一、項目背景
在社區場景中,我們積累了豐富的用戶互動數據。這些歷史互動信息對CTR/CVR預估建模具有重要參考價值,用戶的每次互動都反映了其特定維度的偏好特征。當前,已在多個業務實踐中驗證,基于用戶歷史互動特征進行未來行為預測是有效的。用戶互動序列越長,包含的偏好特征就越豐富,但同時也帶來了更大的技術挑戰。
目前社區搜索領域已經在序列建模方向取得了一些應用成果,顯著提升了搜索效率,但在該方向上仍有優化空間,主要體現在:
算法精排模型現狀:長周期的用戶互動特征尚未被充分利用,現有模型僅使用了基礎標識信息,泛化能力有待提升。我們計劃引入SIM方案來增強個性化序列建模能力,推動搜索效率提升。
迭代效率優化:當前互動特征優化依賴于實時數據采集鏈路,新增特征需要長時間數據積累(2個月以上)才能驗證效果。我們計劃建設用戶特征離線回溯服務,降低算法優化對實時數據的依賴,加快項目迭代速度,提高實驗效率。
離線回溯主要解決迭代效率問題,本文重點探討在社區搜索場景下開發離線回溯,并做離線一致性驗證過程中發現的一些問題,針對這些問題做了哪些優化措施及思考。
二、架構設計
全局架構
序列產出流程鏈路
※ ?在線流程鏈路
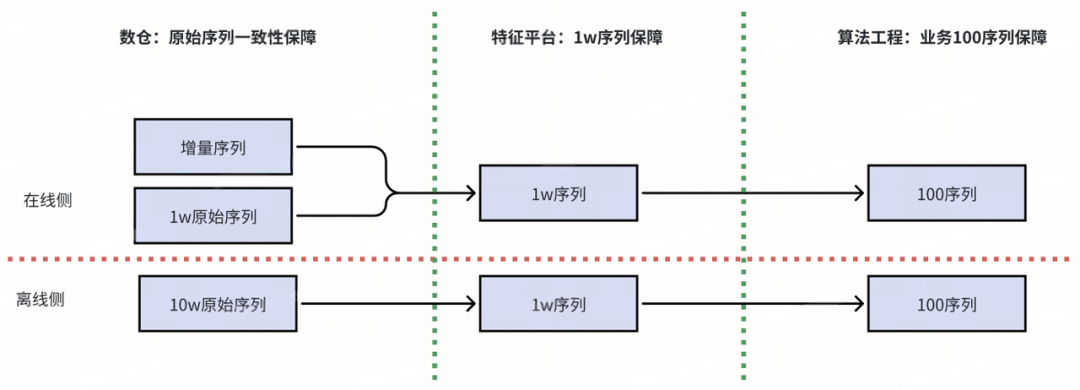
在線鏈路通過實時數倉提供全量表和實時流兩種數據源,在特征平臺下構建1w長度的實時用戶畫像,召回階段SP,將畫像傳給SIM引擎,在引擎中完成對用戶序列hard/soft search等異步加工,最終傳給Nuroe,完成在線序列dump落表。
