一、DMETL的介紹
1.1 概述
我們先來簡單了解一下DMETL。
DMETL是什么?說的簡單一點,DMETL一款數據處理與集成平臺;從功能來說,那DMETL就是對數據同步、數據處理以及數據交換共享提供一站式支持的平臺;從它的意義來說,DMETL就是大幅度降低了用戶使用各種平臺進行大數據整合處理的技術門檻的一個平臺。
這就是DMETL,即達夢數據交換平臺(Dameng Data Exchange Platform)的簡稱。將傳統的ETL工具(Extract、Transform、Loading)與分布式大數據處理平臺相結合,更好地應對大規模數據的實時處理和分析需求,也能更高效地完成數據清洗、過濾和格式化等復雜操作。
1.2功能特點
(1)數據抽取(Extract):能夠從多種數據源中抽取數據,支持關系型數據庫(如 Oracle、MySQL)、NoSQL 數據庫(如 MongoDB)、文件格式(如 CSV、Excel)等。
(2)數據轉換(Transform):提供數據清洗、轉換功能,可以對數據進行格式轉換、去重、合并等操作,并支持靈活的轉換規則。
(3)數據加載(Load):將處理后的數據加載到目標數據源中,支持多種目標數據源。
(4)可視化設計:采用圖形化操作界面,用戶可以通過拖拽和配置的方式快速實現數據的導入和轉換。
(5)高性能與可靠性:支持多節點部署,具備負載均衡和故障轉移功能,能夠滿足大規模數據處理的需求。
