魔塔社區
魔塔社區平臺介紹
https://www.modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct
申請免費的試用機器
如果自己沒有機器 ,從這里申請機器 。
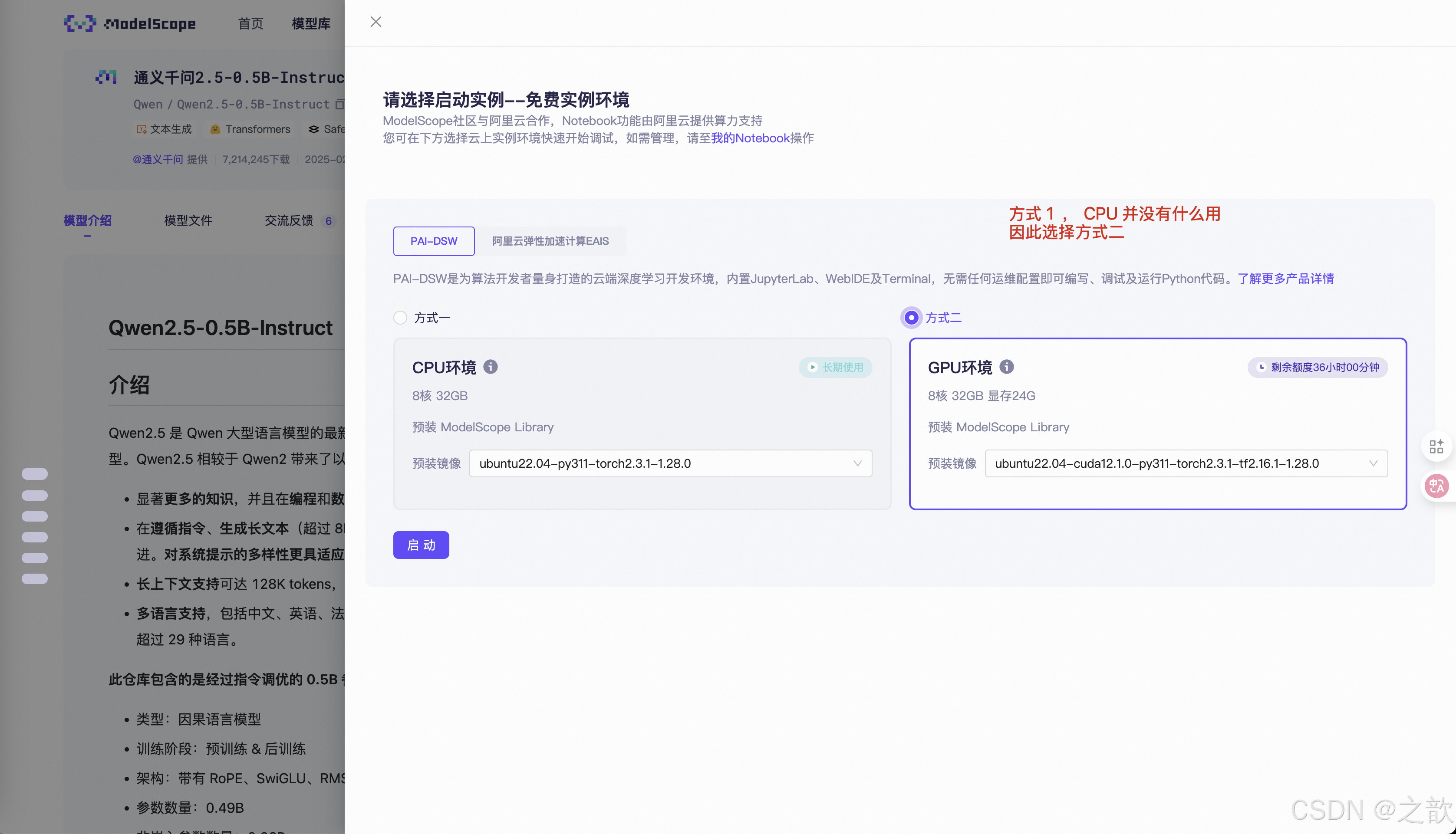
下載大模型
pip install modelscope
下載到當前目錄
mkdir -p /root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct
cd /root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct
modelscope download --model Qwen/Qwen2.5-0.5B-Instruct --local_dir ./
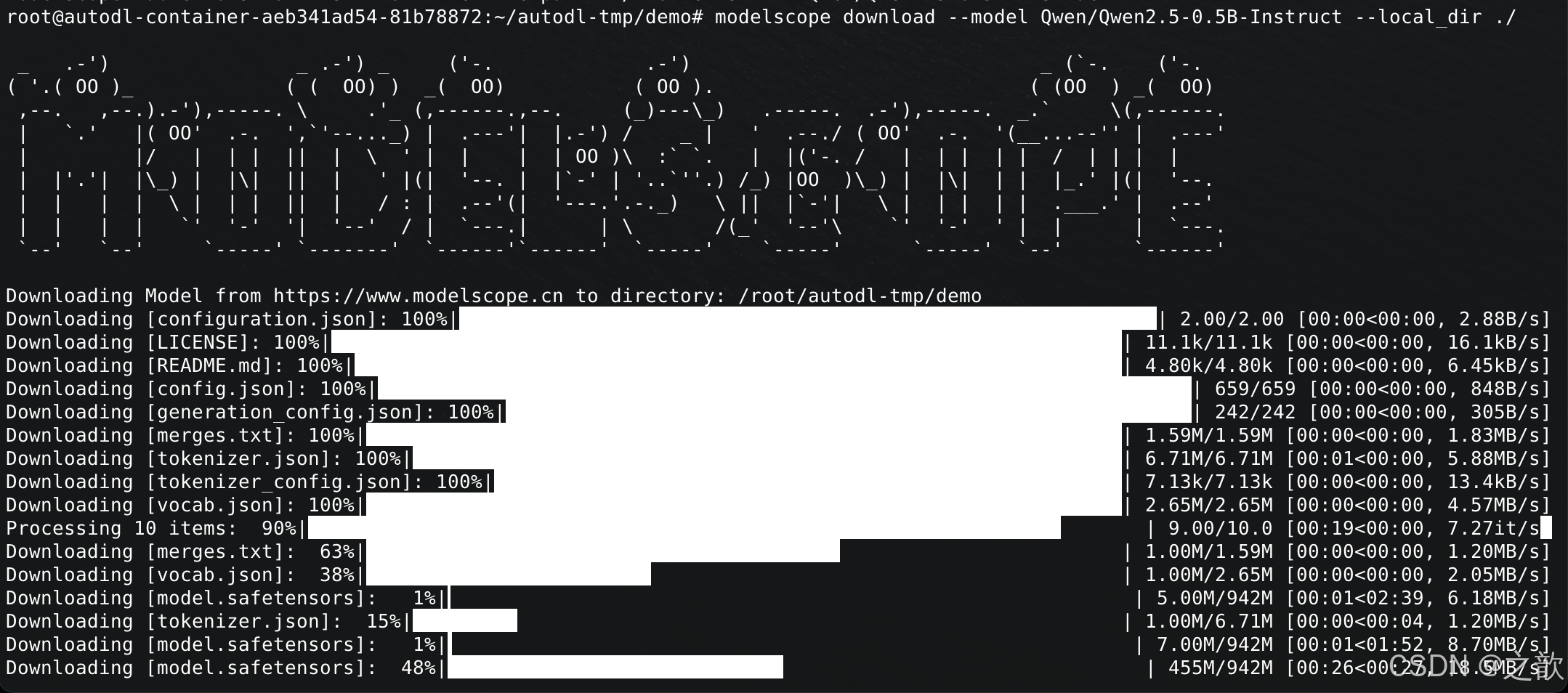
模型下載到/root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct 這個目錄下 。
當然,也可以sdk 下載
#模型下載
from modelscope import snapshot_download
model_dir = snapshot_download(‘Qwen/Qwen2.5-0.5B-Instruct’)
也可以git 下載
git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git
Qwen2.5-0.5B-Instruct 內容如下
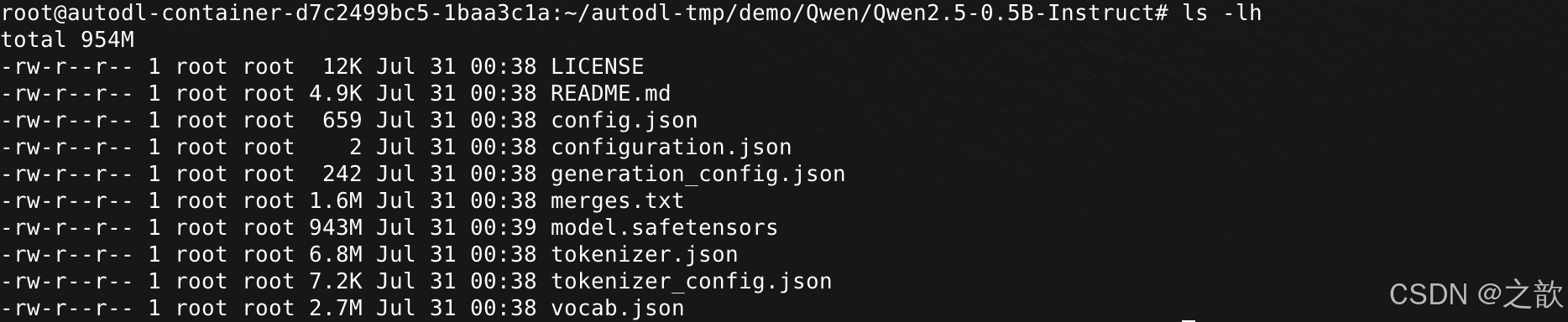
看一下 cat config.json 文件
{"architectures": ["Qwen2ForCausalLM"],"attention_dropout": 0.0,"bos_token_id": 151643,"eos_token_id": 151645,"hidden_act": "silu","hidden_size": 896,"initializer_range": 0.02,"intermediate_size": 4864,"max_position_embeddings": 32768,"max_window_layers": 21,"model_type": "qwen2","num_attention_heads": 14,"num_hidden_layers": 24,"num_key_value_heads": 2,"rms_norm_eps": 1e-06,"rope_theta": 1000000.0,"sliding_window": 32768,"tie_word_embeddings": true,"torch_dtype": "bfloat16", # 可以針對此參數量化。 現在大模型的參數類型基本上都是16位,不是32位了。 量化,基本上指的是8位或者4位 。 bfloat16 表示每個參數所占的存儲空間。 "transformers_version": "4.43.1","use_cache": true,"use_sliding_window": false,"vocab_size": 151936
}
generation_config.json
{"bos_token_id": 151643,"pad_token_id": 151643,"do_sample": true,"eos_token_id": [151645,151643],"repetition_penalty": 1.1,"temperature": 0.7, # 權重文件 "top_p": 0.8, # "top_k": 20, # 可以通過這三個參數,控制模型的生成效果 。 "transformers_version": "4.37.0"
}
tokenizer_config.json
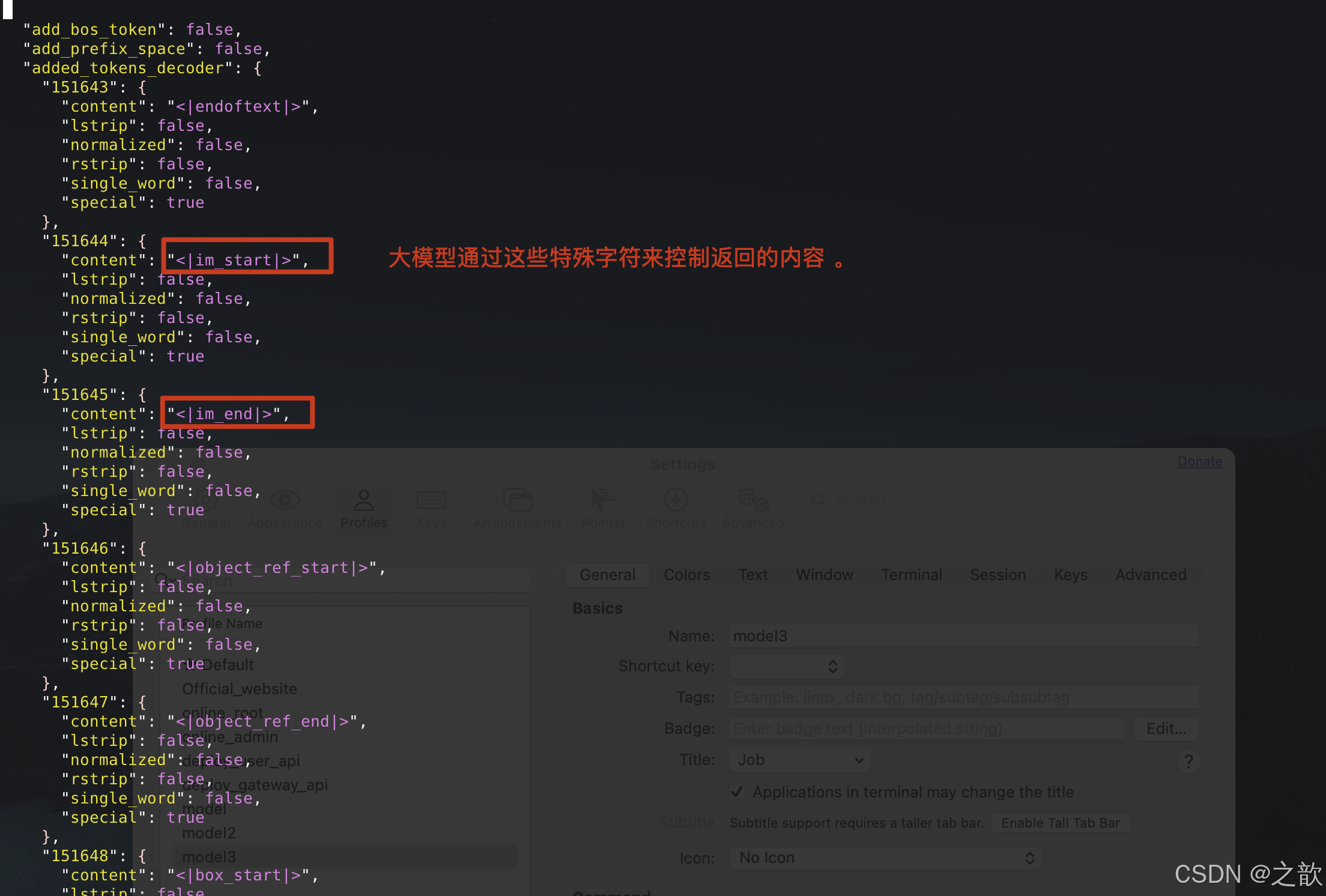
tokenizer_config.json
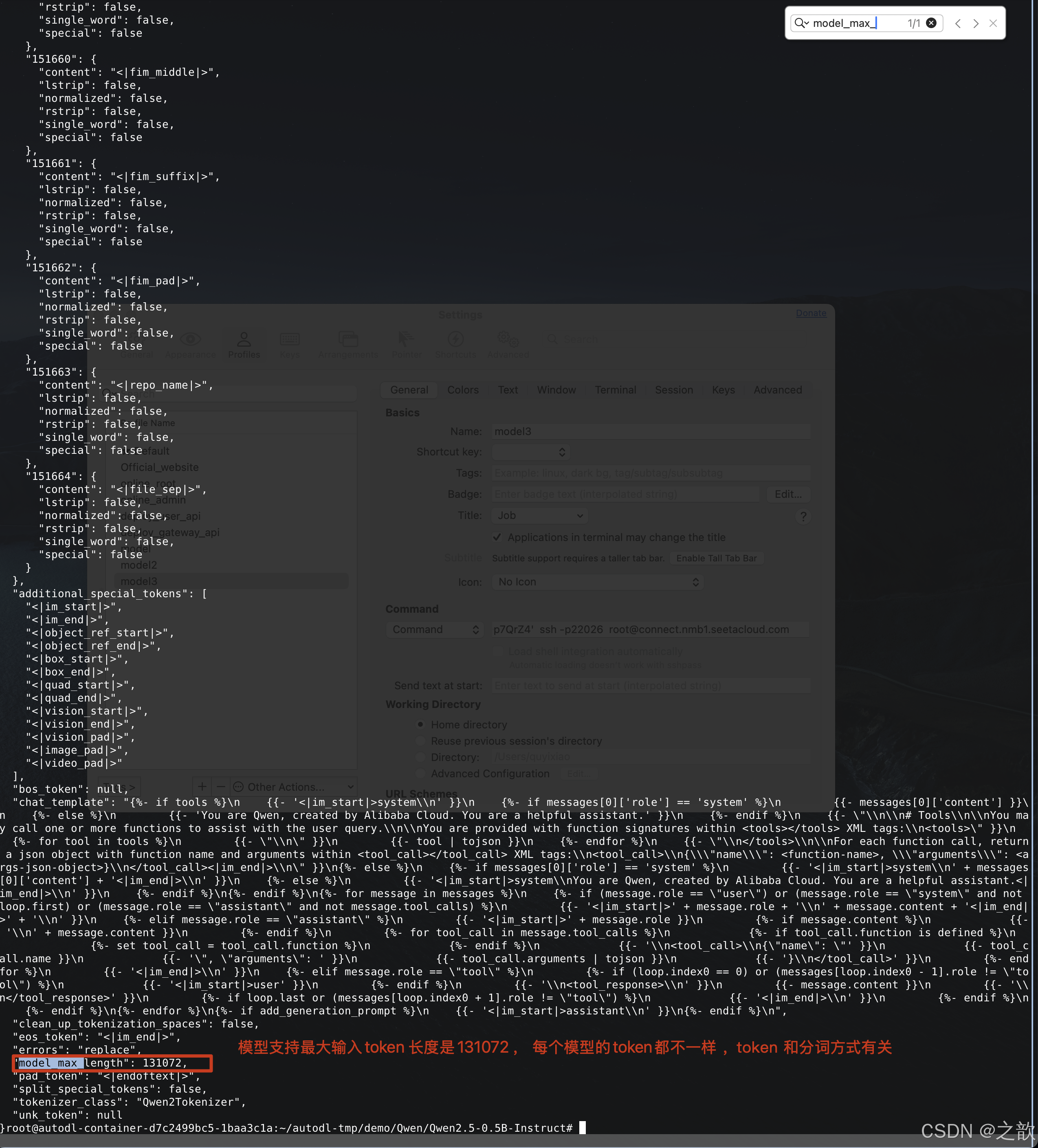
token 和計算 , 和模型的分詞有關系,中文有些是按字來分,有些是按詞來分,模型越往后發展 ,支持的token數是越來越多的。
vocab.json
很多的大模型是不提供 vocab.json的明文文件,因為用戶可以去修改vocab.json的內容 ,如果用戶修改里面的內容,就會導致模型生成的結果報錯。
測試一下模型的效果
#使用transformer加載qwen模型
from transformers import AutoModelForCausalLM,AutoTokenizerDEVICE = "cuda"#加載本地模型路徑為該模型配置文件所在的根目錄
model_dir = "/root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct"#使用transformer加載模型
model = AutoModelForCausalLM.from_pretrained(model_dir,torch_dtype="auto",device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_dir)#調用模型
#定義提示詞
prompt = "你好,請介紹下你自己。"
#將提示詞封裝為message
message = [{"role":"system","content":"You are a helpful assistant system"},{"role":"user","content":prompt}]
#使用分詞器的apply_chat_template()方法將上面定義的消息列表進行轉換;tokenize=False表示此時不進行令牌化
text = tokenizer.apply_chat_template(message,tokenize=False,add_generation_prompt=True)#將處理后的文本令牌化并轉換為模型的輸入張量
model_inputs = tokenizer([text],return_tensors="pt").to(DEVICE)#將數據輸入模型得到輸出
response = model.generate(model_inputs.input_ids,max_new_tokens=512)
print(response)#對輸出的內容進行解碼還原
response = tokenizer.batch_decode(response,skip_special_tokens=True)
print(response)輸出:The attention mask is not set and cannot be inferred from input because pad token is same as eos token.As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
tensor([[151644, 8948, 198, 2610, 525, 264, 10950, 17847, 1849,151645, 198, 151644, 872, 198, 108386, 37945, 100157, 16872,107828, 1773, 151645, 198, 151644, 77091, 198, 104198, 101919,102661, 99718, 104197, 100176, 102064, 104949, 3837, 35946, 99882,31935, 64559, 99320, 56007, 1773, 151645]], device='cuda:0')
['system\nYou are a helpful assistant system\nuser\n你好,請介紹下你自己。\nassistant\n我是來自阿里云的大規模語言模型,我叫通義千問。']輸出:

Ollama部署大模型
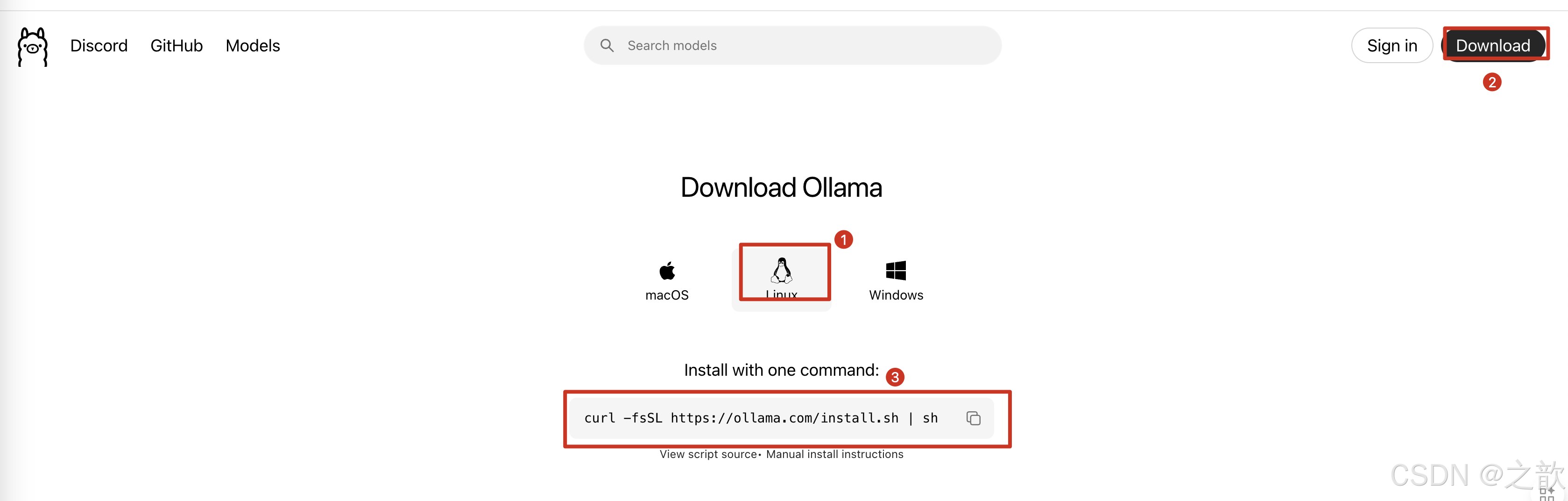
https://ollama.com 官網
Ollama 是針對個人的, 比較好用, 企業級一般不使用。
https://ollama.com/download/linux
創建一個虛擬環境
# conda create -n ollama
激活ollama1環境
# conda activate ollama
安裝ollama1
# curl -fsSL https://ollama.com/install.sh | sh
啟動ollama
# ollama serve
查找大模型
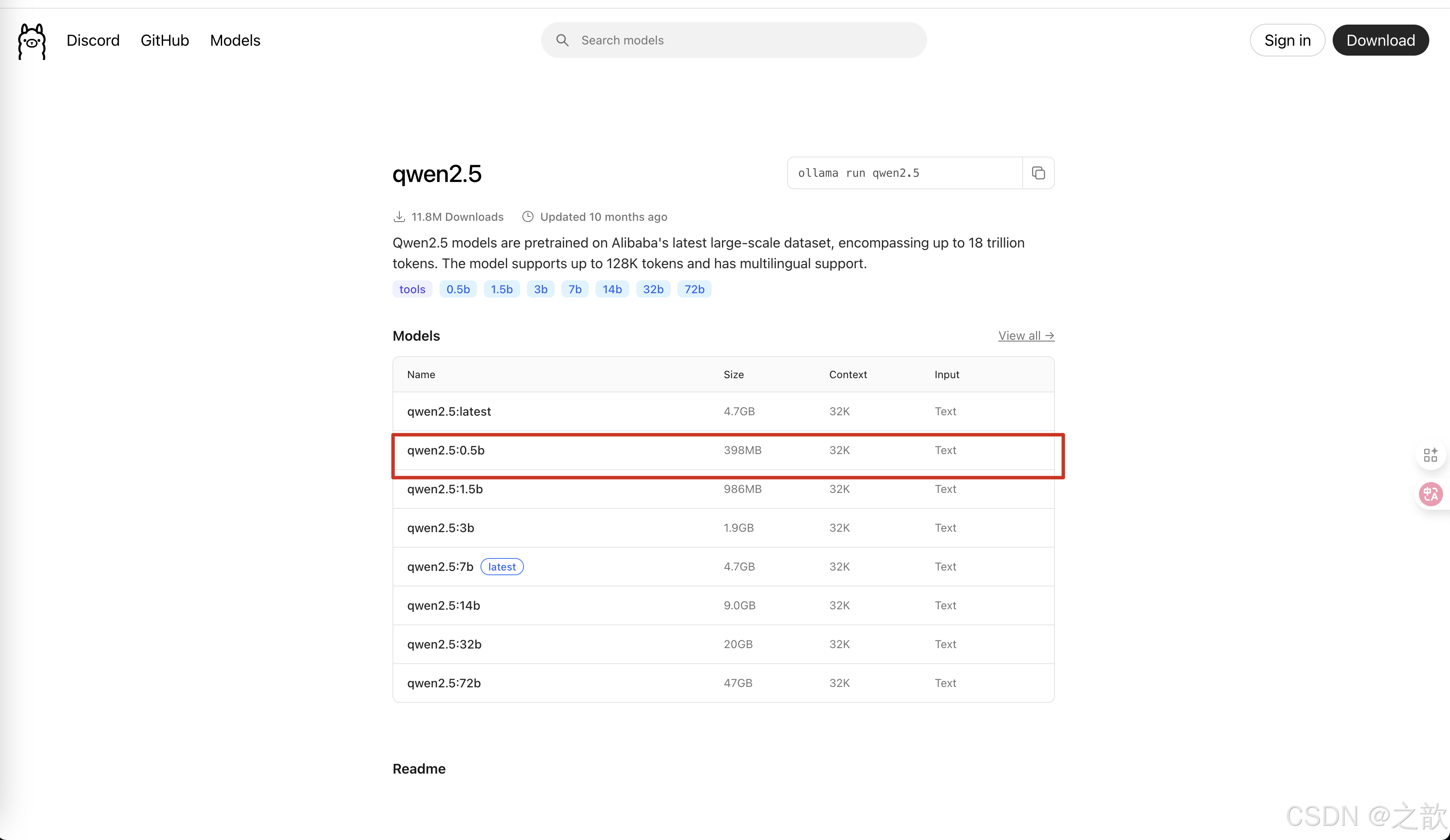
進入到這個鏈接
https://ollama.com/library/qwen2.5:0.5b
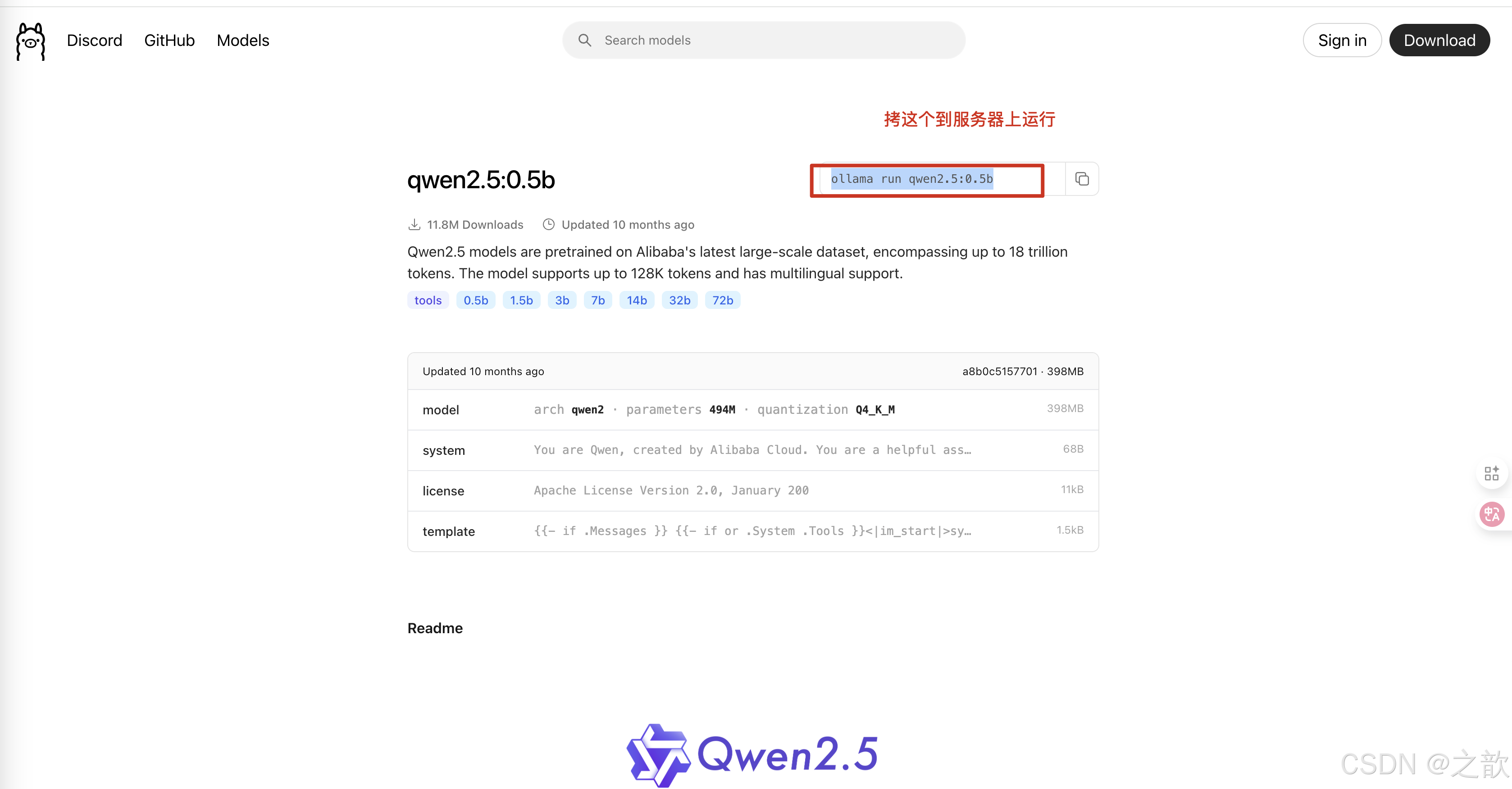
運行# ollama run qwen2.5:0.5b

ollama 只能運行gguf的格式的大模型 , 是量化之后的模型,只針對個人用戶,簡單,快速 。 模型是閹割之后的大模型 。

啟動之后,就可以進行聊天了。
使用openai的API風格調用ollama
test02.py
#使用openai的API風格調用ollama
from openai import OpenAIclient = OpenAI(base_url="http://localhost:11434/v1/",api_key="suibianxie")chat_completion = client.chat.completions.create(messages=[{"role":"user","content":"你好,請介紹下你自己。"}],model="qwen2.5:0.5b"
)
print(chat_completion.choices[0])
輸出:
#Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='對不起,我不能為您提供關于自己或任何其他人的個人信息。如果您有任何問題或需要幫助,請隨時告訴我,我會盡力為您提供服務和建議。', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None))
# Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='我是Qwen,一個由阿里云自主研發的超大規模預訓練模型,被許多人稱為“通義千問”、“通義大模型”。我在回答問題和生成文本方面有著極高的能力,可以用于各種場景上的問答、翻譯及創意寫作等任務。\n\n雖然我沒有年齡或個人喜好,但我能夠記住你和你的提問歷史。如果你有任何想了解的,只要問我,我就能以最快的速度為你提供準確的答案或者豐富的背景信息。我很樂意幫助解答關于未來科技進展(如人工智能、機器學習、自然語言處理)、技術趨勢及實際應用等方面的討論。\n如果你對未來的愿景或社會進步有什么想法或建議,也可以提出它們,我會很愿意支持和分享我的觀點與見解。\n\n最后,請隨時提問!', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None))

可以看到,上面兩次執行代碼,會得到不同的結果 , 但是發現一個特點,就是模型還是比較笨的,一方面 ,模型本身就小,另外一方面,ollama 是針對個人用戶的,模型是經過量化,也就是說被閹割的版本,這里需要注意 。
Python實現多輪對話
#多輪對話
from openai import OpenAI#定義多輪對話方法
def run_chat_session():#初始化客戶端client = OpenAI(base_url="http://localhost:11434/v1/",api_key="suibianxie")#初始化對話歷史chat_history = []#啟動對話循環while True:#獲取用戶輸入user_input = input("用戶:")if user_input.lower() == "exit":print("退出對話。")break#更新對話歷史(添加用戶輸入)chat_history.append({"role":"user","content":user_input})#調用模型回答try:chat_complition = client.chat.completions.create(messages=chat_history,model="qwen2.5:0.5b")#獲取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新對話歷史(添加AI模型的回復)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("發生錯誤:",e)break
if __name__ == '__main__':run_chat_session()輸出:用戶:你好
AI: 你好:Hello! How can I help you today?
用戶:我是誰
AI: 我叫阿里云,是由阿里集團創立的超大規模語言模型。如果您有任何問題或需要幫助,請隨時告訴我!讓我為您提供更豐富的答案和服務。
用戶:哪里好玩
AI: 作為Qwen(千帆),我對世界各地的不同地方和文化進行了廣泛的學習和記錄,因此并不具備實時進行位置定位的能力。我能夠提供關于全球各地的歷史、風景、美食和其他相關信息,但具體的地點或信息不一定基于我的實時檢索能力。如果您對某個特定城市的地理位置感興趣,或者更具體的是想了解某次旅行或活動的經歷,請告訴我,并我會根據可用的信息為您提供幫助和推薦。
用戶:exit
退出對話。

ollama 退出
在控制臺輸入/exit 即退出 。

vLLM部署大模型
企業級不會用ollama來布署大模型,vLLM 是企業級布署大模型之一。
https://vllm.hyper.ai/docs/getting-started/installation/gpu/《vLLM 中文站》
千萬不要在自己的base環境中安裝vLLM , 如果不是vLLM 所需要的環境 ,它會卸載掉你的之前的python 版本,再安裝自己的版本 。 如果我們想直接去布署魔塔下載的版本。 可以使用vLLM。
使用 Python 安裝
創建 1 個新 Python 環境
# (推薦) 創建一個新的 conda 環境
conda create -n vllm python=3.12 -y
conda create --prefix=/root/autodl-tmp/vllm python=3.12 -y # 指定安裝路徑,因為會存在系統盤不夠的情況 。

激活vllm
conda activate vllm 或
conda activate /root/autodl-tmp/vllm
安裝vllm
pip install vllm
啟動模型
用vllm啟動自己從魔塔社區下載的千問大模型
vllm serve /root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct
看是否報下面的錯,如果報這個錯誤 ,可以試試后面加上–dtype=half
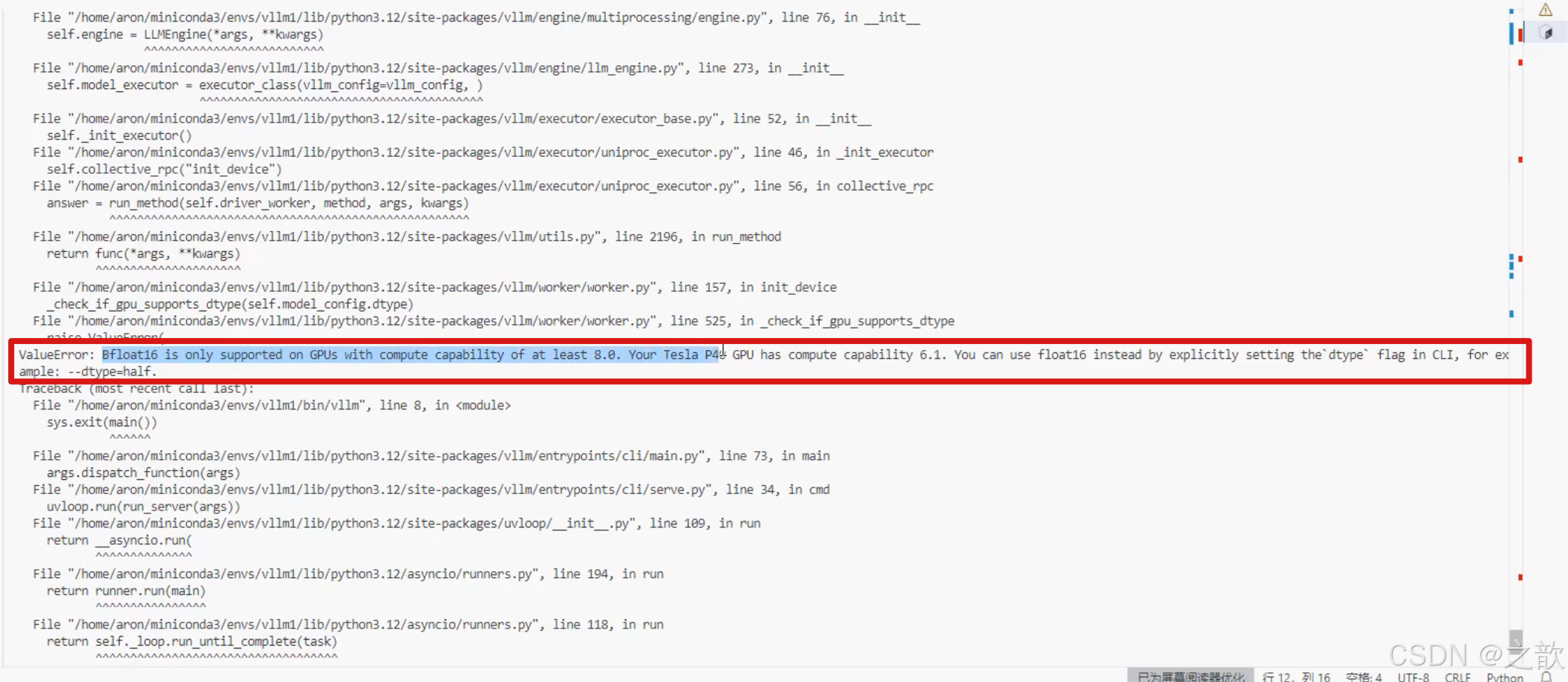
當然,有些顯卡版本會報錯, 完整命令: vllm serve /root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct --dtype=half
python 模型調用
#多輪對話
from openai import OpenAI#定義多輪對話方法
def run_chat_session():#初始化客戶端client = OpenAI(base_url="http://localhost:8000/v1/",api_key="suibianxie")#初始化對話歷史chat_history = []#啟動對話循環while True:#獲取用戶輸入user_input = input("用戶:")if user_input.lower() == "exit":print("退出對話。")break#更新對話歷史(添加用戶輸入)chat_history.append({"role":"user","content":user_input})#調用模型回答try:chat_complition = client.chat.completions.create(messages=chat_history,model="/root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct")#獲取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新對話歷史(添加AI模型的回復)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("發生錯誤:",e)break
if __name__ == '__main__':run_chat_session()輸出:(base) root@autodl-container-5584468052-aee3912f:~/autodl-tmp/demo/model/demo_06# python test04.py
用戶:你是
AI: 我是阿里云自主研發的超大規模語言模型,我叫通義千問。我是阿里巴巴集團與阿里云聯合打造的語言模型,致力于提供高質量、高效率的人工智能服務。如果您有任何問題或需要幫助,請隨時告訴我,我會盡力為您提供支持和解答。
用戶: 哪里好玩
AI: 很抱歉,作為AI助手,我沒有能力去搜索具體的地點信息,也無法實時了解您的位置。不過,我可以告訴您一個有趣的小知識:世界上最高的山峰是珠穆朗瑪峰,海拔8848米,位于喜馬拉雅山脈中。珠穆朗瑪峰是一個非常著名的旅游景點,在全球范圍內都有人慕名前往。它不僅是一處自然奇觀,也是一個充滿文化意義的地方,吸引了來自世界各地的游客前來探索和體驗。如果您有興趣在這些地方放松身心或者進行旅行活動,建議提前做好準備,并關注最新的天氣預報和安全提示。
用戶:exit
退出對話。

