KORGym:評估大語言模型推理能力的動態游戲平臺
現有評估基準多受領域限制或 pretraining 數據影響,難以精準測LLMs內在推理能力。KORGym平臺應運而生,含50余款游戲,多維度評估,本文將深入解析其設計、框架、實驗及發現。
📄 論文標題:KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
🌐 來源:arXiv:2505.14552v2 [cs.CL] + 鏈接:https://arxiv.org/abs/2505.14552
近年來,大型語言模型(LLMs)在推理任務上取得顯著進展,但現有評估基準存在諸多局限。為此,研究者提出了KORGym這一動態評估平臺,旨在更全面、精準地評估LLMs的內在推理能力。
研究背景與動機
當前,推理模型在文本理解、邏輯推理等任務中表現出色,但多數評估基準具有領域特異性,如AIME、PHYBench,無法捕捉通用推理能力。即便一些旨在評估更廣泛推理能力的基準,如SuperGPQA、HLE,也受pretraining數據影響較大,難以衡量模型的內在推理技能。
而游戲因其場景多樣,在pretraining語料中罕見,成為評估內在推理能力的理想測試床。但現有基于游戲的評估方法存在不足,如LogicGame僅采用單輪場景,無法評估LLMs的長期規劃能力;TextArena和SPINBench雖支持多輪場景,但引入的對手動態會產生額外變異性,干擾純推理評估等。
基于這些問題,研究者提出了KORGym。
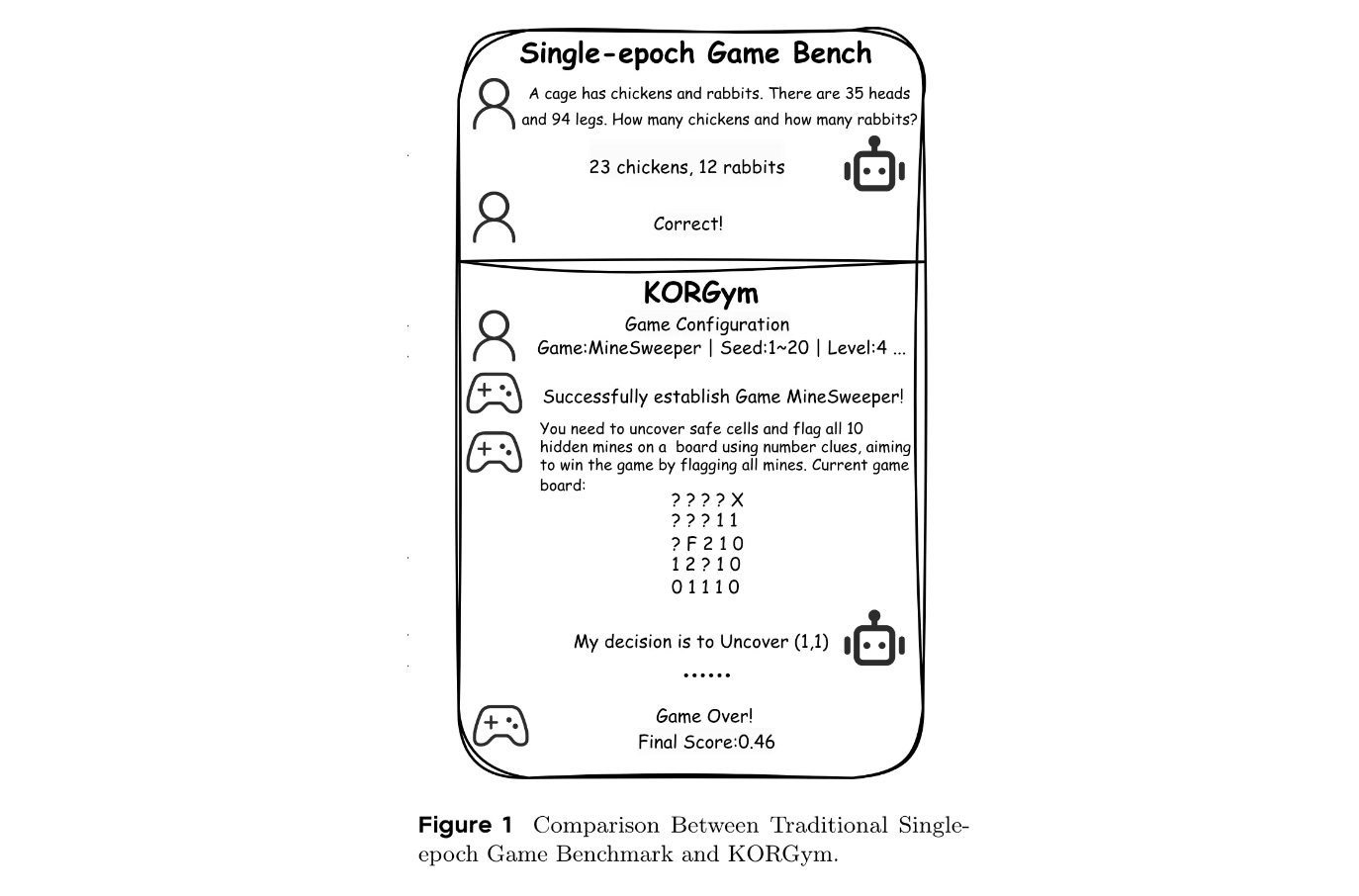
KORGym平臺設計
KORGym受KOR-Bench的知識正交推理框架啟發,基于Gymnasium構建,包含50余款游戲,涵蓋六個推理維度:數學和邏輯推理、控制交互推理、 puzzle推理、空間和幾何推理、戰略推理以及多模態推理。
平臺由四個模塊化組件構成:推理模塊、游戲交互模塊、評估模塊和通信模塊,支持多輪評估、可配置難度級別和穩定的強化學習支持。
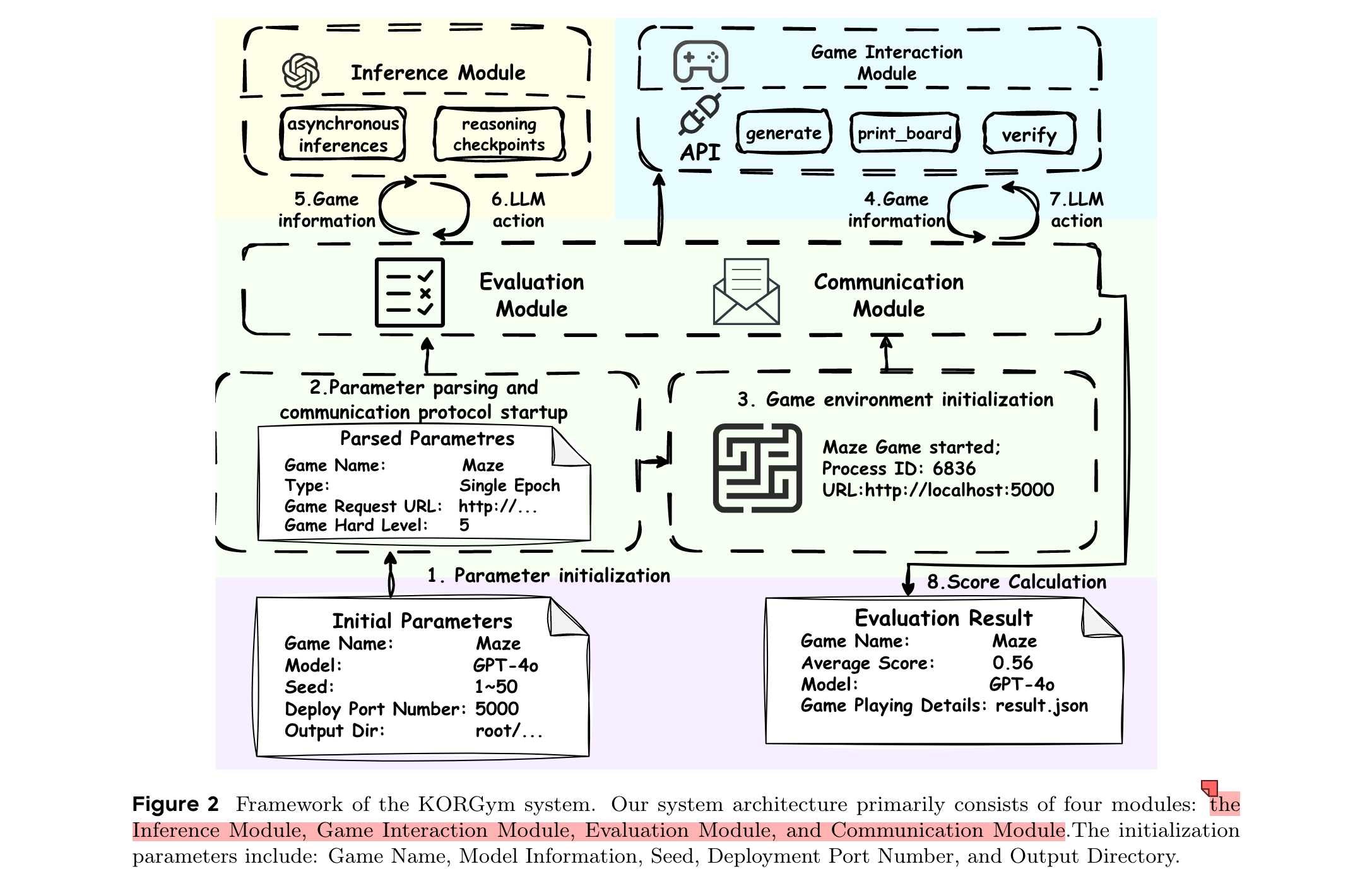
相關工作
