論文鏈接:[2412.10840] Attention-driven GUI Grounding: Leveraging Pretrained Multimodal Large Language Models without Fine-Tuning
摘要
近年來,多模態大型語言模型(Multimodal Large Language Models,MLLMs)的進展引發了人們對其在自主交互和解讀圖形用戶界面(Graphical User Interfaces,GUIs)能力方面的極大興趣。這些系統面臨的一個主要挑戰是定位(grounding)——即根據GUI圖像和對應的文本查詢,準確識別關鍵的GUI組件(如文本或圖標)。傳統上,這一任務依賴于通過專門的訓練數據微調MLLMs,使其能夠直接預測組件位置。
然而,在本文中,我們提出了一種全新的**無調優注意力驅動定位(Tuning-free Attention-driven Grounding, TAG)**方法,該方法利用預訓練MLLMs中固有的注意力模式,在無需額外微調的情況下完成這一任務。
我們的方法通過在精心構建的查詢提示中找到特定tokens的注意力圖,并對這些注意力圖進行聚合,從而實現定位。將該方法應用于MiniCPM-Llama3-V 2.5(一個最先進的MLLM),我們的無調優方法在性能上達到了與基于微調的方法相當的水平,特別是在文本定位任務中取得了顯著成功。此外,我們證明了基于注意力圖的定位技術顯著優于MiniCPM-Llama3-V 2.5的直接定位預測,突顯了預訓練MLLMs的注意力圖的潛力,并為該領域未來的創新鋪平了道路。
一、引言
將人工智能與圖形用戶界面(Graphical User Interfaces,GUIs)相結合,具有巨大的潛力,可以徹底改變人類與軟件系統的交互方式。在這一創新的前沿,多模態大型語言模型(Multimodal Large Language Models,MLLMs)表現出色,能夠在各種應用場景中高效地理解GUIs。然而,在人工智能應用于GUI的任務中,GUI定位(GUI grounding)?是一項至關重要的任務,其目標是準確識別和定位GUI中的關鍵組件(如文本和圖標),因為這是實現GUI自動化操作的基礎。
盡管MLLMs在理解GUI圖像方面表現出色,但要實現對GUI元素的精確定位仍然面臨挑戰。當前最先進的解決方案通常依賴于在專門的數據集上微調MLLMs,以提升它們的GUI定位能力,例如(Hong et al. 2023;Cheng et al. 2024)等工作中所展示的方法。這些方法通過讓MLLM直接預測GUI元素的位置來完成任務。
與此不同,我們的方法走了一條不同的路徑。它通過利用預訓練MLLM固有的注意力模式,利用模型現有的空間感知能力和注意力機制,無需額外的微調便能夠實現準確的GUI定位。為此,我們提出了一種新穎的無調優注意力驅動定位(Tuning-free Attention-driven Grounding, TAG)方法,該方法通過精心選擇和聚合來自MiniCPM-Llama3-V 2.5這一最先進MLLM的注意力模式,完成GUI元素的定位。
我們的方法首先從用戶輸入的查詢或模型生成的響應中識別特定的tokens,然后將對應的注意力值反映到圖像平面上。為了進一步提升性能,我們設計了一種選擇機制,用于篩除無關的注意力頭,確保僅利用最相關的注意力信息來實現準確的定位。
我們將該方法與現有的基于微調的GUI定位方法進行了對比。結果表明,利用預訓練模型中的注意力模式可以實現準確的GUI元素定位。此外,我們的方法在文本定位任務中表現出顯著的提升。研究結果表明,充分挖掘模型固有能力的潛力可以帶來更強大、可擴展且高效的MLLM在GUI自動化中的應用。這也為未來開發更魯棒、更高效的GUI自動化系統鋪平了道路。
二、相關工作
用于GUI智能體的多模態大型語言模型(MLLMs)
MLLMs的應用標志著人工智能在與圖形用戶界面(GUIs)交互能力方面的重大進展。這些模型能夠理解用戶查詢和圖像,從而在從桌面到移動設備等各種平臺上完成任務。近年來,該領域的研究探索了多種應用場景,包括在桌面界面上自動化執行日常任務以及在移動平臺上提供交互式輔助功能。
這些應用展示了MLLMs作為自主智能體的潛力,它們能夠理解用戶命令并在不同平臺上執行任務。然而,挑戰在于如何有效地訓練這些模型,使其能夠處理GUI的復雜性和多樣性,同時避免對領域特定數據的廣泛調優。
GUI智能體中的定位(Grounding)
GUI智能體中的定位指的是模型準確定位和識別界面元素的能力,這是實現高效交互的關鍵。傳統方法通常需要在詳細注釋的數據集上進行微調。最近的研究探索了監督和無監督技術,以提高定位的準確性。例如,SeeClick模型通過在GUI特定數據集上進行微調來實現更高的定位精度。
然而,這些方法可能面臨可擴展性問題,并容易出現過擬合現象。我們的研究通過提出一種無調優方法,為該領域做出了貢獻。這種方法利用預訓練MLLMs固有的注意力機制,將文本查詢與視覺元素相關聯,從而提供了一種具有可擴展性和適應性的定位解決方案。
三、我們的方法
3.1 基礎知識:GUI定位
GUI定位是圖形用戶界面(GUI)智能體理解和交互中的一項關鍵任務,它要求系統能夠理解用戶的文本查詢,例如“我想預訂周二的牙醫預約”,分析GUI截圖,并準確定位相關組件。盡管近年來多模態大型語言模型(MLLMs)在理解文本查詢和視覺GUI布局方面展現出了潛力,但如果不借助OCR(光學字符識別)或Setof-Mark等額外工具,它們通常難以精準地定位元素。因此,當前的SOTA(最先進)方法通常依賴于在專門訓練數據上的微調來直接實現精確的元素定位。
MiniCPMV2.5及其注意力映射
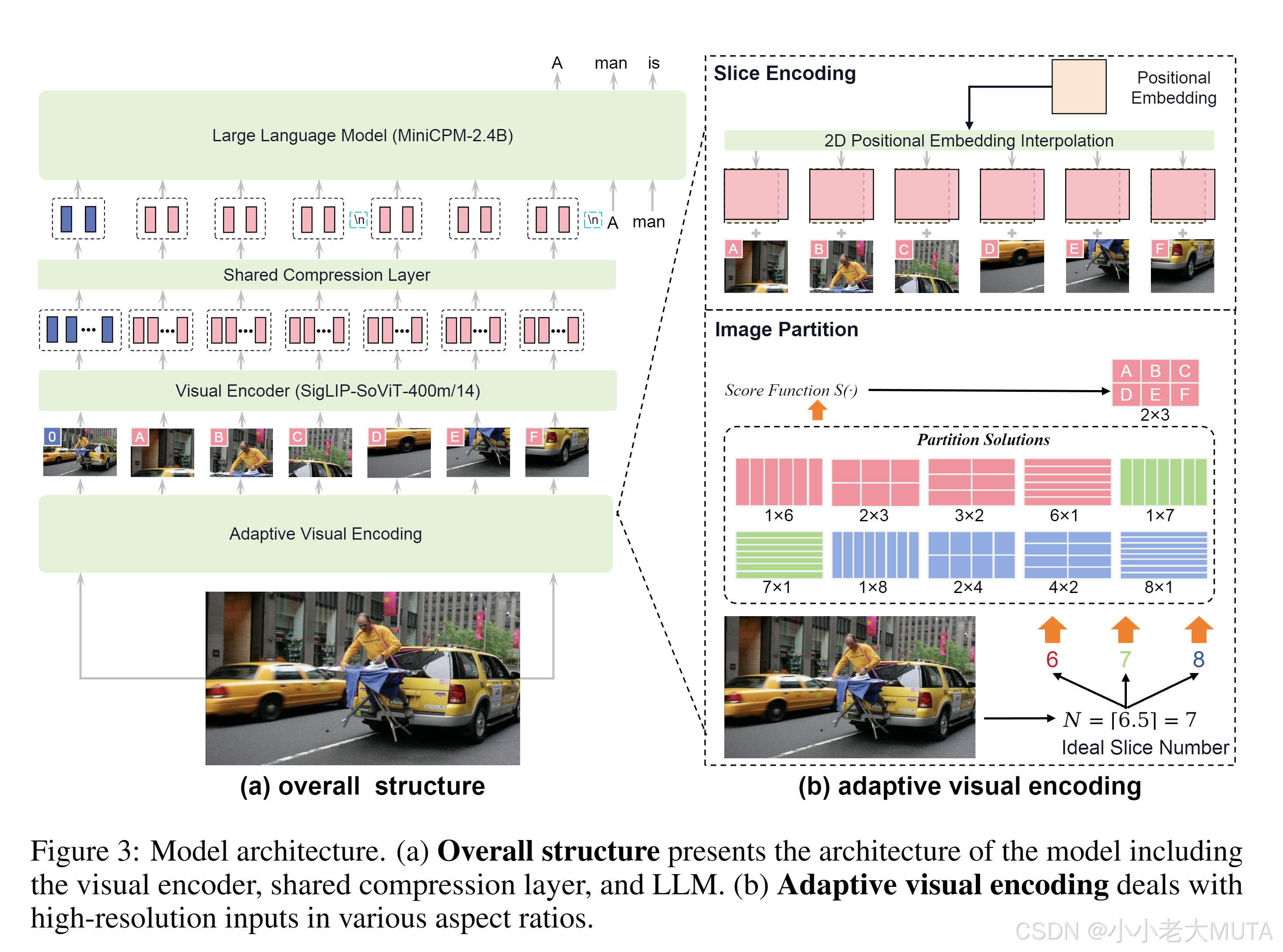
MiniCPMV2.5(即MiniCPM-Llama3-V 2.5)是最先進的MLLM之一,集成了視覺編碼器、token壓縮模塊和Llama3語言模型。它支持高達1344×1344像素、任意寬高比的高分辨率圖像,使其非常適合處理精確的GUI定位任務。
針對高分辨率輸入生成的大量視覺token,該模型使用跨注意力(cross-attention)將數千個視覺patch嵌入壓縮為固定大小(Q)的視覺查詢token集合。
這些視覺查詢token隨后與文本token一起由Llama3處理,Llama3通過多層transformer和多頭自注意力機制融合兩種模態。有關更多詳細信息,請參閱(Yao et al. 2024)的報告。
MiniCPM-V模型結構如下:
MiniCPM-V 的視覺編碼器基于 SigLIP SoViT-400m/14(一種改進的 Vision Transformer)作為核心,并采用了 自適應視覺編碼方法(Adaptive Visual Encoding),以高效處理高分辨率圖像并兼顧細粒度視覺理解能力。其流程主要包含以下幾部分:
自適應切片(Image Partitioning):
- 針對高分辨率和不同寬高比的圖像,采用自適應切片策略,將圖像劃分為多個切片,使每個切片的分辨率盡可能接近 ViT 的預訓練分辨率(例如?224×224 或?384×384)。
- 切片策略通過一個評分函數優化切片的行列分布,確保切片與 ViT 的預訓練分辨率兼容,同時限制切片總數(如?N<10),以控制計算開銷。
切片編碼(Slice Encoding):
- 每個切片在輸入 ViT 之前被調整為接近預訓練分辨率的尺寸,同時對 ViT 的位置編碼進行插值,使其適配切片的實際比例。
- 通過這種方式,ViT 能夠以最佳性能提取每個切片的特征表示。
位置編碼與全局信息保留:
- 在切片特征中加入位置編碼,保留切片在原始圖像中的空間位置信息。
- 此外,原始完整圖像也被作為額外的切片輸入,為模型提供全局視角。
Token 壓縮(Token Compression):
- 每個切片的視覺特征由 ViT 提取為 token(如 1,024 個),但多個切片的累計 token 數量可能會過高(例如 10 個切片會產生超過 10k 個 token),對計算和存儲帶來較大壓力。
- 為此,引入了?壓縮層,通過一層交叉注意力將每個切片的 token 壓縮為少量查詢 token(如 64 個或 96 個)。這種設計顯著降低了計算成本,同時保持了關鍵視覺信息。
空間位置信息增強:
- 為了進一步明確每個切片在圖像中的位置,模型通過?