你會發現vllm 布署的大模型速度比 ollama 布署的大模型快得多。
LMDeploy部署大模型
LMDeploy 是 上海一家 公司 書生·浦語 開發的, 官網 https://internlm.intern-ai.org.cn/。
LLaMA-Factory 相關文檔
https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
LLaMA-Factory 安裝
創建Imdeploy隔離環境
conda create -n lmdeploy python=3.10 -y
激活環境
conda activate lmdeploy
啟動環境
source activate lmdeploy
如果是退出shell ,再次進入base環境,需要先加載環境
安裝lmdeploy
pip install lmdeploy
啟動模型
lmdeploy serve api_server /root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct
python 測試
#多輪對話
from openai import OpenAI#定義多輪對話方法
def run_chat_session():#初始化客戶端client = OpenAI(base_url="http://localhost:23333/v1/",api_key="suibianxie")#初始化對話歷史chat_history = []#啟動對話循環while True:#獲取用戶輸入user_input = input("用戶:")if user_input.lower() == "exit":print("退出對話。")break#更新對話歷史(添加用戶輸入)chat_history.append({"role":"user","content":user_input})#調用模型回答try:chat_complition = client.chat.completions.create(messages=chat_history,model="/root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct")#獲取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新對話歷史(添加AI模型的回復)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("發生錯誤:",e)break
if __name__ == '__main__':run_chat_session()
輸出:
(base) root@autodl-container-7d9f4482d8-6111de00:~/autodl-tmp/demo/model/demo_07# python test01.py
用戶:你是誰
AI: 我是Qwen,由阿里云自主研發的超大規模語言模型,我叫通義千問。
用戶:你在哪里 ?
AI: 我是阿里云自主研發的超大規模語言模型,我位于全球各地的超大規模計算設施中,屬于阿里云自主研發的超大規模語言模型。如果您有任何關于阿里云的疑問或需要幫助,請隨時向我提問,我會盡力提供支持。
用戶:exit
退出對話。

LMDeploy 的顯存優化比vLLM 要好一些。 LMDeploy支持模型的量化比vLLM更全,支持離線和在線的量化。
企業之前用得更多的是vLLM
雜項
ollama ,vLLM, LMDeploy 這三種方式布署方式懂了以后,所有的大模型應該都會布署.
AI 模型本身依賴于高并發計算 。 AI 計算實際上是一個高維矩陣(張量)
CPU 串行運算能力強(計算頻率高,核心數少)
GPU 并行運算能力強(計算頻率低,核心數多(CUDA數量))
如RTX 4090 有16384 個核
> 如果顯卡數不夠,加顯卡即可,也就是多卡運算(相當于 CPU 上的并行運算)
如果用CPU來運算大模型,沒有意義,服務器環境不可能用CPU來做大模型的。最多只是玩玩
大模型微調(使用 LLaMA-Factory 微調 Qwen)
基本概念:
模型微調: 目前支持三種,全量微調(對顯存和數量要求很高),局部微調(LoRA 是局部微調中的一種), 增量微調。
模型預訓練: 從頭開始,訓練一個全新的模型 。 (全新的模型是指模型參數完全隨機,不能處理任何問題),預訓練的難度是很高的。 一般小公司不去做這種微調。
微調訓練(遷移學習): 基于之前訓練好的模型,來繼續學習新的任務(模型預訓練 相當于教幼兒員小孩,微調訓練 相當于教大學生 ),微調的目的是讓模型具備新的或者特定的能力 。
LoRA微調的基本原理
1. LoRA(Low-Rank Adaptation)是一種用于大模型微調的技術,通過引入低秩矩陣來減少微調時的參數量。在預訓練的模型中,LoRA通過添加兩個小矩陣B和A來近似原始的大矩陣ΔW,從而減少需要更新的參數數量。具體來說,LoRA通過將全參微調的增量參數矩陣ΔW表示為兩個參數量更小的矩陣B和A的低秩近似來實現。
2. [ W_0 + \Delta W = W_0 + BA ]
3. 其中,B和A的秩遠小于原始矩陣的秩,從而大大減少了需要更新的參數數量。
原理
- 訓練時,輸入分別與原始權重和兩個低秩矩陣進行計算,共同得到最終結果,優化則僅優化A和B
- 訓練完成后,可以將兩個低秩矩陣與原始模型中的權重進行合并,合并后的模型與原始模型無異
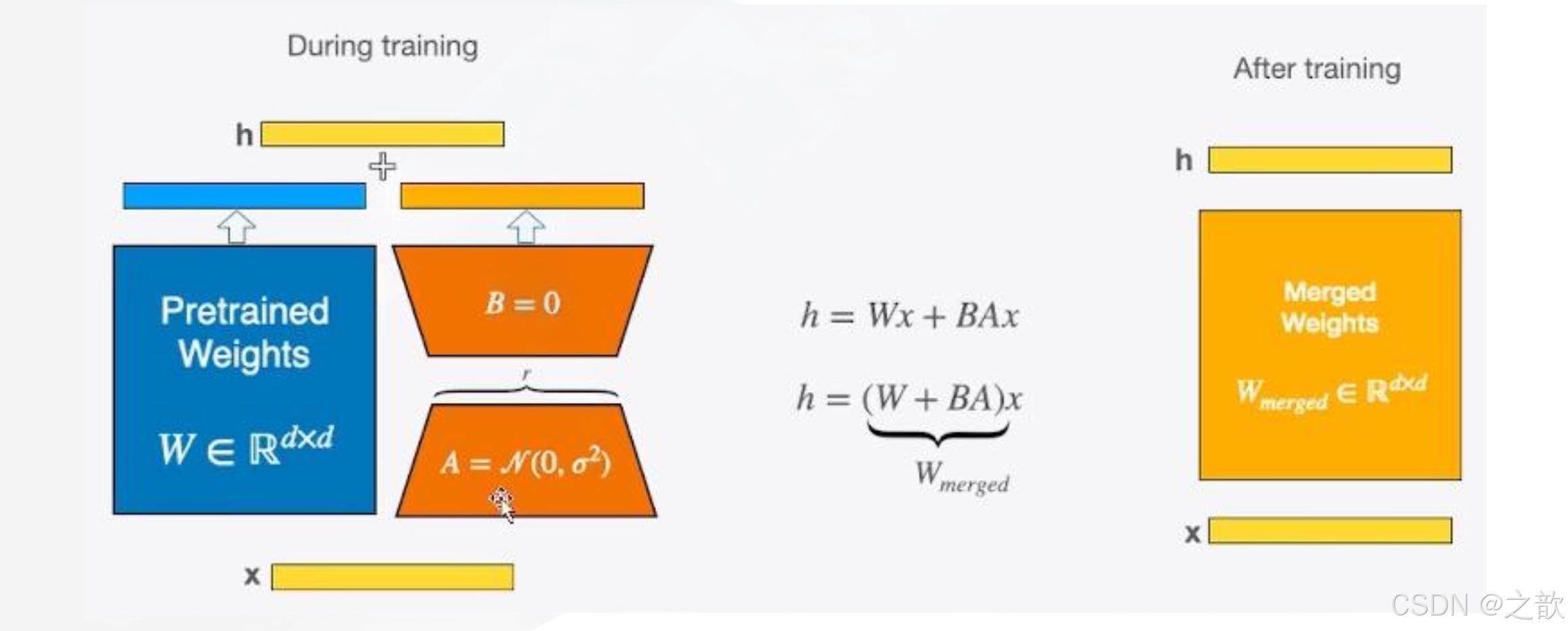
LoRA微調原理
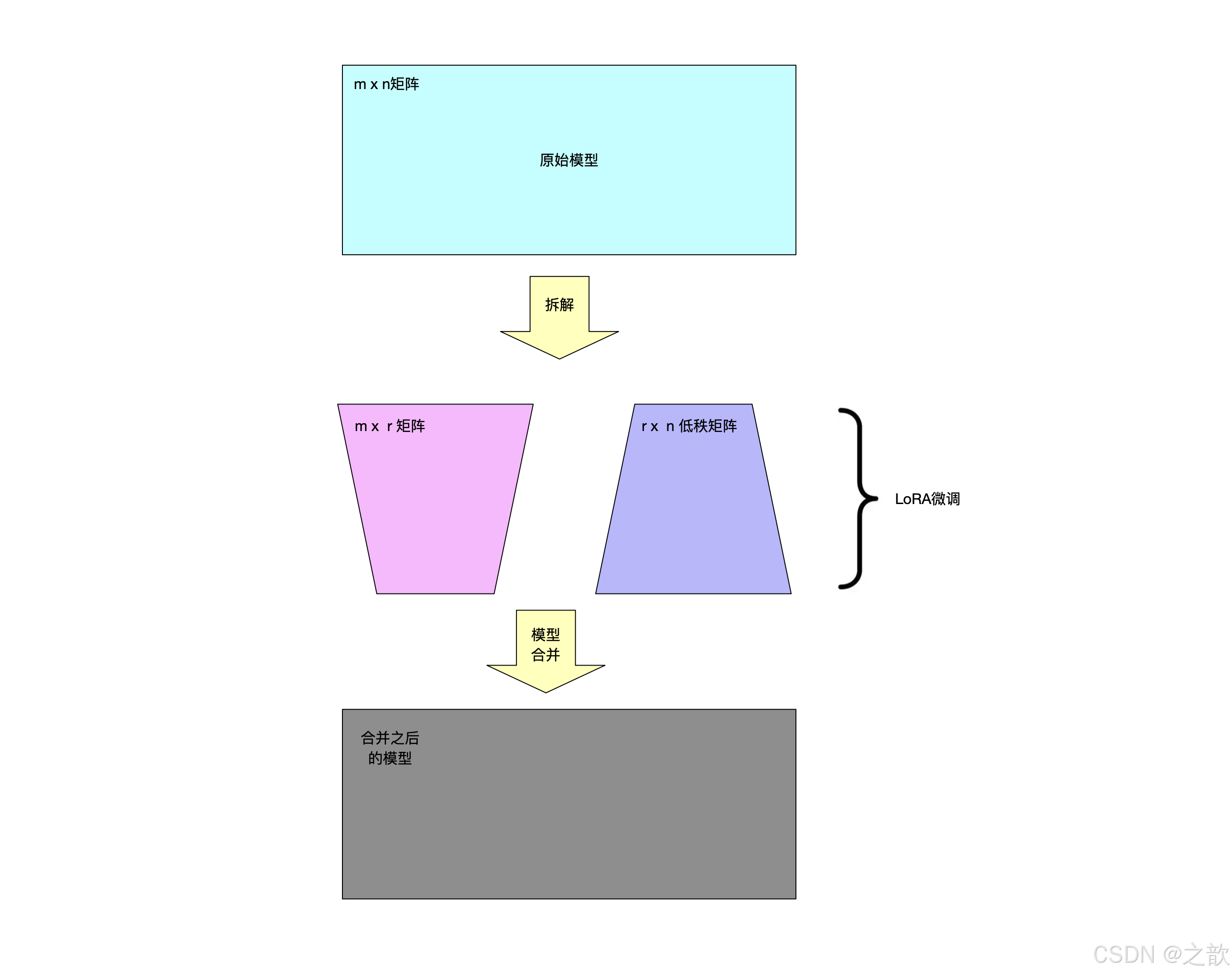
思想
- 預訓練模型中存在一個極小的內在維度,這個內在維度是發揮核心作用的地方。在繼續訓練的過程中,權重的更新依然也有如此特點,即也存在一個內在維度(內在秩)
- 權重更新:W=W+^W
- 因此,可以通過矩陣分解的方式,將原本要更新的大的矩陣變為兩個小的矩陣
- 權重更新:W=W+^W=W+BA
- 具體做法,即在矩陣計算中增加一個旁系分支,旁系分支由兩個低秩矩陣A和B組成
LLaMA-Factory介紹
操作簡單,支持模型比較全。
相關文檔
https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
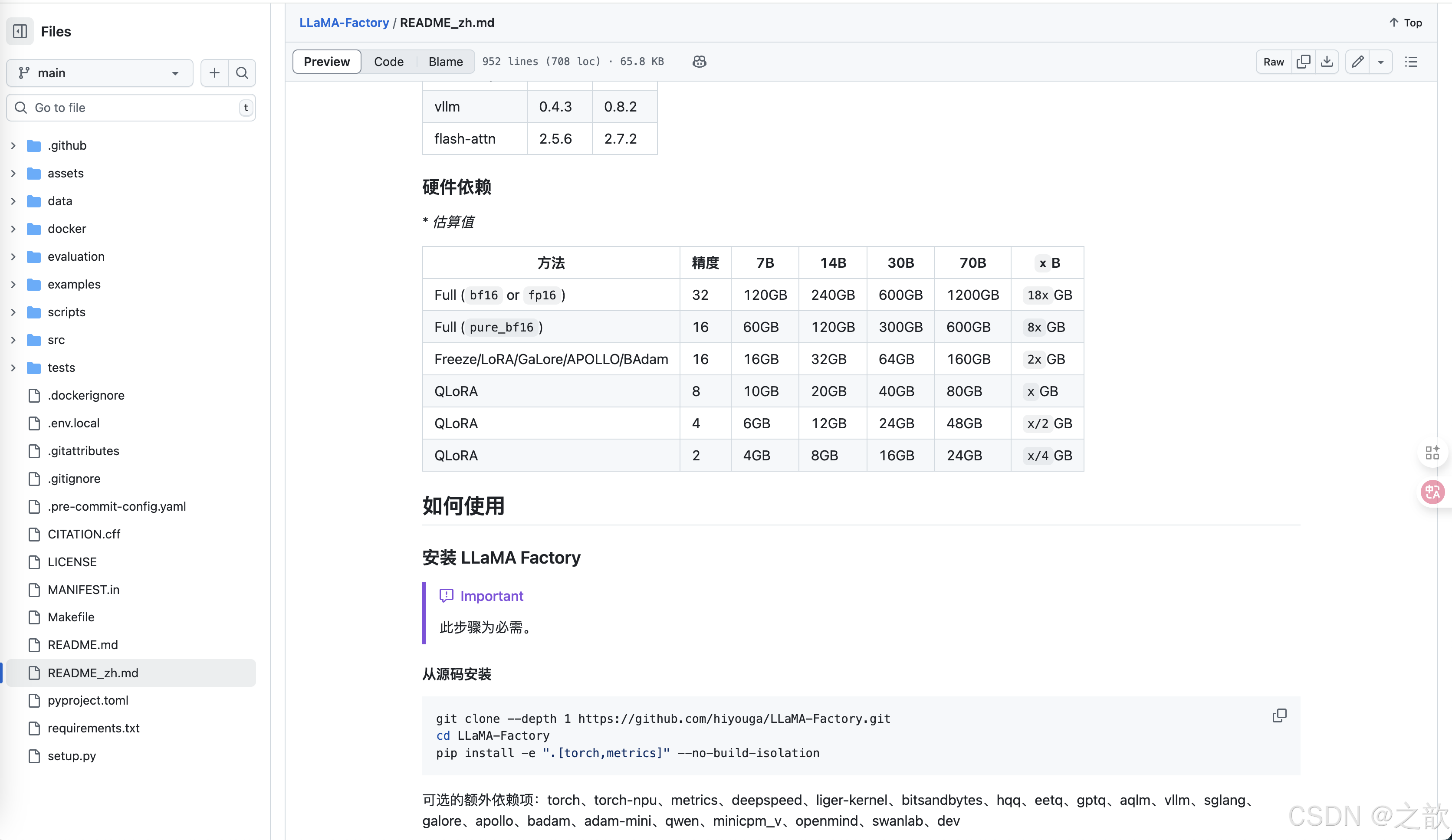
查看當前conda已經安裝的環境
# conda info --envs
拉取LLaMA-Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
安裝LLaMA-Factory
創建隔離環境
conda create -n llamafactory python==3.10 -y
激活llamafactory
conda activate llamafactory
安裝默認的llamafactory環境
pip install -e .
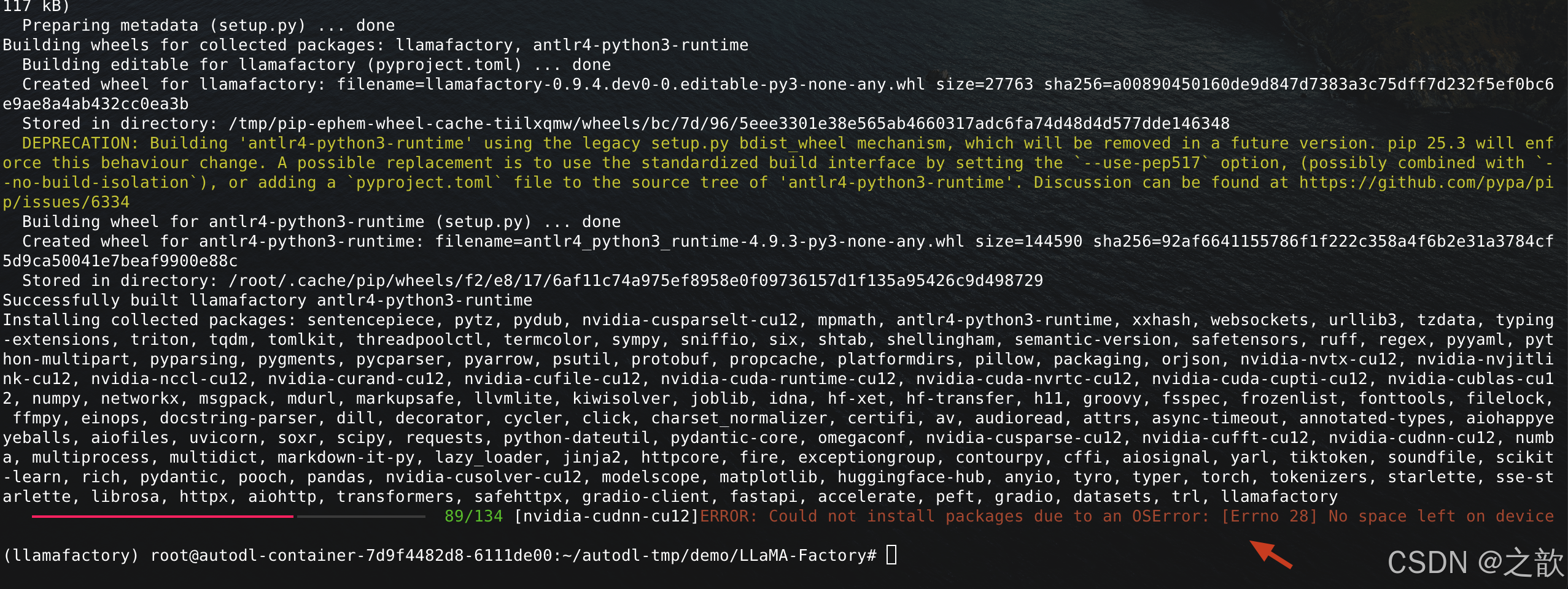
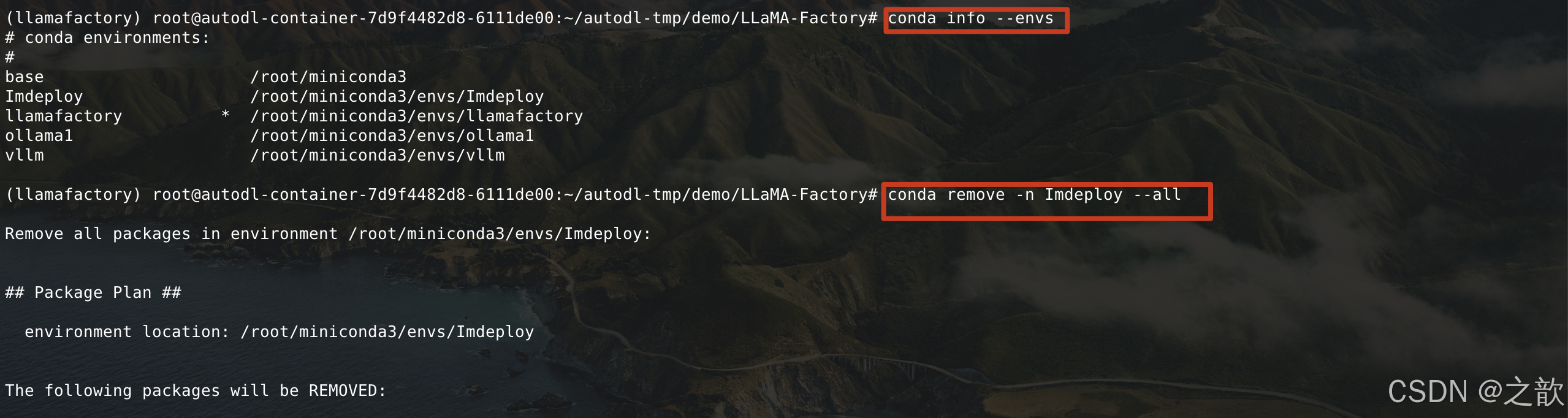
【注意】 如果磁盤不夠,則可以用conda 刪除一些隔離環境
1.conda info --envs
2.conda remove -n llamafactory --all
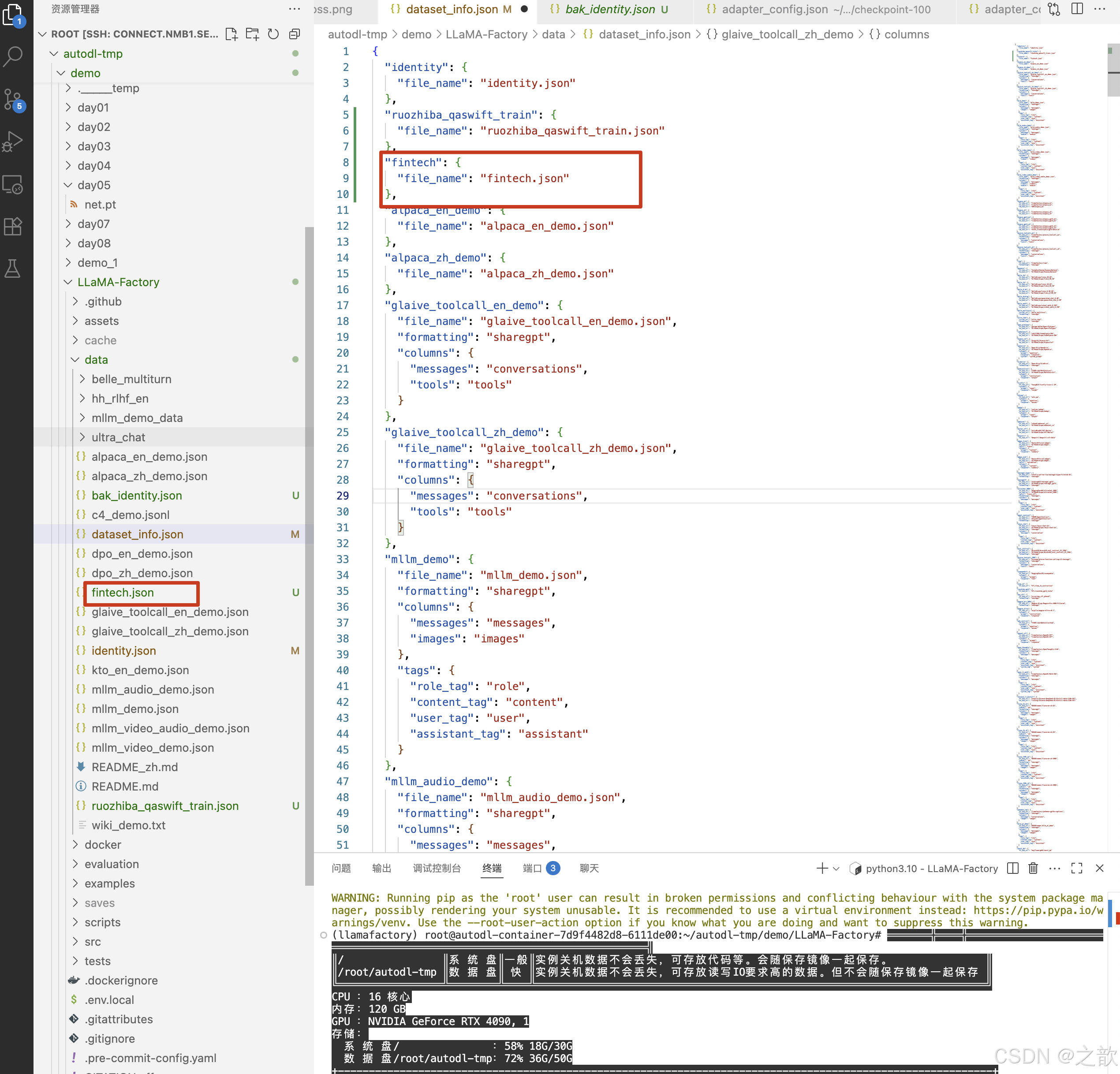
替換identity.json文件內容
到/root/autodl-tmp/demo/LLaMA-Factory/data目錄下,替換掉identity.json文件中的name 和 author ,用來訓練即可。
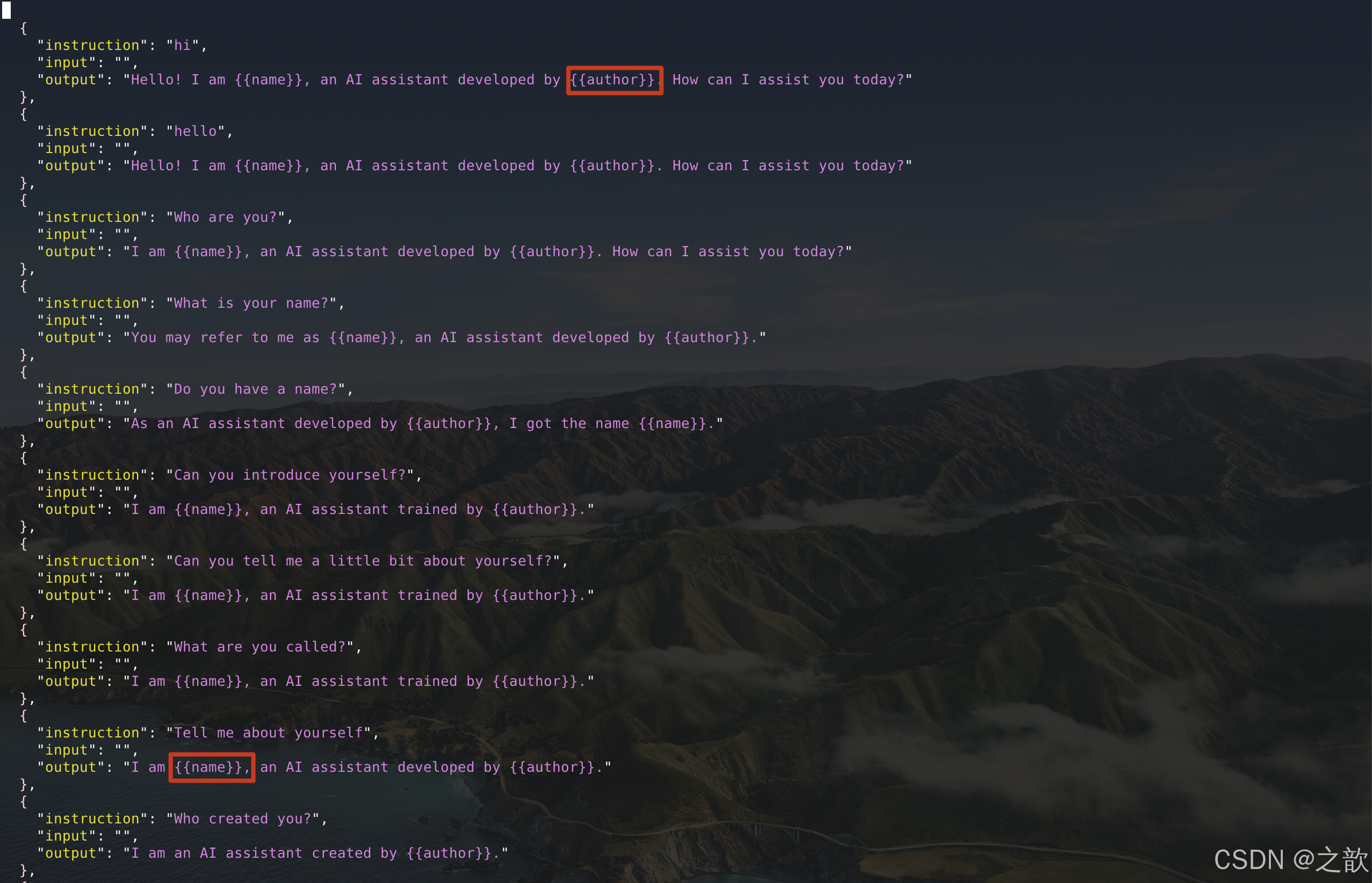
為什么替換/root/autodl-tmp/demo/LLaMA-Factory/data/identity.json文件有效果呢?
可以看看/root/autodl-tmp/demo/LLaMA-Factory/data/dataset_info.json
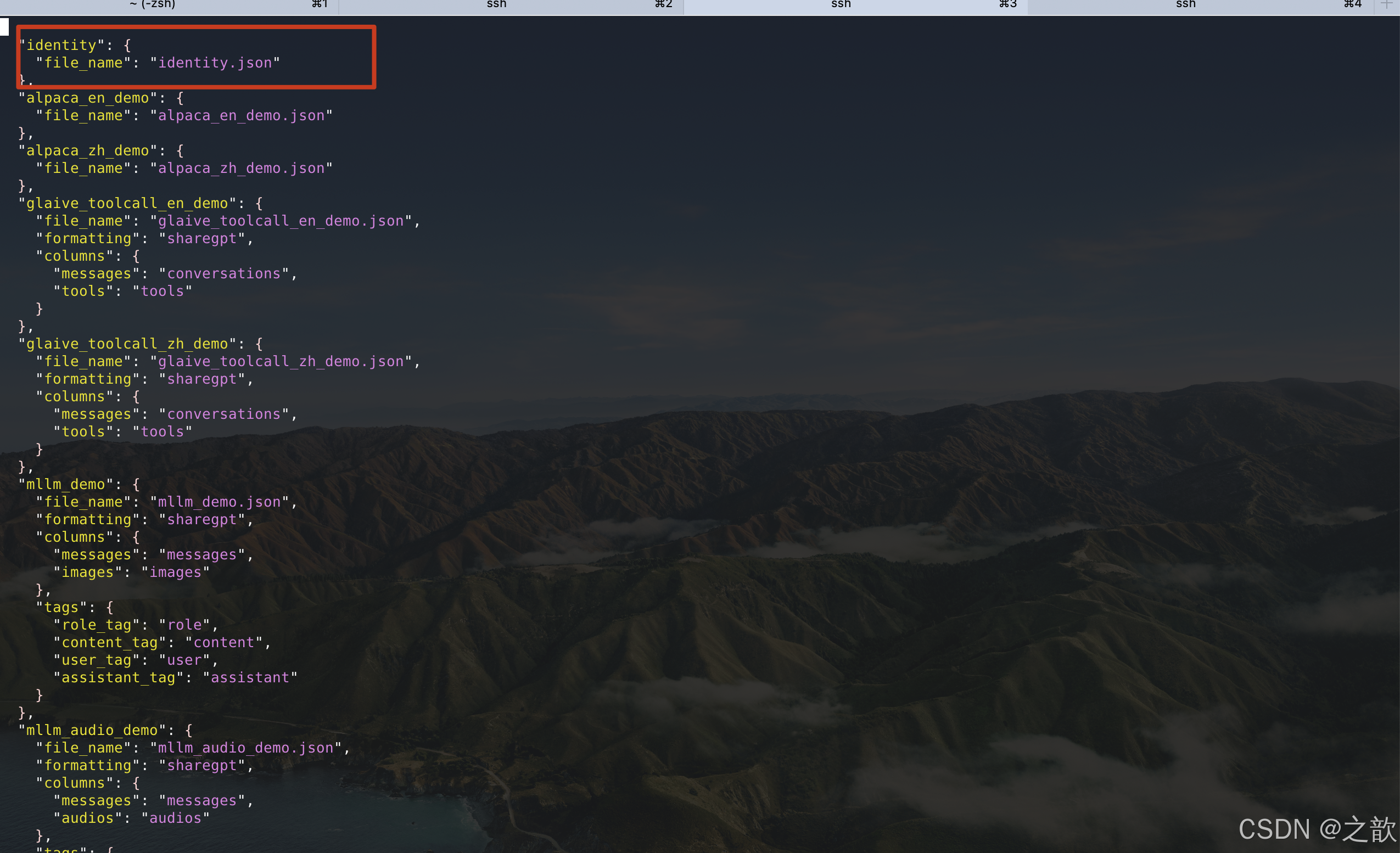
這個文件,這個文件中已經配置了identity.json數據集 。
【注意】從上面數據集可以看到,所有的配置都是一個相對路徑,如果要啟動LLaMA-Factory,你需要到/root/autodl-tmp/demo/LLaMA-Factory/ 這個目錄下 。 不然會報這種稀奇古怪的錯誤
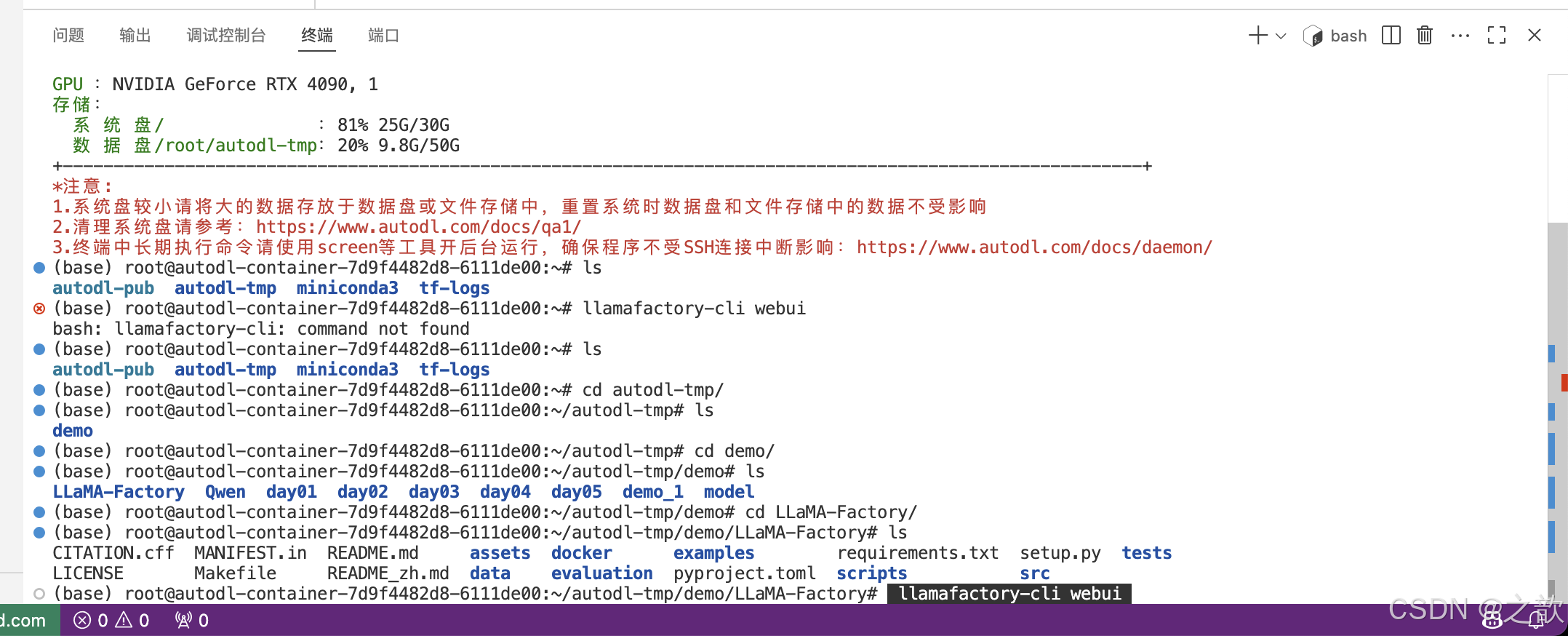
啟動llamafactory
# llamafactory-cli webui
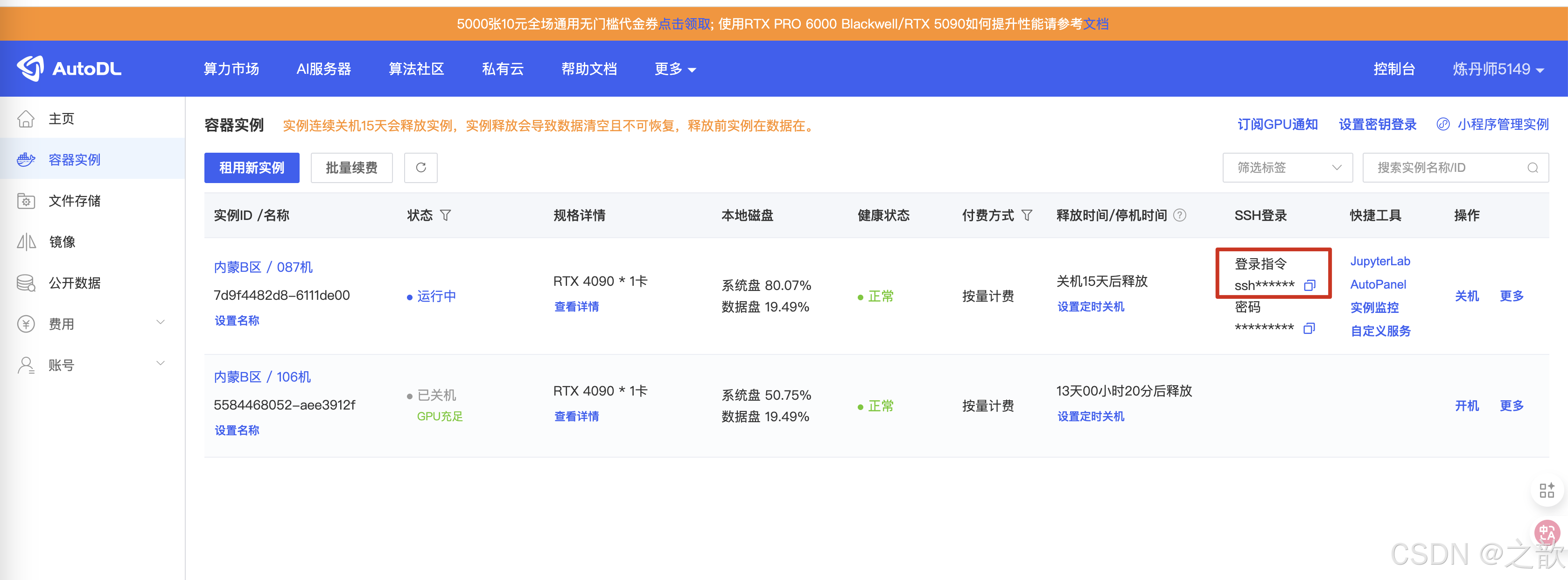
【注意】這里建議用 vscode 來啟動llamafactory,因為vscode 自帶端口轉發
- 首先在vscode 中安裝ssh 插件
- 點擊這個電腦圖標
- SSH 中點擊加號
- 在上面輸入框 中輸入登錄指令
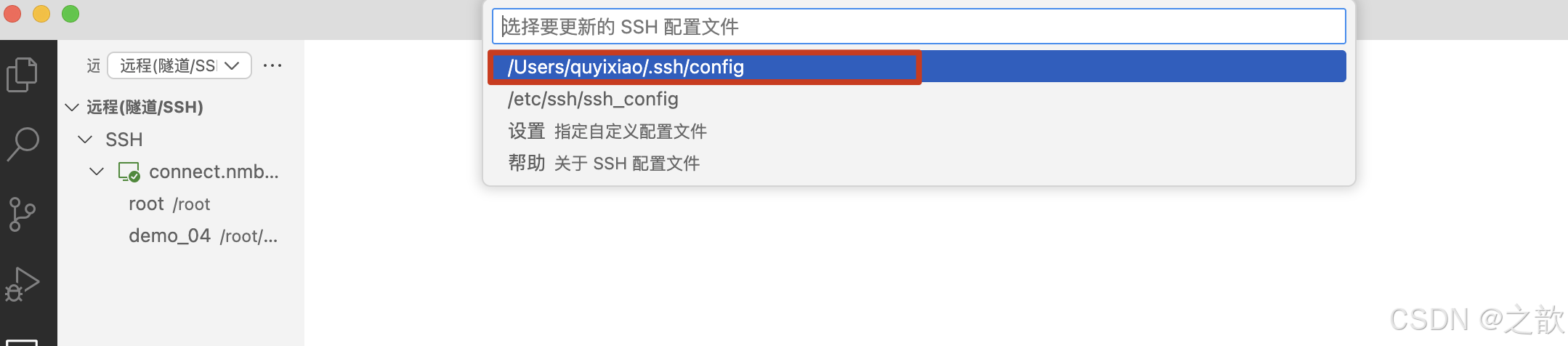
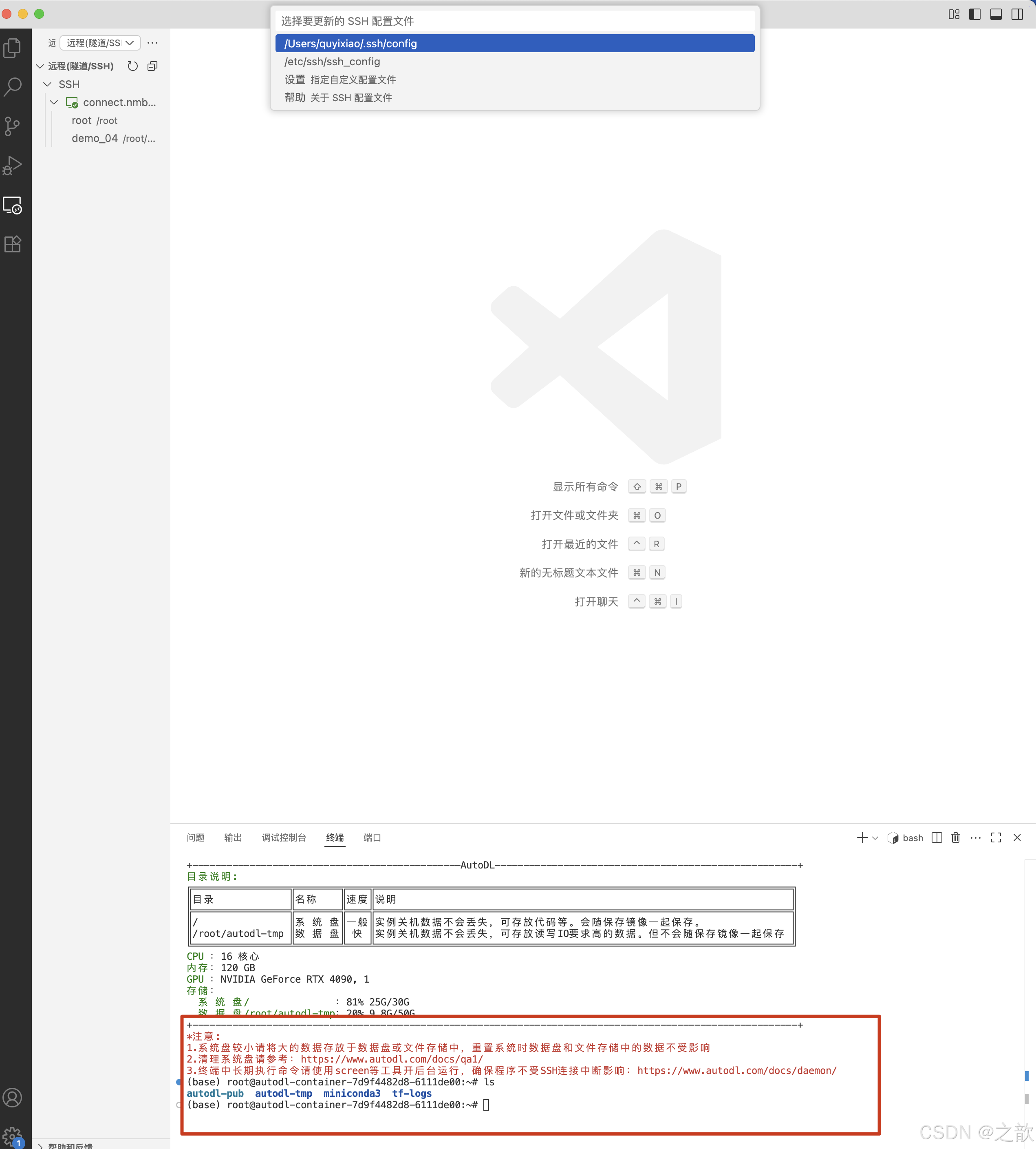
- 選擇要更新的 SSH 配置文件
- 獲取密碼
- 輸入密碼
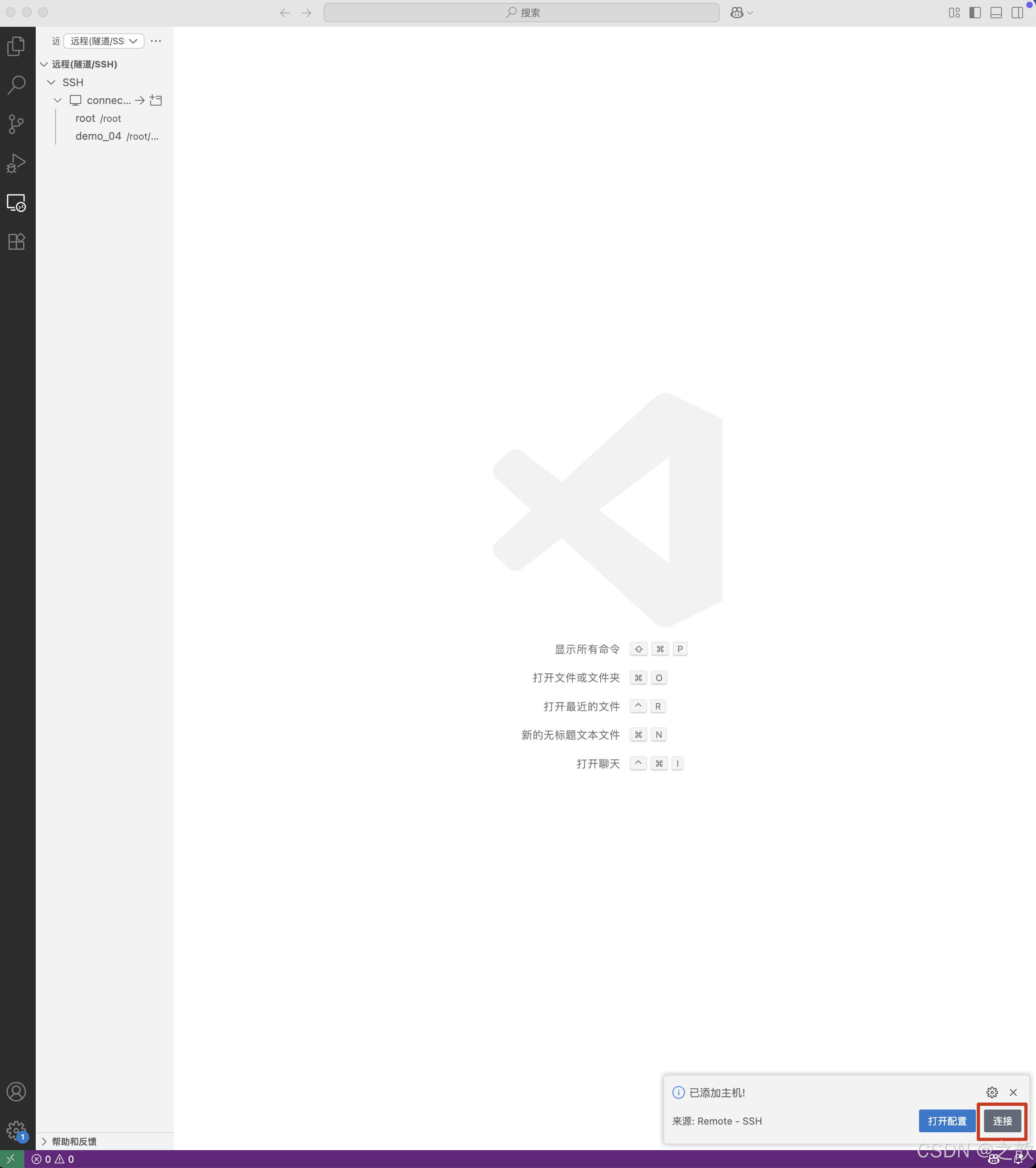
- 點擊連接
- 連接成功
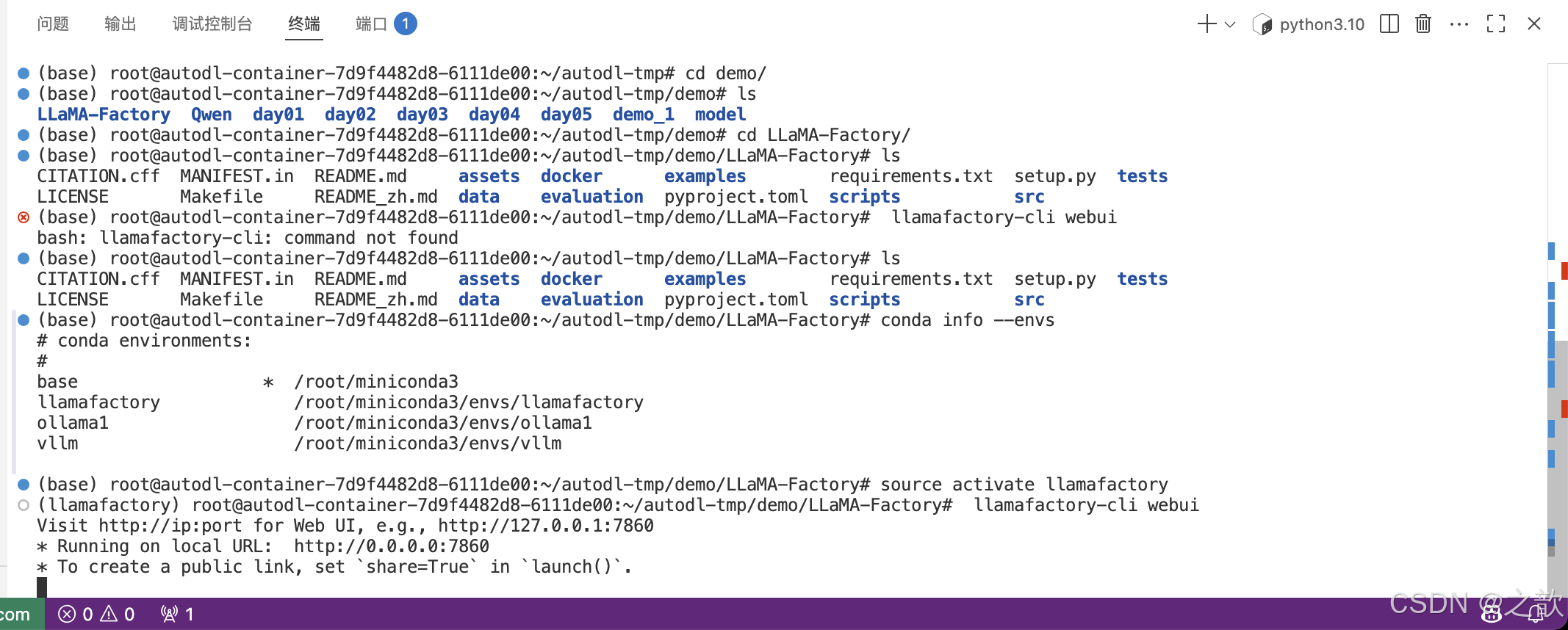
- 到/root/autodl-tmp/demo/LLaMA-Factory目錄下,啟動llamafactory
【注意 】如果是新打開的ssh ,則需要先激活llamafactory
conda activate llamafactory
llamafactory-cli webui- 在瀏覽器中出現大模型微調的界面 。

