摘要
最近在整一些3D檢測和分割的任務,接觸了一下ptv3,在之前梳理的工作owlv2中用到了vit,去年年假閱讀《多模態大模型:算法、應用與微調》(劉兆峰)時學習了Transformer網絡架構及其在文本數據中的應用,細數下來,似乎各方面都多多少少了解和應用過一些,但是直到昨天跟別人討論起Transformer在多模態數據中的應用,發現自己了解的不太系統,基于這個大背景,我希望借助閑暇時間梳理一下相關的代表性工作,后面如果有機會,也會做一些實踐記錄,希望自己學會的同時也可以幫助到一些有需要的小伙伴。
Transformer基礎知識
網絡架構
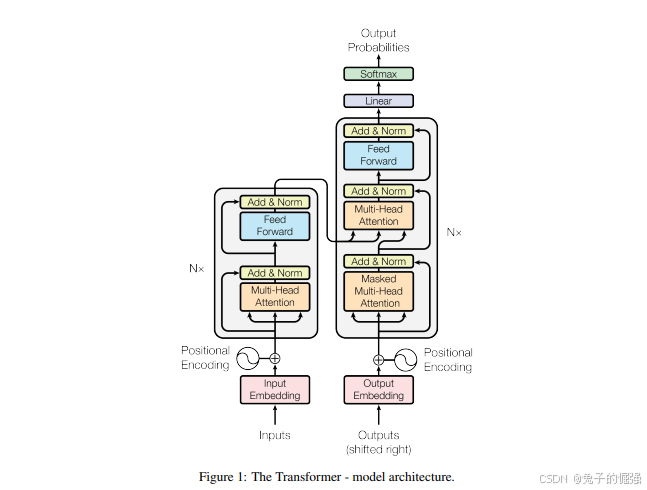
Transformer在nlp中的應用
Transformer在image處理中的應用
Transformer在point clouds處理中的應用
20250820:因為最近在整一些3d相關的工作,所以從該部分開始梳理。如果大家對pointnet系列的點云分割工作感興趣的話,可以去看一下我之前整理的這篇文章3D分割系列論文梳理,歡迎一起討論。
PT
參考鏈接:https://zhuanlan.zhihu.com/p/681682833
貢獻
We design a highly expressive Point Transformer layer for point cloud processing. The layer is invariant to permutation and cardinality and is thus inherently suited to point cloud processing.
在pointnet中有提到,3d點云實際上是一種集合,在點云網絡結構的設計中,由于點云是無序的,所以設計與點云排序和點數量無關的網絡至關重要。而transformer的自注意力機制天生具有排序和點個數不變性,使得它非常適合用來提取點集的特征。
而本文也是聚焦在對點云局部特征提取結構的改造,將自注意力機制應用在了局部特征提取上。
Based on the Point Transformer layer, we construct high-performing Point Transformer networks for classification and dense prediction on point clouds. These networks can serve as general backbones for 3D scene understanding.
We report extensive experiments over multiple domains and datasets. We conduct controlled studies to examine specific choices in the Point Transformer design and set the new state of the art on multiple highly competitive benchmarks, outperforming long lines of prior work.
相關工作梳理
第一類,將不規則點云轉換成規則表示:
Projection-based networks
將點云投影成圖片,利用2D CNN進行處理,最后利用多視角特征融合構建最終的輸出特征表示。
在基于投影的框架中,點云中的幾何信息會在投影階段被壓縮。這些方法在投影平面上構建密集像素網格時,可能未能充分利用點云的稀疏特性。投影平面的選擇會顯著影響識別性能,而三維場景中的遮擋現象也可能導致精度下降。
Voxel-based networks
3D體素+3D 卷積
該類方法,如果直接簡單粗暴的使用3D卷積的話,計算量和內存占用會隨著分辨率增加導致體素塊數量呈三次方增長而增加,解決方式是使用稀疏卷積或者非平衡八叉樹結構,一定程度上減少計算量和內存占用。此外,由于體素網格上的量化處理,仍可能丟失部分幾何細節。
第二類,直接操作不規則點云
Point-based networks.
研究人員沒有將不規則點云投影或量化到二維或三維的規則網格上,而是設計了深度網絡結構,直接將點云作為嵌入連續空間的集合來吸收。(pointnet/pointnet++)
許多方法將點集連接成一個圖,并在此圖上進行信息傳遞。(此類目前了解的比較少)
許多方法基于直接應用于三維點集的連續卷積,而無需量化。(此類目前了解的比較少)
本文的研究靈感
在序列處理和二維圖像任務中,Transformer和自注意力網絡的表現可與卷積網絡相媲美甚至更勝一籌。自注意力機制在本研究中具有特殊意義,因其本質上屬于集合運算:位置信息作為元素屬性被處理為集合形式。由于三維點云本質上是具有空間屬性的點集,這種機制特別適合此類數據類型。為此,開發了專門針對三維點云的點變換器層,實現了自注意力機制的應用。
Point Transformer
background
Self-attention operators can be classified into two types: scalar attention [39] and vector attention [54]. 此處文章中公式很清晰,如果還是看不懂的話,可以問問豆包,并讓它給舉個例子,很清晰。
Point Transformer layer
數學運算:

在局部鄰域應用vector self-attention,對特征所做的數學運算見上圖公式(3),對應的網絡架構見下圖。(確定提局部鄰域特征的運算是關鍵,后續搭建網絡是水到渠成的事情)
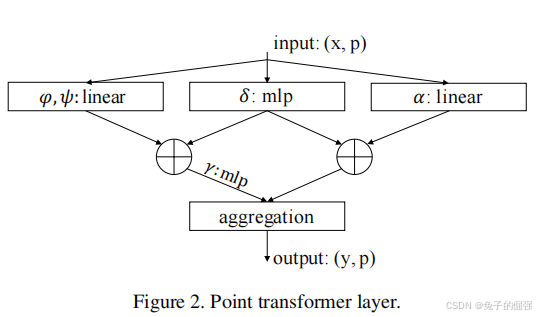
Position Encoding

Network Architecture
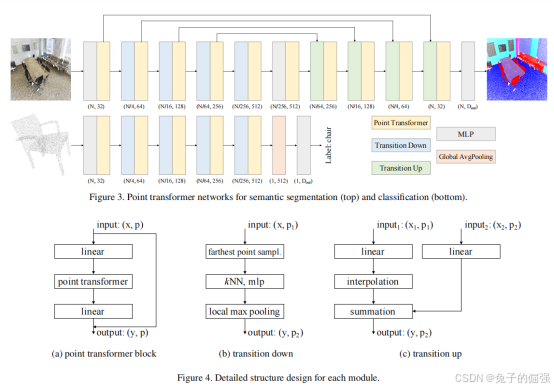
Backbone structure
The feature encoder in point transformer networks for semantic segmentation and classification has five stages that operate on progressively downsampled point sets. The downsampling rates for the stages are [1, 4, 4, 4, 4], thus the cardinality of the point set produced by each stage is [N, N/4, N/16, N/64, N/256], where N is the number of input points.
Transition down
見網絡架構圖
Transition up
見網絡架構圖
Output head
見網絡架構圖
問題及解答
問題1:TransitionDown與PointTransformerLayer都是做局部特征提取的,它倆有什么不同?并且兩個塊之間的數據是怎么流動的?
參考了openpoints庫中的代碼:
class TransitionDown(nn.Module):def __init__(self, in_planes, out_planes, stride=1, nsample=16):super().__init__()self.stride, self.nsample = stride, nsampleif stride != 1:self.linear = nn.Linear(3 + in_planes, out_planes, bias=False)self.pool = nn.MaxPool1d(nsample)else:self.linear = nn.Linear(in_planes, out_planes, bias=False)self.bn = nn.BatchNorm1d(out_planes)self.relu = nn.ReLU(inplace=True)# 如果self.stride != 1會減少點數,通過最大池化獲取每個分組的全局特征。def forward(self, pxo):p, x, o = pxo # (n, 3), (n, c), (b)if self.stride != 1:n_o, count = [o[0].item() // self.stride], o[0].item() // self.stridefor i in range(1, o.shape[0]):count += (o[i].item() - o[i - 1].item()) // self.striden_o.append(count)n_o = torch.cuda.IntTensor(n_o)# print(n_o.device, p.device)idx = pointops.furthestsampling(p, o, n_o) # (m)n_p = p[idx.long(), :] # (m, 3)x = pointops.queryandgroup(self.nsample, p, n_p, x, None, o, n_o, use_xyz=True) # (m, nsample,3+c)x = self.relu(self.bn(self.linear(x).transpose(1, 2).contiguous())) # (m, out_planes, nsample)x = self.pool(x).squeeze(-1) # (m, out_planes)p, o = n_p, n_oelse:x = self.relu(self.bn(self.linear(x))) # (n, out_planes)return [p, x, o]class PointTransformerLayer(nn.Module):def __init__(self, in_planes, out_planes, share_planes=8, nsample=16):super().