(6)易于使用和擴展:降低了使用 Hadoop 和 Flink 等大數據技術的門檻,同時具備良好的可擴展性(通過對數據源適配器的擴展,可以增加系統所支持的數據源,比如JDBC數據源、文件數據源、FTP數據源、XML數據源。通過對消息適配器的擴展,可以增加系統所支持的第三方消息中間件,如JMS)。
1.3應用場景
數據同步:實現不同數據源之間的數據同步,保持數據一致性。
數據交換:用于不同部門或系統之間的數據交換,支持數據的流動和共享。
數據整合:將來自不同來源的數據進行清洗、轉換和整合,存儲到數據中心或數據倉庫中,為數據分析和共享提供支持。
數據倉庫和數據中心建設:是構建數據倉庫、數據中心等數據集成類應用的理想平臺。
這里找了個圖片來介紹一下DMETL的功能

二、系統架構及核心功能組件
DMETL 的系統架構包括以下主要組件:
調度器:負責流程分解和作業調度,協調多個執行器的功能。
執行器:用于執行作業和轉換流程,支持多節點部署,包括native、yarn和flink。
管理器:提供可視化的 web 管理、設計、監控界面,用于操作、配置和監控系統。
控制器:是調度器和執行器的守護進程,用于遠程修改參數、啟停服務、監控系統資源等。
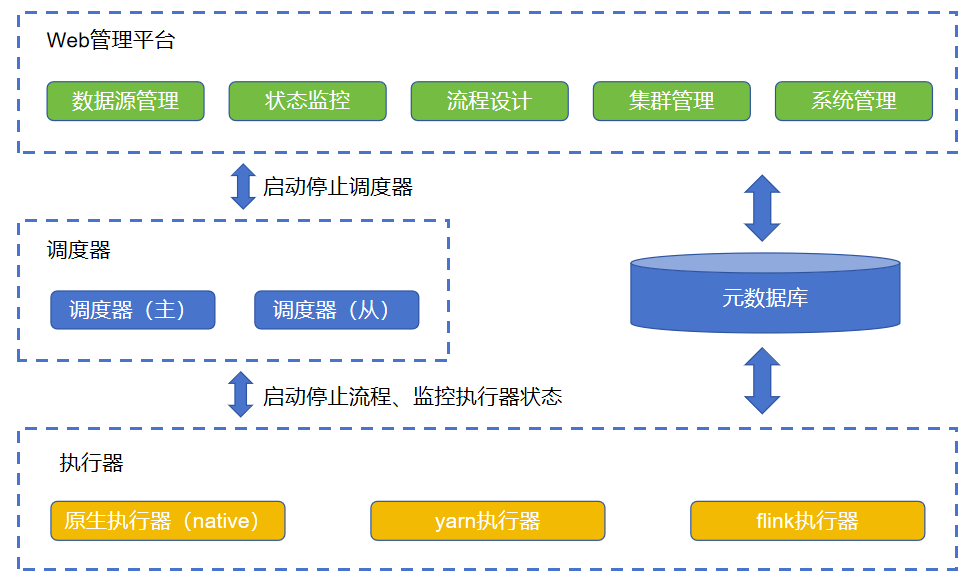
2.1Web管理平臺
Web管理平臺提供統一的管理界面,主要有以下功能模塊:
數據源管理:數據源、數據集的統一管理和維護;
狀態監控:系統各個部件(調度器、執行器、控制器)以及作業的狀態監控,運行日志查詢、統計;
集群管理:執行器、調度器的注冊、版本升級;