※ ?離線流程鏈路
離線鏈路通過仿真在線的處理邏輯,利用請求pv表和離線數倉提供的10w原始序列,模擬在線序列10w->1w->100的過程,最終產出離線回溯序列。
最終通過在線/離線全鏈路數據的一致性驗證,確認全流程數據無diff(或diff可解釋),序列流程可靠性達標,可交付算法團隊用于模型訓練。
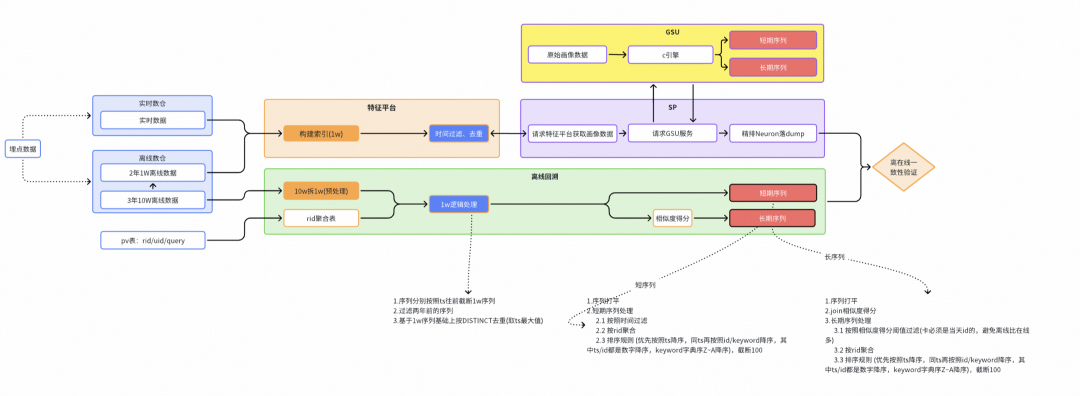
序列產出全局架構
在線架構
在線側抽象GSU模塊支持社區搜索和增長搜索等多場景復用。該模塊在QP(Query Processing)階段后,通過外調基于DSearch構建的SIM引擎進行用戶序列處理。SIM引擎內完成hard/soft search等用戶序列加工,在精排階段前獲取topk序列特征及對應sideinfo,并將其透傳給精排模塊,最終實現用戶序列的落表存儲。
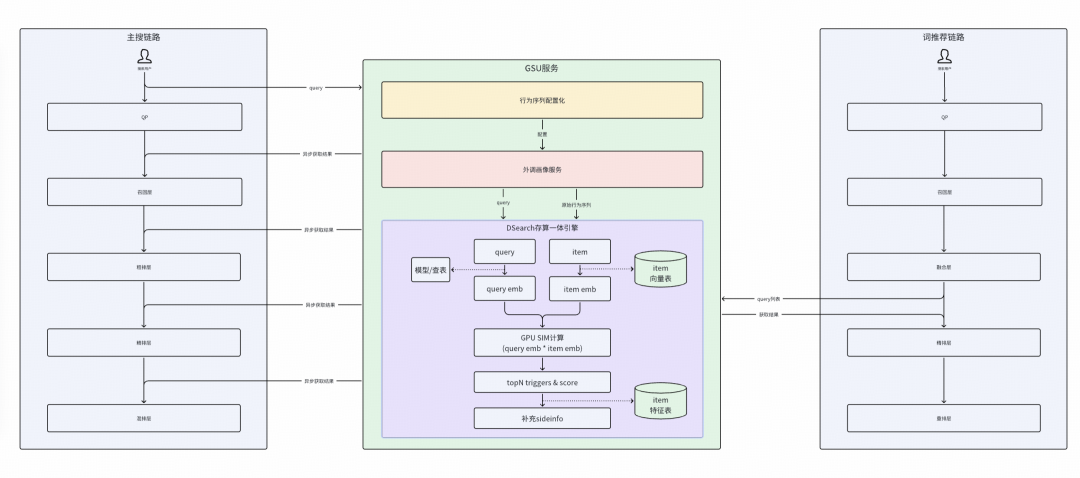
在線通用GSU模塊
離線鏈路
數據產出三階段
※ ?原始序列預處理階段
通過收集一個用戶,按照 [月初ts+1w, ?月末ts] 將序列進行預處理。
※ ?pv表合并序列表階段
按照user_id將畫像和pv表合并,將每個request_id的數據按照request_time過濾處理。
