在 MySQL 中,Redo Log(重做日志) 是 InnoDB 存儲引擎實現事務持久性(ACID 中的 D) 的核心機制,同時也通過 “預寫日志(Write-Ahead Logging, WAL)” 策略提升了數據寫入性能。它記錄的是數據頁的物理修改操作(而非 SQL 邏輯),用于在數據庫崩潰后恢復未持久化到磁盤的數據,避免事務丟失。
目錄
核心作用
存儲形式:文件組形式存儲
寫入方式:循環寫入
寫入策略:由innodb_flush_log_at_trx_commit參數控制
參數設置與查看
參數選型
寫入流程
核心參數選型與設置
選型
查看與設置語法
配置注意事項
Redo Log 實際應用的常見誤區
Redo Log 的核心實際應用場景
?
核心作用
Redo Log 的核心目標是解決 “內存數據與磁盤數據不一致” 的問題,具體有兩大作用:
- 保證事務持久性:即使數據庫在事務提交后、數據未刷入磁盤前崩潰,重啟后可通過 Redo Log 重新執行修改操作,將數據恢復到提交狀態,避免事務 “提交了但數據丟了”。
- 提升寫入性能:InnoDB 的寫入并非直接將數據刷入磁盤(磁盤隨機寫速度慢),而是先修改內存中的數據頁(Buffer Pool),再異步將 Redo Log 刷入磁盤(順序寫速度快),后續由后臺線程(如page cleaner)將內存數據批量刷盤,大幅降低磁盤 IO 開銷。
存儲形式:文件組形式存儲
Redo Log 并非單文件,而是以日志文件組的形式存在(默認是ib_logfile0和ib_logfile1),文件大小和數量可通過配置調整:
| 配置參數 | 核心作用 | 默認值 | 取值范圍 / 限制 | 生產環境建議值 | 關鍵注意事項 |
|---|---|---|---|---|---|
innodb_log_file_size | 定義單個 Redo Log 文件的大小,決定單文件可存儲的日志量 | 48M | - 最小值:無明確下限(通常不小于 1M) - 最大值:單個文件無獨立上限,但需滿足? innodb_log_files_in_group * innodb_log_file_size ≤ 512G(整個日志文件組總大小上限) | 2G - 4G | 1. 需平衡 “恢復速度” 與 “日志切換頻率”: - 過小:日志切換頻繁,觸發 Checkpoint 次數多,增加 IO 開銷 - 過大:崩潰后掃描日志時間長,恢復速度慢 2. 修改需謹慎,需先停止 MySQL,刪除舊日志文件后重啟 |
innodb_log_files_in_group | 定義 Redo Log 文件組的文件數量,文件命名格式為?ib_logfile0、ib_logfile1... | 2 | - 最小值:1 - 最大值:100 | 2 - 4 個 | 1. 多文件通過 “循環寫” 機制避免單文件損壞導致日志丟失,提升可靠性 2. 數量并非越多越好:過多文件會增加日志管理開銷,2-4 個可滿足絕大多數場景需求 3. 需與? innodb_log_file_size?配合,確保總大小不超過 512G |