流程設計:數據流(轉換)和控制流(作業)的設計調試,流程調度配置;
系統管理:元數據備份、用戶權限、系統參數、系統日志;
2.2共享元數據庫
存儲DMETL的元數據,包括作業定義、數據源信息、調度配置等。它支持多種數據庫作為外置元數據庫,如DM7、MySQL6、Oracle12c、SQLServer2012,內置元數據庫僅支持Derby。
2.3調度器
負責流程分解和作業調度,協調多個執行器的工作,實現負載均衡。調度器不執行流程,只負責作業步驟的分解和分發,以及流程運行日志元數據的寫入,調度器暫不支持主備(HA)模式。
2.4執行器
執行器接收調度器的請求,用于執行作業和轉換流程。支持多節點部署,可以根據需求擴展。包括原生執行器、yarn執行器和flink執行器。原生執行器適用于常規作業,yarn執行器和flink執行器分別支持大數據批處理和流處理。關于這三種執行器,我找了一篇對這三者介紹的比較詳細的博客內容如下:
(1)native本地執行器:
類似于DMETL4的執行引擎,不依賴于yarn以及其它的分布式計算框架,獨立運行。一個系統中本地執行器可以部署多個,多個執行器之間是對等的,除非用戶在配置流程時特別指定,否則作業步驟可以運行在任何一個執行器上。一個系統中理論上可以部署任意多個本地執行器,但是實際能夠支持的數量取決調度器以及元數據庫的支撐能力。
(2)yarn執行器:
yarn執行器僅執行專門的大數據處理流程,不用于執行常規作業步驟(如文件同步,執行sql,設置變量等作業步驟),yarn執行器會把調度器分發過來的轉換流程,通過數據源的切分,得到多個切分后的流程,通過Hadoop MapReduce機制提交到Hadoop集群進行流程的分布式并行執行;同時通過Hadoop YARN機制來管理集群節點的負載問題。
(3)flink執行器:
利用flink框架特性,將ETL流程分解、組合成可以在flink服務器上運行的任務,并將其提交到flink服務器上運行。在每個JobManager和TaskManager中都啟動并維護一個native執行器實例。TaskSlot通過構建微型ETL流程并提交到native執行器實例的方式處理數據;不同TaskSlot之間則利用flink的數據交互系統來傳遞數據。根據部分組件的特性,可支持數據的分片并發讀取、持續讀取并處理、exactly-once的容錯機制等。
2.5控制器
控制器是調度器和執行器的守護進程(在上面的架構圖中沒有畫出),與調度器和執行器部署在同一服務器上,其主要功能是提供遠程管理調度器、執行器的服務。web管理平臺通過控制器可以實現遠程啟停調度器、執行器,遠程對執行器和調度器進行版本升級。
三、安裝部署
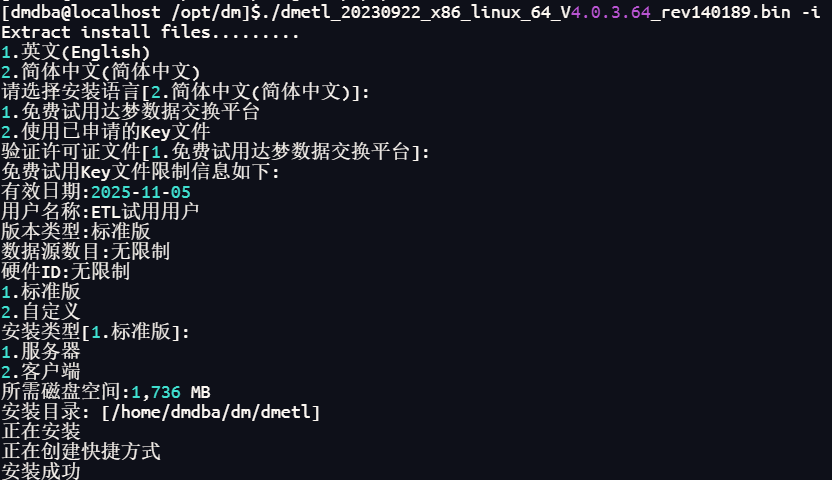
我這里安裝的是DMETL4.0版本(截至博客發布日期,市面上使用的DMETL產品大多數是4.0,雖然已經推出5.0但幾乎沒人用,對5.0感興趣的直接去官方文檔搜一下,那里的教程是5.0的)
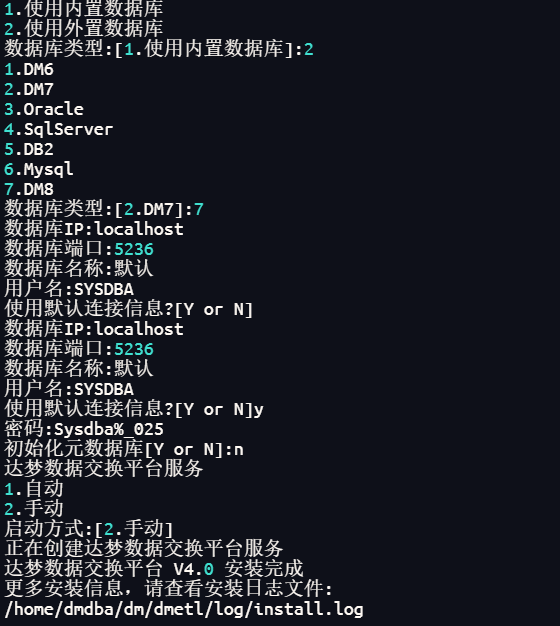