※ ?用戶序列加工階段
完成hard/soft search等用戶序列加工邏輯處理,包括對長期序列按照相似度過濾,對短期序列按照時間過濾等。
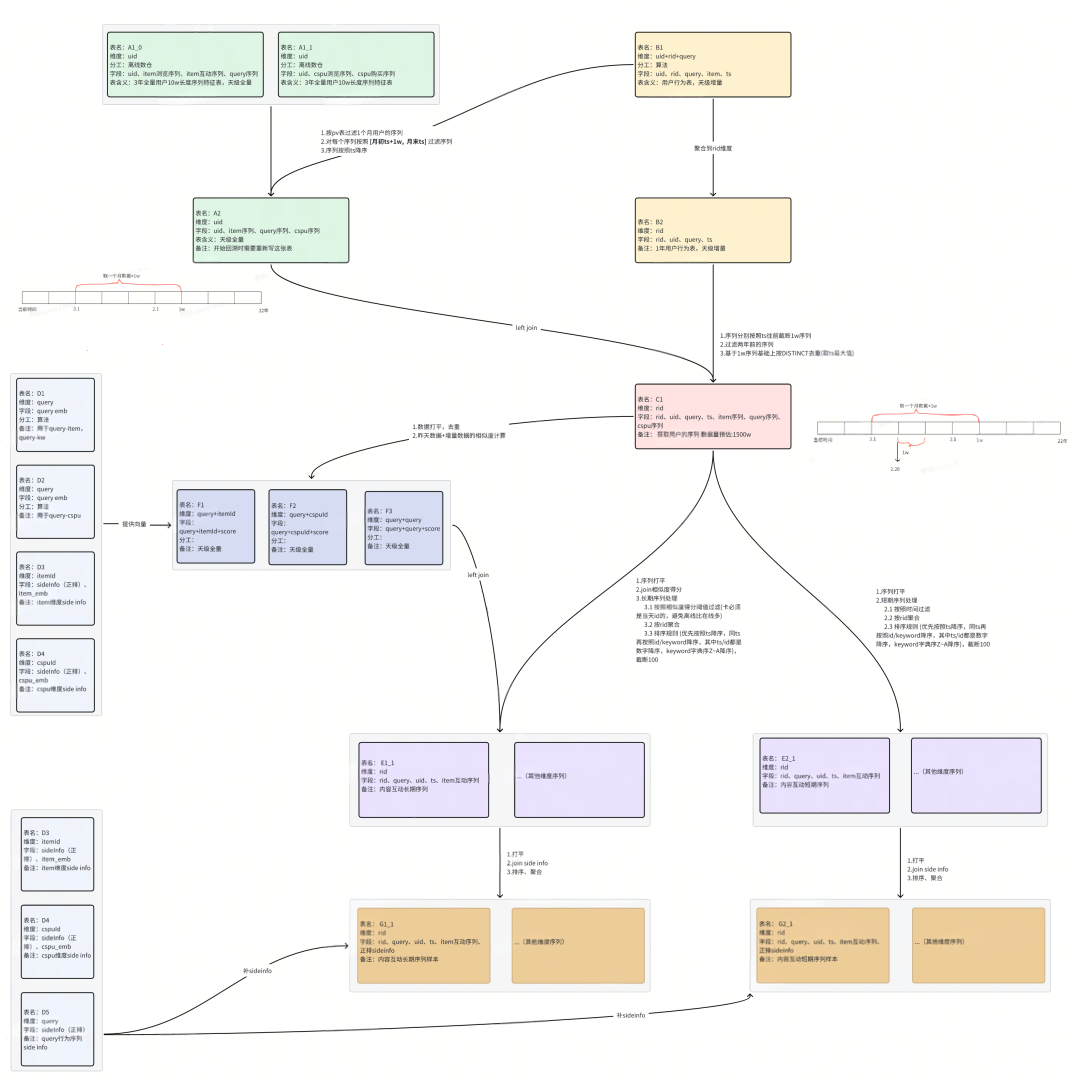
離線回溯鏈路圖
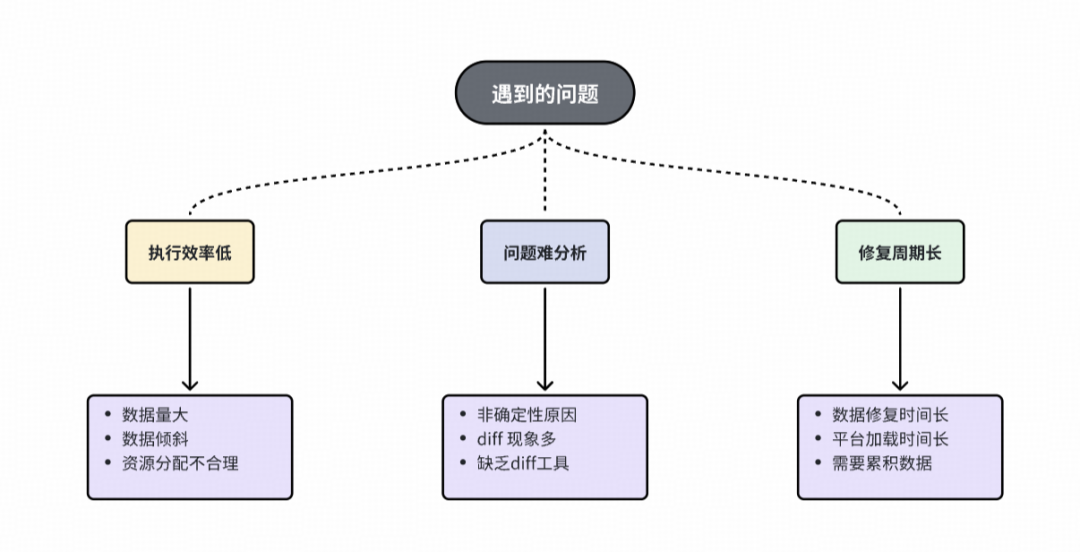
三、問題與挑戰
在離線回溯開發階段,主要面臨以下挑戰。
挑戰
※ ?任務執行問題
任務頻繁失敗或執行效率低下,數據規模達單表數TB級別,且序列分布不均,部分長尾用戶序列過長導致嚴重數據傾斜;
※ ?一致性校驗階段問題
異常類型復雜多樣,累計發現25+種異常原因,導致數據diff形態復雜,一致性原因分析困難。修復鏈路冗長,涉及問題修復、在線索引重建、數據累計和離線數據回補,單次修復周期約需一周。
四、從踩雷到填坑的實戰記錄
離線任務運行耗時長的問題
問題說明
初步方案運行時存在兩大問題:
1.任務處理延遲顯著,單個任務運行3-8小時。
2.任務處理無法運行成功頻繁OOM。
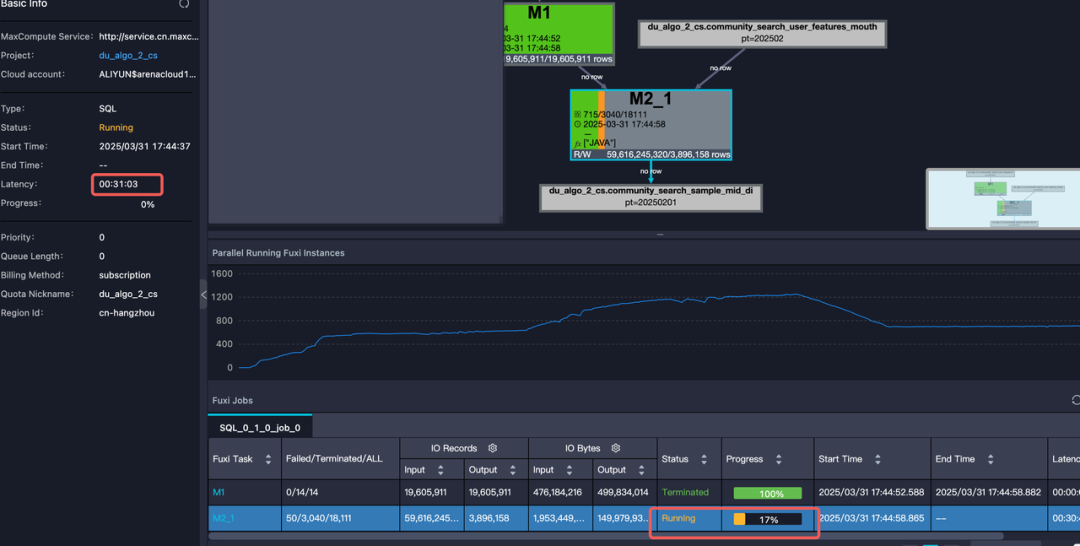
任務執行慢
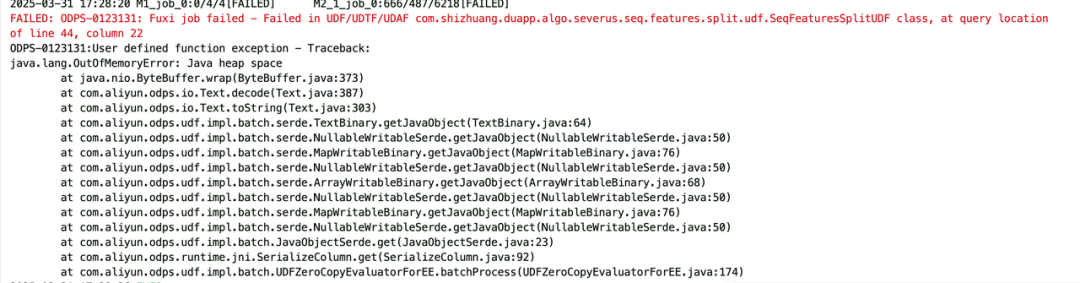
任務頻繁OOM
解決方案
※ 方案優化
任務執行慢主要是有長尾用戶打滿10w長序列,出現數據傾斜問題甚至oom。
