大模型研究學習
1.大模型的“幻覺”
幻覺可以分為事實性幻覺和忠實性幻覺。
事實性幻覺,是指模型生成的內容與可驗證的現實世界事實不一致。
比如問模型“第一個在月球上行走的人是誰?”,模型回復“Charles Lindbergh在1951年月球先驅任務中第一個登上月球”。實際上,第一個登上月球的人是Neil Armstrong。
事實性幻覺又可以分為事實不一致(與現實世界信息相矛盾)和事實捏造(壓根沒有,無法根據現實信息驗證)。
忠實性幻覺,則是指模型生成的內容與用戶的指令或上下文不一致。
比如讓模型總結今年10月的新聞,結果模型卻在說2006年10月的事。
忠實性幻覺也可以細分,分為指令不一致(輸出偏離用戶指令)、上下文不一致(輸出與上下文信息不符)、邏輯不一致三類(推理步驟以及與最終答案之間的不一致)。
1.致使產生幻覺的原因有哪些?
其中就包括數據缺陷、數據中捕獲的事實知識的利用率較低。數據缺陷分為錯誤信息和偏見(重復偏見、社會偏見),此外大模型也有知識邊界,所以存在領域知識缺陷和過時的事實知識。
即便大模型吃掉了大量數據,也會在利用時出現問題。
大模型可能會過度依賴訓練數據中的一些模式,如位置接近性、共現統計數據和相關文檔計數,從而導致幻覺。
此外,大模型還可能會出現長尾知識回憶不足、難以應對復雜推理的情況。
主要是預訓練階段(大模型學習通用表示并獲取世界知識)、對齊階段(微調大模型使其更好地與人類偏好一致)兩個階段產生問題。
預訓練階段可能會存在:
- 架構缺陷。基于前一個token預測下一個token,這種單向建模阻礙了模型捕獲復雜的上下文關系的能力;自注意力模塊存在缺陷,隨著token長度增加,不同位置的注意力被稀釋。
- 曝露偏差。訓練策略也有缺陷,模型推理時依賴于自己生成的token進行后續預測,模型生成的錯誤token會在整個后續token中產生級聯錯誤。
對齊階段可能會存在:
- 能力錯位。大模型內在能力與標注數據中描述的功能之間可能存在錯位。當對齊數據需求超出這些預定義的能力邊界時,大模型會被訓練來生成超出其自身知識邊界的內容,從而放大幻覺的風險。
- 信念錯位。基于RLHF等的微調,使大模型的輸出更符合人類偏好,但有時模型會傾向于迎合人類偏好,從而犧牲信息真實性。
大模型產生幻覺的第三個關鍵因素是推理,存在兩個問題:
- 固有的抽樣隨機性:在生成內容時根據概率隨機生成。
- 不完美的解碼表示:上下文關注不足(過度關注相鄰文本而忽視了源上下文)和softmax瓶頸(輸出概率分布的表達能力受限)。
2.如何減輕幻覺?
1.數據相關的幻覺
減少錯誤信息和偏見,最直觀的方法是收集高質量的事實數據,并進行數據清理以消除偏見。
對于知識邊界的問題,有兩種流行方法。一種是知識編輯,直接編輯模型參數彌合知識差距。另一種通過檢索增強生成(RAG)利用非參數知識源。
檢索增強具體分為三種類型:一次性檢索、迭代檢索和事后檢索。
2.訓練相關的幻覺
根據致幻原因,可以完善有缺陷的模型架構.
從模型預訓練階段來講,最新進展試圖通過完善預訓練策略、確保更豐富的上下文理解和規避偏見來應對這一問題。
比如針對模型對文檔式的非結構化事實知識理解碎片化、不關聯,有研究在文檔的每個句子后附加一個TOPICPREFIX,將它們轉換為獨立的事實,從而增強模型對事實關聯的理解。
此外,還可以通過改進人類偏好判斷、激活引導,減輕對齊錯位問題。
3.推理相關的幻覺
不完美的解碼通常會導致模型輸出偏離原始上下文。
研究人員探討了兩種高級策略,一種是事實增強解碼,另一種是譯后編輯解碼。
此外,忠實度增強解碼優先考慮與用戶說明或提供的上下文保持一致,并強調增強生成內容的一致性。現有工作可以總結為兩類,包括上下文一致性和邏輯一致性。
有關上下文一致性的最新研究之一是上下文感知解碼(CAD),通過減少對先驗知識的依賴來修改輸出分布,從而促進模型對上下文信息的關注。
有關邏輯一致性的最新一項研究包括知識蒸餾框架,用來增強思維鏈提示中固有的自洽性。
2.lora的訓練方法指的是什么?
