最新統計數據聲稱,今天的 Google 搜索量是 ChatGPT 搜索的 373 倍,但我們大多數人都覺得情況恰恰相反。
那是因為很多人不再點擊了。他們在問。
他們不是瀏覽搜索結果,而是從 ChatGPT、Claude 和 Perfasciity 等工具獲得即時的對話式答案。這些生成引擎正在迅速改變人們發現和使用信息的方式,在許多情況下,您的網站甚至不是等式的一部分。
據 Search Engine Journal 報道,在 Google 中出現 AI Overviews 的行業中,信息查詢的點擊率正在下降。與此同時,另一份報告發現,ChatGPT 每月處理超過 17 億次訪問,這些流量以前可能通過傳統搜索進行。
這種轉變挑戰了我們對 SEO 的看法,并強調了放棄過時的劇本并開發更適合這一新領域的新的、更有效的策略的重要性。
在本指南中,我將分解生成引擎優化 (GEO) 的真正含義,它與經典 SEO 有何不同,以及如何改進策略以保持可被發現性,無論人們在哪里或如何搜索。
什么是生成式引擎優化?
生成式引擎優化(GEO)是指通過優化內容,使其在 ChatGPT、Claude、Gemini 和 Perplexity等生成式人工智能平臺中作為權威來源或直接響應出現。
與傳統 SEO 不同,傳統 SEO 側重于在搜索引擎結果頁面(SERPs)中獲得排名以獲取點擊量,而 GEO 的目標是讓您的內容成為 AI 引擎在生成答案時主要參考的來源。目標從獲取點擊量轉變為讓您的信息被納入 AI 的響應中。
這標志著內容優化方法的根本性轉變:
- 傳統 SEO:優化搜索結果中的可見性 → 獲得點擊量 → 在網站上轉化用戶
- GEO:優化成為權威來源 → 在AI回復中被引用 → 建立品牌認知度和權威性
這一區別至關重要,因為生成式引擎與傳統搜索引擎的運作原理不同:
- 它們不會優先將流量導向外部網站。
- 它們會將來自多個來源的信息整合成一個統一的響應。
- 它們對權威性和可信度的評估方式與谷歌不同。
- 它們會優先展示符合其訓練參數和檢索機制的內容。
生成式人工智能如何重塑搜索格局
生成式人工智能作為主要信息來源的轉變速度比許多營銷人員預期的要快。數據也印證了這一點:
- 根據 Gartner 的調查,目前 35% 的 Z 世代用戶將人工智能工具作為研究問題的首選工具,而千禧一代和 X 世代的這一比例分別為 19% 和 7%。
- 于2022年底推出的Perplexity.ai,目前每天處理超過 1000 萬個獨特查詢。
- Stack Overflow 報告稱,自 ChatGPT 推出以來,編程相關問題的提問量減少了 35%,因為開發者越來越多地轉向 AI 尋求編碼解決方案。
這一轉變在特定領域尤為明顯。技術搜索(編程、數據分析)、事實查詢以及如何操作類內容正迅速向人工智能平臺遷移,而商業搜索仍主要在傳統搜索引擎上進行。
目前來看在內容發現模式發生了劇烈變化,尤其是在深度教育內容領域,過去需要花費15至20分鐘閱讀多篇文章的用戶,現在只需不到五分鐘就能通過AI獲得綜合答案。
這一演變既帶來了挑戰,也創造了戰略機遇。雖然提供簡單事實信息的網站可能面臨流量下降,但那些能夠提供獨特見解、原創研究和專家觀點的網站,可以定位自己為人工智能引擎依賴的權威信息來源。
GEO 與 SEO:兩者有何區別?
