文章目錄
- 文章研究思路
- 創建了DeLiVER任意模態分割基準數據集
- 統計信息
- 4種模態
- 25個語義類
- 提出了任意跨模態分割模型CMNeXt
- 自查詢中心(Self-Query Hub,SQ-Hub)
- 并行池化混合器(Parallel Pooling Mixer,PPX)
- 實驗部分
paper:https://arxiv.org/pdf/2303.01480
Github:https://github.com/jamycheung/DELIVER
文章研究思路
多模態融合可以使語義分割更加魯棒。然而,融合任意數量的模態仍然是一個未充分探索的問題。為了深入研究這一問題,我們
1:創建了DeLiVER任意模態分割基準數據集,涵蓋了深度(Depth)、激光雷達(LiDAR)、多視角(Multiple Views)、事件(Events)和RGB模態。除此之外,我們還提供了四種惡劣天氣條件下的數據集,并包括五種傳感器故障情況,以利用模態間的互補性并解決部分故障問題。
2:提出了任意跨模態分割模型CMNeXt。該模型包含一個自查詢中心(Self-Query Hub,SQ-Hub),旨在從任意模態中提取有效信息,以便隨后與RGB表示進行融合,并且每增加一個模態僅增加極少的參數(約0.01M)。此外,為了高效且靈活地從輔助模態中獲取判別性線索,我們引入了簡單的并行池化混合器(Parallel Pooling Mixer,PPX)。通過在六個基準數據集上的大量實驗,我們的CMNeXt實現了最先進的性能,能夠在DeLiVER、KITTI-360、MFNet、NYU Depth V2、UrbanLF和MCubeS數據集上實現從1個模態到80個模態的擴展。在新收集的DeLiVER數據集上,四模態的CMNeXt在mIoU上達到了66.30%,相較于單模態基準提高了9.10%。
