? ? ? 3)Sentinel 節點上線:如果要添加的是 Sentinel 節點,無論其是否曾經出現在 Sentinel 集群中,都需要手工完 成。即添加者在添加之前必須知道當前 master 是誰,然后在配置文件中修改 sentinel monitor 屬性,指定要監控的 master。然后啟動 Sentinel 即可
2.CAP 定理
? ? ? 2.1.概念
????????是在一個分布式系統中,一致性、可用性、分區容錯性,三者不可兼得
? ? ? ? 1)一致性:分布式系統中多個主機之間是否能夠保持數據一致的特性。即,當系統數據發生更新操作后,各個主機中的數據仍然處于一致的狀態
? ? ? ? 2)可用性:系統提供的服務必須一直處于可用的狀態,即對于用戶的每一個請求,系統總是可以在有限的時間內對用戶做出響應
? ? ? ? 3)分區容錯性:分布式系統在遇到任何網絡分區故障時,仍能夠保證對外提供滿足一 致性和可用性的服務
? ? ?2.2.定理
????????CAP 定理的內容是:對于分布式系統,網絡環境相對是不可控的,出現網絡分區是不可 避免的,因此系統必須具備分區容錯性。但系統不能同時保證一致性與可用性。即要么 CP, 要么 AP
? ? ?2.3.BASE 理論
????????BASE 是 Basically Available(基本可用)、Soft state(軟狀態)和 Eventually consistent(最 終一致性)三個短語的簡寫,BASE 是對 CAP 中一致性和可用性權衡的結果,其來源于對大 規模互聯網系統分布式實踐的結論,是基于 CAP 定理逐步演化而來的
? ? ? ? 核心思想:即使無法做到強一致性,但每個系統都可以根據自身的業務特點,采用適當的方式來使系統達到最終一致性
? ? ? ? 1)基本可用:分布式系統在出現不可預知故障的時候,允許損失部分可用性
? ? ? ? 2)軟狀態:允許系統數據存在的中間狀態,并認為該中間狀態的存在不會影響系統的 整體可用性,即允許系統主機間進行數據同步的過程存在一定延時。軟狀態,其實就是一種 灰度狀態,過渡狀態
? ? ? ? 3)最終一致性:強調的是系統中所有的數據副本,在經過一段時間的同步后,最終能夠達到 一個一致的狀態。因此,最終一致性的本質是需要系統保證最終數據能夠達到一致,而不需要保證系統數據的實時一致性
?????2.4.CAP 的應用
? ? ? ? 1)Zookeeper 與 CAP:Zookeeper 遵循的是 CP 模式,即保證了一致性,但犧牲了可用性。當 Leader 節點中的數據發生了變化后,在 Follower 還沒有同步完成之前,整個 Zookeeper集群是不對外提供服務的。如果此時有客戶端來訪問數據,則客戶端會因訪問超時而發生重試。不過,由于 Leader 的選舉非常快,所以這種重試對于用戶來說幾乎是感知不到的。因此Zookeeper 保證了一致性,但犧牲了可用性
? ? ? ? 2)Consul 與 CAP:Consul 遵循的是 CP 模式,即保證了一致性,但犧牲了可用性
? ? ? ? 3)Redis 與 CAP:Redis 遵循的是 AP 模式,即保證了可用性,但犧牲了一致性
? ? ? ? 4)Eureka 與 CAP:Eureka 遵循的是 AP 模式,即保證了可用性,但犧牲了一致性
? ? ? ? 5)Nacos 與 CAP:Nacos 在做注冊中心時,默認是 AP 的。但其也支持 CP 模式,但需要用戶提交請求進行 轉換