3.1執行以下語句開始安裝,并按提示進行操作
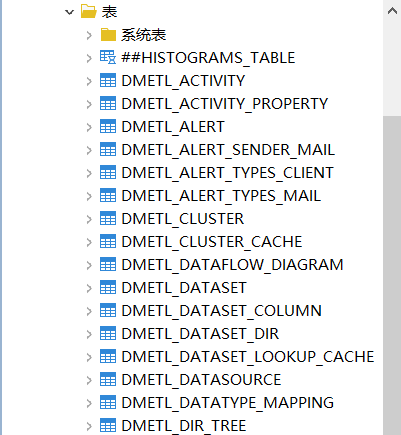
DMETL連接數據庫后會自動創建相關資源表
3.2啟動服務器
(方法1)執行 server 目錄下的 dmetl_start.sh 腳本文件即可,當出現“Metadata engine started”日志信息時說明達夢數據交換平臺服務器啟動完畢
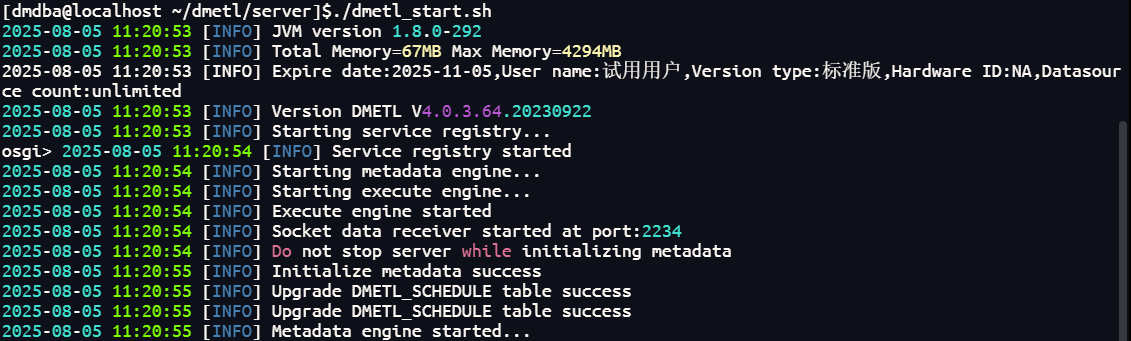
(方法2)在 server 目錄下執行對應的腳本文件dmetl_service_start.sh來管理達夢數據交換平臺服務

3.3啟動客戶端
在 client 目錄下,執行./studio.sh啟動客戶端,客戶端啟動后,彈出登錄界面,默認用戶名和密碼都是 admin,如果是在遠程工具上執行困難會報錯,建議在虛擬機上直接執行。
四、嘗試使用
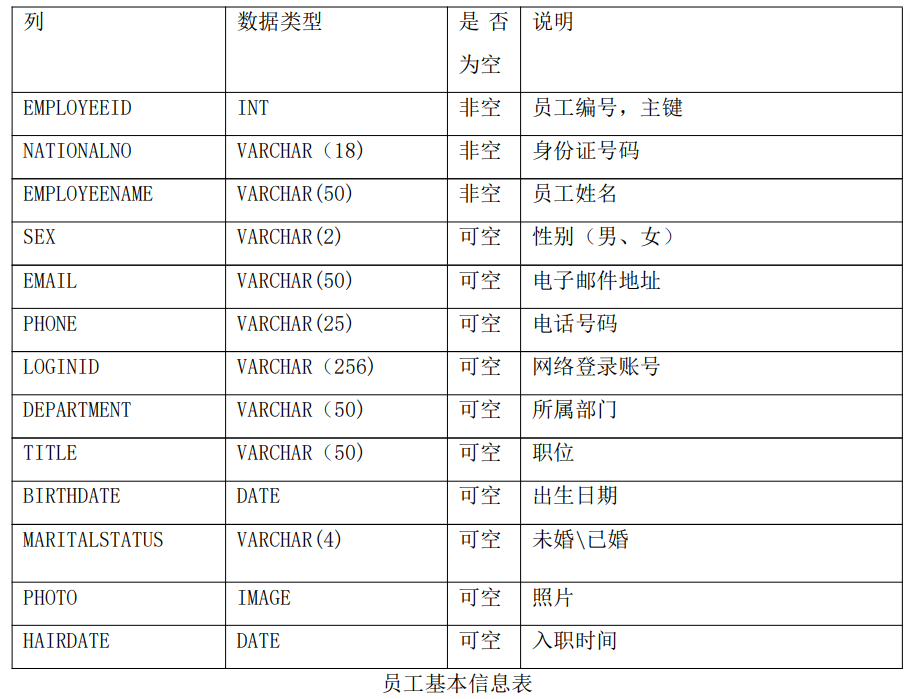
DMETL V4.0 的使用通常可以分為五個主要步驟:創建數據源、創建工程、設計轉換、 設計作業和查看運行日志五個步驟。以一個例子說明一下轉換過程,該例子功能是將源庫中的 EMPLOYEE、EMPLOYEE_DEPARTMENT、DEPARTMENT 以及 PERSON 三張有關員工的表整合成一張完整的員工信息表(EMPLOYEEINFO)。作業的功能是控制轉換以及其它任務運行的時間和順序,這里就不演示了。
