Apache Hudi是一個開源的數據湖存儲格式和框架,它通過引入類似數據庫的事務機制,解決了傳統數據湖在實時更新、低延遲查詢和增量消費方面的痛點。Hudi最初由Uber于2016年開發并應用于生產環境,2017年開源,2019年成為Apache孵化項目,2021年正式畢業為Apache頂級項目。作為數據湖領域的創新者,Hudi的核心價值在于實現了PB級數據湖上的低延遲ACID事務,使數據湖具備了接近數據庫的實時性 ,同時保持了數據湖的靈活性和成本優勢。
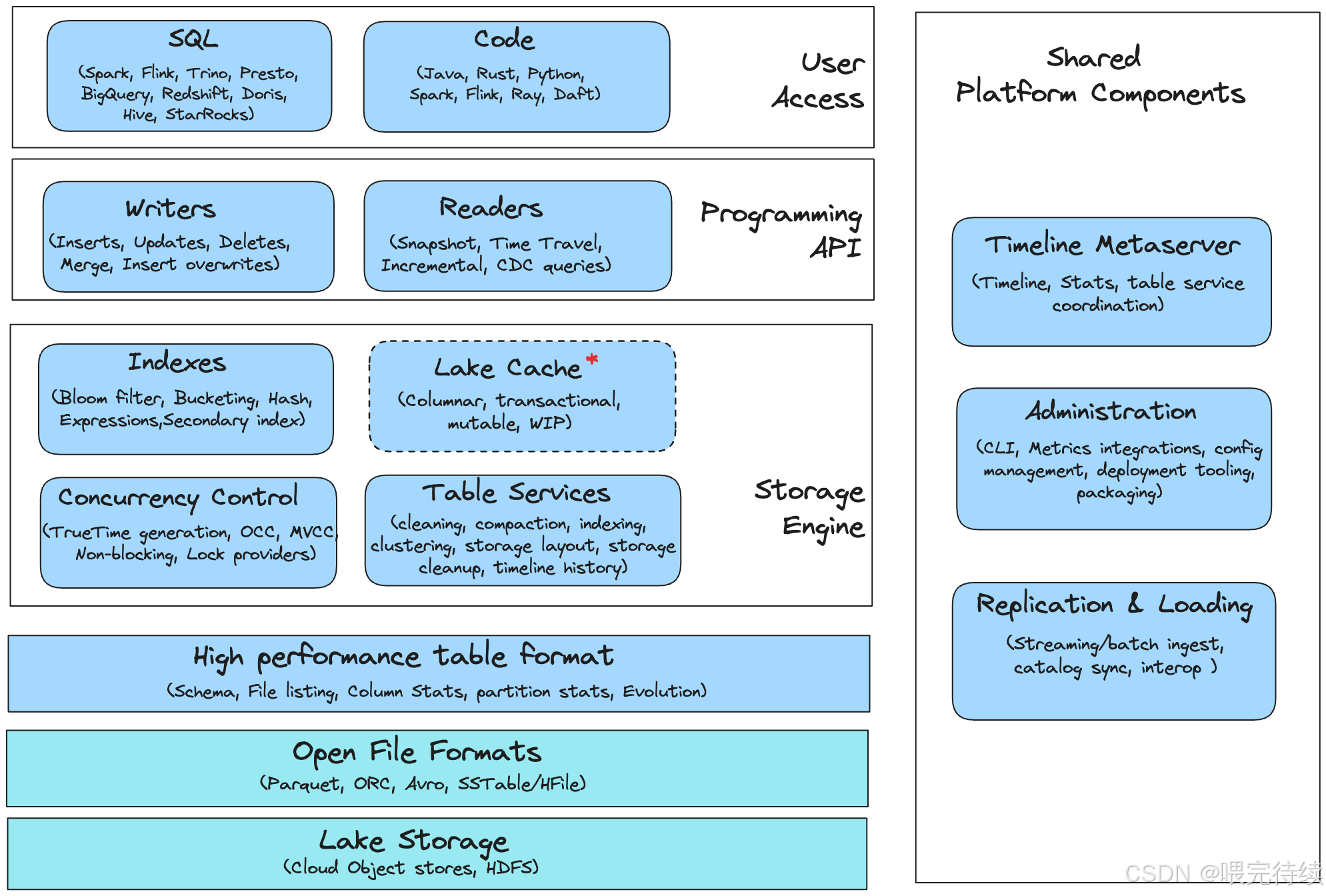
Figure: Apache Hudi Database Architecture
一、Apache Hudi的誕生背景
1.1 傳統數據湖的局限性
在大數據領域,數據湖(Data Lake)作為一種存儲原始數據的低成本解決方案,得到了廣泛應用。然而,傳統數據湖(如HDFS+Parquet)存在幾個關鍵缺陷:
- 僅支持追加操作:傳統數據湖無法高效支持記錄級別的更新、刪除操作,每次更新都需要全量覆蓋,導致存儲膨脹和性能下降 。
- 缺乏版本控制:數據更新后無法回滾,難以支持復雜的數據治理和合規要求 。
- 高延遲查詢:數據更新后需要等待批處理作業完成,才能獲得最新視圖,無法滿足近實時分析需求 。
- 增量消費困難:下游系統需要重新處理全量數據才能獲取變更,導致資源浪費和處理延遲?。
這些問題在Uber等處理海量實時數據的企業中尤為突出。Uber每天處理數百TB的行程、乘客和司機數據,傳統的批處理方式無法滿足其對低延遲數據分析的需求。
1.2 Hudi的誕生歷程
為解決上述問題,Uber于2016年8月開發了Hudi(Hadoop Updates and Incrementals的縮寫),并在生產環境中部署 。Hudi最初被稱為"Hoodie",在2017年開源,并于2019年捐贈給Apache軟件基金會,2021年4月左右畢業成為Apache頂級項目 。
Hudi的誕生背景與Uber的業務需求緊密相關。在當時,Uber面臨的主要挑戰包括:
