? ? ? ? 在深度學習與大模型訓練領域,算力是決定研發效率與模型性能的核心要素,而顯卡作為算力輸出的核心硬件,其性能參數直接影響著訓練任務的速度、穩定性與成本控制。對于企業與科研機構而言,選擇一套適配自身需求且性價比優異的顯卡及配套服務器方案,成為推動 AI 項目落地的關鍵前提。

? ? ? ?
? ? ? ? 從當前市場主流顯卡來看,此前廣泛應用的 NVIDIA RTX 4090 與 A6000 因產能調整已正式停產,受供需關系影響,二手市場價格漲幅持續擴大,不僅采購成本攀升,還面臨著售后保障缺失、硬件老化等潛在風險,已不再適合作為長期項目的硬件選擇。而全新上市的 NVIDIA Geforce RTX 5090 憑借架構升級帶來的性能飛躍、更優的能效比以及穩定的供貨渠道,迅速成為深度學習領域的新一代主流選擇。無論是單卡算力、顯存帶寬還是對大模型訓練的兼容性,RTX 5090 均實現了對前代產品的全面超越,結合當前合理的定價,其綜合性價比已處于市場領先水平,成為各類訓練場景下的優選顯卡。
? ? ? ? 針對不同規模的訓練需求,我們篩選出三款基于 RTX 5090 打造的工作站服務器方案,分別覆蓋中小規模單卡訓練、中大規模多卡協同訓練以及大規模集群訓練場景,以下為詳細配置解析:
一、單張 5090 工作站:中小規模訓練的高性價比之選
? ? ? ? 該方案專為中小批量數據處理、模型原型驗證、輕量化模型訓練(如 CNN 圖像分類、小規模 NLP 任務)設計,兼顧性能與成本,適合初創企業、實驗室及個人研究者使用。
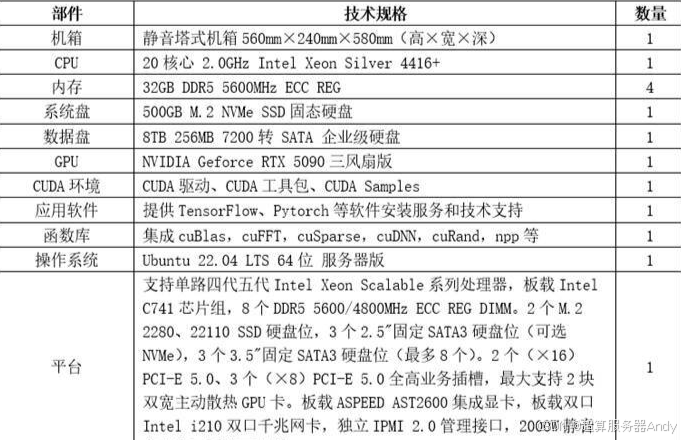
- CPU:搭載 1 顆 Intel Xeon Silver 4416 + 處理器,擁有 20 核心 40 線程,基礎頻率 2.0GHz,睿頻頻率可達 3.0GHz。作為 Intel 至強家族的中端型號,其多核性能足以支撐單卡訓練時的數據預處理、任務調度需求,同時功耗控制優異,避免了不必要的能源浪費。
- 內存:配置 4 根 32GB DDR5 5600MHz ECC REG 內存,總容量 128GB。DDR5 內存的高帶寬(5600MHz 頻率下帶寬可達 44.8GB/s)能夠快速傳輸訓練數據,避免因內存瓶頸拖慢顯卡算力;ECC 錯誤校驗功能則可有效降低內存數據出錯概率,保障訓練過程的穩定性,尤其適合長時間不間斷的訓練任務。
- 硬盤:采用 “系統盤 + 數據盤” 雙盤組合 ——1 塊 500GB M.2 SSD 作為系統盤,具備超高速讀寫能力(順序讀取速度可達 3500MB/s 以上),可快速啟動操作系統與訓練軟件;1 塊 8TB SATA 企業級硬盤作為數據盤,企業級硬盤的高耐用性(MTBF 平均無故障時間達 200 萬小時以上)與大容量特性,能夠滿足中小規模訓練數據的存儲需求,兼顧成本與可靠性。