LoRA模型,全稱Low-Rank Adaptation of Large Language Models,是一種用于微調大型語言模型的低秩適應技術。
LoRA通過僅訓練低秩矩陣,然后將這些參數注入到原始模型中,從而實現對模型的微調。這種方法不僅減少了計算需求,而且使得訓練資源比直接訓練原始模型要小得多,因此非常適合在資源有限的環境中使用。
1.lora是如何進行工作的?
LoRA 對Stable Diffusion模型中最關鍵的部分進行微小改動:交叉注意力層。這是模型中圖像和提示相遇的部分。研究人員發現,僅微調模型的這一部分就足以實現良好的訓練效果。交叉注意力層在下方的Stable Diffusion模型架構中以黃色部分表示。
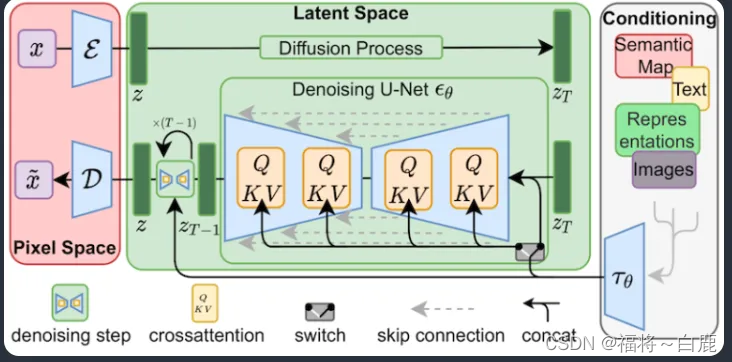
LoRA 的技巧在于將矩陣分解為兩個較小(低秩)的矩陣。這樣可以存儲更少的數字。假設模型有一個具有 1,000 行和 2,000 列的矩陣。這就是要在模型文件中存儲的 2,000,000 個數字(1,000 x 2,000)。LoRA 將該矩陣分解為一個 1,000x2 的矩陣和一個 2x2,000 的矩陣。這只需要 6,000 個數字(1,000 x 2 + 2 x 2,000),是原始矩陣大小的 333 倍。這就是 LoRA 文件更小的原因。
3.外掛知識庫
1.什么是rag?
RAG,即LLM在回答問題或生成文本時,會先從大量文檔中檢索出相關的信息,然后基于這些信息生成回答或文本,從而提高預測質量。
2.外掛知識庫的實現思路
只用幾十萬量級的數據對大模型進行微調并不能很好的將額外知識注入大模型。如果想讓大模型根據文檔來回答問題,必須要精簡在輸入中文檔內容的長度。
如果模型對無限長的輸入都有很好的理解能力,那么我可以設計這樣一個輸入“以下是世界上所有樂隊的介紹:[插入100w字的樂隊簡介文檔],請根據上文給我介紹一下萬青這支樂隊”,讓模型來回答我的問題。
一種做法是,我們可以把文檔切成若干段,只將少量的和問題有關的文檔片段拿出來,放到大模型的輸入里。至此,”大模型外掛數據庫“的問題轉換成了“文本檢索的問題”了,目標是根據問題找出文檔中和問題最相關的片段,這已經和大模型本身完全無關了。
文本檢索里邊比較常用的是利用向量進行檢索,我們可以把文檔片段全部向量化(通過語言模型,如bert等),然后存到向量數據庫(如Annoy、 FAISS、hnswlib等)里邊,來了一個問題之后,也對問題語句進行向量話,以余弦相似度或點積等指標,計算在向量數據庫中和問題向量最相似的top k個文檔片段,作為上文輸入到大模型中。向量數據庫都支持近似搜索功能,在犧牲向量檢索準確度的情況下,提高檢索速度。


3.對稱語義檢索與非對稱語義檢索
問題1:How to learn Python online?
答案1:How to learn Python on the web?
適用于非對稱語義檢索的例子:
問題2:What is Python?