- 實時數據更新:需要支持海量數據的實時更新,如行程狀態變更、乘客信息更新等 。
- 低延遲查詢:業務決策需要基于最新數據,無法接受小時級或天級的延遲 。
- 增量消費:下游系統需要高效獲取數據變更,而不是重新處理全量數據 。
- 數據治理:需要支持數據版本控制、回滾和審計等功能 。
Hudi通過引入類似數據庫的事務機制和文件組織方式,成功解決了這些問題,成為Uber數據湖的核心組件。
二、Hudi的核心架構設計
2.1 三層架構模型
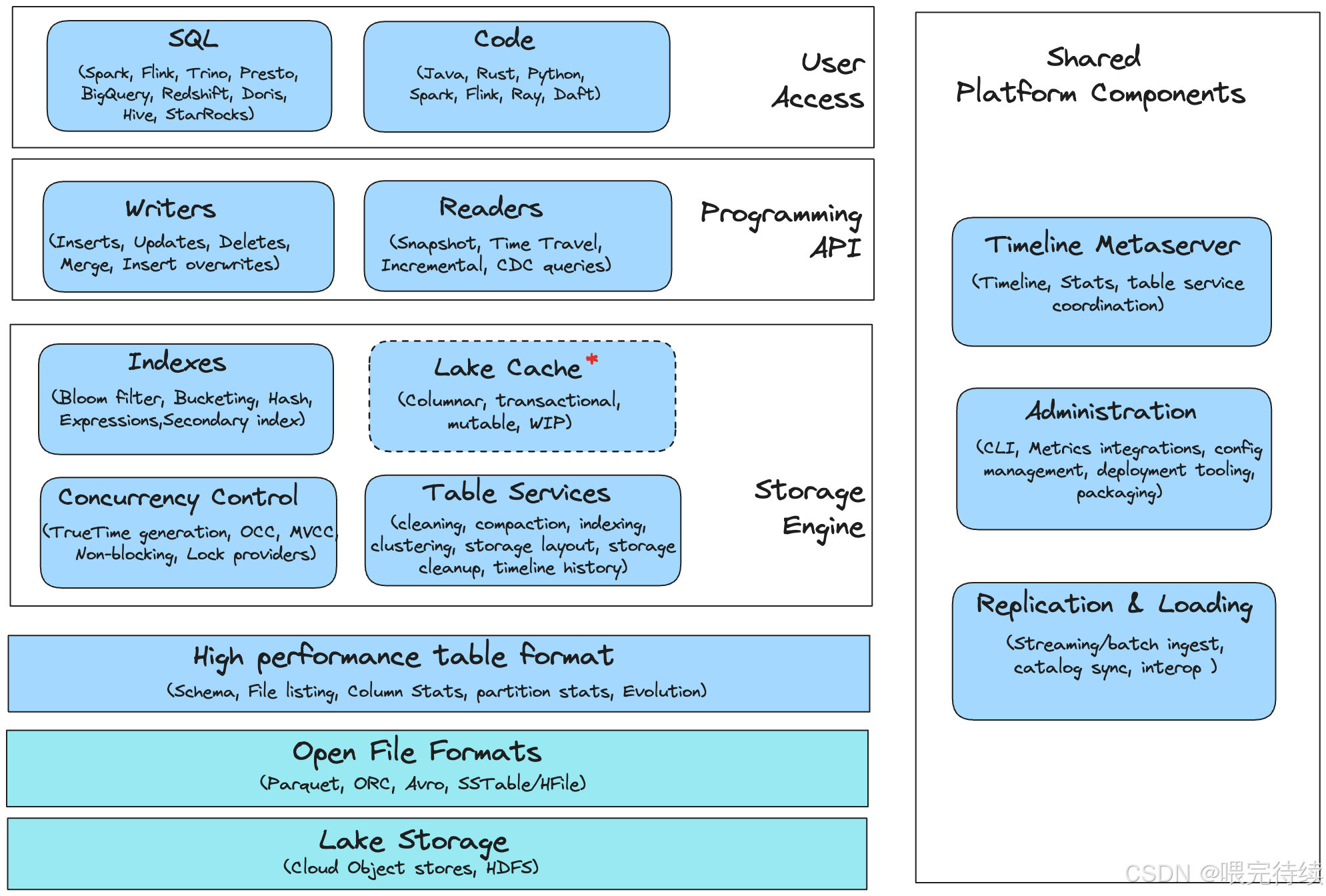
Apache Hudi采用分層架構設計,分為事務數據庫層、編程API層和用戶接口層:
- 事務數據庫層:這是Hudi的核心,包含表格式(存儲布局)、表服務(文件優化)、索引(加速讀寫)、并發控制(確保數據一致性)、湖緩存(提升讀取效率)和元服務器(集中元數據訪問)等組件 。
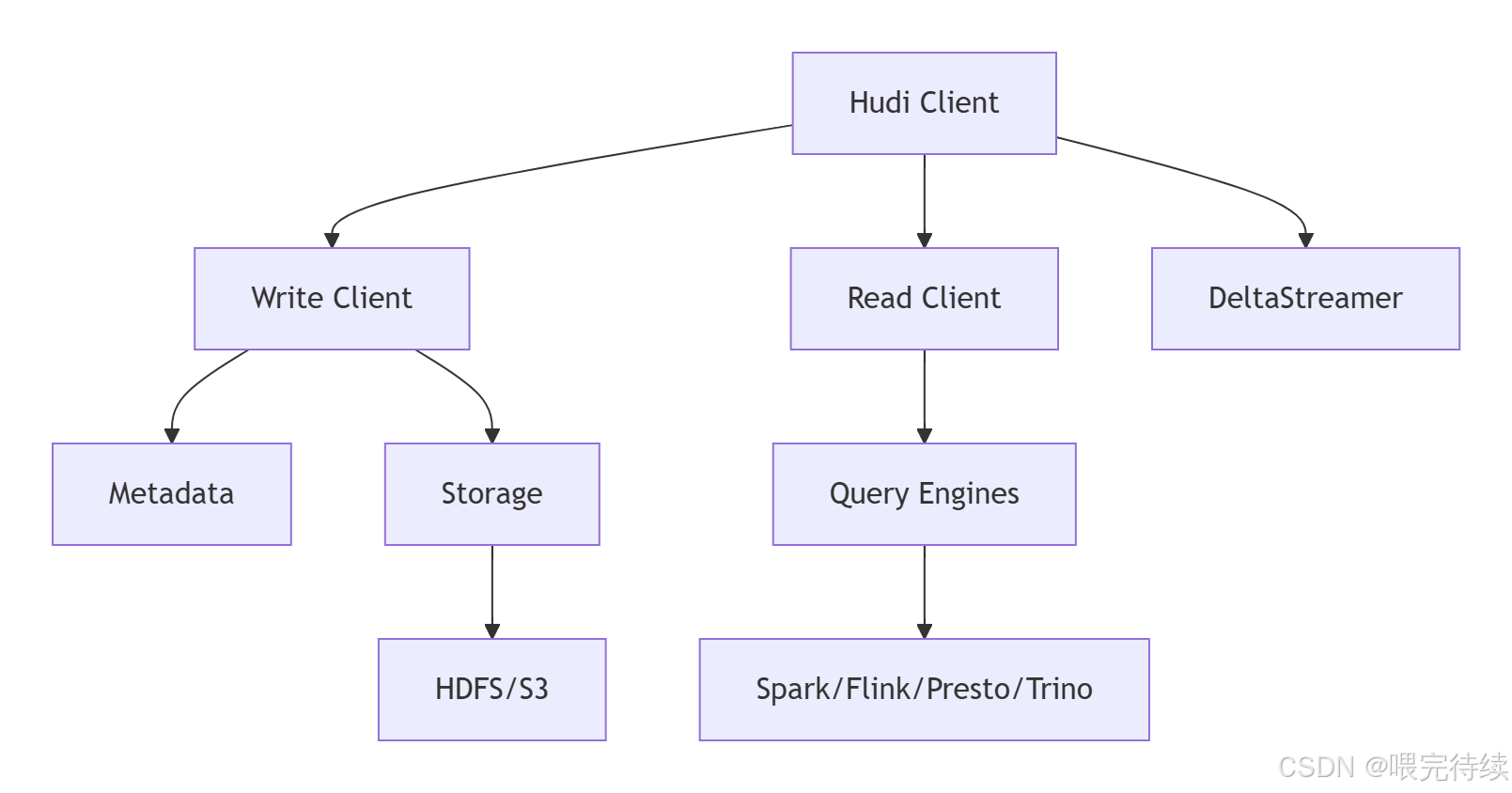
- 編程API層:提供標準化的寫入器和讀取器接口,使Hudi能夠與各種計算引擎(如Spark、Flink)集成,同時支持高效的更新插入和增量處理?。
- 用戶接口層:提供高級別工具,包括攝取實用程序(如DeltaStreamer)、目錄同步工具和管理CLI等平臺服務,以及與Spark、Hive、Presto等查詢引擎的集成 。
這種分層設計使Hudi既具備了數據庫的事務能力和實時性,又保持了數據湖的靈活性和可擴展性。
2.2 存儲類型與文件組織
Hudi支持兩種主要的存儲類型,針對不同的使用場景優化:
寫時復制(Copy On Write, COW):所有數據都存儲在列式文件(如Parquet)中,每次更新都會生成新版本的文件。COW表的寫入成本較高(需要重寫整個文件),但讀取性能最佳,適合讀取密集型分析工作。
讀時合并(Merge On Read, MOR):數據分為基線文件(列式Parquet)和增量日志(行式Avro)兩部分存儲。MOR表的寫入成本較低(只需追加日志),但讀取性能略差(需要合并基線和日志),適合寫入密集型場景和需要低延遲查詢的應用。