通過對鏈路優化,先將原始10w長序列做預處理,由于回溯一般按照一個月跑數據,可以利用pv表先統計有哪些有效用戶,對有效用戶按照 【月初ts+1w, ?月末ts】截取原始序列,獲取相對較短的預處理隊列。
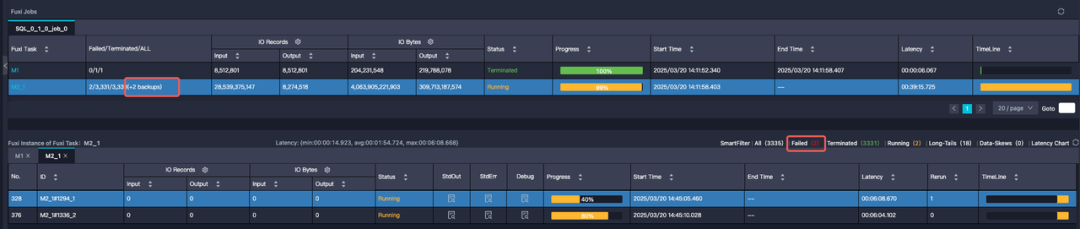
任務傾斜
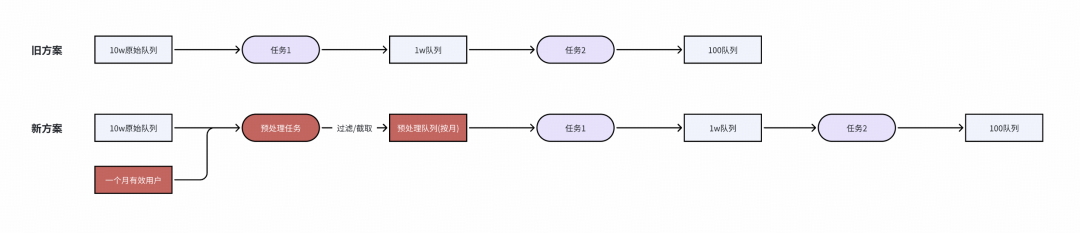
原始序列預處理
※ ?ODPS任務性能調優
a. 按照?CPU :?MEM?=??1 : 4 調整計算和存儲的比例,可以最大化利用資源,因為我們申請的資源池都是按照這個固定比例來的。

資源沒有最大化使用
b. 在固化計算/存儲比例參數后,可以通過xxx.split.size 和 xxx.num 共同調優。xxx.split.size可以實現輸入分片大小,減少oom機會。xxx.num可以實現擴大并發數,加快任務的執行(xxx代表mapper、reducer、joiner幾個階段)。

分批次完成階段處理
c. 減少自定義UDF使用。在離線任務中有部分邏輯比較復雜,可能需要數據平鋪、聚合、再內置函數等。最好的使用原則是內置函數>“數據平鋪+內置函數”>自定義UDF。由于自定義UDF運行在Java沙箱環境中,需通過多層抽象層 (序列化/反序列化、類型轉換),測試發現大數據量處理過程性能相對最差。
一致性驗證歸因難的問題
問題說明