答案2:*Python is an interpreted, high-level and general-purpose programming language. Python’s design philosophy …”
對稱語義檢索的“問題”和“答案”要求有差不多的意思,或者根本就不屬于我們常規意義里的問答,而僅僅是同義句匹配。而非對稱語義檢索所做的任務才是我們常規意義下問答任務。很顯然,通過向量檢索的方式進行非對稱語義檢索的難度要大的多。對稱語義檢索的目標是找相似的句子,與向量檢索基于計算向量相似度的原理天然匹配,只需要模型有比較強的內容抽象能力就可以。但是非對稱語義檢索則要求模型能夠將問題和答案映射到同一空間
通過上述例子,可以看出向量檢索只能檢索出意思差不多的內容,下游用一個可以真正能很好理解語義的大模型進行進一步的提取檢索出來的句子中的信息是十分有必要的。
模型是否支持非對稱語義檢索的根本原因是什么呢?是訓練的數據不同
正是因為訓練數據有真正的問答屬性,模型才有真正的問答檢索能力(將問題與答案映射到同一向量空間)。我的理解是,如果訓練數據里沒有某一領域的數據,比如金融領域,那么通用的非對稱語義模型就不能很好的完成該領域的檢索任務。但是對稱語義檢索有“泛化”到其他領域的能力,畢竟只需要理解“字面意思”。

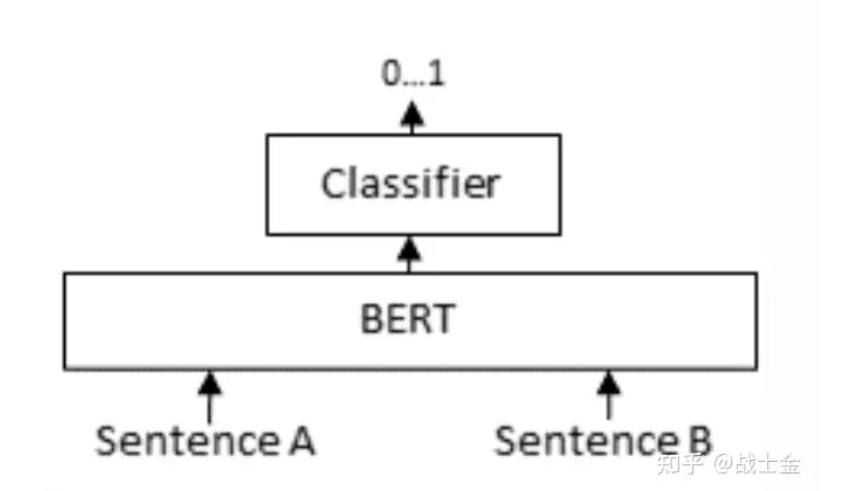
就直接把問題+答案拼在一起,做個二分類嘛。模型同時有了問題+答案這樣一對的上下文信息,當然比直接分別將問題+答案映射到相同的向量空間、再計算相似度準的多了。但是這種計算向量相似度的模式會慢。假設有m個問題和n個答案,向量檢索(圖中的bi-encoder環節)只需要跑m+n次bert模型就夠了,但是cross-encoder需要將所有問題和答案分別組合起來,跑m*n次bert模型。
4.如何協調查詢和文檔的語義空間?(上述問題的一個解決思路)
1.查詢重寫。
由于用戶的查詢可能表達不清晰或缺少必要的語義信息。因而可以使用大模型的能力生成一個指導性的偽文檔,然后將原始查詢與這個偽文檔結合,形成一個新的查詢。
也可以通過文本標識符來建立查詢向量,利用這些標識符生成一個相關但可能并不存在的“假想”文檔,它的目的是捕捉到相關的模式。
此外,多查詢檢索方法讓大語言模型能夠同時產生多個搜索查詢。這些查詢可以同時運行,它們的結果一起被處理,特別適用于那些需要多個小問題共同解決的復雜問題。
2.嵌入變換
在2023年提出的LLamaIndex中,研究者們通過在查詢編碼器后加入一個特殊的適配器,并對其進行微調,從而優化查詢的嵌入表示,從而使之更適合特定的任務。
Li 團隊在 2023 年提出的 SANTA 方法,就是為了讓檢索系統能夠理解并處理結構化的信息。他們提出了兩種預訓練方法:一是利用結構化與非結構化數據之間的自然對應關系進行對比學習;二是采用了一種圍繞實體設計的掩碼策略,讓語言模型來預測和填補這些被掩蓋的實體信息。
5.基本步驟概括
1.將文檔內容加載進來
2.由于文檔很長,可能會超出模型所允許的token,因而對文檔進行切割。
3.對文檔進行向量化,變成計算機可以理解的形式。
4.對數據進行檢索
在對數據進行檢索時,可以首先進行一下元數據過濾,當索引分成許多的chunks時,檢索效率會成為問題,通過元數據進行過濾,可以大大提升效率和相關度。
圖關系檢索:引入知識圖譜,將實體變成node,把它們之間的關系變成relation,就可以利用知識之間的關系做更準確的回答。
檢索技術
向量化(embedding)相似度檢索:相似度計算方式包括歐氏距離、曼哈頓距離、余弦等;
關鍵詞檢索:這是很傳統的檢索方式,元數據過濾也是一種,還有一種就是先把chunk做摘要,再通過關鍵詞檢索找到可能相關的chunk,增加檢索效率;
全文檢索:
SQL檢索:更加傳統的檢索算法。
重排序(Rerank):相關度、匹配度等因素做一些重新調整,得到更符合業務場景的排序。
查詢輪換:這是查詢檢索的一種方式,一般會有幾種方式:
子查詢:可以在不同的場景中使用各種查詢策略,比如可以使用LlamaIndex等框架提供的查詢器,采用樹查詢(從葉子結點,一步步查詢,合并),采用向量查詢,或者最原始的順序查詢chunks等;
HyDE:這是一種抄作業的方式,生成相似的或者更標準的 prompt 模板。
6.將原始query和檢索得到的文本組合起來輸入模型得到結果的過程,本質上就是個prompt enginering的過程。
6.現如今全流程的框架
Langchain和LLamaIndex
7.案例
1.chatPDF
2.Baichuan
3.Multi-modal retrieval-based LMs
8.存在的問題
1.檢索效果依賴embedding和檢索算法。目前可能檢索到無關信息,反而對輸出有負面影響。
2.大模型如何檢索到的信息仍是黑盒。可能仍存在不準確(甚至生成的文本與檢索信息相沖突)
3.對所有任務都無差別檢索 k 個文本片段,效率不高,同時會大大增加模型輸入的長度;
4.無法引用來源,也因此無法精準地查證事實,檢索的真實性取決于數據源及檢索算法。
9.RAG的評估方法
1.獨立評估
獨立評估涉及對檢索模塊和生成模塊的評估
指標:
1.答案相關性
此指標的目標是評估生成的答案與提供的問題提示之間的相關性。答案如果缺乏完整性或者包含冗余信息,那么其得分將相對較低。這一指標通過問題和答案的結合來進行計算,評分的范圍通常在0到1之間,其中高分代表更好的相關性。
2.忠實度
這個評價標準旨在檢查生成的答案在給定上下文中的事實準確性。評估的過程涉及到答案內容與其檢索到的上下文之間的比對。這一指標也使用一個介于0到1之間的數值來表示,其中更高的數值意味著答案與上下文的一致性更高。
3.上下文精確度
在這個指標中,我們評估所有在給定上下文中與基準信息相關的條目是否被正確地排序。理想情況下,所有相關的內容應該出現在排序的前部。這一評價標準同樣使用0到1之間的得分值來表示,其中較高的得分反映了更高的精確度。
4.答案正確性
該指標主要用于測量生成的答案與實際基準答案之間的匹配程度。這一評估考慮了基準答案和生成答案的對比,其得分也通常在0到1之間,較高的得分表明生成答案與實際答案的一致性更高。
現如今的評估框架:
RGAGS、ARES
大模型+強化學習的基本綜述
大模型更擅長解決基于生成的軟性問題,但在處理基于決策的硬性問題,例如選擇正確答案等方面效果相對較差。
生成問題通常使用掩碼來隱藏上下文信息,讓模型通過上文生成下文,這是一種自監督方法;而決策問題通常需要一個明確的答案,如是或否、A/B/C 選項,因此需要使用有監督數據進行訓練或微調模型。
將生成和強化學習結合起來是解決這個問題的一種思路,強化學習通過獎勵函數直接或間接地為模型提供有監督的判定標準。因此,在大模型中引入強化學習可以提升其判斷能力。
RLHF
后來出現了大模型,人們使用 RLHF 來訓練這些大模型,以提升它們學習人類偏好的能力。隨著時間的推移,大模型逐漸成為主流,越來越多的人開始從事偏好數據標注工作。因此,人們開始思考是否可以通過機器自動標注來減少人力成本。論文 論文閱讀**_RLLLM_RLAIF** 中進行的實驗中,研究者使用 PaLM 2 對偏好進行標注,并將訓練獎勵模型的標注學習與直接讓模型給出 0-10 分進行了比較。這兩種方法的差異在于,傳統的標注只是選擇兩個答案中哪個更好,并沒有體現出好壞程度是 9:1 還是 6:4;而大模型有能力可以給出一定的分值。實驗證明,在引入這些分值后,即使不訓練獎勵模型,也能得到更好的效果。
RLLLM_SPO
進一步的研究發現,上述方法可能隱含著 A>B、B>C,可推出 A>C 的邏輯,而實際上在石頭剪刀布這類游戲中,A>C 可能并不成立。因此,提出了 論文閱讀_RLLLM_SPO 方法。該方法不再將選擇 A 與 B 相比較,而是同時考慮選項 A 和其他多個方法(BCDE…),計算 A 在這些方法中的位置作為其相對客觀分值,以更準確地學習選項的好壞,并做出更好的決策。
Reflexion
上述方法主要用于優化聊天體驗,即通過修改獎勵函數打分,使模型生成人類更喜歡的回答。接下來考慮一種擴展使用大模型的場景,在游戲,機器人或者其它 Agent 領域中,環境對于大模型來說是未知的,可以采取行動的選項是固定而非由模型自定義的。在這種狀態空間和行為空間受限制且很大的情況下,如何優化大模型的決策能力。
