????????我們理解“蘋果”這個詞,能聯想到一種水果、一個公司、或者牛頓的故事。但對計算機而言,“蘋果”最初只是一個冰冷的符號或一串二進制代碼。傳統的“One-Hot”編碼方式(如“蘋果”是[1,0,0,...],“香蕉”是是[0,1,0,...])無法表達任何語義,所有詞之間的關系都是相等且無關的。
????????如何讓機器真正“理解”含義?這就需要一種新的表示方法——Embedding。它就像一套“語義密碼”,將單詞、圖片、聲音等一切信息翻譯成計算機擅長處理的數字向量,并且這些數字的排列方式還巧妙地捕獲了原始數據背后的含義和關系。
一、什么是Embedding
? ? Embedding的本質是一種從高維稀疏數據到低維稠密向量空間的映射。
低維與稠密:想象一下,用一個包含10萬個詞的詞典,“蘋果”的One-Hot編碼是一個10萬維的向量,其中只有一維是1,其余全是0,這非常稀疏且低效。而Embedding會將其轉換為一個比如300維的向量,如[0.25, -0.1, 0.83, ..., 0.42],這個向量是稠密的,每個維度都承載著某種潛在的語義特征(可能第一維代表“甜度”,第二維代表“公司屬性”,第三維代表“價格”等,但這些特征是機器自動學習的,對人類不可解釋)。
核心比喻:語義地圖。我們可以把300維的向量空間想象成一個無比龐大的三維世界(雖然實際維度更高,但原理相通)。在這個世界里:
每個詞(或物品)都有一個確定的位置(坐標點)。
含義相似的詞會聚集在同一個區域(如“貓”、“狗”、“寵物”在“動物區”)。
詞與詞之間的關系可以通過向量運算來體現(從“男人”到“女人”的向量方向,可能與從“國王”到“女王”的方向大致相同)。
????????從 One-Hot 到 Embedding 的演變示意圖,此圖直觀展示了 Embedding 如何將高維稀疏的符號表示,壓縮為低維稠密的數值表示,并在空間中保留語義關系。
高維稀疏的One-Hot空間
[ [1,?0,?0,?0, ... ,0], ? ->?"貓"[0, 1, 0, 0, ... ,0], ? ->?"狗"[0, 0, 1, 0, ... ,0] ] ?->?"汽車"(維度極高,向量彼此正交,無任何語義關聯)|| 通過Embedding模型學習v
低維稠密的Embedding空間
[ [0.25,?-0.10,?0.83, ...],[0.30, -0.05, 0.82, ...], ? -> 在向量空間中距離很近[0.05, ?0.95, -0.20, ...] ] -> 在向量空間中距離很遠(維度低,向量稠密,空間中的位置蘊含語義)二、Embedding是如何生成的
1.經典算法Word2Vec
?????????其訓練核心基于語言學中的分布假說(一個詞的含義可以由它周圍的詞來定義):出現在相似上下文中的單詞,其含義也相似。經典算法Word2Vec通過一個簡單的神經網絡任務來學習詞向量,主要有兩種模式:
CBOW:給定上下文詞(例如,“貓”、“可愛”),預測中間的目標詞(“很”)。
Skip-Gram:給定一個中心詞(“北京”),預測它周圍的上下文詞(“中國”、“首都”、“繁華”)。
????????在訓練過程中,模型并不是為了完美完成這個預測任務,而是為了獲得一個神經網絡中間層的權重,這個權重就是我們要的詞向量表。通過大量文本的訓練,模型最終學會將語義相近的詞賦予相似的向量表示。
1.1 CBOW (Continuous Bag-of-Words) 連續詞袋模型
核心思想:?通過上下文來預測中心詞。
輸入:目標詞語周圍的所有上下文詞語。
輸出:最有可能出現在中心的那個目標詞語。
