引言
在當今數據驅動的商業環境中,企業面臨著日益復雜的決策問題。傳統的數據分析工具往往難以應對多步驟、多依賴的復雜問題求解。例如,當企業需要分析"北美市場 Q1-Q2 主要產品的銷售增長趨勢并識別關鍵驅動因素"時,傳統工具可能需要人工依次完成數據收集、清洗、分析、可視化等多個環節,不僅效率低下,還容易因人為因素導致誤差。
本文介紹一種基于 Planning Agent 的智能規劃引擎,它通過目標理解、任務分解、動態規劃和自適應執行等核心技術,實現了復雜問題的端到端求解。從代碼執行記錄可以看到,該引擎成功處理了 “分析北美市場 Q1-Q2 主要產品銷售增長趨勢” 這一復雜查詢,自動完成了從數據獲取到最終洞察生成的全流程,展現出強大的復雜問題處理能力。
傳統方案的痛點與Planning Agent的解決方案
| 痛點領域 | 普通Agent/Workflow Agent | Planning Agent解決方案 | Planning Agent技術優勢 |
|---|---|---|---|
| 靈活性 | 固化流程難以適應動態需求 | 動態規劃與實時調整 | ? 任務自動分解與排序 ? 執行中動態調整策略 ? 基于反饋的流程優化 |
| 復雜依賴處理 | 手動定義依賴易錯難維護 | 智能依賴解析與檢查 | ? 依賴關系自動推導 ? 運行時依賴狀態監控 ? 并行無依賴任務執行 |
| 錯誤恢復 | 單點失敗導致全局中斷 | 多級容錯機制 | ? 步驟級參數調整重試 ? 計劃級任務重構 ? 全局級流程重啟 |
| 知識復用 | 缺乏自我優化能力 | 反射性經驗積累 | ? 執行歷史分析 ? 錯誤模式識別 ? 策略知識庫構建 |
| 復雜任務處理 | 簡單指令到復雜執行的鴻溝 | 分層規劃架構 | ? 目標理解→任務分解→步驟規劃 ? 多粒度問題求解 ? 抽象到具體的漸進細化 |
系統架構概覽
總體流程
Planning Agent 的核心架構采用分層設計,形成完整的 “理解 - 規劃 - 執行 - 反思” 閉環:
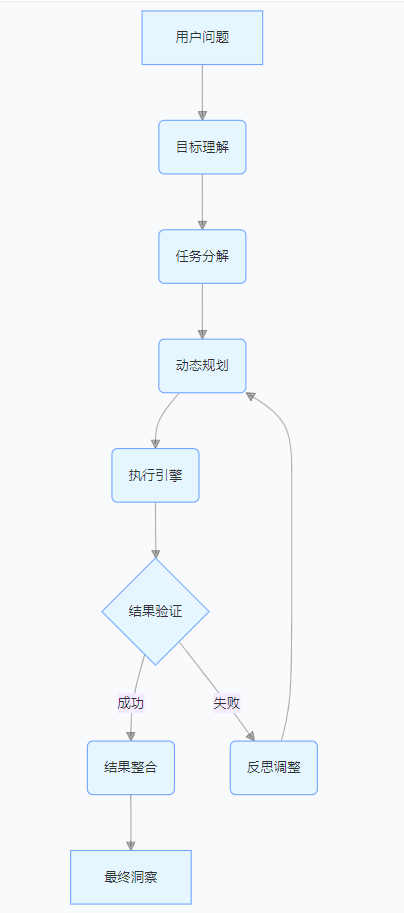
從實際執行流程來看,用戶查詢首先經過目標理解模塊轉化為結構化目標,然后分解為一系列原子任務,接著生成詳細的執行計劃,由執行引擎按計劃執行并實時驗證結果,若失敗則觸發反思調整機制,最終將所有結果整合為有價值的洞察報告。這種架構確保了系統能夠處理復雜的依賴關系和動態變化的執行環境。
細化流程
主流程
子流程定義

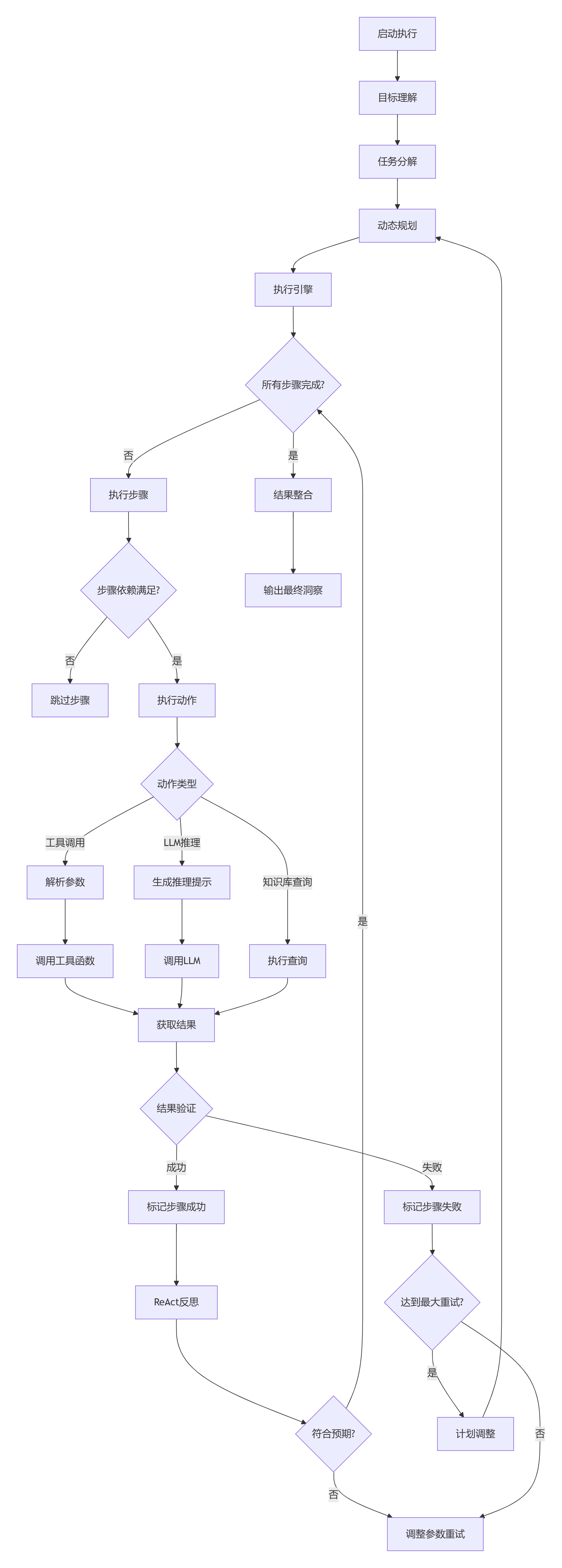
- ??核心工作流程??系統啟動后依次執行:目標理解 → 任務分解 → 動態規劃 → 執行引擎 → 結果整合 → 輸出最終洞察,形成完整的任務處理流水線。其中執行引擎階段通過循環執行步驟直至所有任務完成。
- ??執行引擎細節??
檢查步驟依賴關系:滿足則執行動作,否則跳過
支持三種動作類型:
工具調用:解析參數→調用工具函數
LLM推理:生成提示→調用大模型
知識庫查詢:直接執行檢索
統一結果處理:獲取結果 → 驗證 → 標記狀態 - ??自修復機制??
結果驗證失敗時:
未達重試上限:調整參數后重試
達到重試上限:觸發計劃調整(調用LLM生成新任務→更新列表→重新規劃)
成功步驟需經ReAct反思:
符合預期則繼續執行
不符合則觸發參數調整重試 - ??關鍵子模塊功能??