創建了DeLiVER任意模態分割基準數據集
統計信息

DeLiVER 多模式數據集包括 (a) 5種天氣情況(多云、有霧、夜間、下雨和晴天),含有4種不利條件;6種傳感器情況, 除了正常情況外,有5個傳感器故障情況 (MB:運動模糊、OE: 過度曝光、UE: 曝光不足、LJ: LiDAR-Jitter:LiDAR 抖動、和 EL:事件低分辨率),傳感器安裝在 Ego Car 上的不同位置提供多個視圖,包括前、后、左、右、上和下,因此 每個樣本有 6 個視圖,每個視圖都有4種模態(RGB、Depth、Lidar、Event)和2類標簽(semantic 和 instance)。(b) 是數據統計,共計 47,310 幀,大小為1042*1042 。其中 7,885 個前視圖樣本分為 3,983/2,005/1,897 分別用于訓練/驗證/測試。(c) 是 25 個語義類的數據分布。
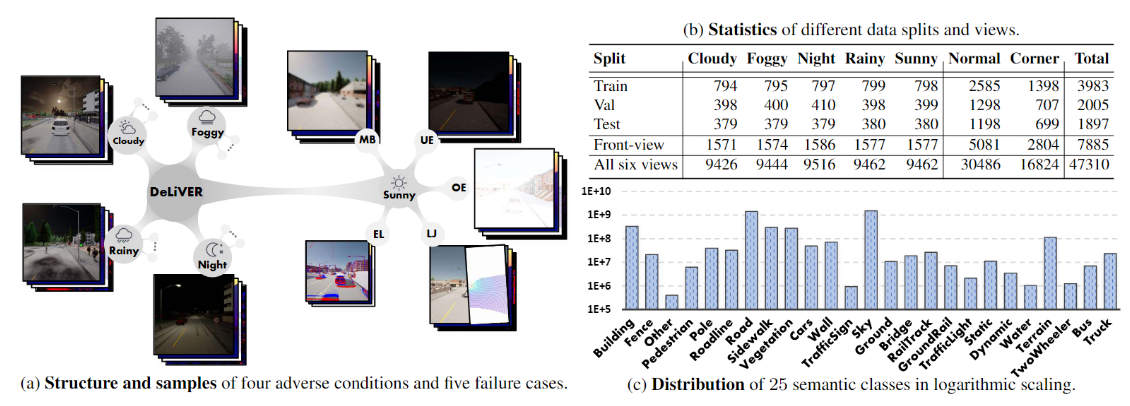
4種模態


25個語義類
Building - 建筑物、Fence - 圍欄、Other - 其他、Pedestrian - 行人、Pole - 桿、RoadLine - 路線、Road - 道路、SideWalk - 人行道、Vegetation - 植被、Cars - 汽車、Wall - 墻壁、TrafficSign - 交通標志、Sky - 天空、Ground - 地面、Bridge - 橋梁、RailTrack - 鐵路軌道、GroundRail - 地面鐵路、TrafficLight - 交通燈、Static - 靜態、Dynamic - 動態、Water - 水、Terrain - 地形、TwoWheeler - 兩輪車、Bus - 公共汽車、Truck - 卡車
提出了任意跨模態分割模型CMNeXt
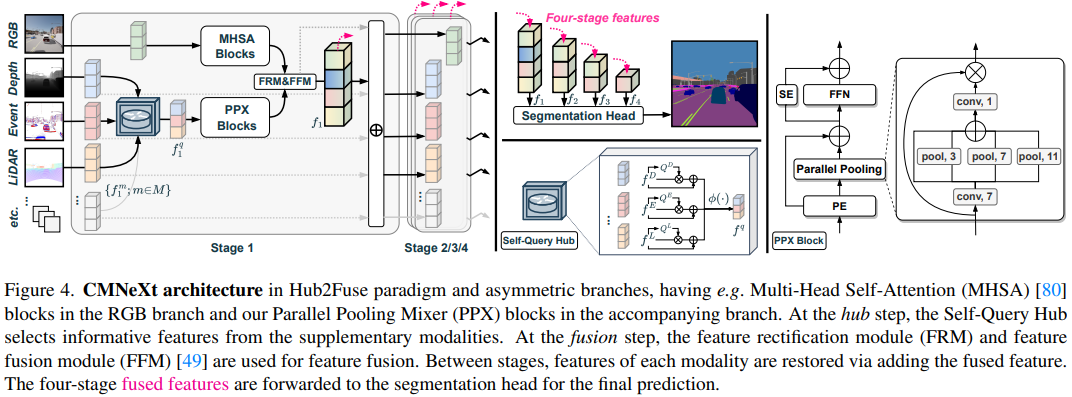
下圖為CMNeXt的整體架構圖,該模型是編碼器-解碼器(Encoder-Decoder)架構。其中,編碼器是一個雙分支和四階段的編碼器,雙分支分為RGB的主要分支和其他模態的次要分支,為了保持模態表示的一致性,Lidar、Event信息按照文章[ ISSAFE: Improving semantic segmentation in accidents by fusing event-based data.][Perception-aware multi sensor fusion for 3D LiDAR semantic segmentation]預處理為類似圖像的表示形式。backbone遵循大多數的CNN/Transformer結構,以用于提取多尺度的金字塔特征,四階段以下只詳細標注第一階段。采用Hub2Fuse范式和不對稱分支設計,RGB圖像通過多頭注意力(MHSA)逐步處理[來自SegFormer],其他M種模態圖像則通過本文提出的自查詢中心(Self-Query Hub)和并行池化混合器(PPX)進行處理:在Hub步驟中,Self-Query Hub從輔助模態中選擇出具有信息量的特征;在融合步驟中,特征修正模塊(FRM)和特征融合模塊(FFM)被用于特征融合[ CMX: Cross-modal fusion for RGB Xsemantic segmentation with transformers],各個階段之間,融合后的特征會通過add的方式疊加到每種模態的特征而后進入下一階段;經過四個階段后,會得到四階段特征,傳遞給MLP解碼器分割頭,進行預測。
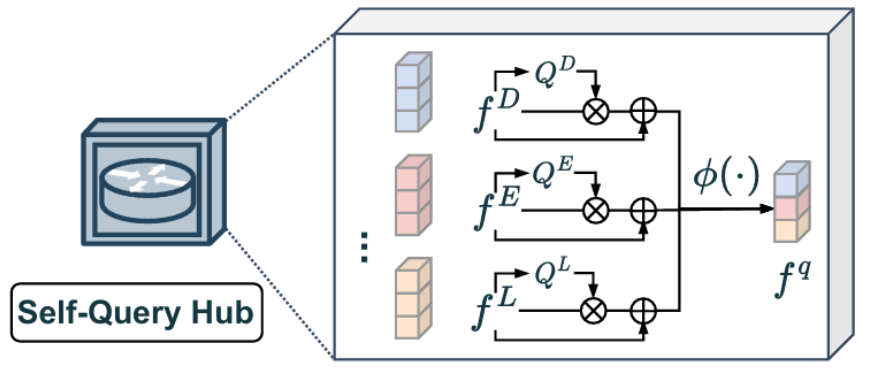
自查詢中心(Self-Query Hub,SQ-Hub)
為了執行任意模態融合,自查詢中心(SQ-Hub)是一個關鍵設計,用于在與 RGB 特征融合之前選擇補充模態的信息特征,簡單的理解就是用一個類自注意力機制的模塊將不同的模態信息進行融合輸出。隨后,該輸出特征經過PPX模塊進行進一步加工。
并行池化混合器(Parallel Pooling Mixer,PPX)
并行池化混合器作用是從上述 SQ-Hub 中的任意模態補充中高效靈活地獲取判別線索。結構如下所示,先是7*7的DW-conv,再通過3種不同核尺度的池化層,殘差連接; 最后通過FFN和SEnet的結構Squeeze-and-Excitation module 跨通道增強信息。
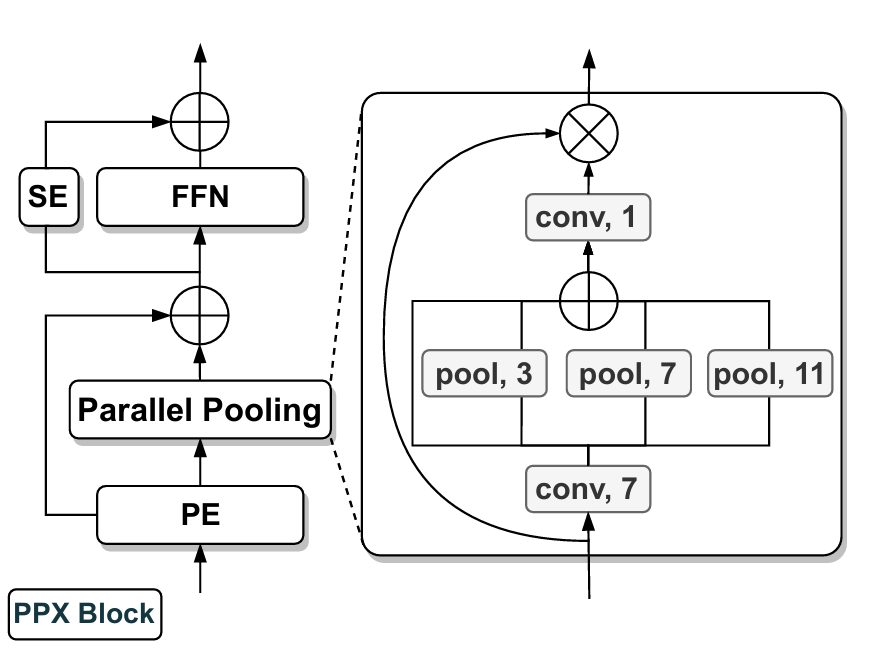
與基于卷積的MSCA [27]、基于池化的MetaFormer [86]、全注意力的FAN [99]相比,PPX包含兩項創新:
- (1) 在注意力部分使用并行池化層進行高效加權;
- (2) 在特征混合部分進行通道級增強。
PPX模塊的這兩項特點有助于分別在空間和通道維度上突出跨模態融合特征。
實驗部分
