1. 【前言】

大語言模型(LLMs) 在推理任務中通過自一致性等測試時縮放方法展現出巨大潛力,但存在精度收益遞減和計算開銷高的問題。為此,Meta與UCSD的研究人員提出DeepConf方法,它利用模型內部的置信度信號,在生成過程中或生成后動態過濾低質量推理軌跡,無需額外模型訓練或超參數調優,可無縫集成到現有服務框架中。在多種推理任務和最新開源模型(如Qwen 3和GPT-OSS系列)上的評估顯示,DeepConf在挑戰性基準測試(如AIME 2025)中表現優異,DeepConf@512的準確率高達99.9%,與完全并行思維相比,生成的** tokens減少多達84.7%,顯著提升了推理效率**和性能。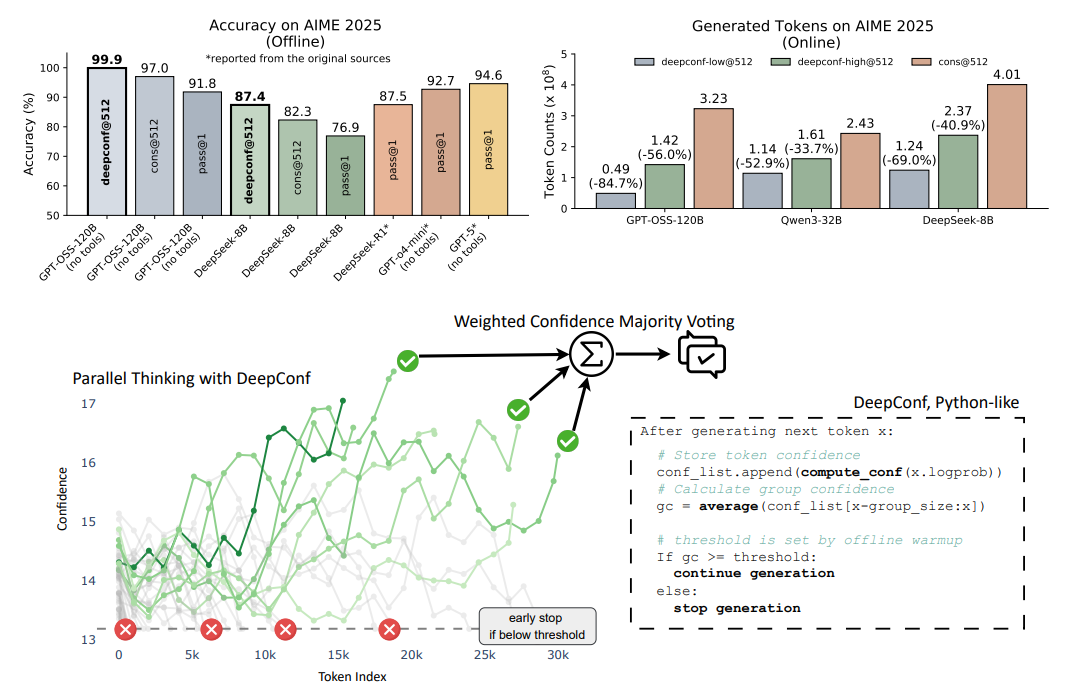
2. 【論文基本信息】