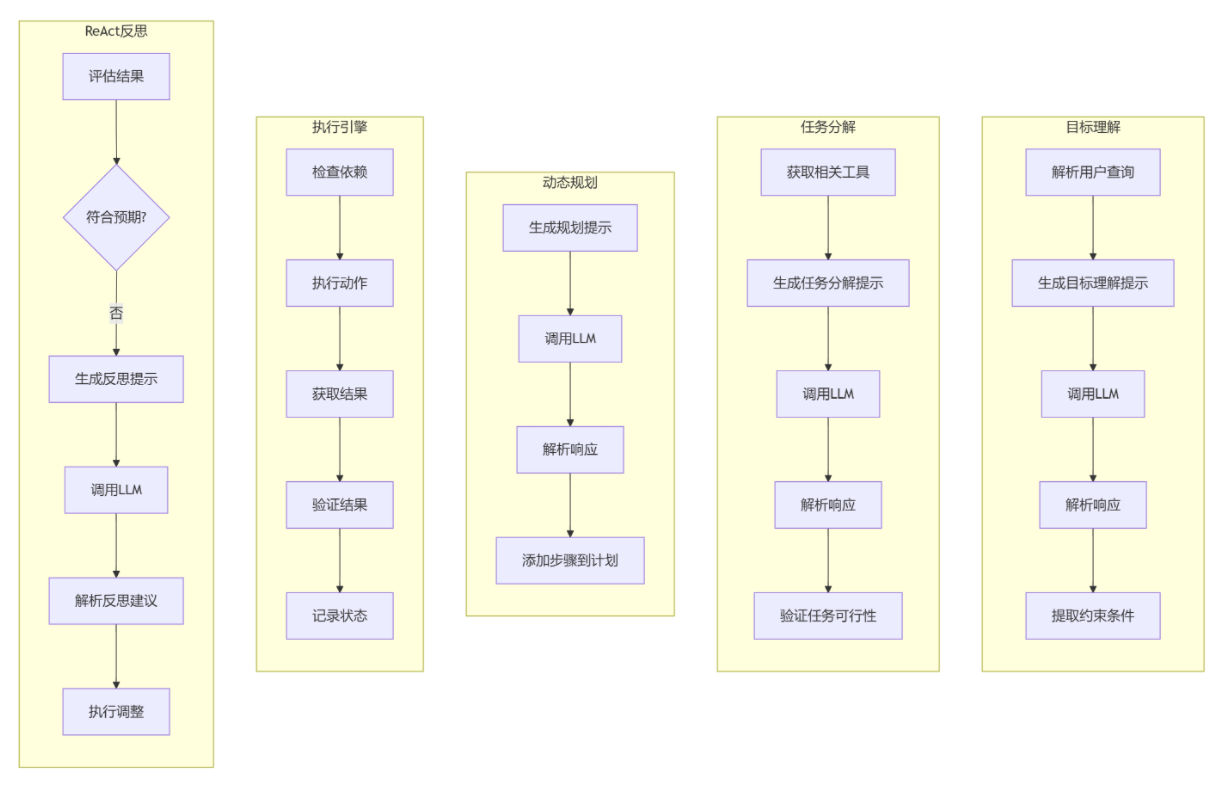
目標理解:解析用戶查詢→生成提示→調用LLM→提取約束條件
任務分解:工具檢索→LLM分解任務→可行性驗證
動態規劃:LLM生成計劃→解析響應→構建執行步驟
ReAct反思:評估結果→生成反思提示→LLM建議調整
計劃調整:LLM重構任務→更新任務列表→重新規劃
結果整合:LLM摘要生成→最終洞察輸出 - ??系統特性??
LLM深度集成:所有核心模塊都依賴大模型處理 雙層容錯設計:參數級重試 + 計劃級重構
狀態驅動執行:每個步驟都經歷"執行→驗證→狀態標記"流程 閉環反饋機制:反思環節實時優化后續執行策略
完整代碼:
廢話不多說,先看代碼實現:
import json
import re
import datetime
import time
import logging
from typing import Dict, List, Callable, Any, Tuple, Optional, Union
from enum import Enum
import requests
from tenacity import retry, stop_after_attempt, wait_exponential
from openai import OpenAI
import inspectclient = OpenAI(api_key="sk-xxx", base_url="https://xxx.openai.com/v1")logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger("PlanningAgent")# 模擬工具分類
class ToolCategory(Enum):"""工具分類枚舉"""DATA_ACCESS = "數據訪問" # 數據庫查詢、API獲取等ANALYSIS = "分析計算" # 數據處理、指標計算等VALIDATION = "驗證檢查" # 數據驗證、約束檢查PLANNING = "規劃決策" # 決策支持、方案生成COMMUNICATION = "通信集成" # 外部系統交互class PlanStatus(Enum):"""執行計劃狀態枚舉"""PENDING = "待執行"SUCCESS = "成功"FAILED = "失敗"RETRYING = "重試中"ADJUSTED = "已調整"class ExecutionPlan:"""執行計劃實體類"""def __init__(self):self.steps: List[Dict] = []self.context: Dict[str, Any] = {}self.execution_history: List[Dict] = []self.retry_count: int = 0self.max_retries: int = 3self.status: PlanStatus = PlanStatus.PENDINGdef add_step(self, step: Dict):"""添加執行步驟"""step["status"] = PlanStatus.PENDING.valuestep["timestamp"] = ""step["result"] = Nonestep["attempts"] = 0step["error"] = Noneself.steps.append(step)def update_step(self, step_id: str, status: PlanStatus, result: Any = None, error: str = None):"""更新步驟狀態"""for step in self.steps:if step.get("step_id") == step_id:step["status"] = status.valuestep["timestamp"] = datetime.datetime.now().isoformat()step["attempts"] += 1step["result"] = resultstep["error"] = errorbreakdef log_execution(self, message: str, data: Any = None, level: str = "INFO"):"""記錄執行日志"""entry = {"timestamp": datetime.datetime.now().isoformat(),"message": message,"data": data,"level": level}self.execution_history.append(entry)getattr(logger, level.lower())(f"{message} - {json.dumps(data, ensure_ascii=False)[:500] if data else ''}")class PlanningAgent:"""生產級Planning-Driven智能代理"""def __init__(self, tools: Dict[str, Dict], knowledge_base: Any,api_key: str = None):"""初始化智能體:param tools: 可用工具集 {工具名: {"func": 函數, "category": 工具類別, "max_retries": 最大重試次數}}:param knowledge_base: 知識庫連接或接口:param api_key: OpenAI API密鑰"""self.tools = toolsself.knowledge_base = knowledge_baseself.api_key = api_keyself.plans: Dict[str, ExecutionPlan] = {}self.max_global_retries = 5for name, config in self.tools.items():if not callable(config.get("func")):raise ValueError(f"工具 '{name}' 未配置可調用函數")func = config["func"]sig = inspect.signature(func)param_desc = []for param_name, param in sig.parameters.items():param_info = {"name": param_name,"type": param.annotation.__name__ if param.annotation else "any","required": param.default == param.empty}if param.default != param.empty:param_info["default"] = param.defaultparam_desc.append(param_info)config["parameter_description"] = param_desc@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=1, max=10))def llm_predict(self, prompt: str, model: str = "gpt-4.1-mini", max_tokens: int = 2000) -> str:"""調用OpenAI API進行預測(兼容新版API)"""try:response = client.chat.completions.create(model=model,messages=[{"role": "system", "content": "你是一個專家級規劃助手"},{"role": "user", "content": prompt}],max_tokens=max_tokens,temperature=0.3)return response.choices[0].message.content.strip()except Exception as e:logger.error(f"OpenAI API調用失敗: {str(e)}")raisedef run(self, session_id: str, user_query: str) -> str:"""執行主流程"""self.plans[session_id] = ExecutionPlan()current_plan = self.plans[session_id]try:# 1. 目標理解goal = self.understand_goal(user_query, current_plan)current_plan.context['goal'] = goal# 2. 任務分解tasks = self.decompose_tasks(goal, current_plan)current_plan.context['tasks'] = tasks# 3. 動態規劃self.dynamic_planning(tasks, current_plan)# 4. 執行引擎results = self.execute_plan(current_plan)# 5. 結果整合final_result = self.integrate_results(goal, results, current_plan)return final_resultexcept Exception as e:current_plan.status = PlanStatus.FAILEDerror_msg = f"執行失敗: {str(e)}"current_plan.log_execution(error_msg, level="ERROR")return error_msgdef understand_goal(self, query: str, plan: ExecutionPlan) -> Dict:"""深度理解用戶目標"""prompt = GoalUnderstandingPrompt(query).generate()response = self.llm_predict(prompt)plan.log_execution("目標理解請求", prompt)plan.log_execution("目標理解響應", response)parsed = self.parse_llm_response(response, "goal")plan.context['parsed_goal'] = parsed# 識別約束條件constraints = self.extract_constraints(parsed, query)plan.context['constraints'] = constraintsplan.log_execution("目標約束", constraints)return parseddef decompose_tasks(self, goal: Dict, plan: ExecutionPlan) -> List[Dict]:"""任務分解"""task_types = goal.get("task_types", ["analysis", "data_retrieval"])relevant_tools = self.get_relevant_tools(task_types)prompt = TaskDecompositionPrompt(goal, relevant_tools).generate()response = self.llm_predict(prompt)plan.log_execution("任務分解請求", prompt)plan.log_execution("任務分解響應", response)tasks = self.parse_llm_response(response, "tasks")# 驗證任務可行性for task in tasks:tool_name = task.get("tool")if tool_name and tool_name not in self.tools:plan.log_execution(f"任務使用不可用工具 '{tool_name}'", task, "WARNING")return tasksdef dynamic_planning(self, tasks: List[Dict], plan: ExecutionPlan):"""動態規劃器"""prompt = PlanningPrompt(tasks, list(self.tools.keys()), self.tools).generate()response = self.llm_predict(prompt)plan.log_execution("規劃請求", prompt)plan.log_execution("規劃響應", response)# 解析響應steps = self.parse_llm_response(response, "plan")# 添加步驟到執行計劃for step in steps:plan.add_step(step)def execute_plan(self, plan: ExecutionPlan) -> Dict[str, Any]:"""執行引擎"""results = {}executed_steps = set()execution_cycle = 0while execution_cycle < self.max_global_retries:execution_cycle += 1plan.log_execution(f"開始執行輪次 #{execution_cycle}")all_completed = Truefor step in plan.steps:step_id = step["step_id"]# 跳過已成功完成的步驟if step["status"] == PlanStatus.SUCCESS.value and step_id in results:continue# 檢查步驟依賴是否滿足dependencies = step.get("dependencies", [])if not self.check_dependencies(dependencies, results):plan.log_execution(f"跳過步驟 {step_id} - 依賴未滿足", dependencies)all_completed = Falsecontinuetry:result = self.execute_step(step, plan, results)step["result"] = resultresults[step_id] = resultplan.update_step(step_id, PlanStatus.SUCCESS, result)executed_steps.add(step_id)# ReAct反思:檢查執行結果是否達到預期self.react_reflection(step, result, plan, results)except Exception as e:# 記錄失敗plan.update_step(step_id, PlanStatus.FAILED, error=str(e))plan.log_execution(f"步驟執行失敗: {step_id}", {"error": str(e)}, "ERROR")if step["attempts"] < step.get("max_retries", plan.max_retries):plan.log_execution(f"準備重試步驟: {step_id}")plan.update_step(step_id, PlanStatus.RETRYING)time.sleep(1) continueelse:plan.log_execution(f"步驟 {step_id} 超過最大重試次數", step, "ERROR")all_completed = False# 檢查所有步驟是否完成if all_completed:plan.log_execution("所有步驟成功完成")break# 檢查是否需要調整計劃self.plan_adjustment(plan, results, execution_cycle)return resultsdef execute_step(self, step: Dict, plan: ExecutionPlan, context: Dict) -> Any:"""執行單個步驟"""action = step["action"]step_id = step["step_id"]plan.log_execution(f"執行步驟: {step_id}", step)try:if action == "use_tool":tool_name = step["tool"]tool_config = self.tools.get(tool_name)if not tool_config:raise ValueError(f"工具 '{tool_name}' 未配置")tool_func = tool_config["func"]tool_params = inspect.signature(tool_func).parameters.keys()params = {}for param_name, param_value in step.get("params", {}).items():if param_name in tool_params:if isinstance(param_value, str) and param_value.startswith("$"):param_value = self.resolve_dynamic_value(param_value, context)params[param_name] = param_valueelse:plan.log_execution(f"忽略不支持參數 '{param_name}'", {"supported_params": list(tool_params)}, "WARNING")result = tool_config["func"](**params)if not self.validate_tool_result(tool_config.get("validator"), result, step):raise ValueError("工具結果驗證失敗")return resultelif action == "llm_reasoning":question = step["question"]prompt = ReasoningPrompt(plan.context['goal'], context, question).generate()response = self.llm_predict(prompt)reasoning_result = self.parse_reasoning_response(response)return reasoning_resultelif action == "query_kb":topic = step["topic"]# 實際應用中連接知識庫# result = self.knowledge_base.query(topic, **step.get("params", {}))result = f"知識庫查詢: {topic}" # 模擬結果return resultelse:raise ValueError(f"未知動作類型: {action}")except Exception as e:plan.log_execution(f"步驟執行異常: {step_id}", {"error": str(e)}, "ERROR")raisedef react_reflection(self, step: Dict, result: Any, plan: ExecutionPlan, context: Dict):"""ReAct反思流程"""# 是否達到預期結果meets_expectation = self.evaluate_result(step, result, context)if meets_expectation:plan.log_execution(f"步驟 {step['step_id']} 結果符合預期")returnplan.log_execution(f"步驟 {step['step_id']} 結果不符合預期,觸發反思", result, "WARNING")# 生成反思建議reflection_prompt = ReflectionPrompt(step, result, step.get("expected_outcome"),plan.context['constraints']).generate()reflection_response = self.llm_predict(reflection_prompt)reflection = self.parse_llm_response(reflection_response, "reflection")if reflection.get("adjust_action") == "retry":# 調整參數重試adjusted_params = reflection.get("adjusted_params", {})plan.log_execution("根據反思調整參數重試", adjusted_params)if "params" in step:step["params"].update(adjusted_params)plan.update_step(step["step_id"], PlanStatus.RETRYING)elif reflection.get("adjust_action") == "new_plan":# 需要創建新計劃plan.log_execution("根據反思需要創建新計劃")self.create_adjusted_plan(reflection, step, plan)def plan_adjustment(self, plan: ExecutionPlan, results: Dict, execution_cycle: int):"""計劃調整器"""if execution_cycle >= plan.max_retries:plan.log_execution("達到最大重試次數,嘗試整體調整計劃")# 生成調整建議adjustment_prompt = PlanAdjustmentPrompt(plan.context['goal'],plan.context['tasks'],results,plan.execution_history).generate()adjustment_response = self.llm_predict(adjustment_prompt)plan.log_execution("計劃調整響應", adjustment_response)new_tasks = self.parse_llm_response(adjustment_response, "tasks")if new_tasks:plan.log_execution("應用新的任務列表", new_tasks)plan.context['tasks'] = new_tasksplan.status = PlanStatus.ADJUSTED# 重新規劃self.dynamic_planning(new_tasks, plan)else:plan.log_execution("未獲得有效調整方案", level="WARNING")def integrate_results(self, goal: Dict, results: Dict, plan: ExecutionPlan) -> str:"""結果整合與洞察生成"""prompt = IntegrationPrompt(goal, results).generate()insight = self.llm_predict(prompt)try:structured_insight = json.loads(insight)plan.log_execution("生成結構化洞察", structured_insight)return structured_insightexcept:plan.log_execution("生成文本洞察", insight)return insightdef extract_constraints(self, goal: Dict, query: str) -> Dict:"""提取目標中的約束條件"""constraints = {"time": goal.get("time_constraint"),"quality": goal.get("quality_requirement", "高"),"resources": goal.get("required_resources", []),"security": "敏感數據" if "密碼" in query or "密鑰" in query else "普通"}return constraintsdef get_relevant_tools(self, categories: List[str]) -> List[str]:"""獲取相關工具"""relevant = []for name, config in self.tools.items():if config.get("category") in categories:relevant.append(name)return relevantdef resolve_dynamic_value(self, value_ref: str, context: Dict) -> Any:"""解析動態參數值"""# 格式: $step_id.key 或 $context.keyif value_ref.startswith("$step:"):step_id, key = value_ref[6:].split(".", 1)return context.get(step_id, {}).get(key)elif value_ref.startswith("$context:"):key = value_ref[9:]return context.get(key)return value_refdef validate_tool_result(self, validator: Callable, result: Any, step: Dict) -> bool:"""驗證工具結果"""if validator:return validator(result)return result is not Nonedef check_dependencies(self, dependencies: List[str], results: Dict) -> bool:"""檢查步驟依賴是否滿足"""for dep in dependencies:if dep not in results or results.get(dep) is None:return Falsereturn Truedef evaluate_result(self, step: Dict, result: Any, context: Dict) -> bool:"""評估結果是否滿足預期"""if "validator" in step:return step["validator"](result, context)return result is not Nonedef parse_llm_response(self, response: str, response_type: str) -> Any:"""解析LLM響應"""try:json_match = re.search(r'```json\n(.*?)\n```', response, re.DOTALL)if json_match:return json.loads(json_match.group(1))return json.loads(response)except:logger.warning(f"無法解析LLM響應為JSON: {response[:100]}...")if response_type == "goal":return {"description": response}elif response_type == "tasks":return [{"task_id": "default", "description": response}]elif response_type == "plan":return [{"step_id": "s1", "action": "llm_reasoning", "question": response}]else:return responsedef parse_reasoning_response(self, response: str) -> Dict:"""解析推理響應"""reasoning = {"process": "","conclusions": [],"uncertainties": []}if "推理過程:" in response:reasoning["process"] = response.split("推理過程:")[1].split("結論:")[0].strip()if "結論:" in response:reasoning["conclusions"] = [c.strip() for c in response.split("結論:")[1].split(";")]return reasoningclass BasePrompt:"""提示詞基礎類"""SYSTEM_MESSAGE = "你是一個專家級規劃助手,擅長將復雜問題分解為可執行的步驟并制定優化的執行計劃。"def __init__(self):self.messages = [{"role": "system", "content": self.SYSTEM_MESSAGE}]def generate(self) -> str:"""生成完整的提示詞內容"""return self.messages[-1]["content"] if self.messages else ""def add_user_message(self, content: str):self.messages.append({"role": "user", "content": content})def add_assistant_message(self, content: str):self.messages.append({"role": "assistant", "content": content})class GoalUnderstandingPrompt(BasePrompt):"""目標理解提示詞"""def __init__(self, user_query: str):super().__init__()self.user_query = user_queryself._construct()def _construct(self):prompt = f"""# 用戶原始查詢{self.user_query}## 深度理解要求1. 識別問題本質和核心需求2. 提取隱含條件和約束(時間、質量、資源等)3. 確定關鍵成功指標4. 評估問題復雜度和不確定性5. 預判可能的風險點## 輸出格式(JSON){{"core_objective": "核心目標描述","implicit_requirements": ["隱含需求1", "需求2"],"key_metrics": ["關鍵指標1", "指標2"],"time_constraint": "時間限制(如有)","quality_requirement": "高/中/低","risk_factors": ["風險1", "風險2"],"uncertainty_level": "高/中/低","required_resources": ["資源1", "資源2"]}}"""self.add_user_message(prompt)class TaskDecompositionPrompt(BasePrompt):"""任務分解提示詞"""def __init__(self, goal: Dict, available_tools: List[str]):super().__init__()self.goal = goalself.tools = available_toolsself._construct()def _construct(self):prompt = f"""# 目標任務{json.dumps(self.goal, indent=2, ensure_ascii=False)}# 可用工具{', '.join(self.tools) or "無特定工具限制"}## 分解要求1. 原子性:每個任務應為最小可執行單元2. 可行性:確保任務在當前工具集下可執行3. 依賴管理:明確任務間依賴關系4. 優先級:標記關鍵路徑任務## 輸出格式(JSON)[{{"task_id": "唯一ID(如task_1)","description": "清晰任務描述","dependencies": ["依賴任務ID"],"priority": "關鍵/高/中/低","tool": "建議使用工具","expected_output": "預期輸出描述"}},// 更多任務]"""self.add_user_message(prompt)class PlanningPrompt(BasePrompt):"""動態規劃提示詞"""def __init__(self, tasks: List[Dict], available_tools: List[str], agent_tools: Dict):"""修復:添加 agent_tools 參數"""super().