RPC內核細節(轉載)
背景
隨著數據量、并發量、業務復雜度的增長,服務化是架構演進必由之路。服務化離不開RPC框架。
RPC服務化的好處
服務化的一個好處就是,不限定服務的提供方使用什么技術選型,能夠實現大公司跨團隊的技術解耦。
如下圖所示:
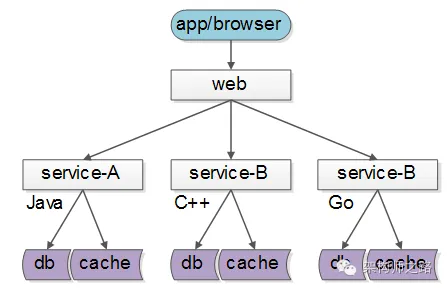
- 服務A:歐洲團隊維護,技術背景是Java;
- 服務B:美洲團隊維護,用C++實現;
- 服務C:中國團隊維護,技術棧是go;
服務的上游調用方,按照接口、協議即可完成對遠端服務的調用。
但實際上,大部分互聯網公司,研發團隊規模有限,大都使用同一套技術體系來實現服務:
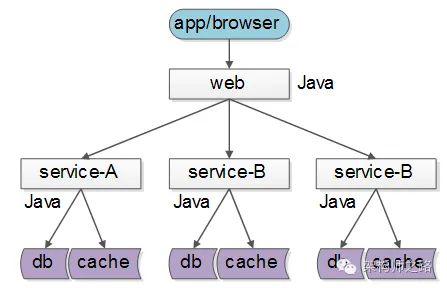
這樣的話,如果沒有統一的服務框架,各個團隊的服務提供方就需要各自實現一套序列化、反序列化、網絡框架、連接池、收發線程、超時處理、狀態機等“業務之外”的重復技術勞動,造成整體的低效。
因此,統一服務框架把上述“業務之外”的工作統一實現,是服務化首要解決的問題。
RPC框架的職責是什么?
RPC框架,要向調用方屏蔽各種復雜性,要向服務提供方也屏蔽各類復雜性:
- 服務調用方client感覺就像調用本地函數一樣,來調用服務;
- 服務提供方server感覺就像實現一個本地函數一樣,來實現服務;
所以整個RPC框架又分為client部分與server部分,實現上面的目標,把復雜性屏蔽,就是RPC框架的職責。
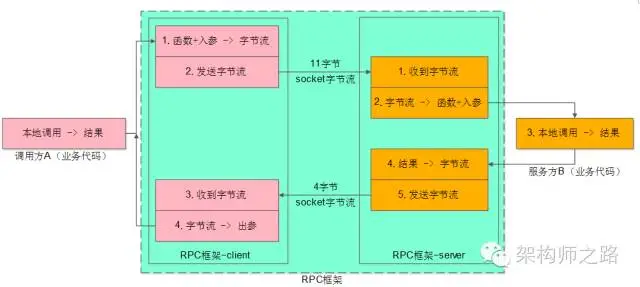
如上圖所示,業務方的職責是:
- 調用方A,傳入參數,執行調用,拿到結果;
- 服務方B,收到參數,執行邏輯,返回結果;
RPC框架的職責是,中間大藍框的部分:
- client端:序列化、反序列化、連接池管理、負載均衡、故障轉移、隊列管理,超時管理、異步管理等等;
- server端:服務端組件、服務端收發包隊列、io線程、工作線程、序列化反序列化等;
序列化協議要考慮什么因素?
