來gongzhonghao【圖靈學術計算機論文輔導】,快速拿捏更多計算機SCI/CCF發文資訊~
在Cvpr、NeurIPS、AAAI等頂會中,遷移學習+多模態特征融合正以“降成本、提性能、省標注”的絕對優勢成為最熱賽道。
面對超大模型全量微調天價算力、異構模態對齊難、跨域數據稀缺三大痛點,前沿工作正把“參數即知識”的理念玩到極致,誰能率先解鎖跨架構、跨任務、跨模態的統一遷移框架,誰就能在下一輪頂會審稿中秒拿高分。
本文精心整理了?3 篇前沿論文,旨在助力大家洞悉前沿動態、把握研究思路。滿滿干貨,點贊收藏不迷路~
Multimodal Representation Learning by Alternating Unimodal Adaptation
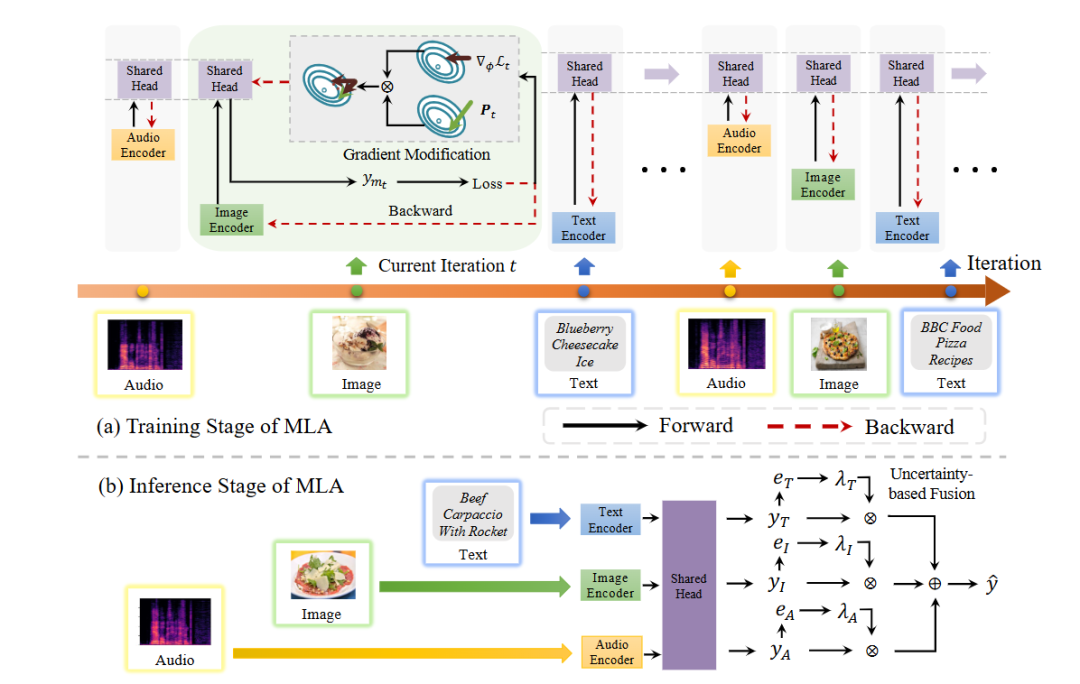
方法:這篇文章針對多模態學習中“某些模態主導、其余被忽視”的頑疾,提出 MLA 框架,把傳統聯合訓練拆成“各模態輪流獨立優化”的交替單模態學習;在共享頭里用梯度正交化機制防止新模態覆蓋舊模態知識;推理階段再用不確定性加權融合各模態預測,從而兼顧信息平衡與跨模態交互。
創新點:
提出交替單模態學習范式,徹底解除模態間梯度干擾;
設計梯度正交化矩陣,解決共享頭在多輪更新中的跨模態遺忘;
構建基于預測不確定性的測試時動態融合,自動權衡缺失或弱模態貢獻。
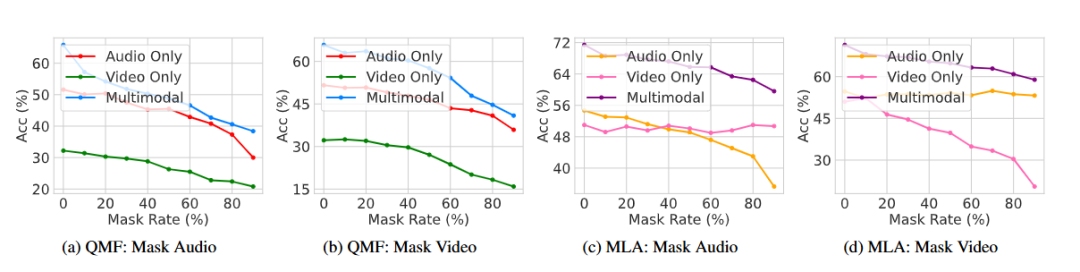
總結:作者將聯合訓練拆為輪詢式單模態優化,借助正交梯度鎖定共享頭記憶,再以不確定性權重整合推理輸出,在五個數據集上顯著抑制模態懶惰并刷新完整與缺失模態場景的 SOTA。