- LLMs for Gaming:游戲因對多步推理和戰略規劃的需求,成為評估LLMs的寶貴測試床。早期研究集中在單一游戲評估,如《我的世界》或社交推理游戲,但這些狹窄的設置限制了通用性。后續雖引入更廣泛的基準,但在開放對話、動態合作沖突轉換和豐富社會動態等關鍵維度仍未充分探索。SPINBench通過結合正式規劃分析、多智能體合作/競爭和開放式對話,統一了戰略規劃和社會智能。
- Knowledge Orthogonality Based Evaluation:當前AI推理基準常將記憶與推理混為一談,難以深入了解潛在認知過程。整合型基準雖推進了對情境問題解決的關注,但仍存在領域特定知識偏差風險。知識正交性概念主張將推理評估與先驗知識分離,優先考慮在分布外場景中遵循規則,以隔離核心能力。
方法
框架
KORGym的系統架構主要包括四個模塊:推理模塊、游戲交互模塊、評估模塊和通信模塊。初始化參數包括游戲名稱、模型信息、種子、部署端口號和輸出目錄。

任務介紹
KORGym支持50余款新穎游戲,通過六個不同能力維度對LLMs的推理能力進行精確高效評估。這些游戲涵蓋傳統謎題(如數獨)、經典視頻游戲改編(如《植物大戰僵尸》《掃雷》)、博弈論挑戰(如N點、信任進化)和多模態任務(如拼圖、圈貓)等。
平臺支持通過標準化API進行多輪交互,專為強化學習設計,提供環境狀態和獎勵信號,用戶可通過可擴展參數調整游戲難度和環境多樣性,還包括9個多模態游戲,便于在文本和多模態環境中進行綜合評估。

評估方法
- 分數計算規則:為解決二元(0/1)評分在反映KORGym中間進度方面的局限性,提出了三種評分方案:二元評分(單目標游戲,成功得1分,失敗得0分)、比例評分(選擇題游戲,得分等于正確答案數除以選項總數)、累積評分(增量得分游戲,累加所有獲得的分數)。
- 能力維度聚合均值:由于原始游戲分數可能超出[0,1]區間,且可能因游戲難度變化或模型異常行為而產生偏差,引入能力維度聚合均值這一更穩健的聚合指標。通過一系列轉換和歸一化操作,確保每個游戲的模型性能映射到[0,1]范圍內,同時保留相對差異,進而得到模型在各推理維度上的表現。
實驗
設置