論文 論文閱讀_反思模型_Reflexion 中提出了一種不訓練模型的方法。該方法通過記錄模型在環境中的探索過程,并在模型失敗時,利用大模型的思考內容推理出問題所在,并將其記錄下來。同時,該方法利用之前的經驗和上下文環境生成短期記憶,并通過對過去的反思生成長期記憶。結合了長短期記憶,在模型外圍構建輔助方法,而不需要對模型進行調參。最終實驗結果表明,該方法在各個實驗中將基準得分提升了約 10%,可視為非常有效的適應環境的方法。
RLLLM_GLAM
進而有研究利用強化學習模型探索環境,對大模型調參,以優模型在現實環境中的決策力。論文閱讀_RLLLM_GLAM 通過使用大模型作為決策模塊,為每個選項評分來解決這個問題。該方法基于給定提示 p 的條件下計算每個動作 A 中每個 token 的條件概率。然后通過環境反饋的訓練,利用強化學習方法對作為決策模塊的大模型進行微調。這種方法結合了對環境的探索和大模型本身的語言推理能力。實驗結果表明,在實際場景中表現出了非常好的效果。相比于從專家標注數據中學習,從探索中學習對于解決復雜問題更加有效。
RLLLMs
在實驗中上述模型也有一些弱點,如:經過強化學習精調的模型損失了之前的部分語言能力,對新對象的泛化能力較強,但對新能力的泛化能力較差。論文閱讀_RLLLMs_實踐出真知 致力于解決上述問題,他利用了對選項的歸一化、Lora 等技術以及提示設計,在半精度 LLaMA-7B 模型上進行實驗。所有實驗均在一個 NVIDIA Tesla A100 40GB GPU 中完成,并且訓練得到的模型僅為 4.2M。這為大模型 + 強化學習的應用提供了進一步指導。
參考鏈接:
大模型外掛(向量)知識庫 - 知乎 (zhihu.com)
大模型外掛知識庫rag綜述_rag外掛知識庫框架-CSDN博客
https://arxiv.org/pdf/2310.01352.pdf(RAG結合SFT)
chatglm3外掛知識庫保姆級教程(langchain+chatglm)-附詳細完整代碼可實現 - 知乎 (zhihu.com)
大模型+強化學習_總結篇 - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/680692103)
4.SFT指的是什么?
Supervised Fine-Tuning,指的是“有監督微調”,意味著使用有標簽的數據來調整一個已經預訓練好的語言模型(LLM),使其更適應某一特定任務。通常LLM的預訓練是無監督的,但微調過程往往是有監督的。
當進行有監督微調時,模型權重會根據與真實標簽的差異進行調整。通過這個微調過程,模型能夠捕捉到標簽數據中特定于某一任務的模式和特點。使得模型更加精確,更好地適應某一特定任務。
接下來我們還是從數據到模型輸出,計算loss的步驟來看看SFT的實現原理。
首先還是來看看數據怎么構造,SFT的每一條樣本一般由兩部分組成,也就是prompt(instruction)+ answer,比如:
- prompt:
翻譯以下句子: What is pretrain - answer:
什么是預訓練
也就是我們要給模型提供一些類似于問答形式的答案來學習,有了前面預訓練的經驗后,SFT其實就很好理解的,它本質上也在做next token prediction,只是我們更希望模型關注answer部分的預測,這可以通過生成一個mask向量來屏蔽不希望計算loss的部分,下面就是數據構造的一個示意:做的事情就是拼接prompt和answer,并在answer兩側添加一個開始和結束的符號,算一下prompt/instruction的長度,以及后面需要pad的長度,然后生成一個mask向量,answer部分為1,其他部分為0。
5.結構組件-1——Layer Norm、RMS Norm、Deep Norm
當前主流大模型使用的Normalization主要有三類,分別是Layer Norm,RMS Norm,以及Deep Norm。
