Focus模塊:早期再yolov5版本提出,后期被常規卷積替換,作用是圖像進入主干網絡之前,進行隔行隔列采樣,把空間維度堆疊到通道上,減少計算量。
SPPF:SPP的改進版本,把SPP的不同池化核改變為K = 5 的池化核,然后不同的其他池化核都是用 k = 5 進行替換,并行結構改為并行 + 串行。
新的激活函數:silu,swish,如果swish的β參數為1,就轉化為silu
自動錨框計算:yolov5根據大量的數據集學習到比較好的一組尺寸的錨框,那么最開始的時候就是直接使用這些錨框,錨框自動計算,手動開啟(默認開啟)計算錨框的尺寸的時候,就會從新的基于數據集進行錨框計算。
1、模型訓練
訓練結果:
best.pt: 就是我們使用模型的文件,即整個訓練過程中最好的一次
last.pt: 整個訓練過程中最后一次,假設訓練模型500次,但是在中間訓練中斷了,就用last.pt恢復訓練,如果500次訓練完了,但是覺得可以繼續訓練,可以考慮best.pt當初始化權重文件來使用
使用訓練模型推理
yolov5s.yaml
網絡結構配置文件,重點掌握depth_multiple和width_multiple的使用,還需要掌握如果更改主干網絡或者檢測頭中的網絡層次,比如加入CBAM之后,如何對網絡的層次信息進行更新,因為新加入一個內容之后,在這一層之后的所有網絡層數都要+1
depth_multiple: 0.33 # model depth multiple
#這個參數就是控制輸出通道數量的倍率,最小為8
width_multiple: 0.50 # layer channel multiple
common.py
這個文件的內容就是定義模塊的。比如Conv 、C3等模塊,提供給后續文件使用構建網絡。
1、改進點
-
主干網絡是修改后的 CSPDarknet53,后面跟了 SPPF 模塊
-
網絡最開始增加 Focus 結構
-
頸部網絡采用 PANet、FPN
-
激活函數換成了 SiLU、Swish
-
采用 CloU 損失
2、Focus 模塊
-