寫入方式:循環寫入
當一組文件寫滿后,會切換到下一個文件;全部寫滿后,會覆蓋最早的日志(前提是這些日志對應的內存數據已刷入磁盤,即 “checkpoint” 完成)。
- 核心指針:write pos(寫入位置) 和checkpoint(檢查點) 。
用于管理 Redo Log 的寫入、循環覆蓋和失效日志清理,確保日志空間高效利用和數據安全。指針 定義 作用 write pos(寫入位置) 記錄當前 Redo Log 的下一個待寫入位置(指向日志文件中即將寫入新日志的位置)。 標記日志的 已使用區域。
從 checkpoint 到 write pos 之間的區域,是已寫入但尚未被覆蓋的有效日志。checkpoint(檢查點) 記錄已刷盤的日志位置(指向所有已寫入 Redo Log 中,對應的數據頁已刷入磁盤的最新位置)。 標記日志的可覆蓋區域。
從日志起始位置到 checkpoint 之間的區域,是已失效的日志(對應數據已持久化),可被新日志覆蓋。 - 循環寫入分析:
redo log 從頭開始寫,寫完一個文件繼續寫另一個文件,寫到最后一個文件末尾就又回到第一個文件開頭循環寫,如下圖所示: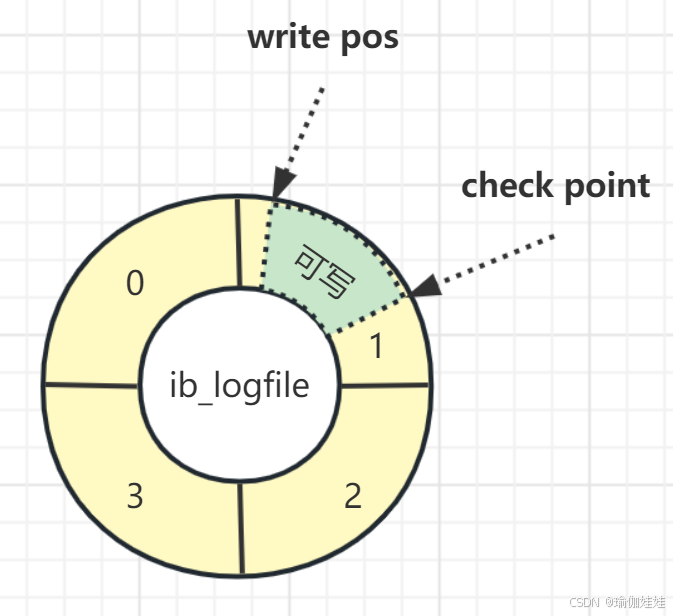
- 日志寫入:事務產生的 Redo Log 從write pos位置開始寫入,write pos隨寫入不斷后移(順時針移動)。如上圖所示,write pos寫到第 3 號文件末尾后就回到 0 號文件開頭。
- 日志覆蓋:當write pos追上checkpoint時,說明日志文件組已寫滿,此時不能繼續寫入新日志,必須先觸發 Checkpoint 機制,推動checkpoint后移(釋放可覆蓋區域),才能繼續寫入。
- checkpoint 推進:當觸發 Checkpoint(如日志快寫滿、臟頁比例過高)時,InnoDB 會將 Buffer Pool 中 “checkpoint到write pos之間的日志對應的臟頁” 刷入磁盤;刷盤完成后,checkpoint向后移動到最新位置,釋放出的區域可被新日志覆蓋。
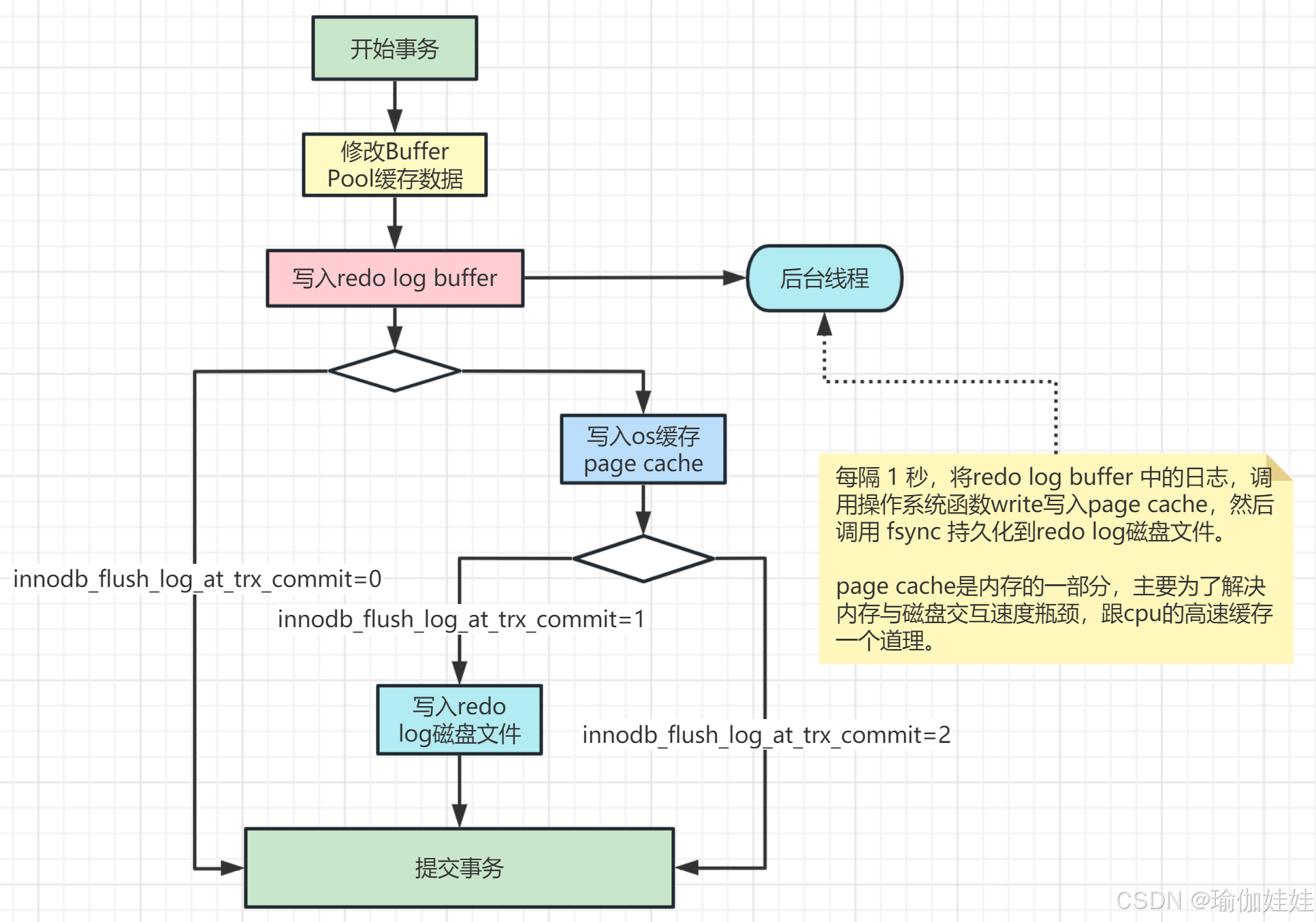
寫入策略:由innodb_flush_log_at_trx_commit參數控制
參數設置與查看
# 查看innodb_flush_log_at_trx_commit參數值:
show variables like 'innodb_flush_log_at_trx_commit';