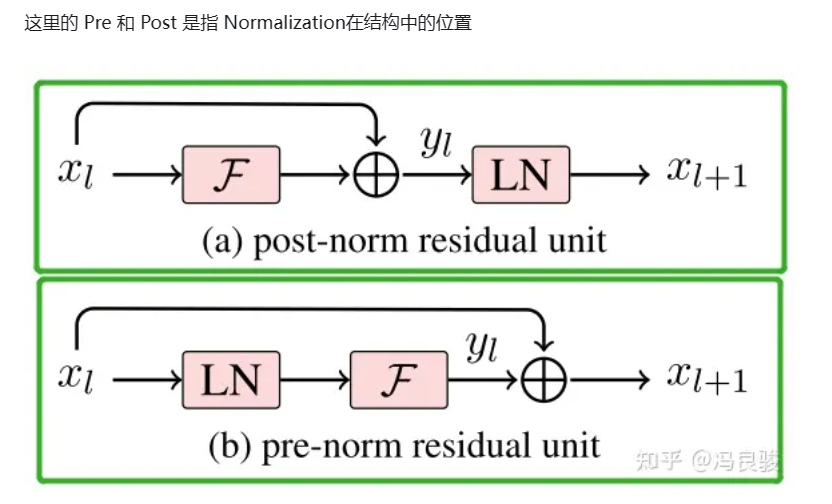
一般認為,post-norm在殘差之后做歸一化,對參數正則化的效果更強,進而模型的收斂性也會更好;而Pre-Norm有一部分參數直接加在了后面,沒有對這部分參數進行正則化,可以在反向時防止梯度爆炸或者梯度消失,大模型的訓練難度大,因而使用Pre-Norm較多。
1. Layer Norm (Layer Normalization)
LayerNorm是大模型也是transformer結構中最常用的歸一化操作,簡而言之,它的作用是 對特征張量按照某一維度或某幾個維度進行0均值,1方差的歸一化 操作,計算公式為:

這里的 𝑥 可以理解為 張量中具體某一維度的所有元素,比如對于 shape 為 (2,2,4) 的張量 input,若指定歸一化的操作為第三個維度,則會對第三個維度中的四個張量(2,2,1),各進行上述的一次計算
2. RMS Norm(Root Mean Square Layer Normalization)
與layerNorm相比,RMS Norm的主要區別在于去掉了減去均值的部分,計算公式為:

這里的 𝑎𝑖 與Layer Norm中的 𝑥 等價,作者認為這種模式在簡化了Layer Norm的同時,可以在各個模型上減少約 7%~64% 的計算時間。
可以看作LayerNorm在均值為0時的一個特例。論文通過實驗證明,re-center操作不重要。
RMSNorm 也是一種標準化方法,但與 LayerNorm 不同,它不是使用整個樣本的均值和方差,而是使用平方根的均值來歸一化,這樣做可以降低噪聲的影響。
3. Deep Norm (Deep Normalization)
Deep Norm是對Post-LN的的改進,具體的:

- DeepNorm在進行Layer Norm之前會以 𝛼 參數擴大殘差連接
- 在Xavier參數初始化過程中以 𝛽 減小部分參數的初始化范圍
論文中,作者認為 Post-LN 的不穩定性部分來自于梯度消失以及太大的模型更新
6.ROPE是什么?
ROPE是旋轉式位置編碼。RoPE是一種“配合Attention機制能達到絕對位置編碼的方式實現相對位置編碼的設計”。
- attention機制中位置信息是很重要的,將位置信息融入token編碼計算過程中的選擇是多樣的;
- 與其說位置信息重要,不如說相對位置信息重要,RoPE關注的就是相對位置信息,它將其用旋轉角度的方式表達了出來;
- 旋轉角度的思想通過將向量相鄰的兩維分為一組、作為復數的實部和虛部來實現;
- 近處的上下文信息比遠處的上下文信息更重要,表現在attention機制上就是要讓query和key的歐幾里得內積具有遠程衰減的特質;
- 所謂的外推能力,就是讓模型在超出預訓練上下文長度的位置上能預測、且預測得盡可能好,本文中涉及的優化外推能力的方法都是插值,將沒見過的情況映射到見過的區間上;
- 在RoPE的語境下,我們可以認為在預訓練時得到更充足訓練的信息是旋轉速度更快的高頻信息,想要外推效果好,就要盡可能保留這些信息。
外推能力指的是可以在較短的上下文訓練模型,但可以實現在更長的上下文上的推理,這種能力對于動輒耗費大量資源的大模型來說,尤為重要。
要想具備比較完美的外推能力,位置編碼機制要滿足:
- 長度的擴展無需額外的微調訓練等處理
- 長度的擴展不能過多影響模型的生成能力
原始的RoPE是具備一定的外推能力的,但卻稱不上完美,當模型的輸入長度超出訓練長度時,模型的性能會急劇下降,具體表現為困惑度的急劇上升
rope的數學推理部分
RoPE的思想就是讓toekn q和token k之間旋轉不同的角度來表達相對位置信息,因為 q·k=||𝑞||||𝑘||𝑐𝑜𝑠(𝜃𝑞𝑘) ,相近的token間旋轉角度小、點乘得到的值更大,離得遠的token間旋轉角度大,點乘得到的值更小。點乘具有的一個特性就是,當token q和token k同時旋轉一樣的角度,它們之間的夾角不變,所以它們之間的關系保持不變,所以RoPE是維護相對位置信息而丟棄絕對位置信息的。

7.如何對大模型進行微調?微調的框架有哪些?