YOLOv5 剛推出時,為了提升模型效率,采用了 Focus 模塊 作為網絡的初始特征提取層,傳統卷積下采樣會丟失部分空間信息,Focus 模塊旨在在不丟失信息的前提下進行高效下采樣
-
核心目標:將高分辨率圖像的空間信息通過切片操作轉換為通道信息,從而實現高效、無信息損失的下采樣
-
Focus 模塊是一種用于特征提取的卷積神經網絡層,用于將輸入特征圖中的信息進行壓縮和組合,從而提取出更高層次的特征表示,它被用作網絡中的第一個卷積層,用于對輸入特征圖進行下采樣,以減少計算量和參數量
-
Focus 層在 YOLOv5 中是圖片進入主干網絡前,對圖片進行切片操作,原理與 Yolov2 的 passthrough 層類似,采用切片操作把高分辨率的圖片(特征圖)拆分成多個低分辨率的圖片(特征圖),即隔列采樣+拼接
-
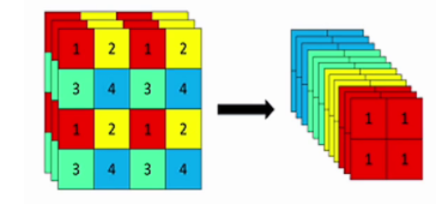
具體操作是在一張圖片中每隔一個像素拿到一個值,類似于鄰近下采樣,這樣就拿到了 4 張圖片,4 張圖片互補,但是沒有信息丟失,這樣一來,將空間信息就集中到了通道空間,輸入通道擴充了 4 倍,即拼接起來的圖片相對于原先的 RGB 3 通道模式變成了 12 個通道,最后將得到的新圖片再經過卷積操作,最終得到了沒有信息丟失情況下的二倍下采樣特征圖
-
案例:假設輸入一張圖像大小為 640x640x3
-
第一步:640 x 640 x 3的圖像輸入Focus結構,采用切片操作
-
第二步:然后進行一個連接(concat),變成 320 x 320 x 12 的特征圖
-
第三步:經過一次 32 個卷積核的卷積操作,最終輸出 320 x 320 x 32 的特征圖
-
-
在 YOLOv5 剛提出來的時候,有 Focus 結構,從 YOLOv5 第六版開始, 就舍棄了這個結構,改用 k=6×6,stride=2 的常規卷積
3、網絡結構
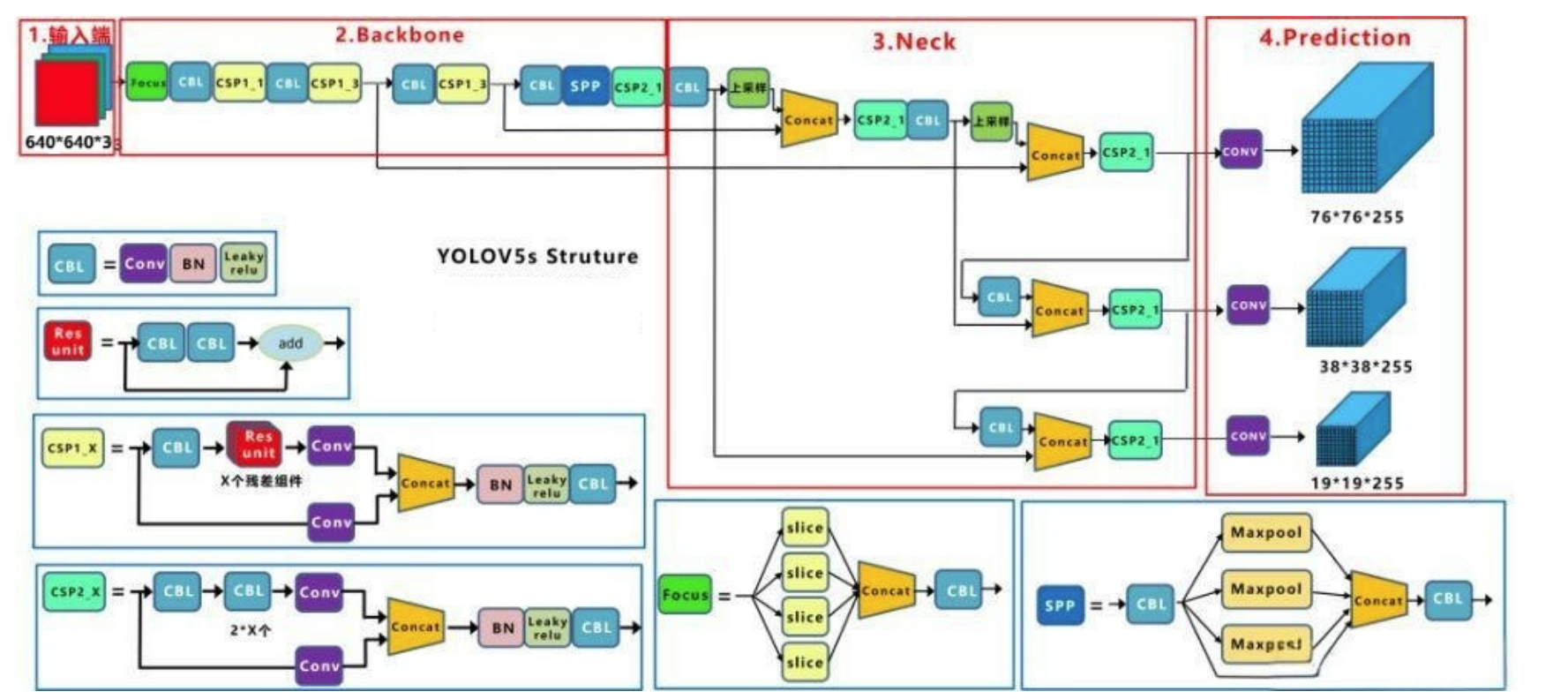
3.1 CSP1_X 與 CSP2_X
-
CSP1_X:
-