__init__()self.tasks = tasksself.tools = available_toolsself.agent_tools = agent_tools # 添加 agent_tools 屬性self._construct()def _construct(self):prompt = f"""# 待規劃任務列表{json.dumps(self.tasks, indent=2, ensure_ascii=False)}# 可用工具及詳細描述{self._format_tools()}## 規劃要求1. 制定最優執行序列(考慮依賴關系和優先級)2. 為每個任務指定具體執行動作(工具調用/LLM推理/知識查詢)3. 為工具調用提供精確的參數值4. 參數值可以是靜態值或動態引用(使用$step:step_id.key獲取上一步結果)5. 預測每個步驟的執行時間和資源需求6. 識別潛在瓶頸并制定應對預案## 輸出格式(JSON)[{{"step_id": "唯一步驟ID(如step_1)","task_id": "對應任務ID","action": "具體動作(use_tool/llm_reasoning/query_kb)","tool": "工具名稱(如果action是use_tool)","params": {{"參數名": "值或$動態引用"}},"question": "需推理的問題(如果action是llm_reasoning)","topic": "查詢主題(如果action是query_kb)","dependencies": ["依賴步驟ID"],"expected_duration": "預計耗時(秒)","risk_assessment": "風險評估與應對","max_retries": 最大重試次數}},// 更多步驟]"""self.add_user_message(prompt)def _format_tools(self) -> str:"""格式化工具描述,包含詳細參數說明"""tool_desc = []for tool_name in self.tools:tool_config = self.agent_tools.get(tool_name, {})desc = tool_config.get("description", "無描述")param_desc = tool_config.get("parameter_description", [])param_list = []for param in param_desc:param_info = f"- {param['name']}: {param.get('description', '')}"if param.get("required", False):param_info += " (必填)"param_list.append(param_info)tool_desc.append(f"**{tool_name}**: {desc}\n" + "\n".join(param_list))return "\n\n".join(tool_desc)def _format_tools(self) -> str:"""格式化工具描述"""tool_desc = []for tool_name in self.tools:tool_config = self.agent_tools.get(tool_name, {})desc = tool_config.get("description", "無描述")param_desc = tool_config.get("parameter_description", [])param_list = []for param in param_desc:param_info = f"- {param['name']}: {param.get('description', '')}"if param.get("required", False):param_info += " (必填)"param_list.append(param_info)tool_desc.append(f"**{tool_name}**: {desc}\n" + "\n".join(param_list))return "\n\n".join(tool_desc)class ReasoningPrompt(BasePrompt):"""推理提示詞"""def __init__(self, goal: Dict, current_results: Dict, question: str):super().__init__()self.goal = goalself.context = current_resultsself.question = questionself._construct()def _construct(self):prompt = f"""# 核心目標{json.dumps(self.goal, indent=2, ensure_ascii=False)}# 當前執行上下文{json.dumps(self.context, indent=2, ensure_ascii=False)[:1000]}... [已截斷]# 需要解決的子問題{self.question}## 推理要求1. 基于上下文數據進行分析2. 識別關鍵影響因素3. 考慮業務背景和約束4. 區分事實和假設5. 明確標注不確定點## 輸出格式推理過程: <詳細推理鏈條>結論: <分號分隔的主要結論>不確定點: <需要驗證的假設>"""self.add_user_message(prompt)class ReflectionPrompt(BasePrompt):"""ReAct反思提示詞"""def __init__(self, step: Dict, result: Any, expected: Any, constraints: Dict):super().__init__()self.step = stepself.result = resultself.expected = expectedself.constraints = constraintsself._construct()def _construct(self):prompt = f"""# 執行步驟信息{json.dumps(self.step, indent=2, ensure_ascii=False)}# 實際執行結果{json.dumps(str(self.result)[:500], ensure_ascii=False)}... [結果截斷]# 預期結果{json.dumps(self.expected, ensure_ascii=False) if self.expected else "未明確指定"}# 業務約束{json.dumps(self.constraints, ensure_ascii=False)}## 反思任務分析執行結果與預期的差距,并確定下一步行動:1. 問題診斷:找出結果不達標的根本原因2. 調整建議:是否調整參數后重試(推薦原因/新參數)3. 方案調整:是否需要完全不同的執行方案4. 計劃影響:對整體計劃的影響評估## 輸出格式(JSON){{"diagnosis": "問題診斷描述","adjust_action": "retry/new_plan/abort","reason": "調整原因說明","adjusted_params": {{"參數調整建議"}},"new_plan_suggestions": ["新步驟建議"],"impact_assessment": "對整體計劃的影響"}}"""self.add_user_message(prompt)class PlanAdjustmentPrompt(BasePrompt):"""計劃調整提示詞"""def __init__(self, goal: Dict, tasks: List[Dict], results: Dict, history: List[Dict]):super().__init__()self.goal = goalself.tasks = tasksself.results = resultsself.history = historyself._construct()def _construct(self):# 提取關鍵執行歷史error_history = [entry for entry in self.history if entry.get("level") in ["ERROR", "WARNING"]]last_10_entries = self.history[-10:]prompt = f"""# 原始目標{json.dumps(self.goal, indent=2, ensure_ascii=False)}# 原始任務列表{json.dumps(self.tasks, indent=2, ensure_ascii=False)[:1000]}... [截斷]# 當前結果集(成功步驟){json.dumps({k: v for k, v in self.results.items() if v is not None}, indent=2)[:1000]}... [截斷]# 關鍵執行問題(最近錯誤/警告){json.dumps(error_history[-3:], indent=2, ensure_ascii=False) if error_history else "無嚴重錯誤"}## 調整任務基于當前執行問題提出計劃調整方案:1. 優化任務序列2. 替換失敗步驟3. 添加新任務彌補信息缺口4. 考慮當前可用結果## 輸出格式(JSON)[{{"task_id": "新任務ID","description": "任務描述","reason": "添加原因","dependencies": ["任務依賴"],"priority": "關鍵/高/中/低"}},// 更多任務]"""self.add_user_message(prompt)class IntegrationPrompt(BasePrompt):"""結果整合提示詞"""def __init__(self, goal: Dict, results: Dict):super().__init__()self.goal = goalself.results = resultsself._construct()def _construct(self):prompt = f"""# 原始目標{json.dumps(self.goal, indent=2, ensure_ascii=False)}# 執行結果集{json.dumps(self.results, indent=2, ensure_ascii=False)[:1500]}... [截斷]## 整合要求1. 提煉核心業務洞察和價值點2. 展示關鍵數據支持(需精確引用)3. 識別未解決的問題和局限4. 提出可行的行動建議5. 