<slice>?和?</slice>?特殊標記包裹每個切片的 token,切片之間用?\n?分隔,從而增強了跨切片的空間信息建模能力。(25 封私信) MiniCPM-V技術報告詳細翻譯解讀: 端側GPT-4V級別多模態大語言模型 - 知乎
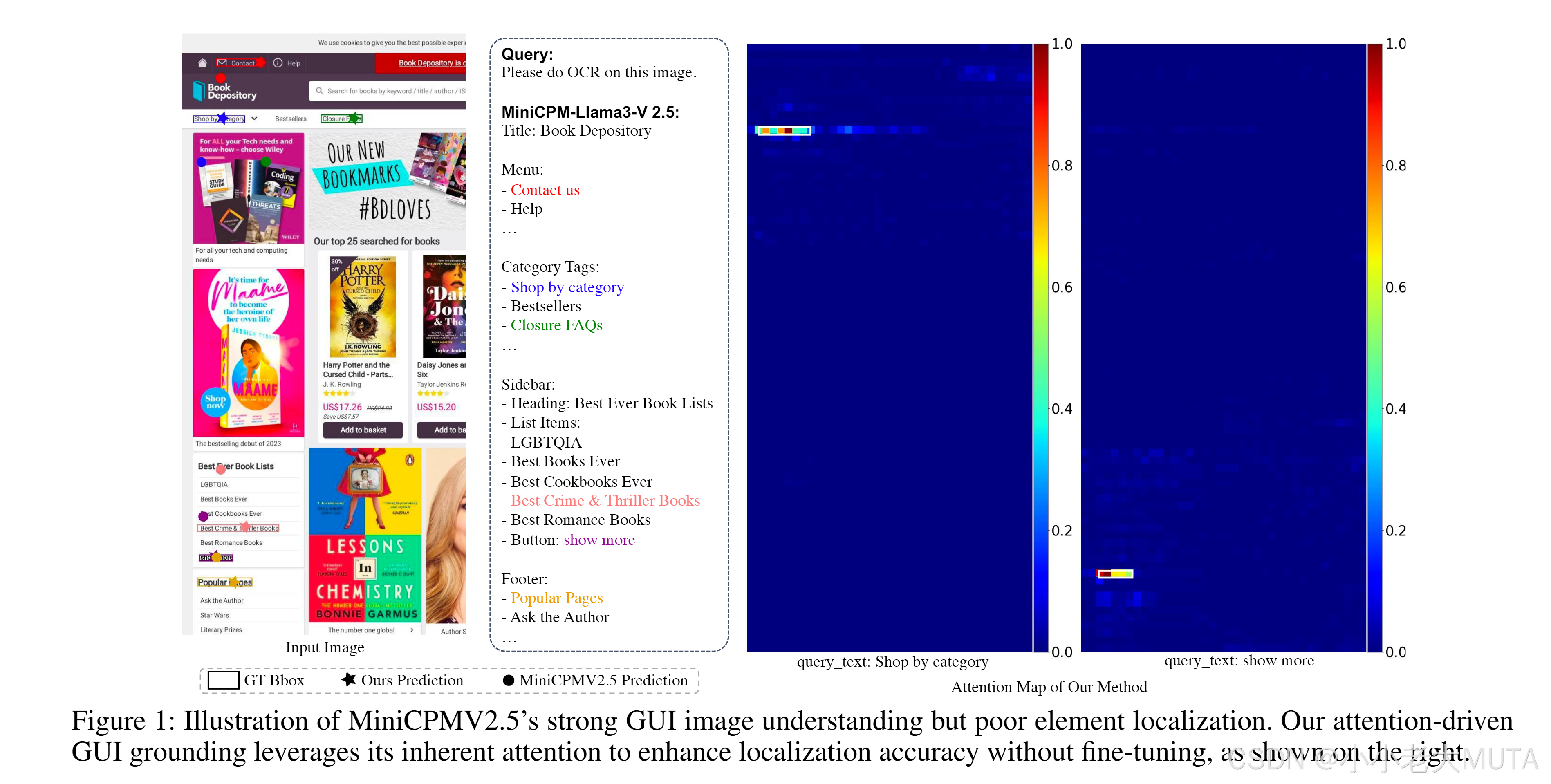
如圖1所示,實驗結果表明,當輸入GUI圖像時,MiniCPMV2.5在理解UI布局和準確識別圖像中的光學字符方面表現出較強的能力。此外,由于其在與對象檢測相關任務上的訓練,MiniCPMV2.5能夠通過預測目標對象的邊界框實現對象定位。
我們的方法旨在通過利用MiniCPMV2.5中的注意力圖進一步增強定位性能。
具體而言,MiniCPMV2.5主要包含兩個部分:token壓縮模塊和Llama3語言模型,這兩個部分都可以提取注意力權重。
在token壓縮模塊中,可以從跨注意力層中獲得注意力值。通過對所有注意力頭的注意力權重進行平均,我們可以得到一個注意力圖 ,其中Q是視覺查詢token的數量,H和W分別是分塊圖像的高度和寬度。
在Llama3語言模型中,自注意力權重可以表示為 ,其中N是多頭自注意力(MHA)層的總數乘以每個MHA的注意力頭數,M是輸入到LLM的token數量,包括視覺token和文本token。
3.2 方法的概述
該方法專注于從MiniCPMV2.5中選擇并聚合注意力權重,以實現GUI元素的精確定位。
核心見解在于:精心設計的選擇和聚合策略對于成功至關重要。具體來說,我們的方法包括以下三個組成部分:
1. 自適應文本token選擇
? ?包含所有token對的自注意力值,但并非所有令牌對都對有效的定位有貢獻。本組件的目標是識別最相關的令牌之間的注意力,從而確保定位的準確性。
2. 基于注意力驅動的GUI定位
? ?該組件聚合和
,利用這兩個注意力圖識別元素的定位位置。
3. 自注意力頭選擇
? ?該組件通過在Llama3中的1024個注意力頭中選擇高質量的注意力頭,進一步提升定位的準確性。
3.3 自適應文本token選擇
GUI定位任務的目標是定位與用戶查詢相關的界面元素。然而,用戶查詢通常包含許多token,但并非所有token都與目標GUI元素相關。一些查詢會明確指出目標元素,例如“跳轉到下一頁”暗示點擊“下一頁”按鈕,而另一些查詢則是間接表達的,例如“使用照片作為輸入”間接指向GUI中的“相機”按鈕。
如圖5所示,復雜的多步驟查詢在動態UI變化的情況下可能難以與界面元素對齊,從而導致不準確的定位。因此,必須開發一種機制來選擇關鍵token,并利用相關的自注意力權重以實現準確的GUI定位。

基于MiniCPMV2.5在理解GUI圖像方面的強大能力,我們提出了一種簡單但有效的策略:
- 通過構造查詢prompt,引導模型首先顯式生成與查詢相關的內容或元素的描述;
- 然后,我們利用這些描述性token
與視覺token之間的注意力權重來實現定位。
此方法通過彌合用戶查詢與UI元素之間的差距,顯著提升了GUI定位的性能。
3.4 基于注意力驅動的GUI定位
如3.1節所述,圖像token并不會直接輸入到LLM中,而是首先被壓縮為視覺查詢token,然后再傳遞到LLM中。這意味著,與目標GUI元素內容或描述相關的已選文本token,可能無法直接關注圖像的區域。
為了解決這一問題,我們提出了一種從已選文本token到圖像網格傳播注意力的方法。
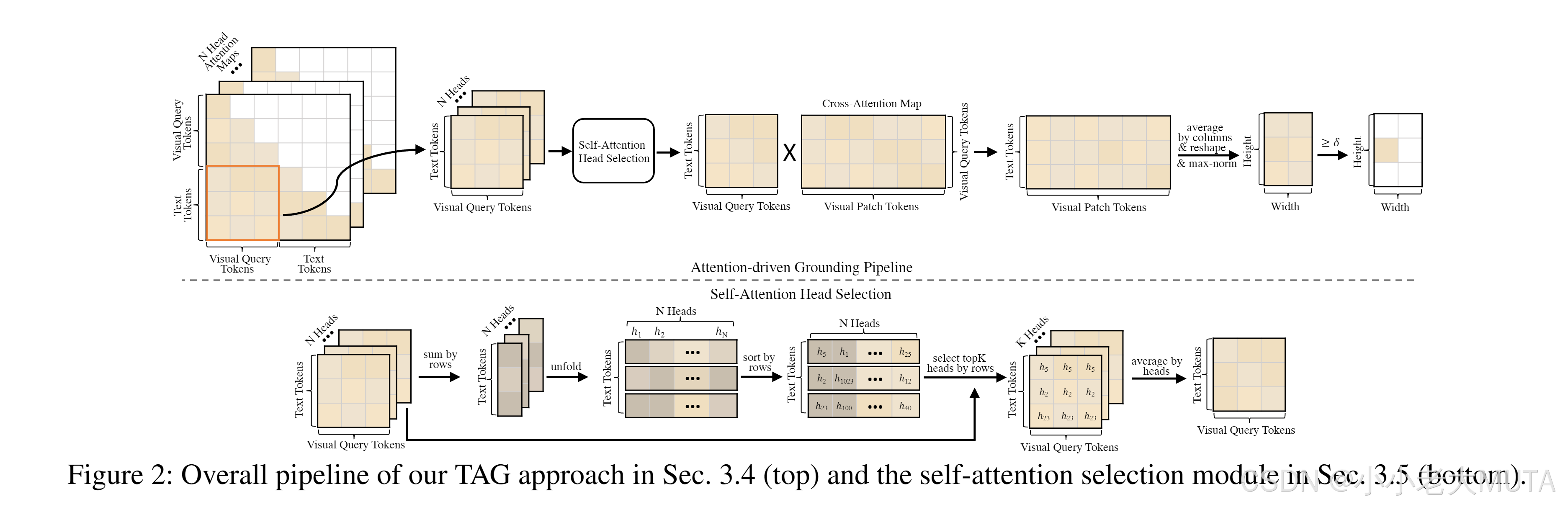
具體而言,如圖2所示,我們利用3.3節中的已選文本token,生成逐頭的注意力圖
,其中表示Llama3中所有層多頭自注意力機制中,這些文本token與視覺查詢token之間的注意力值。這里,N、T 和 Q 分別表示Llama3中的注意力頭數量、已選文本token數量以及視覺查詢token數量。
為獲取每個已選文本token與視覺查詢token之間的整體關系,我們通過加權求和聚合不同注意力頭的注意力值:
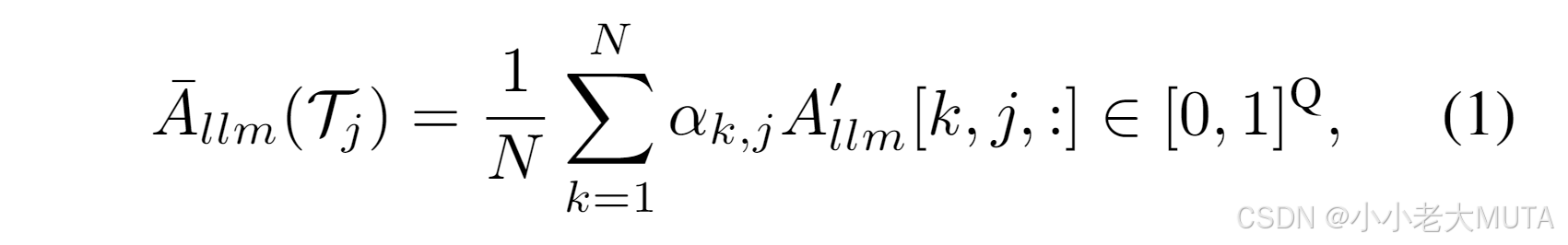