- GPU:核心硬件為 1 張 NVIDIA Geforce RTX 5090 三風扇版,依托全新 Ada Lovelace 架構升級,CUDA 核心數量與顯存容量均大幅提升,支持 PCIe 5.0 接口,可充分發揮單卡算力,輕松應對中小型模型的訓練任務;三風扇散熱設計則能快速帶走顯卡運行時產生的熱量,維持高負載下的穩定性能輸出。
- 電源:配備 2000W 靜音單電源,額定功率完全覆蓋整套硬件的峰值功耗(RTX 5090 滿載功耗約 450W,整套系統峰值功耗約 800-1000W),冗余功率充足;靜音設計則能有效降低工作環境噪音,提升使用體驗。
二、4 張 5090 塔式靜音服務器:中大規模訓練的高效協同方案
? ? ? ? 隨著訓練任務規模擴大(如中等參數大模型預訓練、多模態數據處理、分布式訓練),單卡算力已難以滿足需求,4 卡協同方案成為平衡算力與空間的理想選擇。該塔式服務器采用靜音設計,適合部署于辦公環境或實驗室,無需單獨機房。
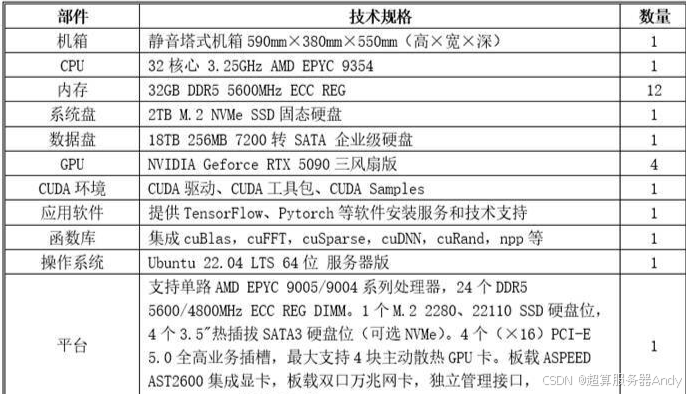
- CPU:選用 1 顆 AMD EPYC 9354 處理器,32 核心 64 線程,基礎頻率 3.25GHz,睿頻頻率高達 4.0GHz。AMD 至強系列處理器在多核性能與內存帶寬支持上表現突出,32 核心的高并發能力可高效調度 4 張顯卡的算力資源,避免出現 CPU 成為訓練瓶頸的情況;較高的基礎頻率也能提升單線程任務處理速度,優化軟件啟動與數據預處理效率。
- 內存:升級為 8 根 32GB DDR5 5600MHz ECC REG 內存,總容量 256GB。4 卡訓練場景下,數據吞吐量大幅增加,256GB 的大內存可同時緩存多組訓練數據,減少硬盤 IO 次數,同時 DDR5 5600MHz 的高帶寬能確保數據在 CPU 與顯卡之間的快速傳輸,避免算力閑置。
- 硬盤:存儲配置全面升級 ——1 塊 2TB M.2 SSD 系統盤,更大的容量可安裝更多訓練軟件與依賴庫,同時保持高速啟動與加載;1 塊 18TB SATA 企業級數據盤,滿足中大規模訓練數據的存儲需求,企業級硬盤的高可靠性也能降低數據丟失風險。
- GPU:搭載 4 張 NVIDIA Geforce RTX 5090 三風扇版,支持 NVIDIA NVLink 技術(需配套主板支持),可實現多卡之間的高速數據互聯,大幅提升分布式訓練效率。4 卡協同算力能夠覆蓋多數中等參數大模型(如 10B-70B 參數模型)的預訓練與微調任務,同時三風扇散熱設計可確保多卡密集部署時的散熱效果,維持穩定性能。
- 電源:采用 2000W+2000W 靜音雙電源設計,雙電源不僅提供充足的總功率(4000W),還支持冗余備份功能 —— 當其中一塊電源出現故障時,另一塊電源可立即接管供電,避免訓練任務因斷電中斷,極大提升了系統的可靠性,尤其適合需要長時間連續運行的訓練場景。
三、8 張 5090 服務器:大規模集群訓練的旗艦級方案
? ? ? ? 該方案面向大規模大模型訓練(如 100B + 參數大模型預訓練、超大規模數據挖掘、AI 集群部署),具備極強的算力輸出與擴展能力,適合大型企業、科研院所及 AI 服務提供商使用,可作為核心算力節點支撐關鍵項目。