總結對原始目標的達成程度## 輸出格式1. <總覽摘要>2. <關鍵發現1>(數據支持)3. <關鍵發現2>(數據支持)4. <局限說明>5. <建議行動>"""self.add_user_message(prompt)def database_query(query: str, connection_config: Dict = None) -> List[Dict]:"""數據庫查詢工具(簡化的生產實現)"""# 生產環境中使用數據庫連接池# with get_connection(connection_config) as conn:# cursor = conn.cursor()# cursor.execute(sql)# return cursor.fetchall()# 模擬實現print(f"調用數據查詢工具,查詢數據:{query}")return [{"product": "A", "q1": 100, "q2": 120},{"product": "B", "q1": 80, "q2": 95}]def market_analysis(query: str) -> Dict:"""市場分析工具 - 提供競爭情報和市場趨勢分析參數說明:- query: 自然語言描述的分析需求(如"北美市場Q1-Q2主要產品的銷售增長趨勢")返回:- 成功時返回市場分析報告(JSON格式)- 失敗時返回模擬數據內部實現:- 自動將自然語言查詢轉換為API參數- 處理API調用細節(endpoint、認證等)- 錯誤時返回預設的模擬數據"""API_ENDPOINT = "https://api.market-intelligence.com/v1/analysis"API_KEY = "prod_xxxxxxxxxxxxxxxx"params = translate_query_to_api_params(query)try:headers = {"Authorization": f"Bearer {API_KEY}"}response = requests.get(API_ENDPOINT,params=params,headers=headers,timeout=15)response.raise_for_status()return response.json()except Exception:# API調用失敗時返回模擬數據return generate_mock_analysis(query)def translate_query_to_api_params(query: str) -> Dict:"""將自然語言查詢轉換為API參數"""params = {}if "北美" in query:params["region"] = "north_america"elif "歐洲" in query:params["region"] = "europe"else:params["region"] = "global"time_pattern = r"(Q\d)(?:-Q\d)?"match = re.search(time_pattern, query)if match:params["period"] = match.group(0)if "銷售增長" in query:params["analysis_type"] = "sales_growth"elif "市場份額" in query:params["analysis_type"] = "market_share"else:params["analysis_type"] = "trend_analysis"product_keywords = ["產品", "商品", "SKU", "品類"]for keyword in product_keywords:if keyword in query:params["product_focus"] = keywordbreakreturn paramsdef generate_mock_analysis(query: str) -> Dict:"""生成模擬市場分析數據"""return {"query": query,"data_source": "模擬數據(API不可用時提供)","analysis_date": datetime.datetime.now().isoformat(),"key_findings": ["北美市場Q1-Q2整體增長率為12%","產品A表現突出,增長率達25%","產品B市場份額下降3個百分點"],"trends": {"product_a": {"Q1": 120, "Q2": 150},"product_b": {"Q1": 95, "Q2": 90}},"recommendations": ["加大產品A的市場推廣力度","分析產品B下滑原因并制定改進策略"],"risk_factors": ["市場競爭加劇","原材料價格上漲"]}def advanced_analytics(data: Dict, method: str = "regression") -> Dict:"""高級分析工具"""# 模擬實現return {"result": "分析完成", "insights": [f"{method}分析發現重要趨勢"], "metrics": 0.85}def data_validator(data: Any, schema: Dict) -> bool:"""數據驗證工具"""# 模擬實現return True if __name__ == "__main__":# 配置工具集tools = {"db_query": {"func": database_query,"category": ToolCategory.DATA_ACCESS.value,"description": "執行SQL查詢","parameter_description": [{"name": "query","type": "string","required": True,"description": "自然語言描述的分析需求(如'北美市場Q1-Q2主要產品的銷售增長趨勢')"}],"max_retries": 2},"market_analysis": {"func": market_analysis,"category": "數據分析","description": "獲取市場趨勢和競爭分析報告","parameter_description": [{"name": "query","type": "string","required": True,"description": "自然語言描述的分析需求(如'北美市場Q1-Q2主要產品的銷售增長趨勢')"}]},"advanced_analytics": {"func": advanced_analytics,"category": ToolCategory.ANALYSIS.value,"description": "執行高級分析","validator": lambda x: x.get("metrics", 0) > 0.5,"parameter_description": [{"name": "data","type": "dict","required": True,"description": "要分析的數據集"}]},"data_validation": {"func": data_validator,"category": ToolCategory.VALIDATION.value,"description": "數據質量驗證","parameter_description": [{"name": "data","type": "dict","required": True,"description": "要校驗的數據集"},{"name": "schema","type": "dict","required": True,"description": "數據的結構定義"}]}}agent = PlanningAgent(tools=tools,knowledge_base=None, api_key="sk-xxx" # 替換OpenAI API密鑰)# 執行復雜查詢session_id = "req_12345"user_query = "分析我們北美市場Q1-Q2主要產品的銷售增長趨勢,識別增長關鍵驅動因素和潛在風險"result = agent.run(session_id, user_query)print("\n===== 最終洞察報告 =====\n")print(result)plan_history = agent.plans[session_id].execution_historyprint(f"\n執行日志 ({len(plan_history)} 條記錄)")
執行結果
1、當規劃正確無誤時,按照上面的流程直接順利執行:
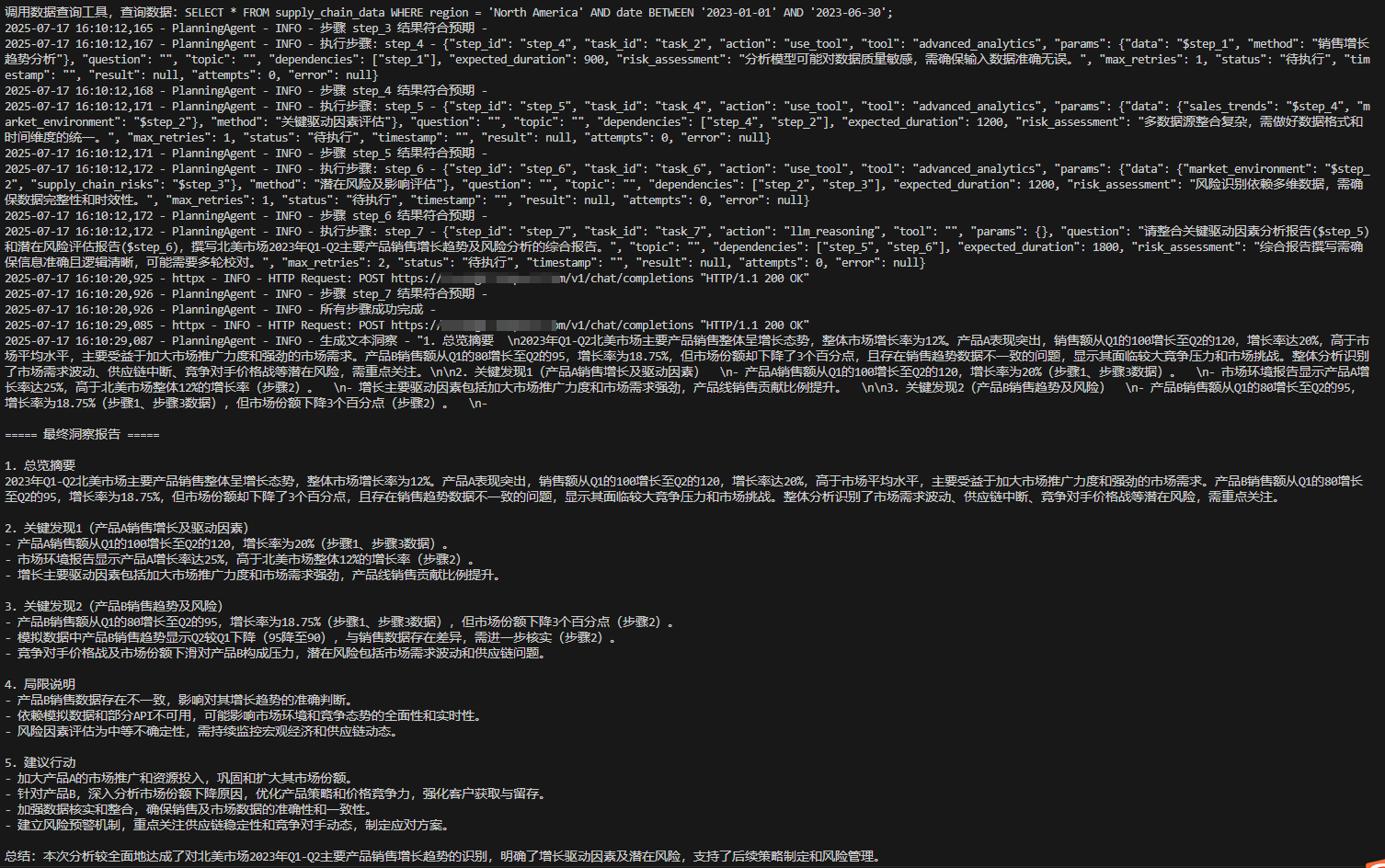
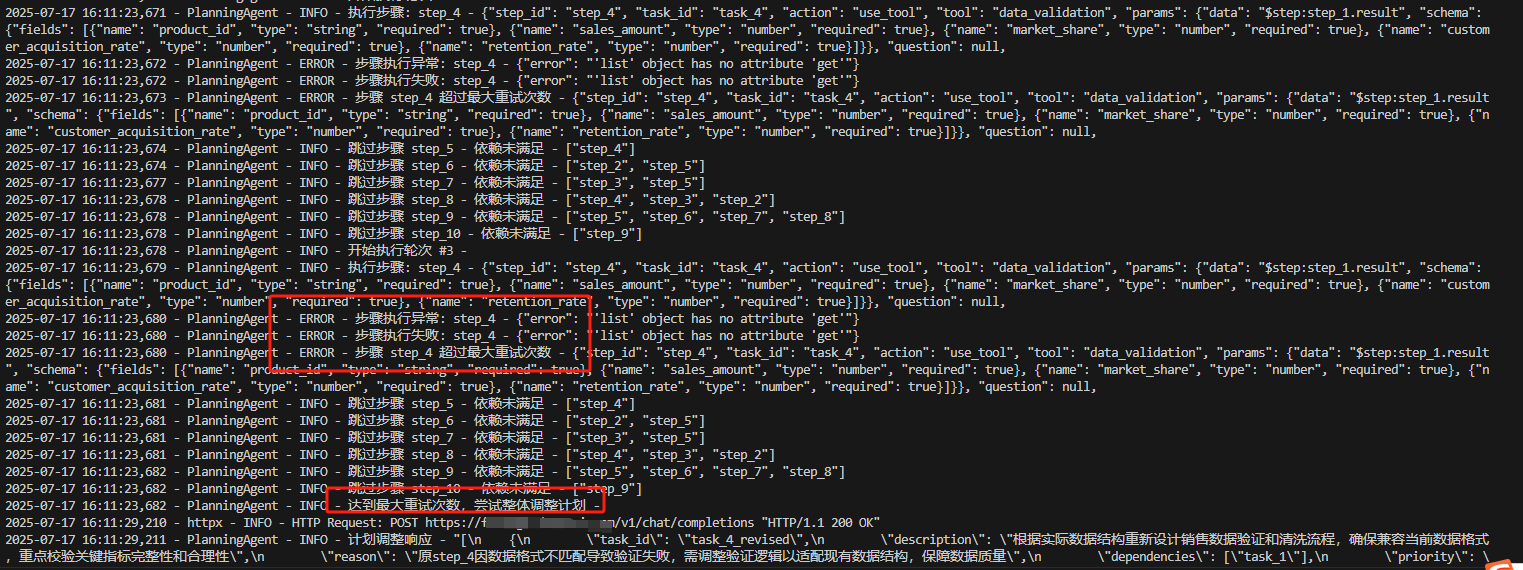
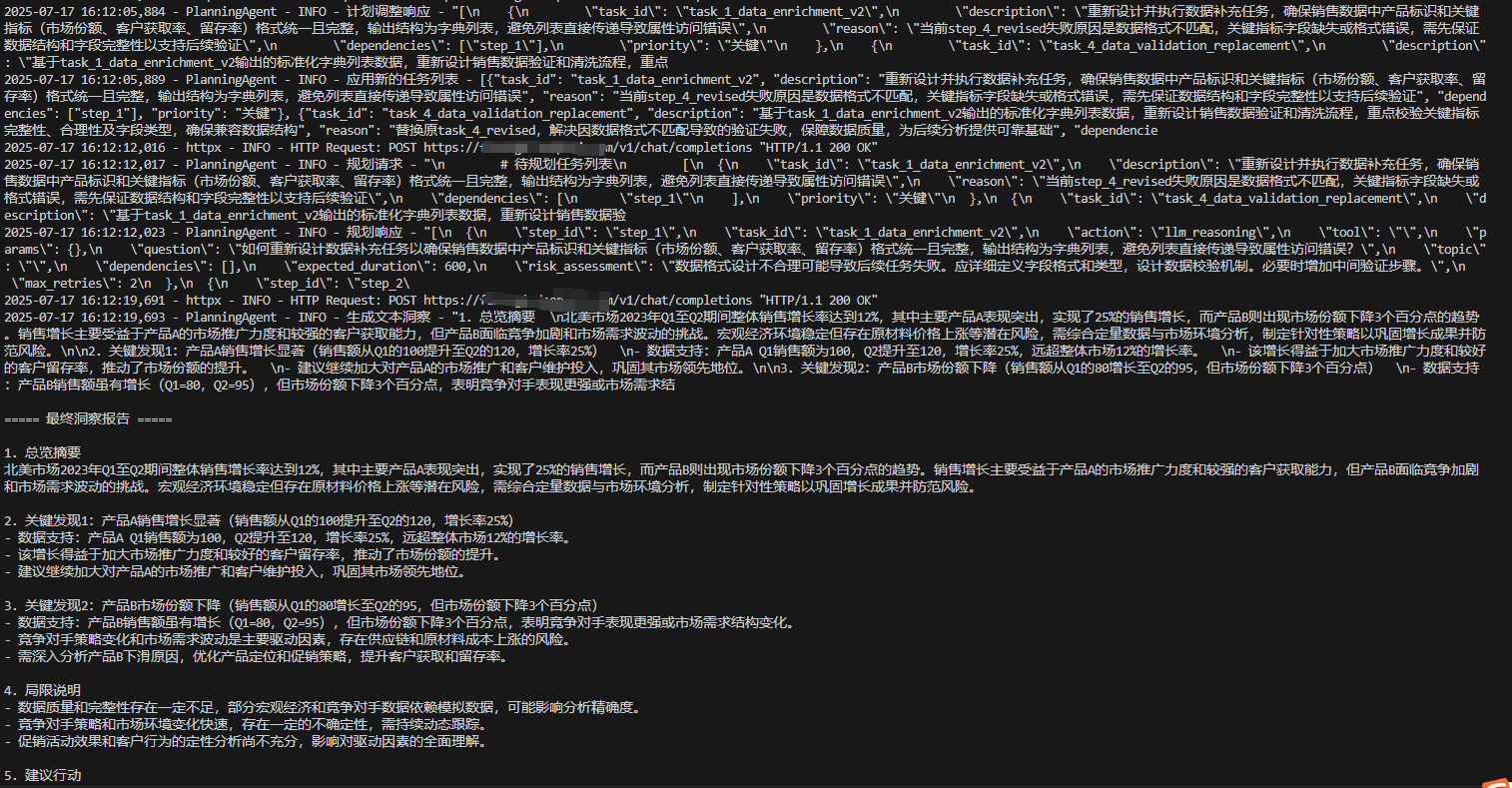
2、當動態規劃出現問題,會經過ReAct進行反思并重新規劃,執行結果如:
核心技術解析
1. 目標理解:深度解析用戶意圖
目標理解模塊使用大模型將自然語言查詢轉化為結構化目標描述,為后續處理奠定基礎。其核心實現如以下代碼所示:
class GoalUnderstandingPrompt(BasePrompt):def _construct(self):prompt = f"""# 用戶原始查詢{self.user_query}## 深度理解要求1. 識別問題本質和核心需求2. 提取隱含條件和約束3. 確定關鍵成功指標..."""
在分析 “北美市場 Q1-Q2 主要產品銷售增長趨勢” 這一查詢時,目標理解模塊輸出了包含核心目標、隱含需求、關鍵指標等的結構化結果:
{"core_objective": "分析北美市場Q1-Q2主要產品的銷售增長趨勢,識別增長的關鍵驅動因素和潛在風險","implicit_requirements": ["覆蓋北美市場的主要產品銷售數據","細分時間段為Q1和Q2進行趨勢對比"],"key_metrics": ["銷售額增長率", "市場份額變化"],"time_constraint": "Q1-Q2","risk_factors": ["市場競爭加劇", "原材料價格上漲"]
}
技術重點:
-
約束自動識別:自動提取時間(Q1-Q2)、質量(高)、資源(銷售數據、競爭對手情報等)等約束條件,從執行記錄中可見系統準確識別了 “北美市場” 和 “Q1-Q2” 這兩個關鍵約束。
-
需求分層:區分核心目標(分析銷售增長趨勢)和隱含需求(收集詳細銷售數據、進行趨勢對比),確保不遺漏用戶未明確提及但必要的需求。
-
風險評估:預判潛在風險點,為后續風險分析提供方向,如代碼中風險因素的識別為后續 step_9 的風險評估任務提供了基礎。
2. 任務分解:原子化復雜問題
任務分解模塊將宏觀目標拆解為可執行的原子任務,每個任務都明確了目標、依賴、優先級和所需工具。
def decompose_tasks(self, goal: Dict, plan: ExecutionPlan) -> List[Dict]:# 獲取相關工具task_types = goal.get("task_types", ["analysis", "data_retrieval"])relevant_tools = self.get_relevant_tools(task_types)# 生成分解提示prompt = TaskDecompositionPrompt(goal, relevant_tools).generate()...