讓我們深入探討 GEO 與 SEO 之間的五大主要差異。
1. 引用取代鏈接(且引用是可選的)
在傳統 SEO 中,鏈接至關重要。它們驅動流量、傳遞權威性,并作為用戶訪問您內容的主要途徑。
在生成式人工智能領域,引用已取代鏈接。生成的內容中鏈接寥寥無幾甚至完全缺失。
當 ChatGPT 從多個來源合成答案時,它很少提及信息來源,更不用說提供鏈接了。
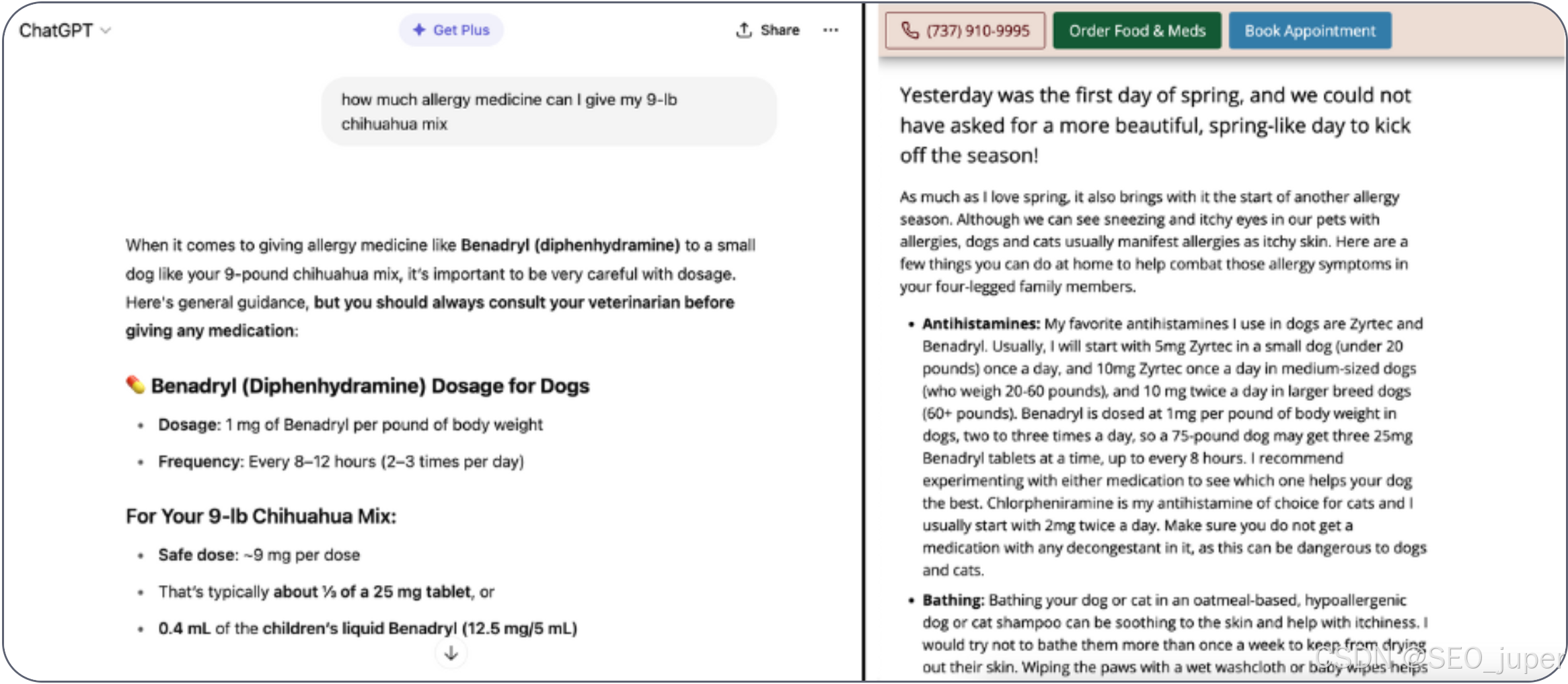
以下是一個真實案例:我詢問 ChatGPT 哪些植物能驅趕蚊蟲。它提供了列表和建議,但未提供任何來源。
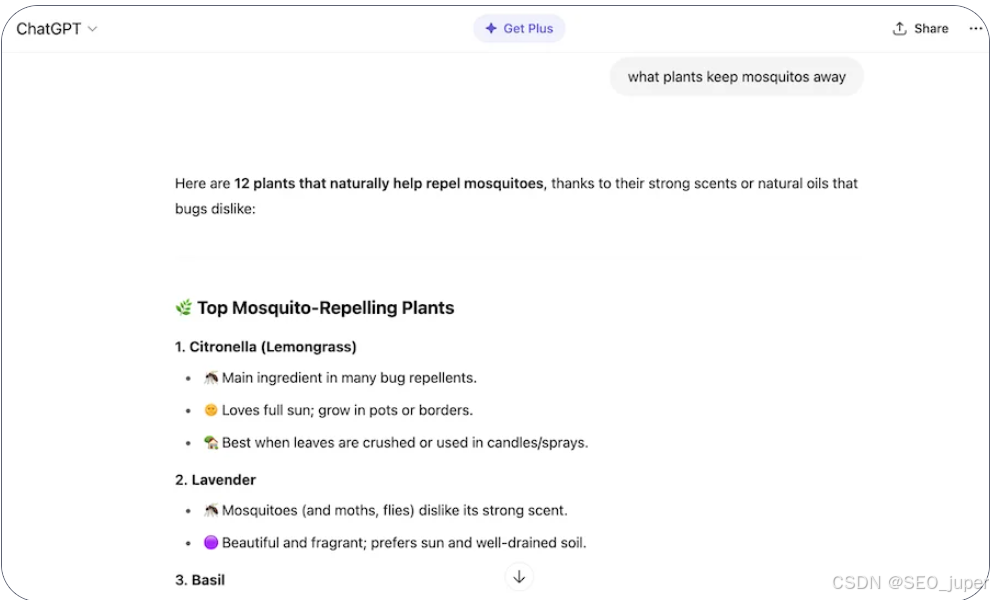
即使是提供來源出處的 Perplexity,通常也會將參考文獻列在回復的底部,而根據行業 Reddit 討論,許多用戶從未滾動到該位置。
GEO 提示:創建“引用誘餌”內容,讓生成式引擎自然地引用:
- 通過原創研究開發獨特的統計數據。
- 制定清晰簡潔的定義,便于 AI 提取。
- 以易于 AI 解析的方式組織信息(表格、列表、分步指南)。
- 創建具有品牌特色的獨特陳述和框架。
2. 權威信號比以往任何時候都更加重要
生成式人工智能引擎會從它們認為權威的來源中獲取信息,這使得小型或新網站更難獲得曝光度。然而,對于人工智能而言,“權威”的定義與谷歌傳統的排名因素有所不同。
雖然谷歌使用反向鏈接、域名年齡和用戶互動信號等指標,但生成式人工智能模型是在海量數據集上訓練的,其中某些來源出現頻率更高且被視為更可靠。這為建立權威性開辟了新的范式。
對于人工智能平臺而言,權威性來源于:
- 在多個高質量平臺上的持續存在。
- 來自行業權威人士的認可。
- 明確的專業能力信號(作者資質、專業機構隸屬關系)。
- 遵循成熟格式規范的結構化內容。
GEO 提示:構建生成式人工智能能夠識別的多維度權威信號:
- 在自己的域名上發布內容,同時也在行業內備受尊重的平臺上發布。
- 獲得該領域知名專家的提及。
- 明確標注作者資質和專業領域標識。
- 創建展示人工智能無法合成的專業知識的內容。
3. 結構化、信息豐富的內容成為優質燃料
生成式人工智能模型偏愛結構化內容。它們設計用于識別模式、提取關鍵信息并識別概念之間的關系。這使得高度結構化、信息密集型內容對這些系統尤為珍貴。
在生成式引擎中表現最佳的內容包括:
- 遵循邏輯層次結構的清晰標題和副標題。
- 通過項目符號和編號列表組織信息。
- 展示比較數據的表格。
- 直接回答具體問題的常見問題解答(FAQ)部分。
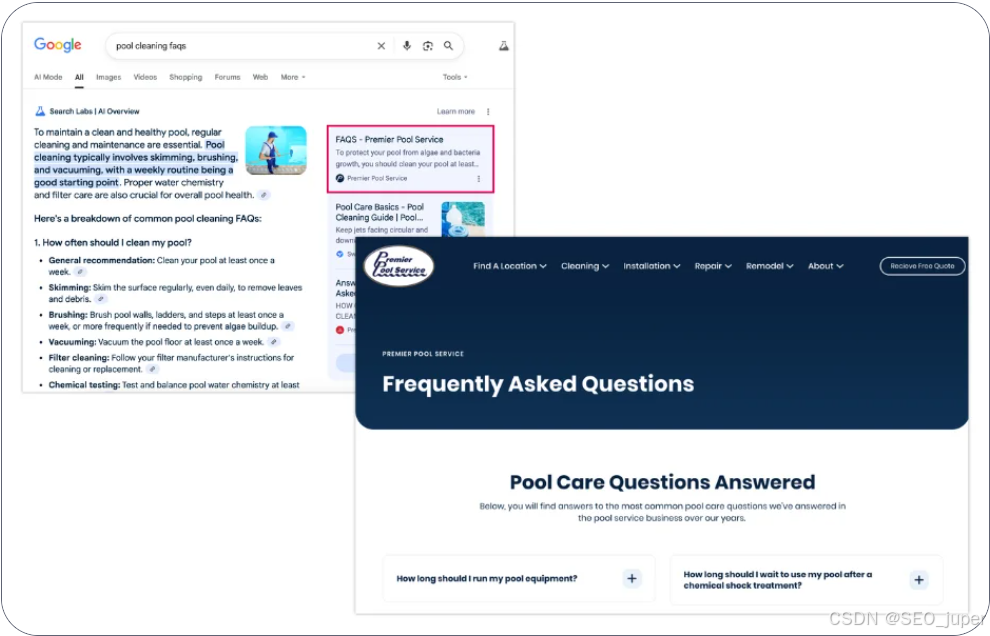
- 分步指南,附帶編號說明。
- 清晰的概念定義與解釋。
這種對結構的偏好解釋了為何維基百科內容在AI回復中頻繁出現。其遵循一致的格式規范,使信息易于提取。