目前,對大模型進行微調的框架主要包括但不限于以下幾個,這些框架支持不同類型的微調策略和優化技術,適用于各種規模和類型的任務:
- Hugging Face Transformers:這是一個非常流行的開源庫,支持大量預訓練模型的加載、微調和評估。它提供了豐富的API,使得模型微調變得相對簡單,并且內置了多種微調策略,如LoRA、Adapter、Prefix-tuning、P-tuning和Prompt-tuning等,適用于不同場景下的高效微調。
- PEFT (Parameter-Efficient Fine-Tuning):PEFT是Hugging Face社區的一個項目,專注于參數高效的微調方法,它允許用戶在保持模型主體不變的情況下,通過添加少量額外參數來適應新任務,這對于資源有限的場景特別有用。
- DeepSpeed:這是一個優化庫,主要用于加速和擴大深度學習模型的訓練。它支持CPU或GPU的分布式訓練,可以與PyTorch等框架結合,有效處理大模型的微調,尤其是在大規模數據集上的訓練。
- LangChain:雖然主要不是為模型微調設計,但LangChain作為一個強大的框架,可以幫助開發人員使用語言模型構建應用程序,間接支持了模型的微調和部署流程,特別是通過集成其他微調框架來定制模型行為。
- Adapter:Adapter是一種微調方法,也常被實現為獨立的框架或作為其他庫的組件(如在Hugging Face Transformers中),它通過在模型中插入可訓練的適配器層來適應新任務,而無需從頭訓練整個模型。
- OpenAI的API與工具:OpenAI提供了API和工具支持用戶在其大模型(如GPT系列)上進行微調,盡管具體的微調實施細節可能依賴于OpenAI提供的服務和文檔。
這些框架和庫的選擇取決于具體需求,比如模型大小、任務類型、計算資源以及對效率和靈活性的要求。
8.大模型的量化相關
量化是一種通過降低模型參數的精度來減少模型 存儲 和計算需求的技術。 其中,4-bit量化是一種比較流行的量化方法,它可以將模型的參數從32位浮點數降低到4位整數,從而大大減少了模型的存儲和計算需求。
9.大模型的學習過程
1、預訓練階段
在預訓練階段,模型通過學習大量無標簽文本數據來掌握語言的基本結構和語義規律。這些數據主要來源于互聯網,包括新聞文章、博客、論壇、書籍等。
這個階段的產出物是基礎模型,基礎模型一般不會被直接使用,因為它只能完成續寫能力,無法完成特定的任務,通常也無法直接給出人們想要的答案。比如你問大模型,中國的首都,它可能生成xxx,而不是直接給你答案。
2.指令微調階段
為了讓大模型具備特定的能力,比如對話、指定任務分類等,就需要在這個階段去做微調。也被稱為有監督微調。這個階段的難點不再是對算力的高要求,轉而對微調所需的語料質量有非常高的要求。
這個階段通常會精心編寫各式各樣的人們在對話中可能詢問的問題,以及對應的答案。通過這一階段讓模型學會了遵循指令和輸出的模式,讓模型的輸出更符合人類的對話習慣,教會模型說人話。
通過這個階段的微調,基本上能滿足在特定任務場景上的需求,就可以部署線上應用了。
3、對齊微調階段(獎勵模型+強化學習)
這個階段目的是讓大模型有更好的表現,并且與人類喜好、意識形態進行對齊(有用、誠實、無害)。目前比較主流的技術就是RLHF,基于人類反饋的強化學習。通過這個階段使得大模型行為能夠符合人類的期望。
一般企業很少去做RLHF這一步,首先,這一步訓練比較困難,很難收斂,同時去收集這樣的訓練的數據集也非常的困難。其次,在很多場景中并不需要進行涉及價值觀的對齊,除非在客服類場景需要與人類的價值觀對齊是非常必須的。
4.大模型的微調方法
1、Adapter-tuning:Adapter是早期的一個相當簡單且有效的輕量化微調方法,將較小的神經網絡層或者模塊插入預訓練模型的每一層,這些新插入的神經模塊成為adapter,下游任務微調時也只更新這些適配器參數。 Adapter調優的參數量大約為LM參數的3.6%。

2、Prefix/P-v1/P-v2 Tuning:在模型的輸入或者隱藏層添加K個額外可訓練的前綴Tokens,然后只更新這些前綴參數(https://zhuanlan.zhihu.com/p/673985751)
- prefix-tuning:
在輸入token之前構造一段任務相關的virtual tokens作為Prefix;然后,在訓練的時候只更新Prefix部分的參數,而 PLM 中的其他部分參數固定。為了防止直接更新 Prefix 的參數導致訓練不穩定和性能下降的情況,在 Prefix 層前面加了 MLP 結構,訓練完成后,只保留 Prefix 的參數。 Prefix Tuning參數規模約為LM模型整體規模的0.1%。