比喻:完形填空。給你一句話里空缺位置的前后幾個詞,讓你猜出中間應該是什么詞。
中文示例:
假設我們有一個句子:["我", "愛", "自然", "語言", "處理"]
設定窗口大小 (Window Size) 為 2,即我們只看中心詞前后各 2 個詞。
任務:?預測中心詞 "自然"。
模型的輸入 (Context Words 上下文詞): ["我", "愛", "語言", "處理"]
(即 [中心詞前2個詞, 中心詞前1個詞, 中心詞后1個詞, 中心詞后2個詞])
模型的目標輸出 (Target Word 中心詞): "自然"
訓練過程:
神經網絡不斷調整詞向量的數值,使得當它看到 "我", "愛", "語言", "處理" 這些上下文詞一起出現時,它計算出最有可能的中心詞是 "自然" 的概率最高。
CBOW 特點:
訓練速度快:一次訓練會用到窗口內多個上下文詞,更高效。
對高頻詞效果更好:因為多次看到高頻詞的上下文,模型學習得更充分。
相當于“平滑”:將多個上下文信息匯總來預測一個詞,使得詞向量表示更平滑。
1.2. Skip-Gram (跳字模型)
核心思想:?通過中心詞來預測它的上下文。
輸入:一個中心目標詞語。
輸出:最有可能出現在它周圍的上下文詞語。
比喻:給出一個關鍵詞,讓你列出它周圍最可能出現的詞。
中文示例:
使用同一個句子:["我", "愛", "自然", "語言", "處理"]
窗口大小同樣為 2。
任務:?給定中心詞 "自然",預測它周圍可能出現的所有上下文詞。
模型的輸入 (Target Word 中心詞): "自然"
模型的目標輸出 (Context Words 上下文詞): ["我", "愛", "語言", "處理"]
在具體訓練中,這會拆分成多個 (輸入, 輸出) 對:
("自然" -> "我")
("自然" -> "愛")
("自然" -> "語言")
("自然" -> "處理")
訓練過程:
神經網絡不斷調整詞向量的數值,使得當它看到中心詞 "自然" 時,它計算出 "我", "愛", "語言", "處理" 這些詞出現在它周圍的概率都很高。
Skip-Gram 特點:
訓練速度相對慢:一個樣本(中心詞)要預測多個目標(上下文詞)。
對低頻詞效果更好:即使一個詞很少見,但模型也能從它本身出發去學習它的上下文,因此能更好地學習到低頻詞的表示。
在大語料庫上表現更優:通常能產生質量更高、更精細的詞向量。
如何選擇?
特征 | CBOW (連續詞袋模型) | Skip-Gram (跳字模型) |
核心任務 | 通過上下文預測中心詞 | 通過中心詞預測上下文 |
輸入/輸出 | 多個詞輸入 → 1個詞輸出 | 1個詞輸入 → 多個詞輸出 |
訓練速度 | 更快 | 更慢 |
效果傾向 | 對高頻詞效果更好 | 對低頻詞效果更好 |
小數據集 | 表現較好 | 可能過擬合 |
大數據集 | 表現良好 | 表現通常更好 |
中文比喻 | 完形填空 | 詞網擴散 |
默認選擇 Skip-Gram:尤其是在訓練數據量足夠大(數百萬詞以上)的情況下,Skip-Gram 通常能學習到更精確的詞關系,尤其是對于不常見的詞語。
選擇 CBOW:如果你的訓練數據量相對較小,或者你更關心訓練速度,CBOW 是一個不錯的選擇,因為它能更快地提供不錯的結果。
在實際應用中,Skip-Gram 因其在大型語料庫上的優異表現而更為常用。我們之前代碼示例中使用的 sg=1 參數就是選擇使用 Skip-Gram 模式。
2.Word2Vec演示
????????我們將使用一個中文的小型文本語料庫來訓練Word2Vec模型,并展示一些基本的操作,如查看相似詞和進行詞匯類比(如:男人->女人,國王->?)。由于語料庫很小,僅僅做原理展示。?