論文標題:Deep Think with Confidence
論文鏈接:https://arxiv.org/html/2508.15260v1 項目鏈接:jiaweizzhao.github.io/deepconf
3 論文背景
3.1 大語言模型推理的現狀與挑戰
大語言模型(LLMs)在推理任務中展現出顯著潛力,尤其通過測試時縮放方法(如自一致性方法),即生成多條推理路徑并通過多數投票聚合答案,可有效提升推理性能。然而,該類方法存在明顯局限:一方面,隨著推理軌跡數量增加,精度提升呈現遞減趨勢,甚至可能因低質量軌跡主導投票而導致性能下降;另一方面,生成大量推理軌跡會帶來極高的計算開銷,例如在AIME 2025任務中,使用Qwen3-8B模型將pass@1精度從68%提升至82%,需額外生成511條推理軌跡,消耗1億個token,嚴重限制了實際部署。
3.2 現有置信度評估方法的不足
近年來,研究開始利用模型的下一個token分布統計(如熵、置信度分數)評估推理軌跡質量,通過聚合token級統計量計算全局置信度(如平均軌跡置信度),以篩選低質量軌跡。但全局置信度方法存在兩大缺陷:一是掩蓋了局部推理步驟的置信度波動,可能忽略關鍵的中間推理錯誤(如少數高置信度token掩蓋大量低置信度片段);二是需生成完整軌跡才能計算,無法實現低質量軌跡的早期終止,導致計算效率低下。
3.3 DeepConf方法的提出動機
為解決上述問題,本文提出“Deep Think with Confidence(DeepConf)”方法。其核心思路是利用模型內部的局部置信度信號,在推理軌跡生成過程中或生成后動態過濾低質量軌跡。該方法無需額外模型訓練或超參數調優,可無縫集成到現有服務框架中,旨在同時提升推理效率(減少生成token)和性能(提高精度),尤其針對復雜推理任務(如AIME 2025)實現高效優化。
4.【研究方法論】
4.1 推理質量的置信度指標
為了有效評估推理軌跡的質量,論文基于模型內部的token分布提出了多種置信度指標,具體如下:
Token熵(Token Entropy):給定語言模型在位置i的預測token分布 ,token熵定義為
,其中
表示詞匯表中第j個token的概率。低熵表明分布集中,模型確定性高;高熵則反映預測的不確定性。
Token置信度(Token Confidence):將位置i的top-k個token的負平均對數概率定義為token置信度 ,k為所考慮的top token數量。高置信度對應分布集中和模型確定性高,低置信度則表示token預測的不確定性。
平均軌跡置信度(Average Trace Confidence):為了評估整個推理軌跡,對token級指標進行聚合,采用平均軌跡置信度(也稱為自確定性)作為軌跡級質量度量,即 ,其中N是生成的token總數。該指標能有效區分正確和錯誤的推理路徑,值越高表明正確性可能性越大,但存在掩蓋中間推理失敗和需完整軌跡才能評估的局限性。

4.2 DeepConf的置信度度量方法
為解決全局置信度度量的局限性,論文提出了多種捕捉局部中間步驟質量的置信度度量方法,具體如下:
組置信度(Group Confidence):通過在推理軌跡的重疊跨度上平均token置信度,量化中間推理步驟的置信度,提供更局部和平滑的信號。每個token與一個滑動窗口組 相關聯,該組由n個先前的token組成(例如n=1024或2048),相鄰窗口重疊。對于每個組
,其中
是組
底部10%組置信度(Bottom 10% Group Confidence):為捕捉極低置信度組的影響,軌跡置信度由軌跡內底部10%組置信度的平均值確定,即 ,其中
是置信度得分最低的10%組的集合。
最低組置信度(Lowest Group Confidence):考慮推理軌跡中最不自信的組的置信度,是底部10%組置信度的特例,僅基于最低置信度組估計軌跡質量,定義為 ,其中G是推理軌跡中所有token組的集合。
尾部置信度(Tail Confidence):通過關注推理軌跡的最后部分來評估其可靠性,基于推理質量在長思維鏈末端往往下降且最終步驟對正確結論至關重要的觀察。尾部置信度 定義為
,其中
代表固定數量的token(例如2048)。
4.3 DeepConf的離線與在線思維方法