3.Raft 算法
? ? ?3.1.概念
????????Raft 算法是一種通過對日志復制管理來達到集群節點一致性的算法。這個日志復制管理 發生在集群節點中的 Leader 與 Followers 之間。Raft 通過選舉出的 Leader 節點負責管理日志 復制過程,以實現各個節點間數據的一致性
? ? ? ? 動畫演示:https://thesecretlivesofdata.com/raft/
? ? ?3.2.角色、任期及角色轉變
????????在 Raft 中,節點有三種角色:
? ? ? ? 1)Leader:唯一負責處理客戶端寫請求的節點;也可以處理客戶端讀請求;同時負責日志 復制工作
? ? ? ? 2)Candidate:Leader 選舉的候選人,其可能會成為 Leader。是一個選舉中的過程角色
? ? ? ? 3)Follower:可以處理客戶端讀請求;負責同步來自于 Leader 的日志;當接收到其它
????????Cadidate 的投票請求后可以進行投票;當發現 Leader 掛了,其會轉變為 Candidate 發起 Leader 選舉
? ? ?3.3.leader 選舉
? ? ? ? 1)參加選舉:若 follower 在心跳超時范圍內沒有接收到來自于 leader 的心跳,則認為 leader 掛了。此 時其首先會使其本地 term 增一。然后 follower 會依次完成:此時若接收到了其它 candidate 的投票請求,則會將選票投給這個 candidate;由 follower 轉變為 candidate;若之前尚未投票,則向自己投一票;向其它節點發出投票請求,然后等待響應
? ? ? ? 2)參加投票:follower 在接收到投票請求后,判斷是否投票:發來投票請求的 candidate 的 term 不能小于自己的 term;在自身當前 term 內,選票還沒有投出去;若接收到多個 candidate 的請求,將采取 first-come-first-served 方式投票
? ? ? ? 3)等待響應:當一個 Candidate 發出投票請求后會等待其它節點的響應結果。這個響應結果:收到過半選票,成為新的 leader,然后會將消息廣播給所有其它節點,以告訴大家自己是新的 Leader 了;接收到別的 candidate 發來的新 leader 通知,比較了新 leader 的 term 并不比自己的 term 小,則自己轉變為 follower;經過一段時間后,沒有收到過半選票,也沒有收到新 leader 通知,則重新發出選舉
? ? ? ? 4)選舉時機:在很多時候,當 Leader 真的掛了,Follower 幾乎同時會感知到,所以它們幾乎同時會變 為 candidate 發起新的選舉。此時就可能會出現較多 candidate 票數相同的情況,即無法選舉出 Leader。為了防止這種情況的發生,Raft 算法其采用了 randomized election timeouts 策略來解決 這個問題。其會為這些 Follower 隨機分配一個選舉發起時間 election timeout,這個 timeout 在 150-300ms 范圍內。只有到達了 election timeout 時間的 Follower 才能轉變為 candidate, 否則等待。那么 election timeout 較小的 Follower 則會轉變為 candidate 然后先發起選舉,一 般情況下其會優先獲取到過半選票成為新的 leader