不管使用成熟協議xml/json,還是自定義二進制協議來序列化對象,序列化協議設計時都需要考慮以下這些因素:
- 解析效率:這個應該是序列化協議應該首要考慮的因素,像xml/json解析起來比較耗時,需要解析doom樹,二進制自定義協議解析起來效率就很高;
- 壓縮率,傳輸有效性:同樣一個對象,xml/json傳輸起來有大量的xml標簽,信息有效性低,二進制自定義協議占用的空間相對來說就小多了;
- 擴展性與兼容性:是否能夠方便的增加字段,增加字段后舊版客戶端是否需要強制升級,都是需要考慮的問題,xml/json和上面的二進制協議都能夠方便的擴展;
- 可讀性與可調試性:這個很好理解,xml/json的可讀性就比二進制協議好很多;
- 跨語言:上面的兩個協議都是跨語言的,有些序列化協議是與開發語言緊密相關的,例如dubbo的序列化協議就只能支持Java的RPC調用;
- 通用性:xml/json非常通用,都有很好的第三方解析庫,各個語言解析起來都十分方便,上面自定義的二進制協議雖然能夠跨語言,但每個語言都要寫一個簡易的協議客戶端;
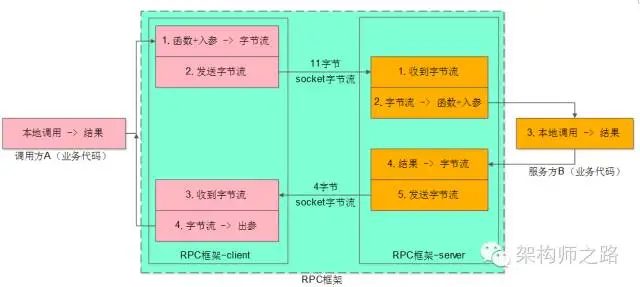
RPC-client包含下面部分:
- 序列化反序列化的部分(上圖中的1、4)
- 發送字節流與接收字節流的部分(上圖中的2、3)
RPC-client同步調用架構如何?
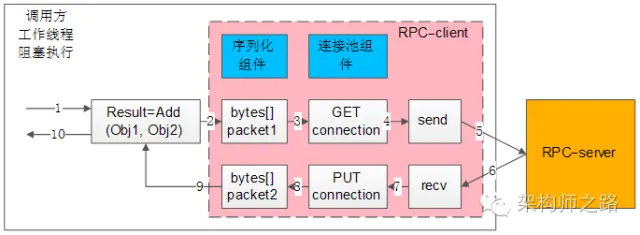
所謂同步調用,在得到結果之前,一直處于阻塞狀態,會一直占用一個工作線程,上圖簡單的說明了一下組件、交互、流程步驟:
- 左邊大框,代表了調用方的一個工作線程
- 左邊粉色中框,代表了RPC-client組件
- 右邊橙色框,代表了RPC-server
- 藍色兩個小框,代表了同步RPC-client兩個核心組件,序列化組件與連接池組件
- 白色的流程小框,以及箭頭序號1-10,代表整個工作線程的串行執行步驟:
1)業務代碼發起RPC調用:
Result=Add(Obj1,Obj2)
2)序列化組件,將對象調用序列化成二進制字節流,可理解為一個待發送的包packet1;
3)通過連接池組件拿到一個可用的連接connection;
4)通過連接connection將包packet1發送給RPC-server;
5)發送包在網絡傳輸,發給RPC-server;
6)響應包在網絡傳輸,發回給RPC-client;
7)通過連接connection從RPC-server收取響應包packet2;
8)通過連接池組件,將connection放回連接池;
9)序列化組件,將packet2反序列化為Result對象返回給調用方;
10)業務代碼獲取Result結果,工作線程繼續往下走;
連接池組件有什么作用?
RPC框架鎖支持的負載均衡、故障轉移、發送超時等特性,都是通過連接池組件去實現的。
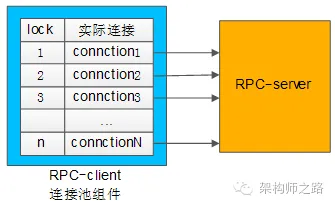
典型連接池組件對外提供的接口為:
int ConnectionPool::init(…);
Connection ConnectionPool::getConnection();
int ConnectionPool::putConnection(Connection t);
- init做了些什么?
和下游RPC-server(一般是一個集群),建立N個tcp長連接,即所謂的連接“池”。 - getConnection做了些什么?
