第05篇:概率基礎——不確定性的數學
寫在前面:大家好,我是藍皮怪!前幾篇我們聊了統計學的基本概念、數據類型、描述性統計和數據可視化,今天我們要進入統計學的另一個重要基礎——概率論。你有沒有想過,為什么天氣預報說"明天下雨概率60%“?為什么醫生說"這個治療方案成功率80%”?為什么保險公司能預估各種風險?這些都離不開概率的計算。今天,我們就來聊聊這個看似神秘,實則無處不在的"不確定性數學"。
🎯 這篇文章你能學到什么
- 概率的基本概念、公理和計算方法
- 條件概率與獨立性的含義和應用
- 全概率公式與貝葉斯定理的實際應用
- 概率思維在生活中的應用與常見誤區
1. 從生活說起:為什么要學概率?
你有沒有遇到過這些場景:
🎲 玩游戲時:抽卡游戲中,“五星角色概率1.6%”,這意味著什么?
? 看天氣預報時:“明天下雨概率70%”,到底是70%的地方會下雨,還是下雨的可能性是70%?
🏥 就醫時:醫生說"這個檢查的假陽性率5%",如果你的檢查結果是陽性,你該有多擔心?
其實,概率已經滲透到我們生活的方方面面。它幫助我們在不確定的世界中做出更明智的決策,也是統計推斷的理論基礎。
2. 概率的核心概念與基礎理論
2.1 什么是概率?
概率是對事件發生可能性的度量,用0到1之間的數值表示。概率為0表示事件不可能發生,概率為1表示事件必然發生。
概率可以從兩個角度理解:
- 頻率派觀點:長期頻率。比如拋硬幣正面朝上的概率是0.5,意味著如果你拋很多次,大約一半的結果是正面。
- 貝葉斯觀點:主觀信念度。比如"明天下雨的概率是0.7",表示對這一事件的確信程度。
2.2 樣本空間與事件
- 樣本空間(S):實驗中所有可能結果的集合。例如,拋一枚硬幣的樣本空間是S={正面,反面}。
- 事件(E):樣本空間的子集,我們感興趣的結果集合。例如,拋骰子得到偶數的事件是E={2,4,6}。
2.3 概率的公理(基本規則)
概率論建立在三個基本公理之上:
- 非負性:對任何事件A,P(A) ≥ 0
- 規范性:樣本空間S的概率為1,即P(S) = 1
- 可加性:若事件A和B互斥(不能同時發生),則P(A∪B) = P(A) + P(B)
2.4 基本概率計算
對于等可能的結果(每個結果發生的可能性相同),概率計算公式為:
P ( A ) = 有利結果數 總結果數 P(A) = \frac{有利結果數}{總結果數} P(A)=總結果數有利結果數?
【例子與代碼】
(1)生活化例子:
從一副標準撲克牌(52張)中隨機抽一張牌,求抽到紅桃的概率。
- 有利結果數:13張紅桃牌
- 總結果數:52張牌
- 概率 = 13/52 = 1/4 = 0.25
(2)Python代碼實現:
# 計算從撲克牌中抽到紅桃的概率
favorable_outcomes = 13 # 紅桃牌數
total_outcomes = 52 # 總牌數
probability = favorable_outcomes / total_outcomes
print(f"抽到紅桃的概率: {probability}")
輸出:
抽到紅桃的概率: 0.25
3. 條件概率與獨立性
3.1 條件概率:已知部分信息后的概率
條件概率是指在事件B已經發生的條件下,事件A發生的概率,記作P(A|B)。
P ( A ∣ B ) = P ( A ∩ B ) P ( B ) P(A|B) = \frac{P(A \cap B)}{P(B)} P(A∣B)=P(B)P(A∩B)?
其中,P(A∩B)表示事件A和B同時發生的概率。
【例子與代碼】
(1)生活化例子:
某班級有60名學生,其中男生35名,女生25名。在這個班級中,喜歡數學的有30名學生,其中包括20名男生和10名女生。如果隨機選擇一名學生,已知這名學生是男生,求他喜歡數學的概率。
- 總學生數:60人
- 男生數:35人
- 喜歡數學的男生數:20人
- P(喜歡數學|男生) = 20/35 ≈ 0.571
(2)Python代碼實現:
# 條件概率計算
total_students = 60
male_students = 35
math_loving_males = 20# 已知是男生,求喜歡數學的概率
p_math_given_male = math_loving_males / male_students
print(f"已知是男生,喜歡數學的概率: {p_math_given_male}")
輸出:
已知是男生,喜歡數學的概率: 0.5714285714285714
3.2 獨立性:事件之間沒有影響
如果事件A的發生與事件B的發生互不影響,則稱事件A和B是獨立的。數學上,如果P(A|B) = P(A),或等價地,P(A∩B) = P(A)×P(B),則A和B獨立。
【例子與代碼】
(1)生活化例子:
連續拋兩次硬幣,第一次得到正面與第二次得到正面是否獨立?