在線/離線全鏈路數據的一致性驗證過程中,由于按照天級全量dump序列,需要驗證15個序列,每個序列diff量在10w~50w不等,這種多序列大規模的diff問題人工核驗效率太慢。
解決方案
※ ?整體diff率分析
通過統計全序列diff率并聚類分析高diff樣本,定位共性根因,實現以點帶面的高效問題修復。
※ ?diff歸因工具
通過建立數據diff的歸因分類體系(如排序不穩定、特征穿越等),并標注標準化歸因碼,實現對diff問題的快速定位與根因分析,顯著提升排查效率。
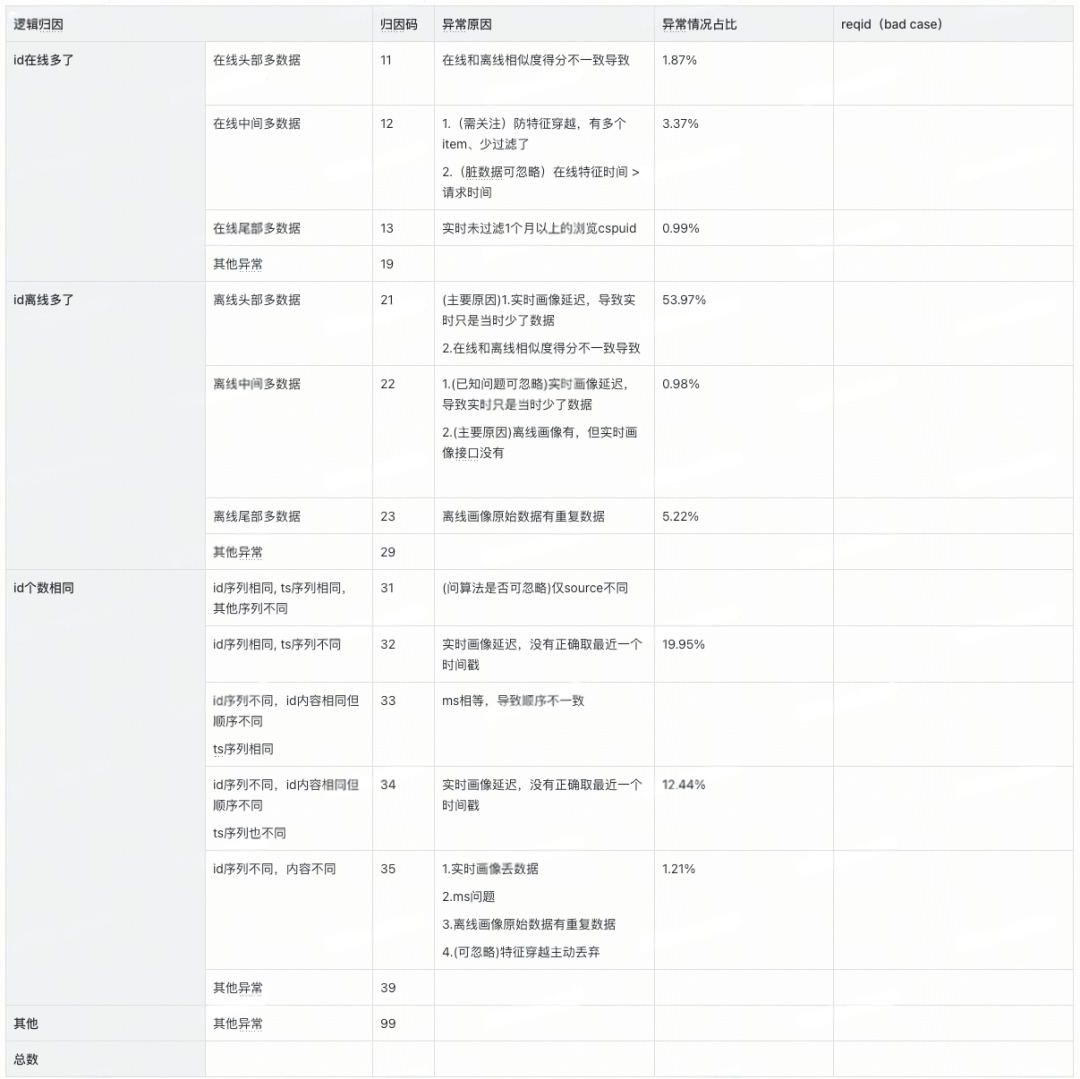
歸因碼分類
※ ?重復度統計工具
由于在線受當時環境的影響,離線回溯無法100%復現原始序列,一致性差異在所難免。我們通過聚焦主要特征并統計其重復度,結合「diff率+重復度」雙維度評估方案,為算法決策提供量化依據,有效減少無效迭代。
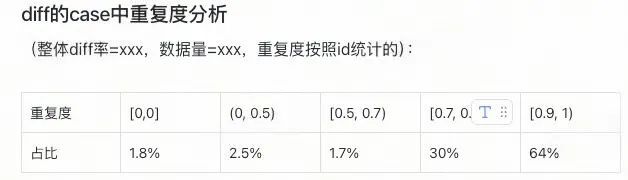
重復度統計
現狀梳理不足的問題
問題說明
由于前期對業務場景理解不足(如用戶行為模式、異常數據、測試賬戶等),部分潛在問題未在開發階段充分識別,直至數據一致性驗證時才集中暴露,導致需緊急調整數據處理邏輯。由于單次全鏈路修復需3-5天,進而對項目進度造成一定延遲。
問題case1:滑動圖片:離線回溯數據分析時發現序列中大量重復且占比很高,后確定為滑動圖片行為