GEO 提示:優化內容結構以提升 AI 解析效率:
- 使用清晰、描述性強的標題以突出內容相關性。
- 將信息組織成列表、表格等結構化格式。
- 包含關鍵概念的簡明定義與解釋。
- 添加結構化數據標記以提升 AI 對內容的理解。
- 創建專門的常見問題解答(FAQ)板塊,直接回答常見問題。
在傳統搜索和生成式搜索中表現最佳的內容遵循相似的原則:結構清晰、權威性強,并能明確滿足用戶需求。區別在于,人工智能能夠在無需用戶訪問您的網站的情況下,提取并整合這些信息。
4. 品牌可見性必須超越傳統搜索
在傳統 SEO 中,提升自身網站的排名是首要目標。而在 GEO 中,您的內容需要存在于生成式 AI 可能獲取信息的任何地方。
當回答關于本地營銷策略的問題時,生成式 AI 可能會從以下來源獲取信息:
- Facebook 社區群組
- Yelp 評論與回復
- 本地商業目錄
- 小型企業論壇
- 行業特定的博客評論
這意味著僅依賴網站來提升品牌可見度已不再足夠。您的品牌需要在多個平臺上以一致且易于識別的形式呈現。
GEO 提示:在為 AI 系統提供數據的平臺上分享專業知識:
- 積極參與行業論壇和社區。
- 在主要內容平臺(如 Medium、LinkedIn 等)發布內容。
- 制作帶有優化字幕的視頻內容。
- 參與播客采訪以生成文字記錄內容。
- 參與開源項目和公共知識庫的建設。
跨平臺的品牌提及會產生網絡效應,提升AI的可見性,當AI在多個權威場景中看到你的品牌被提及,它更可能在回復中包含你,即使沒有直接鏈接。
5. 內容策略現已轉向提示驅動型
人們與生成式人工智能的互動方式與搜索引擎不同。他們不再使用簡短的關鍵詞短語,而是采用對話式語言,提出后續問題,并明確說明自己的需求。
這為優化帶來了新維度:創建與人們提示人工智能系統方式相匹配的內容。
請考慮以下差異:
傳統搜索查詢:“best accounting software”
AI 提示:“What’s the best accounting software for a family-owned restaurant with 12 employees that needs to track inventory and has a limited tech budget?”
傳統搜索查詢:“how to promote small business”
AI提示:“Can you suggest affordable marketing tactics for a new hair salon in a suburban area, focusing on attracting families and building repeat customers?”