定義:帶 shortcut(殘差連接)的 CSP 模塊
-
結構特點:內部包含帶有 shortcut 的 Bottleneck 結構
-
應用場景:主要用于 backbone 部分,如 CSPDarknet53,增強特征提取能力
-
X 的含義:表示 bottleneck 的數量
-
-
CSP2_X:
-
定義:不帶 shortcut 的 CSP 模塊
-
結構特點:內部沒有 shortcut 連接,僅通過卷積操作進行特征提取
-
應用場景:主要用于 neck 部分,如 PANet(Path Aggregation Network),進行特征聚合
-
X 的含義:表示 bottleneck 或其他卷積模塊的數量
-
3.2 自適應Anchor的計算
-
在 YOLOv3、YOLOv4 中,訓練不同的數據集時,計算初始 Anchor 的值是通過單獨的程序運行的。但 YOLOv5 中將此功能嵌入到代碼中,每次訓練時會自適應的計算不同訓練集中的最佳 Anchor 值
-
實現方式:
-
在訓練開始前,YOLOv5 會自動加載訓練集中的標注框
-
使用 K-Means 聚類算法計算 Anchor
-
將結果作為初始 Anchor 值用于模型初始化
-
-
源碼位置:
utils/autoanchor.py/check_anchors()

3.3 激活函數
-
激活函數:使用了 SiLU 激活函數、Swish 激活函數兩種激活函數
3.3.1 SiLU
-
YOLOv5 的 Backbone 和 Neck 模塊和 YOLOv4 中大致一樣,都采用 CSPDarkNet 和 FPN+PAN 的結構,但是網絡中其他部分進行了調整,其中 YOLOv5 使用的激活函數是 SiLU
-
SiLU(x) = x·\sigma(x),具備無上界有下屆、平滑、非單調的特性
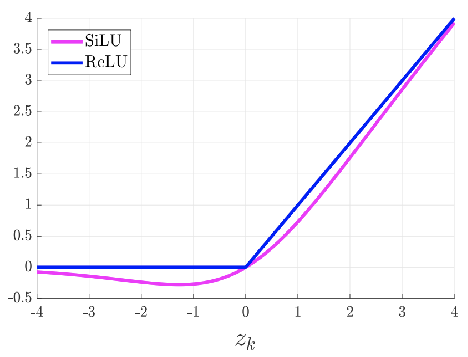
3.3.2 Swish
-
Swish 激活函數是一個近似于 SiLU 函數的非線性激活函數,具有以下形式:
-
\beta是一個可調節的參數,通常設定為 1
