一、概述
1.1 什么是向量庫
向量數據庫是一種專門為存儲、索引和查詢高維向量數據而優化的數據庫系統。與傳統的關系型數據庫不同,向量數據庫將數據映射到向量空間中,使得數據的相似性計算、聚類、分類和檢索變得更加高效和精確
向量數據庫一般包括以下幾個部分:索引、查詢、過濾
第一步:建立索引
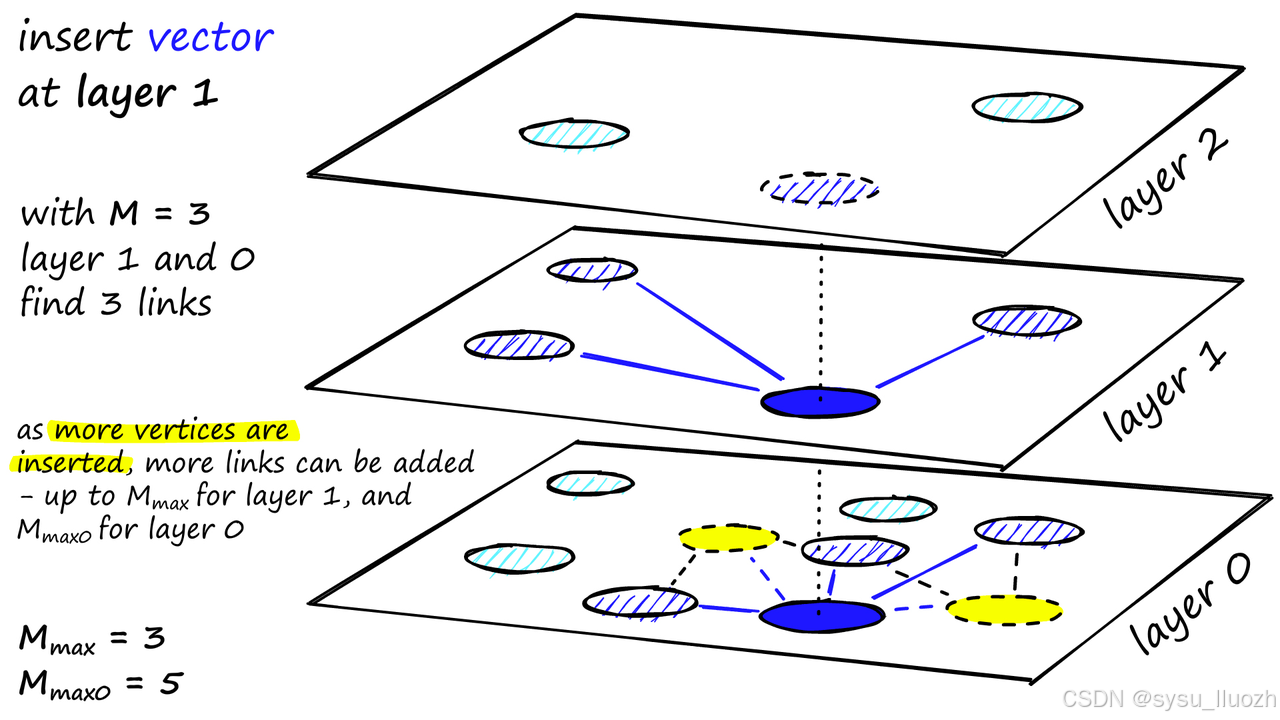
向量數據庫使用 HNSW(分層可導航小世界)等算法對向量進行索引,此步驟將向量映射到數據結構,以實現更快的搜索。索引的目標是通過創建可快速遍歷的數據結構來實現快速查詢,通常會將原始向量的表示形式轉換為壓縮形式以優化查詢過程
HNSW 創建一個分層的樹狀結構,其中樹的每個節點代表一組向量。節點之間的邊代表向量之間的相似度。在高層次,數據點的數量較少,連接關系較少,搜索效率較高。在底層,數據點的數量較多,連接關系更密集,能夠更精確地找到最近鄰。通過逐層導航和搜索,HNSW 能夠快速找到與查詢點最相似的點
第二步:查詢檢索
向量數據庫將索引查詢向量與數據集中的索引向量進行比較,以找到最近的鄰居,這里會應用該索引使用的相似性度量。相似性度量是用于確定向量空間中兩個向量相似程度的數學方法。向量數據庫中使用相似性度量來比較數據庫中存儲的向量并找到與給定查詢向量最相似的向量。可以使用多種相似性度量,包括:余弦相似度

JavaScript 表單驗證)
)


 - 飛控中的傳感器)





)


)

詳解)