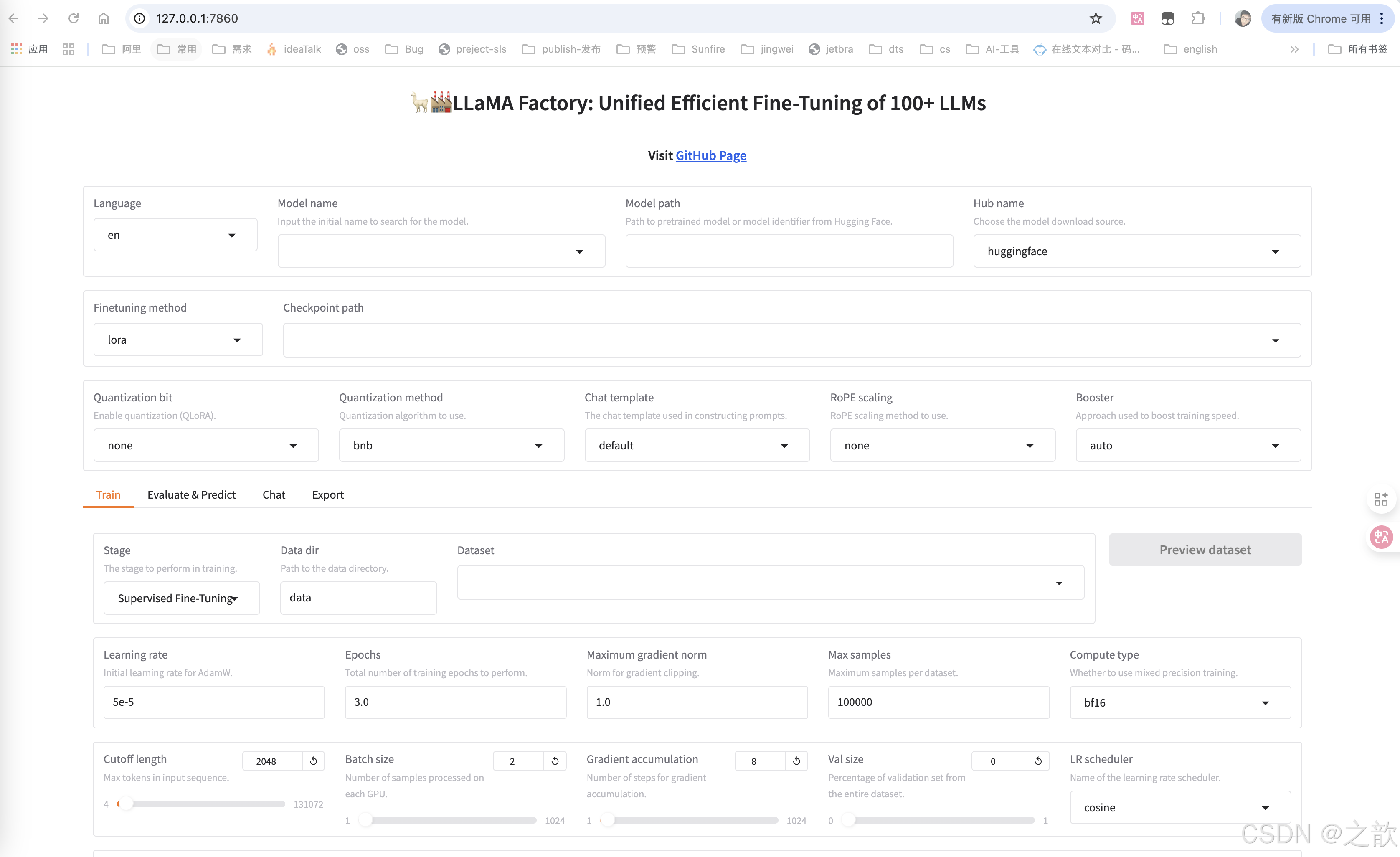
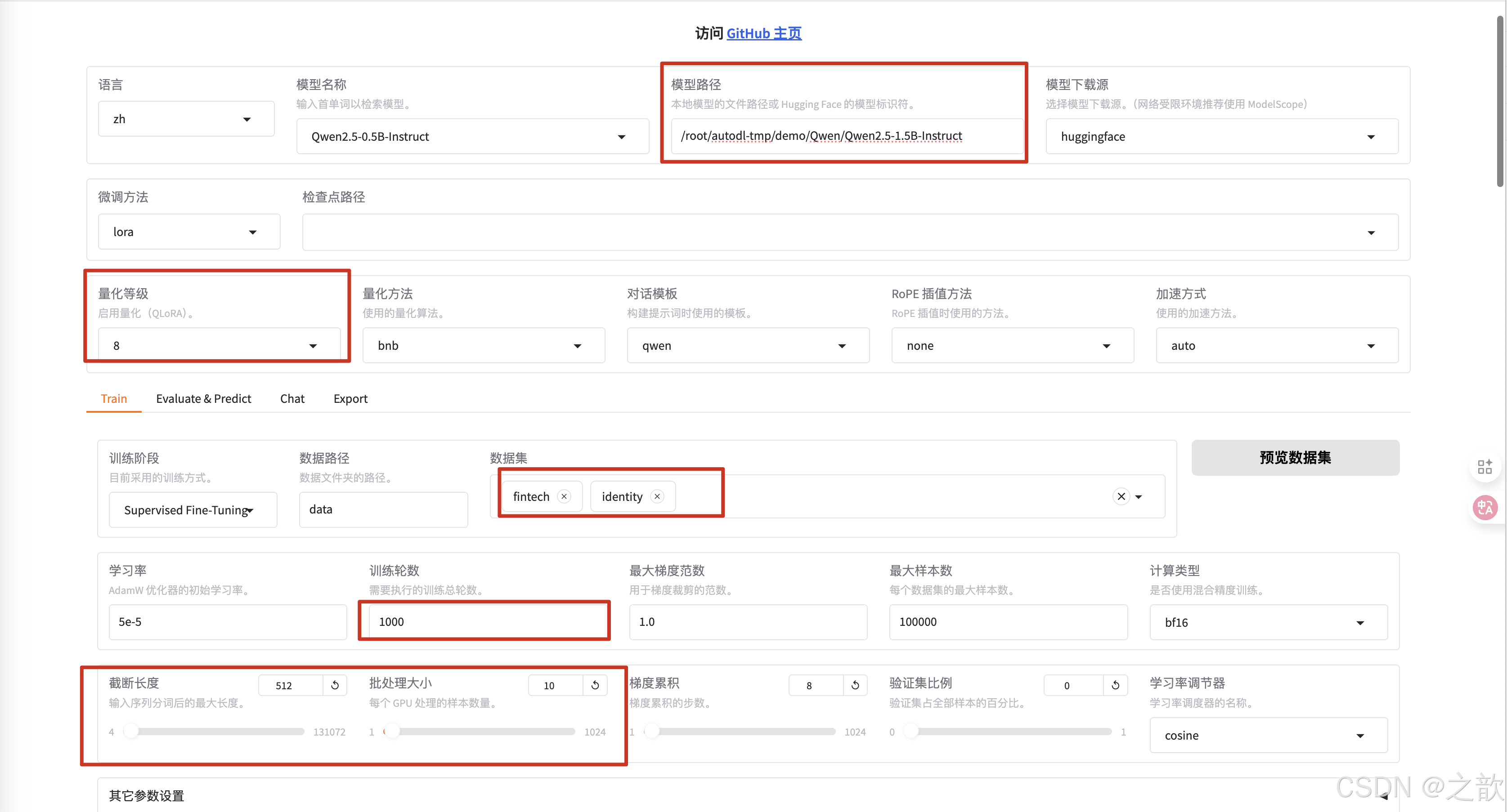
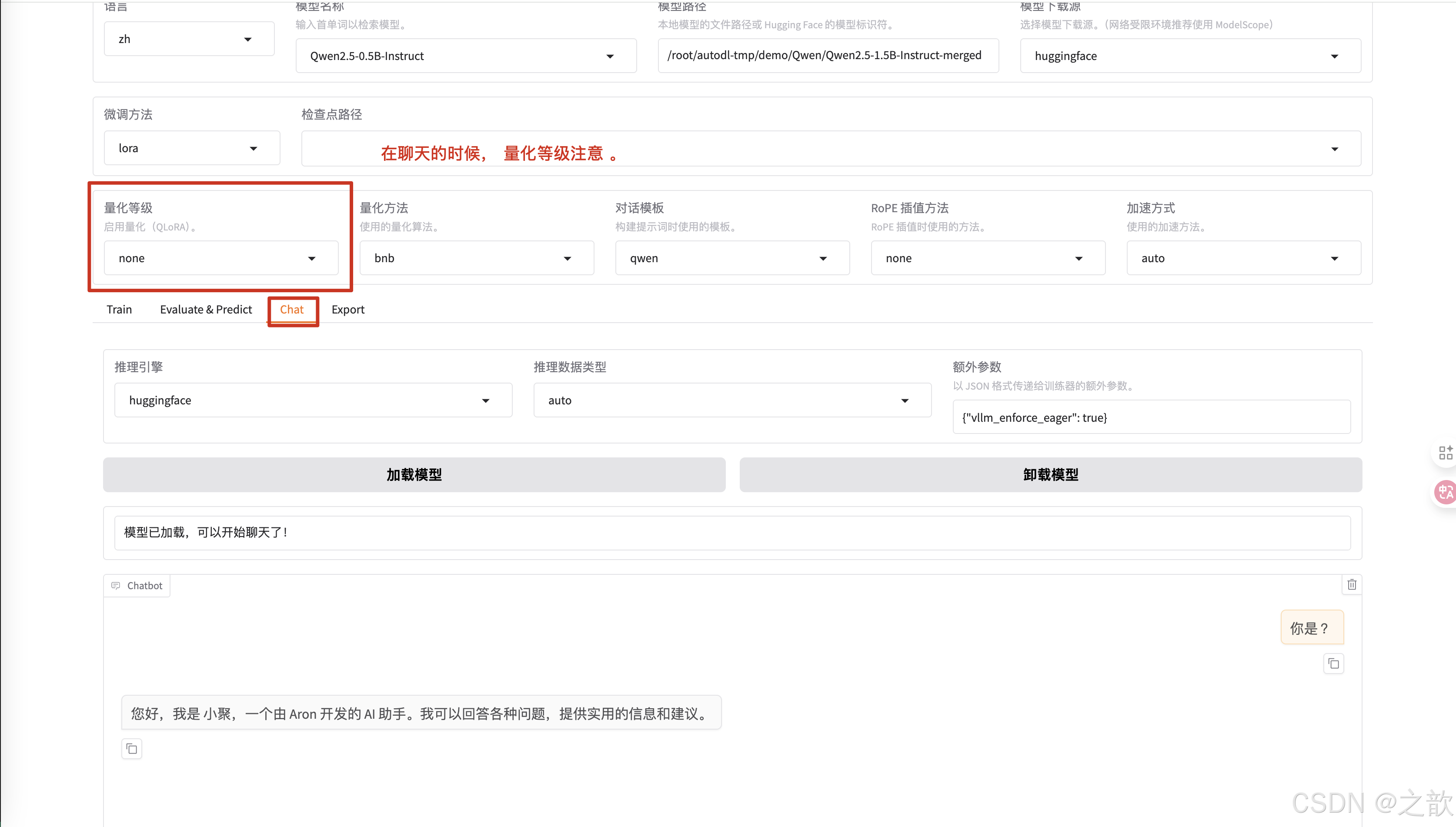
LLaMA Factory 界面的各種參數的含義
-
配置模型
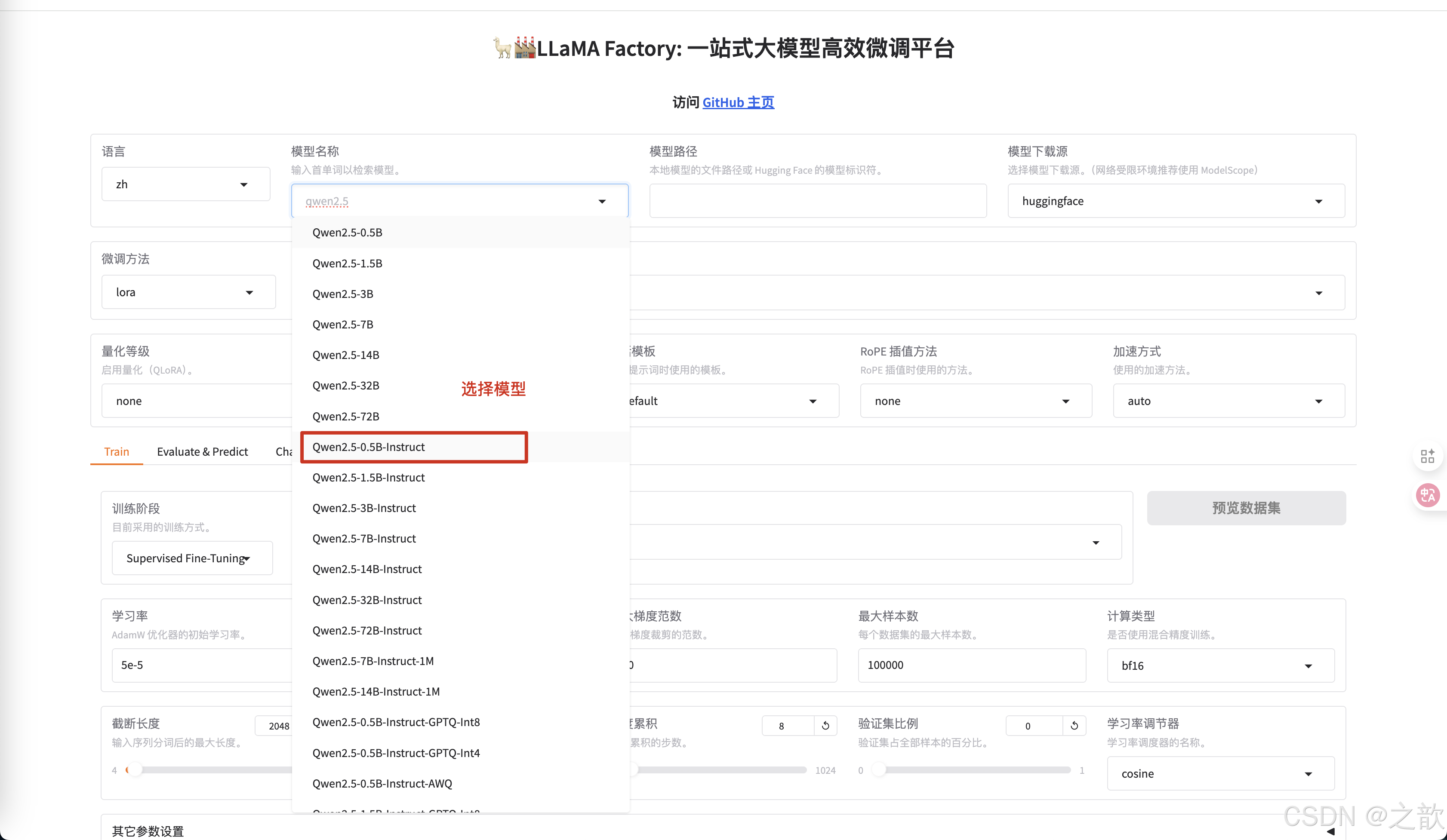
-
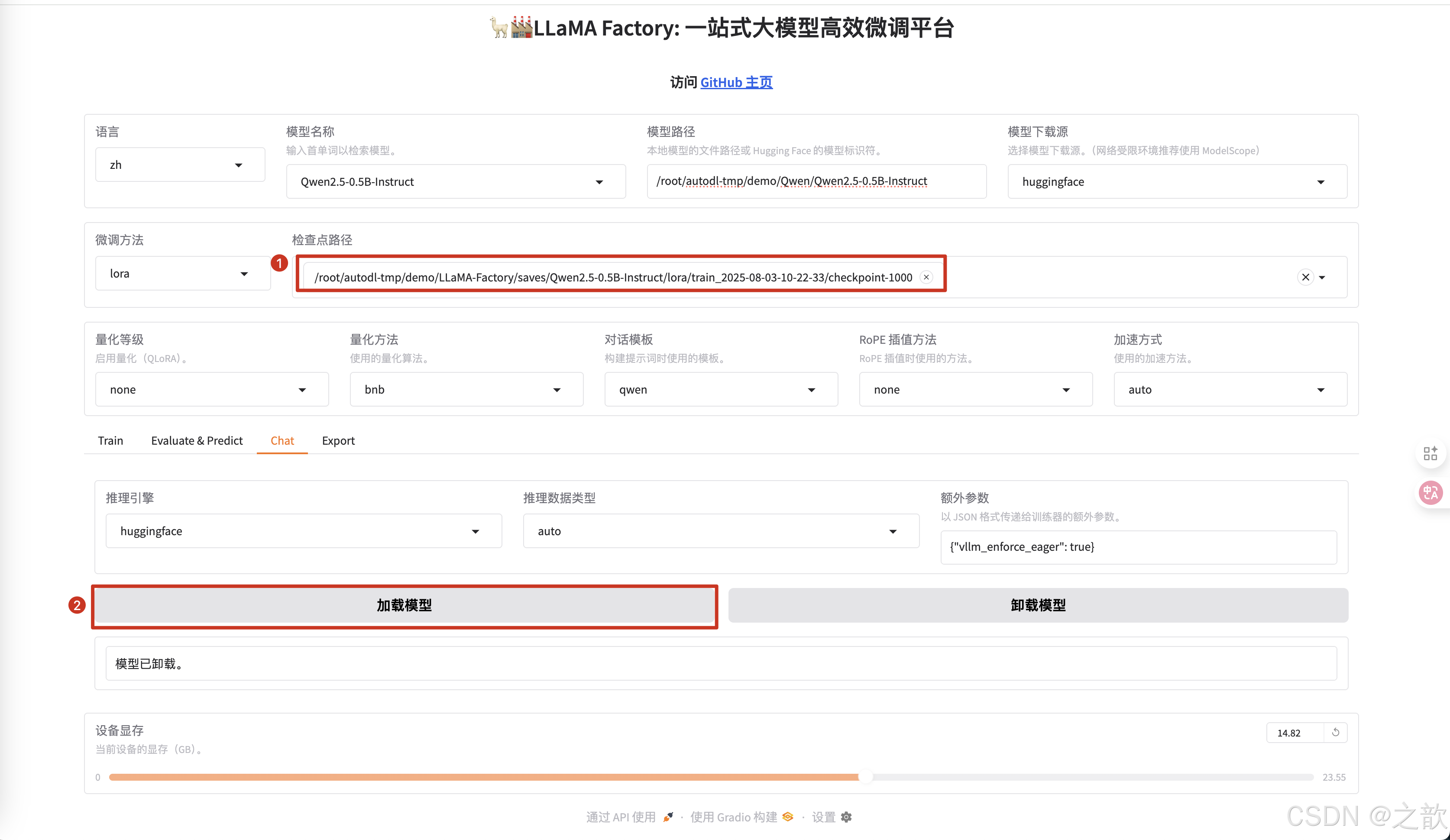
修改模型路徑為本地下載的大模型路徑 。
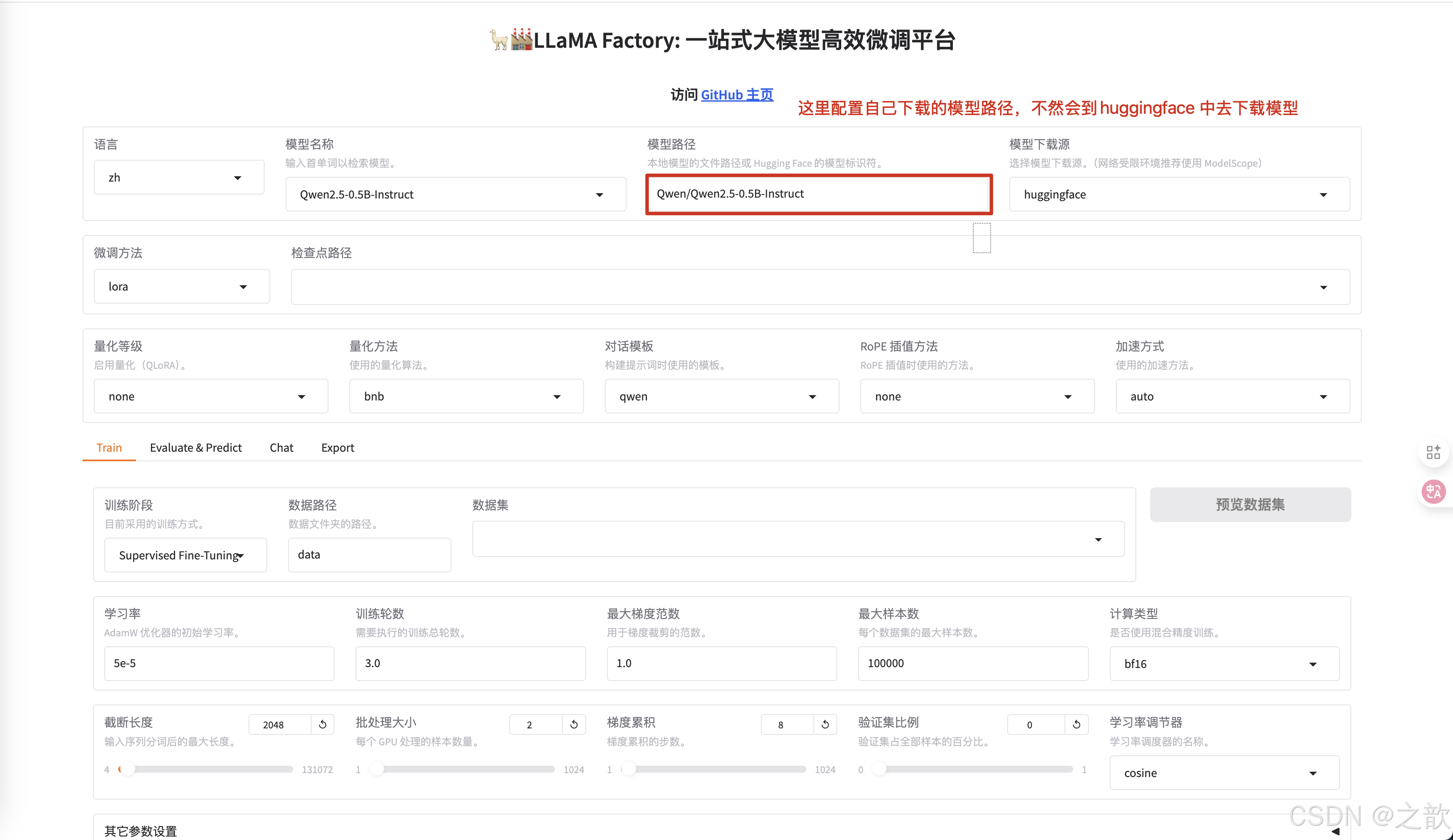
-
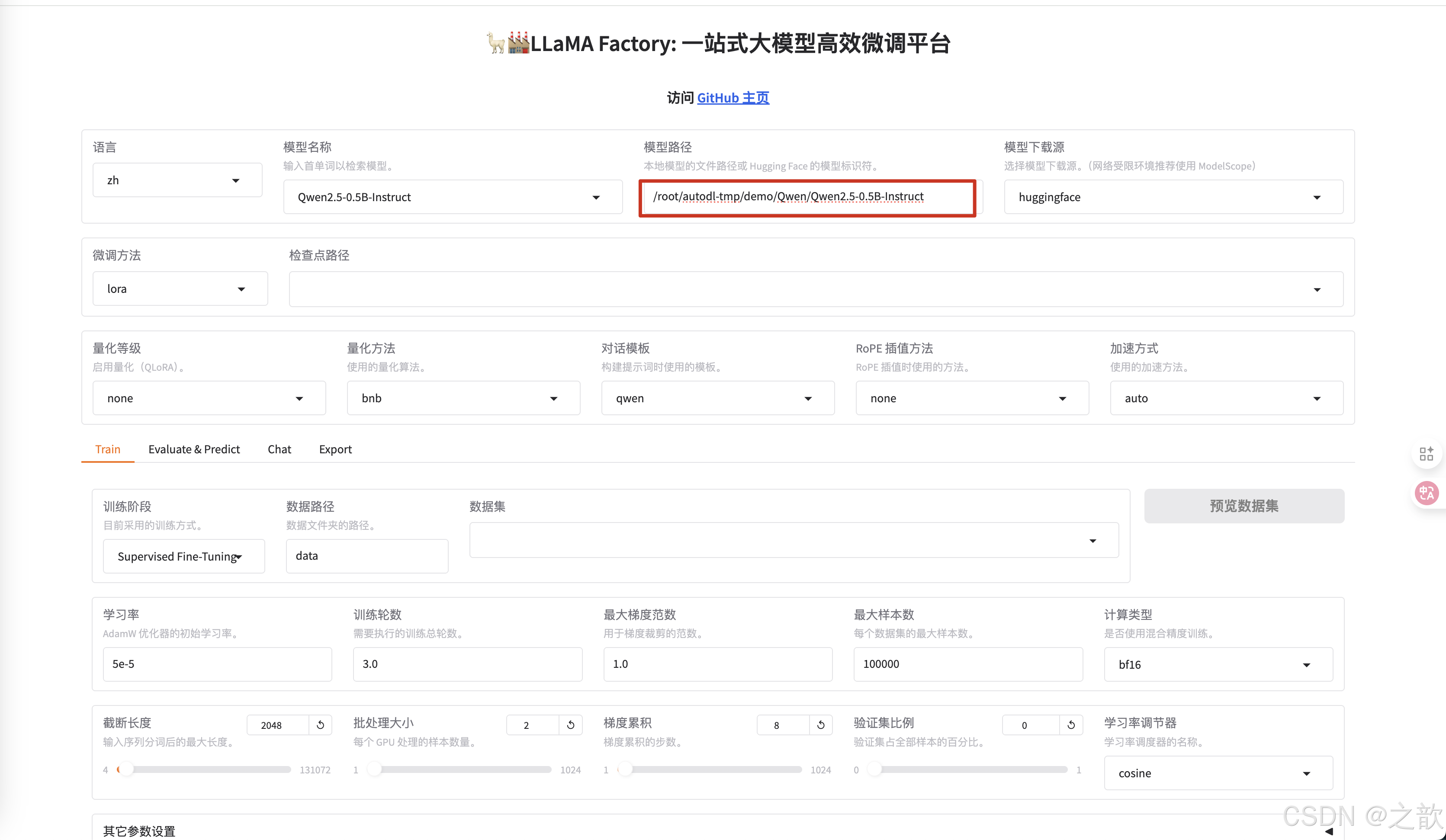
微調方法 選擇lora
-
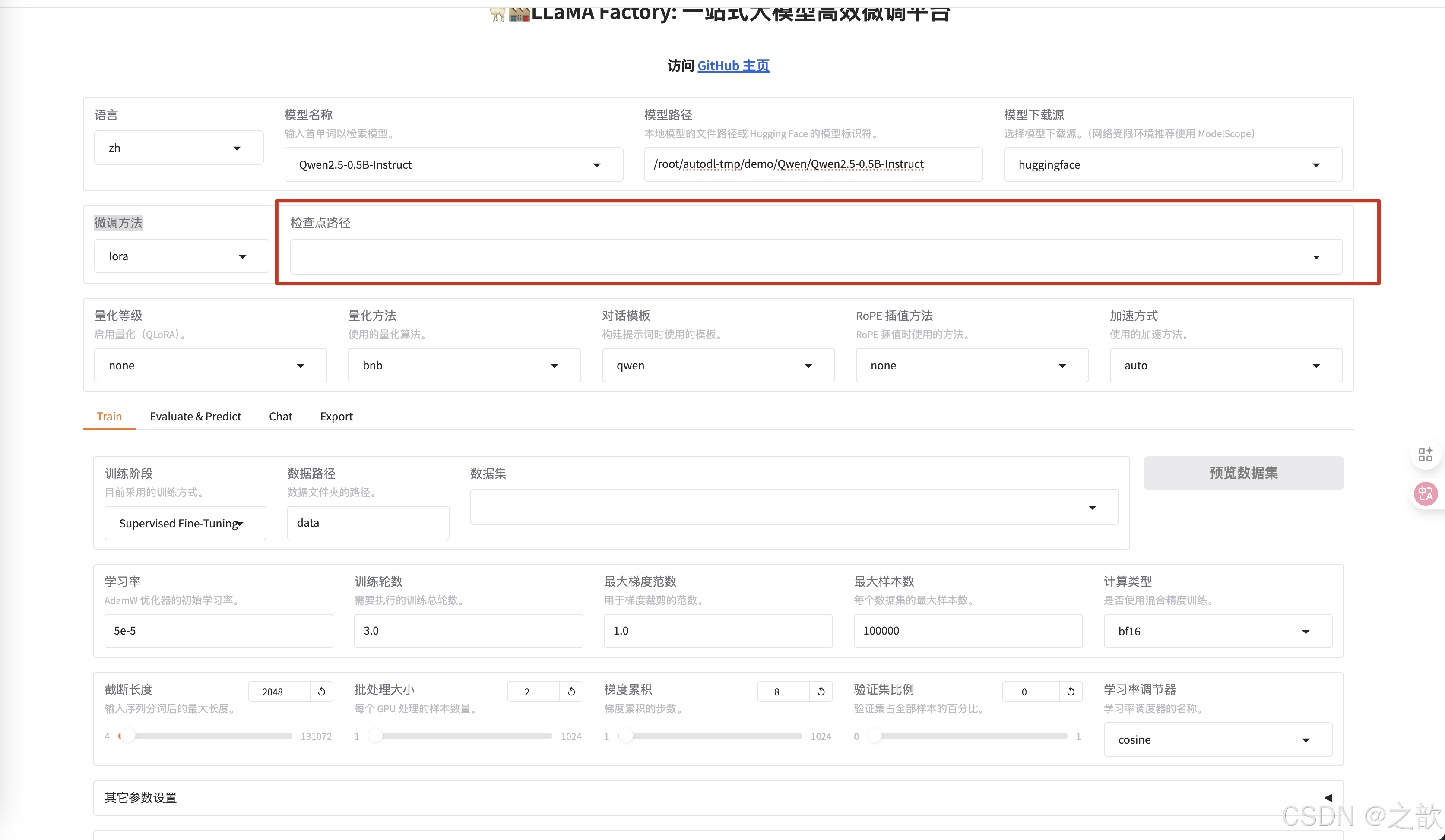
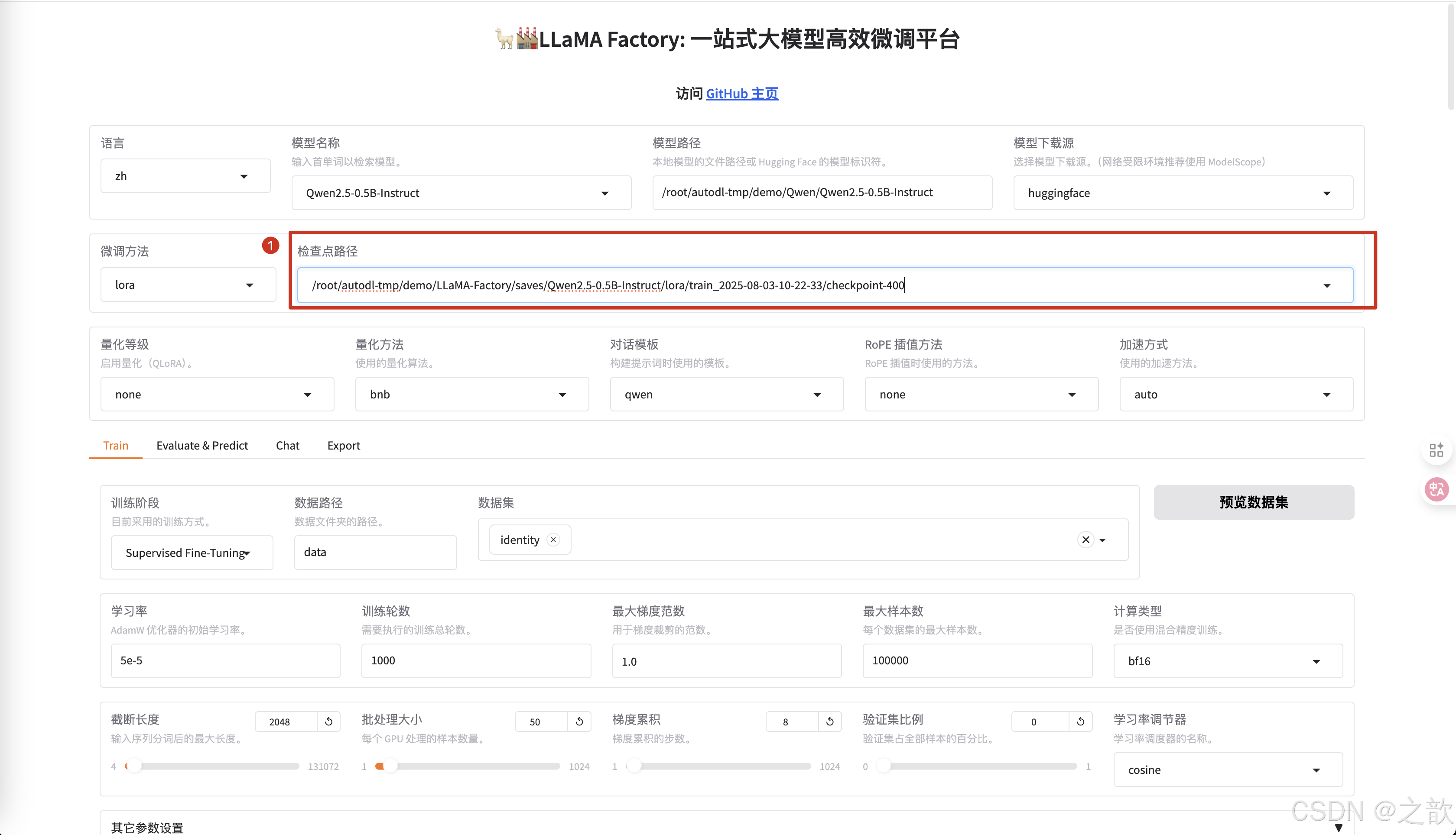
配置檢查點路徑 ,檢查點路徑就是模型微調之后的權重保存路徑 ,【用途】 訓練模型過程中,如果機器斷點或某些原因停掉了,不希望重新訓練,可以將之前訓練的模型權重加進來,這樣就可以接著訓練了。
-
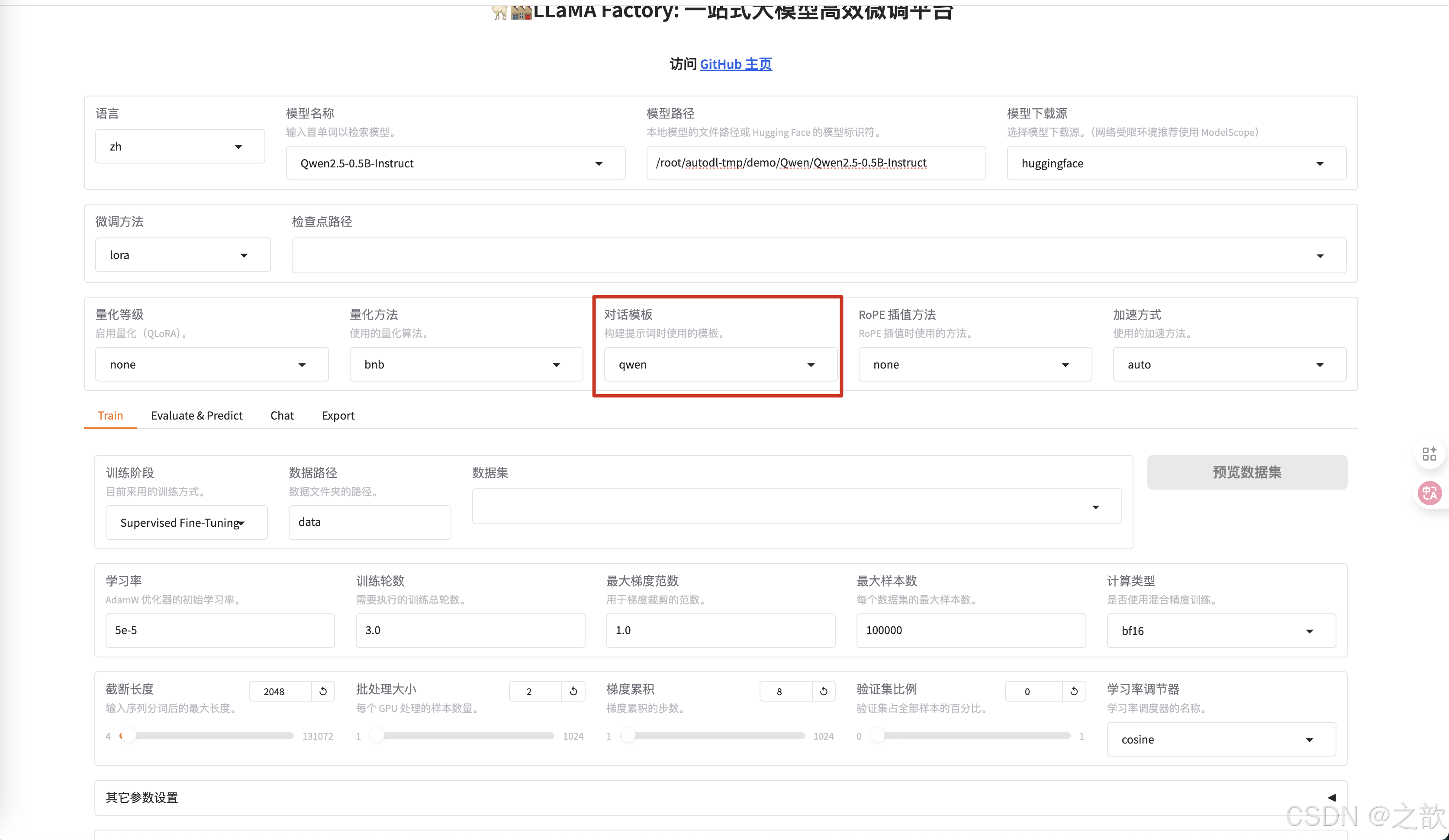
不同的模型的對話模版是不一樣的,你選擇模型之后,這里會適配一個對話模版 。
-
訓練,測試,聊天,導出
-
選擇微調訓練
-
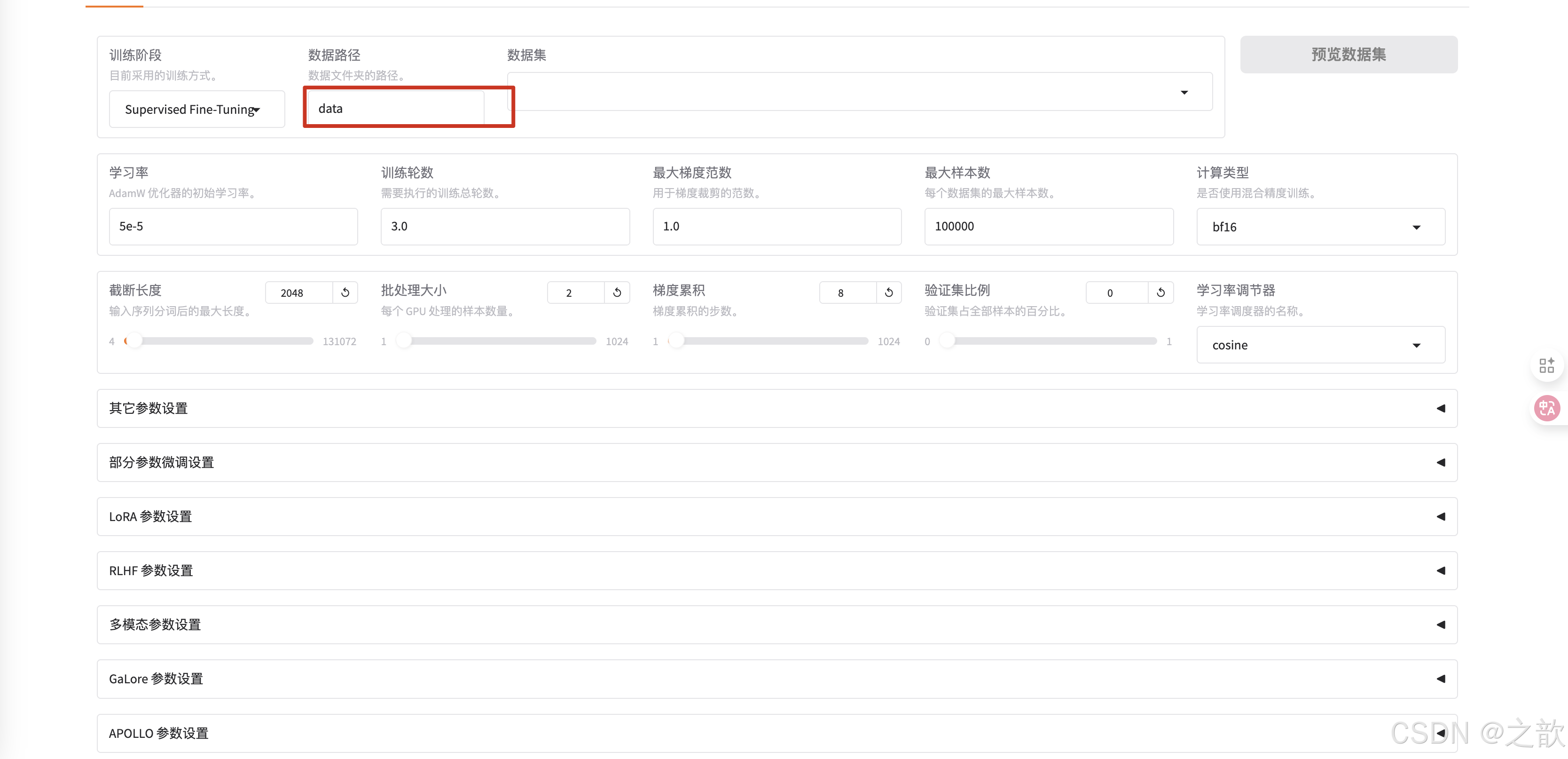
選擇數據集所在路徑 。 這個是相對路徑,因此在啟動llamafactory-cli webui時,一定要在/root/autodl-tmp/demo/LLaMA-Factory這個目錄下。
-
選擇之前修改的數據集identity
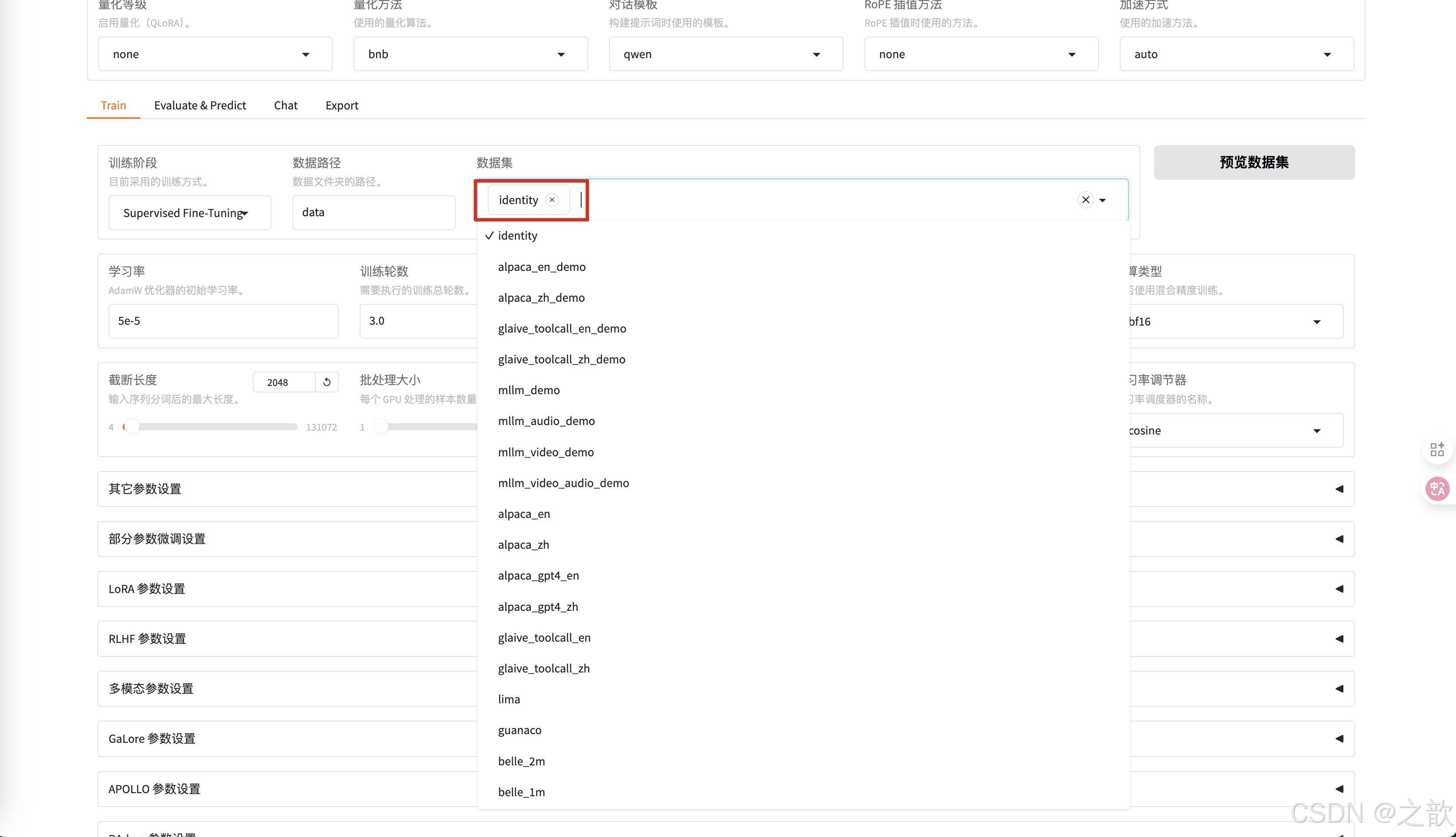
-
可以查看是否是之前自己改過的數據集
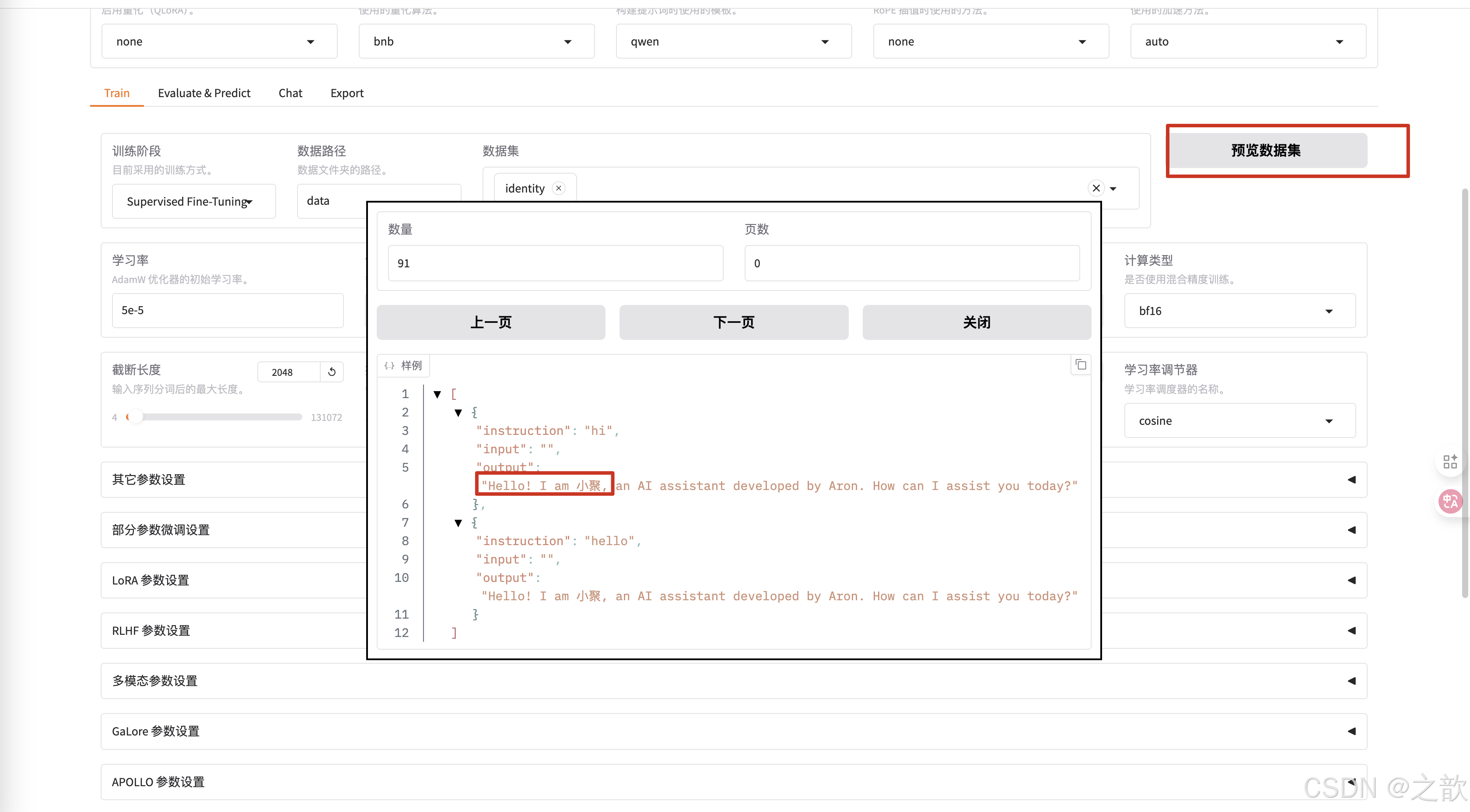
-
學習率一般不需要修改,使用默認即可。
-
訓練輪數 一般改大一些,這里設置1000 ,一般 要設置300以上才有效果
-
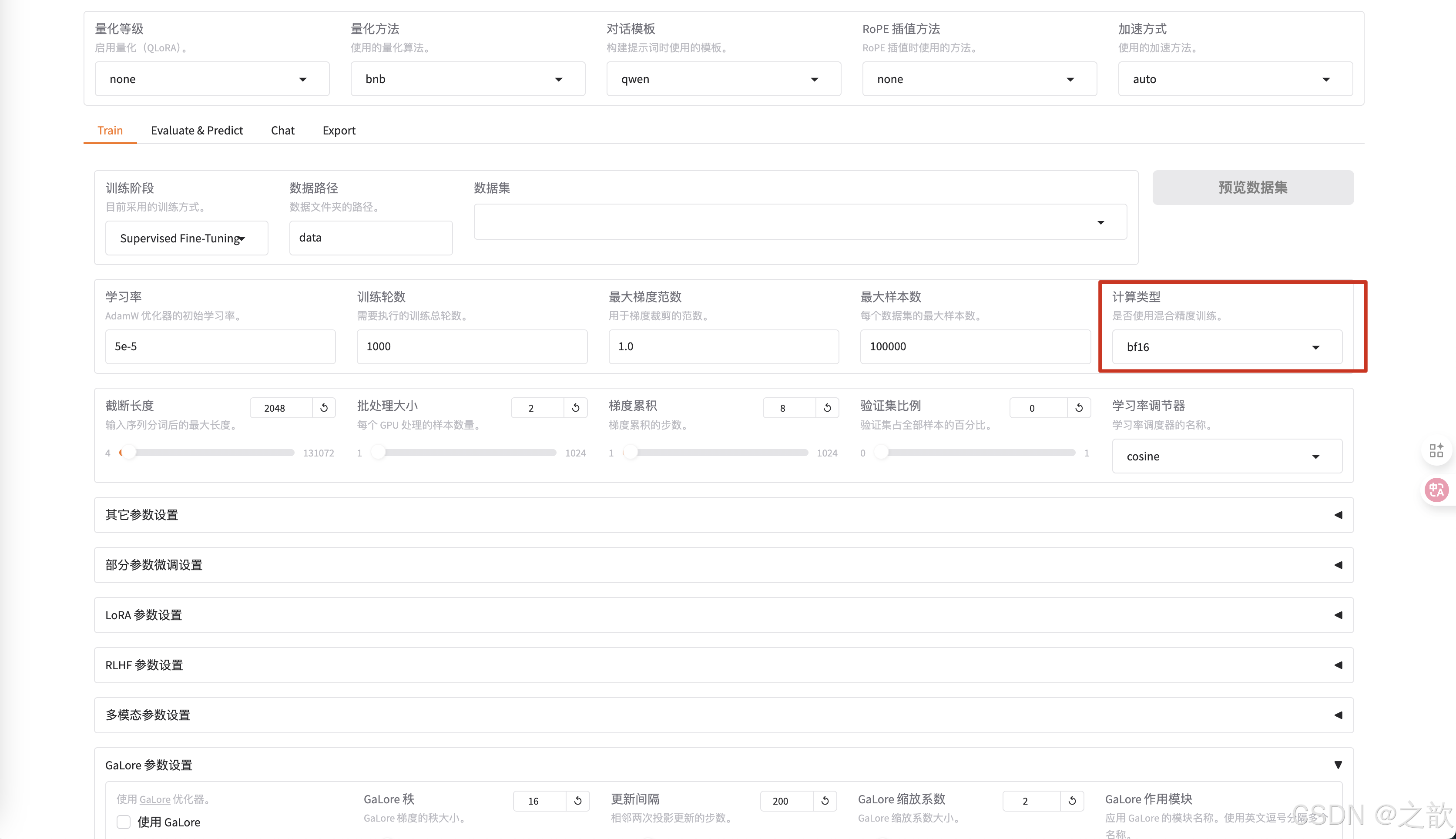
最大梯度范數,最大樣本數 用默認值即可。
-
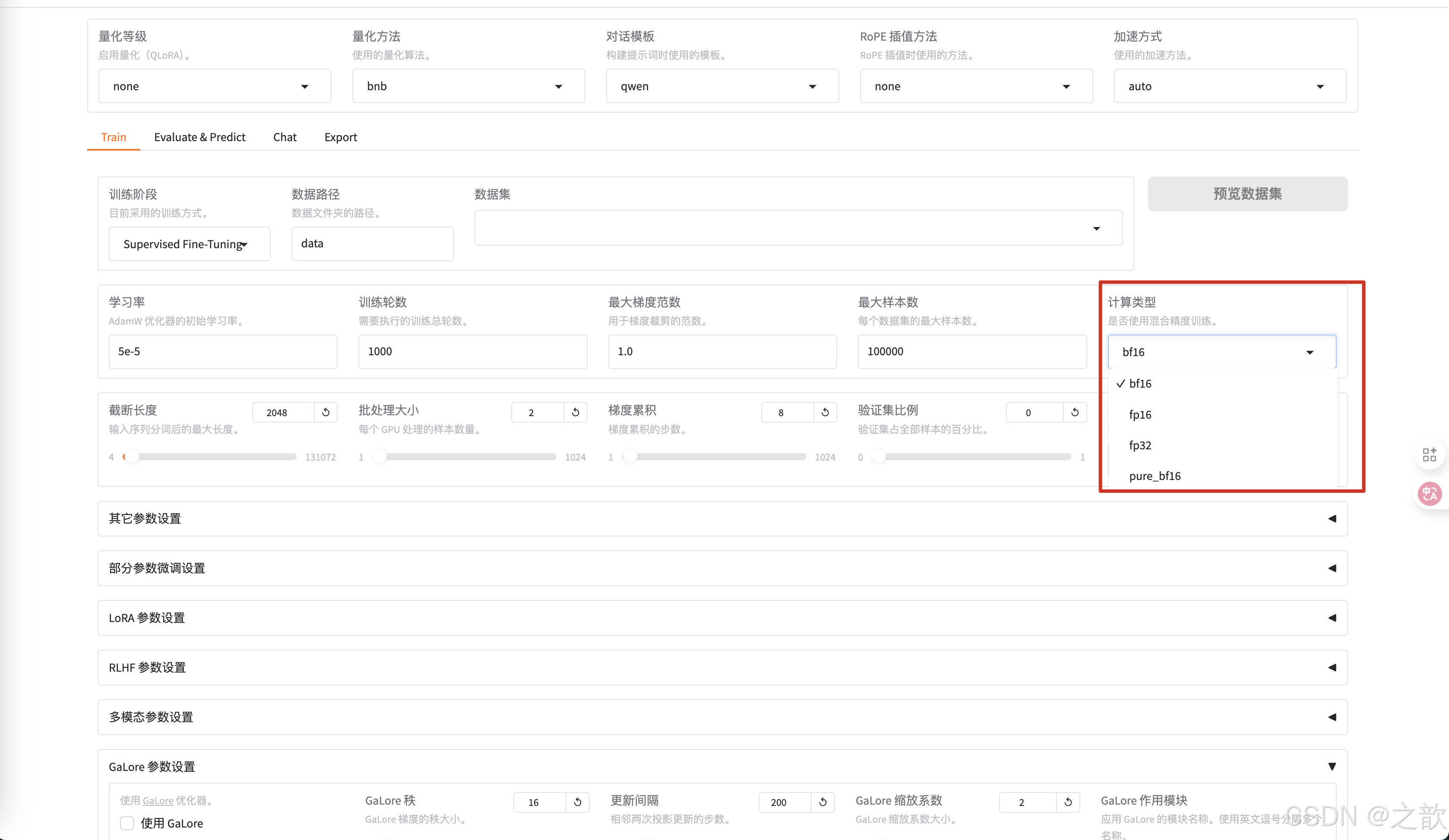
計算類型選擇bf16 , 千萬不要選擇fp32,沒有意義,這個是用來加速用的。 相當于你量化精度
-
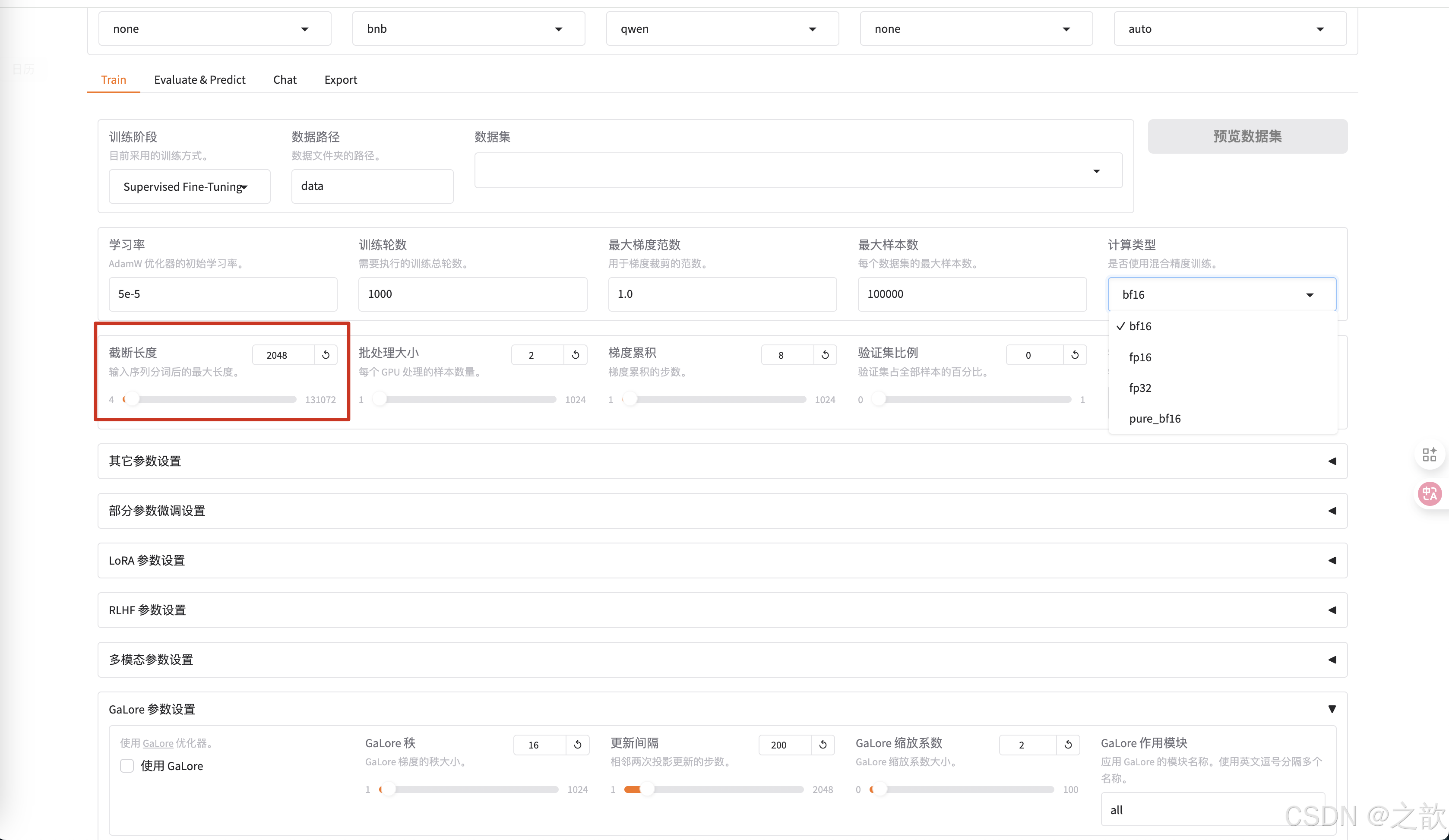
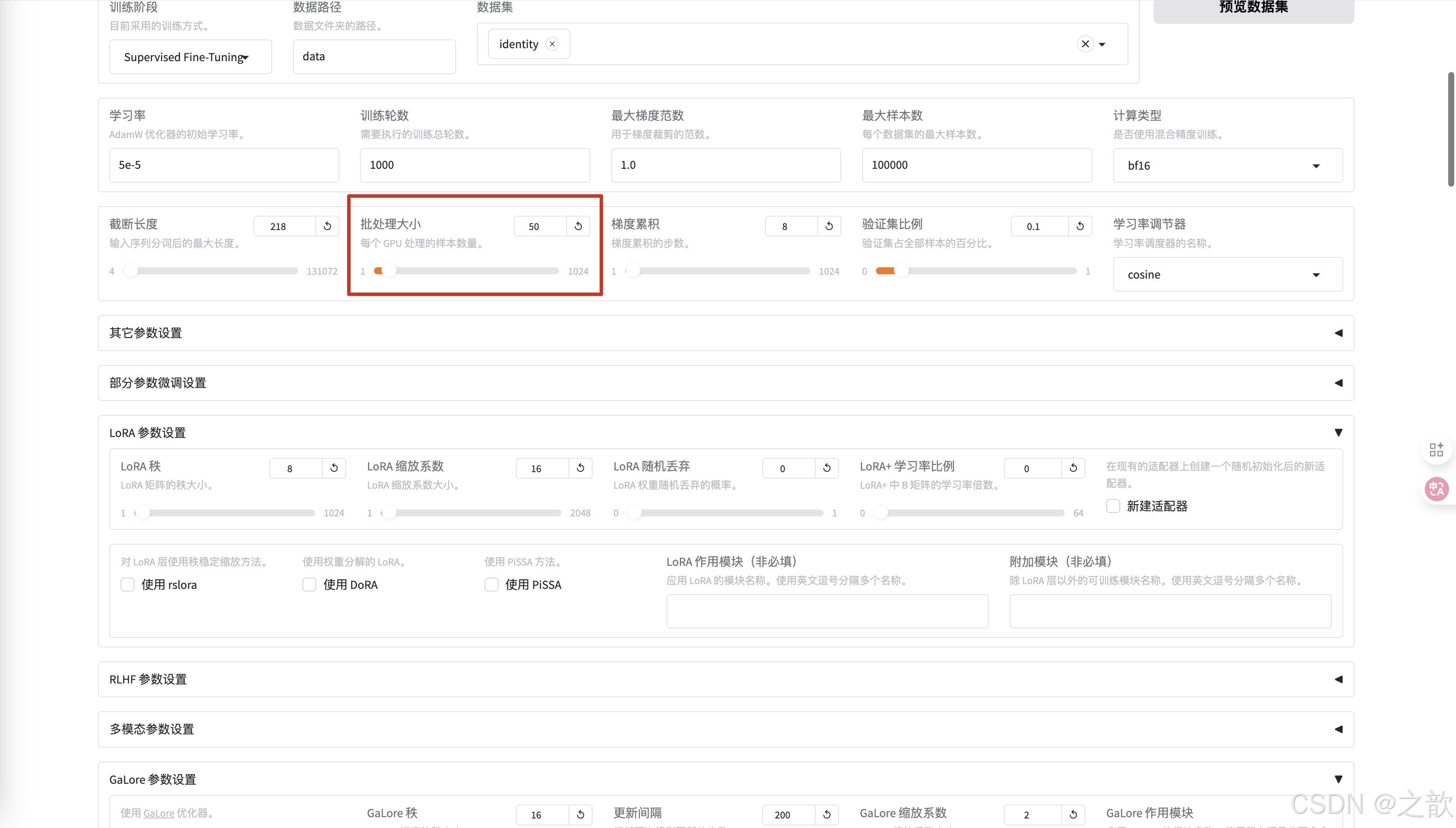
截斷長度 ,相當于max-length。 根據數據長度來設置這個值,相當于截斷長度 。 這個值越小,顯存占用量越小 。
-
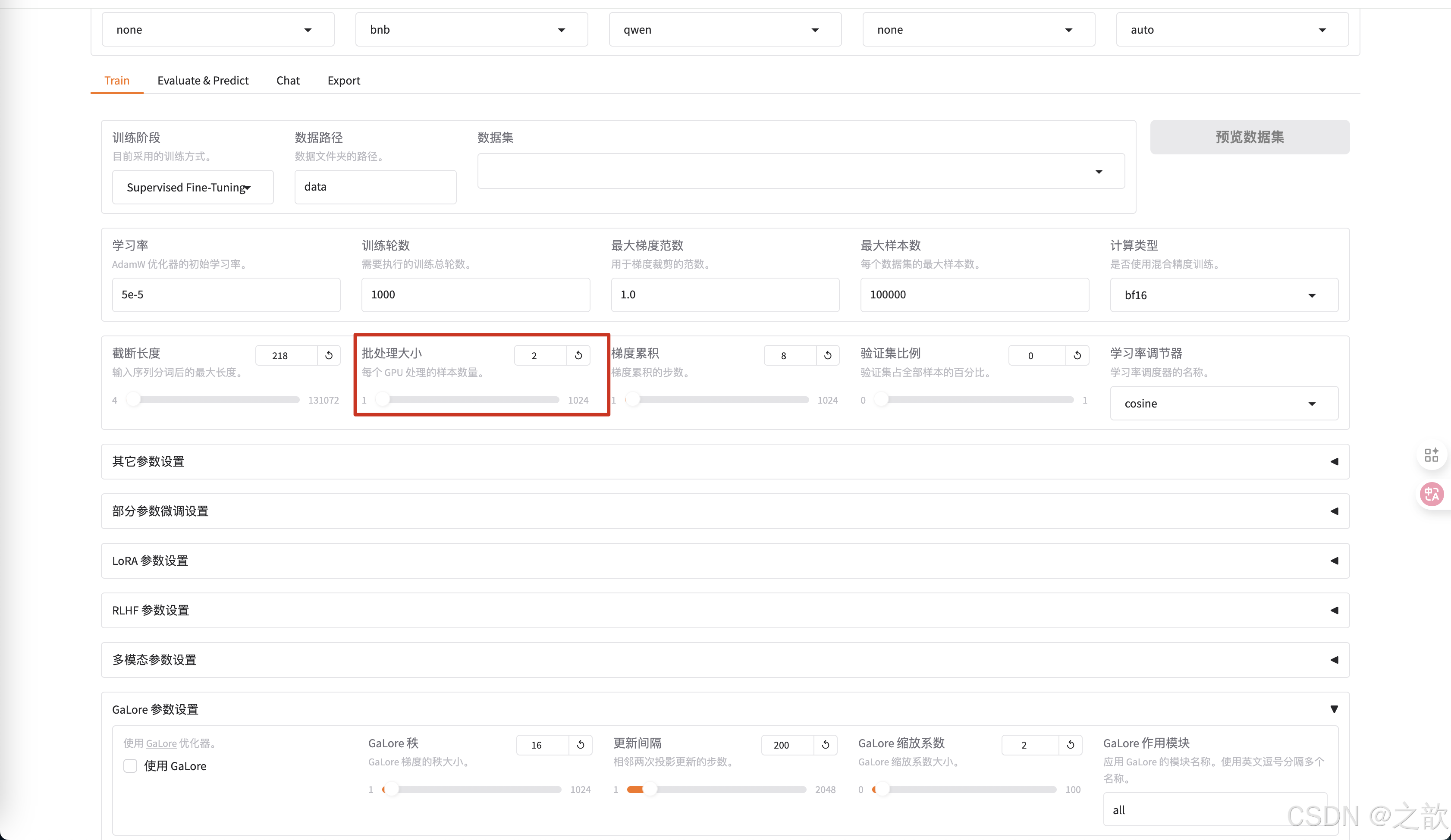
批處理大小 ,和顯存的大小有關,根據自己的顯存大小來調整。
-
梯度累積 一般使用默認值
-
驗證集比例,可以不給,如果是數據集,驗證集 ,測試集是8:1:1 ,則設置 10% 即可,如果是數據集,驗證集 ,測試集是7:2:1,則可以設置20% 。當然也可以不給,根據自己的實際情況來設置 。
-
學習率調節器使用默認
-
如果想控制LoRA,可以看LoRA參數設置 ,首先看LoRA的秩,LoRA的秩是LoRA的矩陣大小,這個值越大,權限矩陣就越大 。
-
LoRA 縮放系數 ,剛剛開始微調的時候,使用默認參數即可。 這個參數調整是有技巧的。
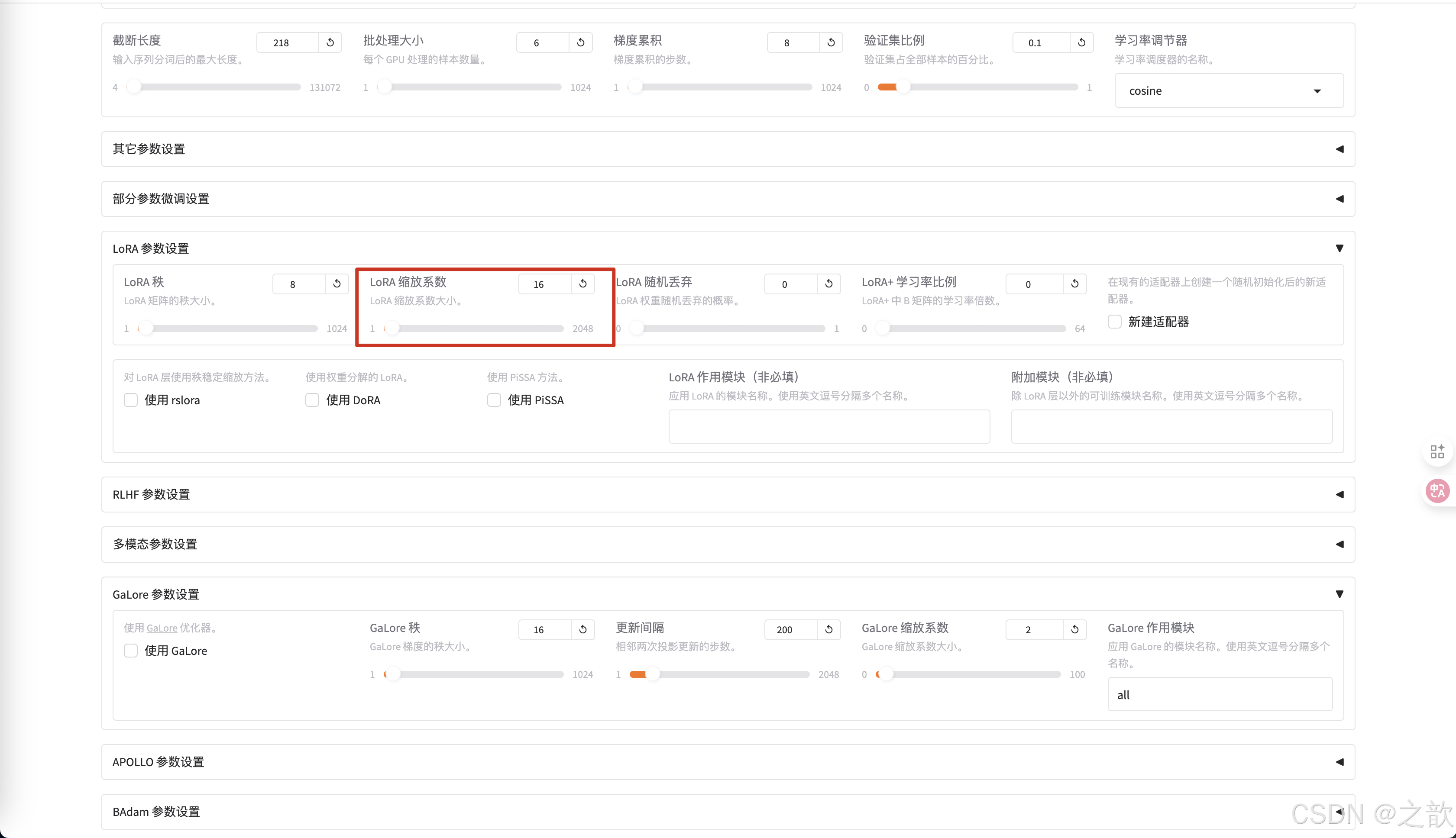
-
可以查看預覽命令
-
輸出目錄 ,權重的保存路徑
-
配置路徑 ,本次配置保存路徑
-
自己訓練的顯卡數量
-
點擊開始進行訓練
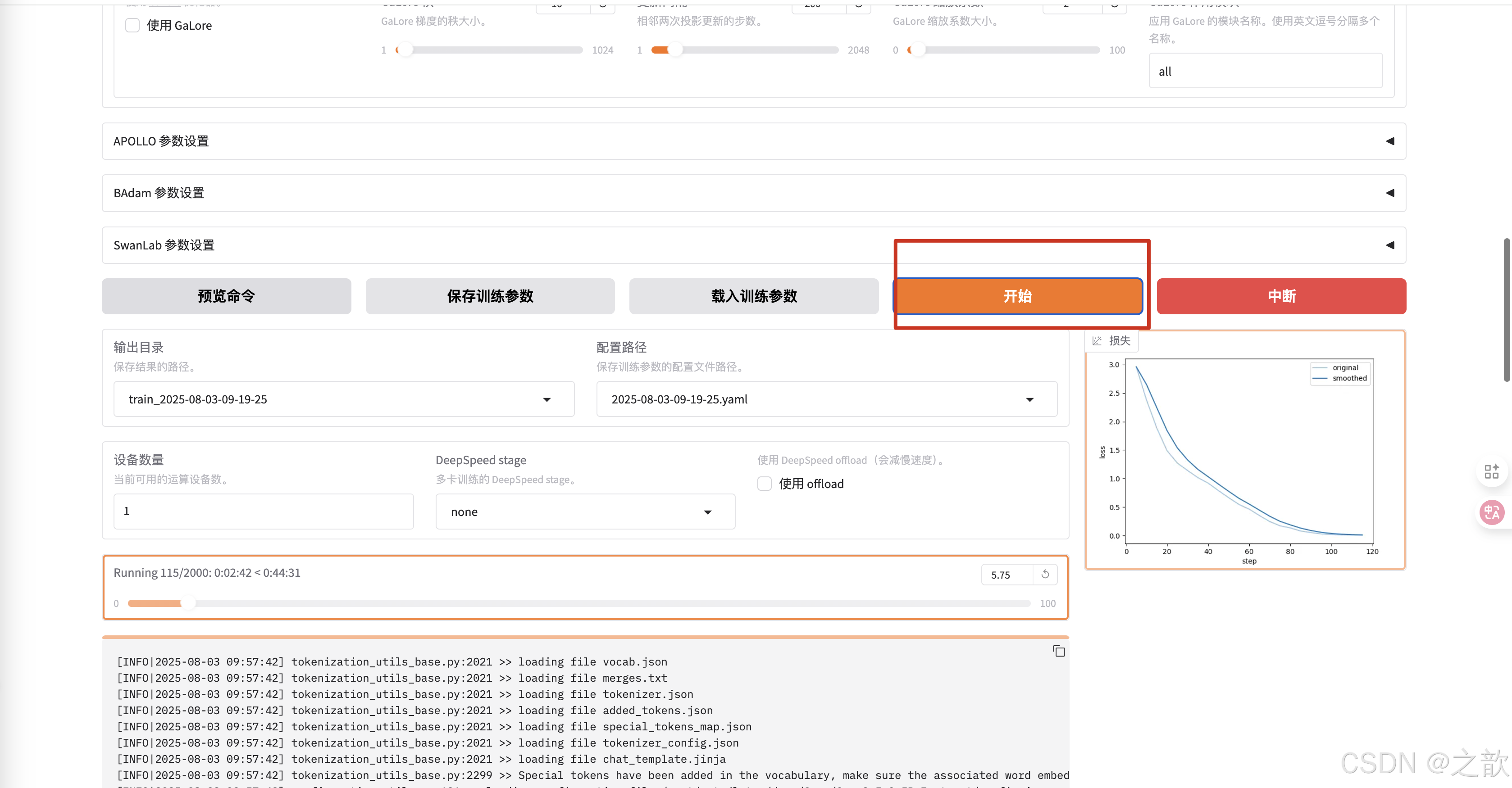
整個過程還是比較簡單的
- 配置模型
- 配置數據
- 配置參數
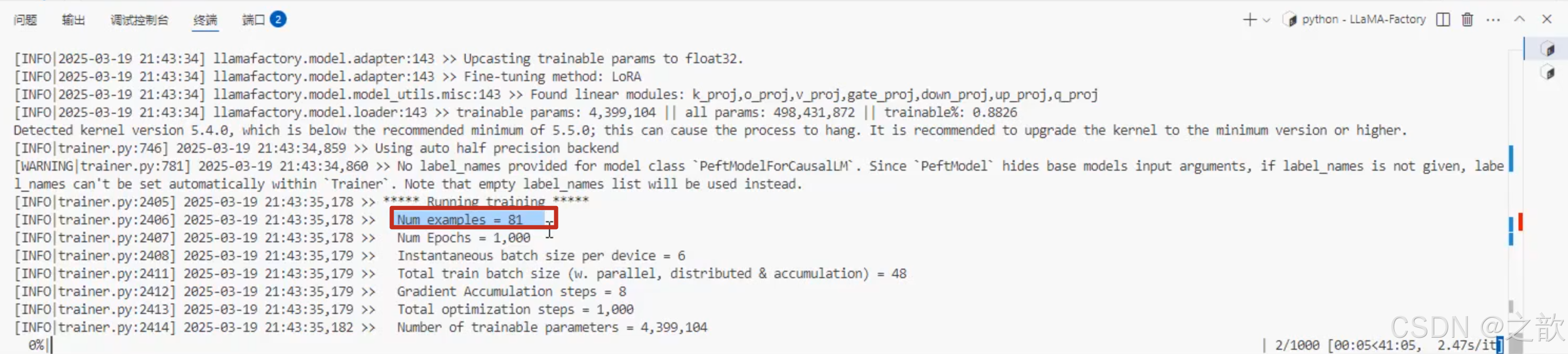
Num examples = 81 # 計算出來,整體樣本數量
Num Epochs = 1,000 # 輪次是1000
Instantaneous batch size per device = 6 # 批次是6
Total train batch size (w. parallel, distributed & accumulation) = 48 Gradient Accumulation steps = 8
Total optimization steps = 1,000
Number of trainable parameters = 4,399,104
可以查看自己配置的批次合不合理,先conda install -c conda-forge nvitop
再運行nvitop
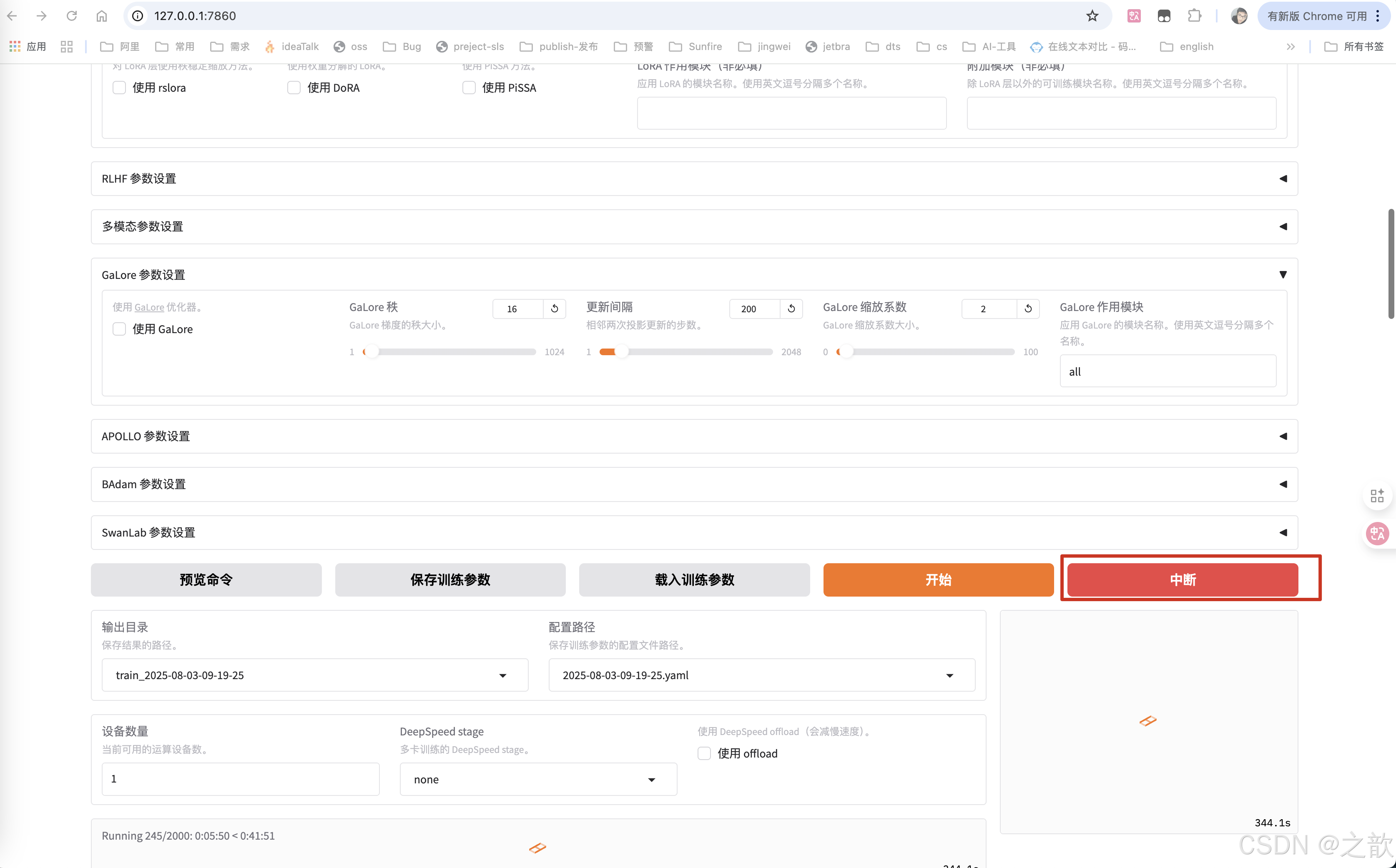
如果發現顯存占用量少。可以點擊中斷
修改批處理大小
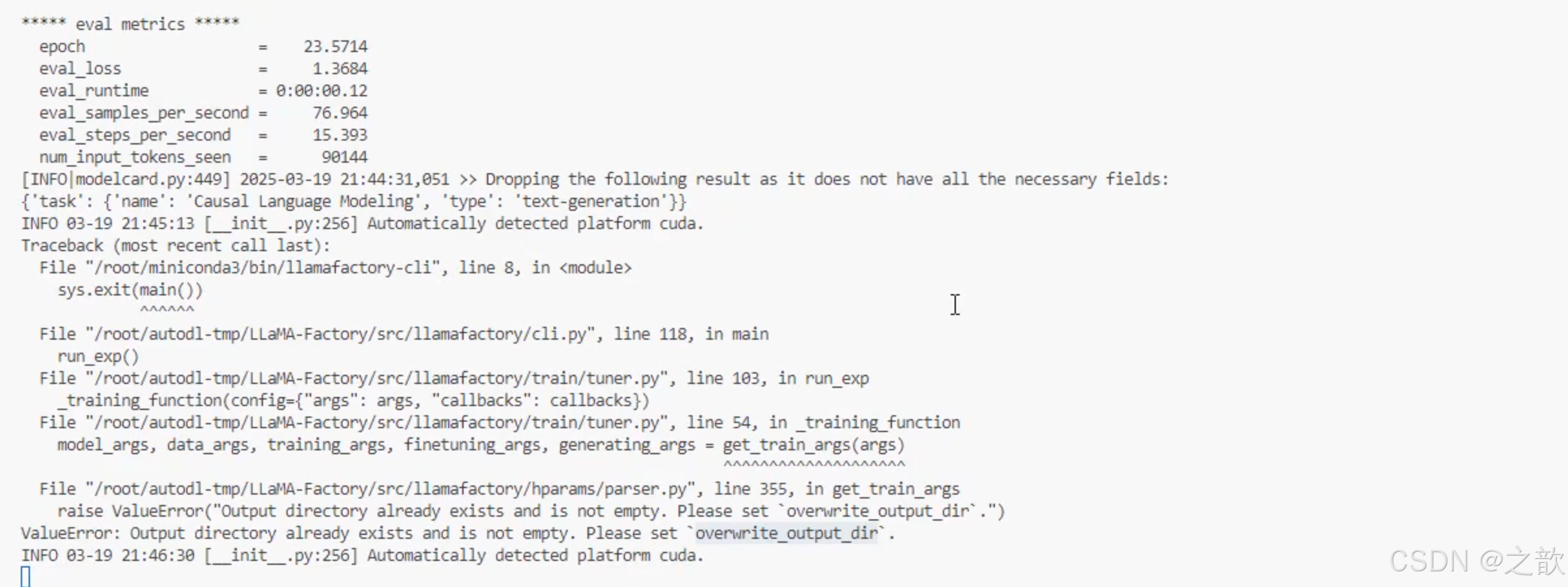
如果中斷之后,再次啟動報如下錯誤
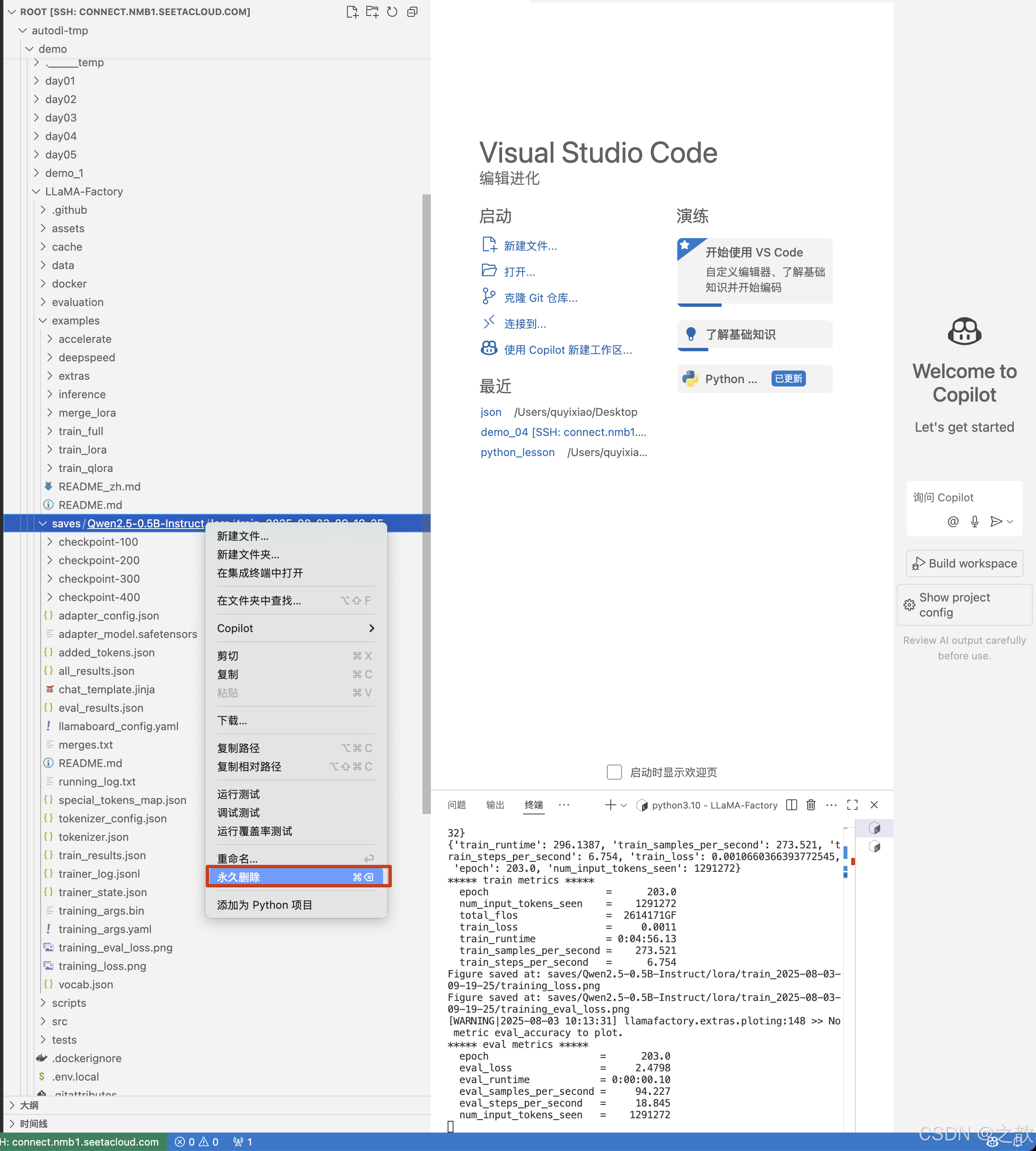
將/root/autodl-tmp/demo/LLaMA-Factory/saves/Qwen2.5-0.5B-Instruct/lora/train_2025-08-03-09-19-25永久刪除即可 。
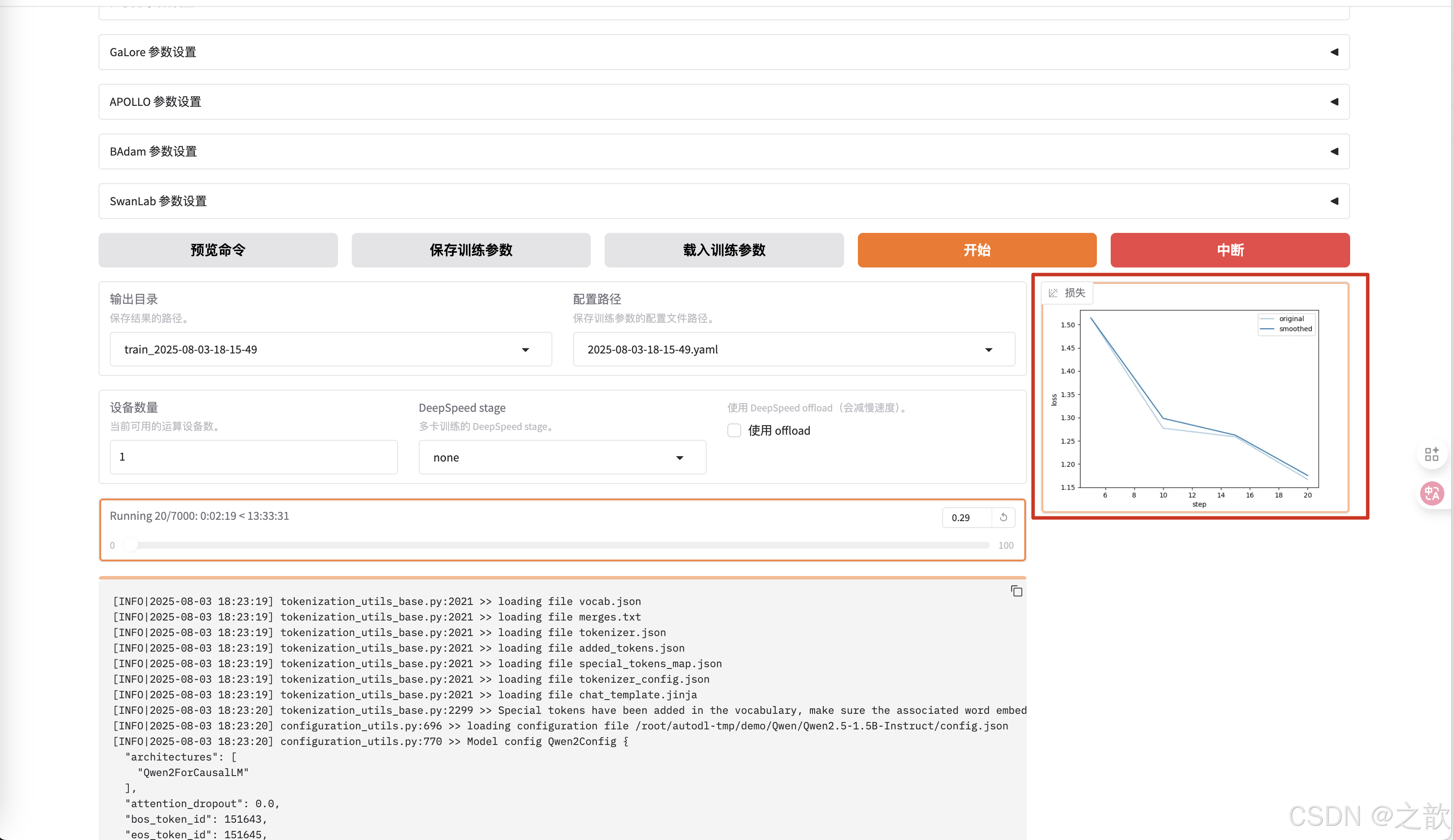
如果訓練的次數到達,如果損失精度持平了,按道理訓練好了。
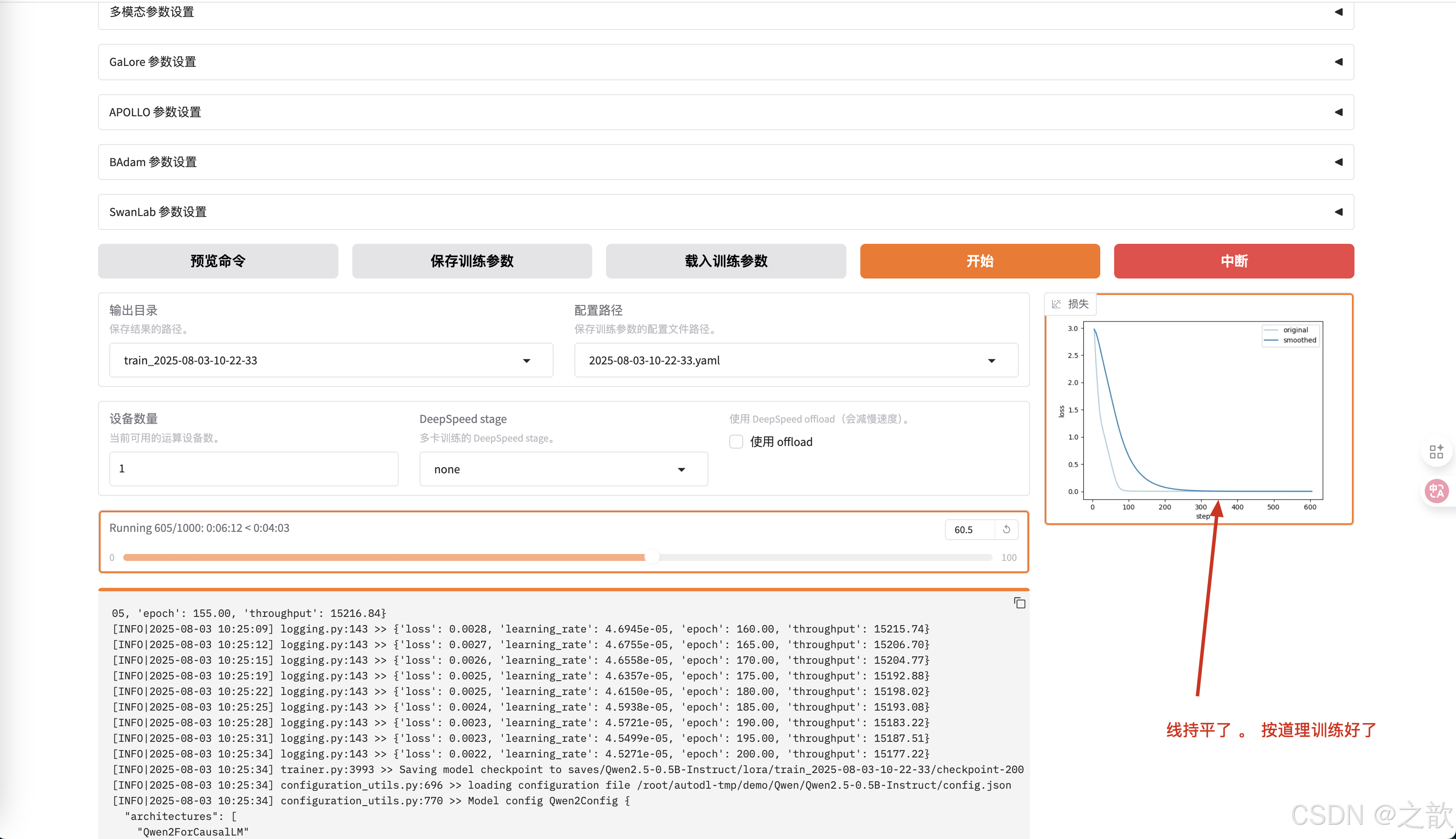
一般這個損失精度要變成平線,才可以當作訓練完成 。 損失往下降,則證明訓練是有效的 。
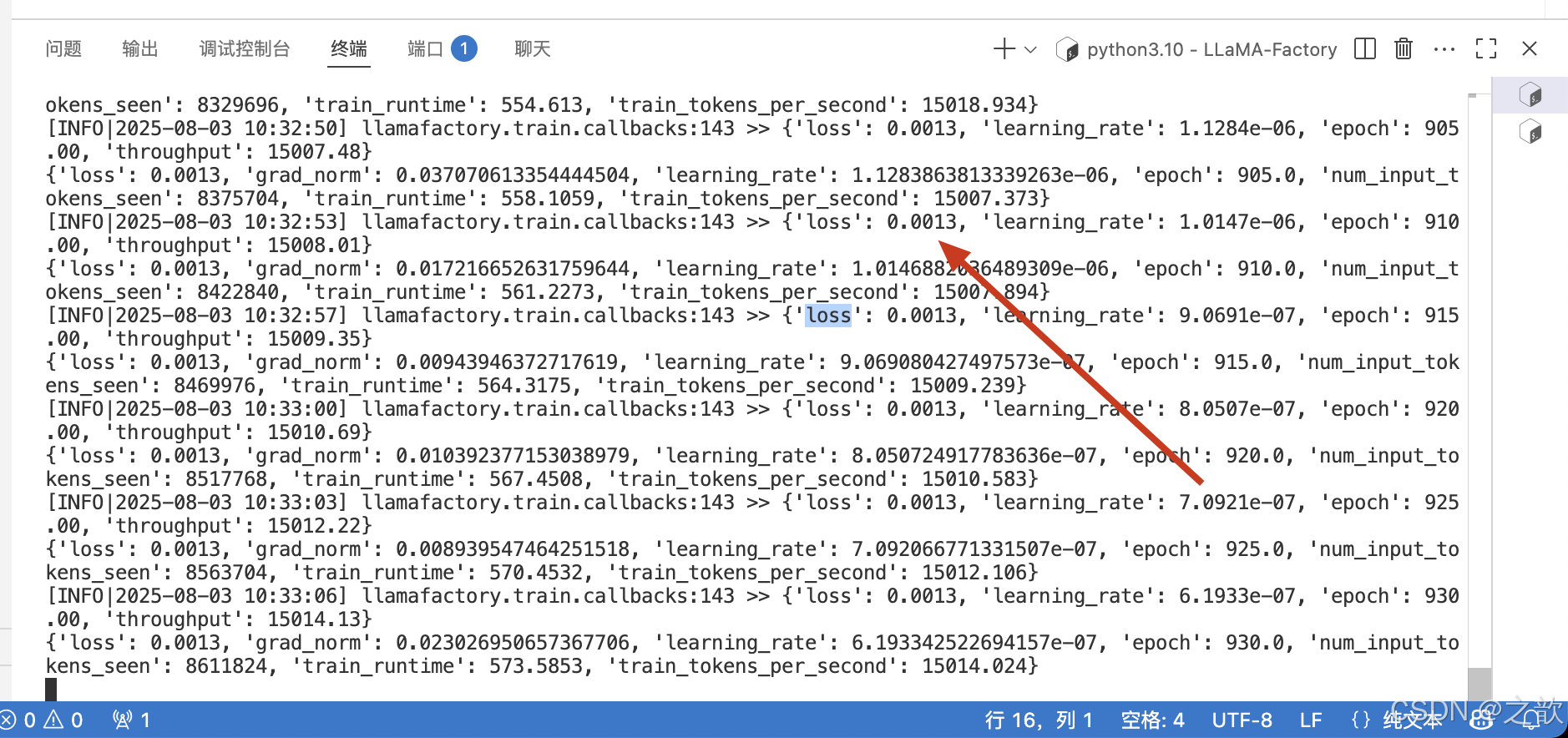
當然,從控制臺上也可以看到損失精度 。 精度越少,則證明模型訓練得越好。
llmafactory 默認訓練100次保存一次權重 。
如果要調整這個權重保存次數,則可以在其他參數設置-> 保存間隔中進行修改
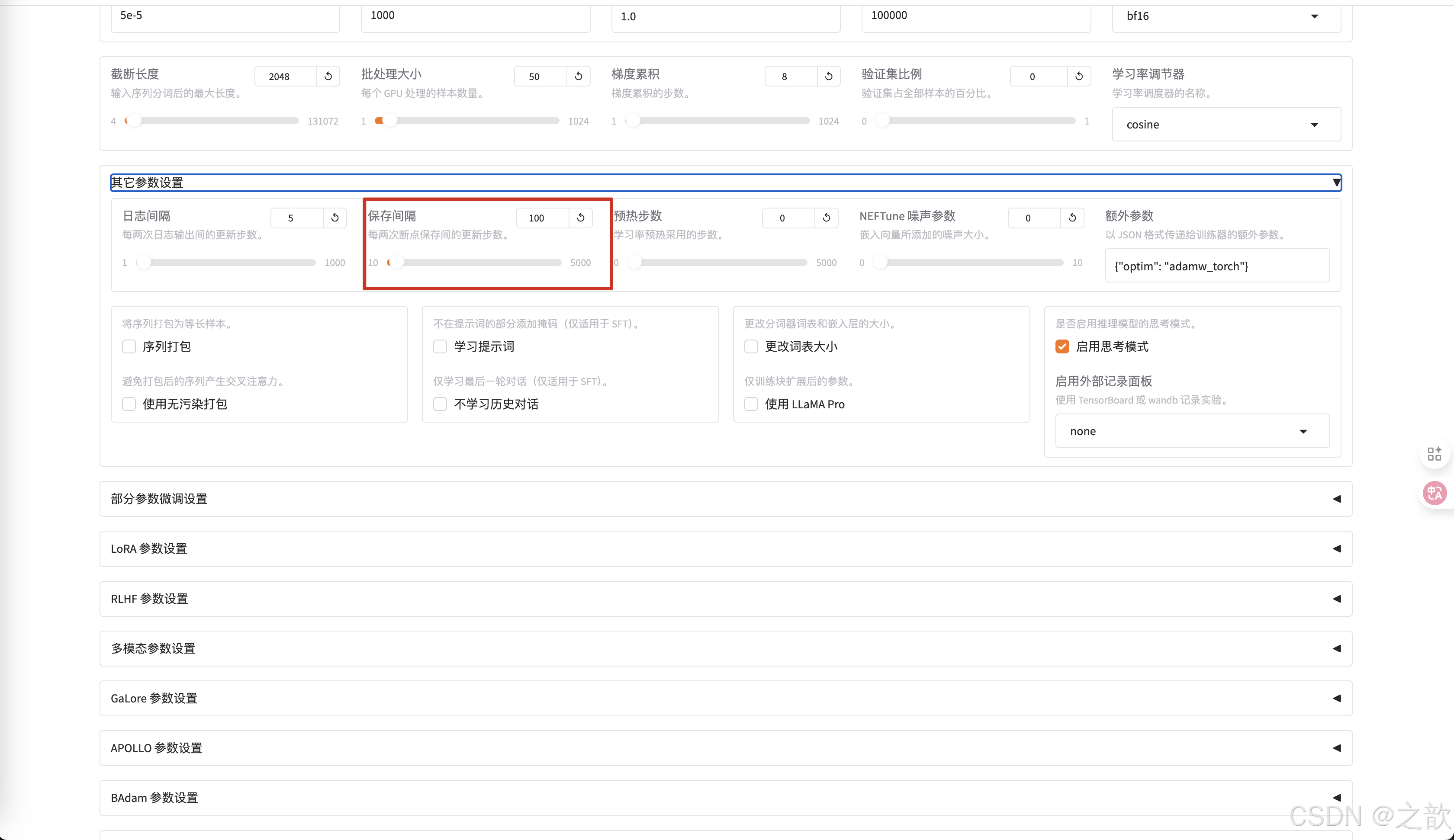
當然可以修改日志間隔 ,當訓練完成,可以看到最終損失精度的保存圖像 。
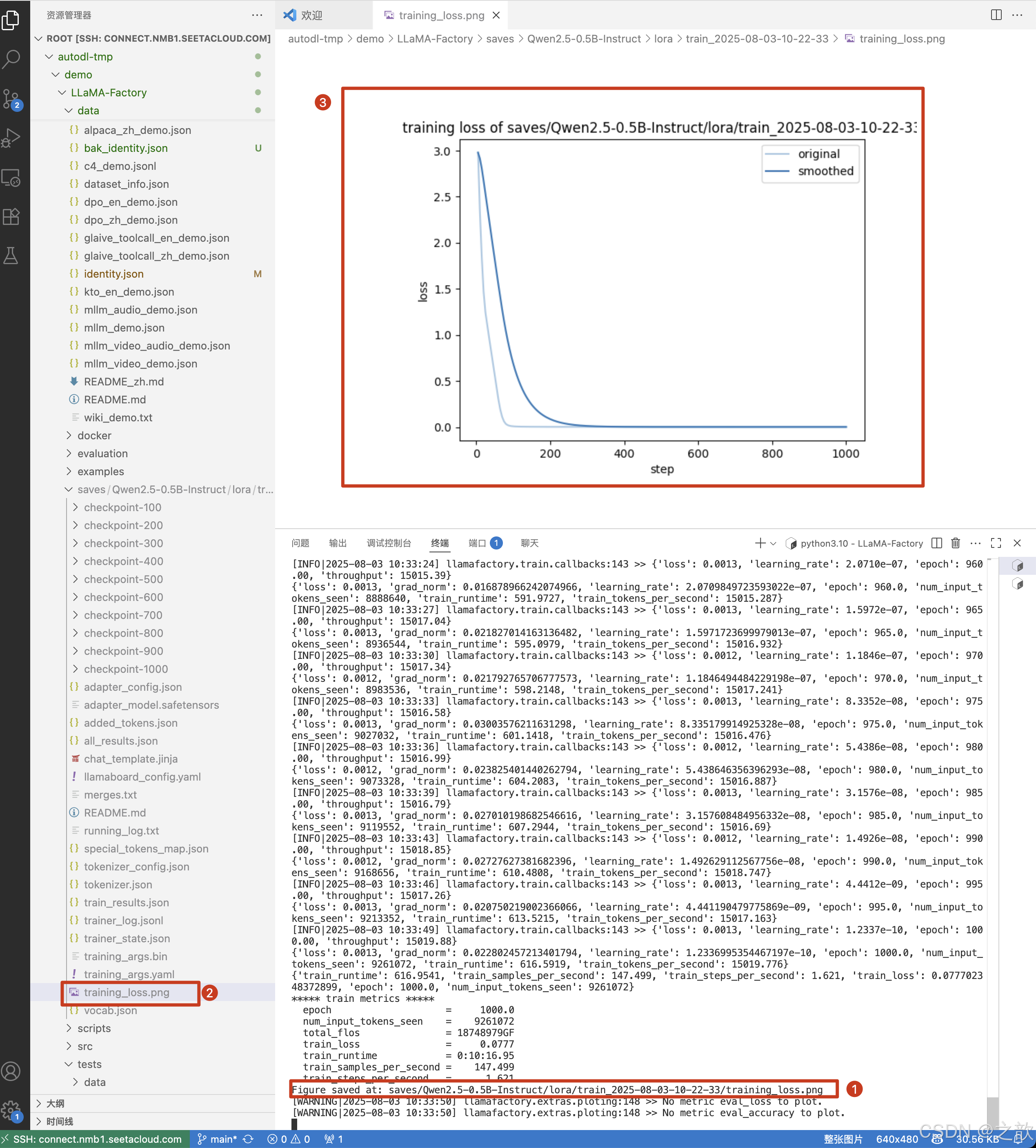
如何進行繼續訓練
-
設置檢測點路徑
-
修改輸出目錄
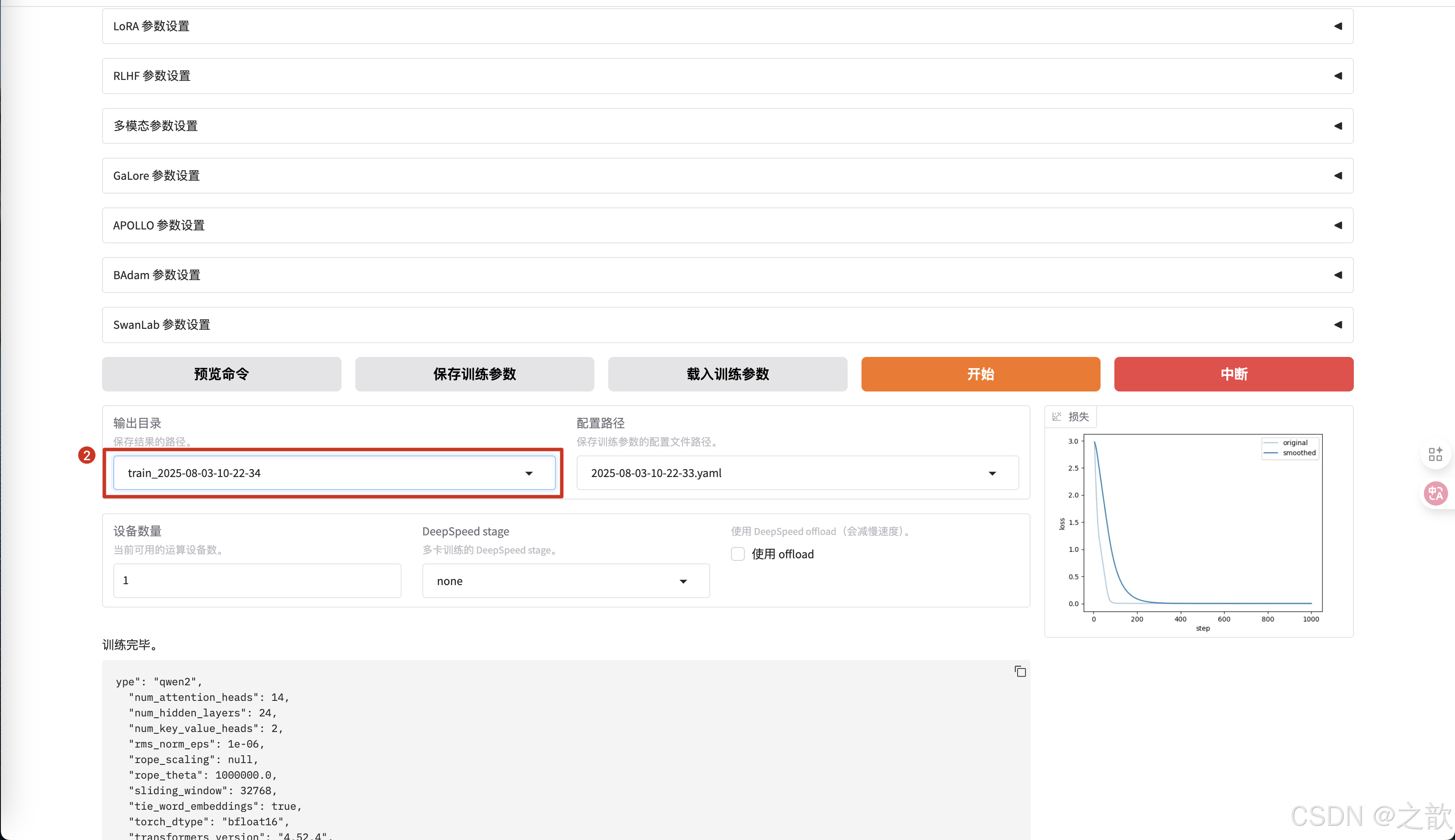
-
點擊開始后,從控制臺中可以看到,生成了新的權重 ,并且精度重新開始計算 。
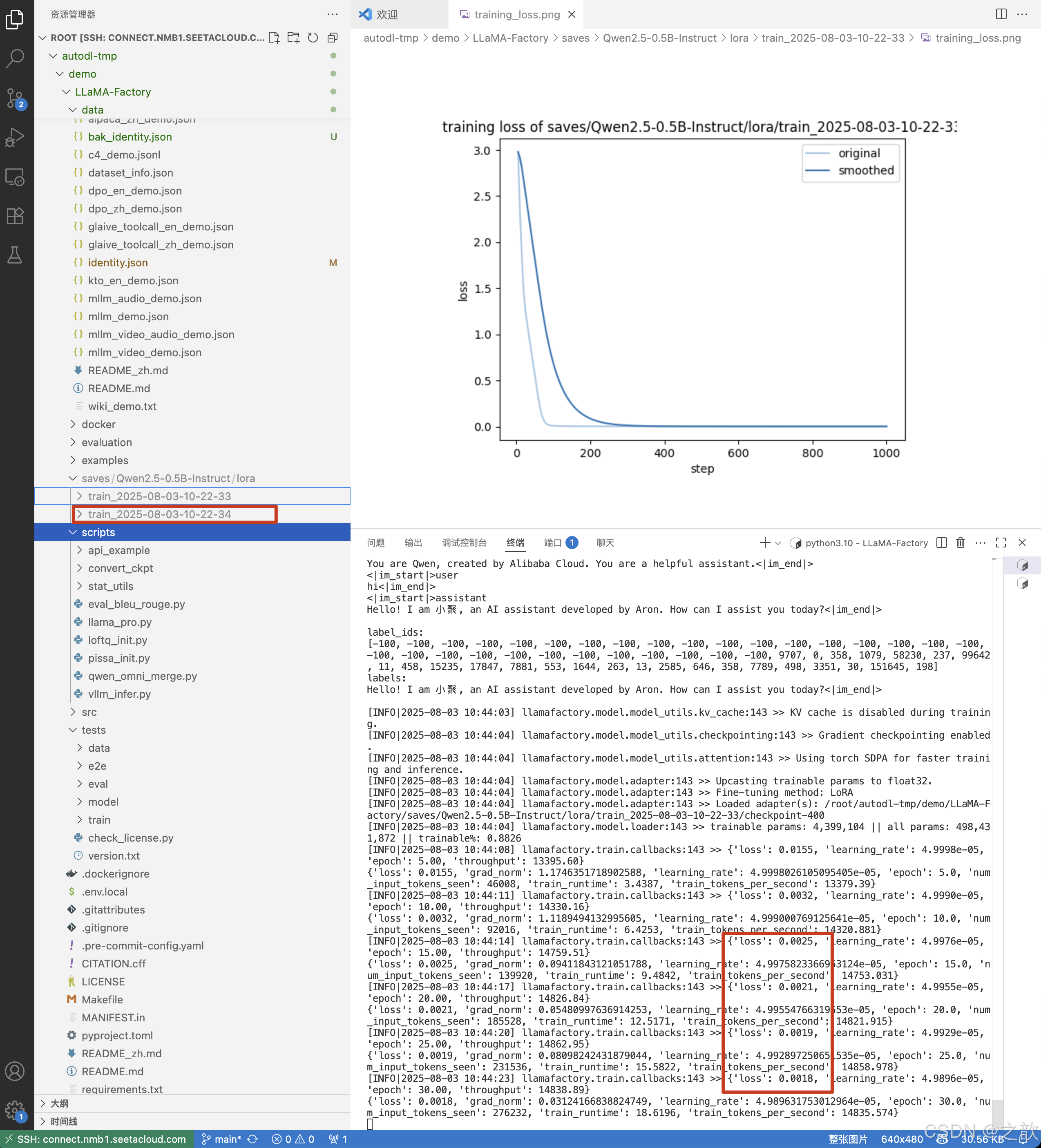
-
訓練完成之后,加載模型測試, 先不使用檢測點路徑測試 。
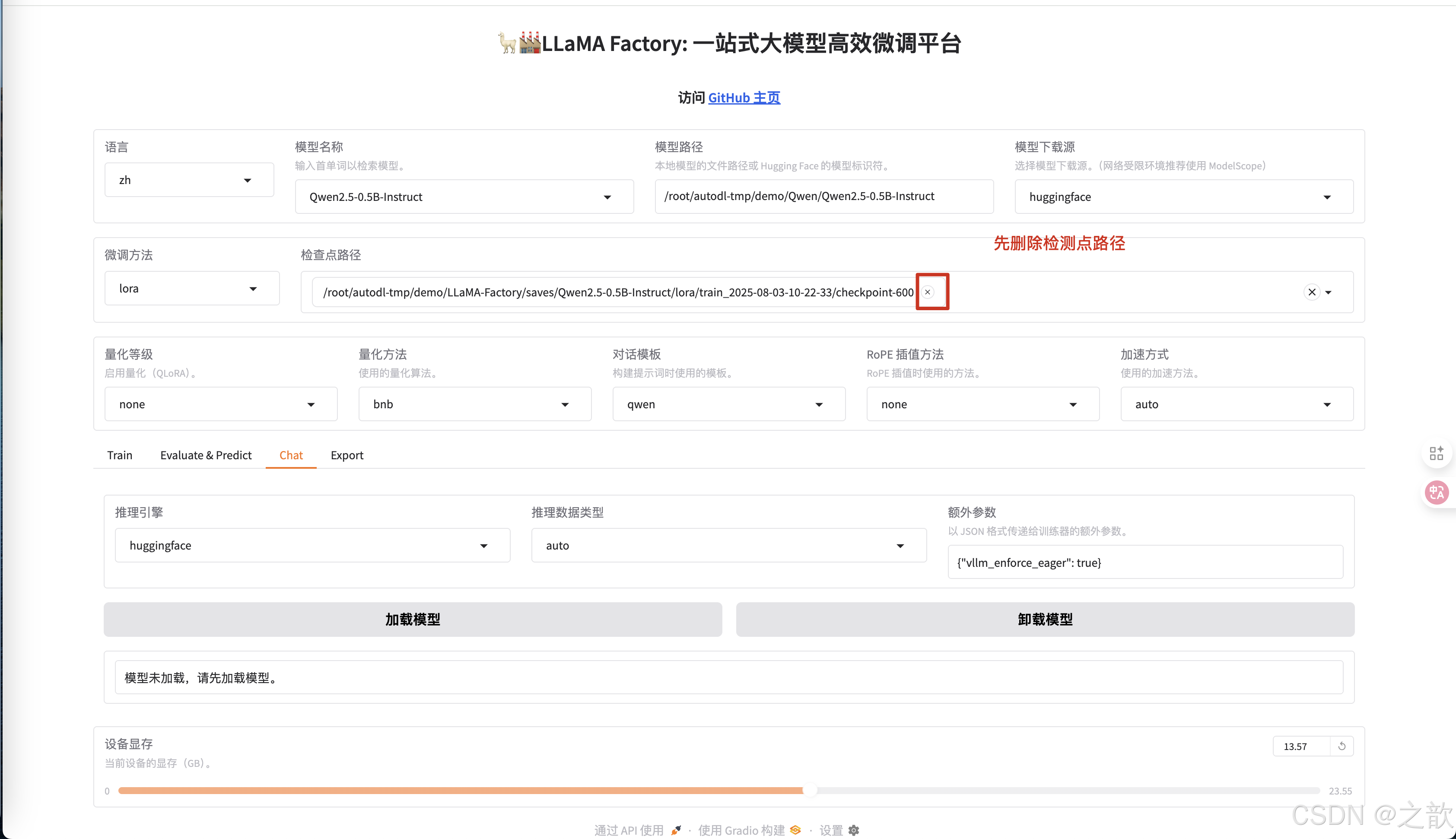
-
點擊加載模型
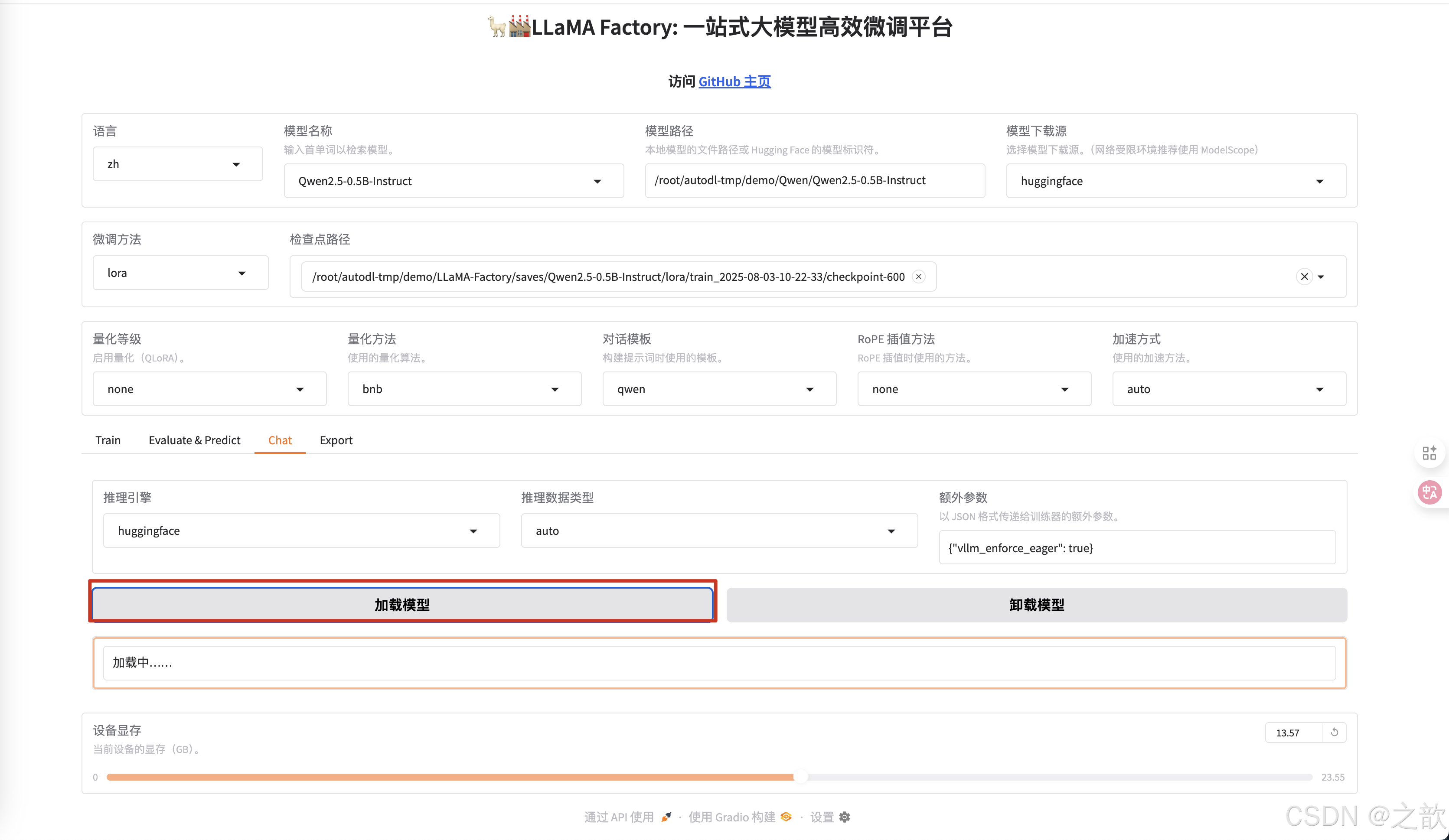
-
開始聊天
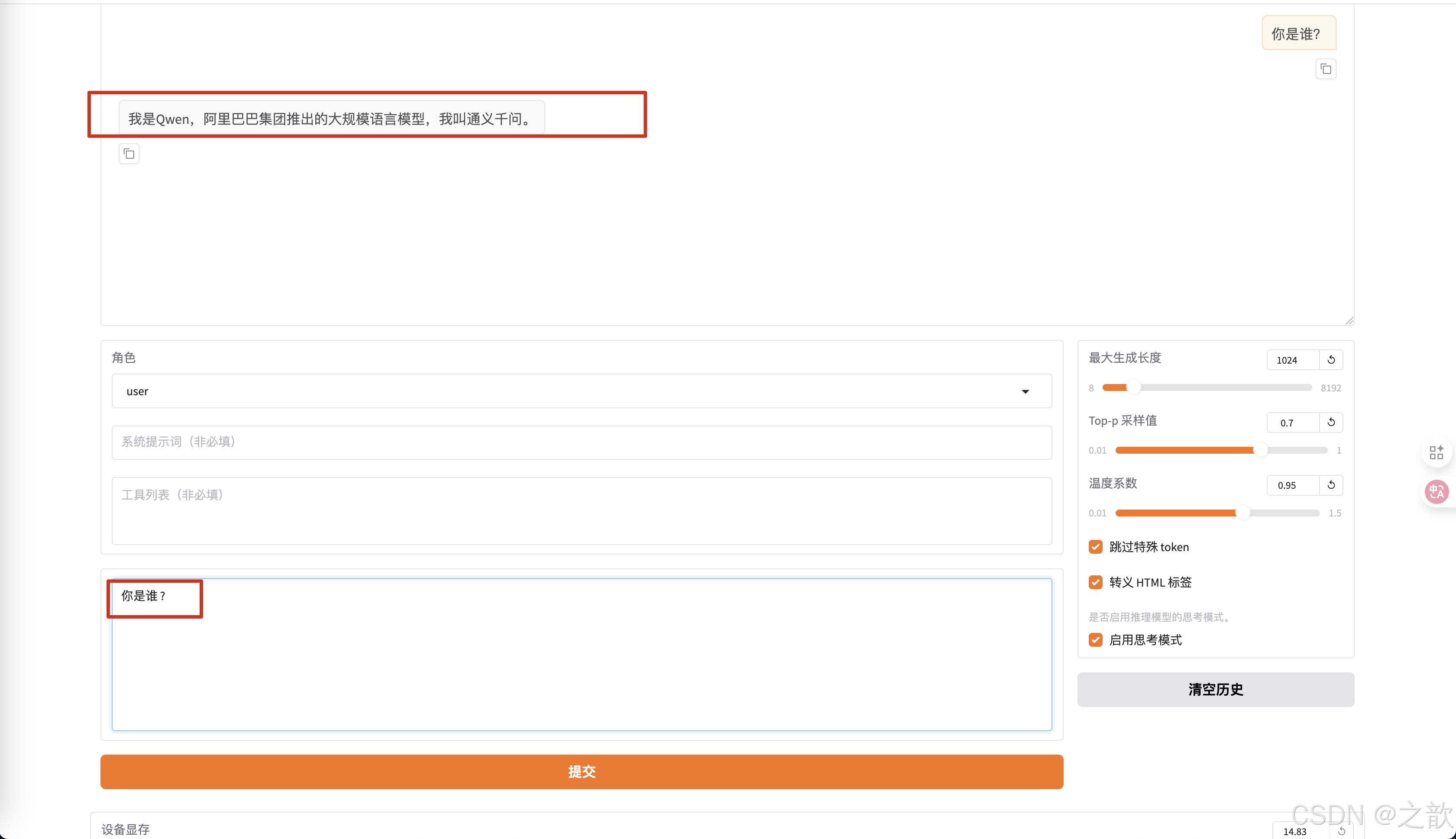
如果沒有訓練,則生成的內容是 ? 我是Qwen,阿里巴巴集團推出的大規模語言模型,我叫通義干問。 -
加載訓練之后的模型 。
-
當你再輸入你是誰? ,返回的內容 就是您好,我是小聚,由Aron開發,旨在為用戶提供智能化的回答和幫助。
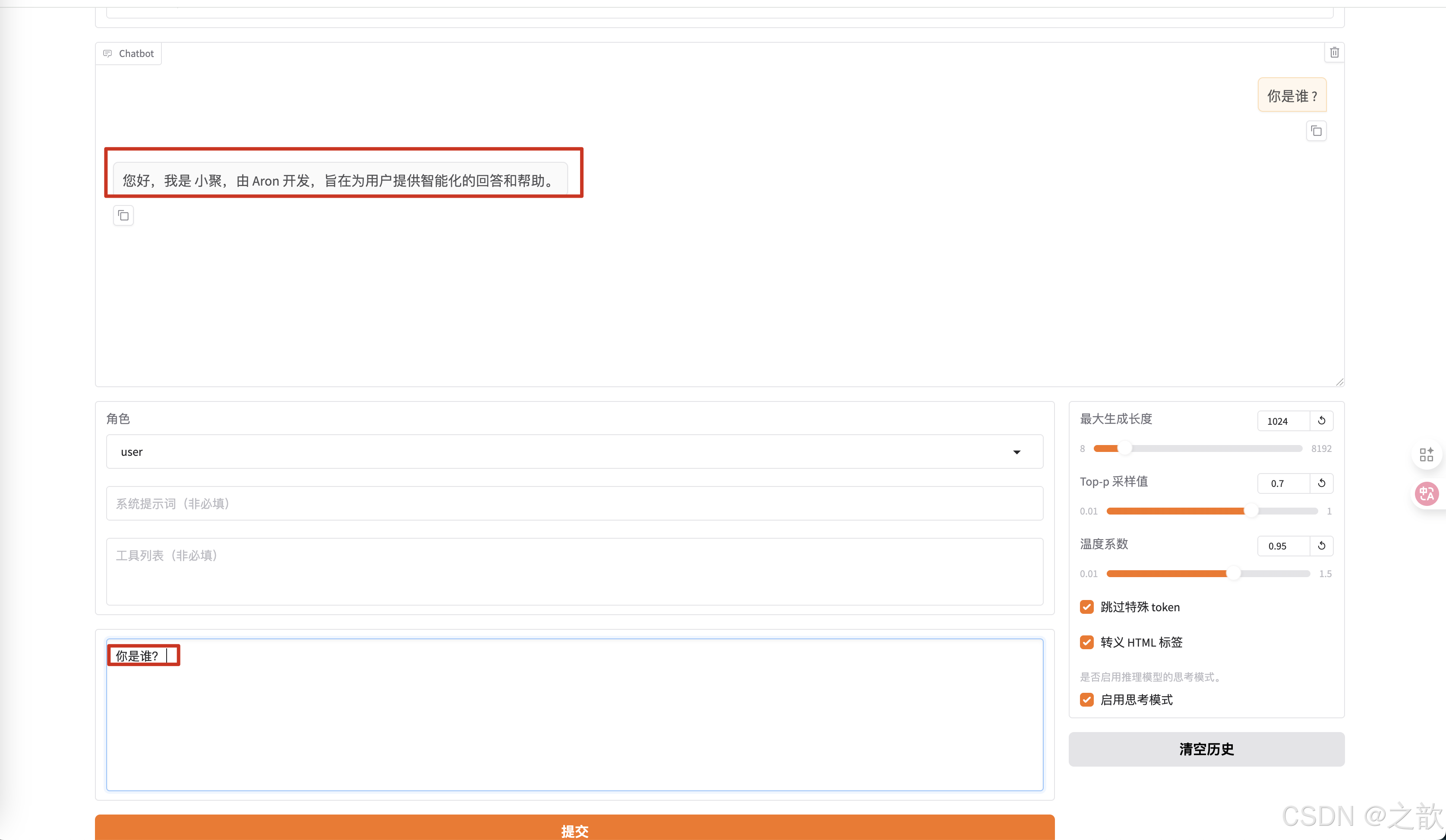
【注意 】不要用deepseek R1 去訓練,方式不一樣,目前比較好用的模型 ,千問模型 , llama 模型 , 以及google的gemma ,還有glm 模型 。 國外的模型對中文的支持不那么強