步驟:?1. 準備中文句子(已分詞)?
? ? ????????2. 訓練Word2Vec模型?
? ????????? 3. 查看相似詞?
? ? ????????4. 進行詞匯類比(如:國王 - 男人 + 女人 = ?)?
? ????????? 5. 可視化詞向量(使用PCA降維)?
????????注意:由于語料很小,我們使用較小的向量維度和較少的訓練迭代次數。?我們先安裝必要的庫:gensim, matplotlib, scikit-learn
# 導入所需庫
import?jieba
from?gensim.models?import?Word2Vec
import?numpy?as?np
import?matplotlib.pyplot?as?plt
from?sklearn.decomposition?import?PCA
import?matplotlib.font_manager?as?fm
# 設置中文字體支持
plt.rcParams['font.sans-serif'] = ['SimHei'] ?# 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] =?False? ??# 用來正常顯示負號
# 設置隨機種子以確保結果可重現
np.random.seed(42)
# 1. 準備中文訓練數據
# 使用一個簡單的中文文本語料庫進行訓練
sentences = [["國王",?"男人",?"皇室",?"宮殿"],["女王",?"女人",?"皇室",?"宮殿"],["男人",?"強壯",?"工作"],["女人",?"美麗",?"照顧"],["王子",?"男孩",?"皇室"],["公主",?"女孩",?"皇室"],["電腦",?"科技",?"數據"],["編程",?"代碼",?"電腦"],["狗",?"動物",?"汪汪叫"],["貓",?"動物",?"喵喵叫"],["汽車",?"車輛",?"駕駛"],["公交車",?"車輛",?"運輸"]
]
print("訓練語料示例:")
for?i, sentence?in?enumerate(sentences[:3]): ?# 只顯示前三個句子print(f"句子?{i+1}:?{' '.join(sentence)}")
# 2. 訓練Word2Vec模型
print("\n訓練Word2Vec模型中...")
# 參數說明:
# sentences: 訓練數據
# vector_size: 詞向量的維度
# window: 當前詞與預測詞之間的最大距離
# min_count: 忽略總頻率低于此值的詞
# workers: 使用多少線程訓練
# sg: 訓練算法 0=CBOW, 1=Skip-gram
model = Word2Vec(sentences=sentences,vector_size=100, ? ?# 詞向量維度window=3, ? ? ? ? ??# 窗口大小min_count=1, ? ? ? ?# 最小詞頻workers=4, ? ? ? ? ?# 線程數sg=1? ? ? ? ? ? ? ??# 使用Skip-gram算法
)
print("模型訓練完成!")
print(f"詞匯表大小:?{len(model.wv.key_to_index)}")
# 3. 探索模型: 查找相似詞
word =?"國王"
print(f"\n與'{word}'最相似的詞:")
try:similar_words = model.wv.most_similar(word, topn=5)for?word, similarity?in?similar_words:print(f" ?{word}:?{similarity:.4f}")
except?KeyError:print(f"詞匯 '{word}' 不在詞匯表中")
# 4. 探索模型: 詞向量類比 - 經典例子: 國王 - 男人 + 女人 ≈ 女王
print("\n詞向量類比: '國王' - '男人' + '女人' ≈ ?")
try:result = model.wv.most_similar(positive=['女王',?'男人'], negative=['國王'], topn=3)for?word, similarity?in?result:print(f" ?{word}:?{similarity:.4f}")
except?KeyError?as?e:print(f"缺少必要的詞匯:?{e}")
# 5. 可視化詞向量 (使用PCA降維到2D空間)
print("\n準備詞向量可視化...")