從連接“池”中拿一個連接,加鎖(置一個標志位),返回給調用方。 - putConnection做了些什么?
將一個分配出去的連接放回連接“池”中,解鎖(也是置一個標志位)。
如何實現負載均衡?
連接池中建立了與一個RPC-server集群的連接,連接池在返回連接的時候,需要具備隨機性。
如何實現故障轉移?
連接池中建立了與一個RPC-server集群的連接,當連接池發現某一個機器的連接異常后,需要將這個機器的連接排除掉,返回正常的連接,在機器恢復后,再將連接加回來。
如何實現發送超時?
因為是同步阻塞調用,拿到一個連接后,使用帶超時的send/recv即可實現帶超時的發送和接收。
總的來說,同步的RPC-client的實現是相對比較容易的,序列化組件、連接池組件配合多工作線程數,就能夠實現。
RPC-client異步調用架構如何?
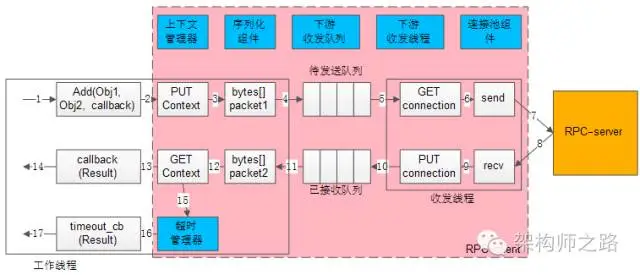
所謂異步回調,在得到結果之前,不會處于阻塞狀態,理論上任何時間都沒有任何線程處于阻塞狀態,因此異步回調的模型,理論上只需要很少的工作線程與服務連接就能夠達到很高的吞吐量,如上圖所示:
左邊的框框,是少量工作線程(少數幾個就行了)進行調用與回調
- 中間粉色的框框,代表了RPC-client組件
- 右邊橙色框,代表了RPC-server
- 藍色六個小框,代表了異步RPC-client六個核心組件:上下文管理器,超時管理器,序列化組件,下游收發隊列,下游收發線程,連接池組件
- 白色的流程小框,以及箭頭序號1-17,代表整個工作線程的串行執行步驟:
1)業務代碼發起異步RPC調用;
Add(Obj1,Obj2, callback)
2)上下文管理器,將請求,回調,上下文存儲起來;
3)序列化組件,將對象調用序列化成二進制字節流,可理解為一個待發送的包packet1;
4)下游收發隊列,將報文放入“待發送隊列”,此時調用返回,不會阻塞工作線程;
5)下游收發線程,將報文從“待發送隊列”中取出,通過連接池組件拿到一個可用的連接connection;
6)通過連接connection將包packet1發送給RPC-server;
7)發送包在網絡傳輸,發給RPC-server;
8)響應包在網絡傳輸,發回給RPC-client;
9)通過連接connection從RPC-server收取響應包packet2;
10)下游收發線程,將報文放入“已接受隊列”,通過連接池組件,將connection放回連接池;
11)下游收發隊列里,報文被取出,此時回調將要開始,不會阻塞工作線程;
12)序列化組件,將packet2反序列化為Result對象;
13)上下文管理器,將結果,回調,上下文取出;
14)通過callback回調業務代碼,返回Result結果,工作線程繼續往下走;
如果請求長時間不返回,處理流程是:
15)上下文管理器,請求長時間沒有返回;
16)超時管理器拿到超時的上下文;
17)通過timeout_cb回調業務代碼,工作線程繼續往下走;
序列化組件和連接池組件上文已經介紹過,收發隊列與收發線程比較容易理解。下面重點介紹上下文管理器與超時管理器這兩個總的組件。
為什么需要上下文管理器?
由于請求包的發送,響應包的回調都是異步的,甚至不在同一個工作線程中完成,需要一個組件來記錄一個請求的上下文,把請求-響應-回調等一些信息匹配起來。
如何將請求-響應-回調這些信息匹配起來?