Hudi的數據組織遵循以下層級結構:
- 基本路徑(Base Path):數據集的根目錄,所有數據和元數據都存儲在此路徑下 。
- 分區(Partition):數據按分區鍵(如時間戳)組織到不同的子目錄中,類似于Hive表的分區機制 。
- 文件組(File Group):由文件ID唯一標識的邏輯單元,包含一組記錄的所有版本。
- 文件切片(File Slice):每個文件組包含多個文件切片,每個切片包含一個基線文件(.parquet)和一組增量日志(.log.*)。
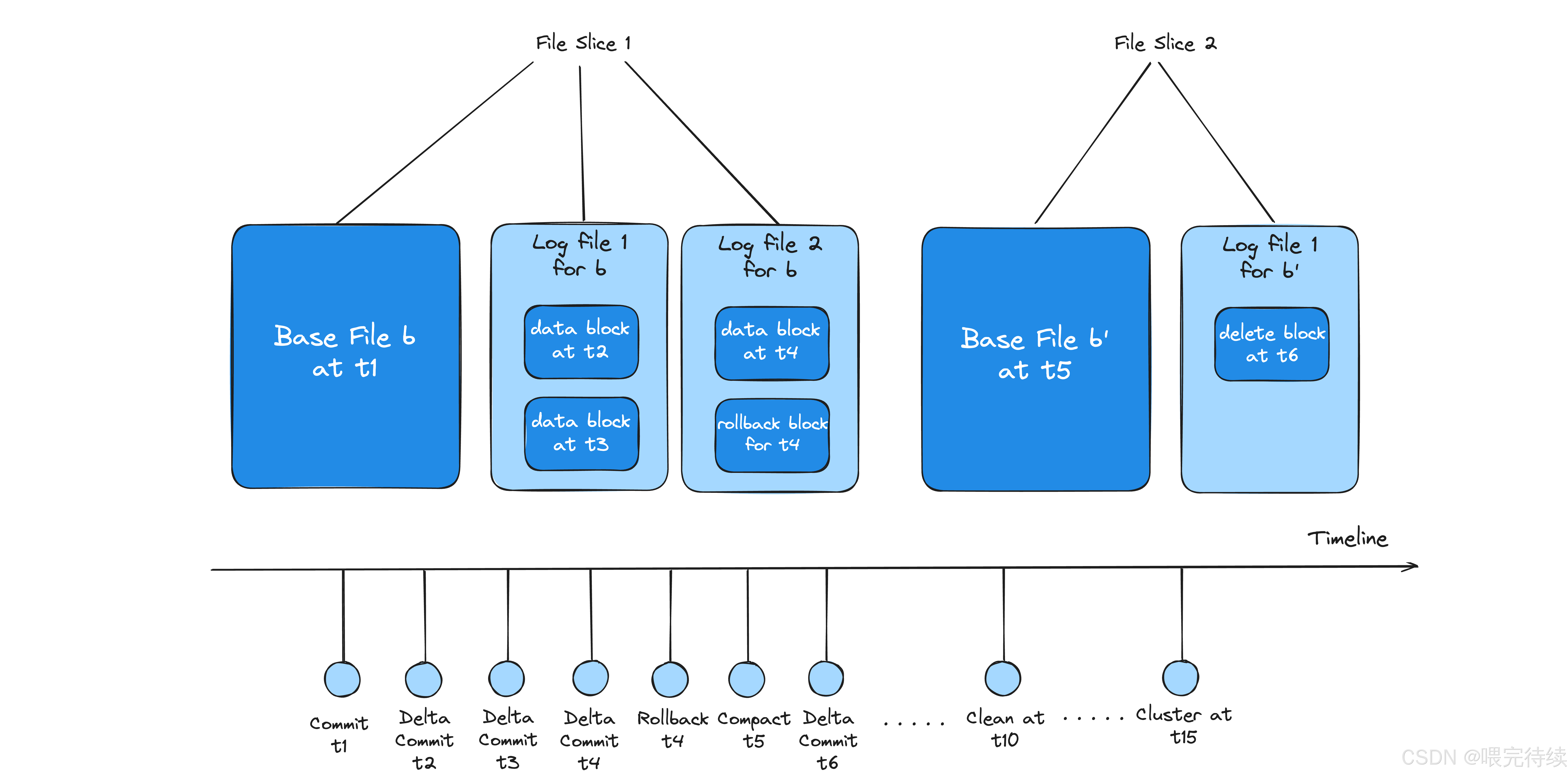
這種組織方式使Hudi能夠高效管理海量數據,并支持記錄級別的更新操作。
2.3 時間軸與版本控制
Hudi的核心創新之一是引入了時間軸(Timeline)機制,用于跟蹤表的歷史變化:
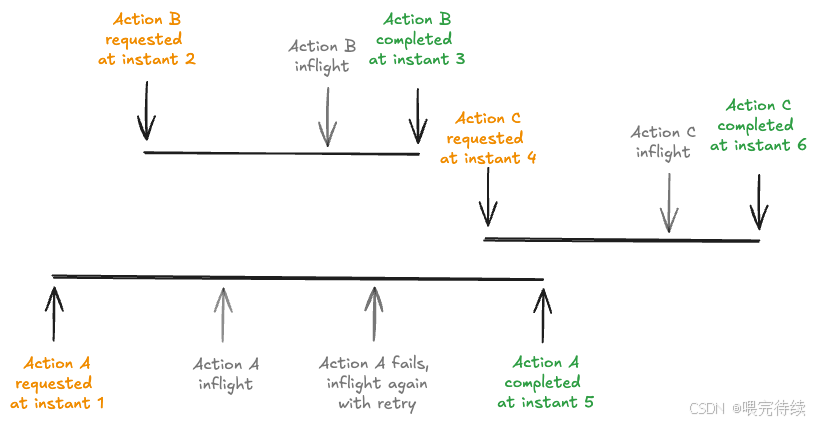
- 時間軸結構:Hudi 1.0版本引入了LSM(Log-Structured Merge)樹時間線,采用分層結構(L0活動層、L1-Ln優化層)管理歷史操作,支持百萬級歷史記錄管理 。
- 操作類型:包括COMMITS(提交)、CLEANS(清理)、DELTA_COMMIT(增量提交)、COMPACTION(壓縮)、ROLLBACK(回滾)和SAVEPOINT(保存點)等 。
- 時間戳管理:Hudi采用TrueTime語義確保所有操作的時間戳單調遞增和全局有序,解決時鐘偏斜問題 。
時間軸機制使Hudi能夠提供三種視圖:
- 快照視圖(Snapshot View):提供表的最新狀態,所有已完成操作的數據?。
- 讀優化視圖(Read Optimized View):僅包含基線文件,優化查詢性能?。
- 增量視圖(Incremental View):提供指定時間點后的增量數據,支持高效消費變更 。
這種設計使Hudi能夠同時滿足實時更新和高效查詢的需求。
三、Hudi解決的關鍵問題
3.1 數據更新問題