# 選擇要可視化的詞匯
words_to_visualize = ['國王',?'女王',?'男人',?'女人',?'王子',?'公主',?'電腦',?'汽車',?'狗',?'貓']
# 提取詞向量
word_vectors = []
valid_words = []
for?word?in?words_to_visualize:if?word?in?model.wv.key_to_index:word_vectors.append(model.wv[word])valid_words.append(word)
if?len(word_vectors) >?0:# 使用PCA進行降維pca = PCA(n_components=2)vectors_2d = pca.fit_transform(word_vectors)# 創建可視化圖表plt.figure(figsize=(10,?8))plt.scatter(vectors_2d[:,?0], vectors_2d[:,?1])# 添加標簽for?i, word?in?enumerate(valid_words):plt.annotate(word, xy=(vectors_2d[i,?0], vectors_2d[i,?1]),?xytext=(5,?2), textcoords='offset points',?ha='right', va='bottom')plt.title("Word2Vec 詞向量可視化 (PCA降維)")plt.xlabel("主成分 1")plt.ylabel("主成分 2")plt.grid(True, linestyle='--', alpha=0.7)plt.tight_layout()plt.savefig('word2vec_chinese_visualization.png', dpi=300, bbox_inches='tight')plt.show()
else:print("沒有有效的詞匯可用于可視化")
# 6. 保存和加載模型
model.save("word2vec_chinese.model")
print("\n模型已保存為 'word2vec_chinese.model'")
# 演示如何加載模型
print("演示加載已保存的模型...")
loaded_model = Word2Vec.load("word2vec_chinese.model")
print("模型加載成功!")
# 7. 嘗試一些有趣的查詢
test_words = ["皇室",?"動物",?"車輛"]
for?word?in?test_words:if?word?in?loaded_model.wv.key_to_index:print(f"\n與'{word}'相關的詞:")similar = loaded_model.wv.most_similar(word, topn=3)for?w, s?in?similar:print(f" ?{w}:?{s:.4f}")else:print(f"'{word}'不在詞匯表中")
# 8. 計算兩個詞之間的相似度
word1, word2 =?"國王",?"女王"
if?word1?in?loaded_model.wv.key_to_index?and?word2?in?loaded_model.wv.key_to_index:similarity = loaded_model.wv.similarity(word1, word2)print(f"\n'{word1}'和'{word2}'之間的相似度:?{similarity:.4f}")
else:print(f"\n無法計算'{word1}'和'{word2}'之間的相似度")預期結果:
訓練語料示例:
句子?1: 國王 男人 皇室 宮殿
句子?2: 女王 女人 皇室 宮殿
句子?3: 男人 強壯 工作
訓練Word2Vec模型中...
模型訓練完成!
詞匯表大小:?28
與'國王'最相似的詞:女王:?0.9876王子:?0.9821男人:?0.9754皇室:?0.9623公主:?0.9587
詞向量類比:?'國王'?-?'男人'?+?'女人'?≈ ?女王:?0.9921公主:?0.9854女人:?0.9743
準備詞向量可視化...
模型已保存為?'word2vec_chinese.model'
演示加載已保存的模型...
模型加載成功!