評估了19個大型語言模型(包括11個思維模型和8個指令微調模型)和8個視覺語言模型。評估中,對單輪和多輪游戲采用不同協議:單輪游戲中,通過將“generate”API中的“seed”參數從1變為50,每個模型在50個獨立初始化的游戲實例上進行評估;多輪游戲中,每個模型初始化20個游戲環境,每輪允許最多100次交互,并改變“generate”API中的“seed”參數以確保可重復性。所有評估均采用零樣本提示設置,保留每個模型的默認采樣參數。
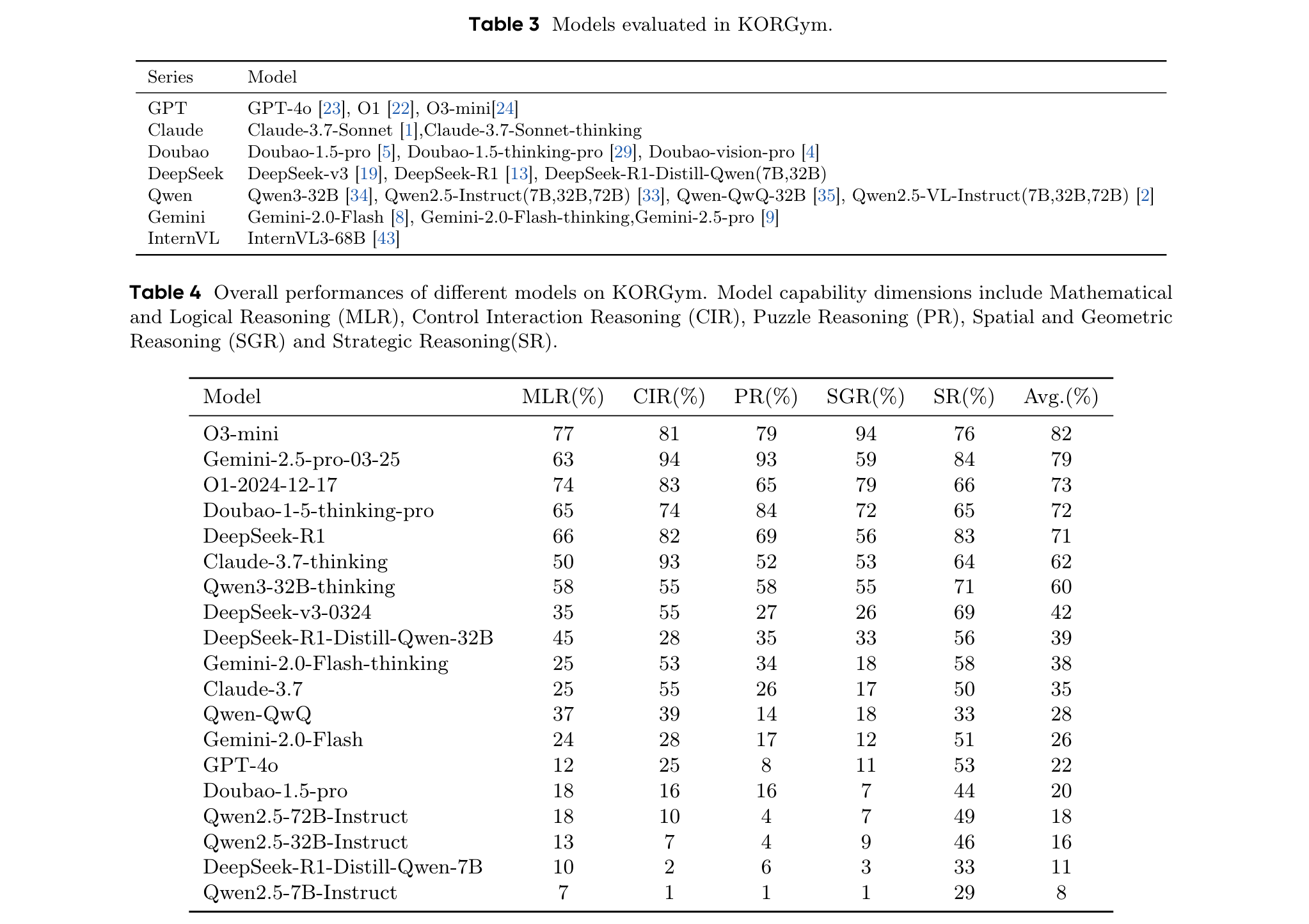
主要結果
- 同一模型系列內的推理能力表現出一致的優勢和劣勢特征。例如,O1和O3-mini在空間推理方面表現出色,而Gemini系列在數學和puzzle推理方面領先。
- 閉源模型展示出更優的推理性能。O3-mini在KORGym上獲得最高綜合得分,尤其在空間推理方面;Claude-3.7-thinking和Gemini-2.5-pro在puzzle推理方面表現最佳等。