? ? ?3.4.數據同步
? ? ? ? 1)狀態機:Raft 算法一致性的實現,是基于日志復制狀態機的。狀態機的最大特征是,不同 Server 中的狀態機若當前狀態相同,然后接受了相同的輸入,則一定會得到相同的輸出
? ? ? ? 2)處理流程:
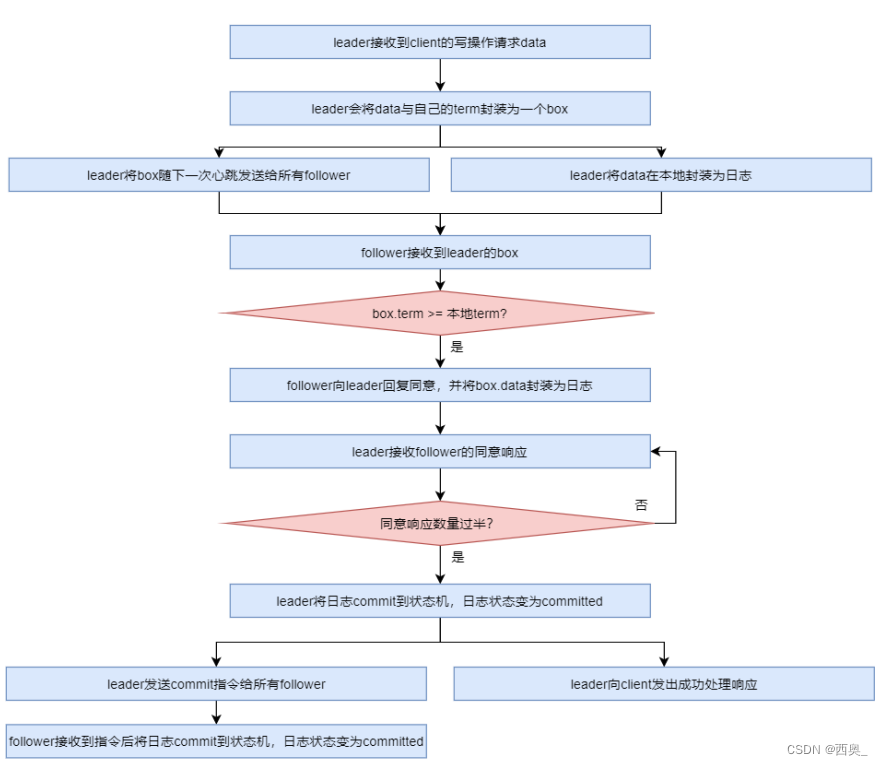
? ? ? ? ? ?a.當leader 接收到 client 的寫操作請求后,leader 會將數據與 term 封裝為一個 box,并隨 著下一次心跳發送給所有 followers,以征求大家對該 box 的意見。同時在本地將數據封 裝為日志
? ? ? ? ? ?b.當follower 接收到來自 leader 的 box 后首先會比較該 box 的 term 與本地記錄的曾接受過 的 box 的最大 term,只要不比自己的小就接受該 box,并向 leader 回復同意。同時會將 該 box 中的數據封裝為日志
? ? ? ? ? ?c.當 leader 接收到過半同意響應后,會將日志 commit 到自己的狀態機,狀態機會輸出一 個結果,同時日志狀態變為了 committed
? ? ? ? ? ?d.同時 leader 還會通知所有 follower 將日志 commit 到它們本地的狀態機,日志狀態變為 了 committed
? ? ? ? ? ?e.在 commit 通知發出的同時,leader 也會向 client 發出成功處理的響應
? ? ? ? 3)AP 支持:Log 由 term index、log index 及 command 構成。為了保證可用性,各個節點中的日志可 以不完全相同,但 leader 會不斷給 follower 發送 box,以使各個節點的 log 最終達到相同。 即 raft 算法不是強一致性的,而是最終一致的
? ? ?3.5.腦裂
????????Raft 集群存在腦裂問題。在多機房部署中,由于網絡連接問題,很容易形成多個分區。而多分區的形成,很容易產生腦裂,從而導致數據不一致。由于三機房部署的容災能力最強,所以生產環境下,三機房部署是最為常見的。下面以三機房部署為例進行分析,根據機房斷網情況,可以分為五種情況:
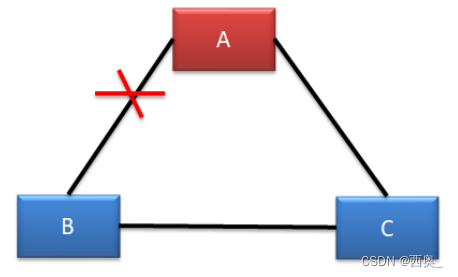
? ? ? ? 1)不確定:B 機房中的主機是感知不到 Leader 的存在的,所以 B 機房中的主機會發起新一輪的 Leader 選舉。雖然 C 機房中的 Follower 能夠感知到 A 機房中的 Leader,但由于其接收到了更大 term 的投票請求,所以 C 機房的 Follower 也就放棄了 A 機房中的 Leader,參與了新 Leader 的選舉。
? ? ? ? ? ?a.若新 Leader 出現在 B 機房,A 機房是感知不到新 Leader 的誕生的,其不會自動下課, 所以會形成腦裂。由于 A 機房 Leader 處理的寫操作請求無法獲取到過半響應,所以無法完成寫操作。但 B 機房 Leader 的寫操作處理是可以獲取到過半響應的,所以可以完成寫操作,形成了數據的不一致。
? ? ? ? ? ?b.若新 Leader 出現在 C 機房,A 機房中的 Leader 則會自動下課,所以不會形成腦裂。
·?????????