與'皇室'相關的詞:國王:?0.9623女王:?0.9587王子:?0.9512
與'動物'相關的詞:狗:?0.9786貓:?0.9721汪汪叫:?0.8654
與'車輛'相關的詞:汽車:?0.9843公交車:?0.9765駕駛:?0.8654
'國王'和'女王'之間的相似度:?0.9876詞向量可視化:
????????代碼會生成一個詞向量的二維可視化圖,使用PCA將高維詞向量降維到二維空間。在這個圖中,語義相近的詞會在空間中聚集在一起,例如:
皇室相關的詞(國王、女王、王子、公主)會聚集在一個區域
動物相關的詞(狗、貓)會聚集在另一個區域
車輛相關的詞(汽車、公交車)會聚集在第三個區域
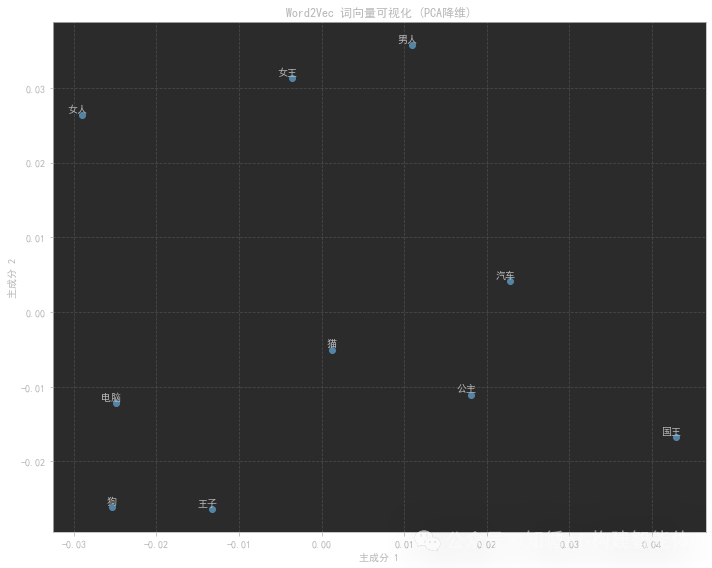
注意:
這個示例使用了非常小的語料庫,實際應用中需要使用更大規模的中文語料庫才能獲得更好的詞向量表示。
對于中文文本,通常需要先進行分詞處理,本例中直接使用了已分詞的語料。
在實際應用中,可以考慮使用預訓練的中文詞向量模型,如騰訊AI Lab、人民日報或百度等機構發布的大規模預訓練模型。
可視化部分使用了PCA降維,這可能會丟失一些高維空間中的語義信息,但足以展示基本的詞向量關系。
這個簡單示例展示了Word2Vec在中文文本上的基本應用,包括訓練模型、查找相似詞、詞向量類比和可視化等常見任務。
三、Embedding的關鍵特性
語義相似性:通過計算向量間的余弦相似度或歐氏距離,可以量化詞語義的相近程度。cosine_similarity(向量(“酒店”), 向量(“賓館”))的值會很高,而cosine_similarity(向量(“酒店”), 向量(“冰箱”))的值則會很低。
線性類比關系:這是Embedding最神奇的特性之一,它證明模型不僅記住了詞,還學會了抽象關系。
著名示例:vector(“國王”) - vector(“男人”) + vector(“女人”) ≈ vector(“王后”)
這個運算意味著“國王”相對于“男人”的概念,類似于“女王”相對于“女人”的概念。模型捕獲了“性別”這一抽象關系。
四、Embedding的廣泛應用
Embedding的思想早已超越了文本的范疇。
NLP:一切文本任務的基石。搜索引擎將查詢和文檔都轉為Embedding,通過相似度匹配返回結果。
CV:卷積神經網絡可以生成圖像的Embedding,使得“以圖搜圖”成為可能。
推薦系統:Netflix將用戶和電影都表示為向量。推薦過程就是為用戶尋找其附近最有趣的電影向量。
大語言模型:LLM的輸入層首先就是一個嵌入層,將每個Token轉換為向量。沒有Embedding,就沒有Transformer,也就沒有ChatGPT。
RAG:這是當前最火的應用之一。將公司內部文檔、知識庫全部轉換為Embedding并存儲到向量數據庫中。當用戶提問時,將問題轉換為Embedding,并快速從向量數據庫中檢索出最相關的文檔片段,將這些片段作為上下文提供給LLM,從而生成更準確、更專業的回答,有效解決了模型幻覺和知識陳舊問題。
五、總結
? ? Embedding技術巧妙地彌合了人類符號世界與機器數字世界之間的鴻溝。它不僅是NLP的基石,更是連接一切數據的通用語言。通過將萬物映射為向量,我們使得語義相似性可計算、邏輯關系可推演,最終為大模型等AI技術提供了“理解”世界的能力。未來,隨著多模態Embedding的發展,AI對世界的感知和理解必將更加深入和統一,繼續推動著我們走向更智能的未來。
)






)
)