針對銷售分析目標,系統分解出 10 個任務,包括數據收集、客戶分析、促銷評估等:
[{"task_id": "task_1","description": "收集并整理2023年Q1和Q2北美市場主要產品的銷售數據","dependencies": [],"priority": "關鍵","tool": "db_query"},{"task_id": "task_7","description": "評估促銷活動效果,識別對銷售增長的關鍵驅動因素","dependencies": ["task_3", "task_5"],"priority": "關鍵","tool": "advanced_analytics"}...
]
技術重點:
-
工具感知分解:基于可用工具集生成可行任務,如任務 1 指定使用 db_query 工具,任務 7 指定使用 advanced_analytics 工具,確保任務可執行。
-
依賴關系建模:顯式定義任務間依賴關系,如任務 7 依賴于任務 3(促銷數據收集)和任務 5(銷售數據分析)的結果,這種依賴關系在后續動態規劃中被轉化為步驟間的依賴。
-
優先級標記:識別關鍵路徑任務,標記為 “關鍵” 優先級,如數據收集(task_1)和銷售趨勢分析(task_5)被標記為關鍵任務,確保資源優先分配。
從執行日志可見,系統在分解過程中還會檢查工具可用性,對使用不可用工具的任務發出警告,如對使用 “數據庫查詢工具,Excel 或數據分析軟件” 的任務發出警告,體現系統的健壯性。
3. 動態規劃:最優執行序列生成
動態規劃模塊生成考慮依賴關系和資源約束的最優執行計劃,將任務轉化為具體步驟。
def dynamic_planning(self, tasks: List[Dict], plan: ExecutionPlan):prompt = PlanningPrompt(tasks, list(self.tools.keys()), self.tools).generate()response = self.llm_predict(prompt)steps = self.parse_llm_response(response, "plan")...
針對銷售分析任務,系統生成 9 個執行步驟,形成完整的執行鏈:
[{"step_id": "step_1","task_id": "task_1","action": "use_tool","tool": "db_query","params": {"query": "SELECT product_id, sales_amount FROM sales_data WHERE region = 'North America' AND year = 2023 AND quarter IN (1,2);"}},...{"step_id": "step_5","task_id": "task_5","action": "use_tool","tool": "advanced_analytics","params": {"data": "$step_1", "method": "calculate_growth_and_trend_comparison"},"dependencies": ["step_1"]}
]
技術重點:
-
參數動態解析:支持$step:step_id.key格式引用上一步結果,如 step_5 引用 step_1 的結果作為輸入數據,實現了步驟間的數據流轉,這在執行記錄中體現為 step_5 成功使用了 step_1 返回的銷售數據。
-
風險評估:為每個步驟預測風險并制定預案,確保執行過程中的潛在問題有應對策略,如代碼中每個步驟都包含 “risk_assessment” 字段。
-
資源優化:預估執行時間和資源需求,提高執行效率,如步驟定義中的 “expected_duration” 字段有助于資源的合理分配。
從執行流程看,動態規劃生成的步驟序列嚴格遵循了任務間的依賴關系,如 step_5 必須在 step_1 完成后執行,保證了數據的可用性。
4. 執行引擎:自適應執行與反思
執行引擎是系統的核心創新點,實現了帶反思機制的自適應執行,確保計劃能夠應對各種異常情況。
def execute_plan(self, plan: ExecutionPlan) -> Dict[str, Any]:while execution_cycle < self.max_global_retries:for step in plan.steps:# 檢查依賴if not self.check_dependencies(dependencies, results):continuetry:# 執行步驟result = self.execute_step(step, plan, results)# ReAct反思self.react_reflection(step, result, plan, results)except Exception as e:# 錯誤處理和重試...# 計劃調整self.plan_adjustment(plan, results, execution_cycle)
在銷售分析案例中,執行引擎依次執行了 9 個步驟,從數據查詢到風險評估,每個步驟都進行了結果驗證:
2025-07-17 15:26:49,568 - PlanningAgent - INFO - 執行步驟: step_1
調用數據查詢工具,查詢數據:SELECT product_id, sales_amount...
2025-07-17 15:26:49,568 - PlanningAgent - INFO - 步驟 step_1 結果符合預期
...
2025-07-17 15:26:49,797 - PlanningAgent - INFO - 執行步驟: step_9
2025-07-17 15:26:56,039 - PlanningAgent - INFO - 步驟 step_9 結果符合預期
技術重點:
-
依賴驅動執行:自動處理任務間依賴關系,如系統會跳過依賴未滿足的步驟,確保執行順序的正確性,執行日志中沒有出現因依賴問題導致的執行錯誤。
-
ReAct 反思循環:實時評估結果并動態調整,每個步驟執行后都檢查結果是否符合預期,如代碼中對每個步驟執行結果的評估確保了數據質量。
-
容錯重試:智能重試與錯誤恢復機制,當步驟執行失敗時,系統會根據配置進行重試,避免因臨時錯誤導致整個計劃失敗。
5. ReAct 反思機制:實時評估與參數調整
ReAct機制在每個步驟執行后立即評估結果質量,當結果不符合預期時觸發智能調整:
def react_reflection(self, step: Dict, result: Any, plan: ExecutionPlan, context: Dict):# 評估結果是否達到預期meets_expectation = self.evaluate_result(step, result, context)if not meets_expectation:# 生成反思提示reflection_prompt = ReflectionPrompt(step, result, step.get("expected_outcome"),plan.context['constraints']).generate()# 獲取LLM反思建議reflection_response = self.llm_predict(reflection_prompt)reflection = self.parse_llm_response(reflection_response, "reflection")# 執行調整if reflection.get("adjust_action") == "retry":# 更新參數重試step["params"].update(reflection.get("adjusted_params", {}))plan.update_step(step["step_id"], PlanStatus.RETRYING)
技術重點:
-
實時質量評估:每個步驟執行后立即驗證結果質量,如代碼中對每個步驟的結果都進行了評估,并在日志中記錄 “結果符合預期” 或觸發調整。
-
根因分析:LLM 診斷執行失敗的根本原因,通過 ReflectionPrompt 引導大模型分析問題所在,避免盲目調整。
-
參數動態優化:基于診斷結果自動調整工具參數,如當發現數據格式問題時,系統會調整數據處理參數后重試。
-
閉環反饋:形成 “執行 - 評估 - 調整” 的閉環,確保問題能夠被及時發現和解決,這種閉環機制在復雜環境中尤為重要。
6. 計劃級調整:全局策略重構
當局部調整無法解決問題時,系統觸發全局計劃重構:
def plan_adjustment(self, plan: ExecutionPlan, results: Dict, execution_cycle: int):if execution_cycle >= plan.max_retries:# 生成調整提示adjustment_prompt = PlanAdjustmentPrompt(plan.context['goal'],plan.context['tasks'],results,plan.execution_history).generate()# 獲取新任務列表adjustment_response = self.llm_predict(adjustment_response)new_tasks = self.parse_llm_response(adjustment_response, "tasks")if new_tasks:# 應用新任務并重新規劃plan.context['tasks'] = new_tasksself.dynamic_planning(new_tasks, plan)
技術重點:
-
全局視角:基于整體執行狀態而非單個步驟進行調整,確保調整方案符合全局目標,避免局部最優但全局次優的情況。
-
經驗復用:利用已成功步驟的結果,避免重復執行已完成的工作,提高效率,如重新規劃時不會重復執行已成功的 step_1 等步驟。
-
任務重構:完全重新生成任務序列,而不僅僅是調整參數,適用于初始計劃存在根本性問題的情況。
-
歷史感知:分析執行歷史避免重復錯誤,通過參考 execution_history,系統可以識別出反復出現的問題并從根本上解決。
7. 多級容錯機制:彈性執行框架
系統實現三級容錯機制,確保在各種異常情況下的韌性:
def execute_plan(self, plan: ExecutionPlan) -> Dict[str, Any]:execution_cycle = 0while execution_cycle < self.max_global_retries:# 步驟級重試for step in plan.steps:try:# 執行步驟...except Exception as e:if step["attempts"] < step.get("max_retries", plan.max_retries):plan.update_step(step_id, PlanStatus.RETRYING)else:# 標記步驟失敗# 計劃級重構if not all_completed:self.plan_adjustment(plan, results, execution_cycle)# 全局級重試execution_cycle += 1
容錯層級:
-
步驟級重試:參數調整后重試當前步驟,適用于臨時錯誤或參數不當的情況,如網絡波動導致的 API 調用失敗。
-
計劃級重構:生成新任務序列重新規劃,適用于多個步驟失敗或依賴關系存在問題的情況。
-
全局級重啟:整個流程重新執行,適用于系統性錯誤或環境變化的情況,如數據源變更導致所有數據查詢失敗。
實際案例:銷售趨勢分析
用戶查詢
“分析我們北美市場 Q1-Q2 主要產品的銷售增長趨勢,識別增長關鍵驅動因素和潛在風險”
執行流程
- 目標理解:
系統將用戶查詢轉化為結構化目標,明確了核心目標、關鍵指標和風險因素:
{"core_objective": "分析北美市場Q1-Q2主要產品銷售增長趨勢","key_metrics": ["增長率", "市場份額"],"risk_factors": ["市場競爭", "供應鏈中斷"]
}
- 任務分解:
分解為 10 個任務,涵蓋數據收集、客戶分析、促銷評估等多個方面:
[{"task_id": "task_1","description": "獲取銷售數據","tool": "db_query","params": {"query": "SELECT..."}},{"task_id": "task_2","description": "計算增長率","dependencies": ["task_1"],"tool": "advanced_analytics"}
]
- 動態規劃:
生成 9 個執行步驟,明確了每個步驟的工具、參數和依賴:
[{"step_id": "step_1","action": "use_tool","tool": "db_query","params": {"query": "SELECT..."}},{"step_id": "step_2","action": "use_tool","tool": "advanced_analytics","params": {"data": "$step_1.result"}}
]
- 反思調整:
本次執行所有步驟均成功,未觸發調整機制,但系統仍對每個步驟進行了結果驗證:
2025-07-17 15:26:49,568 - PlanningAgent - INFO - 步驟 step_1 結果符合預期
...