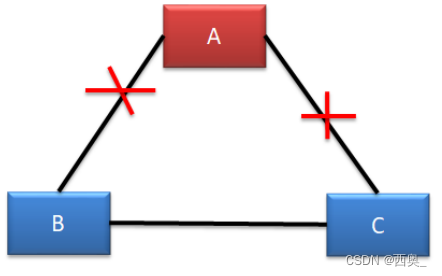
? ? ? ? 2)形成腦裂
? ? ? ? ??
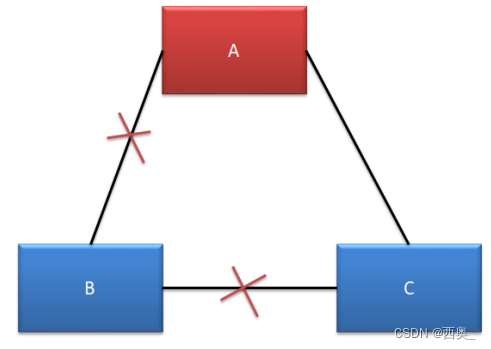
? ? ? ? 3)無腦裂:A、C 可以正常對外提供服務,但 B 無法選舉出新的 Leader。由于 B 中的主機全部變為 了選舉狀態,所以無法提供任何服務,沒有形成腦裂
????????
? ? ? ? 4)無腦裂:A、B、C 均可以對外提供服務,不受影響
????????
? ? ? ? 5)無腦裂:A 機房無法處理寫操作請求,但可以對外提供讀服務。B、C 機房由于失去了 Leader,均會發起選舉,但由于均無法獲取過半支持,所以均無法選舉出新的 Leader
????????
? ? ?3.6.Leader 宕機處理
? ? ? ? 1)請求到達前 Leader 掛了:client 發送寫操作請求到達 Leader 之前 Leader 就掛了,因為請求還沒有到達集群,所以 這個請求對于集群來說就沒有存在過,對集群數據的一致性沒有任何影響。Leader 掛了之 后,會選舉產生新的 Leader。由于 Stale Leader 并未向 client 發送成功處理響應,所以 client 會重新發送該寫操作請求
? ? ? ? 2)未開始同步數據前 Leader 掛了:client 發送寫操作請求給 Leader,請求到達 Leader 后,Leader 還沒有開始向 Followers 發出數據 Leader 就掛了。這時集群會選舉產生新的 Leader。Stale Leader 重啟后會作為 Follower 重新加入集群,并同步新 Leader 中的數據以保證數據一致性。之前接收到 client 的 數據被丟棄。由于 Stale Leader 并未向 client 發送成功處理響應,所以 client 會重新發送該寫操作請求
? ? ? ? 3)同步完部分后 Leader 掛了:client 發送寫操作請求給 Leader,Leader 接收完數據后向所有 Follower 發送數據。在部分 Follower 接收到數據后 Leader 掛了。由于 Leader 掛了,就會發起新的 Leader 選舉。
? ? ? ? ? ?a.若 Leader 產生于已完成數據接收的 Follower,其會繼續將前面接收到的寫操作請求轉換 為日志,并寫入到本地狀態機,并向所有 Flollower 發出詢問。在獲取過半同意響應后 會向所有 Followers 發送 commit 指令,同時向 client 進行響應
? ? ? ? ? ?b.若 Leader 產生于尚未完成數據接收的 Follower,那么原來已完成接收的 Follower 則會放 棄曾接收到的數據。由于 client 沒有接收到響應,所以 client 會重新發送該寫操作請求
? ? ? ? 4)commit 通知發出后 Leader 掛了:client 發送寫操作請求給 Leader,Leader 也成功向所有 Followers 發出的 commit 指令, 并向 client 發出響應后,Leader 掛了。由于 Stale Leader 已經向 client 發送成功接收響應,且 commit 通知已經發出,說明這個 寫操作請求已經被 server 成功處理

)






(76))

】圖的最短路徑問題)



)


)