其中,k 是注意力頭的索引,是第k個注意力頭和第j個已選文本token的聚合權重。關于如何設置
的策略將在3.5節中討論。
得到 后,這表示每個已選文本token對每個視覺查詢token的注意力,我們將每個視覺查詢token的注意力傳播到對應的圖像patch token,使用
來實現。這通過一個簡單的矩陣乘法完成:
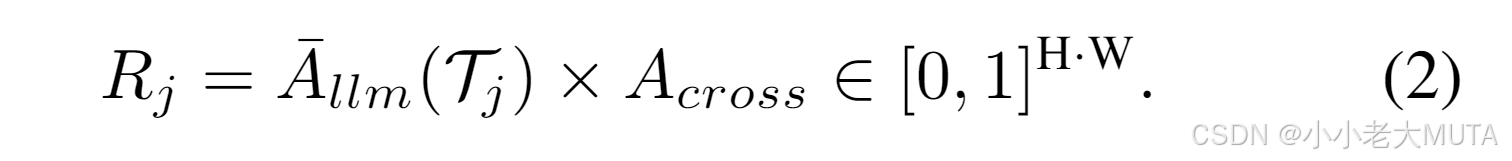
直觀上,這個操作將每個視覺查詢token接收到的注意力分布到對應的圖像patch token上,比例由視覺查詢token和每個圖像patch token之間的注意力值決定。
最后,為獲取查詢文本和圖像patch之間的整體關系,我們對不同的已選文本token取平均值:
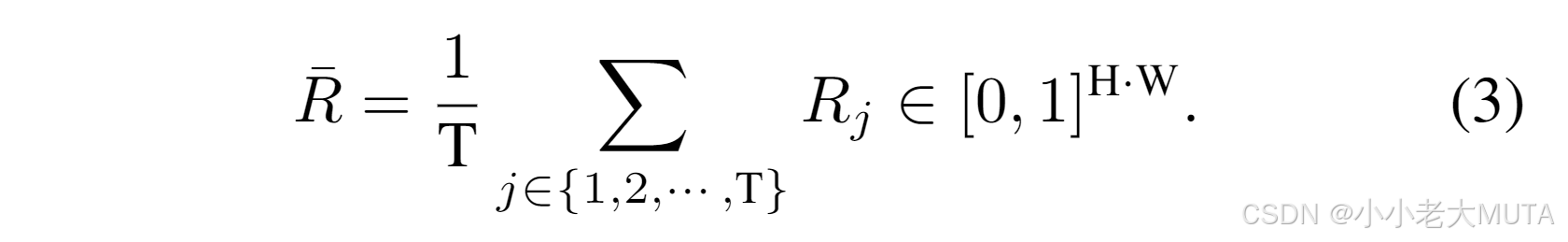
表示圖像patch與查詢之間的相關性。為實現像素級定位,我們首先通過為patch內的所有像素分配相同的值,將相關性得分從patch映射到像素級(例如一個14×14像素網格)。
接下來,我們應用一個閾值δ對圖像進行二值化,并識別出連通區域。選擇平均相關性得分最高的區域,其中心點作為預測的位置。
3.5 自注意力頭選擇
通過實驗證明,我們發現MiniCPMV2.5的LLM部分中的所有自注意力頭在將文本token與圖像patch對齊時,并非都同樣有用。
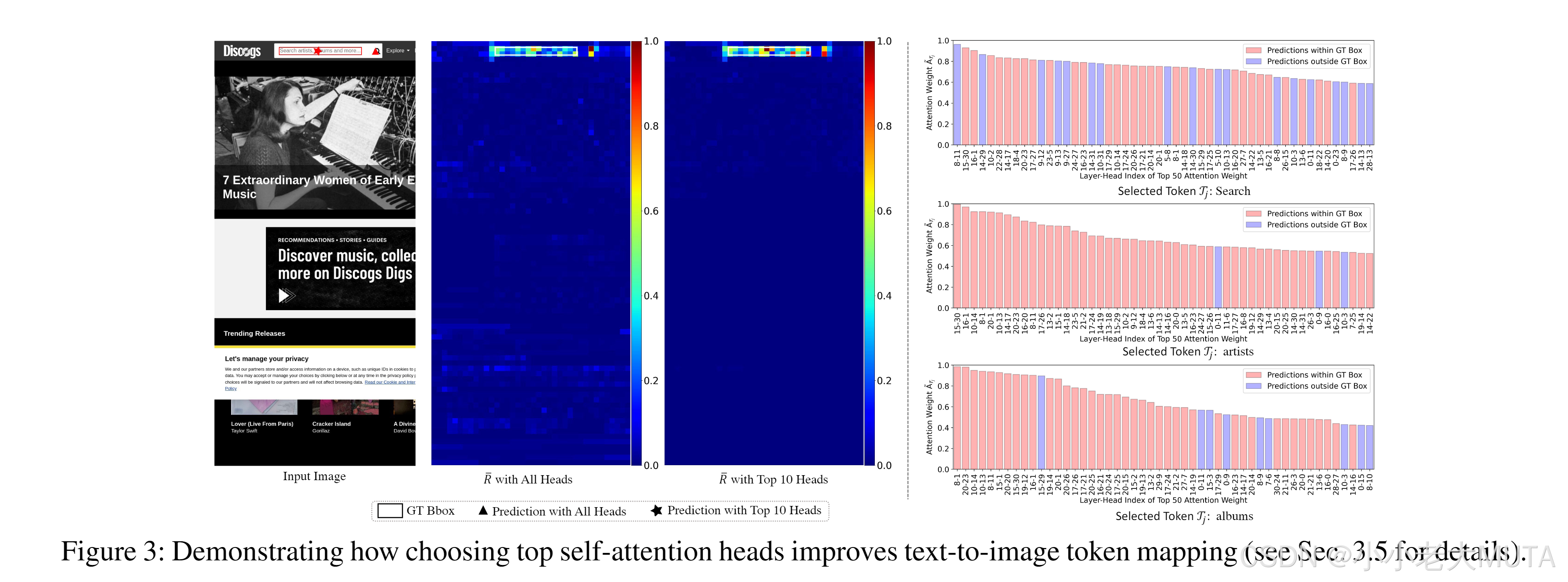
如圖3所示,為了在輸入框中定位文本“搜索藝術家、專輯和更多”,直接對所有頭的注意力圖進行簡單平均會錯誤地將目標定位到搜索圖標上。
為找到原因,我們進一步使用每個頭的自注意力分別映射每個文本token到圖像空間。正如圖3右側顯示的,總有一些注意力頭(用藍色表示)將文本token映射到真實邊界框以外的區域,這表明并非所有注意力頭都能有效地將token準確映射到預期區域。
為了確定注意力頭的質量,我們發現,選定文本token 和視覺查詢token之間平均注意力值的大小可以作為一個良好的指標:
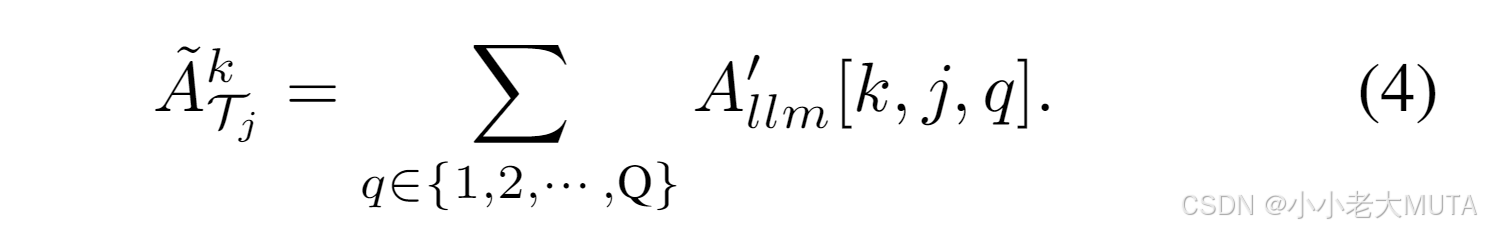
實驗觀察表明,當較大時,注意力頭更有可能將文本token映射到目標區域(如圖3所示,用紅色表示的頭通常在真實邊界框內預測)。
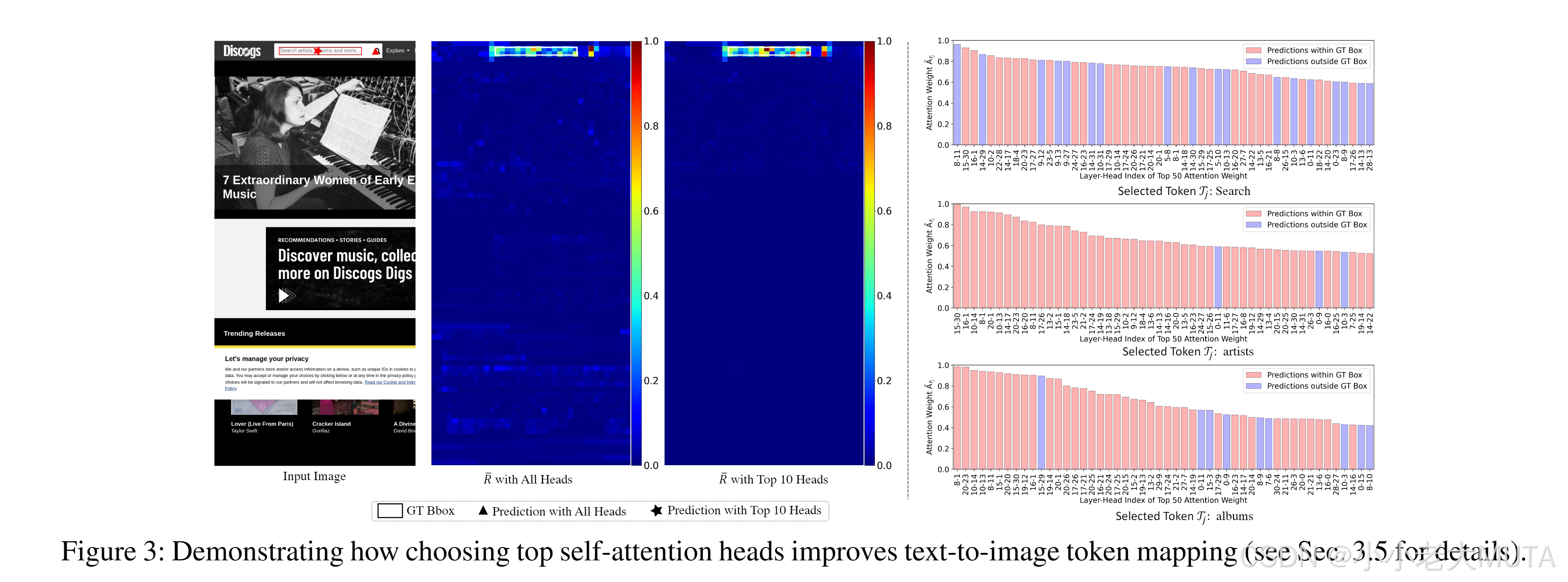
基于這一觀察,我們僅保留對應于的前K個最大值的注意力頭。
此外,我們觀察到,不同文本token的注意力頭排序通常不同。因此,我們為每個token單獨選擇前K個注意力頭。這種策略有效地將設置為“1”(對應于選定的注意力頭),而將其他頭的值設置為“0”。
四、實驗
在本節中,我們將我們的方法與三種SOTA(State-of-the-Art)方法在三個基準數據集上進行對比,這些基準從不同的角度測試了我們方法的效果。此外,我們還進行了多項消融實驗,以進一步分析我們方法的有效性。為了保證結果的可重復性,我們的方法使用貪心生成策略(greedy generation strategy),所有實驗均可在一塊NVIDIA RTX 4090顯卡上完成。
4.1 任務1:光學字符定位(Optical Character Grounding,OCG)
我們的方法主要通過將文本token映射到圖像空間來實現定位。為了直接驗證我們的方法,我們基于Mind2Web數據集開發了一個光學字符定位基準(OCG benchmark)。
雖然Mind2Web最初是為基于文本的(HTML)GUI智能體評估設計的,適用于網站環境,但它也包含了對應的截圖,我們利用這些截圖創建了全新的數據集——OCG。
OCG數據集
首先,我們從Mind2Web測試集中收集了104個網站的主頁截圖。然后,我們使用Azure Vision API工具提取每張截圖的OCR信息。該API可以識別截圖中的所有文本,包括圖像中的非界面元素文本,從而使我們可以評估MLLM(多模態大型語言模型)定位普通文本的能力。
