完整代碼關注公眾號 :


爬取網站:BOSS直聘:https://www.zhipin.com/
難點
1. boss直聘不論什么崗位都只會展示10頁數據,就算在網頁里加到了11,內容也會和10一樣。
2.多次訪問會有驗證碼需要登錄,這部分需要手動解除
3. 網站源碼被加密了,沒法通過request直接鏈接網站獲取源碼

解決辦法:
采用selenium控制瀏覽器的方式,成功獲取源碼,并且獲取頁面元素
防止頁面需要驗證來中斷爬取,采用企業微信(或者釘釘機器人)的方式來提醒需要驗證了(這部分沒法代碼通過,除非后續采用圖像識別跳過驗證碼)
既然每個崗位只能爬取10頁,我們可以采取一個崗位分10個地區,比如我需要爬取長沙市的xx崗位,直接爬取只能出現10頁總共300個崗位,但是可以拆分成8個區的爬取,每個區假設都有10頁,就可能爬取到80頁數據。
爬取系統介紹
功能介紹:
1. 首先在配置文件config中更改爬取要求,
jobs = ['數據分析師']citys = {# '101280600':'深圳''101250100': "長沙",# '101280100': '廣州',# '101230200':'廈門'}# areaBusiness = '330113,'.split(',')experience = (",".join([ # 不需要的可以注釋掉# '108', # 在校生# '102', # 應屆生'101', # 經驗不限'103', # 1年以內'104', # 1-3年# '105', # 3-5年# '106', # 5-10年# '107', # 10年以上]))degree = ",".join([ # 學歷要求'209', # 初中及以下'208', # 中專/中技'206', # 高中'202', # 大專'203', # 本科# '204', # 碩士# '205', # 博士])# 獲取該城市的各一級區域區號
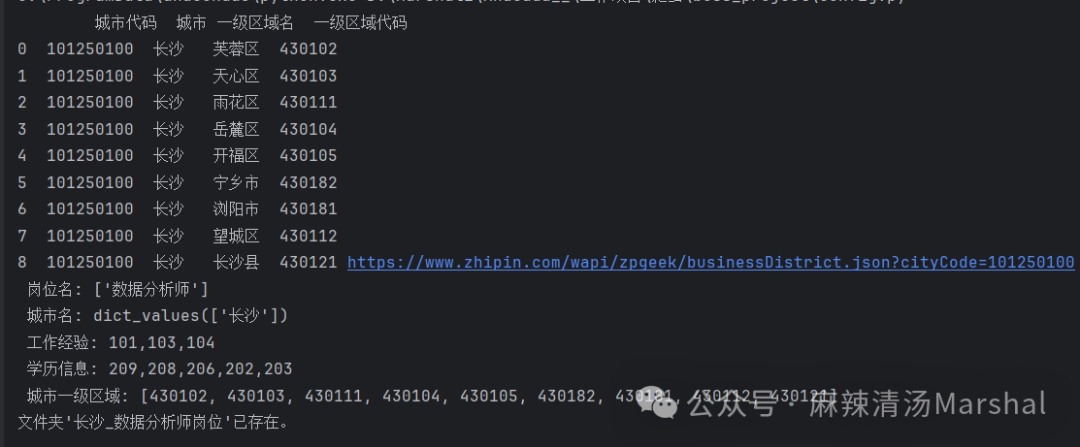
確定好爬取需求之后,會在當前目下創建一個根據崗位和城市名的文件,后續爬取好的崗位信息都會保存在該文件內。