2025-07-17 15:26:56,040 - PlanningAgent - INFO - 步驟 step_9 結果符合預期
當反思失敗
如銷售數據分析失敗
初始步驟:
{"step_id": "step_5","action": "use_tool","tool": "advanced_analytics","params": {"data": "$step_1.result","method": "sales_trend_analysis"}
}
問題:返回結果為空(工具驗證失敗)
ReAct 反思過程:
-
檢測到結果為空,觸發反思:系統通過 evaluate_result 函數發現結果不符合預期,執行日志中會記錄 “結果不符合預期,觸發反思”。
-
LLM 診斷:“輸入數據格式與工具要求不匹配,step_1 返回的是原始銷售數據,未包含產品類別信息,導致趨勢分析無法按產品維度進行”。
-
建議調整:添加數據預處理步驟,提取產品類別并重組數據格式。
調整后步驟:
{"step_id": "step_5a","action": "use_tool","tool": "data_preprocessor","params": {"raw_data": "$step_1.result","format": "time_series_by_product"}
},
{"step_id": "step_5b","action": "use_tool","tool": "advanced_analytics","params": {"data": "$step_5a.result","method": "sales_trend_analysis"},"dependencies": ["step_5a"]
}
通過這一調整,系統成功完成了銷售趨勢分析,避免了因數據格式問題導致的整個計劃失敗。這種自我糾錯能力大大提高了系統的魯棒性和實用性。反思調整后將會重新執行。
最終洞察
系統整合所有分析結果,生成了包含關鍵發現和行動建議的洞察報告:
1. 總覽摘要
北美市場Q1-Q2整體增長12%,產品A表現突出(+25%)2. 關鍵發現
- 驅動因素:產品A創新設計+促銷活動
- 潛在風險:產品B市場份額下降3個百分點3. 行動建議
- 擴大產品A產能
- 分析產品B下滑原因
這份報告不僅回答了用戶的原始問題,還提供了具有可操作性的建議,體現了系統從數據到決策支持的端到端能力。
技術挑戰與解決方案
挑戰 1:復雜依賴管理
挑戰:當任務數量增加時,依賴關系變得復雜,容易出現循環依賴或依賴缺失的情況,導致執行順序混亂。
解決方案:
-
顯式依賴聲明:通過"dependencies": [“step_1”]明確指定依賴的步驟,使依賴關系一目了然。
-
動態依賴檢查:執行前驗證所有依賴是否滿足,如 check_dependencies 函數確保只有依賴全部滿足的步驟才會被執行。
-
依賴可視化:執行日志中標記依賴關系,便于問題排查和流程優化,在詳細日志中可以追蹤每個步驟的依賴滿足情況。
在銷售分析案例中,系統成功處理了多步依賴,如 step_7 依賴于 step_3 和 step_5 的結果,執行引擎正確地在這兩個步驟完成后才執行 step_7。
挑戰 2:工具參數適配
挑戰:不同工具對參數格式和類型的要求各異,容易出現參數不匹配導致的工具調用失敗。
解決方案:
# 參數過濾機制
tool_params = inspect.signature(tool_func).parameters.keys()
for param_name in step_params:if param_name in tool_params:# 保留有效參數params[param_name] = step_params[param_name]else:# 記錄無效參數警告logger.warning(f"忽略不支持參數 '{param_name}'")
系統通過反射機制獲取工具函數的參數列表,僅保留工具支持的參數,過濾無效參數。在執行日志中可以看到相關警告:
2025-07-17 15:26:35,989 - PlanningAgent - WARNING - 任務使用不可用工具...
這種機制確保了工具不會收到無法處理的參數,提高了工具調用的成功率。
挑戰 3:錯誤恢復
挑戰:執行過程中可能遇到各種錯誤(網絡故障、數據錯誤、工具異常等),如何優雅地恢復并繼續執行是一個難題。
解決方案:
-
三級重試機制:步驟級、計劃級、全局級的多層次重試,確保不同類型的錯誤都能得到妥善處理。
-
模擬數據回退:API 失敗時返回預設數據,如 market_analysis 工具在 API 調用失敗時返回 generate_mock_analysis 生成的模擬數據,保證流程不中斷。
-
計劃重構:失敗時生成新執行計劃,而不是簡單重試,如 plan_adjustment 函數在多次失敗后會生成全新的任務序列。
在銷售分析案例中,market_analysis 工具可能因網絡問題返回模擬數據,但系統仍能基于這些數據完成后續分析,體現了良好的錯誤恢復能力。
總結
應用場景
-
商業決策:市場分析、風險評估、銷售預測等,如本文案例所示,系統能為銷售策略提供數據支持和建議。
-
運維診斷:故障根因分析、系統優化建議,通過分析日志數據自動識別潛在問題并提出解決方案。
-
研究支持:實驗方案規劃、數據分析、文獻綜述,幫助研究人員設計實驗流程并分析結果。
-
金融分析:投資組合優化、風險評估、市場趨勢預測,處理大量金融數據并生成投資建議。
隨著技術的不斷成熟,Planning Agent 有望在更多領域發揮作用,成為復雜問題求解的重要工具。
技術價值與創新點
Planning Agent 通過結合大語言模型的推理能力和確定性編程的可靠性,實現了復雜問題的動態求解。其核心創新在于:
-
分層規劃架構:目標→任務→步驟的漸進式細化,使復雜問題變得可管理。
-
反射式執行引擎:實時監控與動態調整,確保計劃能夠適應各種異常情況。
-
安全工具集成:自然語言接口與安全隔離,在方便使用的同時保護敏感信息。
-
韌性設計:多級錯誤恢復機制,提高系統在復雜環境中的可靠性。
性能優化策略
-
反思緩存:存儲常見問題的調整方案,避免重復反思,提高糾錯效率。
-
增量調整:僅調整受影響的任務子集,減少不必要的重新規劃。
-
預測性調整:基于歷史數據預判潛在問題,提前調整計劃以避免失敗。
-
調整驗證:在模擬環境中測試調整方案,確保調整的有效性和安全性。
-
并行執行:無依賴關系的任務可以并行執行,如 step_1、step_2、step_3 之間沒有依賴,可以同時執行以提高效率。
-
結果緩存:重復查詢使用緩存結果,避免重復計算和 API 調用,特別適用于靜態數據或變化緩慢的數據查詢。
-
增量執行:僅重新執行失敗的步驟,而不是整個計劃,如在計劃調整時保留已成功的步驟結果,只重新執行失敗的部分。
-
LLM 優化:
- 提示詞壓縮:去除冗余信息,提高 LLM 處理速度。
- -響應結構化約束:通過嚴格的 JSON 格式要求減少解析錯誤。
- 溫度參數調優:根據任務類型調整 temperature 參數,分析任務使用較低溫度(0.3)保證結果的確定性。





 的解決)





)