傳統數據湖僅支持追加操作,無法高效支持記錄級別的更新、刪除操作。Hudi通過COW/MOR表結構實現了記錄級的IUD(插入、更新、刪除)操作:
- COW表:通過重寫文件保證更新一致性,適合讀取密集型場景。
- MOR表:通過日志追加降低寫入開銷,適合寫入密集型場景 。
Hudi的索引機制(如BloomFilter、HBase索引)將hoodie鍵(記錄鍵+分區路徑)映射到文件組,確保更新操作能夠快速定位到目標文件。這種設計使Hudi能夠處理PB級數據湖的實時更新,而無需全量覆蓋。
3.2 延遲處理問題
在流處理場景中,數據通常存在延遲到達的情況。Hudi通過事件時間(Event Time)與提交時間(Arrival Time)分離的機制,支持亂序數據處理:
- 事件時間:數據中記錄的時間,表示事件實際發生的時間。
- 提交時間:數據到達Hudi的時間,表示數據被寫入的時間。
這種分離使Hudi能夠將延遲數據歸入正確的事件時間分區,而不是提交時間分區。例如,一個9:00事件的數據在10:20到達,Hudi仍會將其寫入9:00的分區,而不是10:20的分區。這使得下游系統能夠基于事件時間進行一致的分析,而無需擔心數據延遲。
3.3 增量消費問題
傳統數據湖的增量消費通常依賴文件夾/分區的創建時間,這在處理延遲數據時效率低下。Hudi通過時間軸機制提供了高效的增量消費能力:
- 增量視圖:下游系統可以基于提交時間戳獲取增量數據,無需掃描全量數據。
- 增量查詢:通過時間軸的元數據,Hudi能夠快速定位哪些文件切片包含新數據,只消費這些文件。
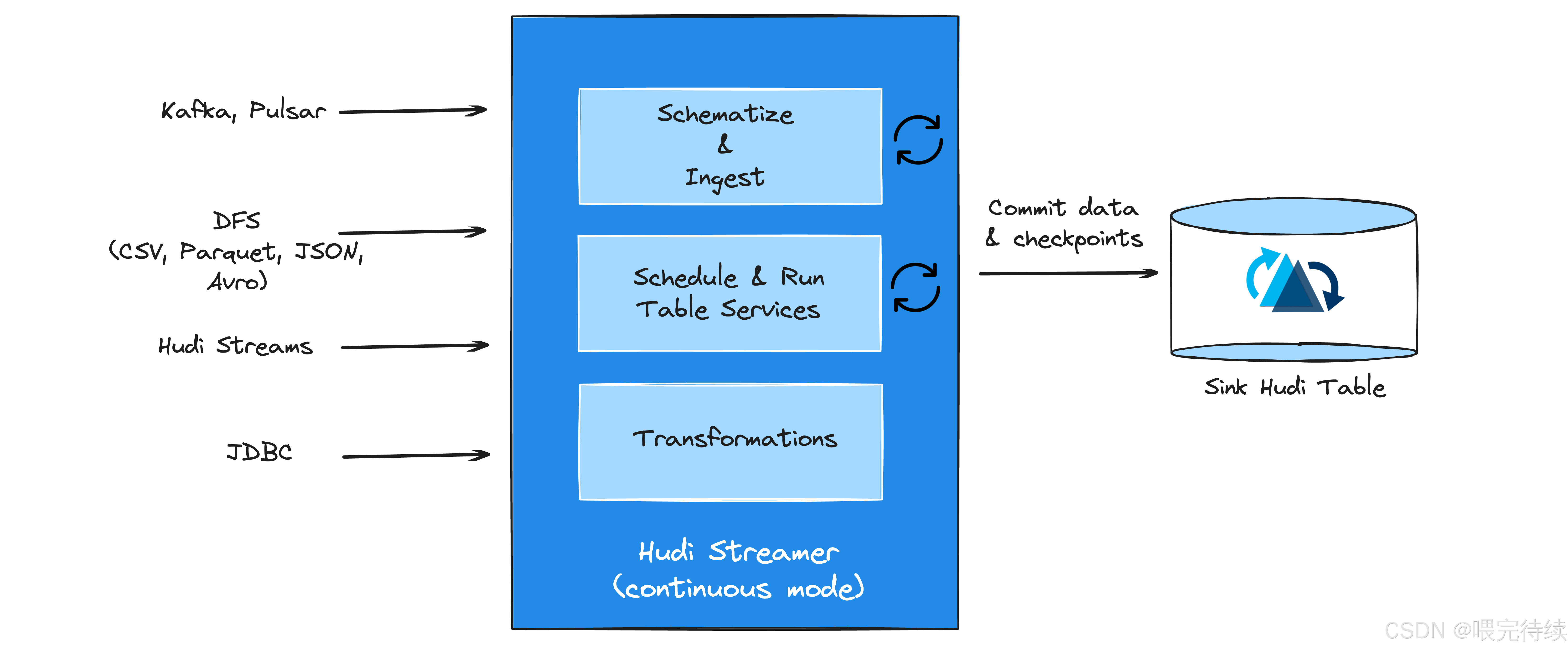
- 增量管道:Hudi支持構建高效的增量ETL管道,每小時處理TB級數據,端到端延遲僅30分鐘。
這種能力在構建實時數據管道、機器學習特征工程和數據分發等場景中尤為重要,能夠顯著降低計算資源消耗和處理延遲。
四、Hudi的核心特性
4.1 ACID事務支持
Hudi提供了類似數據庫的ACID事務能力,確保數據更新的原子性、一致性、隔離性和持久性 :