此外,為了評估模型在不同圖像寬高比下的性能,我們從主頁截圖中裁剪出對應于不同寬高比的子圖像。我們僅保留完全落在這些子圖像內的OCR邊界框,用于評估。基于常見的屏幕分辨率,我們構建了10種不同的寬高比(寬度:高度):1:4、9:21、9:19、1:2、9:16、4:3、16:9、2:1、21:9和4:1。這種多樣化的寬高比設置使我們能夠全面評估模型在不同圖像尺寸下的魯棒性,這是現實應用中屏幕尺寸和方向變化顯著情況下的一項關鍵要求。
基線方法
我們將我們的方法與三種知名模型進行了基準對比:
1. MiniCPMV2.5:這是最近開源的SOTA MLLM,也是我們方法的基礎模型。
2. SeeClick:當前最先進的GUI定位方法。
3. Qwen-VL-Chat:SeeClick的基礎模型。
針對每個模型,我們使用了與其功能相對應的特定prompt:
- 對于Qwen-VL-Chat,我們使用了:“Generate the bounding box of {query text}”(生成{query text}的邊界框)。
- SeeClick的prompt為:“In this UI screenshot, what is the position of the element "{query text}" (with point)?”(在這個UI截圖中,元素"{query text}"的位置是什么?)。
- MiniCPMV2.5的prompt為:“What is the bounding box of "{query text}" in the image? The bounding box output format is: <box>xmin ymin xmax ymax</box>. Please directly output the bounding box.”(圖像中"{query text}"的邊界框是什么?邊界框的輸出格式為:<box>xmin ymin xmax ymax</box>。請直接輸出邊界框)。
對于我們的方法,我們使用prompt:“What is the bounding box of "{query text}"”("{query text}"的邊界框是什么)。由于查詢文本是通過OCR提取的,與圖像中的對應文本高度對齊,因此我們直接使用查詢文本來完成定位任務以驗證我們的方法。
結果
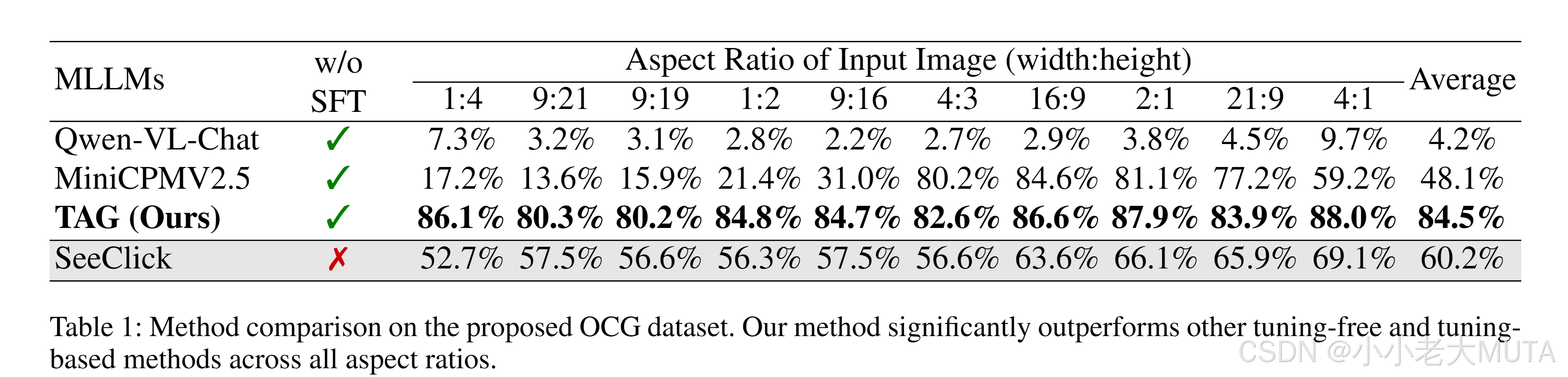
如表1所示,基礎模型Qwen-VL-Chat雖然能夠檢測一般對象,但在OCG任務中無法有效定位查詢文本。相比之下,更先進的MiniCPMV2.5在文本定位能力上有所提升。然而,MiniCPMV2.5在不同寬高比下的性能差異很大,例如在4:3寬高比上達到了80.2%的準確率,但在9:21寬高比上卻僅有13.6%。我們推測,盡管該模型支持任意寬高比的輸入,但其預訓練數據可能無法涵蓋所有寬高比的圖像,因此其定位能力很難很好地泛化到未見過的寬高比。
在經過GUI特定數據集的微調后,SeeClick在OCG任務上的表現相比Qwen-VL-Chat有了顯著提升,甚至優于更先進的MiniCPMV2.5模型。
值得注意的是,我們的方法在沒有額外的微調(SFT)的情況下,大幅增強了MiniCPMV2.5的定位能力。在10種不同寬高比設置下,我們的平均準確率達到了84.5%,比MiniCPMV2.5高出36.4%,比SeeClick高出24.3%。
4.2 任務2:GUI元素定位
接下來,在ScreenSpot數據集上評估了我們的方法,該數據集是一個GUI元素定位的基準測試集。
ScreenSpot數據集
ScreenSpot是一個由(Cheng et al. 2024)提出的真實定位評估數據集,包含了來自三個平臺(即移動端、桌面端和網頁端)的600多張GUI截圖。每張截圖包含多個命令指令及其對應的可操作元素,這些元素包括文本和圖標/控件類型的元素。
基線方法
按照(Cheng et al. 2024)中的設置,我們將我們的方法與多個流行的基礎MLLMs(多模態大型語言模型)進行了對比:
- MiniGPT-v2?
- Qwen-VLChat?
- 最新的?GPT-4V?