4.3.1 離線思維(Offline Thinking)
在離線思維中,每個問題的推理軌跡已生成,重點是聚合多個軌跡的信息以更好地確定最終答案,主要包括以下方法:
多數投票(Majority Voting):在標準多數投票中,每個推理軌跡的最終答案對最終決策的貢獻相同。設T為所有生成軌跡的集合,對于每個 ,令answer(t)為從軌跡t中提取的答案字符串。每個候選答案a的得票數為
,其中
是指示函數。最終答案選擇得票最高的那個,即
。
置信度加權多數投票(Confidence-Weighted Majority Voting):不再平等對待每個軌跡的投票,而是根據相關軌跡的置信度對每個最終答案進行加權。對于每個候選答案a,其總得票權重定義為 ,其中
是從上述討論的置信度度量中選擇的軌跡級置信度。選擇加權得票最高的答案,該投票方案有利于高置信度軌跡支持的答案,從而減少不確定或低質量推理答案的影響。
置信度過濾(Confidence Filtering):除了加權多數投票外,還應用置信度過濾來集中關注高置信度推理軌跡。置信度過濾根據軌跡置信度得分選擇前η百分比的軌跡,確保只有最可靠的路徑對最終答案有貢獻,提供η=10%和η=90%兩種選擇。 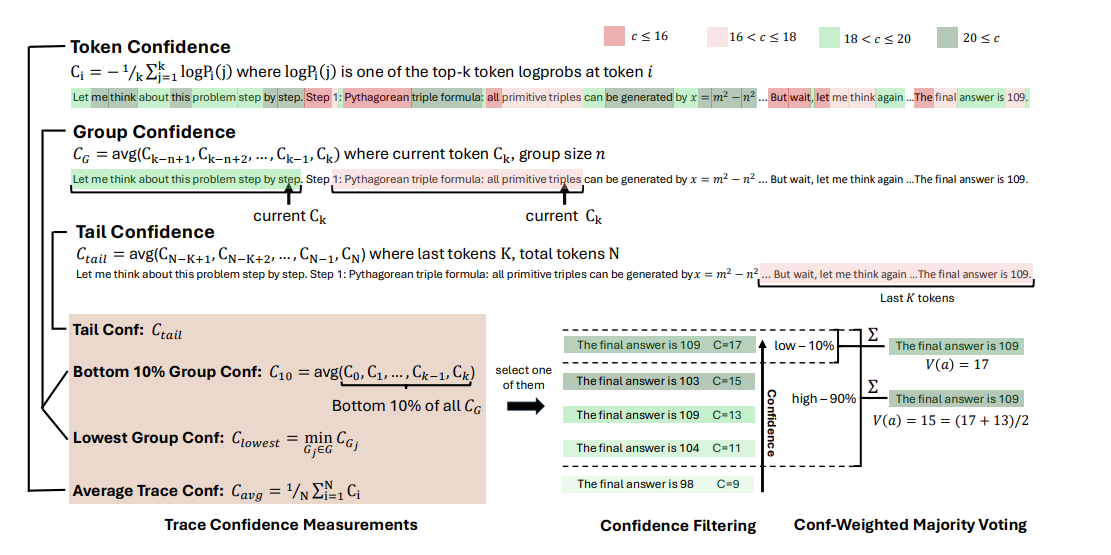
4.3.2 在線思維(Online Thinking)
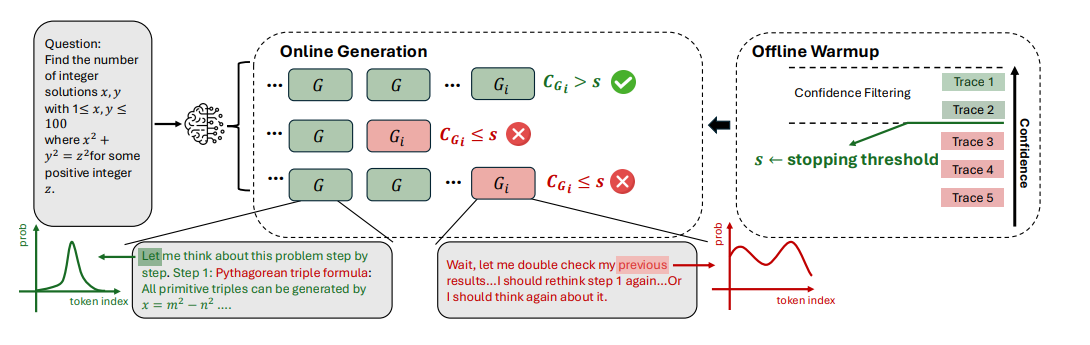
在線思維過程中評估置信度,能夠在生成過程中實時估計軌跡質量,從而動態終止無前景的軌跡,主要包括以下內容:
算法介紹:提出了基于最低組置信度的DeepConf-low和DeepConf-high兩種算法,在在線思維中自適應地停止生成并調整軌跡預算,包括離線預熱和自適應采樣兩個主要部分。 離線預熱(Offline Warmup):DeepConf需要一個離線預熱階段來確定在線決策的停止閾值s。對于每個新提示,生成 個推理軌跡(例如