- 原子性(Atomicity):通過時間軸的atomic commit機制實現,提交前生成臨時文件,成功后原子替換 。
- 一致性(Consistency):保證數據更新符合業務規則,如主鍵唯一性等 。
- 隔離性(Isolation):通過快照隔離(Snapshot Isolation)確保并發事務互不干擾,讀取器始終基于提交時間戳訪問已完成的文件版本?。
- 持久性(Durability):確保已提交的數據即使在系統故障后也能恢復 。
Hudi的ACID事務支持使其能夠處理關鍵業務場景,如GDPR數據刪除、金融交易記錄更新等,確保數據的準確性和可靠性。
4.2 MVCC與并發控制
Hudi采用多版本并發控制(MVCC)和非阻塞并發控制(NBCC)機制,實現高并發寫入和低延遲查詢:
- MVCC機制:基于時間軸的瞬時(Instant)生成Read View,事務開始時創建快照,后續查詢僅訪問該快照時間點前的已完成版本?。
- NBCC機制:允許多個寫入器并行追加日志文件(MOR表),沖突在壓縮階段解決,通過記錄提交開始和完成時間戳實現日志排序?。
- OCC機制:用于COW表,寫入前檢查版本,沖突時重試 。
這些機制使Hudi能夠在處理大量并發寫入的同時,保持低延遲的查詢性能,滿足實時分析的需求。
4.3 文件組織與LSM樹時間線
Hudi 1.0版本引入了LSM樹時間線,優化了元數據管理和歷史版本控制:
- 分層結構:元數據文件按對數結構合并(LSM)樹布局組織成層(L0、L1、L2等),每層文件按時間戳排序,命名遵循{min_instant}_{max_instant}_${level}.parquet格式?。
- 壓縮策略:活動層(L0)的事務日志(Avro格式)在達到閾值后被合并到優化層(L1),進一步減少存儲開銷和查詢延遲? 。
- 清單文件:跟蹤同一層中可能重疊時間范圍的文件,提高元數據查詢效率? 。
LSM樹時間線使Hudi能夠有效管理海量歷史版本,支持長時間窗口的增量查詢,而不會因文件列表膨脹導致性能下降。
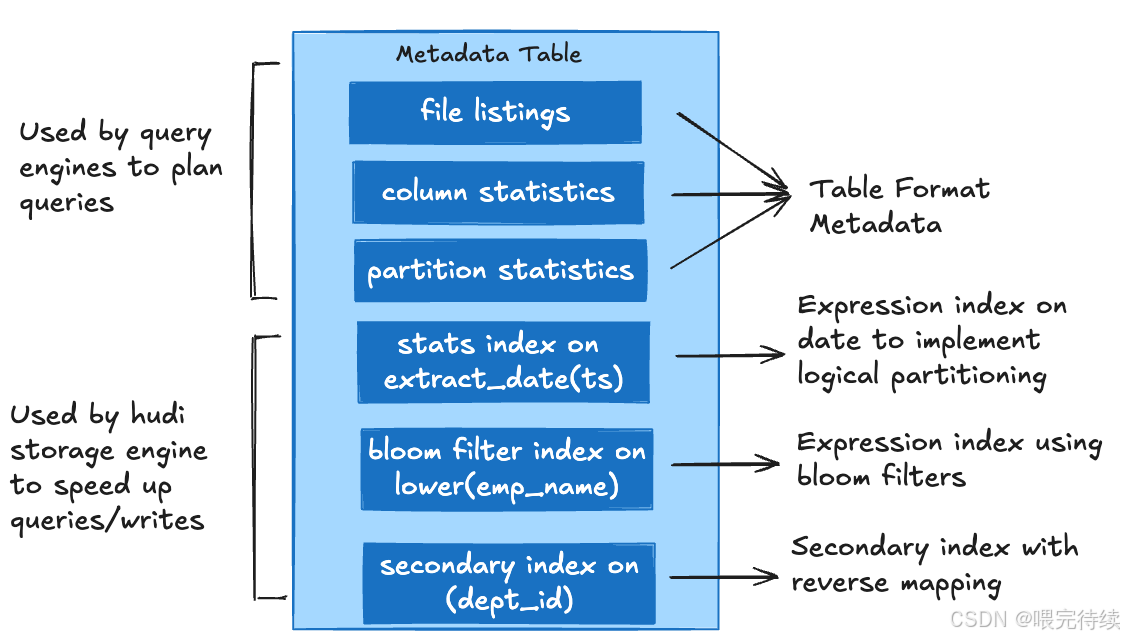