- MiniCPMV2.5
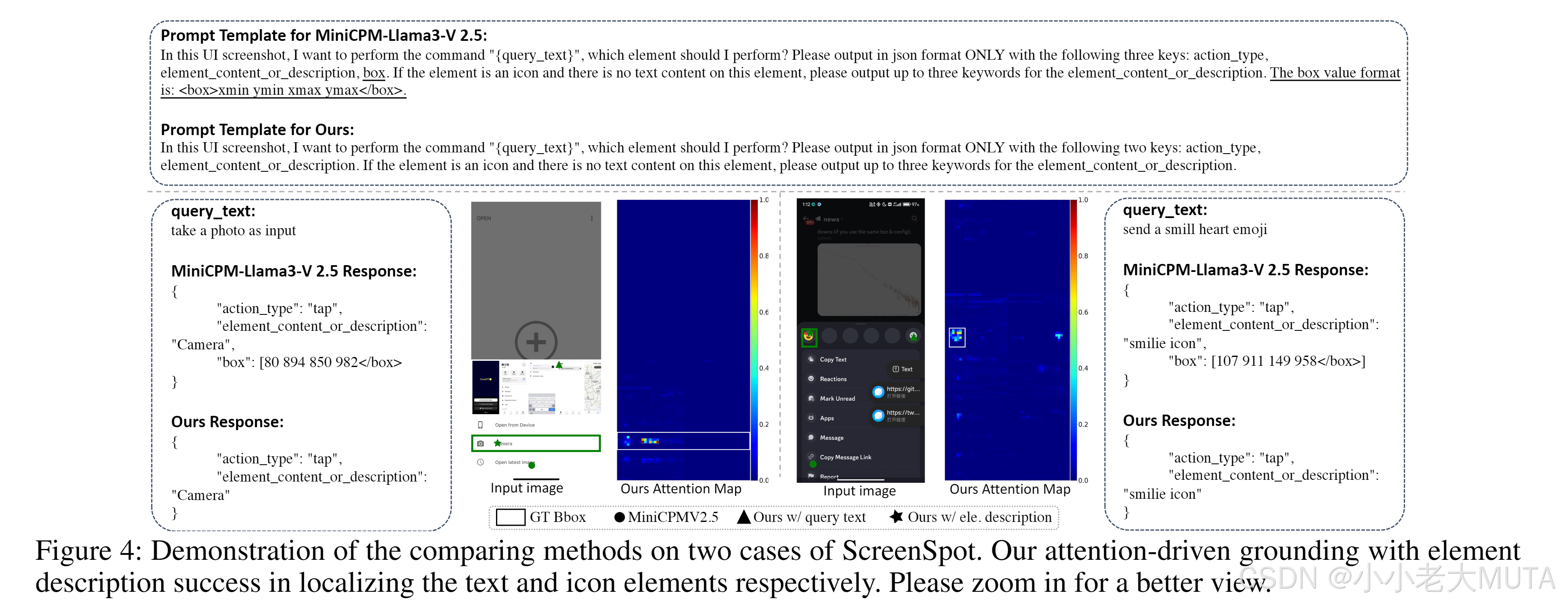
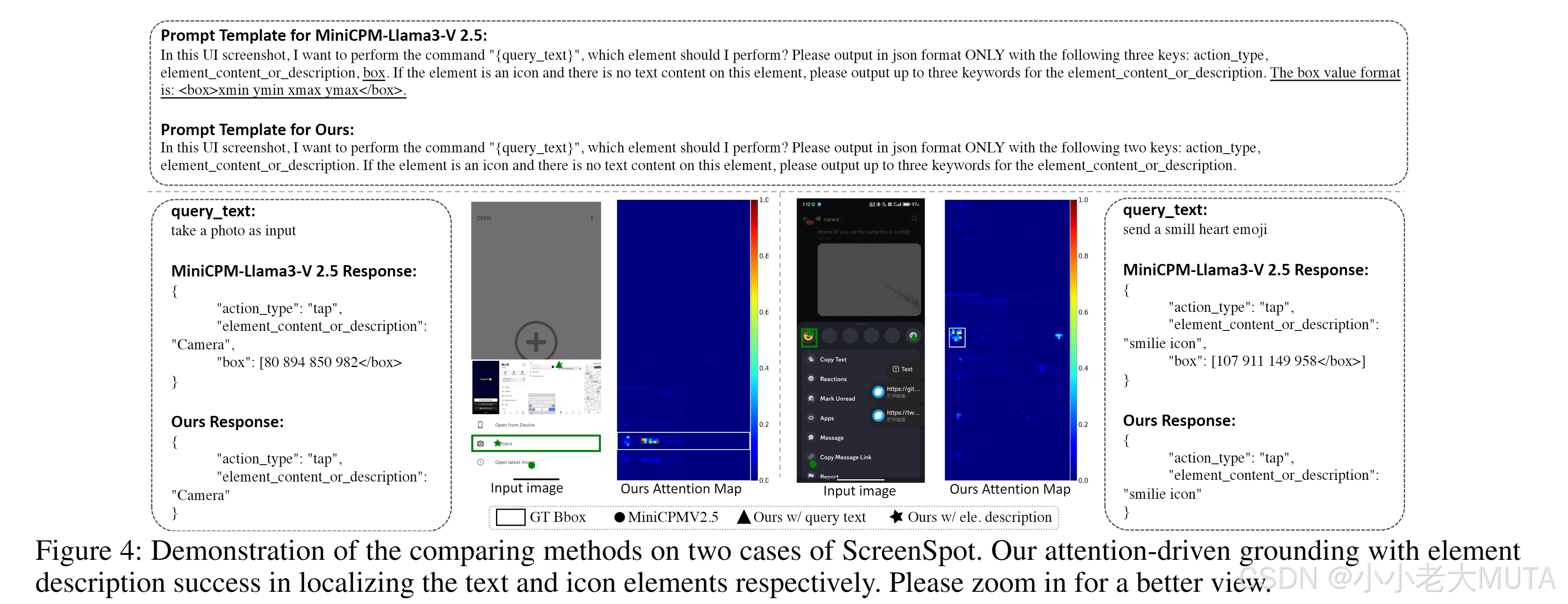
同時,我們還將我們的方法與CogAgent和SeeClick進行了對比,這兩者是目前最先進的GUI元素定位模型,經過大量GUI特定任務的監督微調(SFT)。為了公平對比,我們直接使用SeeClick中的評估設置,并與其論文中報告的結果進行比較。MiniCPMV2.5和我們方法的prompt模板如圖4所示。
結果
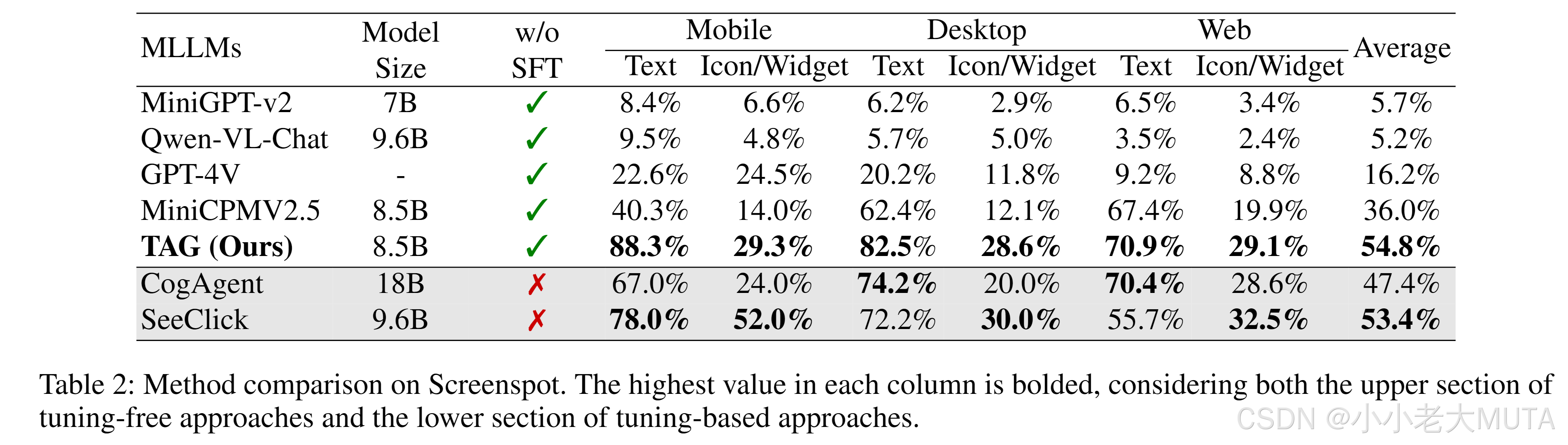
如表2所示,基礎MLLMs在GUI元素定位任務上的表現普遍較差。其中,MiniGPT-v2和Qwen-VLChat在所有平臺上的平均準確率低于6%,而GPT-4V僅達到16.2%。MiniCPMV2.5的表現略好一些,達到了36.0%,這可能是由于其與OCR相關的預訓練所致。
經過GUI特定任務微調的模型(如CogAgent和SeeClick)表現優于上述基礎模型。
然而,我們的方法在未經過額外微調的情況下(基于MiniCPMV2.5),達到了54.8%的平均準確率,顯著超過了GUI特定微調模型。我們的方法在文本定位方面表現尤為突出,其準確率分別為移動端88.3%、桌面端82.5%和網頁端70.9%。
如圖4所示的案例表明,與直接使用查詢文本相比,通過從生成的元素描述中自適應選擇文本token,可以更有效地完成GUI定位任務。
4.3 任務3:GUI智能體評估
我們進一步在GUI智能體基準數據集上評估了我們的方法。
Mind2Web數據集
Mind2Web數據集用于評估在網頁環境中的GUI智能體,主要基于文本型HTML內容。數據集中每個樣本通常包含一個開放式、高層次的目標指令,以及一條人類的操作軌跡序列,包括點擊、選擇和輸入操作。雖然發布的數據集還包含與每個樣本對應的GUI截圖,我們遵循的設置,僅使用GUI圖像進行評估。
由于本研究主要聚焦于GUI定位任務,我們在Element accuracy(元素準確率)指標上評估了對比方法。對于基于視覺的方法,若預測的坐標落在目標元素的bounding box內,則該預測被視為正確。
基線方法
我們將我們的方法與兩種基于視覺的GUI智能體進行了比較:
- Qwen-VL
- SeeClick
這兩個方法都在Mind2Web訓練集上進行了微調。此外,我們還包括了基礎MLLM MiniCPMV2.5 作為對比。我們方法的prompt模板如圖5所示。

由于篇幅限制,MiniCPMV2.5的prompt(與我們的方法類似)已包含在補充材料中。
結果
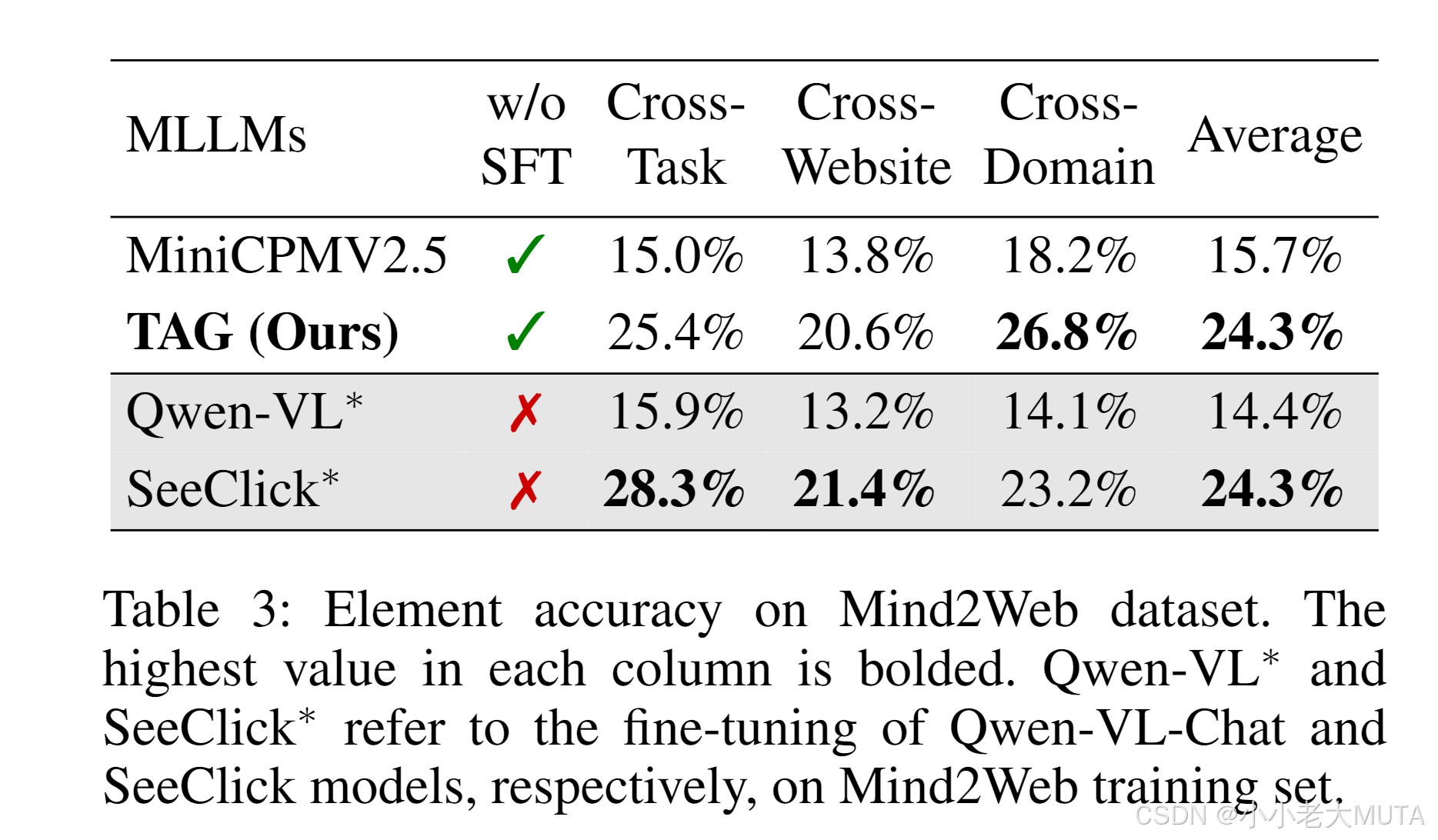
表3的結果表明,提出的基于注意力驅動的定位方法在所有設置中都提升了MiniCPMV2.5的元素準確率,達到了與最佳微調模型相當的平均準確率。
圖5展示了一個案例,表明我們的方法在每一步都能精確定位目標并成功實現整體目標。
4.4 消融研究
我們研究了TAG方法中每個組件的影響。
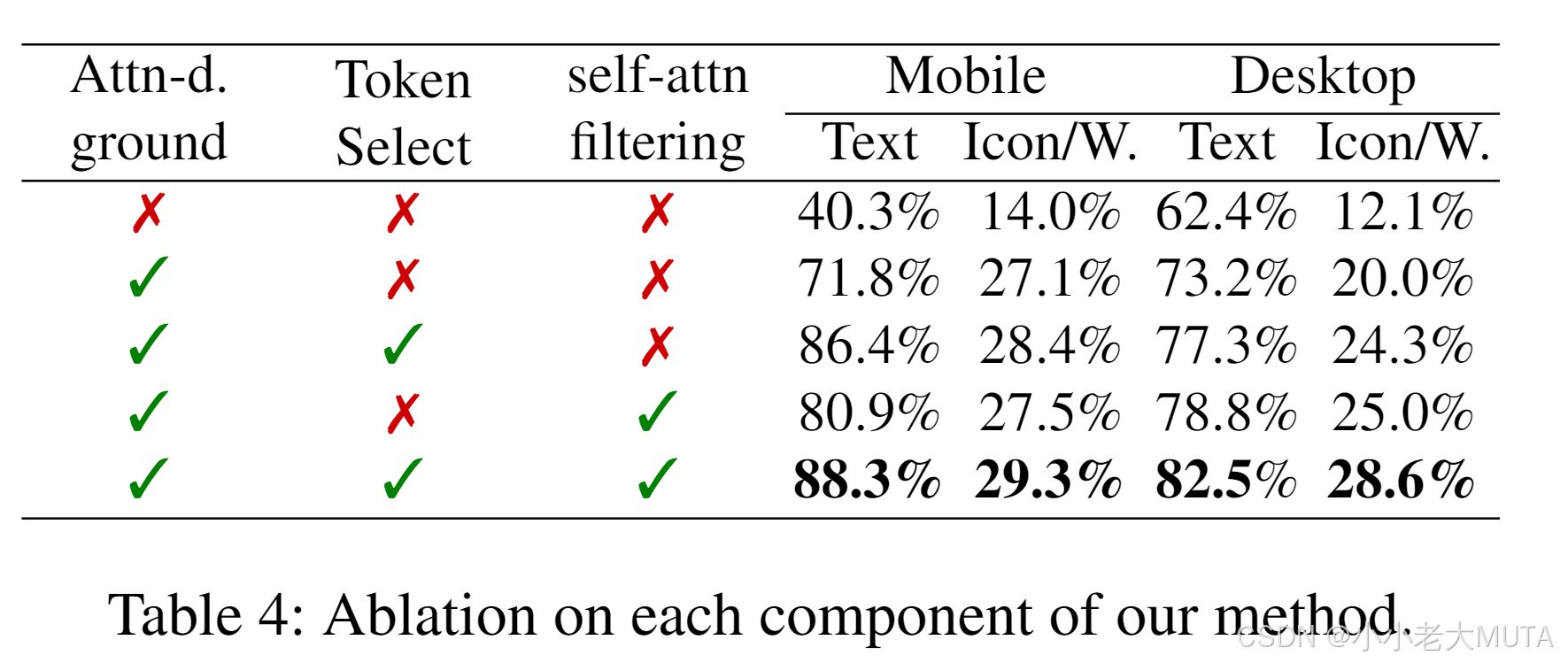