2. 開始爬取
這是整體系統框架,包含五個函數,最下面是系統的入口
首先需要知道每個地區總共有多個頁面可以爬取,首先完成
if __name__ == "__main__":boss = webdriver.Edge(service=Service(EdgeChromiumDriverManager().install()), options=edge_options)存放文件夾位置=f'D:\Marshal1\Anacada__\工作項目\爬蟲\\boss_project\\'+f'{文件名}'對應頁碼表=查看每個區存在多少頁崗位(存放文件夾位置)
這里需要更改文件存放位置,選擇想要將文件保存的地址
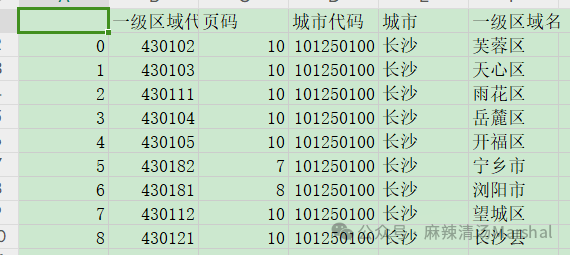
執行完函數“查看每個區存在多少頁崗位(存放文件夾位置)”之后,在存放文件夾位置下會生成一個文件“對應頁碼表”,后續需要根據這個文件來確定不同區需要爬取的頁碼數,防止爬取重復數據。
if __name__ == "__main__":
boss = webdriver.Edge(service=Service(EdgeChromiumDriverManager().install()), options=edge_options)
存放文件夾位置=f'D:\Marshal1\Anacada__\工作項目\爬蟲\\boss_project\\'+f'{文件名}' 對應頁碼表=查看每個區存在多少頁崗位(存放文件夾位置)對應頁碼表=pd.read_csv(f"{存放文件夾位置}\對應頁碼表.csv") 獲取對應崗位信息(對應頁碼表,存放文件夾位置)
然后執行“獲取對應崗位信息(對應頁碼表,存放文件夾位置)”,之后在本地生成一個csv文件,不包含崗位的職位描述的文件,如果還需要職位的描述字段需要繼續執行最后一行代碼
獲取崗位職責(存放文件夾位置)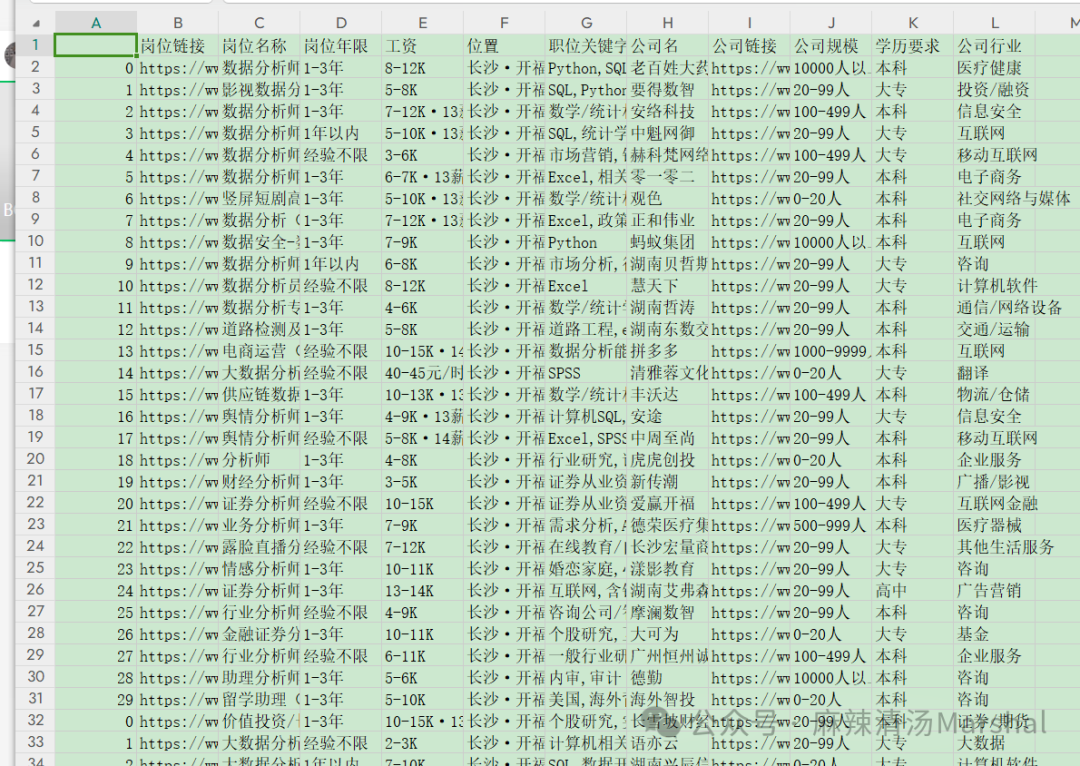






:樹形DP)












