note
文章目錄
- note
- 一、GLM-4.5模型
- 二、Slime RL強化學習訓練架構
- Reference
一、GLM-4.5模型
大模型進展,GLM-4.5技術報告,https://arxiv.org/pdf/2508.06471,https://github.com/zai-org/GLM-4.5,包括GLM-4.5(355B總參數,32B激活參數)和精簡版GLM-4.5-Air(106B參數),均采用混合專家(MoE)架構。
分開來看,訓練上,包括三階段。預訓練階段,數據規模:23Ttokens,涵蓋網頁、社交媒體、書籍、代碼等,分兩階段訓練,第二階段重點提升代碼、數學和科學領域數據占比;
中期訓練階段,增強推理和智能體能力,序列長度從4K擴展至128K。包含倉庫級代碼訓練、合成推理數據訓練、長上下文與智能體訓練。
后期訓練階段,采用兩階段難度課程學習,先訓練中等難度數據,再切換至極難數據(確保有正確答案),解決獎勵信號不足問題;同時直接在64K長輸出上進行單階段RL,避免多階段訓練導致的能力退化;
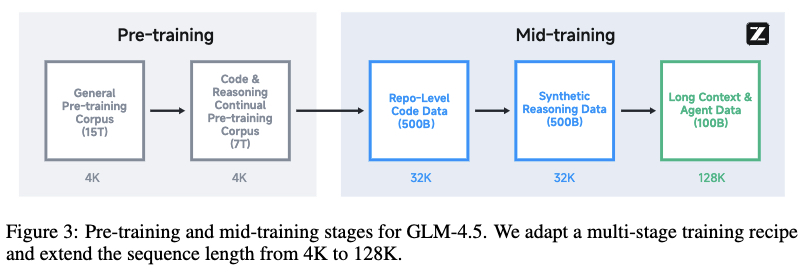
創新點方面,減少模型寬度(隱藏維度)、增加深度(層數)以提升推理能力,采用分組查詢注意力(GQA)和QK-Norm穩定訓練。
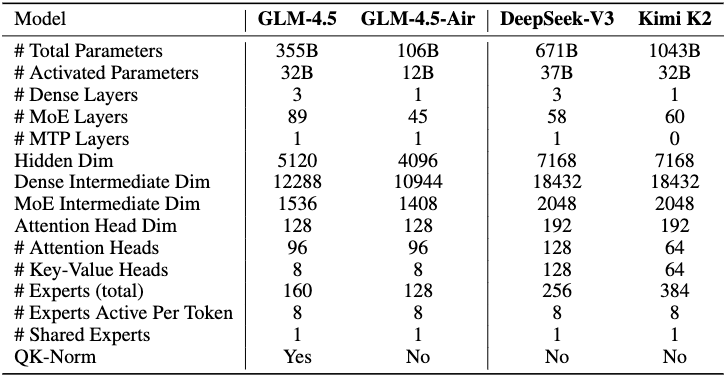
具體的,通過減少隱藏維度(5120)和增加層數(89個MoE層)提升推理能力,而DeepSeek-V3和KimiK2側重更大的隱藏維度(7168);此外,GLM-4.5引入QK-Norm穩定注意力計算,且包含1個MTP層支持推測解碼,而KimiK2無MTP層。
二、Slime RL強化學習訓練架構
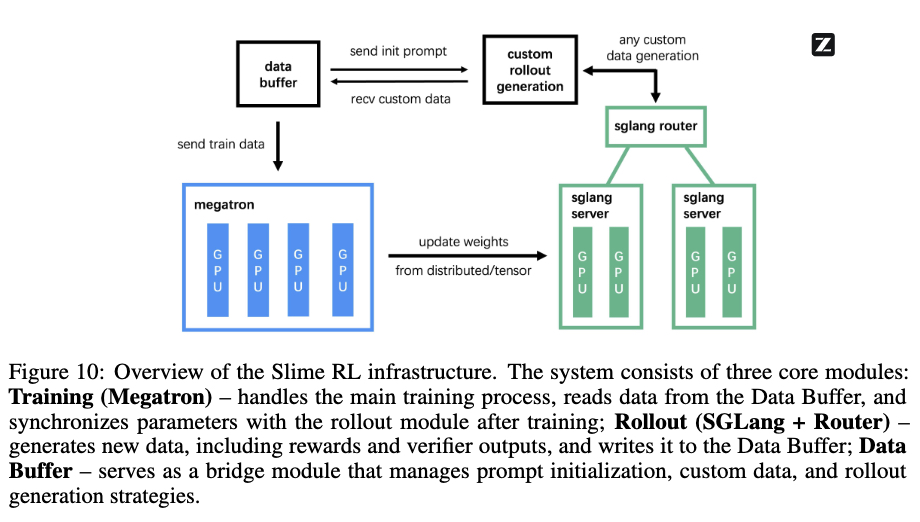
1、核心設計:三模塊解耦(分工明確)??:??訓練車間(Megatron)??:專注“學習”,用 GPU 全力計算梯度更新模型參數,就像工廠里埋頭干活的工人。
2、??數據車間(SGLang + Router)??:負責“模擬環境”,比如讓模型練習網頁搜索或寫代碼,生成訓練需要的“經驗數據”,類似工廠的原料生產線。
3、??中央倉庫(Data Buffer)??:管理數據流轉,存放下游的“經驗數據”和上游的“訓練任務”,相當于智能調度中心,避免生產線堵塞。
Reference
[1] https://github.com/zai-org/GLM-4.5/tree/main
[2] https://www.modelscope.cn/models/ZhipuAI/GLM-4.5/files












 一 歸一化)

 egui (0.32.1) 學習筆記(逐行注釋)(十八) 使用表格)


)