__init__()self.mid_planes = mid_planes = out_planes // 1self.out_planes = out_planesself.share_planes = share_planesself.nsample = nsampleself.linear_q = nn.Linear(in_planes, mid_planes)self.linear_k = nn.Linear(in_planes, mid_planes)self.linear_v = nn.Linear(in_planes, out_planes)self.linear_p = nn.Sequential(nn.Linear(3, 3), nn.BatchNorm1d(3), nn.ReLU(inplace=True),nn.Linear(3, out_planes))self.linear_w = nn.Sequential(nn.BatchNorm1d(mid_planes), nn.ReLU(inplace=True),nn.Linear(mid_planes, mid_planes // share_planes),nn.BatchNorm1d(mid_planes // share_planes), nn.ReLU(inplace=True),nn.Linear(out_planes // share_planes, out_planes // share_planes))self.softmax = nn.Softmax(dim=1)# 不會減少點數,只是會對每個點,計算其鄰域的self-attentiondef forward(self, pxo) -> torch.Tensor:p, x, o = pxo # (n, 3), (n, c), (b)# 點特征分別經過三個線性層,獲得q,k,vx_q, x_k, x_v = self.linear_q(x), self.linear_k(x), self.linear_v(x) # (n, c)# 查找最近鄰x_k = pointops.queryandgroup(self.nsample, p, p, x_k, None, o, o, use_xyz=True) # (n, nsample, 3+c)x_v = pointops.queryandgroup(self.nsample, p, p, x_v, None, o, o, use_xyz=False) # (n, nsample, c)p_r, x_k = x_k[:, :, 0:3], x_k[:, :, 3:]for i, layer in enumerate(self.linear_p): p_r = layer(p_r.transpose(1, 2).contiguous()).transpose(1,2).contiguous() if i == 1 else layer(p_r) # (n, nsample, c)w = x_k - x_q.unsqueeze(1) + p_r.view(p_r.shape[0], p_r.shape[1], self.out_planes // self.mid_planes,self.mid_planes).sum(2) # (n, nsample, c)for i, layer in enumerate(self.linear_w): w = layer(w.transpose(1, 2).contiguous()).transpose(1,2).contiguous() if i % 3 == 0 else layer(w)w = self.softmax(w) # (n, nsample, c)n, nsample, c = x_v.shapes = self.share_planes# w.unsqueeze(2)廣播機制x = ((x_v + p_r).view(n, nsample, s, c // s) * w.unsqueeze(2)).sum(1).view(n, c) # (n, out_planes)return x
由上述開源代碼可以看出來,TransitionDown是對輸入點集進行最遠點采樣,分組,逐點特征提取以及組內最大池化后輸出各個鄰域的特征。
而PointTransformerLayer是對輸入的點集中的每一個點查找k近鄰,然后對每個鄰域做自注意力,獲得每個點的聚合特征,并不會減少點的數量。(自注意力機制的核心是 “同一組數據內部元素之間的注意力交互”(即查詢、鍵、值均來自同一組輸入)。)




?)


:DMA(直接存儲器訪問))



)

TLS介紹及握手過程詳解)
)