-
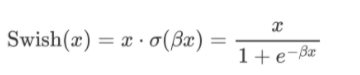
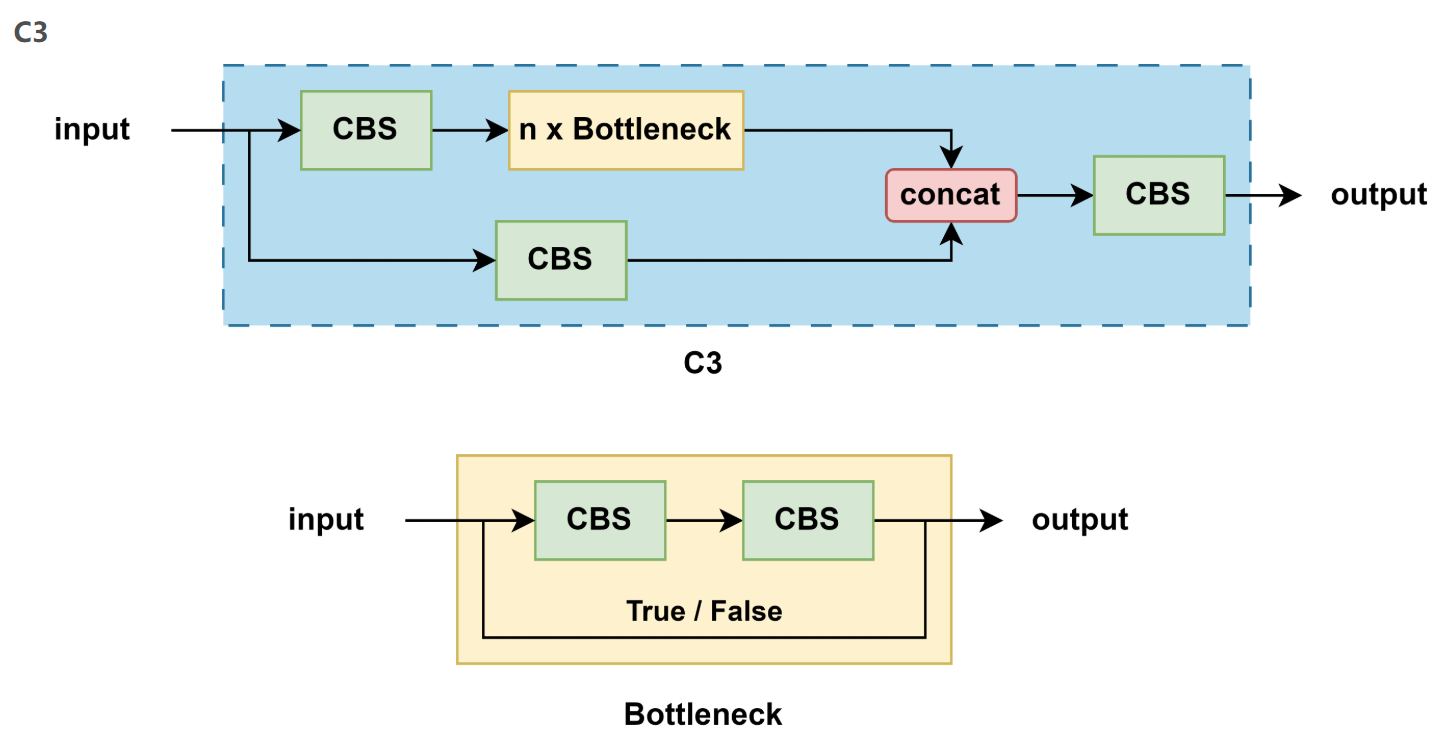
3.4 Bottleneck
-
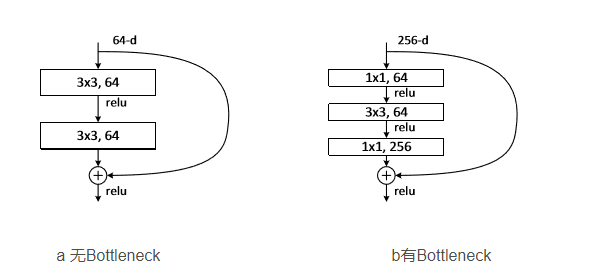
Bottleneck 是用于減少參數和計算量的結構,其設計靈感來自于ResNet,結構如下:
-
1x1卷積:用于減少特征圖的通道數
-
3x3卷積:用于提取特征,后接一個 Batch Normalization 層和 ReLU 激活函數
-
1x1卷積:用于恢復特征圖的通道數,后接一個BN層
-
跳躍連接(Shortcut):將輸入直接加到輸出上,以形成殘差連接
-
3.5 C3
-
YOLOv5 中的 C3 模塊在 CSP上進行了優化,非常相似但略有不同:
-
YOLOv5 一共使用過兩種 CSP 模塊
-
v4.0 版本之前的 BottleneckCSP,用的 LeakyReLU 作為激活函數
-
v4.0 版本之后的 C3,用的 SiLU 作為激活函數
-
3.5.1 BottleneckCSP
-
結構特點:
-
包含多個帶 shortcut 的 Bottleneck
-
輸入通道被劃分,一部分直接傳遞,一部分經過 Bottleneck 塊
-
-
激活函數:LeakyReLU
-
用途:主要用于早期 YOLOv5 的 backbone
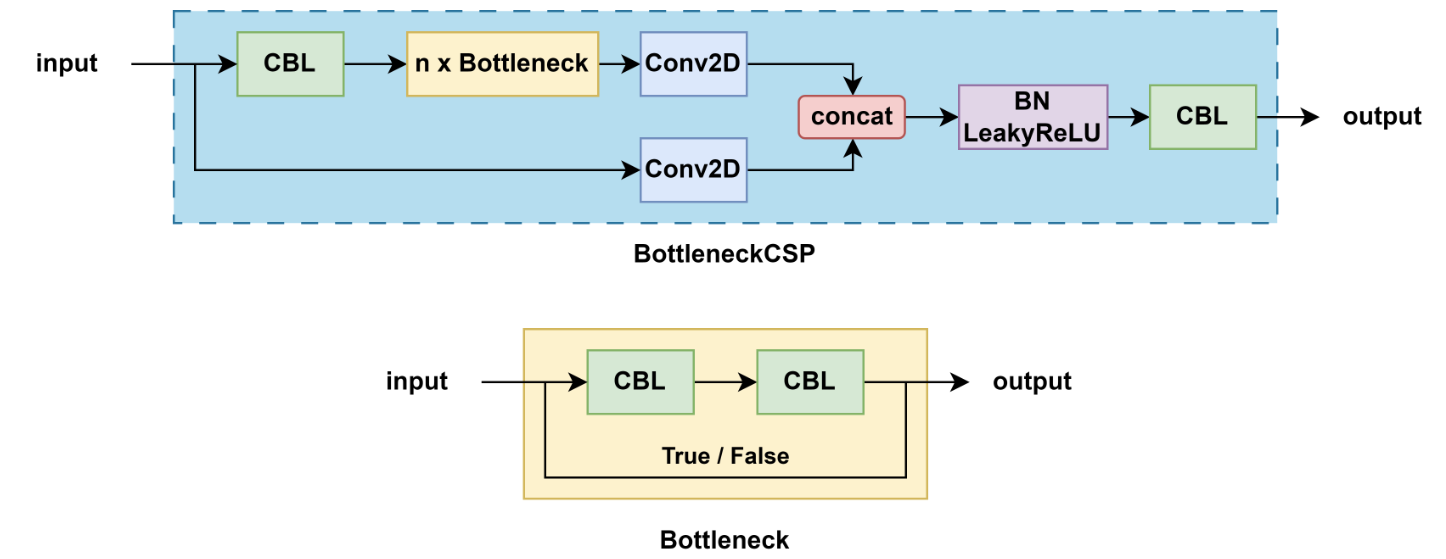
3.5.2 C3
-
結構特點:
-
不再使用 shortcut(即 Bottleneck 不帶殘差連接)
-
更加簡潔,更適合部署
-
-
激活函數:SiLU
-
用途:廣泛用于 backbone 和 neck(如 PANet)
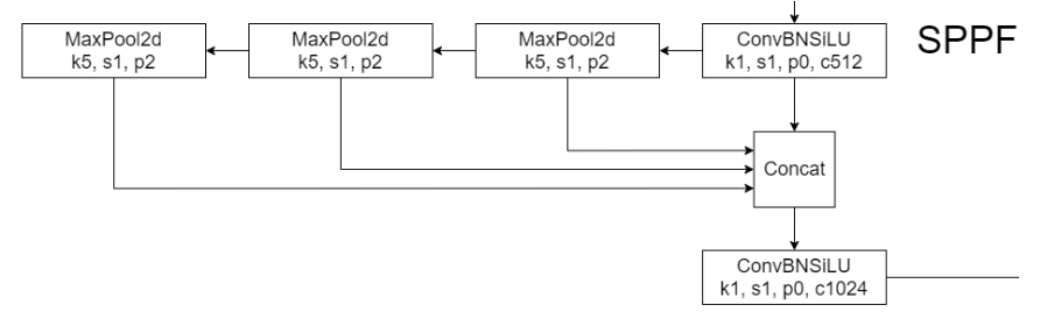
3.6 SPPF
-
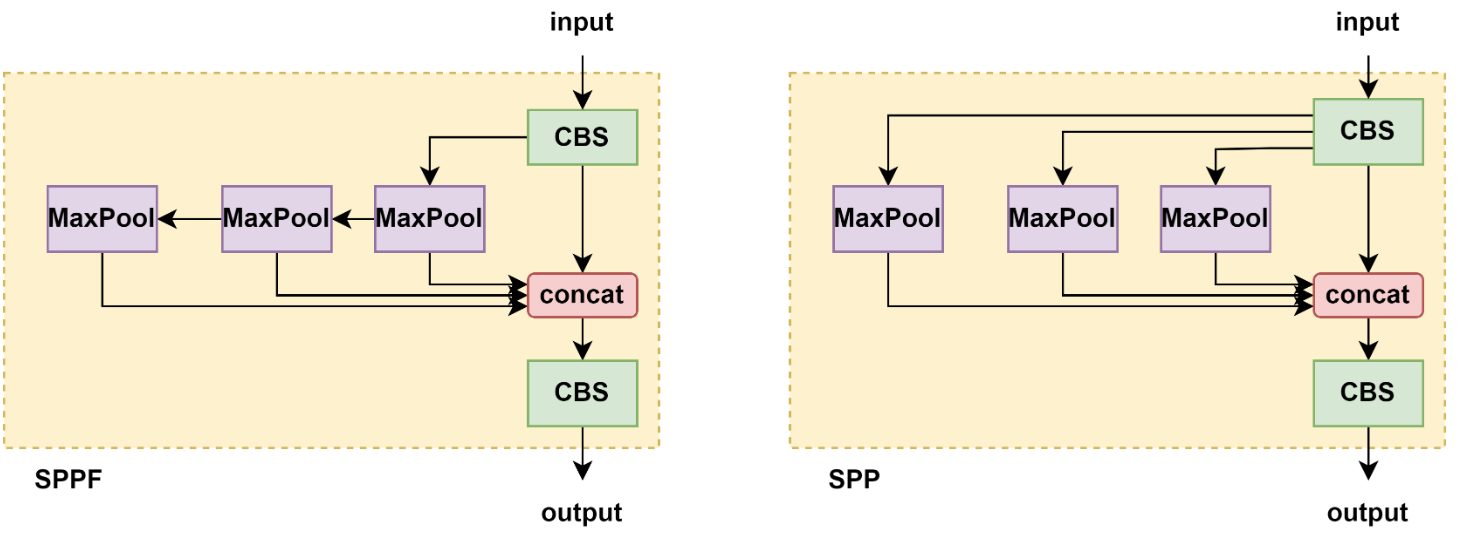