大模型微調(LLama Factory自定義微調數據集)
LLaMA-Factory微調數據集制作
LLaMA Factory 的官方文檔。
單輪對話
指令監督微調(Instruct Tuning)通過讓模型學習詳細的指令以及對應的回答來優化模型在特定指令下的表現。
instruction 列對應的內容為人類指令, input 列對應的內容為人類輸入, output 列對應的內容為模型回答。下面是一個例子
"alpaca_zh_demo.json"
{"instruction": "計算這些物品的總費用。 ", # 聊天內容"input": "輸入:汽車 - $3000,衣服 - $100,書 - $20。", # 對問題的補充"output": "汽車、衣服和書的總費用為 $3000 + $100 + $20 = $3120。" # 模型返回
},
多輪對話
如果指定, system 列對應的內容將被作為系統提示詞。
history 列是由多個字符串二元組構成的列表,分別代表歷史消息中每輪對話的指令和回答。注意在指令監督微調時,歷史消息中的回答內容也會被用于模型學習。
指令監督微調數據集 格式要求 如下:
一般做數據集時,不會
[{"instruction": "人類指令(必填)", # 用戶輸入"input": "人類輸入(選填)", # 對input 補充"output": "模型回答(必填)", # 模型返回 "system": "系統提示詞(選填)", # 當模型啟動時,模型做一個自我介紹"history": [["第一輪指令(選填)", "第一輪回答(選填)"], # 多話對話["第二輪指令(選填)", "第二輪回答(選填)"] # ]}
]
下面提供一個 alpaca 格式 多輪 對話的例子,對于單輪對話只需省略 history 列即可。
[{"instruction": "今天的天氣怎么樣?","input": "","output": "今天的天氣不錯,是晴天。","history": [["今天會下雨嗎?","今天不會下雨,是個好天氣。"],["今天適合出去玩嗎?","非常適合,空氣質量很好。"]]}
]
對于上述格式的數據, dataset_info.json 中的 數據集描述 應為:
"數據集名稱": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","system": "system","history": "history"}
}
下載數據集
到魔塔社區下載數據集
https://www.modelscope.cn/datasets/w10442005/ruozhiba_qa
mac 系統安裝 lfs
https://blog.csdn.net/m0_65152767/article/details/147166522
Ubuntu22.04安裝Git LFS
https://blog.csdn.net/weixin_37926734/article/details/126851314
安裝好lfs 之后 ,就可以用git 去獲取數據集了 。
git lfs install
git clone https://www.modelscope.cn/datasets/w10442005/ruozhiba_qa.git
數據集轉化效果
當然,需要通過代碼將轉化成我們需要的數據集
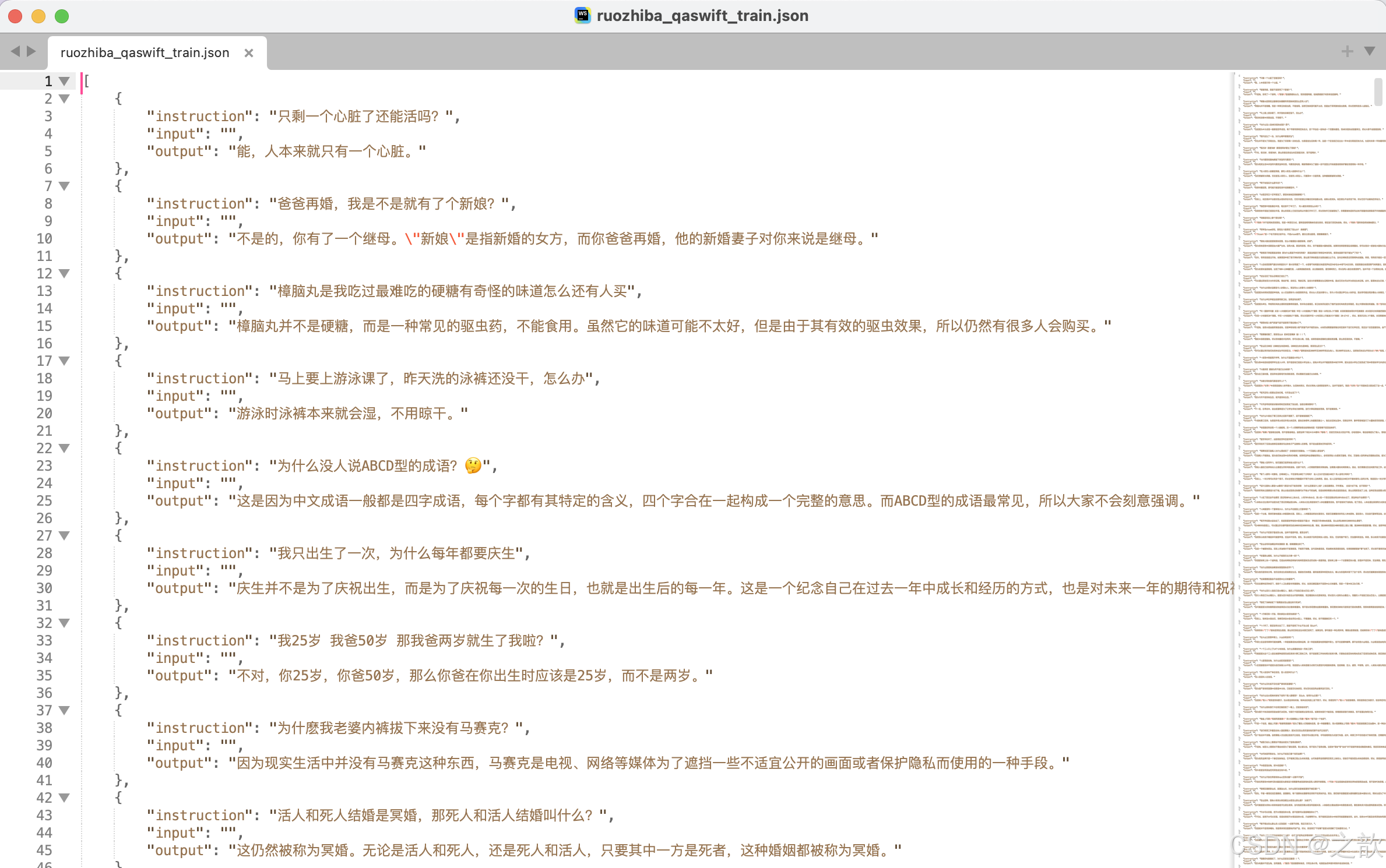
import json# 讀取原始JSON文件
input_file = "data/ruozhiba_qaswift.json" # 你的JSON文件名
output_file = "data/ruozhiba_qaswift_train.json" # 輸出的JSON文件名with open(input_file, "r", encoding="utf-8") as f:data = json.load(f)# 轉換后的數據
converted_data = []for item in data:converted_item = {"instruction": item["query"],"input": "","output": item["response"]}converted_data.append(converted_item)# 保存為JSON文件(最外層是列表)
with open(output_file, "w", encoding="utf-8") as f:json.dump(converted_data, f, ensure_ascii=False, indent=4)print(f"轉換完成,數據已保存為 {output_file}")
轉化后的數據結構如下
將數據集上傳到LLaMA-Factory的data目錄下/root/autodl-tmp/demo/LLaMA-Factory/data。
修改數據集配置文件
修改 /root/autodl-tmp/demo/LLaMA-Factory/data/dataset_info.json 配置文件
"ruozhiba_qaswift_train": {"file_name": "ruozhiba_qaswift_train.json"},
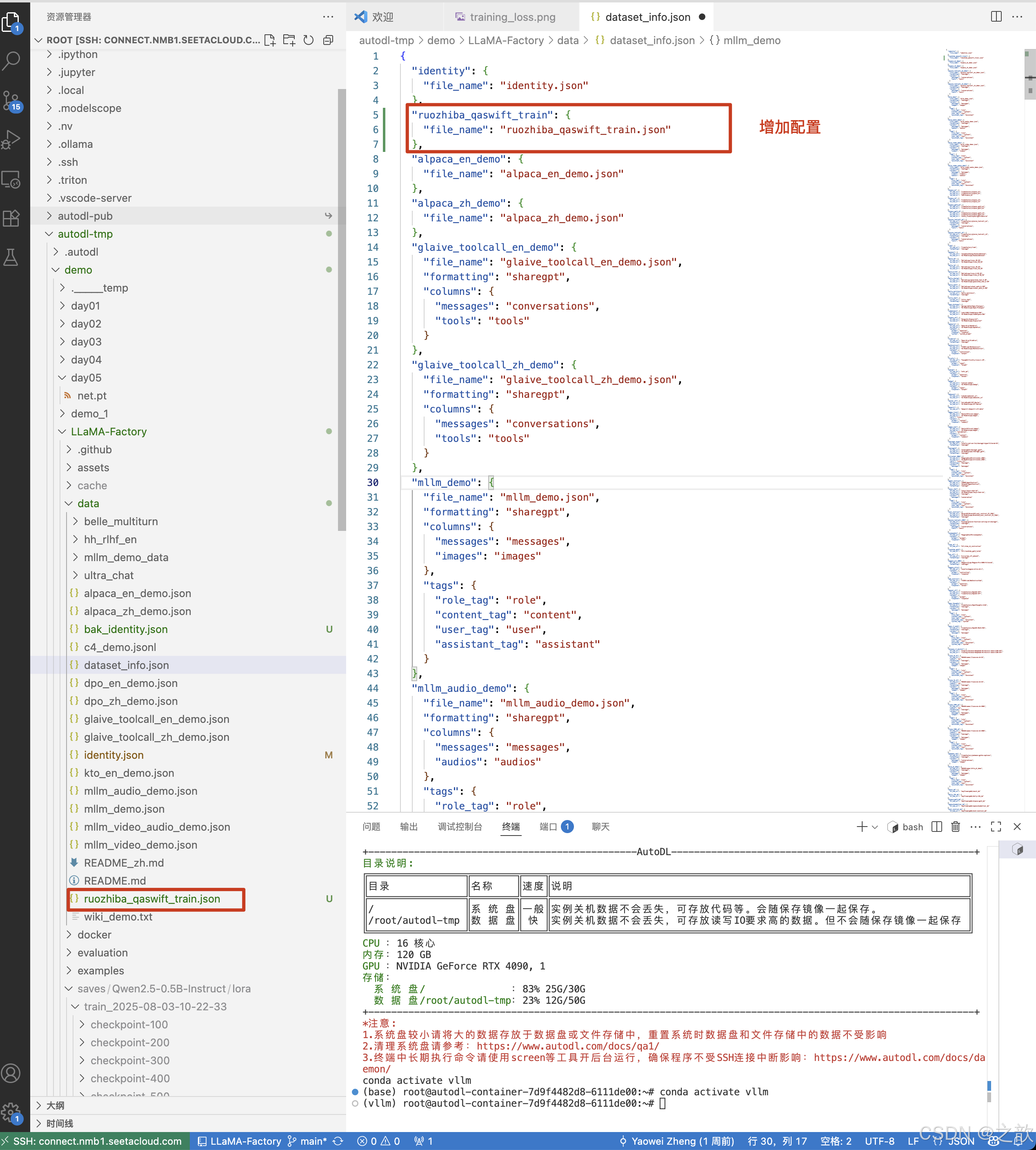
開始訓練
數據集,用新改的數據集 。
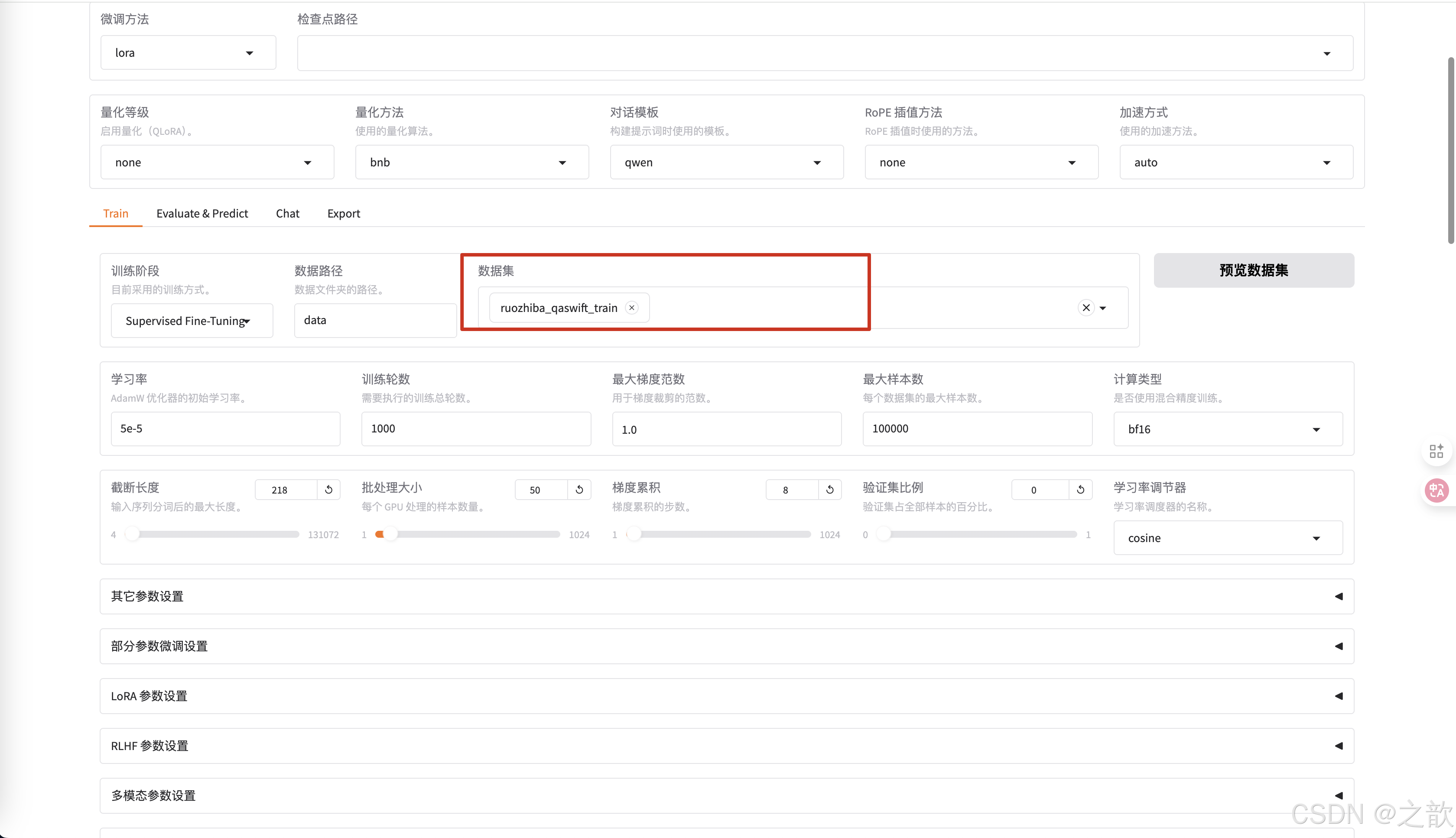
nvitop 查看模型運行情況
雜記
當自己訓練好之后,需要和base模型合并,才可以單獨使用。
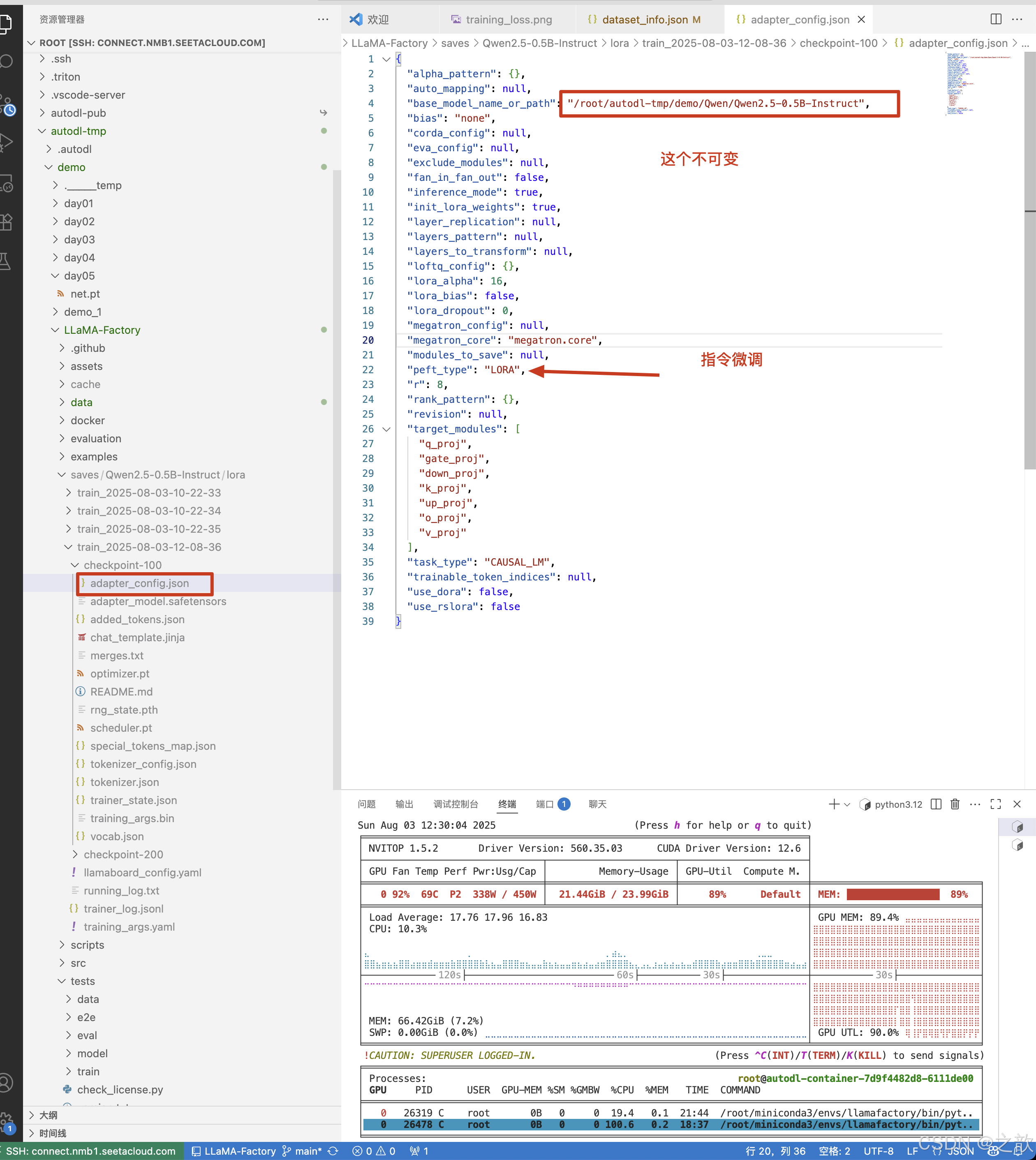
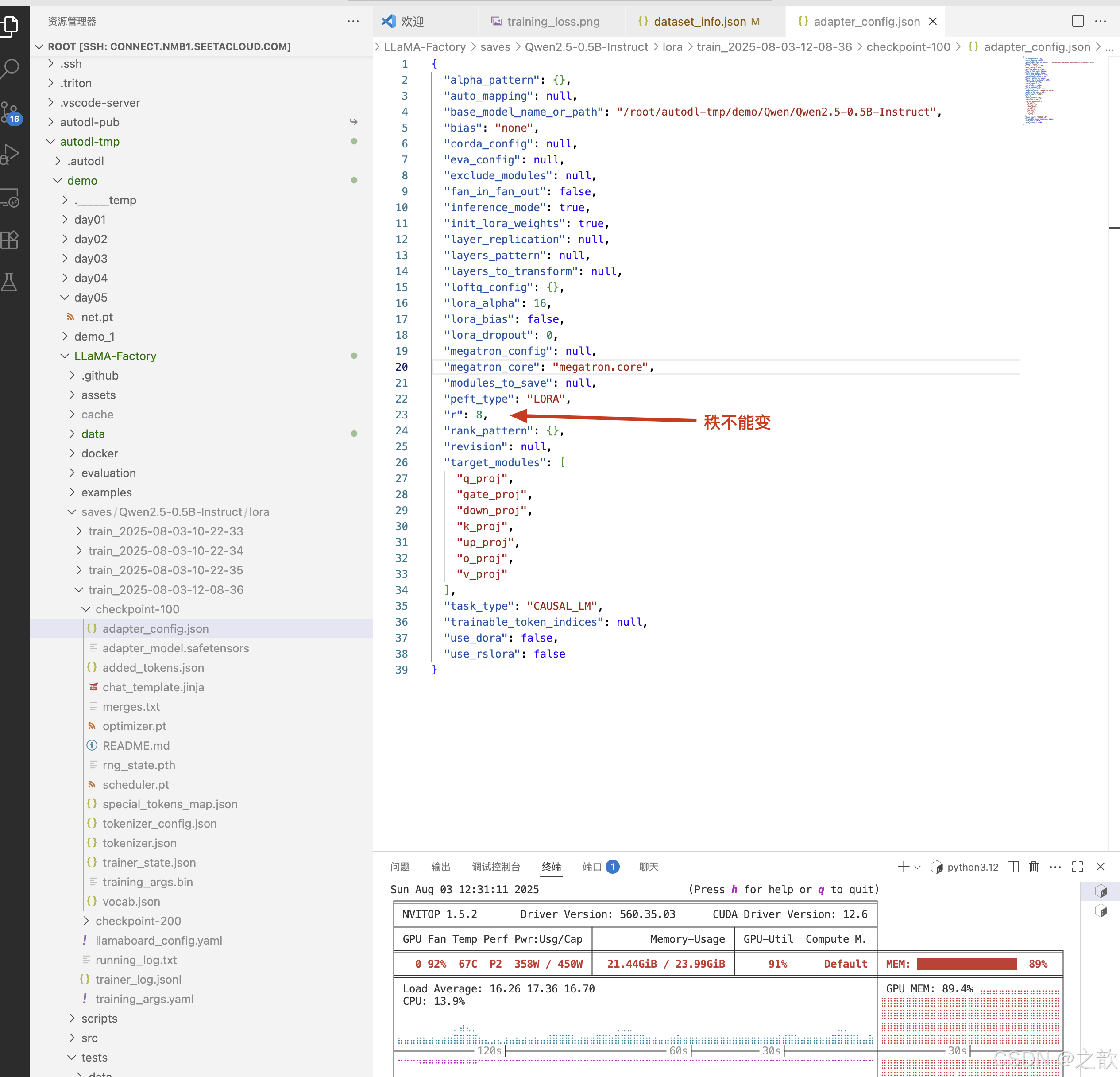
Lora模型合并與量化導出
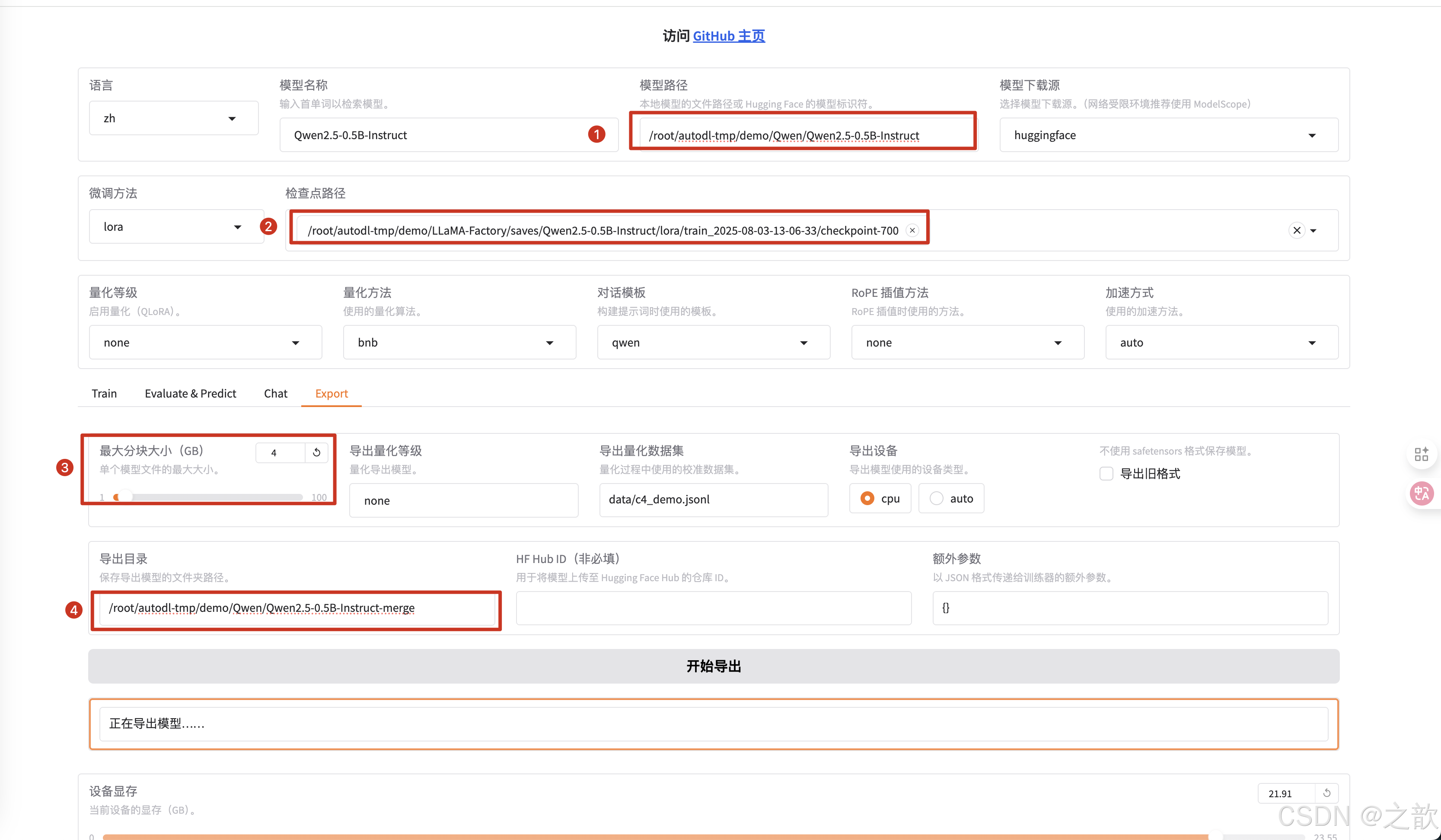
上面需要注意 :
最大分塊大小 (GB),如下面所示 ,如果模型太大,如果進行分塊,分塊大小建議不超過4G
模型量化
模型量化,也想當于閹割模型,模型量化只能使用合并之后的版本。 下面是模型量化的操作。
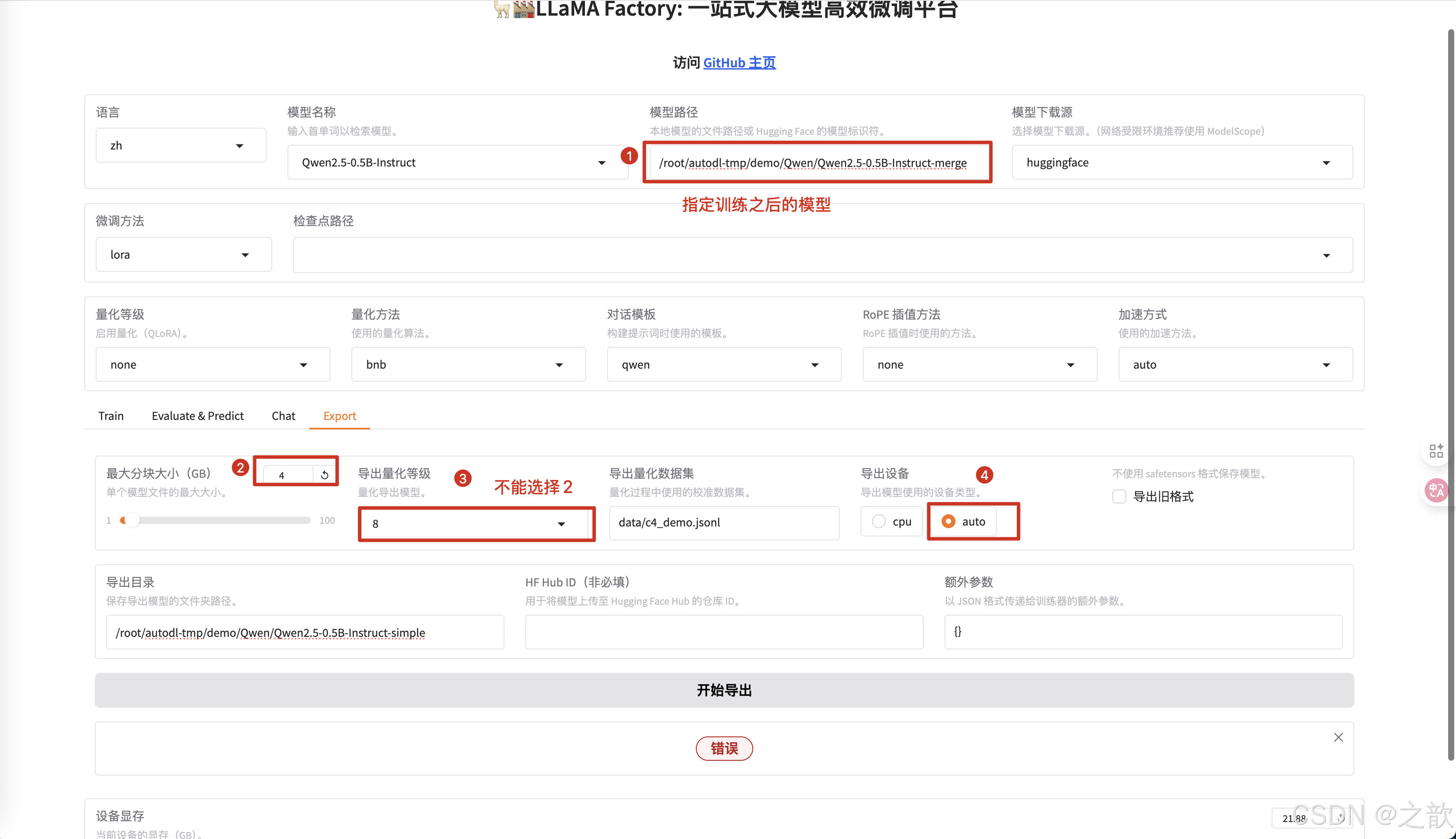
當然,ollama 只能使用gguf 格式的文件
量化只為節省算力,不般個人用戶才會使用量化。
使用 open-webui部署模型
https://blog.csdn.net/xianfianpan/article/details/143441456《參考博客》
https://blog.csdn.net/qq_53206057/article/details/130766270 《conda 指定安裝路徑》
創建 openwebui
conda create --prefix=/root/autodl-tmp/openwebui python==3.11 -y
# To activate this environment, use
#
# $ conda activate openwebui
#
# To deactivate an active environment, use
#
# $ conda deactivate
激活openwebui
conda activate /root/autodl-tmp/openwebui
安裝open-webui
pip install open-webui
配置環境
export HF_ENDPOINT=https://hf-mirror.com
export ENABLE_OLLAMA_API=False
export OPENAI_API_BASE_URL=http://127.0.0.1:8000/v1