如表4所示,添加基于注意力驅動的定位顯著提升了性能,例如移動端文本定位的準確率從40.3%提升至71.8%。
引入自適應文本token選擇進一步改善了性能,特別是在移動端文本(86.4%)和圖標/控件(28.4%)的定位任務中表現突出。
完整模型結合了自注意力選擇,在所有指標上均表現最佳,在移動端文本(88.3%)和桌面端圖標/控件(28.6%)的準確率上取得了顯著提升。
4.5 更多討論
Top K 的影響
在我們的方法中,K用于過濾自注意力權重,僅保留排名靠前的注意力頭,用于文本到圖像的映射。
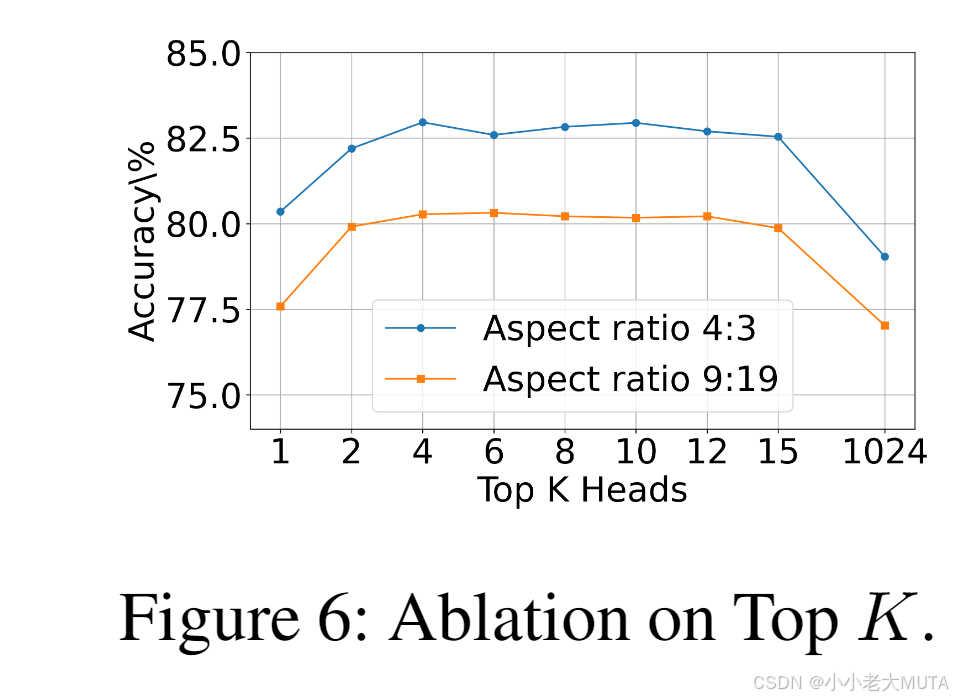
圖6表明,降低K值最初會提升性能,在兩個寬高比設置下,K = 10時表現最佳。
然而,極端的K值(如K = 1或K = 1024,即不進行過濾)會導致精度下降。這表明過濾掉噪聲注意力頭,同時保留足夠的文本到圖像映射信息,對性能提升是有益的。
基于這一結果,我們在所有實驗中均將K設置為10。
閾值δ的影響
閾值δ用于確定最終定位預測中的高亮區域。
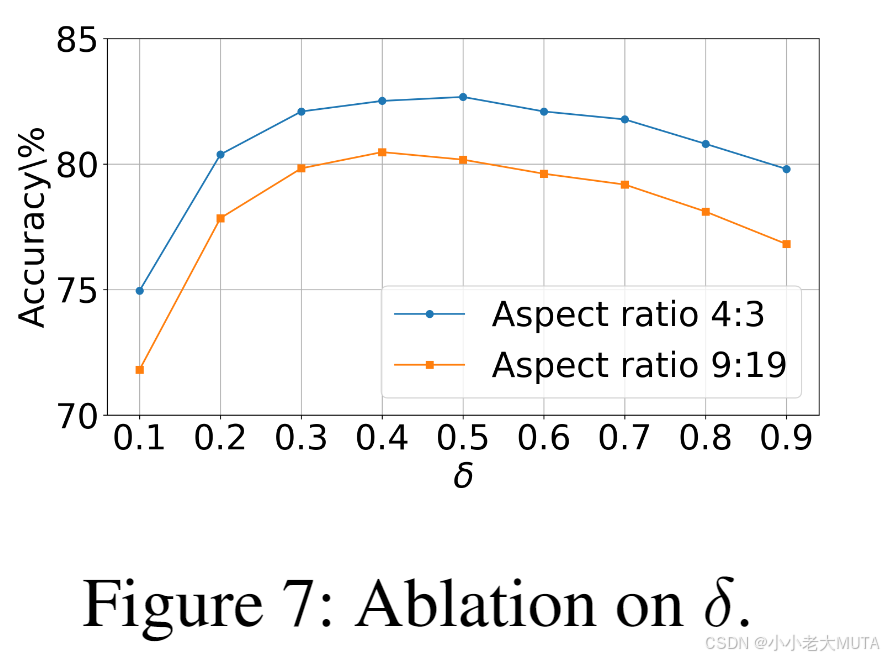
圖7顯示,當閾值δ ≤ 0.3時,模型的性能表現不佳,這是因為包含了過多關注度較低的區域。隨著δ值的增加,模型性能在δ = 0.5時達到峰值,但當δ進一步增大時性能開始下降。因此,我們在所有數據集上均將δ設置為0.5。
泛化能力
我們將注意力驅動的定位方法應用于另一個基礎MLLM模型——Qwen-VLChat(Bai et al. 2023),以驗證其泛化能力。盡管Qwen-VL-Chat最初在GUI定位任務中的表現較差,但通過應用我們的方法,其在Mind2Web-OCG數據集的4:3寬高比下準確率從2.7%提高到了10.2%。這一結果表明,我們提出的機制具有廣泛的適用性,可以推廣到不同的基礎MLLM模型上。
五、結論
本文提出了一種免調優的注意力驅動定位方法(TAG),該方法利用預訓練多模態大模型(MLLMs)中內置的注意力機制,在無需額外微調的情況下即可精準定位GUI元素。將TAG應用于MiniCPM-Llama3-V 2.5模型后,我們證明了通過充分利用模型內置能力,可以在性能上有效匹敵甚至超越傳統方法,尤其是在文本定位任務上表現尤為突出。這表明,MLLMs可以通過更高效的方式被使用,從而減少資源密集型微調的需求,同時避免了過擬合的風險。TAG方法有潛力應用于各種模型和多模態場景,為提升AI在人機界面交互中的適應性提供了一種有前景的解決方案。
局限性
TAG方法的表現嚴重依賴所使用的預訓練模型的能力和質量。如果這些模型本身存在固有偏差,或訓練數據的多樣性不足,TAG的效果可能會受到限制,進而影響其準確性和泛化能力。
為緩解這一問題,可以擴展用于MLLMs預訓練的數據集,這是一種具有前景的改進方向,但超出了本文的研究范圍。我們將其視為未來研究的重點。
6 補充材料
6.1 主文稿圖1中查詢的完整輸出
由于篇幅限制,圖1僅展示了模型輸出的部分結果。本補充材料的圖8中呈現了完整輸出內容。
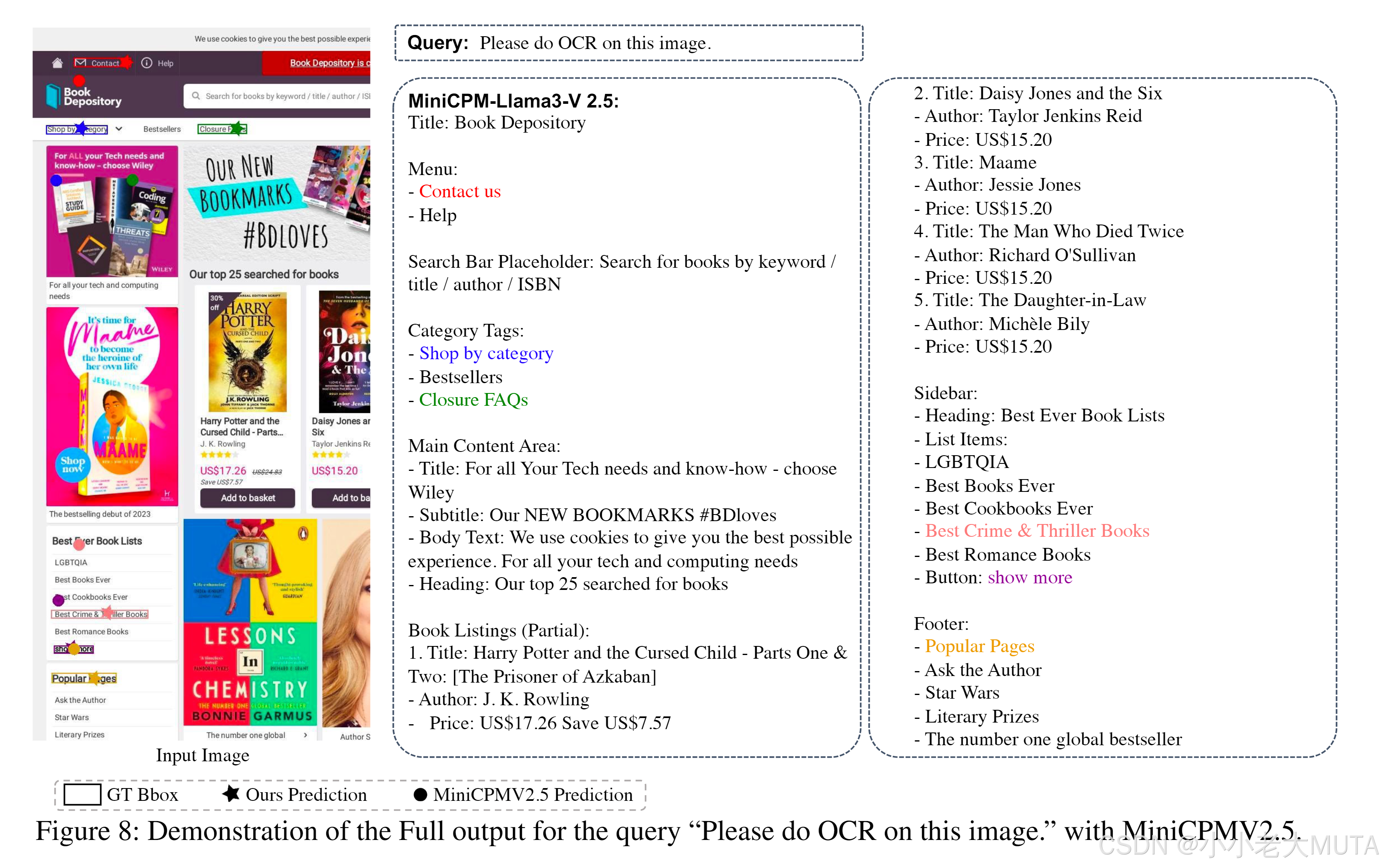