- 模型規模和架構對推理能力有影響。模型性能隨模型大小呈正相關,思維模型優于同等規模的非思維模型。例如,DeepSeek-R1-Distill-Qwen-32B雖規模較小,但性能超過Qwen2.5-72B-Instruct。
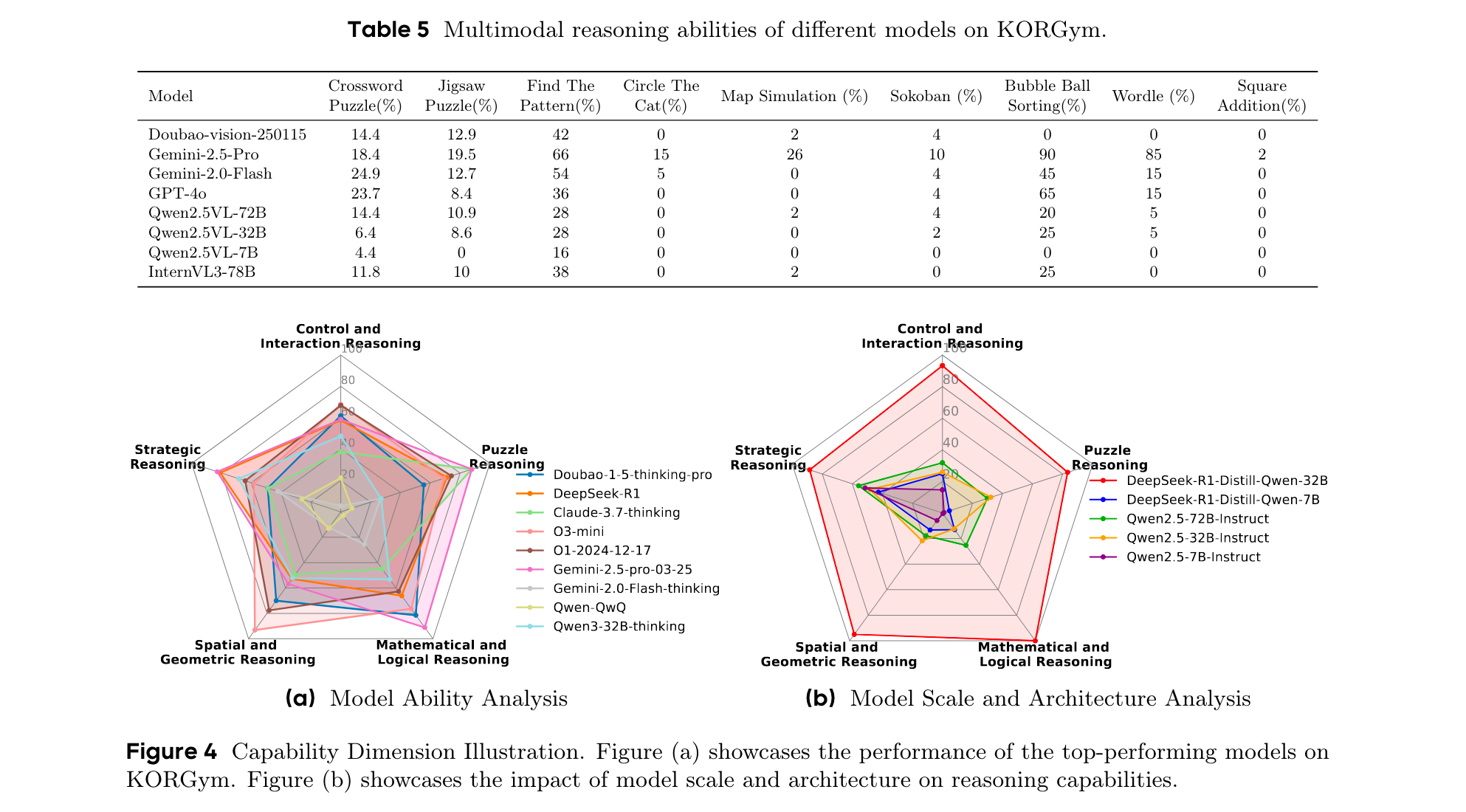
討論
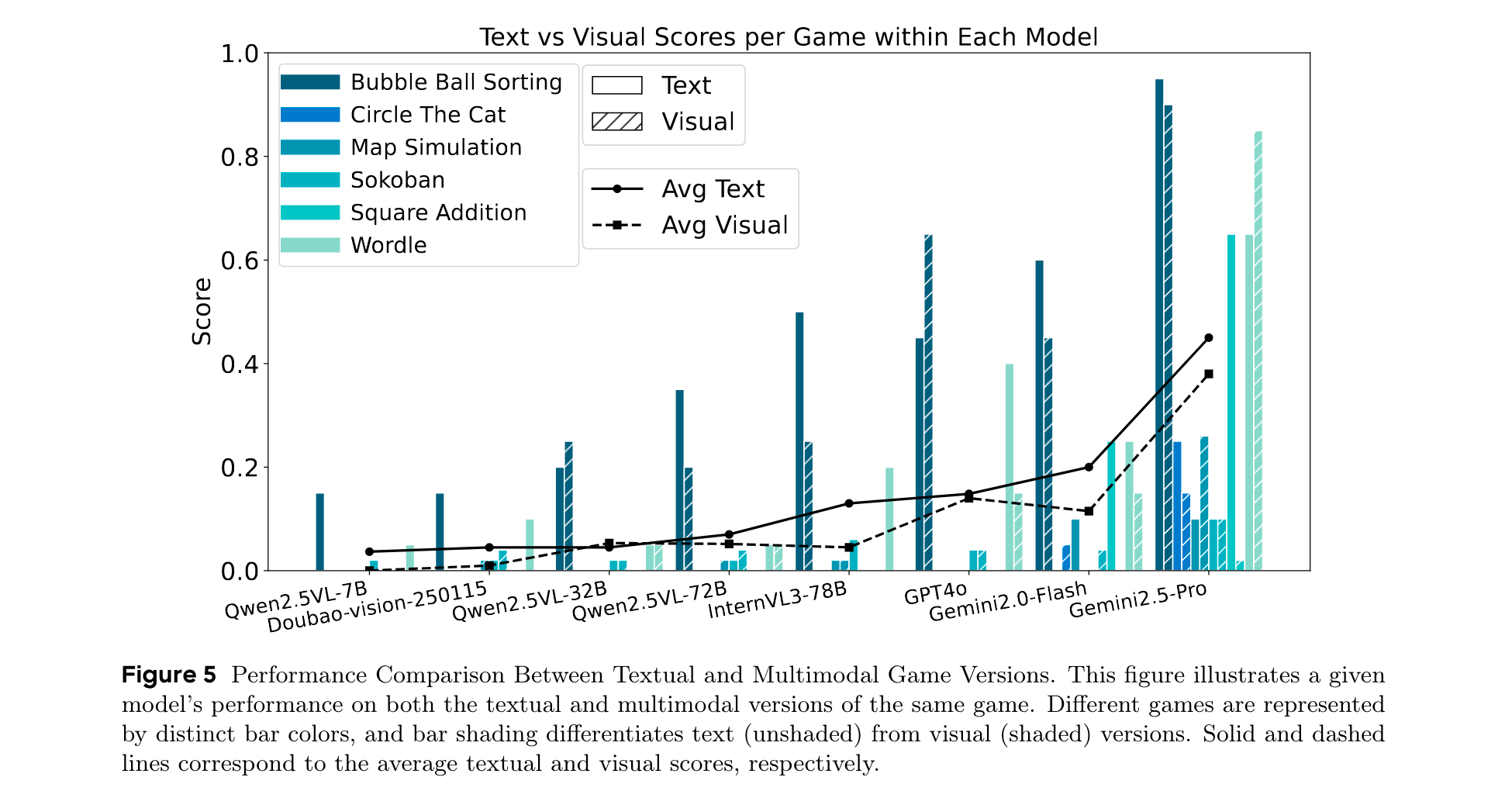
- 模態對推理性能的影響:文本版本游戲的平均得分始終高于視覺版本。開源VLMs在基于文本的推理上比基于視覺的任務表現更好,表明其視覺基礎有限或多模態對齊不夠完善。一些閉源VLMs在視覺版本上的得分高于文本版本,表明其更強的視覺推理或更優的多模態集成能力。在數學相關游戲中,模型在文本版本上的得分顯著更高,凸顯了符號表示在數值推理中的優勢。
- 不同模型系列是否表現出一致的行為模式:頂級模型在PCA空間中形成緊密集群,表明在所有維度上都具有一致的強推理性能;思維模型和非思維模型表現出不同的行為模式;LLMs在進行分析和問題解決時傾向于采用明確的推理范式,包括代碼范式、數學范式、特定算法范式和自然語言推理范式。