將卷積核大小變成相同,然后將并行變成了串行+并行,2個K5池化=1個K9池化,3個K5池化=1個K13池化,也就是結果相同的基礎上,速度更快,計算量更小
-
對于連續堆疊 n 層,每層使用大小為 k 的核的操作(例如卷積或池化),其等效感受野大小可以通過以下公式計算:K_{等效}=1+n(k?1)
| 層數 n | 卷積核大小 k | 等效感受野 |
|---|---|---|
| 1 | 5 | 1+1×(5?1)=5 |
| 2 | 5 | 1+2×(5?1)=9 |
| 3 | 5 | 1+3×(5?1)=13 |
3.6.1 SPP 和 SPPF 區別
4、 輸出頭
-
靈活度較高,支持多種尺寸:
-
輸入圖像尺寸:通常為 640x640(或者其它尺寸,如 416x416 等)
-
輸出特征圖:YOLOv5 使用大、中、小三個尺寸
-
輸出尺寸:
-
大目標: 通常是輸入圖像尺寸的 1/32
-
中目標: 通常是輸入圖像尺寸的 1/16
-
小目標: 通常是輸入圖像尺寸的 1/8
-
-
-
假設輸入圖像尺寸為640x640,具體的特征圖尺寸如下:
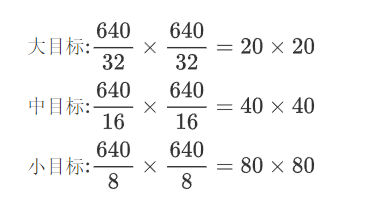
5、開源項目
ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
項目鏈接
不同v5版本的差異表
| Model | size (pixels) | mAPval 50-95 | mAPval 50 | Speed CPU b1 (ms) | Speed V100 b1 (ms) | Speed V100 b32 (ms) | params (M) | FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
| YOLOv5x6 + TTA | 1280 1536 | 55.0 55.8 | 72.7 72.7 | 3136 - | 26.2 - | 19.4 - | 140.7 - | 209.8 - |
-
YOLOv5的一些主要模型變體:
-
YOLOv5n:
-
