處理消息隊列(MQ)積壓是一個需要系統化分析的運維挑戰。下面我將結合常見原因,分步驟說明處理方案,并區分應急措施和根本解決方案:
?一、快速診斷積壓原因(核心!)??
- ?監控告警分析:??
- ?隊列深度監控:?? 檢查積壓量的增長趨勢(是突增還是持續上升?)
- ?生產者速率 vs 消費者速率:?? 對比消息生產速度與消費速度。
- ?消費者處理延遲:?? 監控單個消息處理耗時、失敗率、重試次數。
- ?資源監控:?? 消費者所在服務器的CPU、內存、磁盤IO、網絡I/O是否達到瓶頸?
- ?外部依賴:?? 數據庫連接池、下游API響應時間是否正常?
- ?日志分析:??
- 檢查消費者日志是否有大量錯誤/重試(如數據庫連接超時、HTTP調用異常、業務邏輯失敗)。
- 是否有GC停頓或內存溢出(OOM)導致消費者卡頓。
?二、應急處理方案(立即止血)??
| ?方案? | ?適用場景? | ?操作方式? | ?注意事項? |
|---|---|---|---|
| ?1. 縱向擴容? | 消費者資源不足 | 提升消費者服務器CPU/內存 | 物理機需重啟;虛擬機/容器可在線調整 |
| ?2. 橫向擴容(核心)?? | 消費能力不足 | 動態增加消費者應用實例數 | Kafka等需注意分區數限制(消費實例數≤分區數) |
| ?3. 緊急擴容Broker? | 積壓導致磁盤/內存不足 | 增加Broker節點或提升單節點配置 | Kafka需重新分配分區;RabbitMQ需調整集群 |
| ?4. 緊急處理臟數據? | 因特定消息卡死 | 將問題消息路由至死信隊列(DLQ) | RabbitMQ需配置DLX;Kafka需跳過異常消息 |
| ?5. 臨時限流? | 保護下游服務 | 主動降低生產者發送速率或暫停非核心生產 | Kafka可使用quota功能;RabbitMQ限流插件 |
| ?6. 遷移堆積隊列? | 積壓量過大阻塞集群 | 將部分分區/隊列拆分到獨立集群 | Kafka重分區;RabbitMQ重建隊列 |
?三、根本解決方案(預防再次積壓)??
- ?優化消費者性能:??
- ?異步/批處理:?? 將單條處理改為批量處理(如Kafka的
max.poll.records優化)。 - ?多線程處理:?? 在單個消費者進程內啟用線程池處理(需保證線程安全)。
- ?反序列化加速:?? 使用二進制協議(如Protobuf/Avro),避免JSON解析瓶頸。
- ?資源復用:?? 數據庫連接池預熱,HTTP連接池復用。
- ?異步/批處理:?? 將單條處理改為批量處理(如Kafka的
- ?邏輯優化:??
- ?避免循環調用:?? 消除消息處理中的同步等待(如遞歸查詢)。
- ?降級策略:?? 非核心操作可異步執行或跳過。
- ?消息壓縮:?? 啟用lz4/zstd壓縮減少網絡傳輸量。
- ?內存管理:?? 避免超大消息(>1MB),限制本地緩存大小。
- ?架構優化:??
- ?分區/隊列優化:?? Kafka根據流量分配分區數;RabbitMQ調整prefetch count。
- ?消費鏈解耦:?? 耗時操作拆分成多個隊列(如:接收隊列 → 處理隊列 → 存儲隊列)。