# 設置innodb_flush_log_at_trx_commit參數值(也可以在my.ini或my.cnf文件里配置):
set global innodb_flush_log_at_trx_commit=1;
參數選型
| 參數值 | 含義與行為 | 數據安全性 | 性能表現 | 適用場景 |
|---|---|---|---|---|
| 1 | 事務提交時,強制將 Redo Log 從緩沖區(Redo Log Buffer)刷入磁盤(通過?fsync?系統調用確保物理寫入)。 | 最高:即使數據庫崩潰或服務器斷電,已提交事務的日志也不會丟失。 | 較低:每次提交都觸發磁盤 IO,對高頻提交場景有性能影響。 | 核心業務(如金融交易、訂單支付),對數據一致性要求極高的場景。 |
| 0 | 事務提交時,不刷盤,僅將 Redo Log 寫入緩沖區;由后臺線程每 1 秒批量將緩沖區日志刷入磁盤。 | 較低:若數據庫崩潰,可能丟失最后 1 秒內已提交的事務日志。 | 最高:避免頻繁磁盤 IO,適合寫入密集型場景。 | 非核心業務(如日志采集、臨時數據存儲),可接受少量數據丟失的場景。 |
| 2 | 事務提交時,將 Redo Log 寫入操作系統緩存(OS Cache),不觸發?fsync;操作系統每 1 秒將緩存數據刷入磁盤。 | 中等:若數據庫崩潰,操作系統緩存中的日志不會丟失;若服務器斷電,可能丟失操作系統緩存中的日志(通常不超過 1 秒)。 | 中等:比 1 性能高(減少?fsync?開銷),比 0 安全性高。 | 對性能有一定要求,且允許極短時間數據丟失的場景(如電商商品評論、非實時統計)。 |
寫入流程
核心參數選型與設置
選型
Redo Log 的參數配置直接影響數據庫的性能、可靠性和崩潰恢復速度,以下是核心參數的選型建議:
| 參數名稱 | 功能描述 | 可選值范圍 | 選型建議 | 決策依據 |
|---|---|---|---|---|
innodb_log_file_size | 單個 Redo Log 文件大小 | 1M ~ 512G(受總大小限制) | 生產環境:2G ~ 4G 小型應用:512M ~ 1G | - 過小:日志切換頻繁,Checkpoint 觸發頻繁,IO 開銷大 - 過大:崩潰恢復時間長 - 需滿足: 單個大小 × 文件數 ≤ 512G |
innodb_log_files_in_group | Redo Log 文件數量 | 1 ~ 100 | 推薦:2 ~ 4 個(默認 2 個) | - 數量過少:單文件損壞風險高 - 數量過多:管理開銷增加,2-4 個足以平衡可靠性與性能 |
innodb_flush_log_at_trx_commit | 日志刷盤策略 | 0、1、2 | 核心業務:1 非核心業務:2 測試 / 日志系統:0 | - 1(最安全):事務提交即刷盤,無數據丟失 - 2(折中):提交寫 OS 緩存,秒級刷盤 - 0(最高性能):每秒批量刷盤,可能丟失 1 秒數據 |