這是最小的變體,適用于嵌入式設備或資源受限的環境
-
犧牲了一定的準確性以換取更快的速度
-
-
YOLOv5s:選擇
-
較小的模型,適合在邊緣設備上使用
-
相比于更大的模型,它提供了更好的速度,但在精度上有所降低
-
-
YOLOv5m:
-
中等大小的模型,平衡了速度和精度
-
適用于大多數常規硬件
-
-
YOLOv5l:
-
較大的模型,提供了更高的檢測精度
-
在高端硬件上可以運行良好,但速度較慢
-
-
YOLOv5x:
-
最大的模型,具有最高的精度
-
需要高性能的硬件來保證實時處理速度
-
-
-
各個模型測試速度參數:
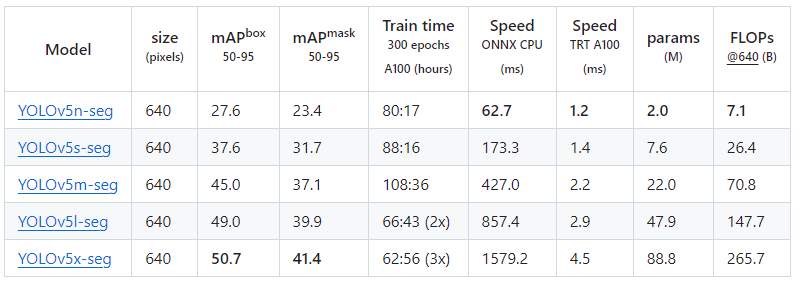
-
第四步:把下載好模型,復制一份到項目中,如下:
第五步:執行命令python detect.py --weights <weights_path> --source <source>,完成推理,結果默認保存到 runs/detect
命令參數詳細說明:
detect.py:是YOLOv5提供的用于目標檢測的腳本
--weights <weights_path>:指定模型權重文件的路徑。例如yolov5s.pt表示使用YOLOv5s模型的預訓練權重
--source <source>: 指定輸入源。可以是以下類型之一:
0: 表示使用默認攝像頭(通常是內置攝像頭)
img.jpg: 指定圖像文件作為輸入
vid.mp4: 指定視頻文件作為輸入
screen: 使用屏幕截圖作為輸入源,需要注意是否所有的YOLOv5版本都支持此選項
path/: 指定一個目錄,該目錄下的所有支持的媒體文件都將作為輸入
list.txt: 一個文本文件,其中每一行是一個輸入源(可以是圖像路徑或視頻路徑)
list.streams: 類似于list.txt,但每一行是一個流媒體鏈接
'path/*.jpg': 使用glob模式匹配文件,此處表示所有.jpg格式的圖像文件
'https://youtu.be/LNwODJXcvt4': 從YouTube URL讀取視頻流