4.1創建數據源DM8
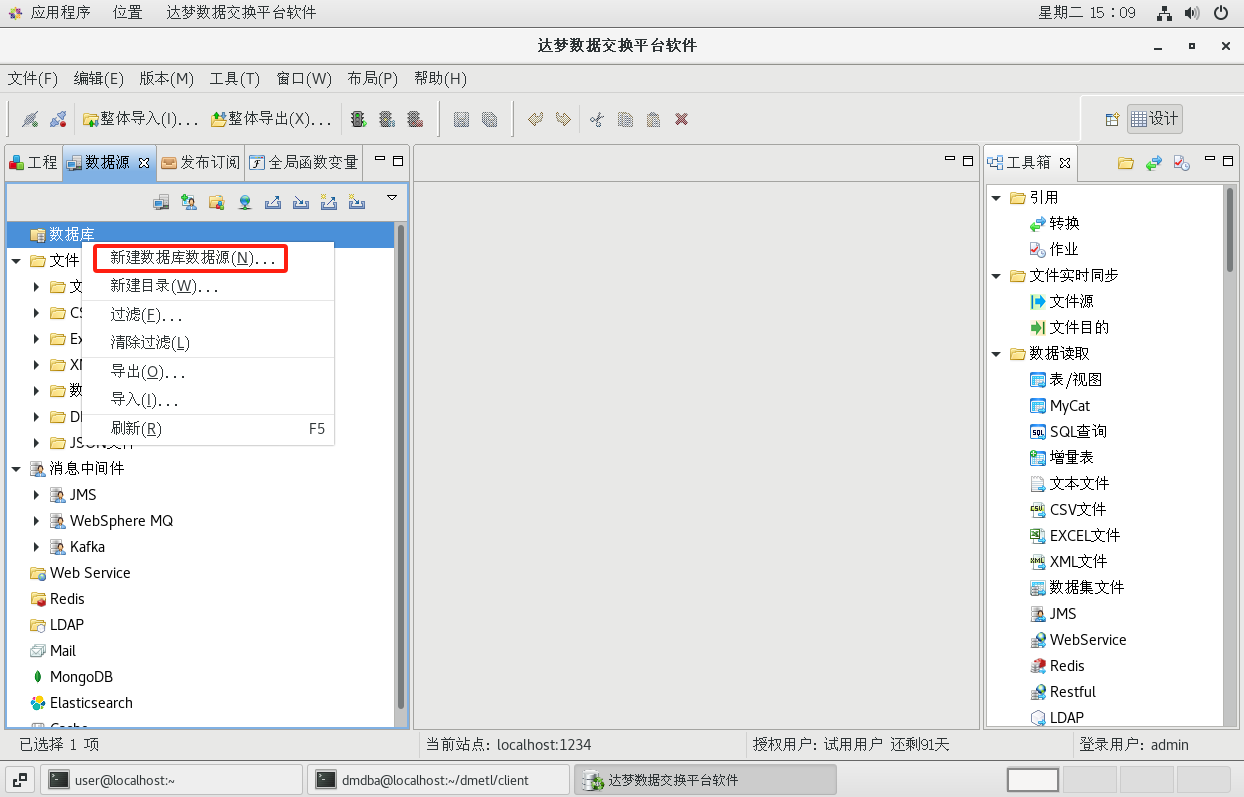
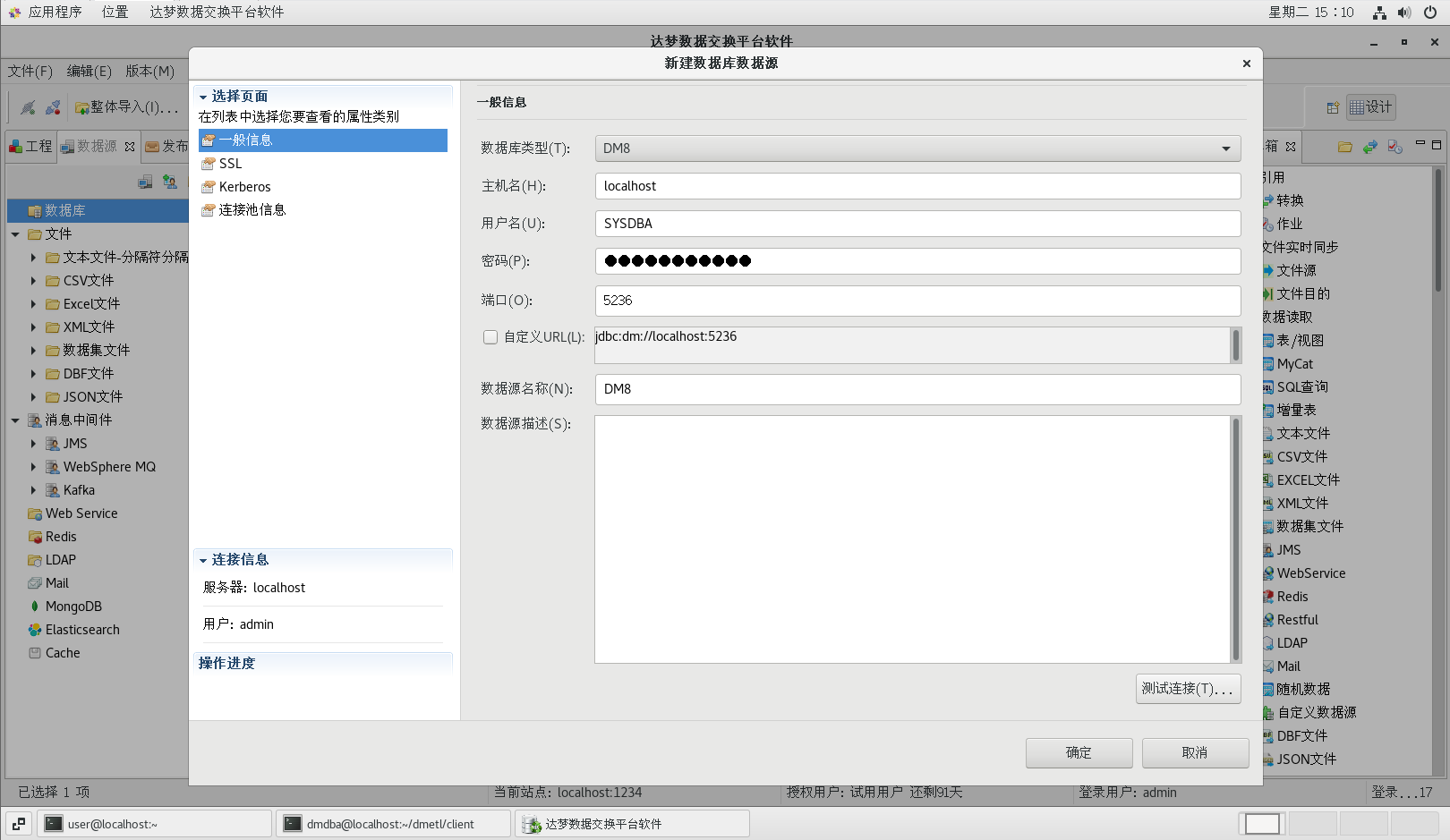
(1)切換到【數據源】選項卡,在【數據庫】點擊右鍵,選擇【新建數據庫數據源】菜單項,打開新建數據庫數據源對話框
(2)選擇源庫類型,并填入相關信息
(3)右擊數據源,選擇添加表
將 EMPLOYEE、 EMPLOYEE_DEPARTMENT、DEPARTMENT、以及 PERSON 表添加到系統中

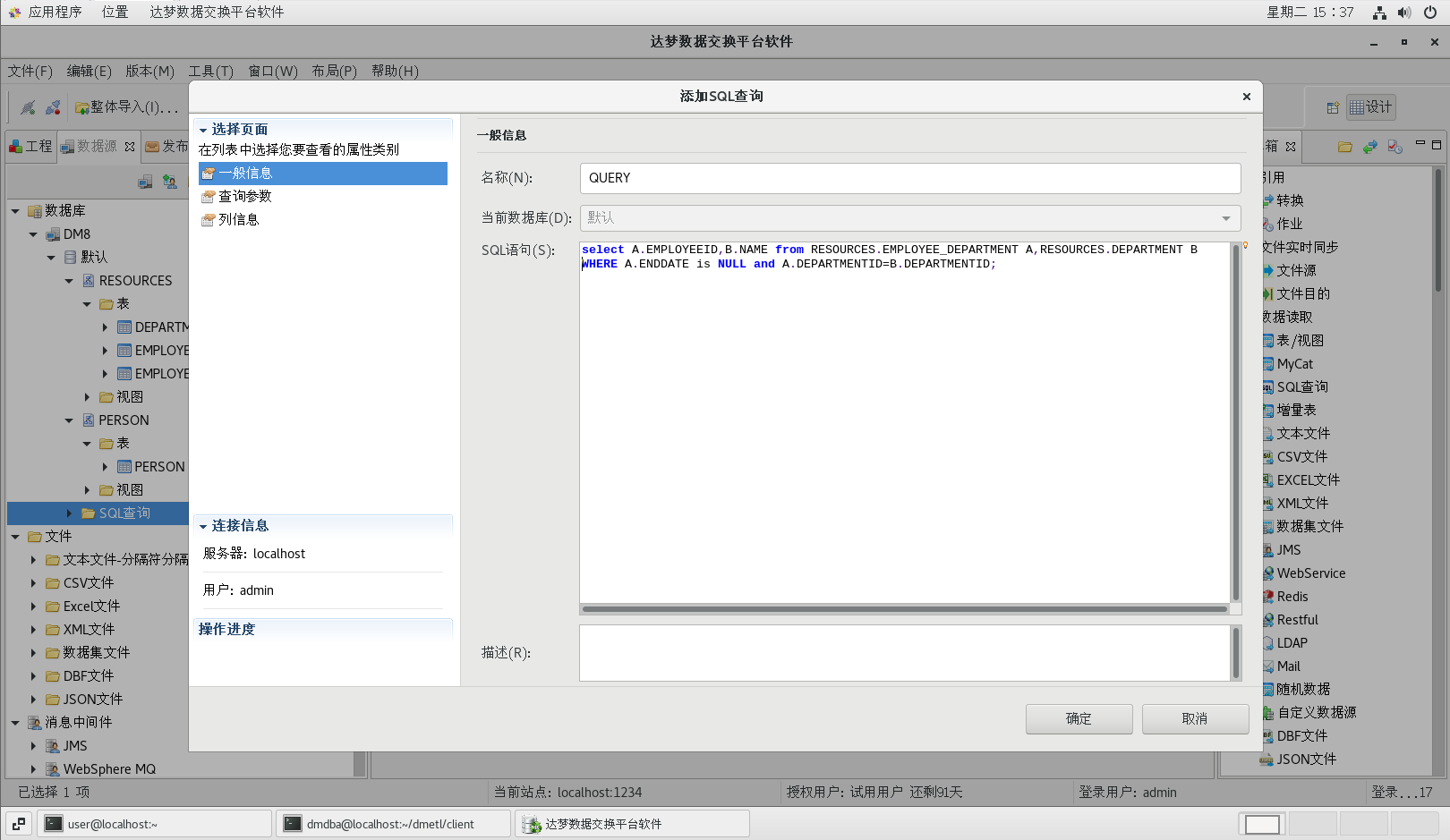
(4)添加 SQL 查詢
4.2創建數據源SAMPLE
同上一步一樣新建數據源,添加表EMPLOYEEINFO

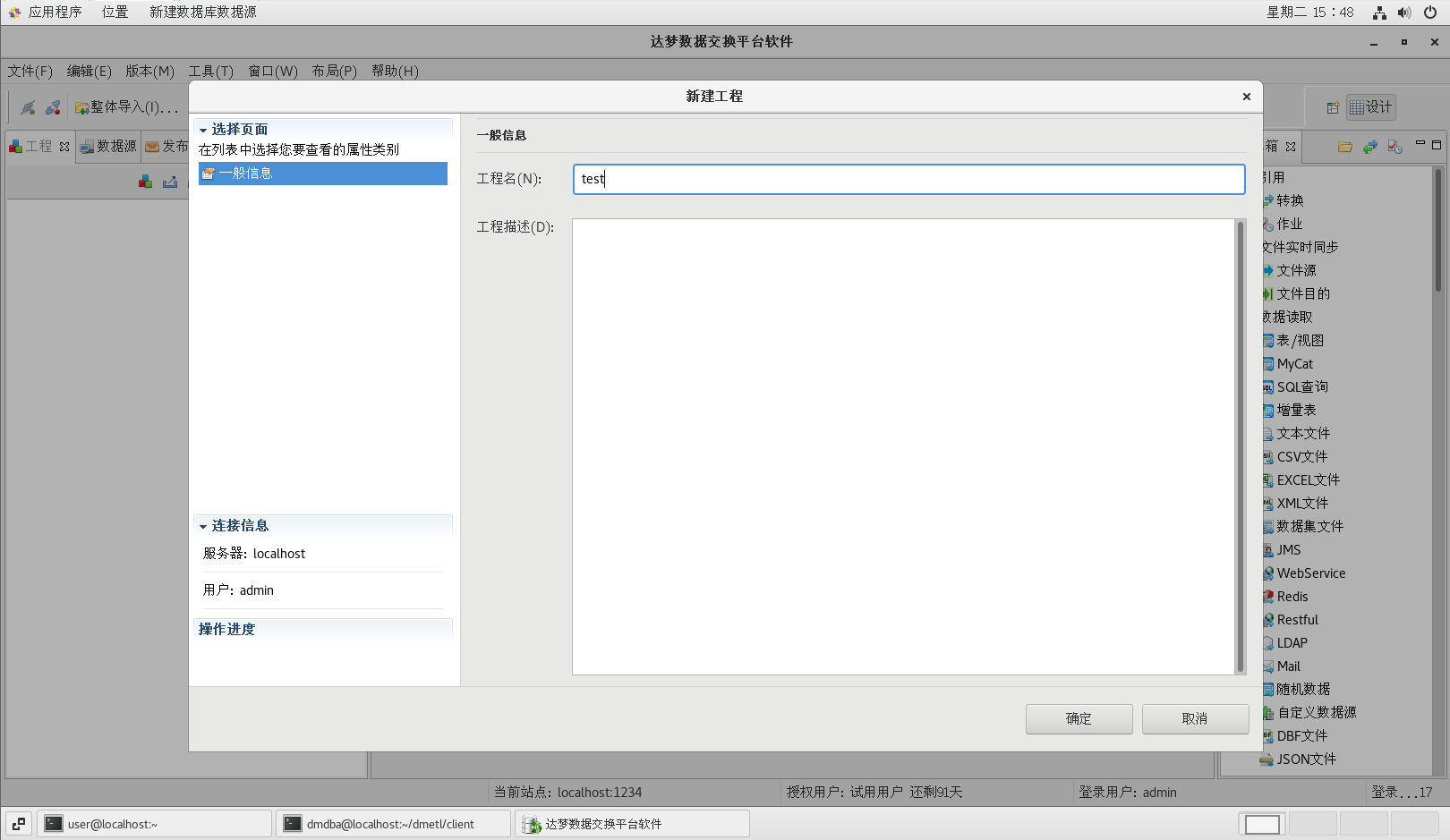
4.3創建工程
4.4設計轉換
(1)新建轉換
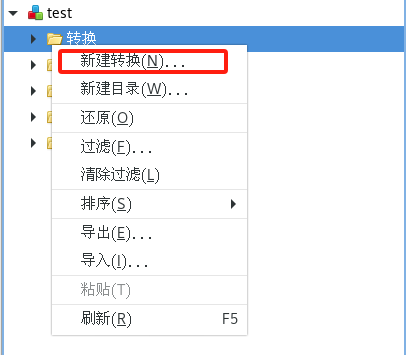
(2)添加源表
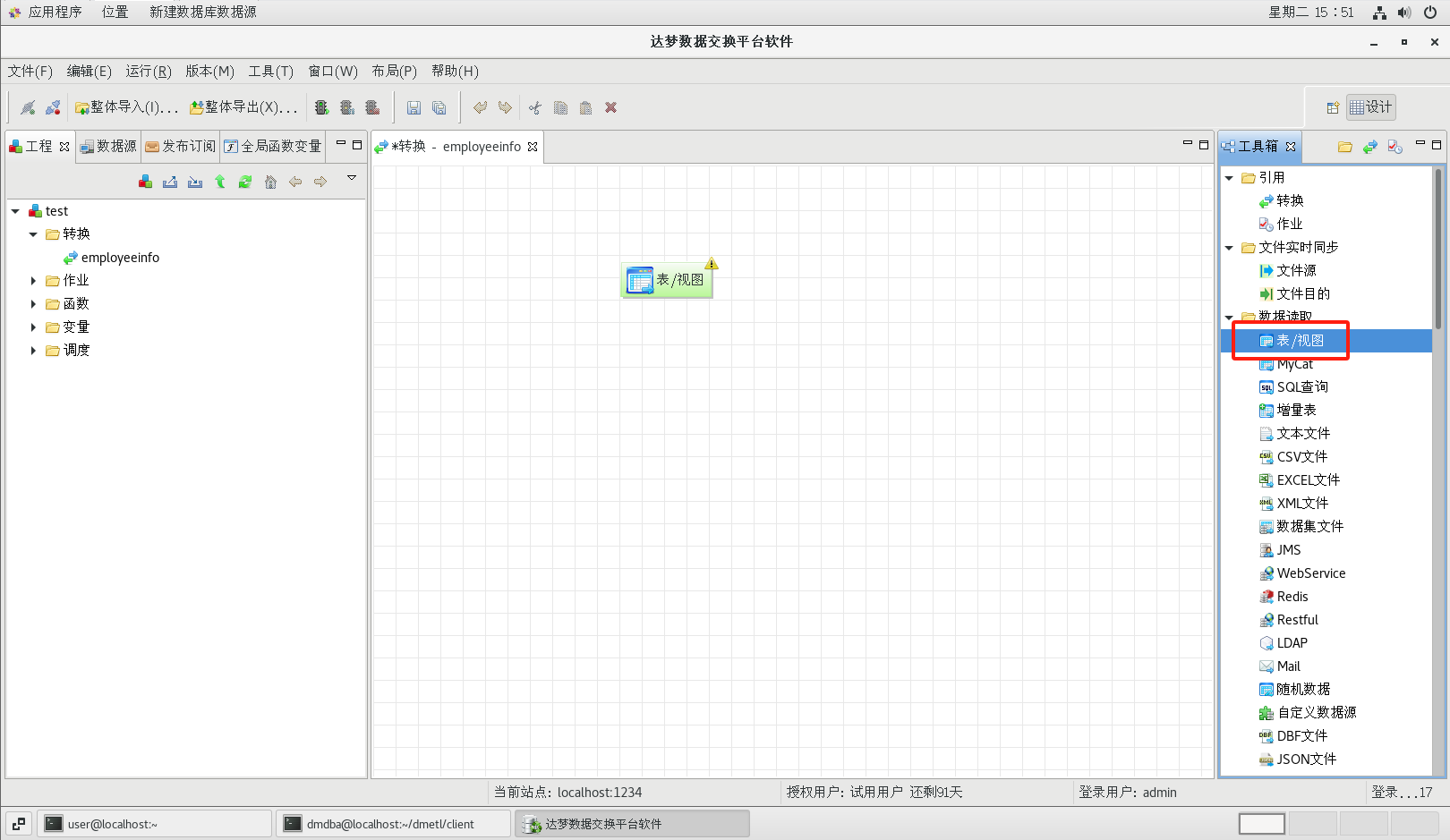
轉換創建成功后系統會自動打開轉換設計器。從工具箱的【數據讀取】標題下面把【表/視圖】組件拖到流程設計器中,然后雙擊圖標,可以打開表數據源的配置對話框
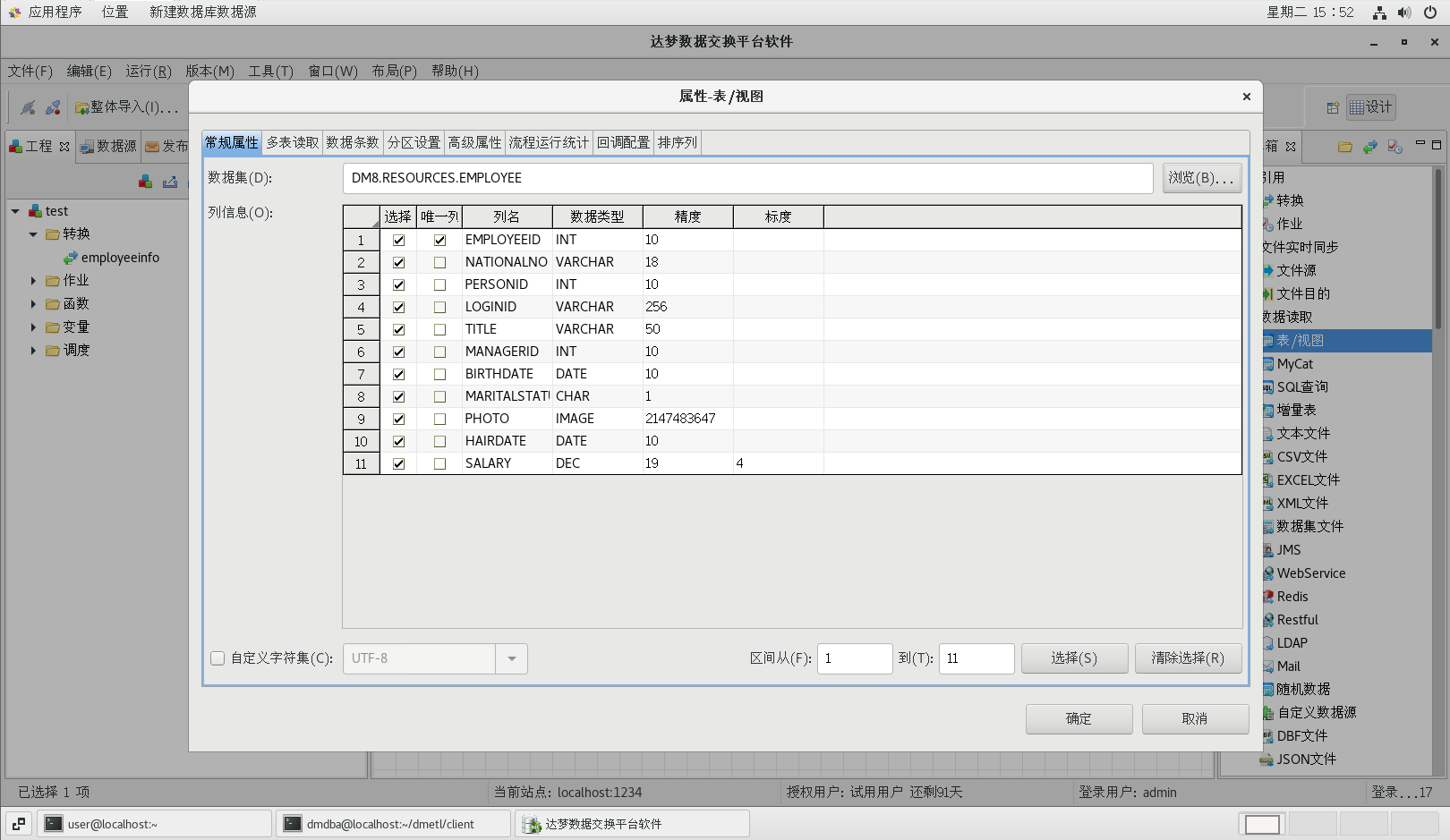
按照下圖配置好各個屬性
(3)增加所屬部門字段