解決方案:對滑動圖片操作連續多次修改為只記錄第一次
問題case2:合并下單:測試購買序列有id重復,實時數倉反饋購買有合并下單的情況,ts會相同
解決方案:為了保持離線回刷數據穩定性,將序列按照ts/id雙維度排序
問題case3:異常數據:有行為時間戳超過當前時間的異常數據
解決方案:數倉對異常數據丟棄
問題case4:測試賬戶:數據不規范導致數據diff
解決方案:測試賬戶數據忽略
問題case5:query問題:取歸一化后還是原始的query、空字符串問題
解決方案:query為空過濾修復
問題case6:數據穿越問題:畫像原始數據request_time取neuron時間導致
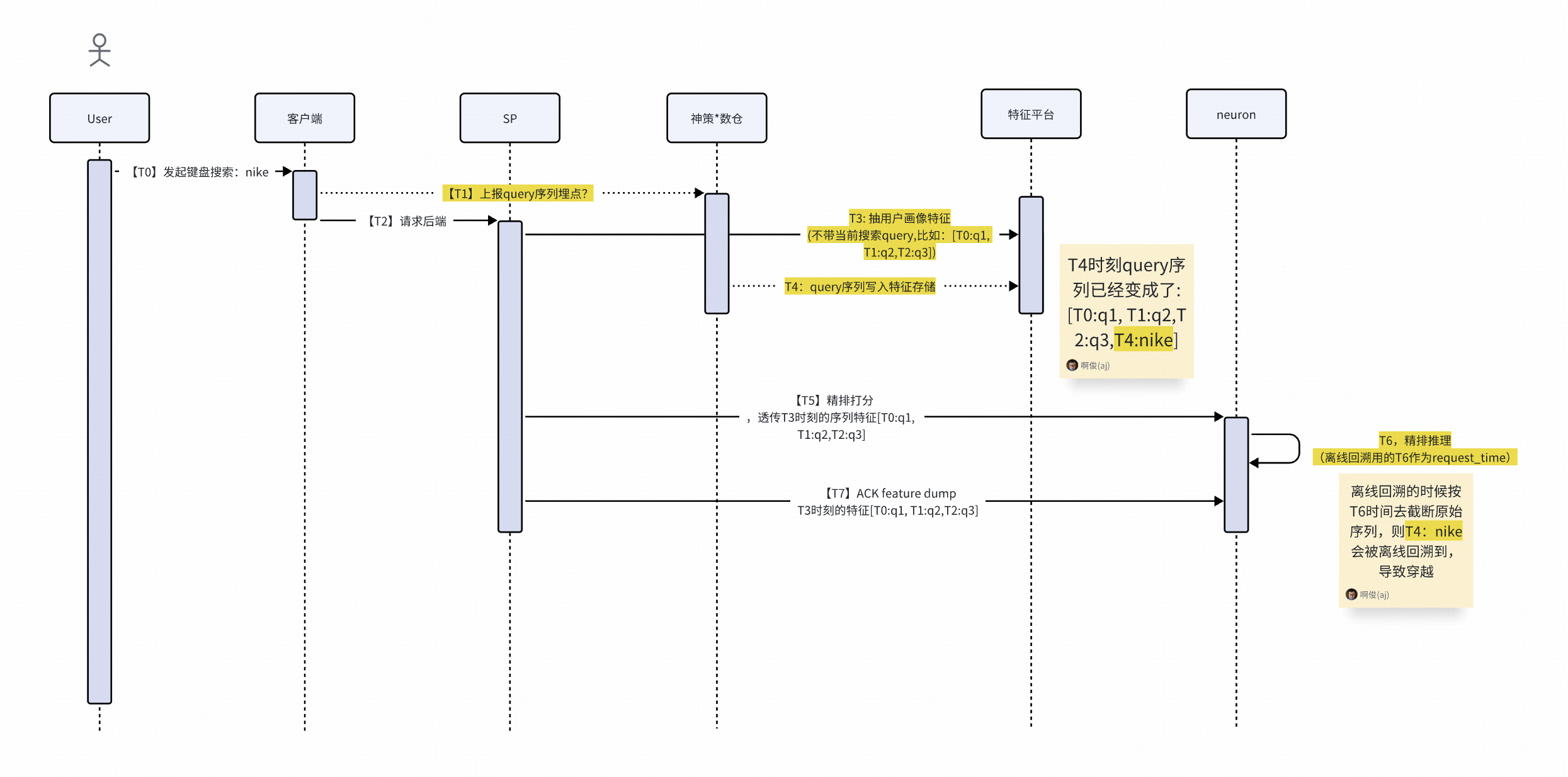
解決方案:在線修改request_time獲取時間,離線回溯前置3s
修復周期長的問題
問題說明
數據問題的完整修復流程包含三個階段,全流程通常需要5-7個工作日完成。

※ ?Diff歸因階段(1-3日)
需要定位數據差異的根本原因,區分是數據異常、處理邏輯錯誤還是業務規則變更導致
涉及多團隊協作排查(數據/算法/工程)
復雜問題可能需要多次驗證
※ ?問題修復階段(1-3日)
根據歸因結果修改代碼邏輯或數據處理流程
可能涉及歷史數據修正
※ ?數據迭代階段(2-3日)
在線畫像引擎部署新數據
累計在線數據
離線畫像回補數據
解決方案