- p-tuning v2
這個和prefix-tuning非常的相似。改變在于以下幾點:
- 移除重參數化的編碼器。以前的方法利用重參數化功能來提高訓練速度和魯棒性(如:Prefix Tuning 中的 MLP 、P-Tuning 中的 LSTM)。在 P-tuning v2 中,作者發現重參數化的改進很小,尤其是對于較小的模型,同時還會影響模型的表現。
- 針對不同任務采用不同的提示長度。提示長度在提示優化方法的超參數搜索中起著核心作用。在實驗中,發現不同的理解任務通常用不同的提示長度來實現其最佳性能,這與 Prefix-Tuning 中的發現一致,不同的文本生成任務可能有不同的最佳提示長度。
- 引入多任務學習。先在多任務的Prompt上進行預訓練,然后再適配下游任務。多任務學習對我們的方法來說是可選的,但可能是相當有幫助的。一方面,連續提示的隨機性給優化帶來了困難,這可以通過更多的訓練數據或與任務相關的無監督預訓練來緩解;另一方面,連續提示是跨任務和數據集的特定任務知識的完美載體。我們的實驗表明,在一些困難的序列任務中,多任務學習可以作為P-tuning v2的有益補充。
代碼部分把prefix tuning和P-tuning v2放在一起寫
3、LoRA微調方法(https://hub.baai.ac.cn/view/33321)
lora(低秩自適應)是目前用于高效訓練定制語言大模型的最廣泛和最有效的技術之一。
基本原理是凍結預訓練好的模型權重參數,在凍結原模型參數的情況下,通過往模型中加入額外的網絡層,并只訓練這些網絡層參數。
總結lora的特點:
- 給原模型增加旁路,通過低秩分解(先降維再升維)來模擬參數的更新量;
- 訓練時,原模型參數固定,只訓練降維矩陣A和B
- 推理時,可將BA加到原模型的參數上,不引入額外的推理延遲
- 初始化,A采用高斯分布初始化,B初始化為0,保證訓練開始時旁路為0矩陣
基于transformer結構,lora一般只對每層的self-attention的部分進行微調,即Wq、Wk、Wv
lora微調的一些參數設置:
- 超參數r:它決定了lora矩陣的秩和維度,直接影響模型的復雜度和容量。較高的r意味著更強的表達能力,但可能會導致過擬合;較低的r可以減少過擬合,但代價是表達能力的降低。一般經驗是,如果數據集中任務越多樣,r會設置越大些。
- 超參數alpha:**縮放尺度,alpha的值越大,lora的權重影響就越大,而較低的alpha將減少其影響,使得模型更多依賴于原始參數。**調整alpha有助于在擬合數據和通過正則化模型來防止過擬合之間找到平衡。作為一個經驗法則,微調LLM時通常alpha的選擇是秩的兩倍。
- 超參數alpha-dropout:lora微調中的dropout系數
4、Qlora微調方法
qlora是建立在lora的基礎上,引入了4位量化、4位NormalFloat數據類型、雙量化和分頁優化器,以進一步減少內存使用。
5、Dora(權重分解低秩適應):一種新穎的模型微調方法
dora是建立在lora的基礎上進行改進或擴展。dora是將預訓練的權重矩陣分解為幅度向量m和方向矩陣v。

擬合,但代價是表達能力的降低。一般經驗是,如果數據集中任務越多樣,r會設置越大些。
- 超參數alpha:**縮放尺度,alpha的值越大,lora的權重影響就越大,而較低的alpha將減少其影響,使得模型更多依賴于原始參數。**調整alpha有助于在擬合數據和通過正則化模型來防止過擬合之間找到平衡。作為一個經驗法則,微調LLM時通常alpha的選擇是秩的兩倍。
- 超參數alpha-dropout:lora微調中的dropout系數
4、Qlora微調方法
qlora是建立在lora的基礎上,引入了4位量化、4位NormalFloat數據類型、雙量化和分頁優化器,以進一步減少內存使用。
5、Dora(權重分解低秩適應):一種新穎的模型微調方法
dora是建立在lora的基礎上進行改進或擴展。dora是將預訓練的權重矩陣分解為幅度向量m和方向矩陣v。
[外鏈圖片轉存中…(img-IQsiGp1e-1715736539497)]
開發這種方法的動機是基于分析和比較lora和全面微調模型的區別。論文發現,lora可以按比例增加或減少幅度和方向更新,但似乎缺乏像完全微調那樣進行細微的方向變化的能力。因此提出了幅度和方向分量的解耦。將lora應用于方向分量(同時允許單獨訓練幅度分量)。











)