4.4 索引機制
Hudi支持多種索引機制,加速記錄的定位和查找:
- BloomFilter索引:為每個文件切片生成布隆過濾器,快速判斷記錄是否存在,減少文件掃描范圍?。
- HBase索引:利用HBase的O(1)查詢能力,實現高效記錄定位。
- Elasticsearch索引:支持全文搜索和復雜查詢,適合非結構化數據場景。
這些索引機制使Hudi能夠處理PB級數據的高效查詢,而無需依賴外部數據庫或搜索引擎。
4.5 增量查詢與消費
Hudi的時間軸機制使其能夠提供高效的增量查詢和消費能力:
- 增量視圖:下游系統可以基于提交時間戳獲取增量數據,無需掃描全量數據?。
- 增量拉取:通過時間軸的元數據,Hudi能夠快速定位哪些文件切片包含新數據,只消費這些文件?。
- 增量處理:支持構建增量ETL管道,每小時處理TB級數據,端到端延遲僅30分鐘?。
這種能力在構建實時數據管道、機器學習特征工程和數據分發等場景中尤為重要,能夠顯著降低計算資源消耗和處理延遲。
五、Hudi與同類產品的技術對比
5.1 Hudi vs Delta Lake
| 特性 | Hudi | Delta Lake | 適用場景 |
|---|---|---|---|
| 存儲類型 | 支持COW和MOR | 僅支持COW | Hudi適合實時更新和低延遲查詢;Delta Lake適合Spark生態內的流批一體 |
| 增量消費 | 時間軸機制,支持事件時間與提交時間分離 | 事務日志,按提交時間戳消費 | Hudi支持延遲數據歸入正確事件時間分區;Delta Lake需重新處理全量數據 |
| 索引機制 | 支持多種索引(BloomFilter、HBase等) | 僅支持簡單的分區索引 | Hudi提供高效的記錄定位能力;Delta Lake依賴分區優化查詢 |
| 并發控制 | COW表使用OCC,MOR表使用NBCC | 僅支持OCC | Hudi的MOR表支持更高的寫入吞吐量;Delta Lake在沖突時需重試 |