- ?流量分級:?? 突發流量獨立隊列 + 動態擴縮容。
- ?消費者池化:?? Kubernetes HPA根據積壓量自動擴縮實例。
- ?冷熱分離:?? 歷史數據歸檔至S3/對象存儲。
- ?容錯機制強化:??
- 合理配置重試次數(如3次)與退避策略(指數退避)。
- 死信隊列(DLQ)需有獨立監控和告警。
- 實現消費者健康檢查(如Kafka Lag Exporter報警)。
?四、關鍵維護實踐?
- ?容量規劃:??
- 壓測確定單分區的吞吐能力(如Kafka單分區5000-10000 msg/s)。
- 預留20%~30%的突發流量緩沖空間。
- ?監控覆蓋關鍵指標:??
- ?Kafka:?? Lag per partition, Produce/Consumer速率,Broker磁盤/CPU
- ?RabbitMQ:?? Queue depth, Unack消息數, Consumer數量
- ?自動化處置:??
- 當lag持續上升時自動觸發擴容
- 消費者死亡自動重啟
- ?消息治理:??
- TTL機制避免消息堆積(如RabbitMQ
x-message-ttl) - 定期清理測試隊列
- TTL機制避免消息堆積(如RabbitMQ
?五、技術選型建議?
- ?極高吞吐量(>100k/s):?? Kafka + 分區擴展
- ?靈活路由需求:?? RabbitMQ + 死信隊列 + 多機部署
- ?Serverless場景:?? AWS SQS / Azure Service Bus(自動擴縮)
- ?云原生集成:?? AWS Kinesis + Lambda Auto Scaling
?執行流程圖?
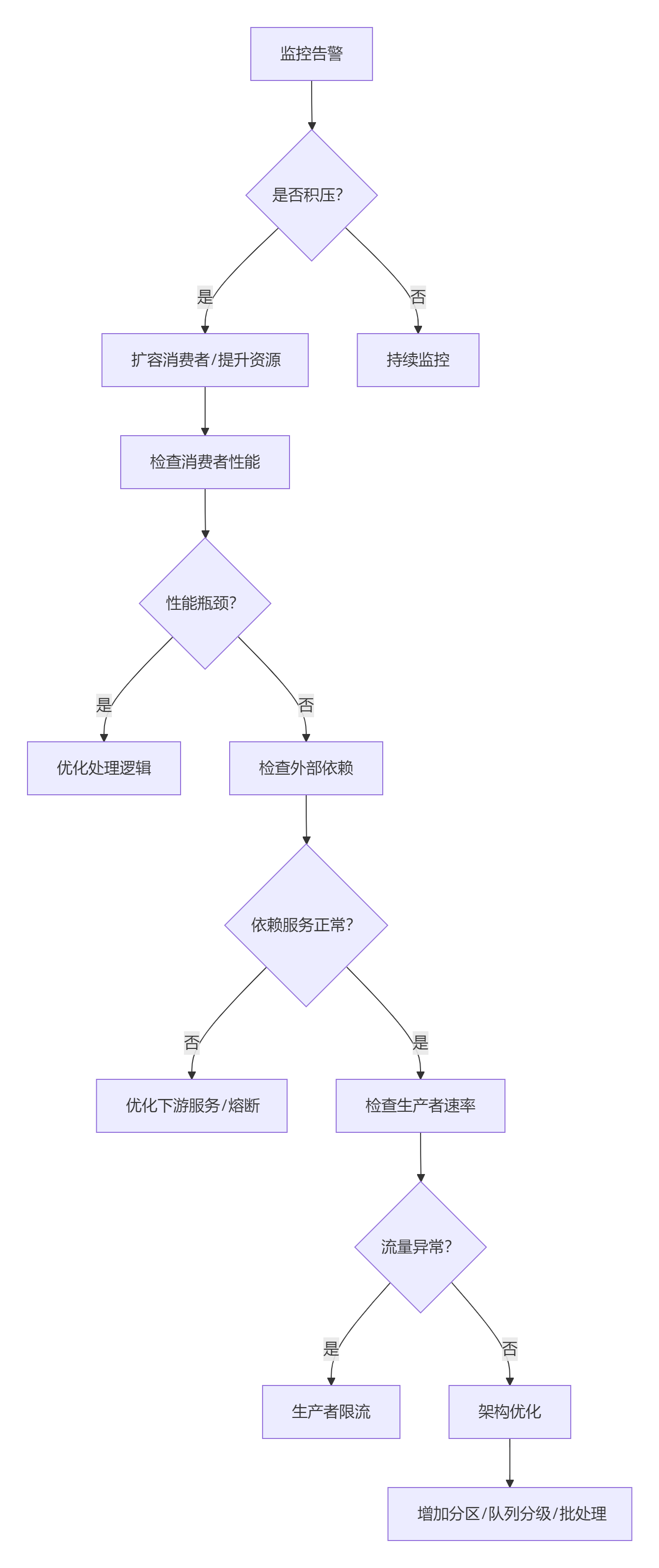
?注意事項:??
- ?避免無腦增加消費者:?? Kafka必須同步增加分區數,否則無效
- ?嚴禁跳過offset:?? 可能導致消息丟失,只應在測試環境使用
- ?監控延遲比隊列深度更重要:?? 例如消費滯后1小時需立即干預
- ?壓測:?? 任何優化后必須做全鏈路壓測,驗證吞吐量提升
📌 ?最終建議:?? 建立從監控告警→自動擴容→故障轉移→根因分析的閉環處理機制。每次積壓事件后需輸出故障報告,持續迭代SOP流程。
通過上述系統化的分析和操作,大部分消息積壓問題都能得到有效控制。務必優先保護消費端穩定性,再逐步提升系統吞吐量上限。


:在QtOpenGL環境下,仿three.js的BufferGeometry管理VAO和EBO繪制四邊形)



)



)
![[論文筆記] WiscKey: Separating Keys from Values in SSD-Conscious Storage](http://pic.xiahunao.cn/[論文筆記] WiscKey: Separating Keys from Values in SSD-Conscious Storage)
![week1-[循環嵌套]畫正方形](http://pic.xiahunao.cn/week1-[循環嵌套]畫正方形)





)
-大模型推理部署(分布式推理與量化部署)-大模型評估測試(OpenCompass))