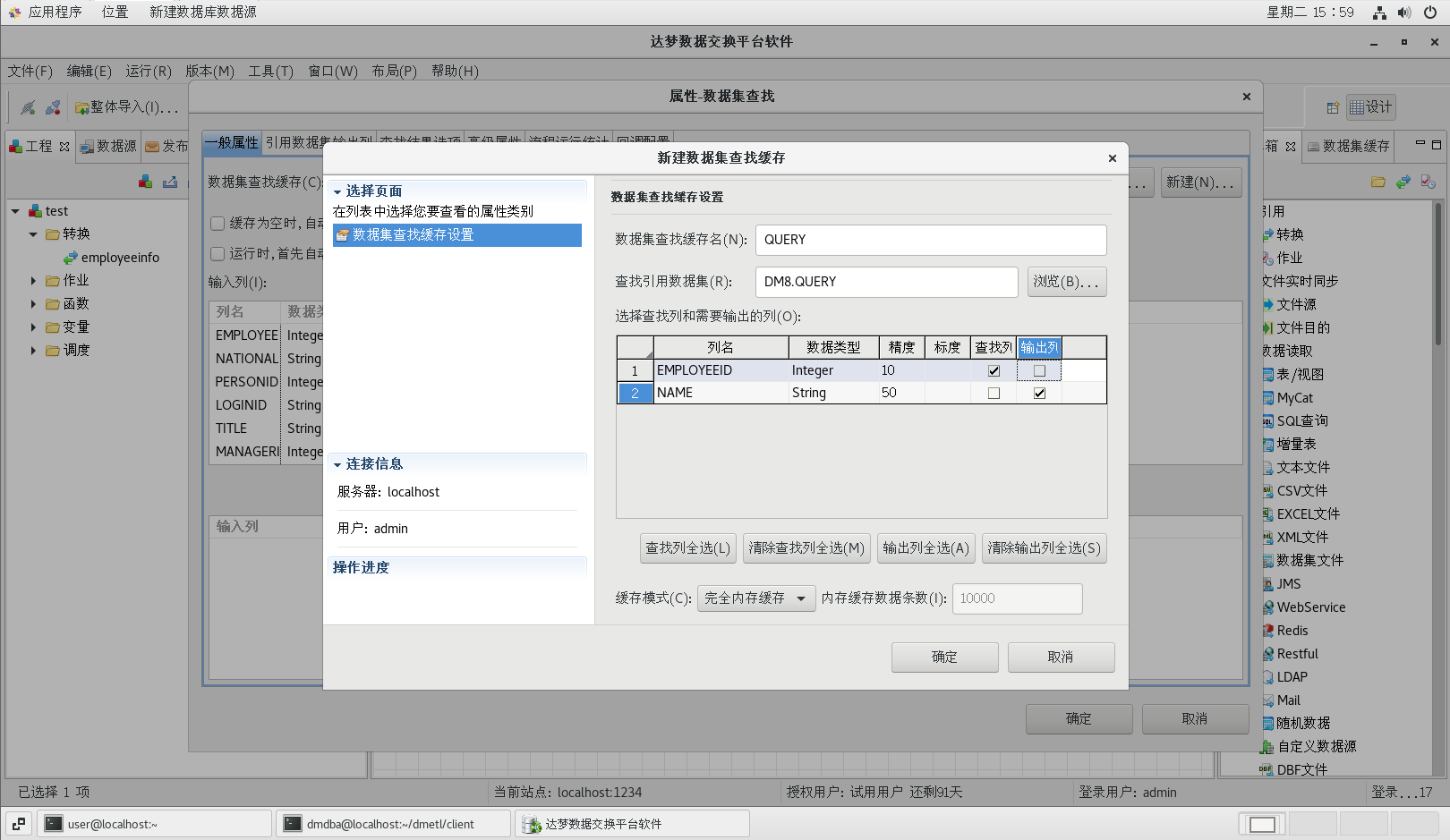
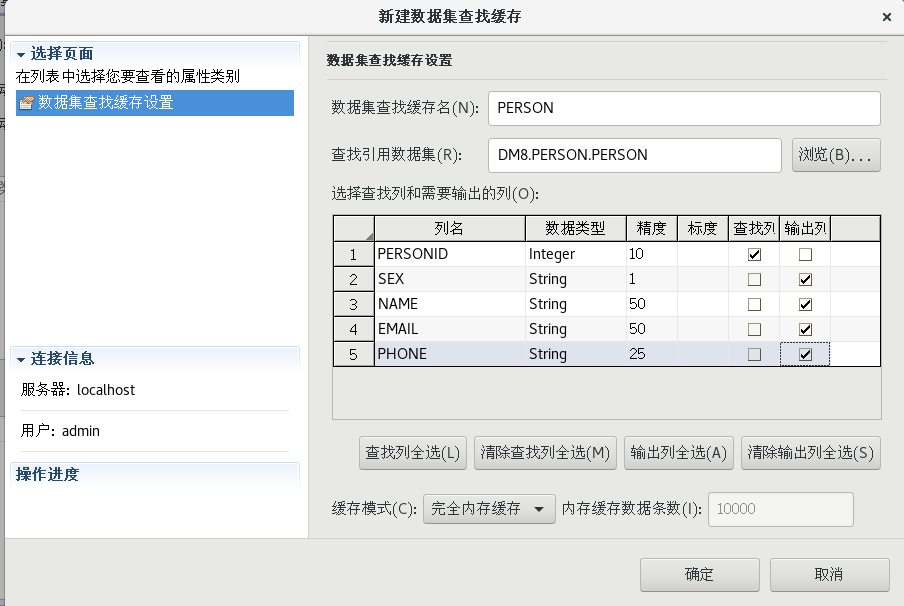
新建數據集緩存,【窗口】菜單中【數據集緩存】,新建數據集緩存;

從工具箱的【數據轉換】標題下面把【數據集查找】組件拖到流程設計器中;
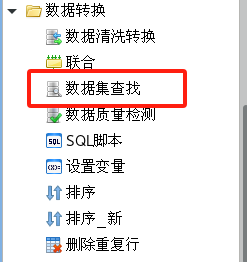
用連接線將流程設計器中的表數據源節點和數據集查找節點連接起來;
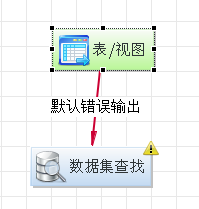
(用綠色的線,這里不對)
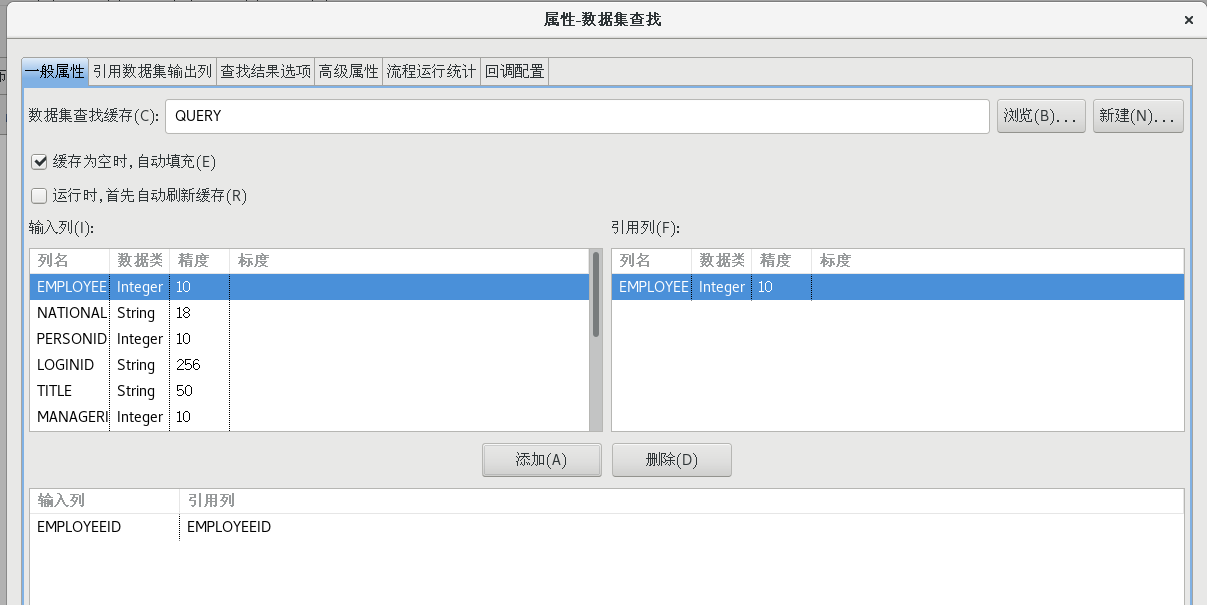
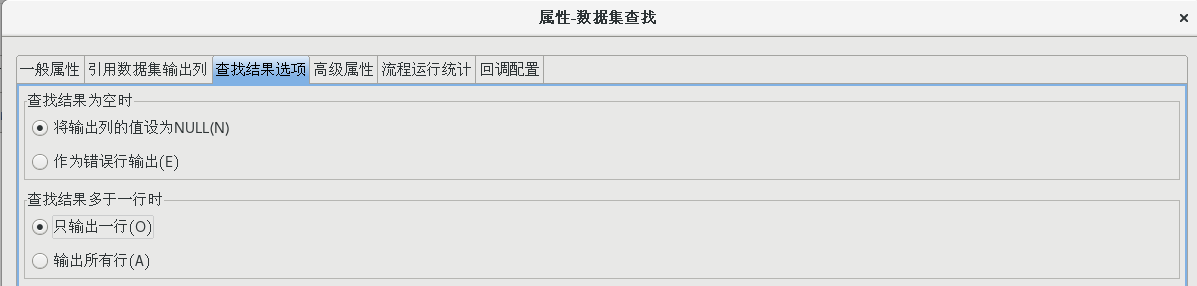
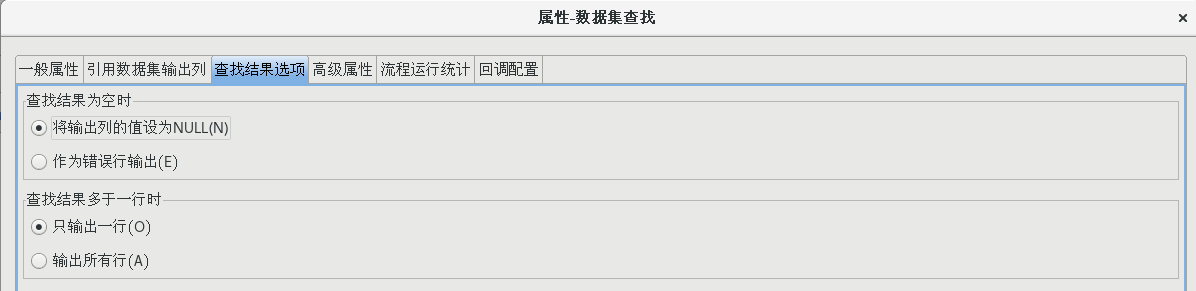
雙擊【數據集查找】節點,打開數據集查找屬性配置對話框,并按照下圖所示配置好各個屬性值

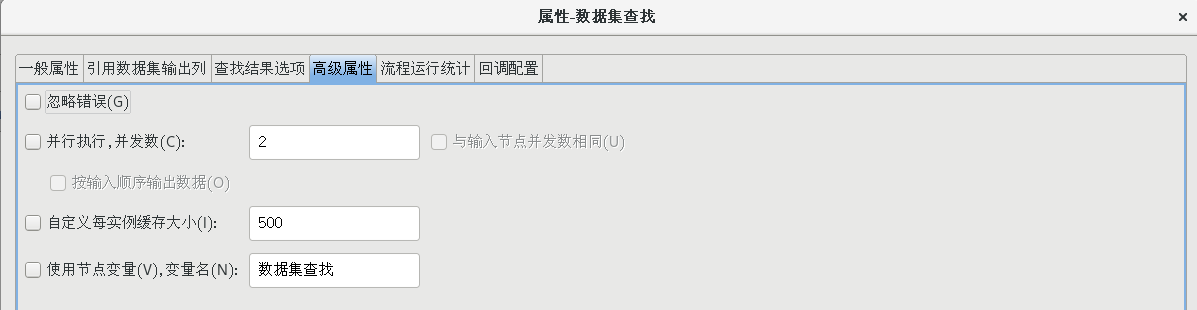
(4)增加姓名、性別、email 地址、電話號碼字段
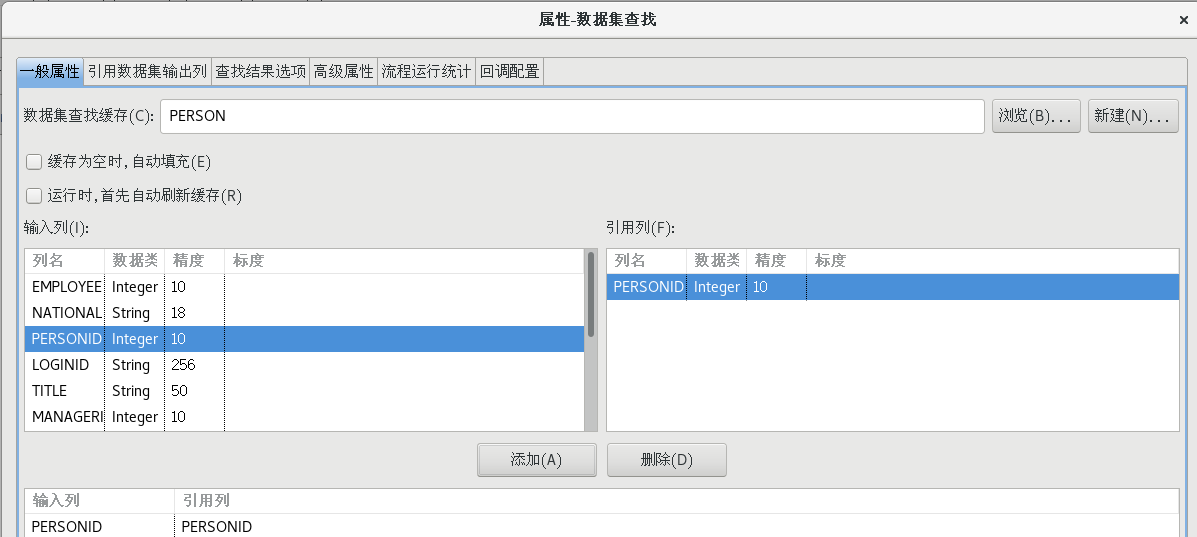
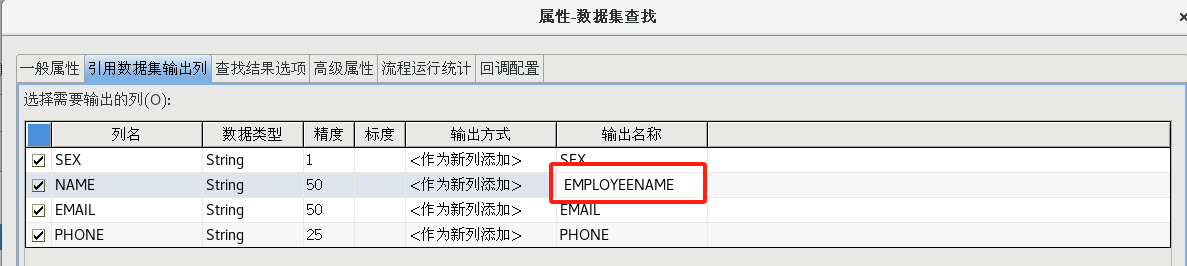
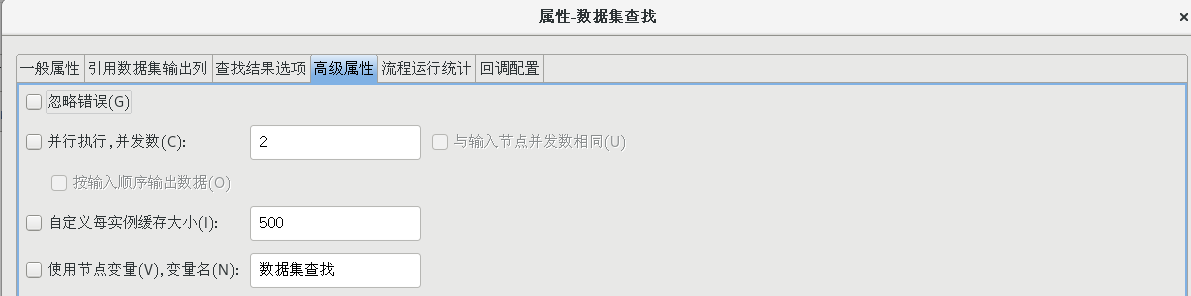