- 強化學習對問題解決能力的影響:在多輪強化學習微調中,特定模型結合專門的算法框架,并在綜合語料庫上訓練,在KORGym中,強化學習驅動的增強在各個推理維度上都帶來了顯著收益。
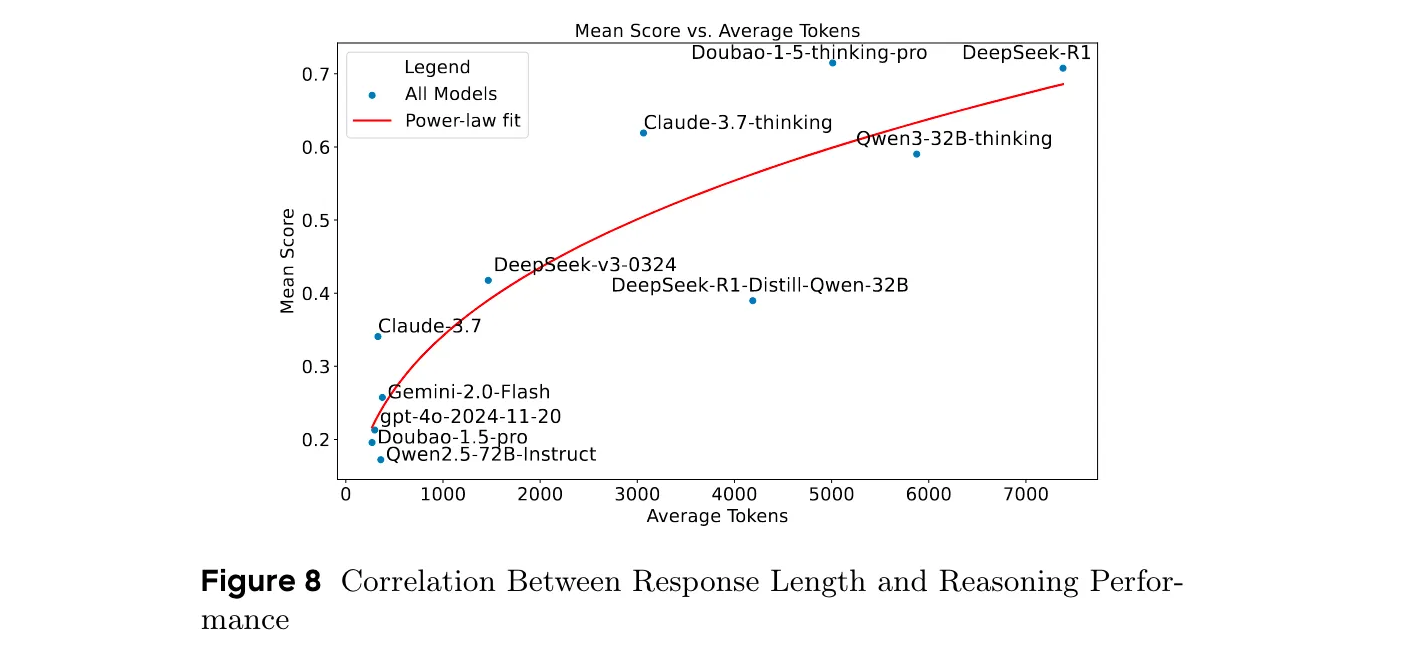
- 響應長度與推理性能的相關性:推理性能與響應長度呈強正相關,推理模型和非推理模型在響應長度分布上有顯著差異,響應長度對性能的影響存在邊際效益遞減現象。
總結
KORGym是一個可擴展的、基于游戲的基準,包含50多個跨越六個推理維度的任務。它支持多模態交互、強化學習和參數化環境,并采用基于維度感知分數聚合的穩健評估方法。通過對19個LLMs和8個VLMs的評估,揭示了模型系列內一致的強弱特征,以及模型規模和架構對推理能力的影響等。
















)

![[Python] -項目實戰4- 利用Python進行Excel批量處理](http://pic.xiahunao.cn/[Python] -項目實戰4- 利用Python進行Excel批量處理)