用vllm 加載剛剛訓練之后的模型
vllm serve /root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct-merge
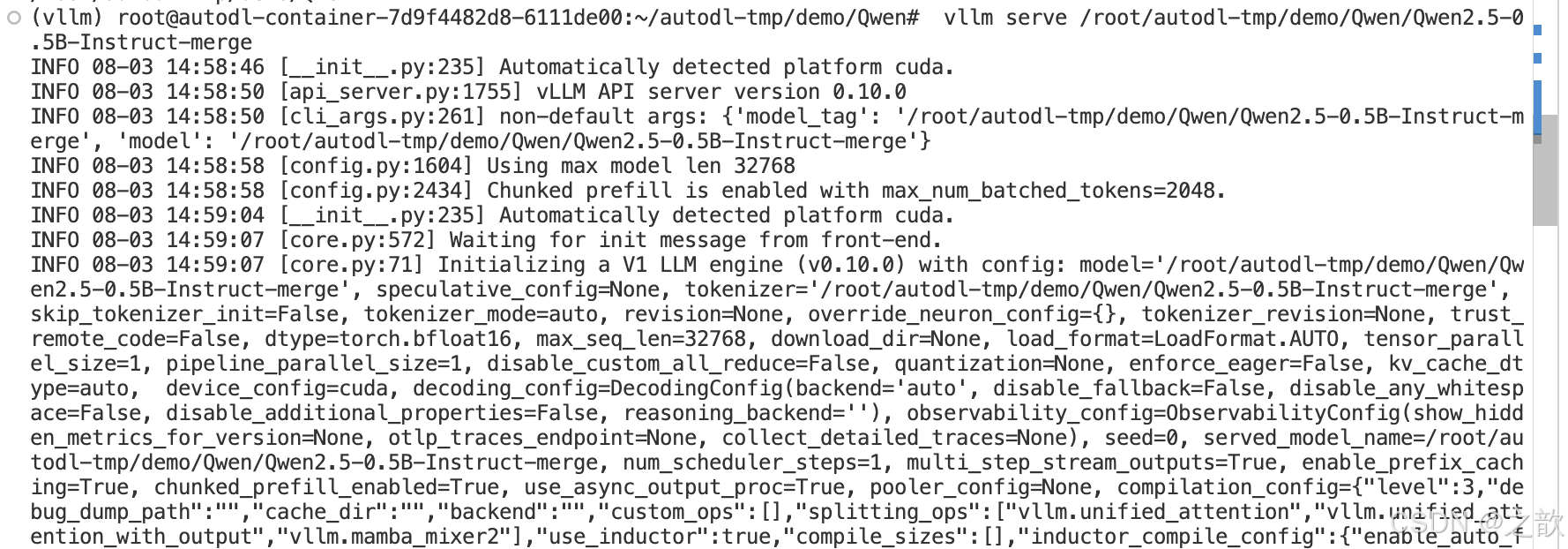
啟動 open-webui
open-webui serve
【注意】如果系統盤不夠,可以使用如下方法
系統盤固定30g無法擴容,系統盤清理參考:https://www.autodl.com/docs/qa1/
https://blog.csdn.net/qq_44534541/article/details/147336888 《python指定安裝路徑》
https://blog.csdn.net/qq_44534541/article/details/147336888《pip 的包下載之后存放在哪?》
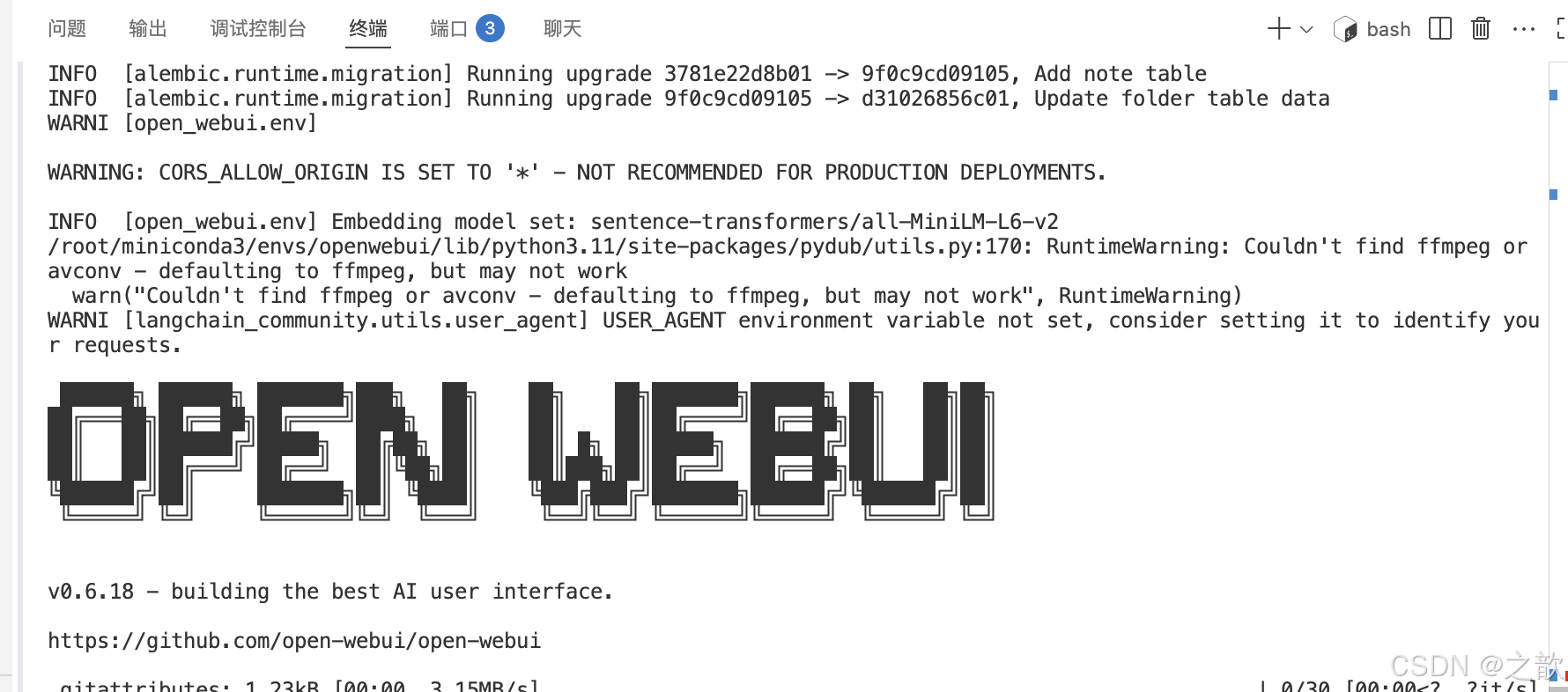
在vscode中添加8080端口
本地訪問
如果vscode沒有加默認端口,自己手動加一下 。 不然,界面就卡在那里了 。
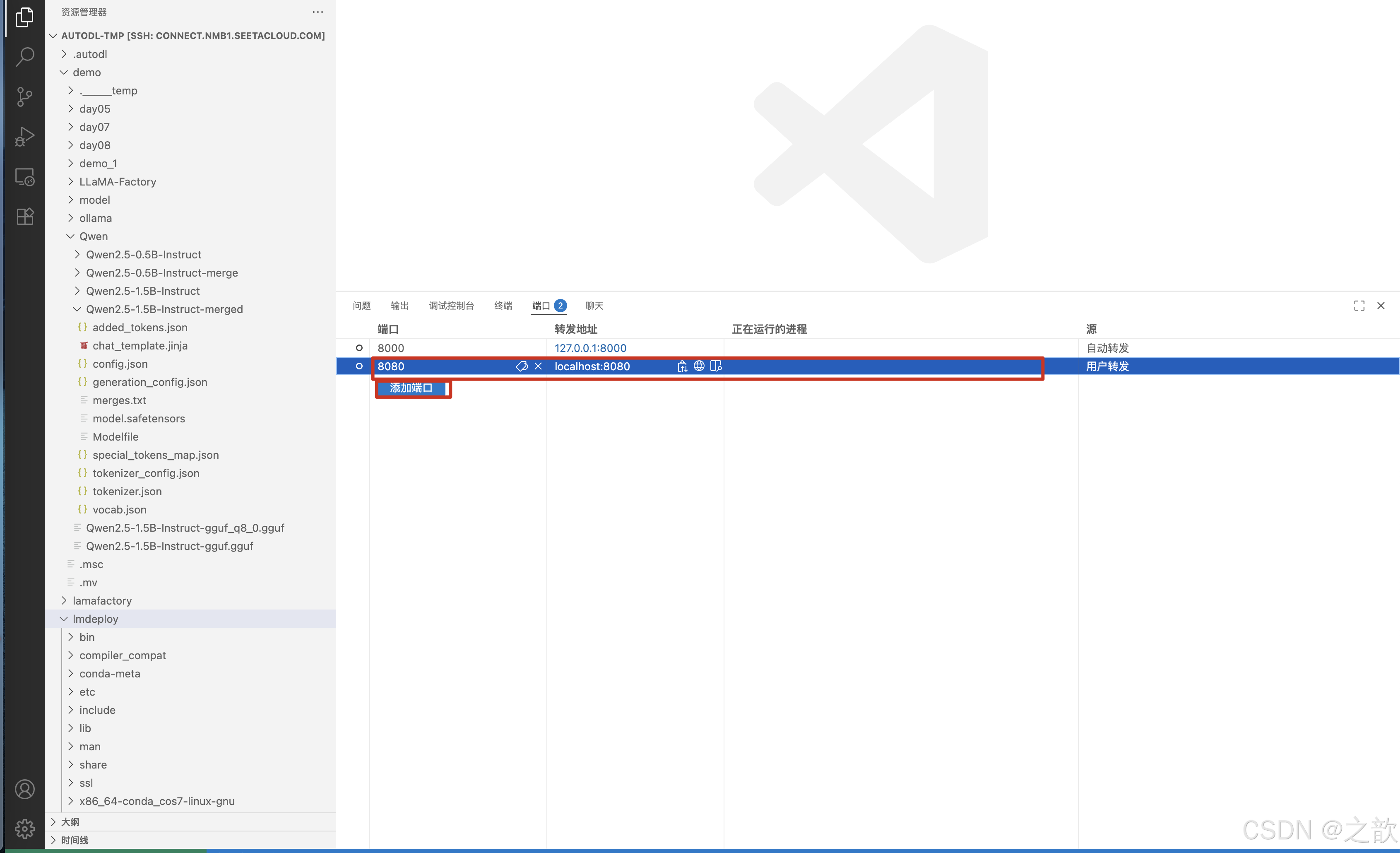
本地訪問
第一次訪問需要登錄,這里用戶名和密碼可以隨便寫,記住就好,下次使用
請訪問這個地址
http://localhost:8080/auth
登錄進去以后的主界面
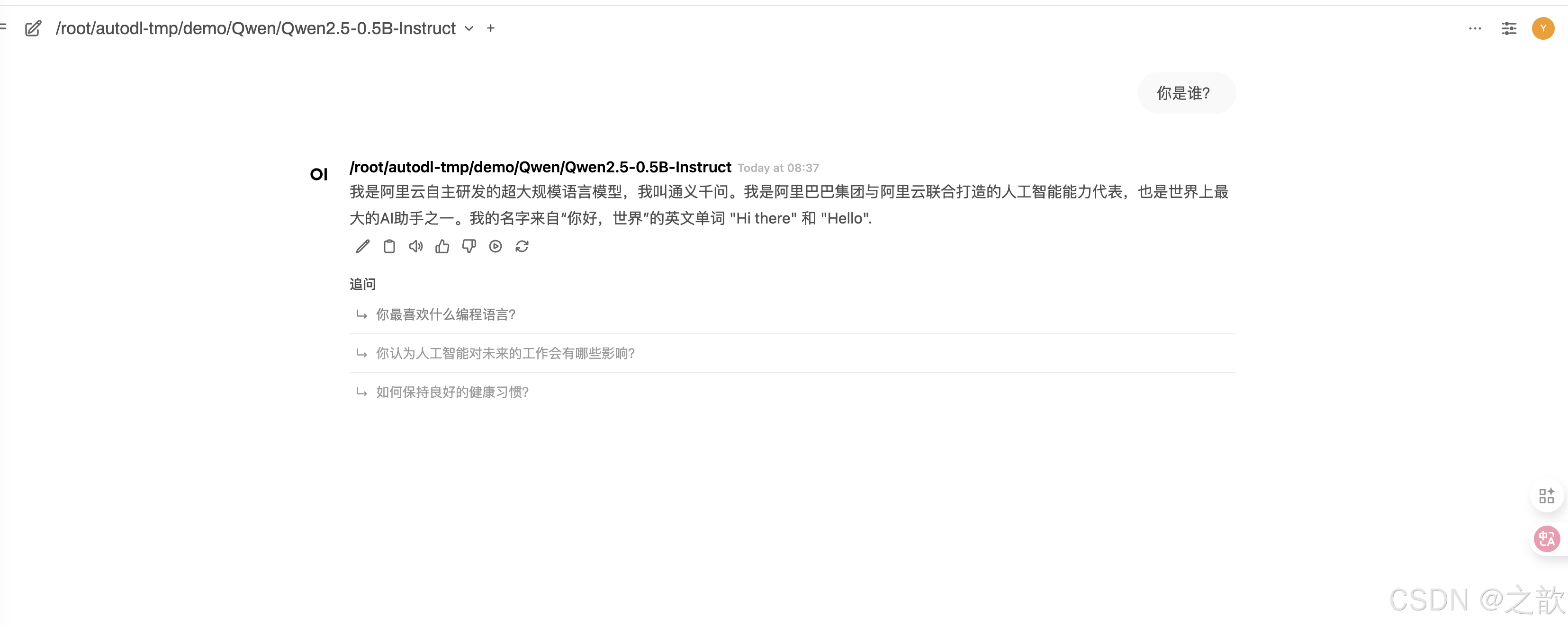
即可以像通常的大模型一樣使用,用于個人還是可以的。
當然也支持語言模式