)。停止閾值s定義為
,其中
表示所有預熱軌跡,
自適應采樣(Adaptive Sampling):在DeepConf中,所有方法都采用自適應采樣,根據問題難度動態調整生成的軌跡數量。難度通過生成軌跡之間的共識來評估,用量化多數投票權重 與總投票權重
的比率表示,即
。τ是預設的共識閾值。如果
,模型對當前問題未達成共識,軌跡生成將繼續,直到達到固定的軌跡預算B。否則,軌跡生成停止,使用現有軌跡確定最終答案。 -
5.【實驗結果】
5.1 實驗設置
模型:評估5個開源LLM(DeepSeek-8B、Qwen3-8B/32B、GPT-OSS-20B/120B),覆蓋多參數規模,側重數學推理與長思維鏈能力。 數據集:5個高難度基準,含4個數學競賽題(AIME24/25、BRUMO25、HMMT25)和1個研究生STEM推理任務(GPQA)。 基線與設置:以自一致性多數投票為基線,預生成4096條推理軌跡池,離線/在線實驗分別重采樣后應用投票方法,結果經64次獨立運行平均,早期終止軌跡僅計停止前token。
5.2 離線評估結果
帶過濾的置信度加權多數投票多數優于標準多數投票(Cons@512)。 η=10%過濾收益最大,如DeepSeek-8B在AIME25準確率從82.3%升至87.4%,GPT-OSS-120B在AIME25達99.9%。 局部與全局置信度度量均有效,但η=10%激進過濾可能因模型過度自信受損,η=90%更保守安全。 所有方法均優于pass@1,最低組置信度下,η=10%平均提升5.27個百分點(相對多數投票),η=90%平均提升0.29個百分點。 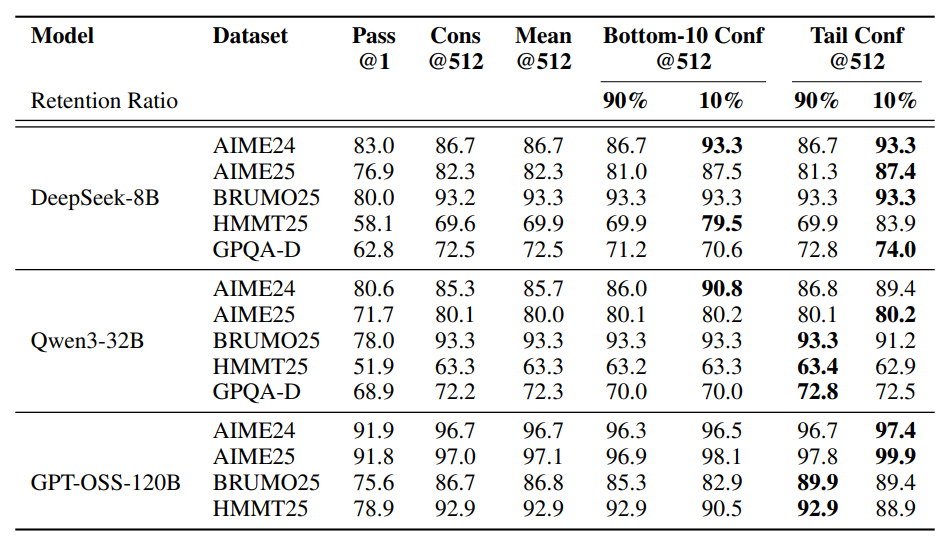