innodb_log_buffer_size | Redo Log 緩沖區大小 | 默認 16M,最大無限制(通常≤1G) | 一般場景:默認 16M 大量短事務:64M ~ 256M | - 過小:頻繁刷盤(尤其大事務) - 過大:內存浪費,超過 256M 收益有限 |
查看與設置語法
# 查看
show variables like '參數名';
# 設置
set global 參數名=目標值; 配置注意事項
選擇配置時,需結合業務的數據安全等級、寫入頻率和硬件 IO 能力綜合決策,建議先在測試環境驗證后再應用到生產。以下為使用 redolog的常見注意事項。
- 修改日志文件大小 / 數量的步驟:
- 停止 MySQL 服務
- 刪除舊日志文件(ib_logfile0、ib_logfile1等)
- 修改配置文件
- 重啟 MySQL(自動生成新日志文件)
- 總大小限制:
確保 innodb_log_files_in_group × innodb_log_file_size ≤ 512G,超出會導致啟動失敗。 - 與其他參數的配合:
- 若innodb_flush_method = O_DIRECT(繞開 OS 緩存),innodb_flush_log_at_trx_commit=2等價于1的安全性
- 高并發寫入場景,建議配合innodb_buffer_pool_size調大內存緩存
- 監控與調優:
|通過SHOW ENGINE INNODB STATUS查看日志使用情況,若Log sequence number與Log flushed up to差距過大,可能需要調大innodb_log_buffer_size。
Redo Log 實際應用的常見誤區
- 誤區 1:認為 “日志文件越大越好”
- 錯誤認知:部分運維人員為減少切換頻率,將 innodb_log_file_size 設為 16G 甚至更大。
- 風險:崩潰恢復時間會急劇增加(如 16G 的日志文件,恢復可能需要 30 分鐘以上),若業務要求 “快速恢復”,會導致長時間服務不可用。
- 正確做法:單個文件大小不超過 4G,總大小控制在 16G 以內(除非業務對恢復時間無要求)。
- 誤區 2:所有業務都用 innodb_flush_log_at_trx_commit=1
- 錯誤認知:為 “絕對安全”,即使是非核心業務(如日志)也強制使用 1。
- 問題:fsync() 操作會導致大量磁盤 IO 開銷,寫入性能下降 30%~50%,浪費硬件資源。
- 正確做法:根據業務優先級選擇刷盤策略,非核心業務用 2 或 0,平衡性能與安全。
- 誤區 3:忽略 Redo Log 與硬件的配合
- 錯誤認知:只調優參數,不關注磁盤類型。
