背景意義
研究背景與意義
隨著工業自動化和智能制造的迅速發展,零件的高效識別與分割在生產線上的重要性日益凸顯。傳統的圖像處理方法在處理復雜場景時往往面臨著準確性不足和實時性差的問題,而深度學習技術的引入為這一領域帶來了新的機遇。特別是基于卷積神經網絡(CNN)的實例分割技術,能夠對圖像中的每一個目標進行精確的像素級別分割,極大地提升了零件識別的精度和效率。
本研究旨在基于改進的YOLOv11模型,構建一個高效的零件實例分割系統。YOLO(You Only Look Once)系列模型以其快速的推理速度和良好的檢測精度而受到廣泛關注。通過對YOLOv11進行改進,我們希望能夠在保持實時性能的同時,進一步提升模型在復雜背景下的分割精度。此外,所使用的數據集包含1600張圖像,涵蓋了兩個類別的零件實例,為模型的訓練和驗證提供了豐富的樣本支持。
在實際應用中,零件實例分割系統不僅可以提高生產效率,還能降低人工干預的需求,減少人為錯誤的發生。通過對零件進行自動化識別和分割,企業能夠實現更高的生產靈活性和資源利用率,進而提升整體競爭力。因此,研究基于改進YOLOv11的零件實例分割系統,不僅具有重要的學術價值,也對實際工業應用具有深遠的意義。通過這一研究,我們期望為智能制造領域的圖像處理技術提供新的思路和解決方案,推動行業的技術進步與創新發展。
圖片效果
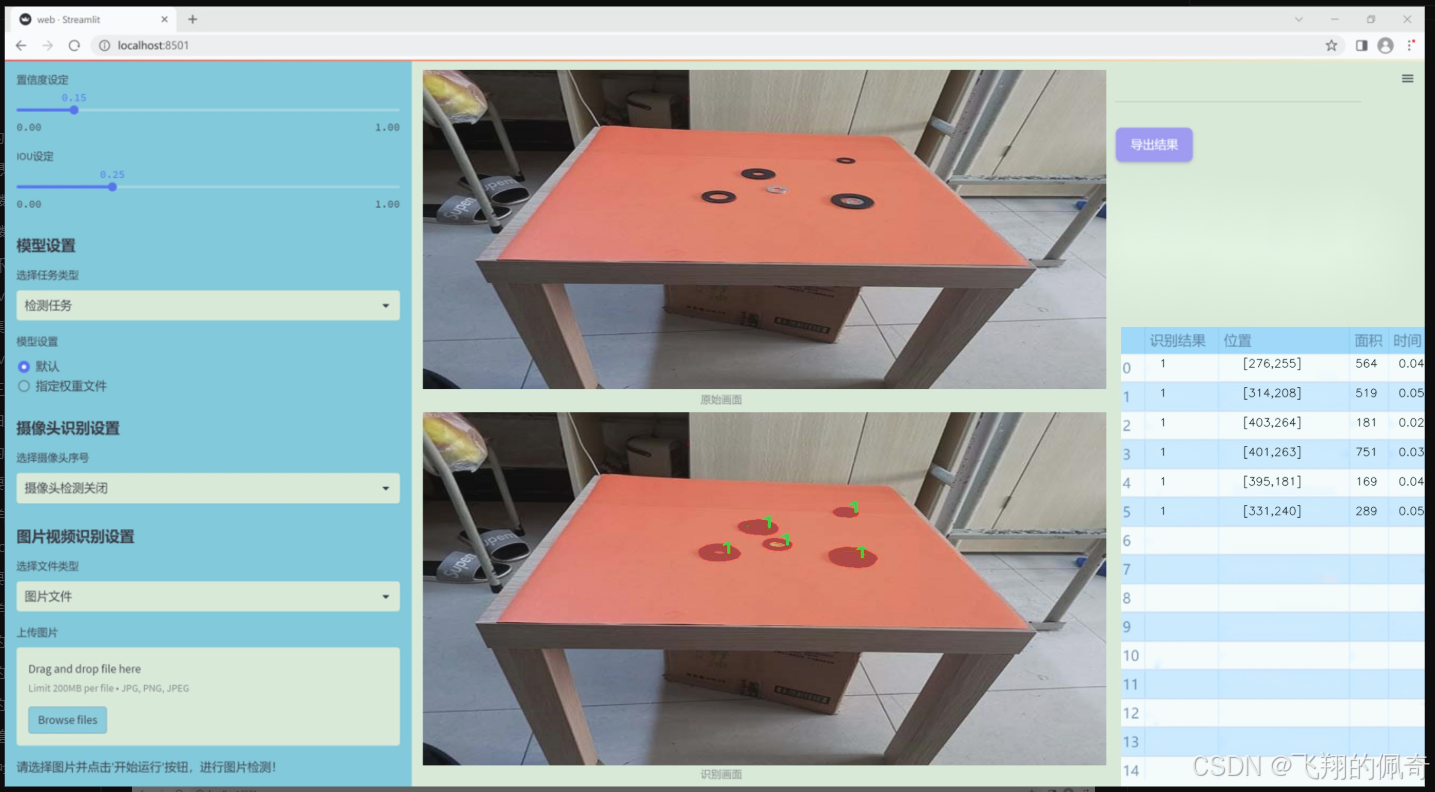
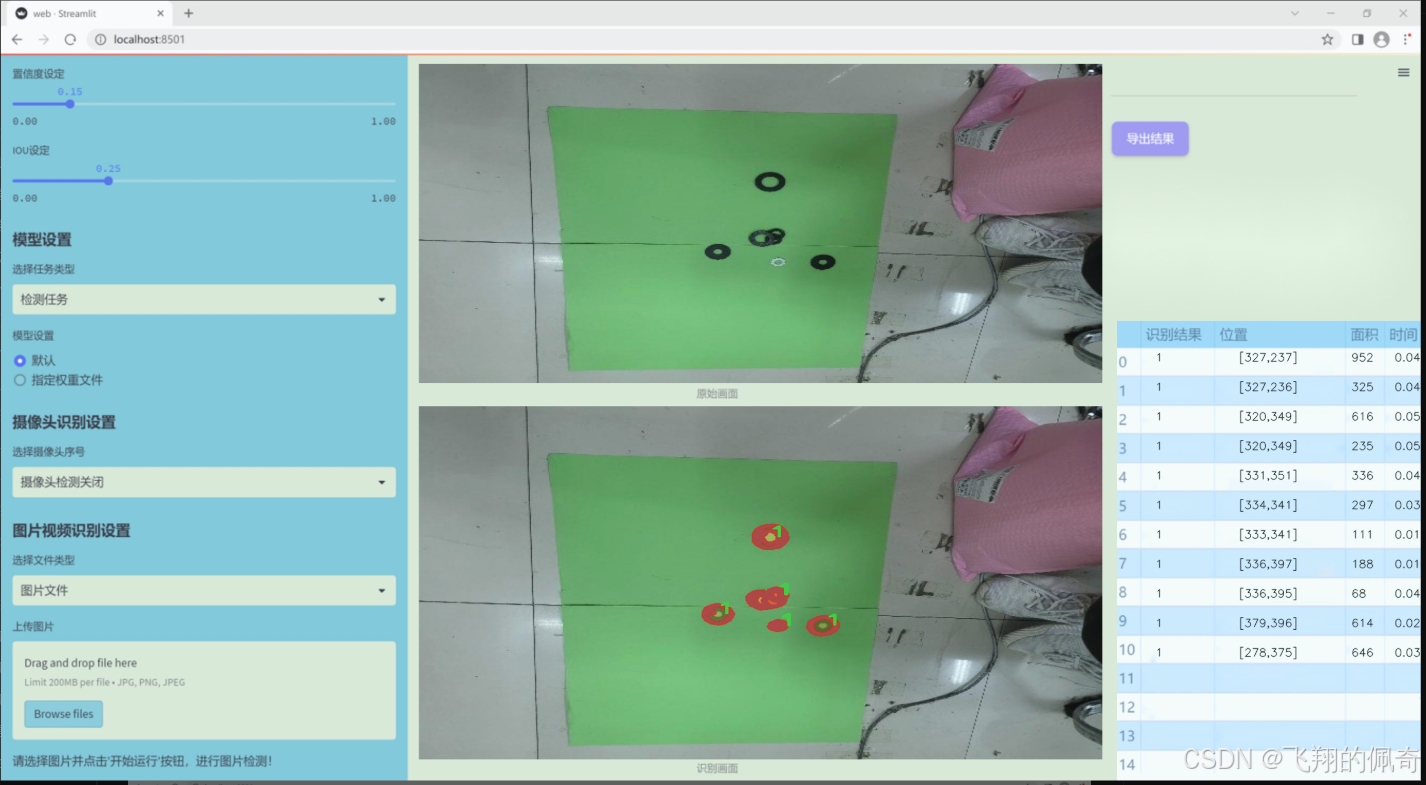
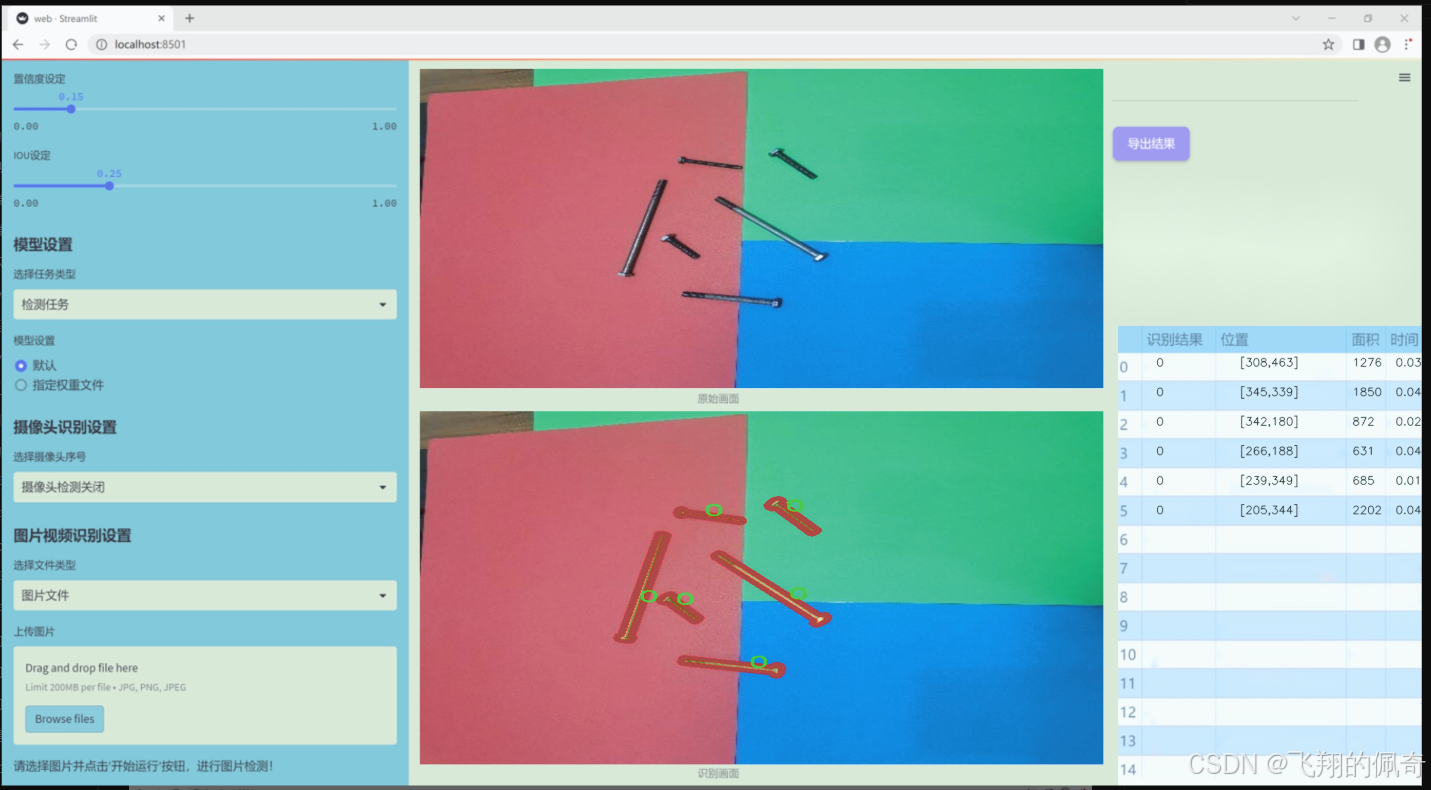
數據集信息
本項目數據集信息介紹
本項目所使用的數據集旨在支持改進YOLOv11的零件實例分割系統,特別聚焦于“2d-segnew”主題。該數據集包含了豐富的圖像數據,專門設計用于訓練和評估深度學習模型在零件實例分割任務中的表現。數據集中包含兩個主要類別,分別標記為“0”和“1”,這兩個類別的選擇旨在涵蓋特定的應用場景,以確保模型能夠在實際應用中有效識別和分割不同類型的零件。
數據集的構建過程遵循嚴格的標準,確保每個類別的樣本數量和質量都能滿足訓練需求。每個圖像都經過精確標注,確保模型在學習過程中能夠獲得準確的反饋。這種高質量的標注不僅提升了模型的學習效率,也為后續的驗證和測試提供了可靠的基礎。此外,數據集中的圖像多樣性涵蓋了不同的拍攝角度、光照條件和背景環境,以增強模型的泛化能力,使其能夠在各種實際應用場景中表現出色。