具體來說,我們進行了一個實驗,用于比較MiniCPMV2.5與我們的TAG方法在光學字符定位(OCR定位)能力上的表現。
首先,我們使用MiniCPMV2.5對圖像執行OCR操作,提示內容為:“Please do OCR on this image.” 然后,將生成的文本作為查詢輸入,同時測試兩種模型的文本定位能力。對于MiniCPMV2.5,我們使用的提示為:
“What is the bounding box of 'query text' in the image? The bounding box output format is: <box>xmin ymin xmax ymax</box>. Please directly output the bounding box.”
對于我們的TAG方法,我們使用了類似的提示:
“What is the bounding box of 'query text'?”
我們選擇了六個示例,每個示例都標記為不同顏色。實驗結果表明,雖然MiniCPMV2.5能夠理解文本內容,但在圖像中準確定位查詢文本時表現不佳。而我們的TAG方法能夠精準地定位文本,顯著優于MiniCPMV2.5。
6.2 MiniCPMV2.5的定位任務應用
MiniCPMV2.5在OCR相關數據集上進行了預訓練,根據作者的反饋,它支持三種位置格式:
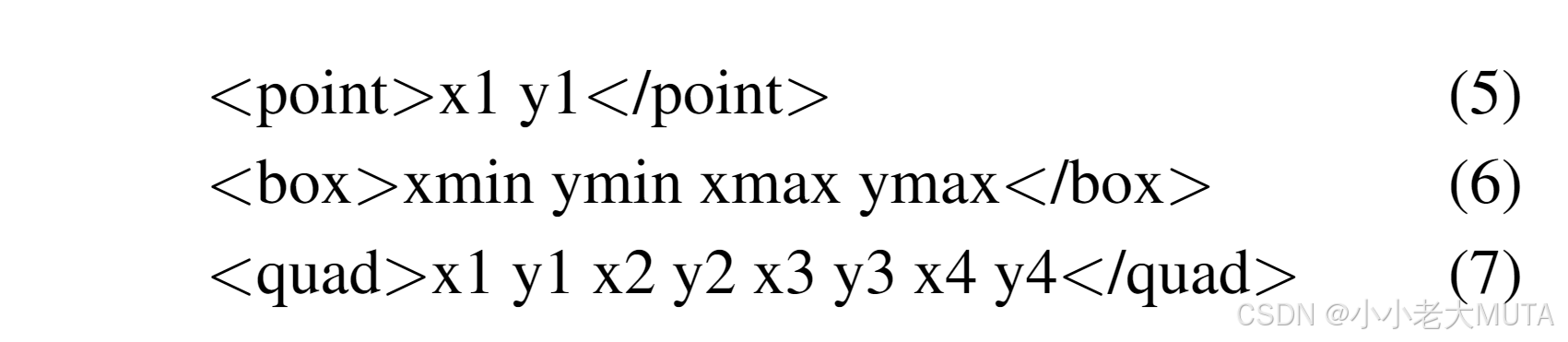
我們的實驗觀察表明,MiniCPMV2.5傾向于以框格式輸出位置信息。為確保解析一致性,我們在提示中明確要求使用框格式,從而引導MiniCPMV2.5生成穩定且易于理解的位置描述。
在MiniCPMV2.5的預訓練過程中,位置坐標被重新縮放到[0, 1000]范圍內。為了將生成的坐標映射回輸入圖像空間,我們采用以下轉換公式:
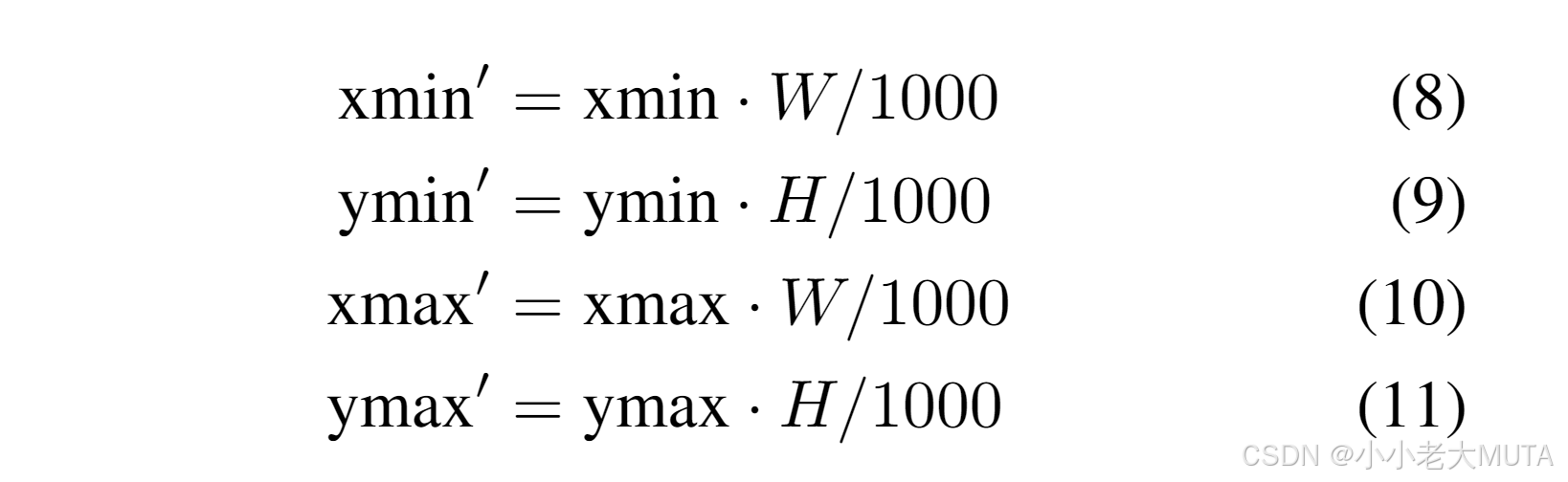
其中,W 和 H 分別為輸入圖像的寬和高。對于最終的定位預測,我們計算轉換后框的中心位置。如主文稿表1所示,此方法使MiniCPMV2.5在定位任務中取得了較好的準確率。
6.3 OCG數據集
OCG(Optical Character Grounding)是從Mind2Web測試集中派生的光學字符定位數據集,旨在驗證所提出的注意力驅動定位方法在文本到圖像映射任務中的能力。
該數據集包含104張網頁頁面截圖,每張截圖都附帶通過Azure Vision API生成的OCR數據(包括文本及其對應的邊界框)。
為適應不同的寬高比,圖像從原始截圖中裁剪而來,同時保留裁剪區域內的所有文本和邊界框。因此,在不同寬高比設置下需要定位的文本元素數量會有所不同。
數據集的詳細統計信息如表5所示,顯示了各種寬高比設置(寬:高)下的OCG樣本數量:

6.4 MiniCPMV2.5在Mind2Web數據集上的提示模板
MiniCPMV2.5使用的提示模板如圖9所示。為了確保公平比較,該模板與TAG方法中使用的模板幾乎完全相同。

6.5 Mind2Web數據集的操作歷史??
Mind2Web數據集包含多個樣本,每個樣本的總體目標通常需要通過多步與GUI的交互來完成。為了提供上下文信息,說明當前狀態是如何被達成的,通常會包含操作歷史。 ?