MergeNet: Knowledge Migration across Heterogeneous Models, Tasks, and?Modalities
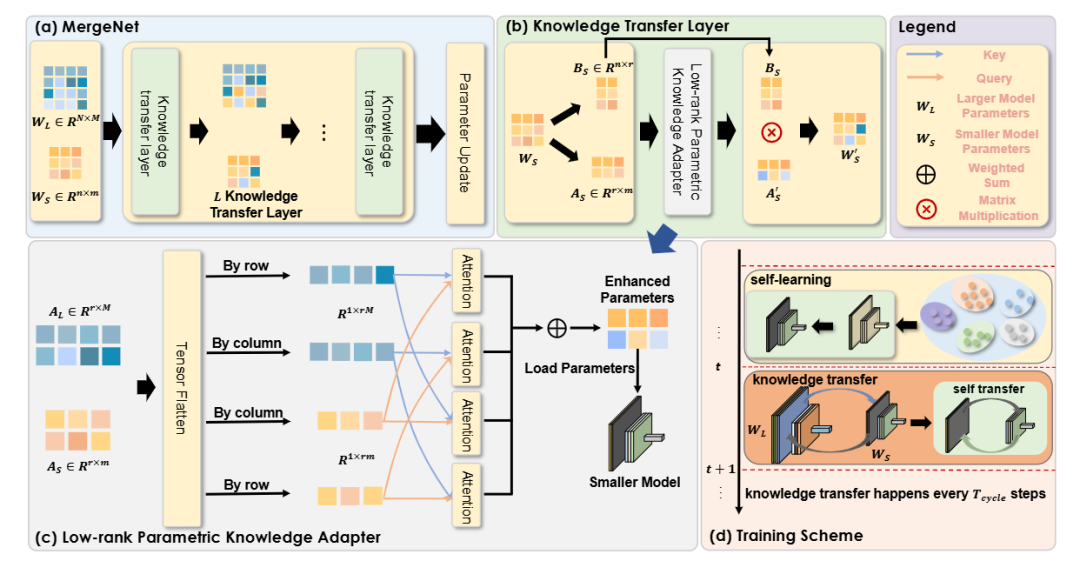
方法:這篇文章打破傳統知識蒸餾與共享骨干的局限,提出MergeNet,通過低秩參數重編碼與參數適配器在異構模型、任務、模態之間直接遷移知識,并在訓練中以周期交替的知識遷移與自學習階段動態整合源模型參數信息。
創新點:
首次將模型參數視為通用知識載體,實現跨架構、跨任務、跨模態的無縫遷移;
引入低秩參數知識適配器LPKA,通過可學習的行/列注意力融合源與目標模型參數,避免直接覆蓋造成知識沖突;
設計周期性知識遷移與自學習交替的訓練機制,使目標模型按需提取源模型知識并自我鞏固。
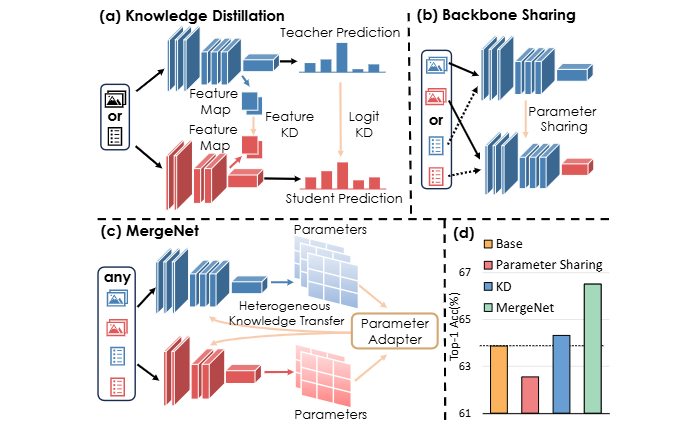
總結:作者先用低秩分解把異構模型參數壓縮成可交互的低秩矩陣,再用LPKA在行/列維度以注意力方式融合雙方知識,生成兼具源模型經驗與目標模型結構的混合參數;訓練時按固定周期插入知識遷移步驟,其余時間保留自學習更新,確保遷移既及時又不過度干擾;測試階段移除參數適配器,實現零額外開銷的推理,在跨結構、跨模態、跨任務三類挑戰性場景上均顯著優于現有方法。
糾結選題?導師放養?投稿被拒?對論文有任何問題的同學,歡迎來gongzhonghao【圖靈學術計算機論文輔導】,獲取頂會頂刊前沿資訊~