'rtsp://example.com/media.mp4': 從RTSP、RTMP或HTTP流讀取視頻
?在這里查看detect的結果
訓練
-
執行以下命令訓練模型,結果默認保存到
runs/train
python train.py --data .\data\coco.yaml --img 640 --epochs 25 --weights .\yolov5s.pt --cfg .\models\yolov5s.yaml --batch-size 2 --device 0
-
命令參數詳細說明:
-
train.py:這是一個 Python 腳本,它負責加載數據、構建模型、設置優化器、定義損失函數,并執行訓練循環 -
--data coco.yaml:用來指定數據集配置文件的路徑,在這個例子中,coco.yaml文件包含了訓練數據集的詳細信息,如訓練集、驗證集的路徑,類別數量等,我們需要把這個coco.yaml替換成我們的數據集對應的.yaml文件路徑 -
--img 640:指定樣本尺寸 -
--epochs 25:用來指定訓練的周期數,這里的值25表示整個訓練過程將在數據集上重復 25 次 -
--weights .\yolov5s.pt:用于指定初始權重文件的路徑。值yolov5s表示在 yolov5 提供的模型基礎上繼續訓練,當路徑為空字符串''時,意味著訓練從零開始,沒有預訓練的權重 -
--cfg yolov5s.yaml:用于指定模型配置文件的路徑。配置文件定義了模型的架構細節,如卷積層的數量、尺寸等,在這個例子中,yolov5s.yaml指定了YOLOv5 小型版本模型配置文件 -
--batch-size 2:用于設置每次梯度更新時使用的樣本數量。批量大小越大,每次迭代所用的時間越長,但同時可能會得到更穩定的梯度,注意虛擬內存問題 -
--device 0:于指定訓練過程中使用的設備,通常是 GPU 或 CPU。這個參數可以幫助你控制模型訓練是在 CPU 上還是在 GPU 上進行,在這個例子中 0 表示第 0 號 GPU,如果計算機沒有 GPU,參數設置為 CPU 即可,如果想讓計算機自動選擇可用的 GPU,把值設置為 -1 即可