在訓練過程中,改進YOLOv11將利用該數據集進行端到端的學習,通過不斷優化模型參數,提升其在零件實例分割任務中的準確性和效率。數據集的設計理念不僅關注模型的性能提升,也考慮到實際應用中的可操作性和適應性,確保最終的系統能夠在工業生產、自動化檢測等領域發揮重要作用。通過對該數據集的深入分析和應用,我們期望能夠推動零件實例分割技術的發展,為相關行業帶來更高的智能化水平和生產效率。
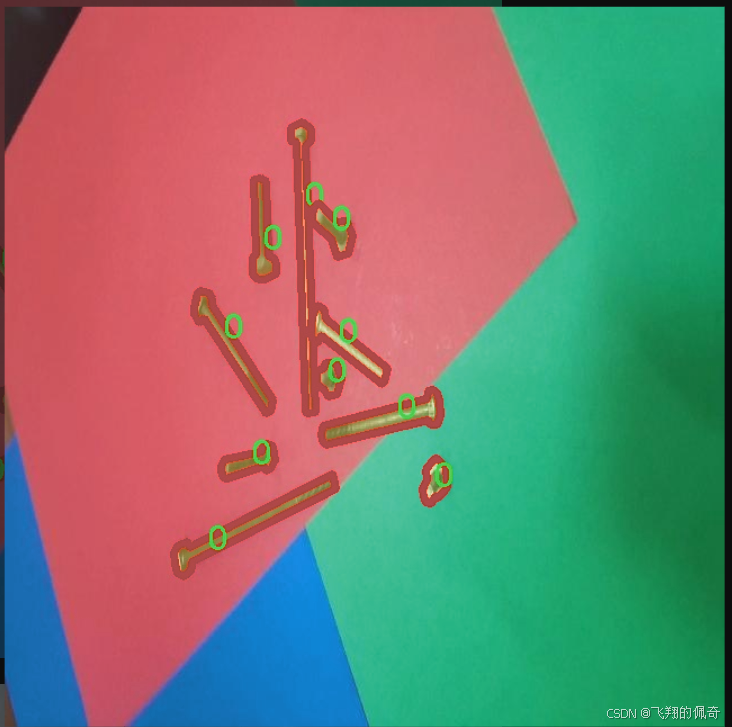




核心代碼
以下是代碼中最核心的部分,并附上詳細的中文注釋:
import torch
import torch.nn as nn
import torch.nn.functional as F
class OmniAttention(nn.Module):
def init(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16):
super(OmniAttention, self).init()
# 計算注意力通道數
attention_channel = max(int(in_planes * reduction), min_channel)
self.kernel_size = kernel_size
self.kernel_num = kernel_num
self.temperature = 1.0 # 溫度參數,用于控制注意力的平滑程度
# 定義平均池化層self.avgpool = nn.AdaptiveAvgPool2d(1)# 定義全連接層self.fc = nn.Conv2d(in_planes, attention_channel, 1, bias=False)self.bn = nn.BatchNorm2d(attention_channel) # 批歸一化self.relu = nn.ReLU(inplace=True) # ReLU激活函數# 定義通道注意力的全連接層self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)self.func_channel = self.get_channel_attention # 設置通道注意力的計算方法# 定義濾波器注意力的計算方法if in_planes == groups