| 生態集成 | 原生支持Flink,與Spark、Hive等兼容 | 深度集成Spark,對其他引擎支持較弱 | Hudi適合多引擎環境;Delta Lake適合Spark主導的生態系統 |
Hudi在實時更新和低延遲查詢方面具有優勢,而Delta Lake在批處理性能和Spark生態集成方面表現更好。例如,在處理每小時TB級數據的增量管道時,Hudi可以提供端到端30分鐘的延遲,而Delta Lake可能需要更長時間。
5.2 Hudi vs Iceberg
| 特性 | Hudi | Iceberg | 適用場景 |
|---|---|---|---|
| 存儲類型 | 支持COW和MOR | 僅支持COW | Hudi適合實時更新;Iceberg適合大規模元數據管理 |
| 文件管理 | LSM樹時間線,動態壓縮日志文件 | 清單文件(Manifest)管理,無內置壓縮機制 | Hudi優化存儲效率;Iceberg提供文件級元數據統計 |
| 版本控制 | 時間軸記錄所有操作,支持按時間戳回滾 | 快照(Snapshot)基于清單文件生成,支持時間旅行 | Hudi提供更細粒度的版本控制;Iceberg適合EB級數據的元數據管理 |
| 并發控制 | COW表使用OCC,MOR表使用NBCC | 基于OCC,依賴外部工具實現沖突檢測 | Hudi的MOR表支持更高的寫入吞吐量;Iceberg在元數據管理上更高效 |
| 生態集成 | 原生支持Flink,與Spark、Hive等兼容 | 兼容多引擎(Spark、Flink、Trino),但需額外適配 | Hudi適合實時流處理;Iceberg適合多引擎聯邦查詢 |
Hudi在實時更新和增量消費方面表現更佳,而Iceberg在元數據管理和大規模數據集查詢方面更具優勢。例如,在處理高吞吐量的實時數據流時,Hudi的MOR表能夠提供更好的性能,而Iceberg更適合需要復雜查詢優化的場景。
??選型建議??:
需要最強UPSERT性能 → ??Hudi??
已深度使用Spark且需求簡單 → ??Delta Lake??
追求最大兼容性和標準性 → ??Iceberg?