-
-
執行過程:
-
訓練過程,介紹如下:
-
Epoch:一個 epoch 指的是模型在整個訓練數據集上完成一次正向傳播和反向傳播的過程,用于衡量訓練的進度
-
Gpu_mem:表示當前GPU的內存使用情況,監控GPU內存使用情況,確保沒有超過顯存限制,避免出現內存溢出錯誤
-
box_loss:表示邊界框回歸損失,用于衡量預測框與真實框之間的偏差,用于優化預測框的位置,使其更加接近真實框的位置
-
obj_loss:表示對象存在性損失,用于衡量預測框是否包含對象,用于判斷預測框是否真正包含了目標對象,提高模型識別目標的能力
-
cls_loss:表示分類損失,用于衡量預測框內對象的分類準確性,用于優化模型對目標對象的分類準確性,使其能夠正確識別不同類別的對象
-
Instances:訓練批次中檢測到的目標實例數量
-
Size:表示輸入到模型中的圖像大小
-
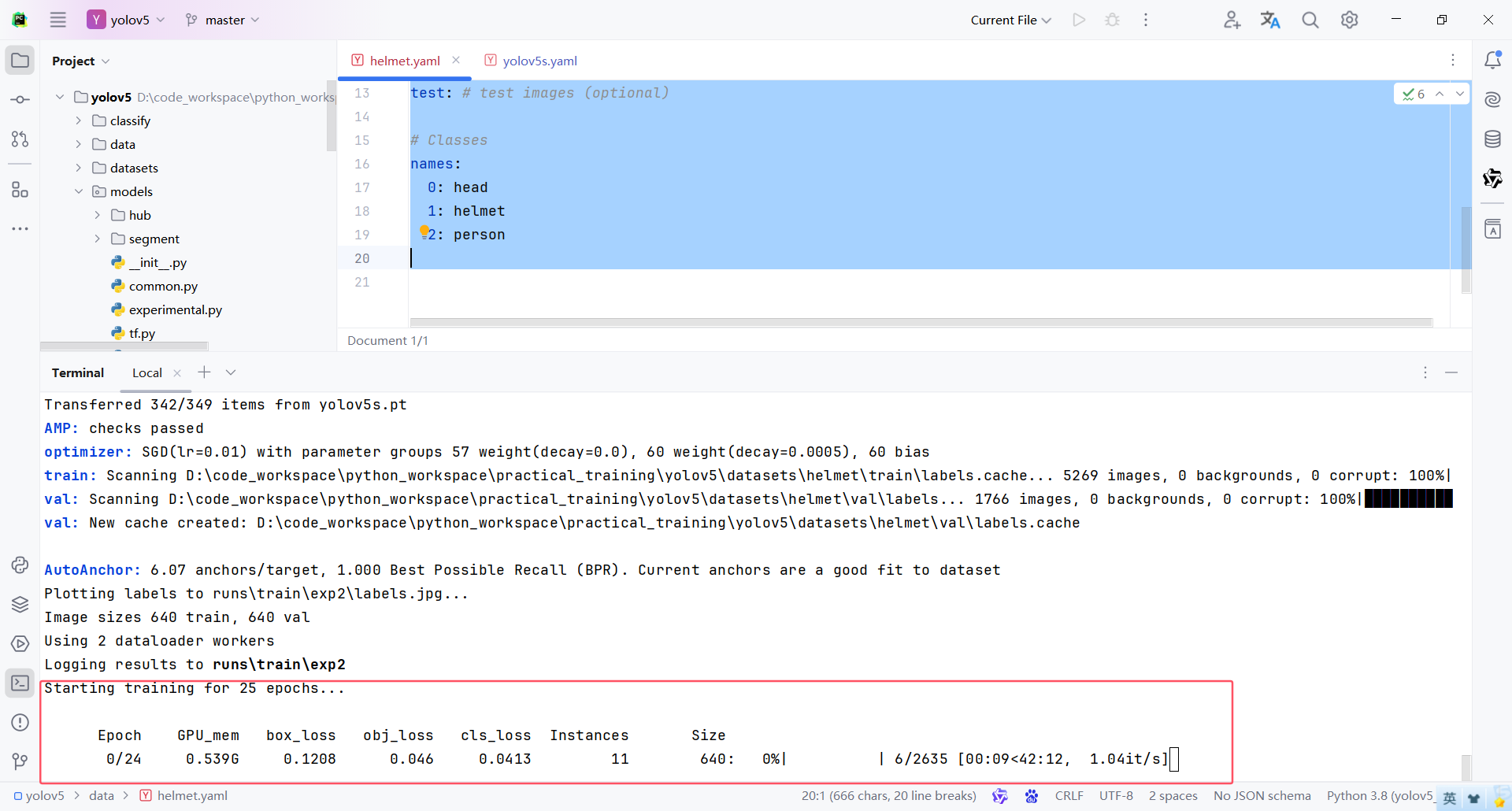
-
訓練結果,這個文件夾中包含了很多文件,重要內容如下:
-
weights 文件夾下,有兩個后綴名為
.pt的文件-
best.pt:表示在整個訓練過程中性能最佳的模型權重,用于推理 -
last.pt:表示訓練結束時的最后一個模型權重,用于設置下次訓練基于這個基礎上繼續訓練,但是需要修改很多參數
-
-
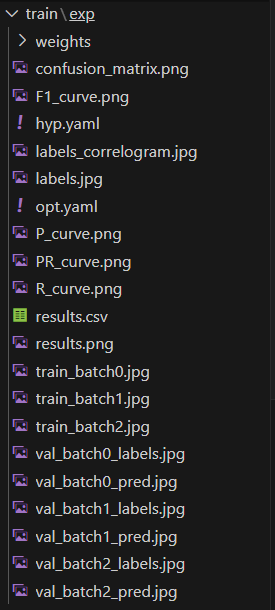
5.9 恢復訓練
-
如果訓練過程中意外停止,在訓練指令后面加上
--resume參數可以恢復訓練,并且不需要同時指定--weights參數。--resume會自動加載最近一次保存的檢查點(包括模型權重、優化器狀態等)
python train.py --weights runs/train/exp/weights/last.pt --resume
)
)



:全面解析容器化革命 | 2025 終極指南)

)
——學習筆記)


)