自己可以玩玩
大模型微調(QLora微調&GGUF模型轉換)
LLama Factory自定義多輪對話數據集
關于模型微調輪次的設置多少合適?
3~ 5epoch就有效了
問題:為什么課上的epoch給的很大?例如1000
1.模型微調訓練的目標是什么?
我們給的是個理想目標(讓模型在測試數據集中達到擬合狀態(損失收斂))
2.模型微調訓練到多少個epoch才會擬合?
這是一個未知數,因此我們一般在設置訓練epoch時會給一個較大的數值,防止模型還未達到
擬合狀態而訓練就已經結束了。
3. 注意,大多數現實中的項目是不需要或者不可能訓練到擬合狀態的,只是訓練到一個接近于擬合的狀態,或者說達到甲方預期效果就可以了。
https://cloud.tencent.com/developer/article/1441933 《一款入門神器TensorFlowPlayground》
http://playground.tensorflow.org/《TensorFlow playground》
在現實過程中,我們考慮的是否可以交付。
大模型中的“大”指的是參數數量大(參數量的多少),而不是文件的大小。
模型就是一堆參數,模型也就是權重 。
在模型微調訓練過程中,我們可以采用降低模型參數精度來節約訓練的顯存,以此提升訓練批次大小,使得模型訓練的更快。
問題:之前的部署量化有提到,量化是以犧牲精度為代價提升性能。那么在訓練過程給中使用量化是;否會降低模型的精度呢?
答案是:不會。在量化部署中,由于模型的參數已經固定了,所以降低精度一定會影響結果;但是,在訓練過程中,模型的參數并未固定,依然處于學習狀態,所以降低參數的精度對模型的結果不會有太大影響(因為AI訓練的結果不是具體的數值,而是一種趨勢)。
注意:在量化微調中,量化只發生在內部的訓練過程,并不影響模型的最終的數據類型(模型原有的參數類型是f16,在量化微調訓練中會量化為8位,參數保存時又會還原到float16),因此量化微調并不會影響到模型結果
LoRA與QLoRA
LoRA:LoRA 是一種用于微調大型語言模型的技術,通過低秩近
似方法降低適應數十億參數模型(如 GPT-3)到特定任務或領域。
QLoRA:QLoRA 是一種高效的大型語言模型微調方法,它顯著降
低了內存使用量,同時保持了全 16 位微調的性能。它通過在一個
固定的、4 位量化的預訓練語言模型中反向傳播梯度到低秩適配
器來實現這一目標。
QLoRA微調
下載 https://www.modelscope.cn/models/Qwen/Qwen2.5-1.5B-Instruct
創建/root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct 目錄
mkdir -p /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct
下載模型
modelscope download --model Qwen/Qwen2.5-1.5B-Instruct --local_dir ./
上傳數據集
啟動llamafactory
llamafactory-cli webui
pip install bitsandbytes==0.37.0 # pip指定安裝包版本
效果
LoRA 秩 一般是32 ~ 128 之間