- 問題:若 Redo Log 存儲在機械硬盤(HDD)上,即使參數優化,順序寫性能也有限(HDD 順序寫速度約 100MB/s);若存儲在 SSD 上,未開啟 innodb_flush_method=O_DIRECT,會導致 OS 緩存與 SSD 緩存疊加,增加延遲。
- 正確做法:
- Redo Log 優先存儲在 SSD 上,利用其高 IOPS 特性;
- 開啟 innodb_flush_method=O_DIRECT,繞開 OS 緩存,直接寫入 SSD,減少延遲(需注意:此時 innodb_flush_log_at_trx_commit=2 等價于 1 的安全性,因為 SSD 掉電保護可避免 OS 緩存數據丟失)。
Redo Log 的核心實際應用場景
- 支撐高并發寫入業務
在電商秒殺、支付交易、日志采集等高頻寫入場景中,Redo Log 是性能保障的關鍵:- 原理:事務執行時,InnoDB 先將 “數據修改記錄”(如 “表 t1 的 id=1 行,name 從 A 改為 B”)寫入 Redo Log Buffer(內存緩沖區),再通過 “刷盤策略” 寫入磁盤上的 Redo Log 文件(順序寫,速度遠快于數據頁的隨機寫);事務提交后,無需等待數據頁立即刷盤,只需確保 Redo Log 已刷盤(即 “WAL 原則”)。
- 實際效果:將 “數據頁隨機寫” 轉化為 “Redo Log 順序寫”,寫入性能提升 10~100 倍,支撐每秒數萬次的事務寫入。
- 崩潰恢復(Crash Recovery)
數據庫意外宕機(如斷電、進程崩潰)后,重啟時 InnoDB 會通過 Redo Log 恢復數據,避免事務丟失:- 恢復流程:
- 讀取 Redo Log 文件中 “未刷盤到數據頁” 的事務記錄(通過 Log Sequence Number 即 LSN 匹配,LSN 是 Redo Log 和數據頁的 “版本標識”);
- 重新執行這些記錄,將數據恢復到宕機前的狀態;
- 對 “未提交但已寫入 Redo Log” 的事務,通過 Undo Log 回滾,確保數據一致性。
- 實際價值:金融、支付等核心業務依賴此機制實現 “零數據丟失”(需配合 innodb_flush_log_at_trx_commit=1)。
- 恢復流程:
- 減少數據頁刷盤頻率
InnoDB 的數據頁(默認 16KB)刷盤成本高,Redo Log 允許數據頁 “延遲刷盤”:- 原理:事務修改數據時,先更新內存中的 “緩沖池(Buffer Pool)數據頁”,并記錄 Redo Log;數據頁只需在 “緩沖池滿”“Checkpoint 觸發” 或 “定時任務” 時刷盤,無需每次事務提交都刷盤。
- 實際影響:減少磁盤 IO 次數,尤其在 “大量短事務” 場景中,可顯著降低 IO 壓力。

)




-電機分類)

)
)



)



)