BIG-FUSION: Brain-Inspired Global-Local Context Fusion Framework for Multimodal Emotion Recognition in Conversations
方法:這篇文章針對對話多模態情感識別中全局主題與局部說話者依賴難以并行建模且相互干擾的頑疾,提出腦啟發的BIG-FUSION框架,用雙注意力Transformer同時捕獲全局上下文與滑動窗局部信息,并在圖對比學習中引入全局-局部雙重節點重要性評估,再以脈沖神經元動態增強跨模態交互,實現生物可信的情感識別。
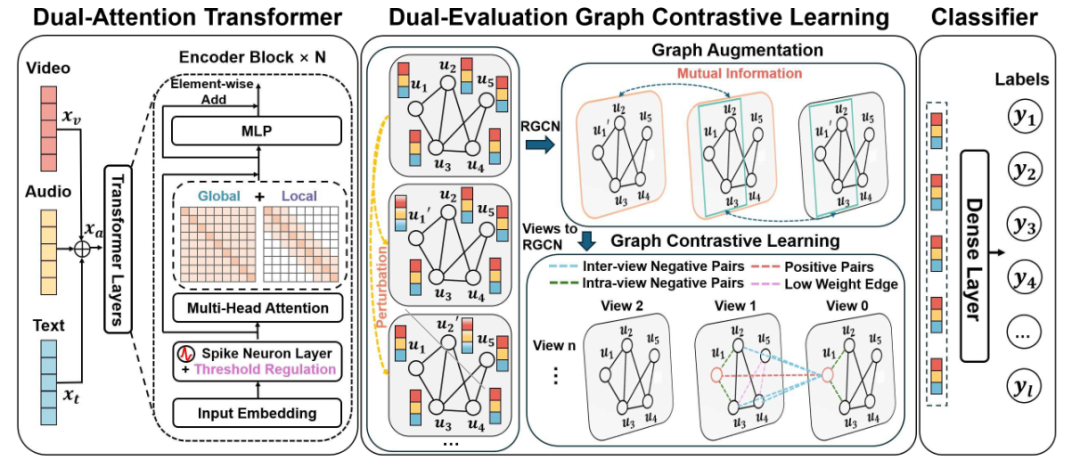
創新點:
首次設計雙注意力Transformer并行提取全局與局部上下文,避免序列式偏差;
提出全局-局部雙重評估的圖增強策略,保留關鍵節點語義;
將脈沖神經元動力學嵌入注意力機制,提升多模態整合與生物可解釋性。
總結:作者先用雙注意力Transformer并行輸出全局與局部表征,經脈沖編碼強化跨模態交互后初始化圖節點;再用基于互信息的全局-局部雙重指標評估節點重要性以生成增強視圖,通過圖對比學習精煉表征;最后融合分類損失與對比損失聯合訓練,在兩個基準對話數據集上顯著超越現有方法。
關注gongzhonghao【圖靈學術計算機論文輔導】,快速拿捏更多計算機SCI/CCF發文資訊~

排序算法——非比較排序(計數排序·動圖演示)、排序算法總結)

程序安裝+數據庫初始+前端配置+服務啟動+Web登錄)

安全管理(3)-數據庫審計)
—— 數組(超絕詳細總結))

通訊--http多文件下載)









)