按照上一步的方法再次新建一個數據集緩存,拖一個【數據集查找】組件到流程設計器中,并建立好連接,并按照下圖設置好各個屬性
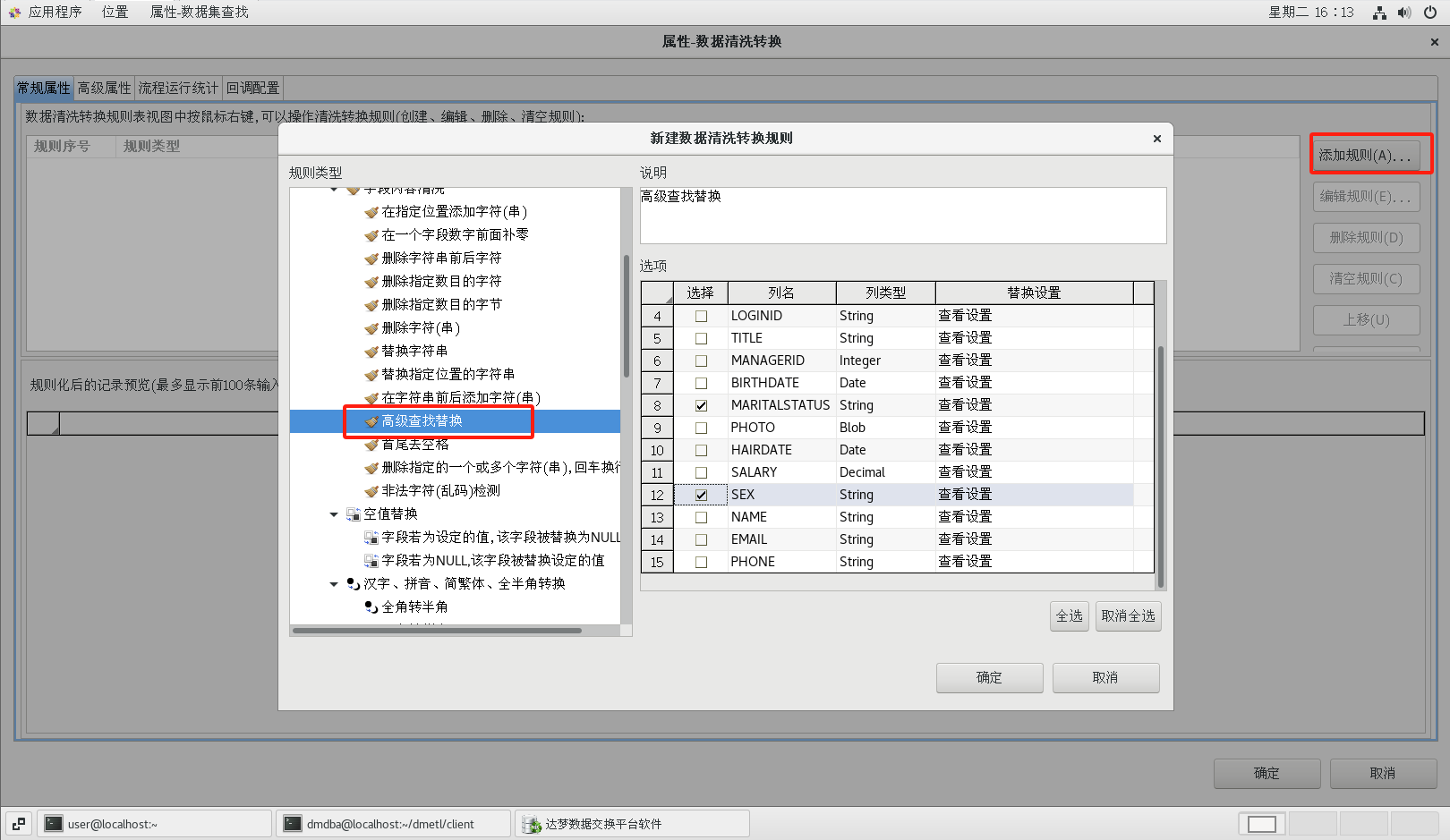
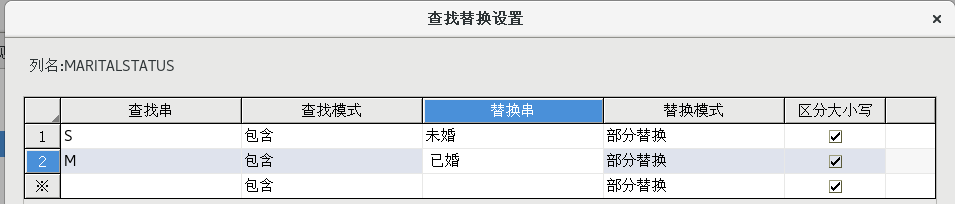
(5)字段值替換
拖動一個【數據清洗轉換】組件到流程設計器中,并建立好連接,并按照下圖所示配置好屬性

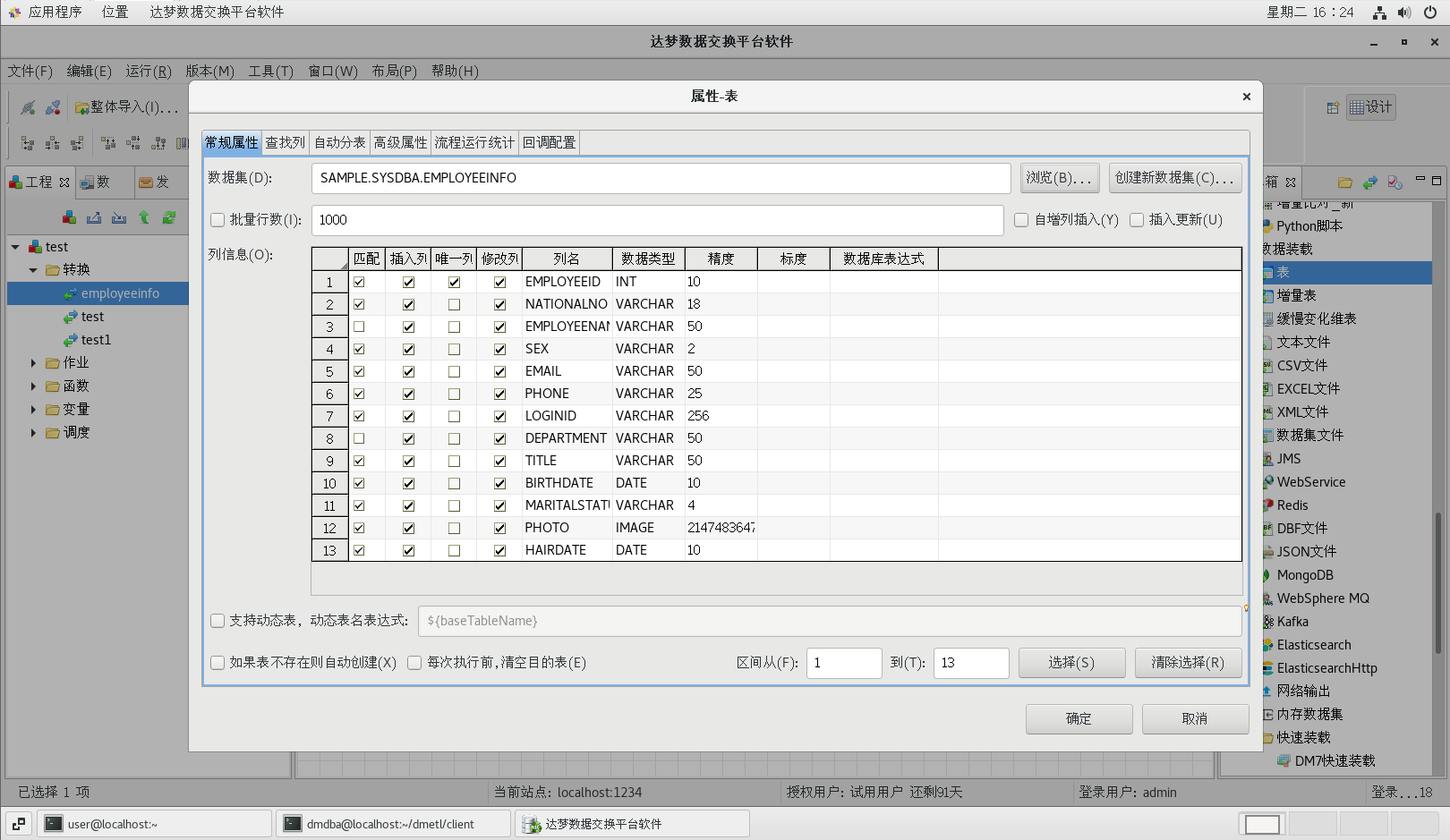
(6)添加目的表
從工具箱中的【數據裝載】標題下拖一個【表】組件到流程設計器中,建立好連接并按照下圖配置好各個屬性值
(7)修改節點名稱
在流程設計器中選中節點,然后按 F2 或者使用鼠標單擊節點右鍵,選擇重命名菜單可以編輯節點名稱
(8)添加注釋
將【工具箱】中【輔助工具】中【備注】組件拖到流程設計器中,可以向流程設計器中添加注釋節點
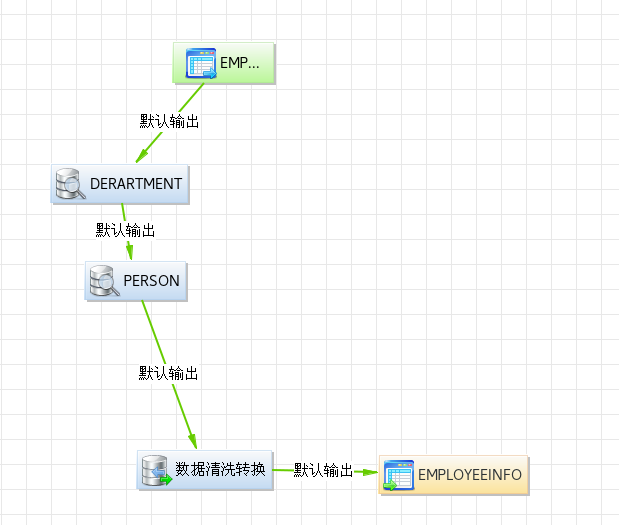
(9)執行流程
經過上述步驟后,最終設計好的流程如下圖所示
保存后點擊綠色執行鍵執行
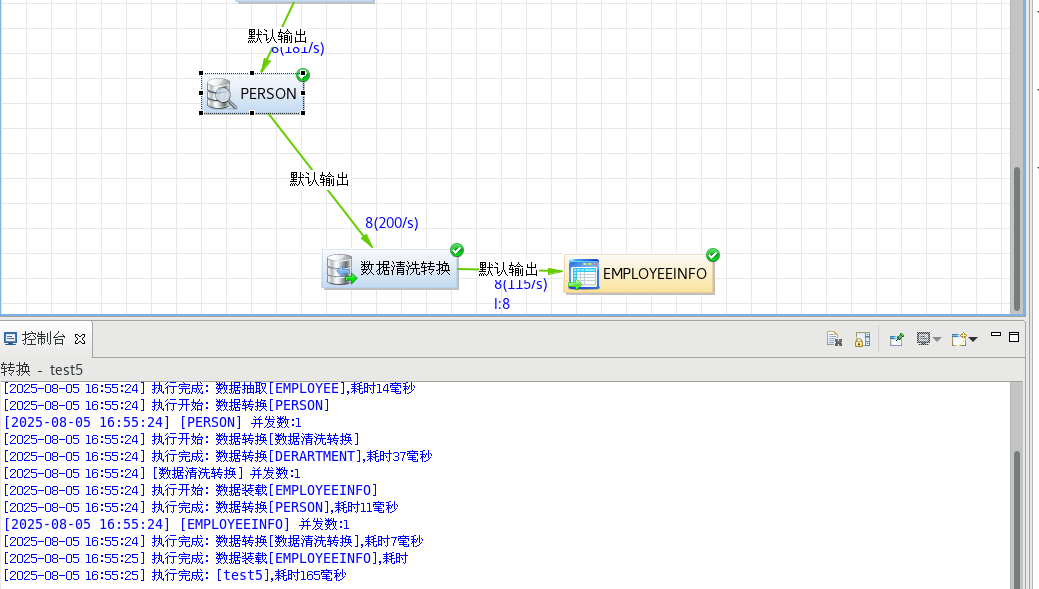
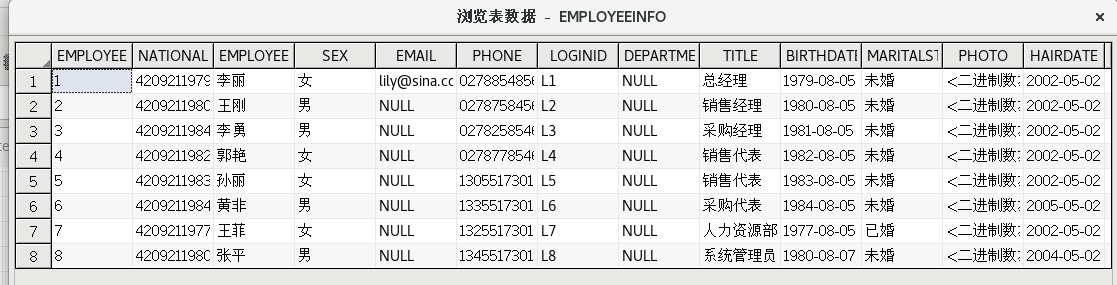
在表目的組件上點擊右鍵選擇【瀏覽數據】菜單項,可以查看目的表中的數據

:全面解析容器化革命 | 2025 終極指南)

)
——學習筆記)


)










與LCS(最長公共子序列))
:5.抽象類和接口)