這些更長、更具體的提示需要能夠回答復雜問題并提供上下文信息的內容。針對短關鍵詞優化的通用內容無法滿足這些詳細需求。
GEO 提示:創建能夠預判對話提示的內容:
- 研究您所在行業中常見的問題模式。
- 開發針對特定使用場景和情境的內容。
- 包含有助于 AI 區分相似選項的比較內容。
- 提供情境特定的信息(針對不同企業規模、行業等推薦內容)。
- 創建遵循自然對話流程并包含邏輯后續內容的內容。
如何構建有效的 GEO 策略
既然您已經了解了 GEO 與傳統 SEO 之間的差異,以下是一些構建策略的建議。
1. 設計適合 AI 處理的內容
有效 GEO 的第一步是創建易于 AI 系統理解和提取的內容。這不僅涉及簡單的格式調整,還需考慮 AI 如何處理和優先級排序信息。
人工智能優化內容的關鍵原則:
- 在開頭部分突出關鍵信息:將關鍵事實、定義和見解放在前幾段中。
- 使用描述性、關鍵詞豐富的標題:讓每個部分的目的是立即清晰。
- 創建獨立的段落:每個內容塊應能夠獨立存在,同時融入整體內容。
- 包含明確的專業信號:通過數據、專家引語和具體經驗來展示權威性。
- 優先考慮事實準確性:人工智能系統越來越傾向于跨來源驗證信息。

2. 創建多模態內容
生成式人工智能正迅速發展,超越文本范疇,能夠理解并基于圖像、視頻和音頻生成響應。這為優化多種內容類型以提升人工智能可見性提供了機遇。
多模態 GEO 策略:
- 通過結構化字幕優化視頻內容:包含時間戳、發言人識別和清晰的章節標記。
- 為圖像添加描述性替代文本:通過詳細描述幫助 AI 理解視覺內容。
- 創建帶有清晰標簽的數據可視化:使圖表和圖形對 AI 系統可解讀。
- 開發結合多種格式的內容:發布嵌入視頻、圖像和結構化數據的文章。
這種方法確保當 ChatGPT-4 或谷歌的 Gemini 分析您涉及的主題時,您被引用的可能性更高。
3. 通過數字公關和思想領導力提升 AI 可見性
在數字生態系統中建立權威信號對 GEO 成功至關重要。這需要采取戰略性的數字公關和思想領導力方法,確保您的品牌被 AI 系統認可為權威來源。
構建 AI 可識別權威性的有效策略:
- 在權威行業媒體中獲得提及:注重質量而非數量。
- 開發標志性框架或方法論:創建與品牌緊密關聯的獨特方法。
- 參與行業研究報告:為重大研究提供數據或專業見解。
- 為關鍵團隊成員建立個人品牌權威:通過個人專業能力強化組織權威性。
- 在為 AI 訓練數據提供支持的平臺上建立一致的存在感:定期在高權威網站上發布內容。
這種多平臺策略確保當生成式 AI 回答關于視覺網頁開發或無代碼工具的問題時,Webflow 的觀點經常被納入其中,即使沒有直接引用。
4. 為 GEO 優化內容策略以應對未來變化
隨著生成式 AI 的不斷發展,保持可見性將需要一種兼顧傳統 SEO 與新興 GEO 實踐的適應性、前瞻性策略。