受限于初期人力投入,我們在當前方案基礎上通過多輪版本迭代逐步完成數據一致性驗證。后續將通過工具升級(數據邊界劃分+自動化校驗框架)和數據采樣策略,實現驗證到修復的階躍式提升。
※ ?數據邊界劃分
現行方案離線鏈路都是算法工程來維護,排查鏈路太長,需要數據源有穩定的保障機制。后續將劃分數據邊界,各團隊維護并保障數據模塊在離線的一致性。
數據邊界劃分
※ ?全鏈路采樣方案減少驗證時間
離在線一致性驗證方面耗時較長,主要在于數據量太大,在數倉構建、特征平臺構建、累計數據等流程消耗大量的時間,如果全鏈路先針對少量用戶走通全鏈路,能快速驗證流程可行性。
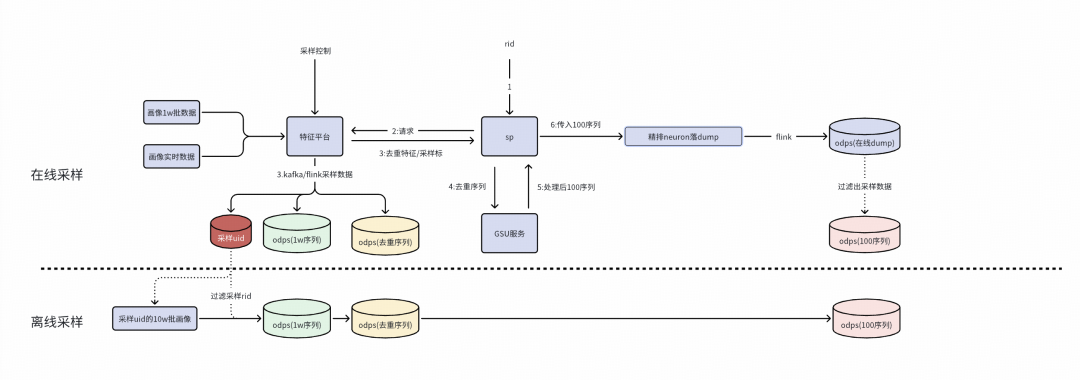
采樣方案
平臺基建的問題
問題說明
首次構建序列建模體系,由于缺乏標準化基礎設施,被迫采用煙囪式開發模式,導致多鏈路驗證復雜且問題頻發。
平臺待建能力
特征平臺排序功能不足,只支持單一字段排序,不支持多字段聯合排序,導致排序結果不穩定。
特征平臺過濾功能限制,僅支持毫秒級時間戳過濾。
索引構建效率低,個性化行為序列表數據量過大(3TB),導致索引構建壓力大,初始構建耗時約28小時。升級至FS3集群后,構建時間降至12小時左右,最短至7小時,但仍未達理想效率。
五、展望與總結
后續我們將深入研究行業內的優秀解決方案,并結合我們的業務特性進行有針對性的優化。