and in_planes == out_planes: # 深度卷積self.func_filter = self.skipelse:self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, bias=True)self.func_filter = self.get_filter_attention# 定義空間注意力的計算方法if kernel_size == 1: # 點卷積self.func_spatial = self.skipelse:self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)self.func_spatial = self.get_spatial_attention# 定義核注意力的計算方法if kernel_num == 1:self.func_kernel = self.skipelse:self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)self.func_kernel = self.get_kernel_attentionself._initialize_weights() # 初始化權重def _initialize_weights(self):# 初始化卷積層和批歸一化層的權重for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)if isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def get_channel_attention(self, x):# 計算通道注意力channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return channel_attentiondef get_filter_attention(self, x):# 計算濾波器注意力filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return filter_attentiondef get_spatial_attention(self, x):# 計算空間注意力spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)spatial_attention = torch.sigmoid(spatial_attention / self.temperature)return spatial_attentiondef get_kernel_attention(self, x):# 計算核注意力kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)kernel_attention = F.softmax(kernel_attention / self.temperature, dim=1)return kernel_attentiondef forward(self, x):# 前向傳播x = self.avgpool(x) # 平均池化x = self.fc(x) # 全連接層x = self.bn(x) # 批歸一化x = self.relu(x) # ReLU激活return self.func_channel(x), self.func_filter(x), self.func_spatial(x), self.func_kernel(x)
class AdaptiveDilatedConv(nn.Module):
“”“自適應膨脹卷積的封裝類,作為普通卷積層的替代。”“”
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):super(AdaptiveDilatedConv, self).__init__()# 定義卷積層self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)def forward(self, x):# 前向傳播return self.conv(x) # 直接調用卷積層進行計算
代碼核心部分說明:
OmniAttention 類:實現了多種注意力機制,包括通道注意力、濾波器注意力、空間注意力和核注意力。通過全連接層和卷積層計算不同的注意力,并在前向傳播中應用這些注意力。
AdaptiveDilatedConv 類:封裝了自適應膨脹卷積的功能,允許使用不同的卷積參數進行卷積操作。
這些部分是實現自適應卷積和注意力機制的關鍵,能夠有效地提高模型的表現。