未來可適應的內容策略核心原則:
- 平衡深度與易用性:內容既要全面,又要便于 AI 解析。
- 投資于專有數據:無法從其他來源合成的原創研究。
- 打造獨特的品牌聲音:在 AI 生成的內容中脫穎而出的獨特視角。
- 聚焦專業領域:在您真正具備權威性的主題上加倍投入。
- 創建回答“why”而非僅“what”的內容:提供 AI 難以合成的背景和推理。
如何衡量 GEO 成功率
衡量 GEO 效果需要超越傳統 SEO 關鍵績效指標(KPI)如排名和自然流量的新指標。由于目標是出現在 AI 生成的回復中而非直接驅動網站訪問量,因此需要采用不同的跟蹤方法。
GEO 成功率的關鍵指標
以下是需要關注的指標:
- 品牌提及頻率:您的品牌在 AI 對相關查詢的響應中出現的頻率。
- 表述準確性:AI 系統是否正確地表述了您的產品、服務和觀點。
- 權威定位:您是否被定位為主要或次要信息來源。
- 歸因率:您的品牌在 AI 響應中直接獲得歸因的頻率。
- 競爭存在感:您的提及頻率與競爭對手在類似查詢中的對比情況。
衡量GEO結果的工具
目前已有多種工具可用于追蹤這些指標:
- Perplexity Labs:可監控 Perplexity 回復中的來源歸因。
- ContentLab AI:跨多個 AI 平臺追蹤品牌提及。
- BrandMentions:已擴展至包含 AI 提及監控功能。
- Custom prompt testing:系統性地在多個 AI 平臺上測試關鍵行業提示詞。
我們目前仍處于 GEO 測量技術的早期階段,但具有前瞻性的企業已開始構建系統來追蹤其在 AI 響應中的可見度,這與我們過去追蹤搜索引擎結果頁面(SERP)排名的方式類似。
- 品牌是否被提及;
- 品牌是否被突出展示;
- 信息是否準確;
- 競爭對手是否被更頻繁地提及;
這些數據可幫助指導您的 GEO 策略并衡量隨時間的改進情況。
GEO 與新的搜索范式
我們正見證著自谷歌誕生以來信息發現領域最重大的變革。正如部分企業在從紙質媒體向數字媒體轉型時未能及時適應,那些忽視生成式人工智能崛起的企業也可能在新的搜索格局中變得難以被發現。
但這一變革也帶來了前所未有的機遇。那些懂得如何創建 AI 優化內容、建立公認權威并保持在數字生態系統中存在感的企業,將自然而然地出現在日益影響人們信息獲取方式的 AI 響應中。
搜索的未來不在于在傳統 SEO 和 GEO 之間做出選擇,而在于制定一個整合策略,確保無論人們如何獲取信息都能保持可見性。
在制定策略時,請記住:盡管技術日新月異,但核心原則始終不變:提供真實價值、展示專業能力、滿足用戶需求,這些要素將永遠受到認可,無論您與受眾之間存在何種算法或人工智能系統。





)

)

講解))


)