5.3 在線評估結果
K=512時,DeepConf-low減少43-79%token,多數情況提升準確率(如DeepSeek-8B在AIME24+5.8%),少數情況下降;DeepConf-high節省18-59%token,準確率基本不變。 GPT-OSS-120B上,DeepConf最高節省85.8%token,保持競爭力。 DeepSeek-8B上,DeepConf-low平均省62.88%token,DeepConf-high省47.67%,效率優勢顯著。 在線行為與離線一致,η=10%過濾增益最高,偶爾在特定數據集下降。
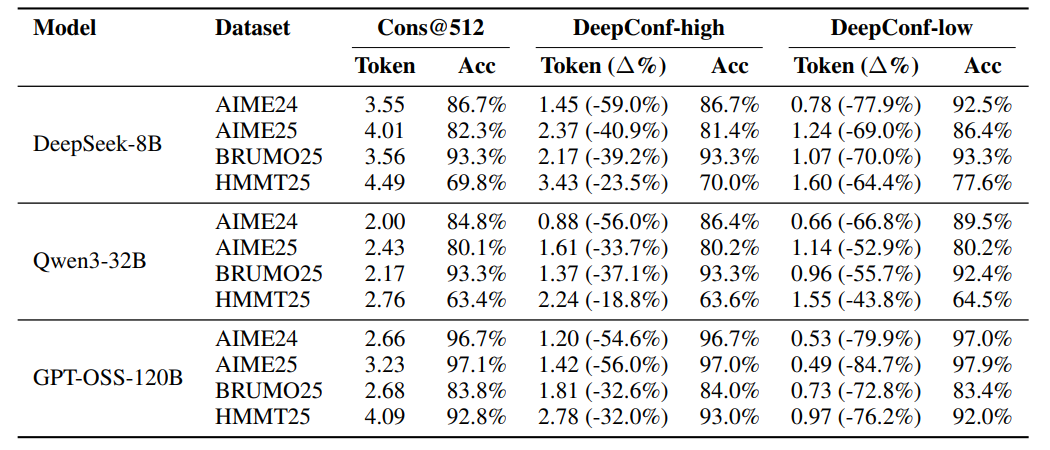
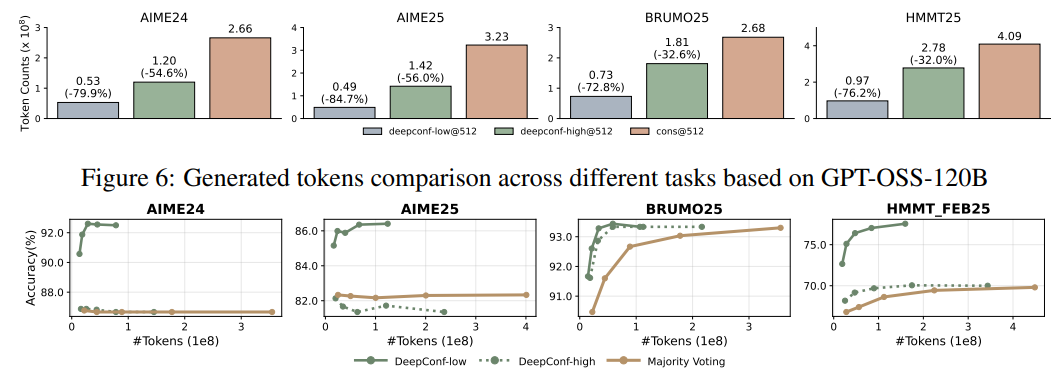
6.【總結展望】
6.1 總結
論文提出了Deep Think with Confidence(DeepConf)方法,旨在解決大型語言模型(LLMs)在推理任務中使用自一致性等測試時擴展方法存在的準確性收益遞減和計算開銷高的問題。DeepConf利用模型內部的置信度信號,在生成過程中或生成后動態過濾低質量的推理軌跡,無需額外的模型訓練或超參數調優,可無縫集成到現有服務框架中。通過在多種推理任務和最新開源模型上的評估表明,在離線模式下,DeepConf@512使用GPT-OSS-120B在AIME 2025上達到99.9%的準確率;在在線模式下,與完全并行思維相比,可減少高達84.7%的生成token,同時保持或超過準確率,有效提升了推理效率和性能。
6.2 展望
未來工作有多個有前景的方向。一是將DeepConf擴展到強化學習場景,利用基于置信度的早期停止來指導策略探索,提高訓練期間的樣本效率。二是解決模型在錯誤推理路徑上表現出高置信度的情況,這是實驗中觀察到的一個關鍵限制。此外,還可探索更 robust的置信度校準技術和不確定性量化方法,以更好地識別和緩解過度自信但錯誤的預測。

-電機分類)

)
)



)



)



![uniapp [全端兼容] - 實現全景圖Vr 720°全景效果查看預覽功能,3D全景圖流暢不卡頓渲染+手勢拖拽+懸浮工具按鈕,uniAPP實現vr看720度全景效果示例代碼(H5小程序APP全兼容)](http://pic.xiahunao.cn/uniapp [全端兼容] - 實現全景圖Vr 720°全景效果查看預覽功能,3D全景圖流暢不卡頓渲染+手勢拖拽+懸浮工具按鈕,uniAPP實現vr看720度全景效果示例代碼(H5小程序APP全兼容))