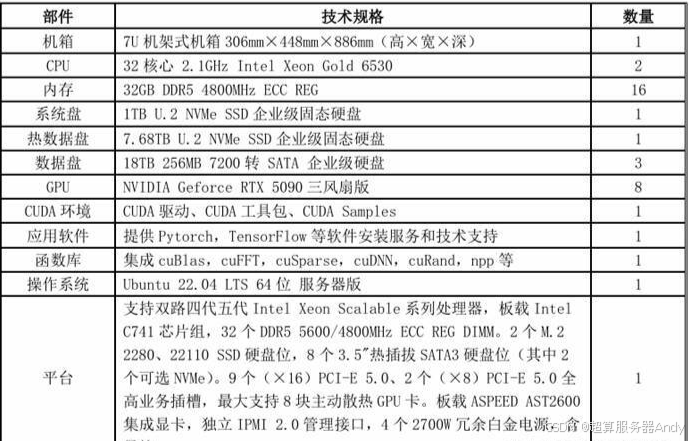
- CPU:采用雙路 CPU 設計,搭載 2 顆 Intel Xeon Gold 6530 處理器,每顆處理器擁有 32 核心 64 線程,基礎頻率 2.1GHz,睿頻頻率 3.5GHz,雙路合計 64 核心 128 線程。大規模訓練場景下,CPU 需要同時處理數據分發、任務調度、多卡協同等復雜任務,64 核心的超高并發能力可確保各類任務高效運行,避免出現算力調度瓶頸;Intel Xeon Gold 系列的穩定性與兼容性也經過長期市場驗證,適合作為核心服務器的計算核心。
- 內存:配置 16 根 32GB DDR5 4800MHz ECC REG 內存,總容量 512GB。8 卡訓練對內存容量與帶寬的需求達到頂峰,512GB 的超大內存可緩存海量訓練數據與模型參數,支持多批次數據并行處理;DDR5 4800MHz 內存雖頻率略低于前兩款方案,但雙路 CPU 支持的多通道內存架構(最高支持 12 通道)可實現更高的總帶寬,確保數據在內存與顯卡之間的傳輸效率。
- 硬盤:采用 “系統盤 + 熱數據盤 + 冷數據盤” 三級存儲架構 ——1 塊 1TB U.2 SSD 作為系統盤,U.2 接口支持 PCIe 4.0 協議,讀寫速度遠超傳統 M.2 SSD,可實現操作系統與軟件的極速啟動;1 塊 7.68TB U.2 SSD 作為熱數據盤,專門存儲高頻訪問的訓練數據與中間結果,PCIe 4.0 協議帶來的超高速讀寫(順序讀取速度可達 7000MB/s 以上)可大幅減少數據等待時間;3 塊 18TB SATA 企業級硬盤作為冷數據盤,總容量 54TB,用于存儲海量訓練原始數據與備份文件,三級存儲架構兼顧了速度、容量與成本,完美適配大規模訓練的存儲需求。
- GPU:核心配置為 8 張 NVIDIA Geforce RTX 5090 三風扇版,支持 NVLink 多卡互聯技術與 NVIDIA Collective Communications Library(NCCL),可實現 8 卡之間的低延遲、高帶寬數據交互,分布式訓練效率接近線性提升。8 卡算力可支撐 100B + 參數大模型的預訓練任務,同時三風扇散熱設計結合服務器內部的風道優化,可有效解決多卡密集部署的散熱問題,確保顯卡長期運行在最佳溫度區間。
- 電源:配備 4 個 2700W 冗余電源,總額定功率達 10800W,不僅能輕松覆蓋 8 張 RTX 5090(單卡滿載 450W,8 卡合計 3600W)及其他硬件的峰值功耗,還支持 N+1 冗余備份 —— 即使其中 1 個電源故障,剩余 3 個電源仍能提供充足功率,確保訓練任務不中斷,為大規模關鍵訓練項目提供極致的可靠性保障。



和噪點(隨機分布的干擾像素),比如電路的方法 計算機視覺)









)