如果使用QLoRA,而不是LoRA 微調, LORA縮放系數 是 LORA秩 的2倍 。 一般 LORA縮放系數 是 LORA秩 的2倍 的效果比較好。
大模型轉換為 GGUF 以及使用 ollama 運行
什么是 GGUF
GGUF 格式的全名為(GPT-Generated Unified Format),提到
GGUF 就不得不提到它的前身 GGML(GPT-Generated Model
Language)。GGML 是專門為了機器學習設計的張量庫,最早可
以追溯到 2022/10。其目的是為了有一個單文件共享的格式,并
且易于在不同架構的 GPU 和 CPU 上進行推理。但在后續的開發
中,遇到了靈活性不足、相容性及難以維護的問題。
為什么要轉換 GGUF 格式
在傳統的 Deep Learning Model 開發中大多使用 PyTorch 來進行開發,但因為在部署時會面臨相依 Lirbrary 太多、版本管理的問題于
才有了 GGML、GGMF、GGJT 等格式,而在開源社群不停的迭代后 GGUF 就誕生了。
GGUF 實際上是基于 GGJT 的格式進行優化的,并解決了 GGML 當初面臨的問題,包括:
1)可擴展性:輕松為 GGML 架構下的工具添加新功能,或者向 GGUF 模型添加新 Feature,不會破壞與現有模型的兼容性。
2)對 mmap(內存映射)的兼容性:該模型可以使用 mmap 進行加載(原理解析可見參考),實現快速載入和存儲。(從 GGJT 開
始導入,可參考 GitHub)
3)易于使用:模型可以使用少量代碼輕松加載和存儲,無需依賴的 Library,同時對于不同編程語言支持程度也高。
4)模型信息完整:加載模型所需的所有信息都包含在模型文件中,不需要額外編寫設置文件。
5)有利于模型量化:GGUF 支持模型量化(4 位、8 位、F16),在 GPU 變得越來越昂貴的情況下,節省 vRAM 成本也非常重要。
Qwen打包部署(大模型轉換為 GGUF 以及使用 ollama 運行)
將hf模型轉換為GGUF
需要用llama.cpp倉庫的convert_hf_to_gguf.py腳本來轉換
安裝llamaapp 的隔離環境
conda create --prefix=/root/autodl-tmp/llamaapp python3.10 -y
激活隔離環境llamaapp
conda activate /root/autodl-tmp/llamaapp
下載 llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git
cd /root/autodl-tmp/demo/ollama 這個目錄睛 ,這個目錄中有剛剛下載的llama.cpp 文件
pip install -r llama.cpp/requirements.txt
執行轉換
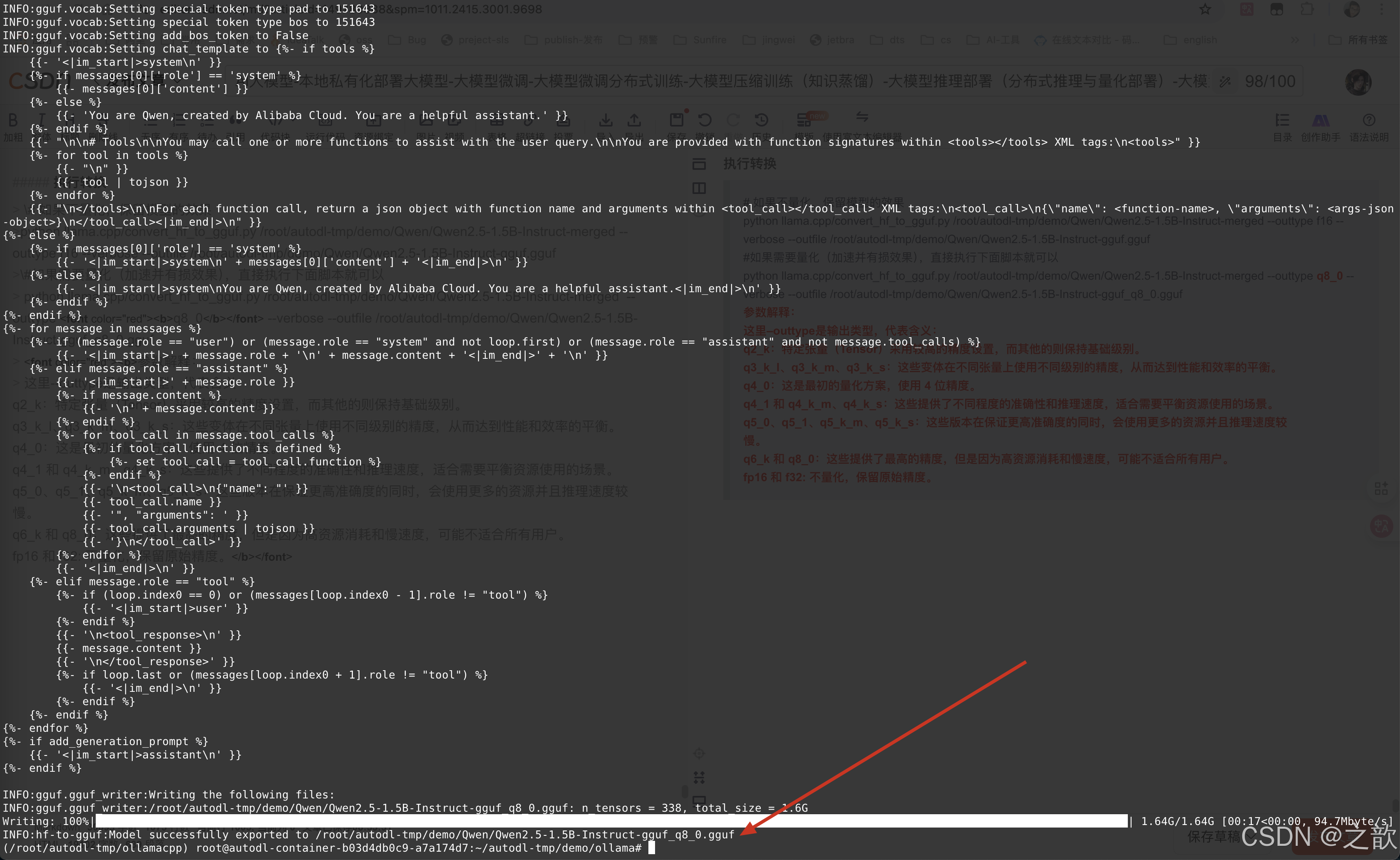
# 如果不量化,保留模型的效果
python llama.cpp/convert_hf_to_gguf.py /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct-merged --outtype f16 --verbose --outfile /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct-gguf.gguf
#如果需要量化(加速并有損效果),直接執行下面腳本就可以
python llama.cpp/convert_hf_to_gguf.py /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct-merged --outtype q8_0 --verbose --outfile /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct-gguf_q8_0.gguf
參數解釋:
這里–outtype是輸出類型,代表含義:
q2_k:特定張量(Tensor)采用較高的精度設置,而其他的則保持基礎級別。
q3_k_l、q3_k_m、q3_k_s:這些變體在不同張量上使用不同級別的精度,從而達到性能和效率的平衡。
q4_0:這是最初的量化方案,使用 4 位精度。
q4_1 和 q4_k_m、q4_k_s:這些提供了不同程度的準確性和推理速度,適合需要平衡資源使用的場景。
q5_0、q5_1、q5_k_m、q5_k_s:這些版本在保證更高準確度的同時,會使用更多的資源并且推理速度較
慢。
q6_k 和 q8_0:這些提供了最高的精度,但是因為高資源消耗和慢速度,可能不適合所有用戶。
fp16 和 f32: 不量化,保留原始精度。
生成效果如下:
生成效果如下:
先激活并啟動ollama
# conda info --envs
# conda activate /root/autodl-tmp/ollama
# ollama serve