這是一個很有意思的問題,通過一條連接往下游服務發送了a,b,c三個請求包,異步的收到了x,y,z三個響應包:
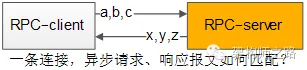
怎么知道哪個請求包與哪個響應包對應?
怎么知道哪個響應包與哪個回調函數對應?
可以通過“請求id”來實現請求-響應-回調的串聯。
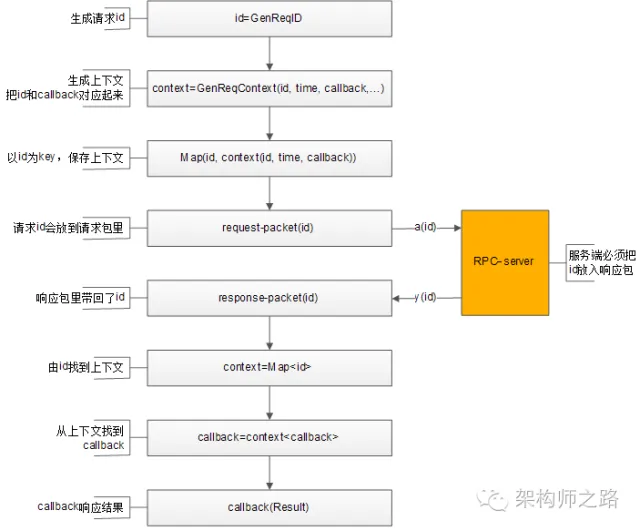
整個處理流程如上,通過請求id,上下文管理器來對應請求-響應-callback之間的映射關系:
1)生成請求id;
2)生成請求上下文context,上下文中包含發送時間time,回調函數callback等信息;
3)上下文管理器記錄req-id與上下文context的映射關系;
4)將req-id打在請求包里發給RPC-server;
5)RPC-server將req-id打在響應包里返回;
6)由響應包中的req-id,通過上下文管理器找到原來的上下文context;
7)從上下文context中拿到回調函數callback;
8)callback將Result帶回,推動業務的進一步執行;
如何實現負載均衡,故障轉移?
與同步的連接池思路類似,不同之處在于:
- 同步連接池使用阻塞方式收發,需要與一個服務的一個ip建立多條連接;
- 異步收發,一個服務的一個ip只需要建立少量的連接(例如,一條tcp連接);
如何實現超時發送與接收?
超時收發,與同步阻塞收發的實現就不一樣了:
3. 同步阻塞超時,可以直接使用帶超時的send/recv來實現;
4. 異步非阻塞的nio的網絡報文收發,由于連接不會一直等待回包,超時是由超時管理器實現的;
超時管理器如何實現超時管理?
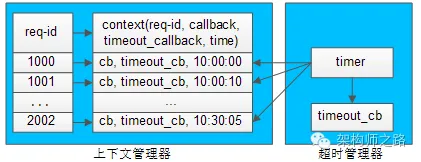
超時管理器,用于實現請求回包超時回調處理。
每一個請求發送給下游RPC-server,會在上下文管理器中保存req-id與上下文的信息,上下文中保存了請求很多相關信息,例如req-id,回包回調,超時回調,發送時間等。
超時管理器啟動timer對上下文管理器中的context進行掃描,看上下文中請求發送時間是否過長,如果過長,就不再等待回包,直接超時回調,推動業務流程繼續往下走,并將上下文刪除掉。
如果超時回調執行后,正常的回包又到達,通過req-id在上下文管理器里找不到上下文,就直接將請求丟棄。
無論如何,異步回調和同步回調相比,除了序列化組件和連接池組件,會多出上下文管理器,超時管理器,下游收發隊列,下游收發線程等組件,并且對調用方的調用習慣有影響。
異步回調能提高系統整體的吞吐量,具體使用哪種方式實現RPC-client,可以結合業務場景來選取。
參考文獻
程序媛,必須知道的RPC內核細節!(第93講,萬字長文,值得收藏)












)




 —— SLS 接入與設置自動化)