這個程序文件 fadc.py 實現了一些深度學習中的卷積操作,特別是與可調變形卷積(Modulated Deformable Convolution)相關的功能。文件中定義了多個類和函數,主要包括 OmniAttention、FrequencySelection、AdaptiveDilatedConv 和 AdaptiveDilatedDWConv,它們都繼承自 PyTorch 的 nn.Module 類。
首先,OmniAttention 類實現了一種注意力機制,用于對輸入特征圖的通道、濾波器、空間和卷積核進行加權。這個類的構造函數接受多個參數,如輸入和輸出通道數、卷積核大小、組數、減少比例等。類中定義了多個方法,包括權重初始化、前向傳播等。在前向傳播中,輸入特征圖經過平均池化、全連接層、批歸一化和激活函數處理后,生成通道注意力、濾波器注意力、空間注意力和卷積核注意力。
接下來,generate_laplacian_pyramid 函數用于生成拉普拉斯金字塔,通常用于圖像處理中的多尺度分析。該函數通過逐層下采樣輸入張量,并計算每層的拉普拉斯差分,返回一個包含不同尺度特征的金字塔。
FrequencySelection 類實現了一種頻率選擇機制,允許對輸入特征進行頻率域的處理。它的構造函數接受多個參數,設置頻率選擇的方式、激活函數、空間卷積參數等。在前向傳播中,輸入特征通過不同的頻率選擇方法進行處理,最終返回加權后的特征圖。
AdaptiveDilatedConv 和 AdaptiveDilatedDWConv 類則是對可調變形卷積的封裝,支持自適應的膨脹卷積操作。它們的構造函數中包含了對偏移量和掩碼的卷積操作,允許在卷積過程中使用注意力機制來調整權重。前向傳播中,輸入特征經過偏移量和掩碼的計算后,使用變形卷積進行處理。
總的來說,這個文件提供了一種靈活的卷積操作實現,結合了注意力機制和頻率選擇,適用于圖像處理和計算機視覺任務。通過這些類和函數,用戶可以構建復雜的神經網絡架構,以提高模型的性能和適應性。
10.4 TransNext.py
以下是保留的核心代碼部分,并添加了詳細的中文注釋:
try:
# 嘗試導入swattention模塊和TransNext_cuda中的所有內容
import swattention
from ultralytics.nn.backbone.TransNeXt.TransNext_cuda import *
except ImportError as e:
# 如果導入失敗(例如swattention模塊不存在),則導入TransNext_native中的所有內容
from ultralytics.nn.backbone.TransNeXt.TransNext_native import *
pass
代碼注釋說明:
try塊:
try::開始一個異常處理塊,嘗試執行其中的代碼。
import swattention:嘗試導入名為swattention的模塊,如果該模塊存在,則可以使用其中的功能。
from ultralytics.nn.backbone.TransNeXt.TransNext_cuda import *:嘗試從ultralytics庫中的TransNeXt子模塊導入所有內容(通常是類和函數),這里指定了使用CUDA版本的實現。
except塊:
except ImportError as e::捕獲導入時可能發生的ImportError異常,as e用于獲取異常信息。
from ultralytics.nn.backbone.TransNeXt.TransNext_native import *:如果swattention模塊或CUDA版本的TransNext導入失敗,則導入TransNext_native中的所有內容,通常是CPU版本的實現。
pass:在異常處理塊中,pass語句表示不執行任何操作,繼續執行后續代碼。
總結:
這段代碼的主要目的是根據系統環境的不同,選擇合適的模塊和實現進行導入,以確保代碼的兼容性和可用性。
這個程序文件名為 TransNext.py,其主要功能是導入所需的模塊和類。首先,程序嘗試導入 swattention 模塊以及 TransNext_cuda 中的所有內容。如果這一步驟成功,程序將繼續執行;如果在導入過程中發生 ImportError(即找不到指定的模塊),則程序會捕獲這個異常,并嘗試導入 TransNext_native 中的所有內容。
這種處理方式通常用于確保程序在不同的環境中都能正常運行。例如,TransNext_cuda 可能依賴于 CUDA(用于加速計算的并行計算平臺和編程模型),而 TransNext_native 則可能是一個不依賴于 CUDA 的實現。通過這種方式,程序能夠根據系統的支持情況選擇合適的模塊,從而提高了代碼的兼容性和靈活性。
源碼文件
源碼獲取
歡迎大家點贊、收藏、關注、評論啦 、查看👇🏻獲取聯系方式👇🏻

)







-Eclipse插件實現)




)