表 1 為 CMNeXt 與其它多模態融合領域的 SOTA 方法在六個多模態的分割數據集上的對比。實現結果表明,與HRFuser、TokenFusion以及CMX等眾多前向研究相比,所提方法無論是在任意單模態或多模態下均能發揮出色的分割性能,具備很強的魯棒性。
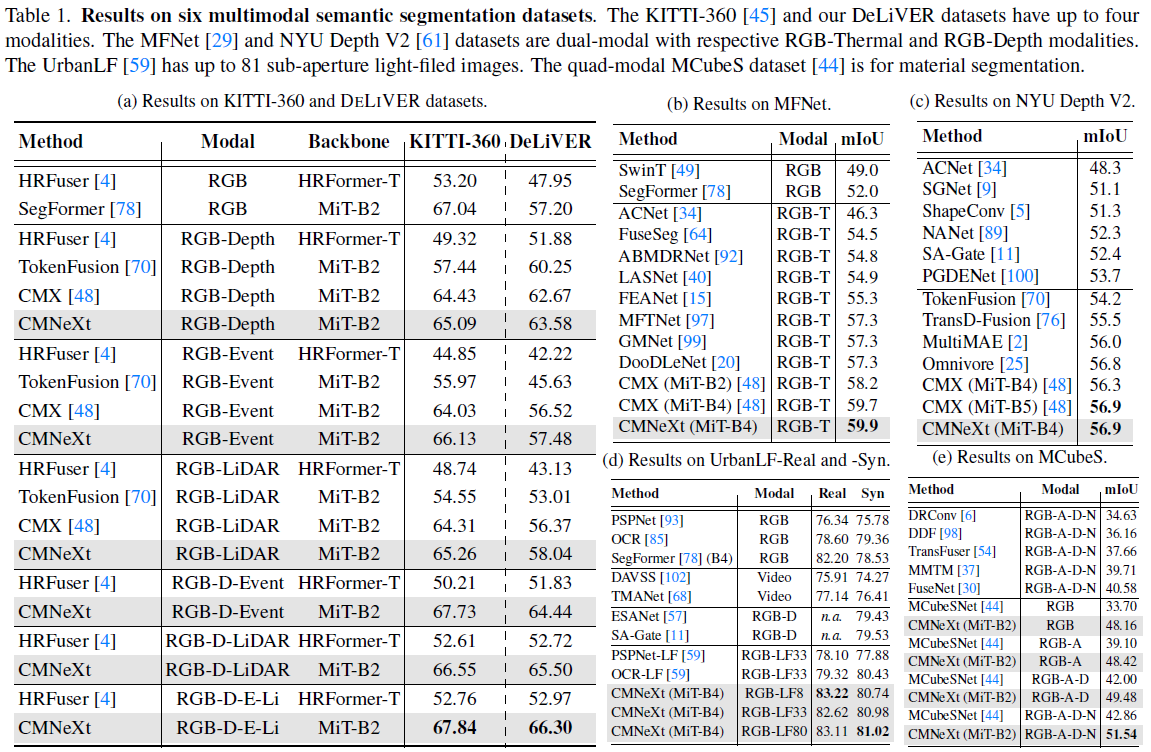
表 2 展示了 CMNeXt 與主流多模式融合范例在不同條件下的比較結果,包括惡劣天氣和部分傳感器故障場景。可以看出,先前的方法在兩大挑戰上均表現不加。受益于所提出的用于選擇有效特征的自查詢中心(SQ-Hub),方法顯著提高了整體的分割性能,平均提升了 9.1 個點。
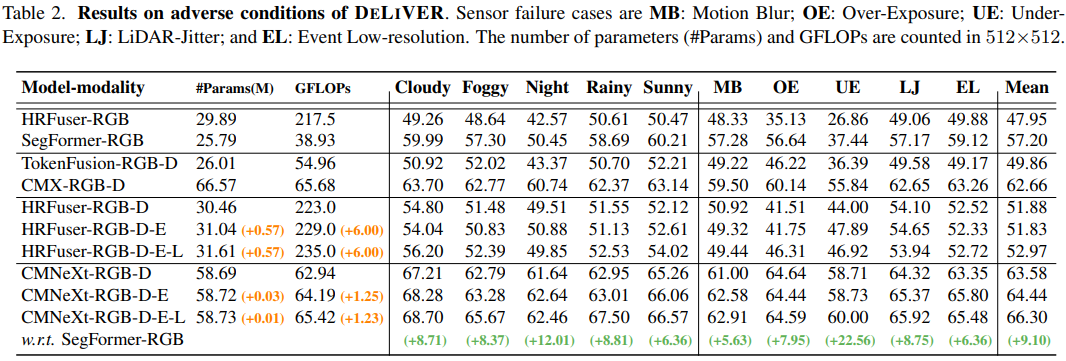
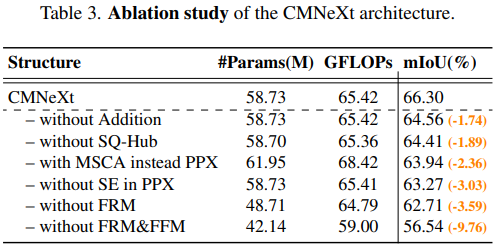
表 3 主要對本文所提的各個模塊進行消融實驗論證。
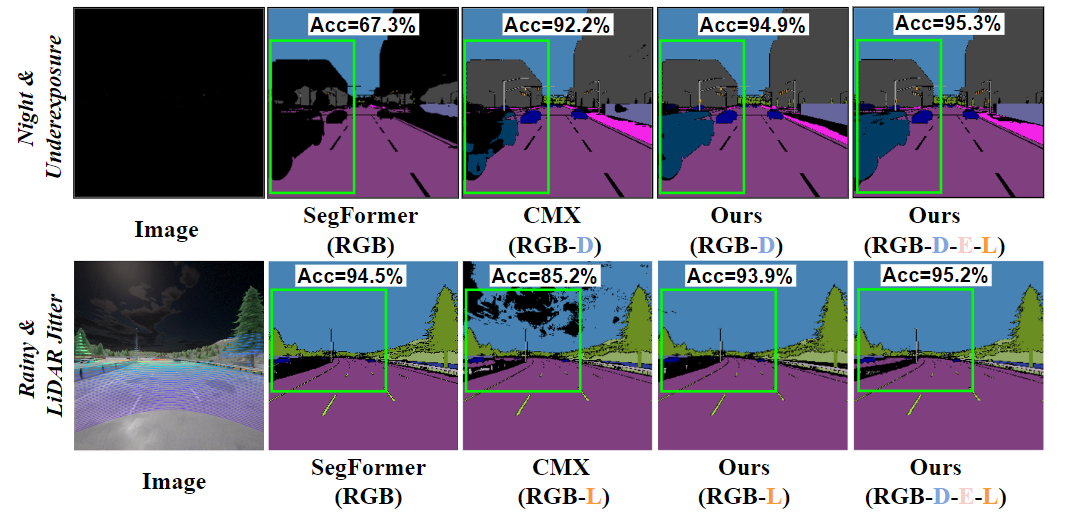
CMNeXt針對RGB-only SegFormer和RGB-X CMX的語義分割結果。可以看出,在曝光不足的黑夜中,僅 RGB 的 SegFormer 幾乎無法分割近處的車輛,而基于 RGB-D 深度估計的 CMNeXt 明顯優于SegFormer。另一方面,結合四種不同模態RGB-D-E-L的CMNeXt方法則進一步提高了性能并產生了更完整的分割效果。同時,在激光雷達抖動的部分傳感器故障場景中,CMX產生了不好的雨景解析結果;而本文所提方法幾乎不受傳感數據未對齊的影響,CMNeXt進一步加強了全場景分割的性能。










)

詳解)






)