例如,我們會嘗試實施離在線數據與邏輯一致性方案,這種方案包括以下幾個特點:
數據一致性:離線與在線共用同一套原始畫像,能夠解決數據源不一致導致的差異問題。
邏輯一致性:離線與在線都調用GSU服務,實現統一的序列邏輯處理,避免邏輯差異。
技術架構復雜性:新方案帶來了新的技術挑戰,比如在線處理10萬序列可能引發的I/O問題、離在線的sim引擎采用存算一體和存算分離架構。
綜上,沒有絕對完美的技術方案,最終都是在成本、性能和效率多方面權衡后的相對最優解。
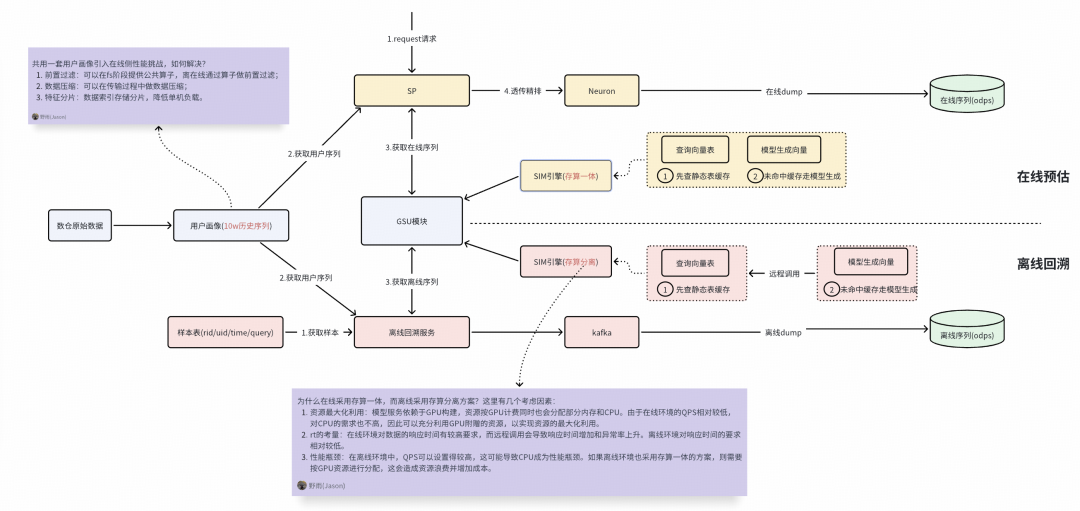
離在線數據與邏輯一致性方案
本次特征回溯雖面臨性能與數據對齊等挑戰,但團隊通過攻堅積累了經驗,為特征平臺后續特征回溯工具化打下基礎,也期待能為后續算法模型迭代帶來質的飛躍。
往期回顧
1.從 “卡頓” 到 “秒開”:外投首屏性能優化的 6 個實戰錦囊|得物技術
2.從Rust模塊化探索到DLB 2.0實踐|得物技術
3.eBPF 助力 NAS 分鐘級別 Pod 實例溯源|得物技術
4.正品庫拍照PWA應用的實現與性能優化|得物技術
5.匯金資損防控體系建設及實踐 | 得物技術
文 / 野雨
關注得物技術,每周更新技術干貨
要是覺得文章對你有幫助的話,歡迎評論轉發點贊~
未經得物技術許可嚴禁轉載,否則依法追究法律責任。








核心解析:下一代搜索技術的演進與落地策略)





)

)

講解))