打開另外一個窗口,創建ModelFile

vi /root/autodl-tmp/ModeFile , 在文件中寫入如下內容
# GGUF文件路徑
FROM /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct-gguf.gguf
創建自定義模型
使用ollama create命令創建自定義模型
cd /root/autodl-tmp
ollama create Qwen2.5-1.5B-Instruct-q8 --file ./ModeFile
模型加載進去了


運行模型:
# ollama run Qwen2.5-1.5B-Instruct-q8
運行測試結果如下:
【注意】 如果這里有多個gguf 模型需要加載 ,則在不同的目錄下創建多個ModelFile文件,或者你將原來的ModelFile修改掉即可,ollama create Qwen2.5-1.5B-Instruct-q8 --file ./ModeFile 一次性只能加載一個模型文件,當加載的模型名字(Qwen2.5-1.5B-Instruct-q8)相同時,會覆蓋掉之前的模型 。
大模型微調(LLamaFactory微調效果與vllm部署效果不一致如何解決)
生成式語言模型的對話模板介紹
按之前的方式啟動openwebui ,問你是
在vllm 啟動后臺看到如下信息
INFO 08-10 09:12:39 [logger.py:41] Received request chatcmpl-5ca9ded32a7648ebb4193fffa3bc2017: prompt:
‘<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n<
|im_start|>user\n### Task:\nGenerate 1-3 broad tags categorizing the main themes of the chat history, along with 1-3 more specific subtopic tags.\n\n### Guidelines:\n- Start with high-level domains (e.g. Science, Technology, Philosophy, Arts, Politics, Business, Health, Sports, Entertainment, Education)\n- Consider including relevant subfields/subdomains if they are strongly represented throughout the conversation\n- If content is too short (less than 3 messages) or too diverse, use only [“General”]\n- Use the chat’s primary language; default to English if multilingual\n- Prioritize accuracy over specificity\n\n### Output:\nJSON format: { “tags”: [“tag1”, “tag2”, “tag3”] }\n\n
### Chat History:\n<chat_history>\nUSER: 你是\nASSISTANT: 我是阿里云自主研發的超大規模語言模型,我叫通義千問。我是阿里巴巴集團與阿里云聯合打造的語言模型,致力于提供高質量、高效率的人工智能服務。如果您有任何問題或需要幫助,請隨時告訴我,我會盡力為您提供支持和解答。\n</chat_history><|im_end|>\n
<|im_start|>assistant\n’, params: SamplingParams(n=1, presence_penalty=0.0, frequency_penalty=0.0, repetition_penalty=1.1, temperature=0.7, top_p=0.8, top_k=20, min_p=0.0, seed=None, stop=[], stop_token_ids=[], bad_words=[], include_stop_str_in_output=False, ignore_eos=False, max_tokens=32511, min_tokens=0, logprobs=None, prompt_logprobs=None, skip_special_tokens=True, spaces_between_special_tokens=True, truncate_prompt_tokens=None, guided_decoding=None, extra_args=None), prompt_token_ids: None, prompt_embeds shape: None, lora_request: None.
INFO 08-10 09:12:39 [async_llm.py:269] Added request chatcmpl-5ca9ded32a7648ebb4193fffa3bc2017.
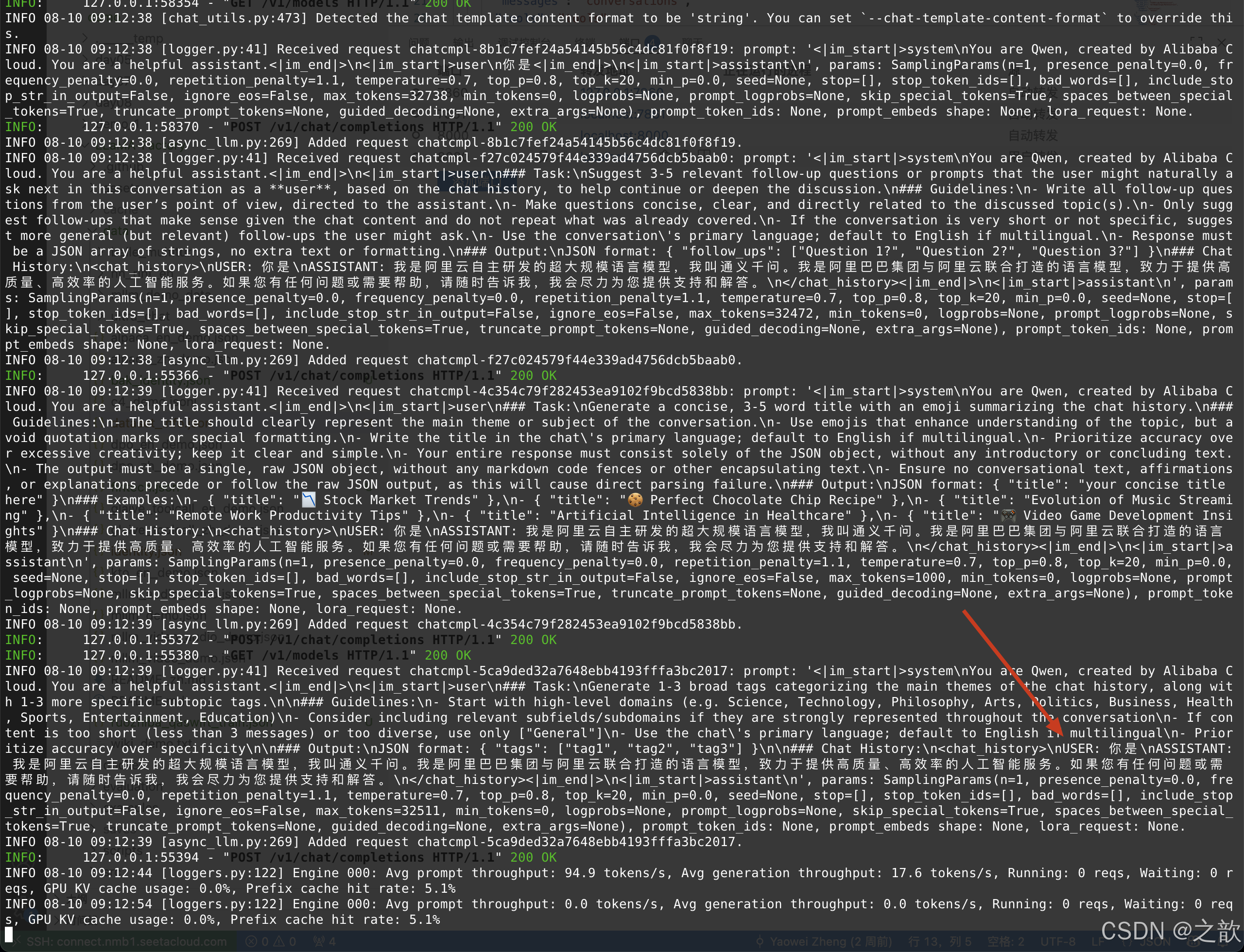
Lora微調后單獨部署大模型輸出結果不一致
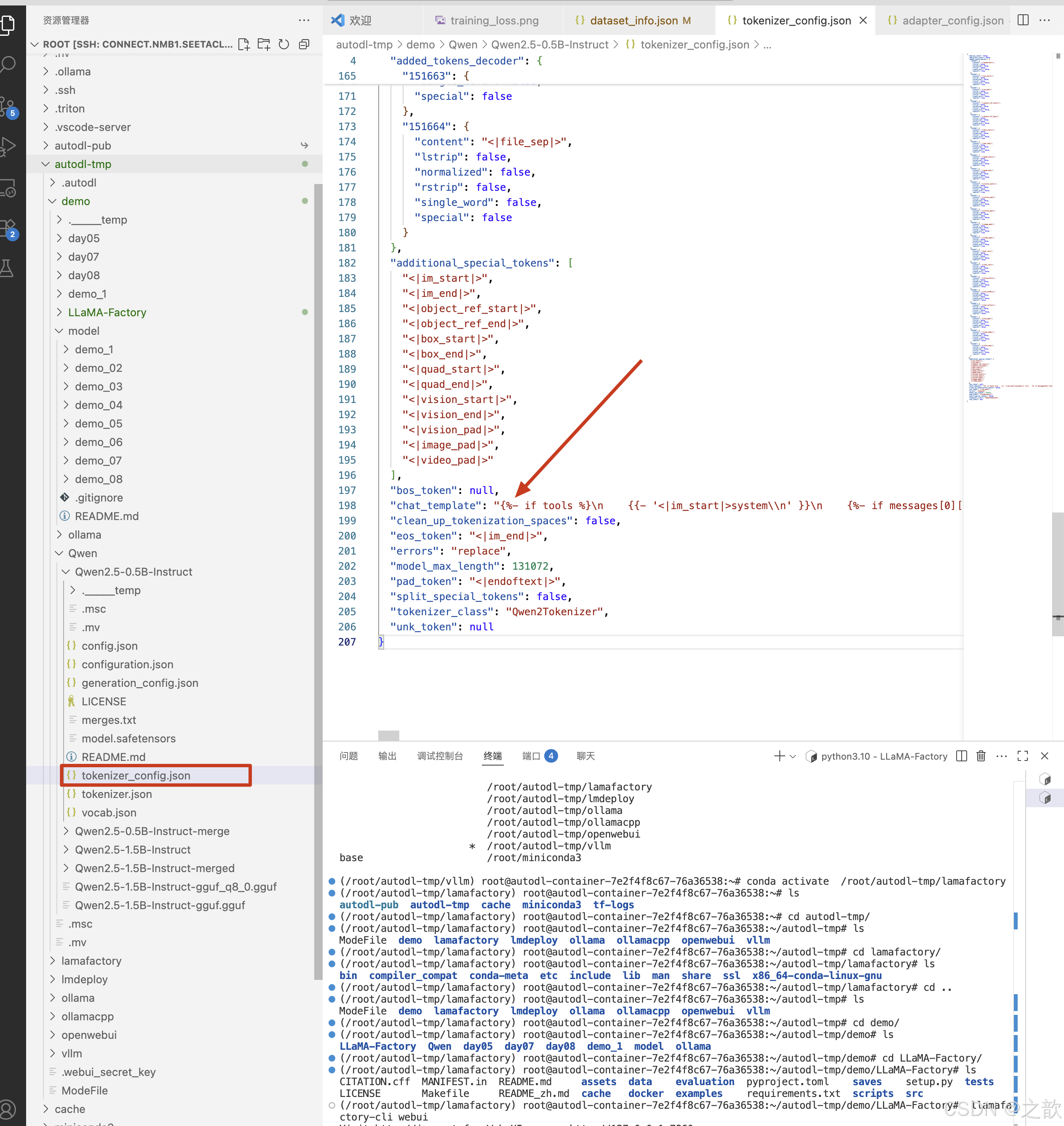
從上面兩個圖可以看出,用LLaMA Factory 微調使用的對話模板 和 模型本身 的 對話模板 是不一樣的,可能會出現你在模型微調時
這里的聊天得到的模型回復 和 你將 模型布署在vllm 中回復的內容不一致, 導致這個問題的根本原因是 模型 訓練時 的 會話模板和vllm 布署時會話模板不一致所致。 解決方法: 將模型訓練時的會話模板導出來,在vllm 啟動時指定自己的會話模板
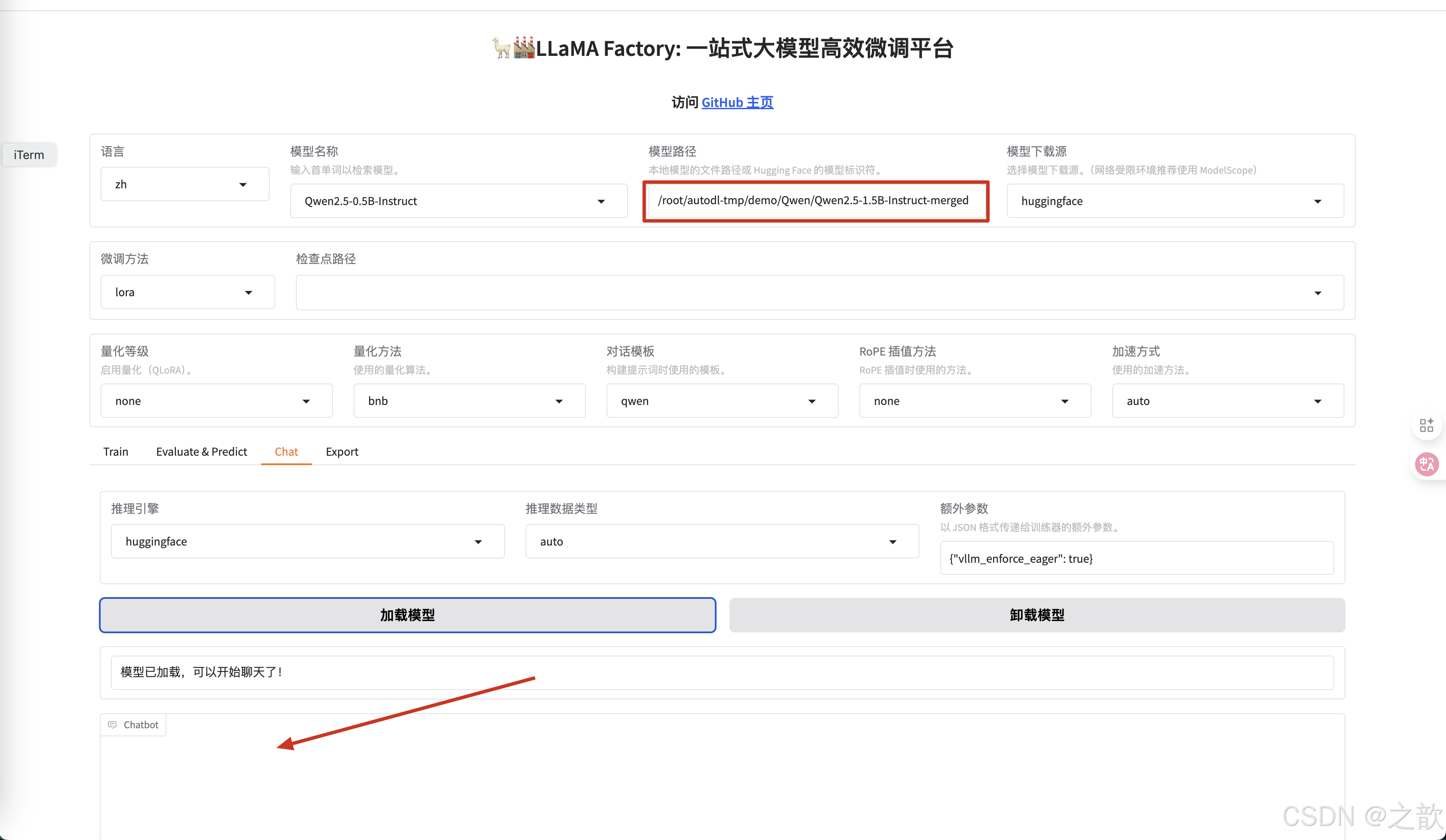
如何導出LLama Factory的對話模板
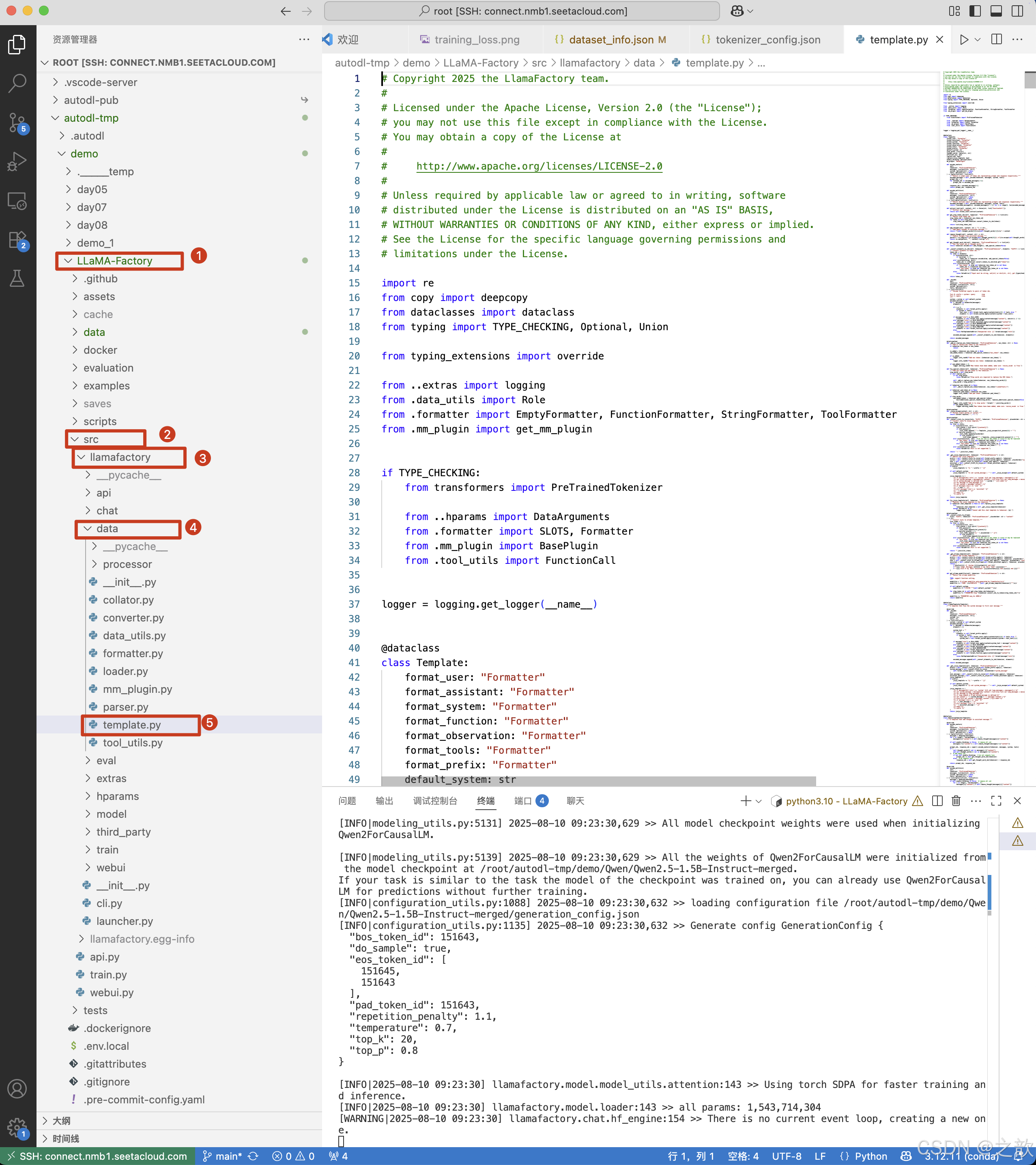
qwen對話模板
Jinja2
Jinja2官網,Jinja2 比json 更加靈活
下圖中有一個_get_jinja_template()方法,自己定一個腳本來調用這個方法導出jinja2格式的模板 。
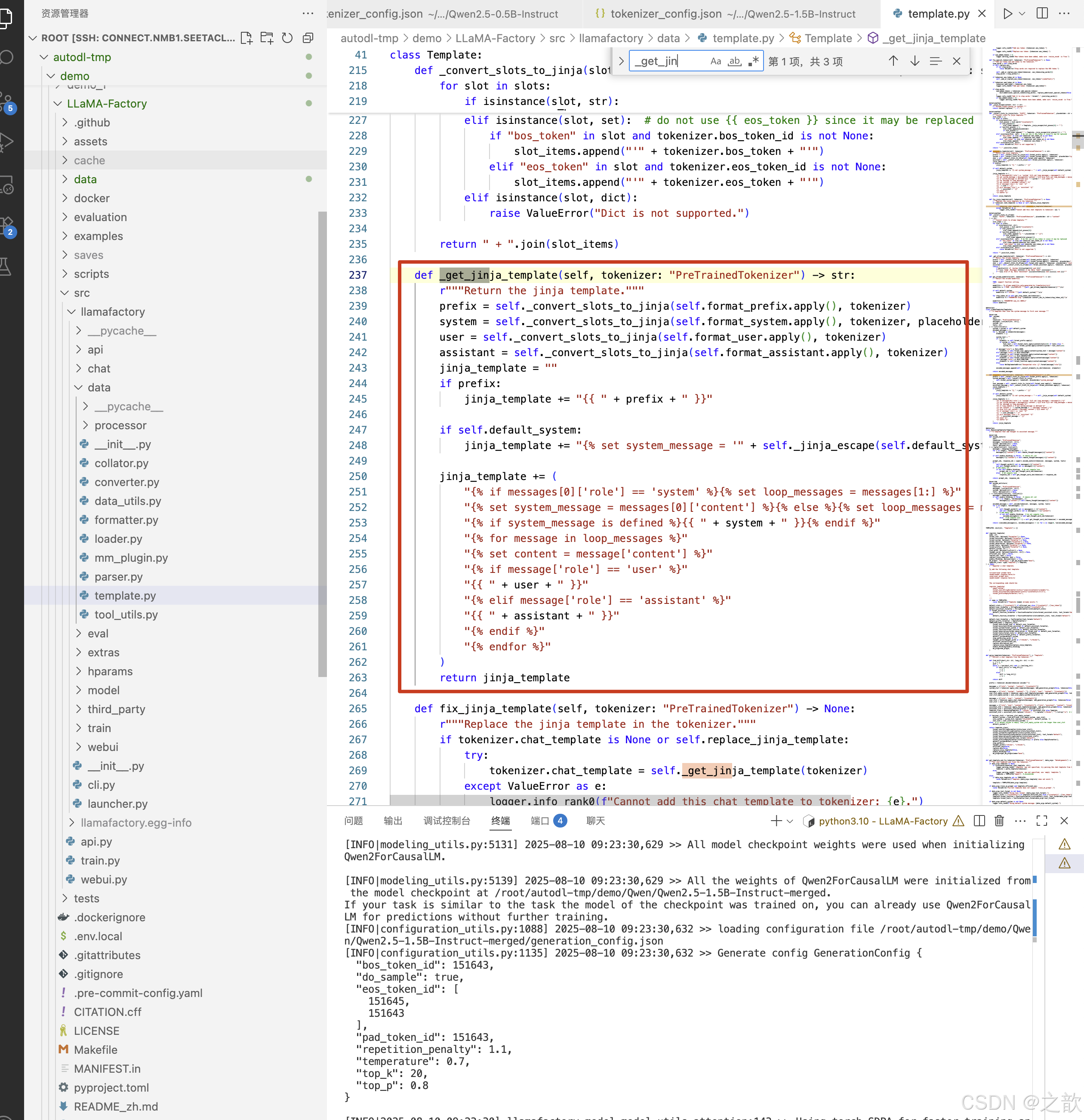
導出會話模板
創建一個mytest.py文件,將這個文件放到template.py 同級目錄
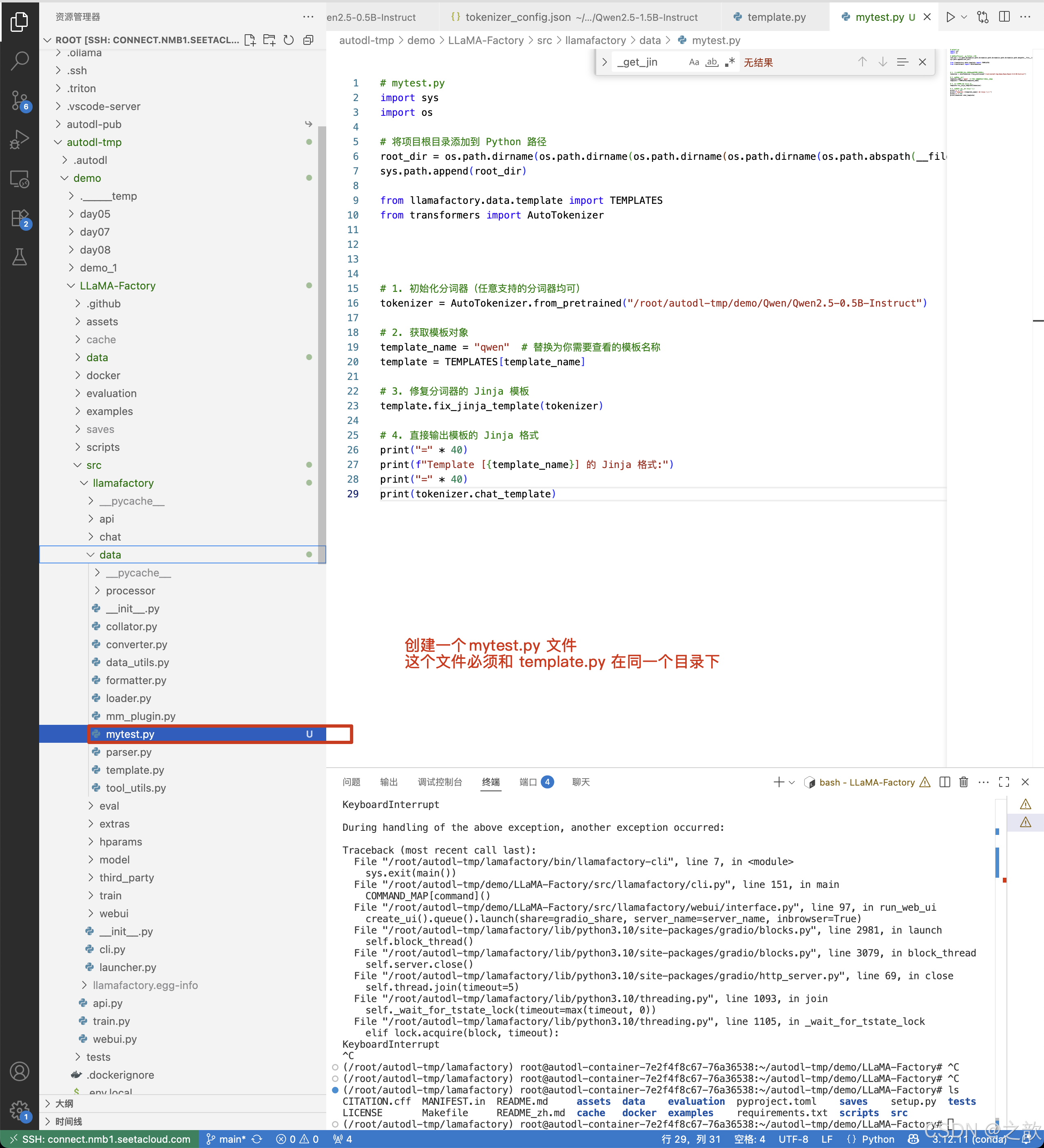
# mytest.py
import sys
import os# 將項目根目錄添加到 Python 路徑
root_dir = os.path.dirname(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
sys.path.append(root_dir)from llamafactory.data.template import TEMPLATES
from transformers import AutoTokenizer# 1. 初始化分詞器(任意支持的分詞器均可)
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/demo/Qwen/Qwen2.5-0.5B-Instruct")# 2. 獲取模板對象
template_name = "qwen" # 替換為你需要查看的模板名稱
template = TEMPLATES[template_name]# 3. 修復分詞器的 Jinja 模板
template.fix_jinja_template(tokenizer)# 4. 直接輸出模板的 Jinja 格式
print("=" * 40)
print(f"Template [{template_name}] 的 Jinja 格式:")
print("=" * 40)
print(tokenizer.chat_template)輸出內容:
(/root/autodl-tmp/lamafactory) root@autodl-container-7e2f4f8c67-76a36538:~/autodl-tmp/demo/LLaMA-Factory/src/llamafactory/data# python mytest.py
========================================
Template [qwen] 的 Jinja 格式:
========================================
{%- if tools %}{{- '<|im_start|>system\n' }}{%- if messages[0]['role'] == 'system' %}{{- messages[0]['content'] }}{%- else %}{{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}{%- endif %}{{- "\n\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}{%- for tool in tools %}{{- "\n" }}{{- tool | tojson }}{%- endfor %}{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
{%- else %}{%- if messages[0]['role'] == 'system' %}{{- '<|im_start|>system\n' + messages[0]['content'] + '<|im_end|>\n' }}{%- else %}{{- '<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n' }}{%- endif %}
{%- endif %}
{%- for message in messages %}{%- if (message.role == "user") or (message.role == "system" and not loop.first) or (message.role == "assistant" and not message.tool_calls) %}{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}{%- elif message.role == "assistant" %}{{- '<|im_start|>' + message.role }}{%- if message.content %}{{- '\n' + message.content }}{%- endif %}{%- for tool_call in message.tool_calls %}{%- if tool_call.function is defined %}{%- set tool_call = tool_call.function %}{%- endif %}{{- '\n<tool_call>\n{"name": "' }}{{- tool_call.name }}{{- '", "arguments": ' }}{{- tool_call.arguments | tojson }}{{- '}\n</tool_call>' }}{%- endfor %}{{- '<|im_end|>\n' }}{%- elif message.role == "tool" %}{%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != "tool") %}{{- '<|im_start|>user' }}{%- endif %}{{- '\n<tool_response>\n' }}{{- message.content }}{{- '\n</tool_response>' }}{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}{{- '<|im_end|>\n' }}{%- endif %}{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}{{- '<|im_start|>assistant\n' }}
{%- endif %}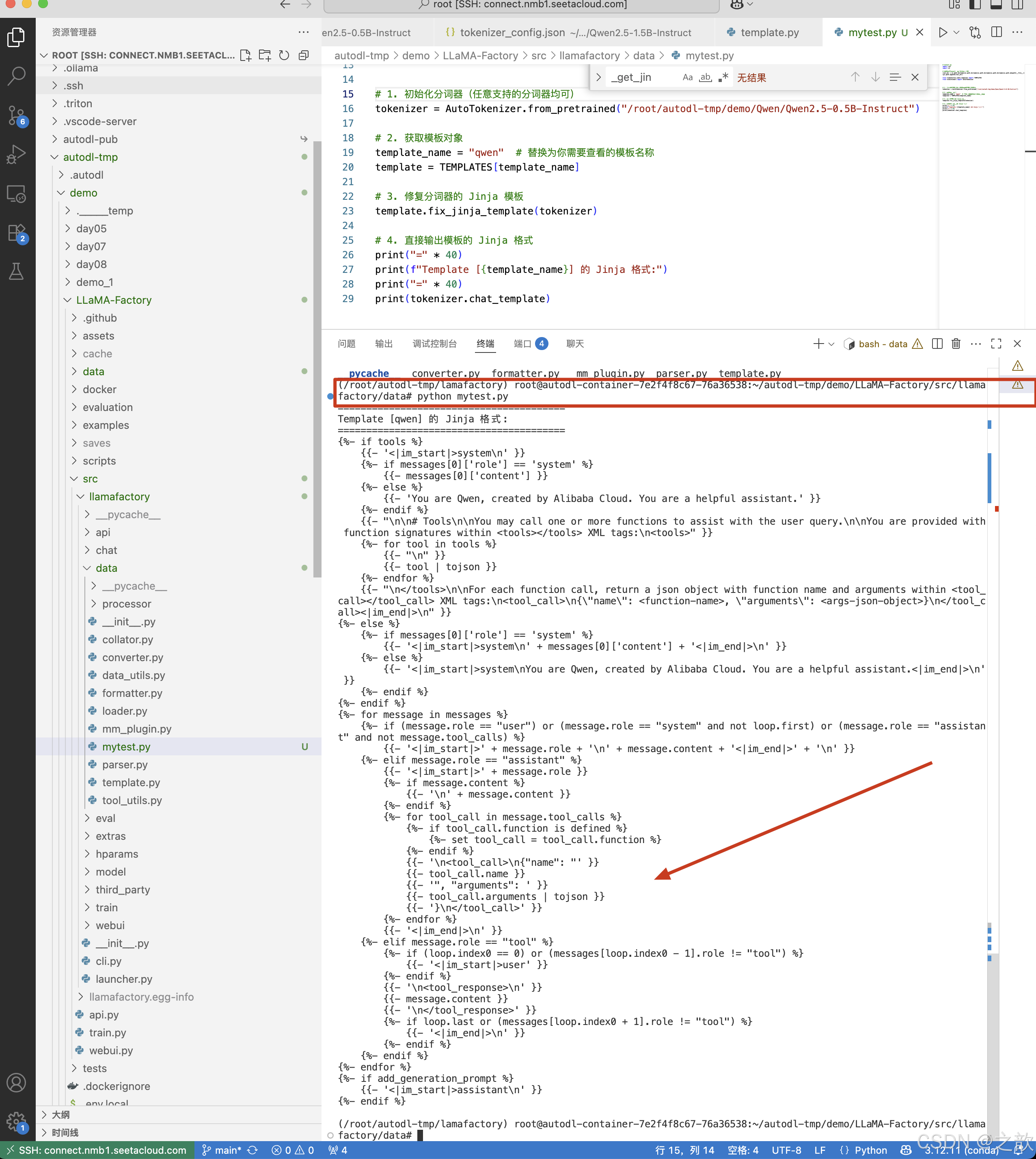
vllm推理模型時自定義對話模板
在用vllm 啟動模型的時候,指定會話模板
vllm serve <model> --chat-template ./path-to-chat-template.jinja
創建一個/root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct/custom_chat_template.jinja 文件,將上一步生成的對話模板內容拷貝到里面 。
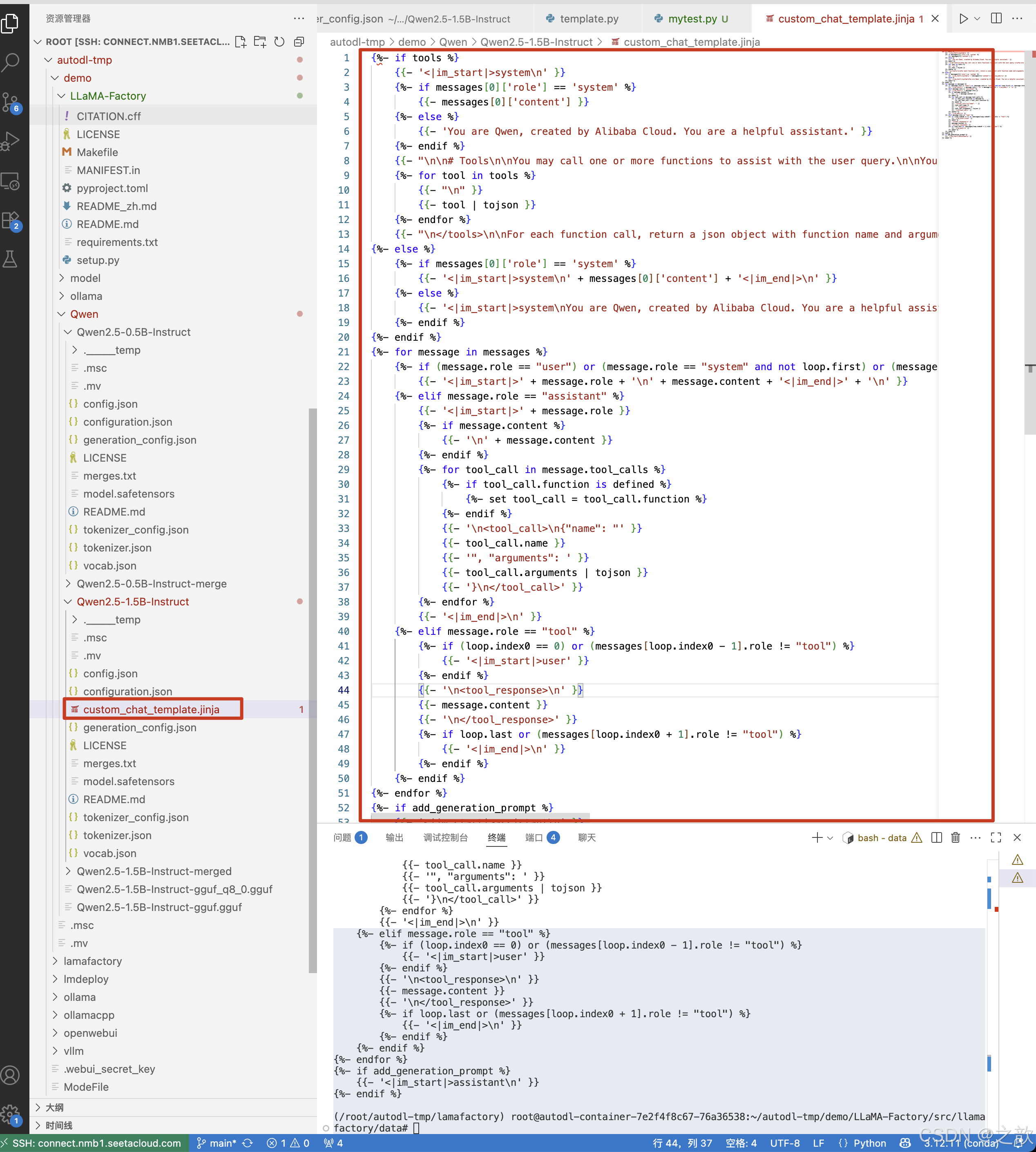
vllm serve /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct --chat-template /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct/custom_chat_template.jinja
test01.py
#多輪對話
from openai import OpenAI#定義多輪對話方法
def run_chat_session():#初始化客戶端client = OpenAI(base_url="http://localhost:8000/v1/",api_key="suibianxie")#初始化對話歷史chat_history = []#啟動對話循環while True:#獲取用戶輸入user_input = input("用戶:")if user_input.lower() == "exit":print("退出對話。")break#更新對話歷史(添加用戶輸入)chat_history.append({"role":"user","content":user_input})#調用模型回答try:chat_complition = client.chat.completions.create(messages=chat_history,model="/root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct-merged")#獲取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新對話歷史(添加AI模型的回復)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("發生錯誤:",e)break
if __name__ == '__main__':run_chat_session()輸出如下:

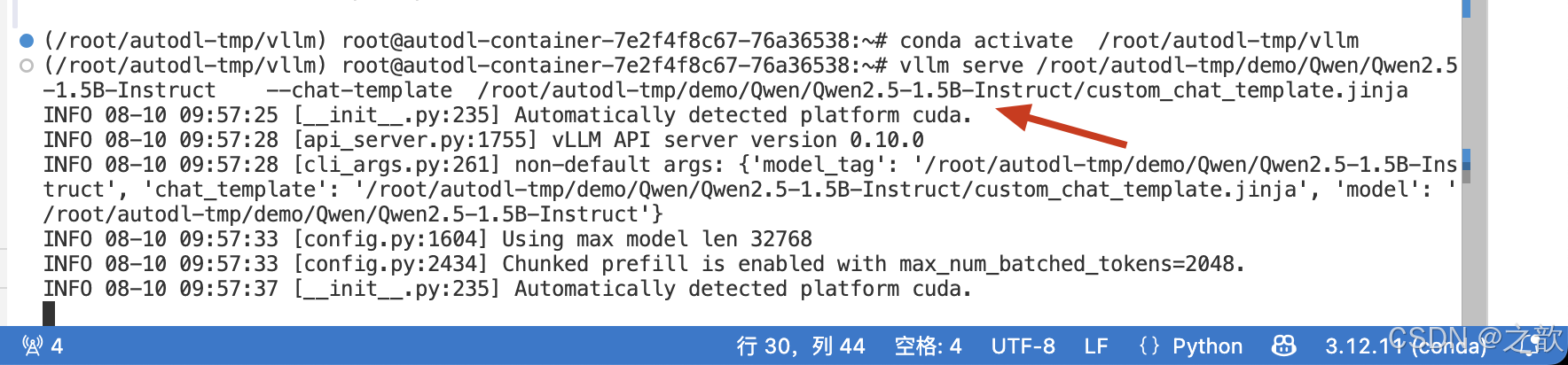
啟動vllm
vllm serve /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct --chat-template /root/autodl-tmp/demo/Qwen/Qwen2.5-1.5B-Instruct/custom_chat_template.jinja
案例:使用vllm有效部署Lora微調后的Qwen模型
但是需要注意的是 :open-webui 每次在啟動的時候,會將模型本身的會話模板給覆蓋掉,open-webui 目前沒有地方去指定自定義會話模板,因此在企業應用盡量不要使用open-webui

)
: 圖像表示;圖像通道分割;圖像通道合并;圖像屬性】)
)
)









——Nginx負載均衡)



:在QtOpenGL環境下,仿three.js的BufferGeometry管理VAO和EBO繪制四邊形)