六、Hudi的使用方法與最佳實踐
6.1 環境準備
要使用Hudi,需要確保以下環境已就緒:
- 存儲系統:HDFS、S3或其他Hadoop兼容文件系統。
- 計算引擎:Spark 2.4.4+版本(Hudi主要依賴Spark的計算能力)。
- 查詢引擎:Hive、Presto、Hudi Native等。
在Spark中配置Hudi的依賴和參數:
// 添加Hudi依賴
val hudiSpark = spark.config("spark.sql.catalog.spark_catalog","org.apache.spark.sql.hudi catalog.HoodieCatalog"
).config("spark.serializer","org.apache.spark.serializer.KryoSerializer"
).config("spark.sql extensions","org.apache.spark.sql.hudi.HoodieSparkSessionExtension"
)6.2 創建Hudi表
Hudi表的創建與普通Spark表類似,但需要指定存儲類型和主鍵:
// 創建COW表
spark.sql("""CREATE TABLE cow_table (id INT, name STRING, price DOUBLE)USINGHUDITBLPROPERTIES (hoodie table type='cow',hoodiehoodie key='id',hoodiehoodie index type='bloom')"""
)// 創建MOR表
spark.sql("""CREATE TABLE mor_table (id INT, name STRING, price DOUBLE)USINGHUDITBLPROPERTIES (hoodie table type='mor',hoodiehoodie key='id',hoodiehoodie index type='bloom',hoodiehoodie compaction strategy='inplace')"""
)6.3 寫入數據
Hudi支持多種寫入方式,包括插入、更新、刪除和合并:
// 插入數據
val df = spark.createDataFrame(data, schema)
df.write.format("HUDI").option("hoodie.insert.update.key", "id").save("basepath/cow_table")// 更新數據
df.write.format("HUDI").option("hoodie.insert.update.key", "id").option("hoodie操作類型", "upsert").save("basepath/mor_table")// 刪除數據
df.write.format("HUDI").option("hoodie.insert.update.key", "id").option("hoodie操作類型", "delete").save("basepath/cow_table")6.4 查詢數據
Hudi支持三種視圖,根據查詢需求選擇合適的視圖:
// 查詢快照視圖(最新狀態)
val snapDF = spark.read.format("HUDI").load("basepath/cow_table")// 查詢讀優化視圖(優化查詢性能)
val roDF = spark.read.format("HUDI").option("hoodie.read.optimize", "true").load("basepath/mor_table")// 查詢增量視圖(獲取指定時間點后的增量數據)
val incDF = spark.read.format("HUDI").option("hoodie.read增量", "true").option("hoodie開始時間", "20250815000000").load("basepath/cow_table")6.5 表服務與優化
Hudi提供了多種表服務操作,用于優化表性能:
// 壓縮操作(合并日志文件到基線文件)
spark.sql("CALLHUDI.執行壓縮('basepath/mor_table')")// 清理操作(刪除舊版本文件)
spark.sql("CALLHUDI.執行清理('basepath/cow_table')")// 保存點操作(標記某些文件組為已保存,防止被清理)
spark.sql("CALLHUDI.創建保存點('basepath/cow_table', '20250815000000')")6.6 實時流處理集成
Hudi與Flink集成,支持實時流處理:
Map<String, String> options = new HashMap<>();
options.put("connector", "hudi");
options.put("path", "hdfs://path/to/table");
options.put("table.type", "MERGE_ON_READ");DataStream<RowData> source = HoodiePipeline.builder("my_table").column("id STRING").column("name STRING").pk("id").options(options).source(env);HoodiePipeline.builder("my_table").options(options).sink(source, false);6.7 讀取優化查詢
僅適用于 Merge-On-Read 表
// 讀優化查詢
val readOptimizedDF = spark.read.format("org.apache.hudi").option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_READ_OPTIMIZED_OPT_VAL).load("/user/hudi/" + tableName + "/*")readOptimizedDF.show()6.8?數據刪除
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConverters._// 定義要刪除的記錄主鍵
val deleteIds = Seq(3).toList.asJava// 執行刪除操作
spark.write.format("org.apache.hudi").option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL).option(HoodieWriteConfig.TABLE_NAME, tableName).option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, primaryKey).option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, partitionColumn).option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.DELETE_OPERATION_OPT_VAL).mode(SaveMode.Append).save("/user/hudi/" + tableName)七、未來展望:Hudi的發展路線
??Z-Order優化??:更高效的多維數據布局
??更強大的流式能力??:降低端到端延遲
??跨云統一??:優化不同存儲后端的性能
??AI集成??:直接支持機器學習工作流
結語:為什么開發者應該選擇Hudi?
在數據架構從傳統數據倉庫向Lakehouse演進的今天,Apache Hudi提供了??唯一兼具數據庫靈活性和數據湖擴展性??的解決方案。其??增量處理能力??特別適合現代實時分析需求,而??ACID保證??則解決了數據一致性的老大難問題。
"掌握Hudi,意味著你能夠在云原生時代構建真正彈性的數據基礎設施"

)








排序算法——非比較排序(計數排序·動圖演示)、排序算法總結)

程序安裝+數據庫初始+前端配置+服務啟動+Web登錄)

安全管理(3)-數據庫審計)
—— 數組(超絕詳細總結))

通訊--http多文件下載)