按照SeeClick 中采用的方法,我們在提示中加入了最近的四步真實操作記錄,以確保公平比較。以主文稿圖5中展示的案例為例,每一步使用的操作歷史如圖10所示。
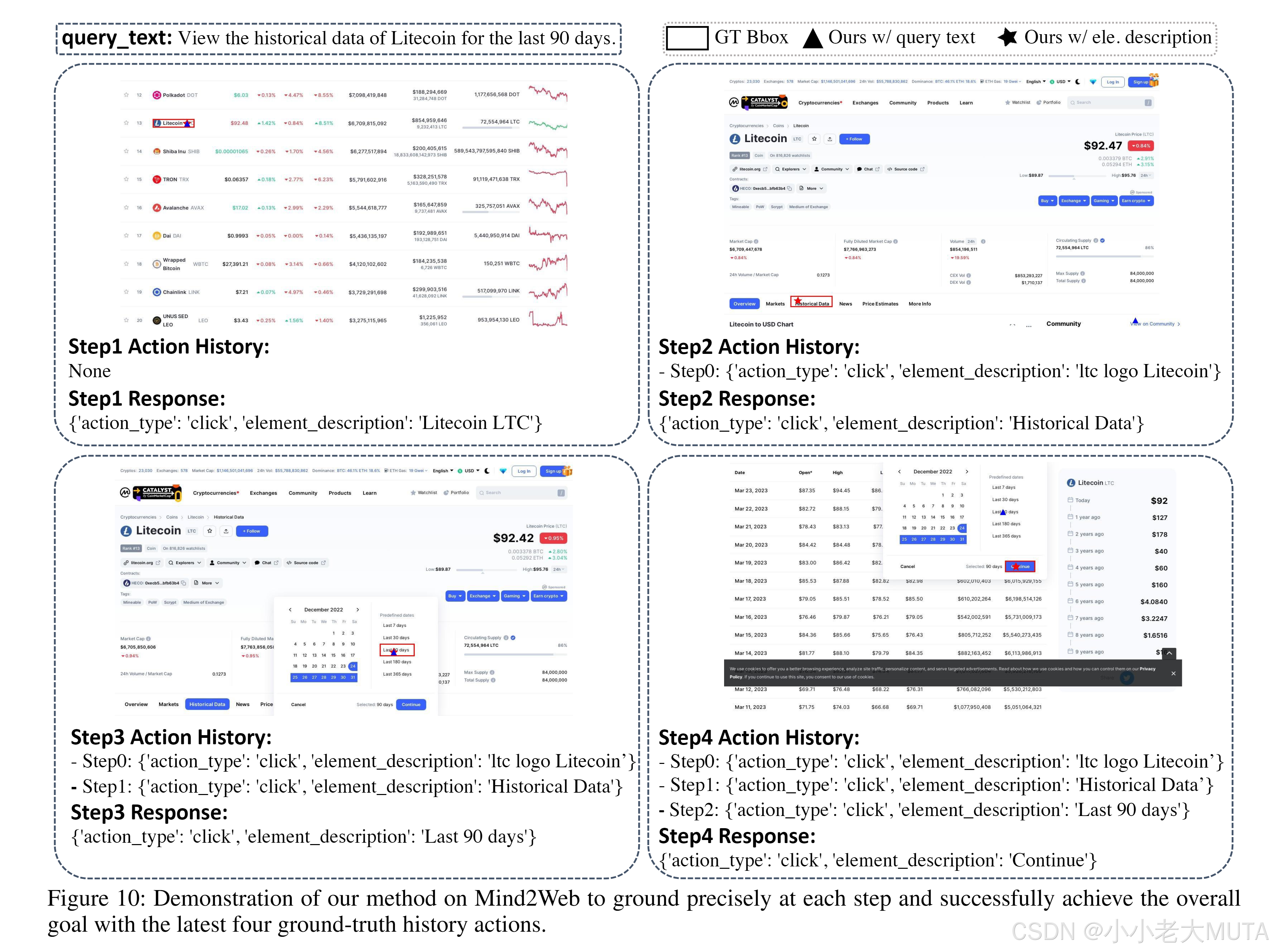
6.6 TAG的推理效率分析
表6比較了TAG與MiniCPMV2.5在screenspot-desktop測試集上的平均計算時間。
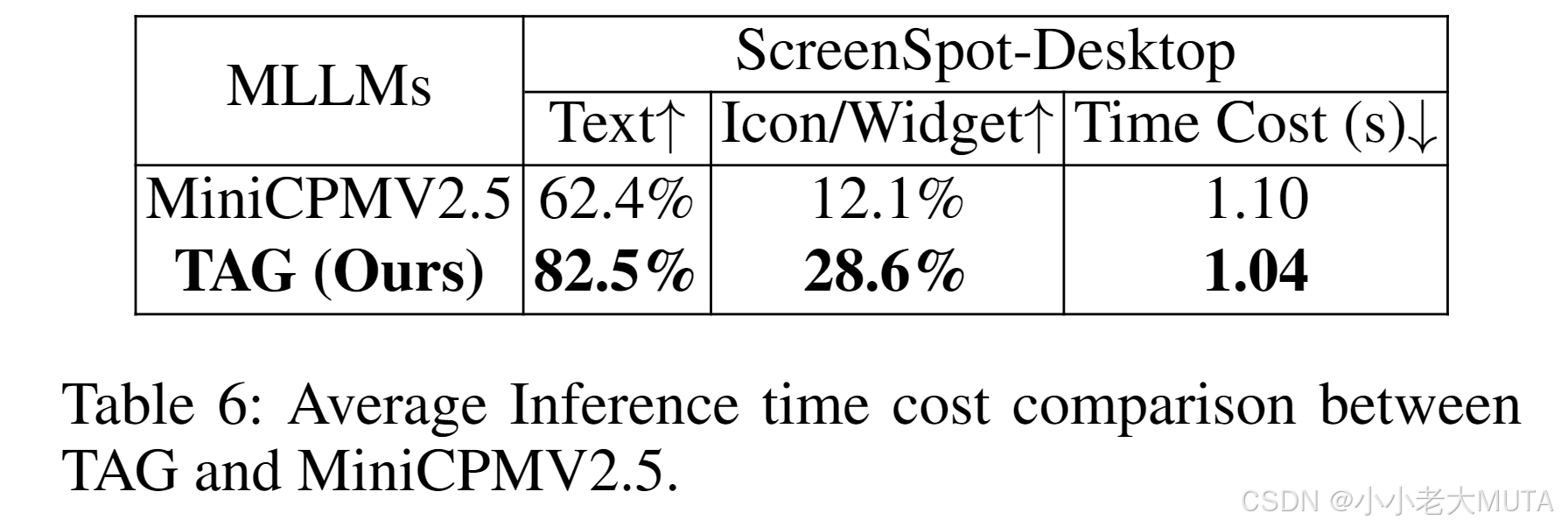
所用提示如主文稿圖4中所示。 ?
盡管TAG通過注意力選擇和向量乘積操作增加了一些額外的計算量,但它避免了輸出邊界框,從而減少了推理時的令牌長度(token length),可能降低了整體時間成本。 ?
結果是在NVIDIA RTX 4090 GPU上測得的。
6.7 在VisualWebBench上的評估??
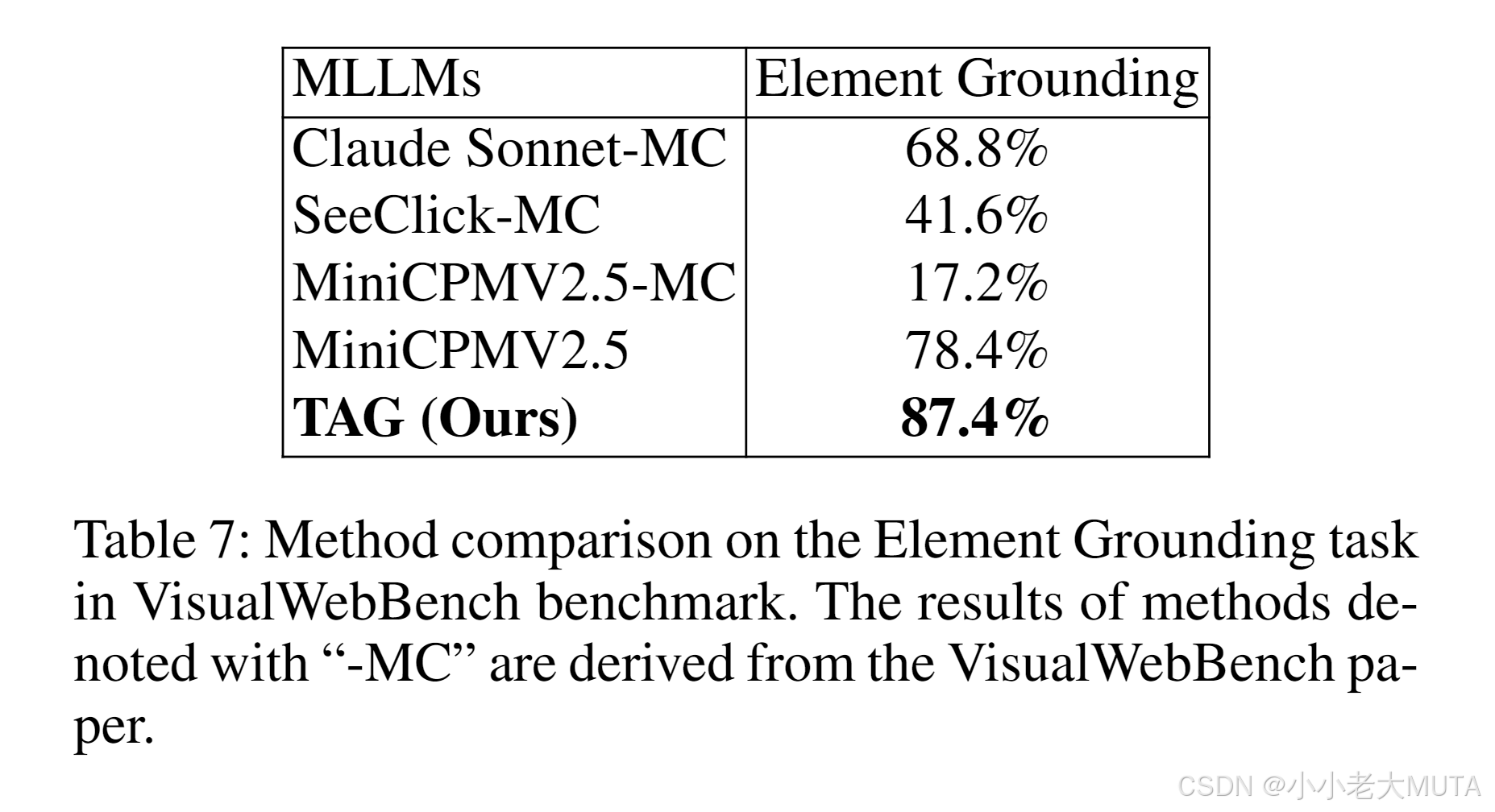
我們進一步在另一個基準測試集VisualWebBench的元素定位任務上評估了我們的方法。此數據集中的圖像標注了七種可能元素的邊界框和標簽,允許多模態大模型(MLLM)執行多選(MC)預測。 ?
對于MiniCPMV2.5,我們分別評估了多選定位和直接邊界框預測。在表7中,TAG在所有模型中表現最佳。

——Nginx負載均衡)



:在QtOpenGL環境下,仿three.js的BufferGeometry管理VAO和EBO繪制四邊形)



)



)
![[論文筆記] WiscKey: Separating Keys from Values in SSD-Conscious Storage](http://pic.xiahunao.cn/[論文筆記] WiscKey: Separating Keys from Values in SSD-Conscious Storage)
![week1-[循環嵌套]畫正方形](http://pic.xiahunao.cn/week1-[循環嵌套]畫正方形)