- 第一次得到正面的概率:P(A) = 0.5
- 第二次得到正面的概率:P(B) = 0.5
- 兩次都得到正面的概率:P(A∩B) = 0.5 × 0.5 = 0.25
- 因為P(A∩B) = P(A)×P(B),所以這兩個事件是獨立的
(2)Python代碼實現:
# 檢驗事件獨立性
p_a = 0.5 # 第一次硬幣正面概率
p_b = 0.5 # 第二次硬幣正面概率
p_a_and_b = 0.25 # 兩次都是正面的概率# 檢驗是否獨立
is_independent = abs(p_a_and_b - p_a * p_b) < 1e-10
print(f"P(A∩B) = {p_a_and_b}, P(A)×P(B) = {p_a * p_b}")
print(f"這兩個事件是否獨立: {is_independent}")# 模擬硬幣投擲,驗證大數定律
import numpy as np
import matplotlib.pyplot as pltnp.random.seed(42)
n_trials = 1000 # 投擲次數
results = np.random.choice([0, 1], size=n_trials, p=[0.5, 0.5]) # 0表示反面,1表示正面
cumulative_mean = np.cumsum(results) / np.arange(1, n_trials + 1)# 繪制累積平均值隨試驗次數的變化
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falseplt.figure(figsize=(12, 7))
plt.plot(np.arange(1, n_trials + 1), cumulative_mean, 'b-', linewidth=2)
plt.axhline(y=0.5, color='r', linestyle='--', linewidth=2, label='理論概率 p=0.5')
plt.xscale('log')
plt.grid(True, alpha=0.3)
plt.title('硬幣投擲模擬: 累積平均值隨試驗次數的變化', fontsize=16)
plt.xlabel('投擲次數', fontsize=14)
plt.ylabel('正面朝上比例', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)# 添加文本說明
plt.text(10, 0.65, '隨著試驗次數增加,\n結果趨近于理論概率', fontsize=14, bbox=dict(facecolor='white', alpha=0.8))# 調整圖例位置和大小
plt.legend(loc='lower right', fontsize=12)# 調整圖表邊距
plt.tight_layout()
plt.show()
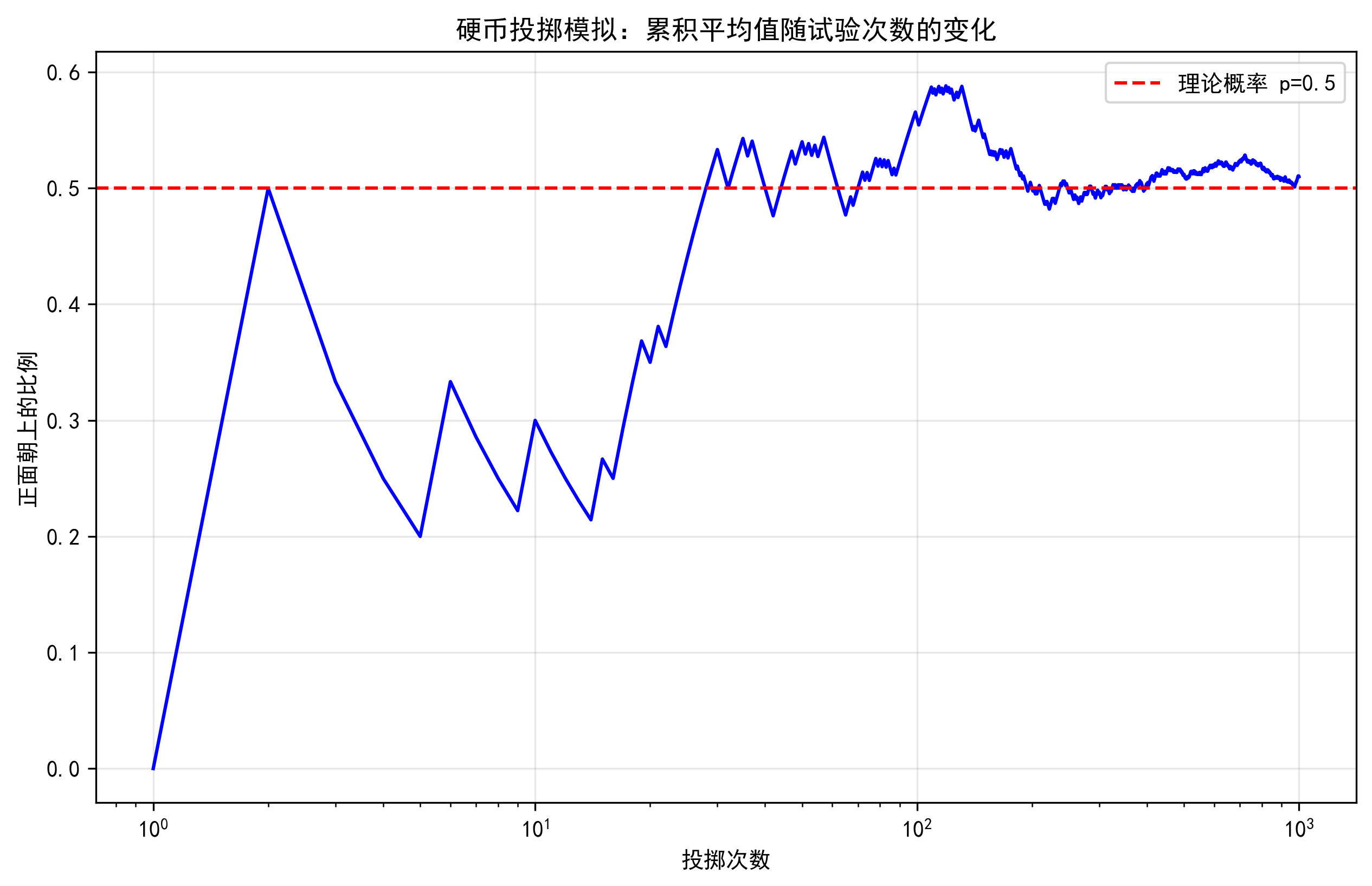
這個圖展示了投擲硬幣的累積平均結果如何隨著試驗次數的增加而趨近于理論概率0.5。圖中可以看到,在試驗次數較少時(如10次以內),結果可能與理論值有較大偏差;但隨著試驗次數增加到數百次后,結果穩定地接近理論值。這正是大數定律的直觀體現,也說明了為什么我們不能從少量觀察中得出可靠結論。
4. 全概率公式與貝葉斯定理
4.1 全概率公式:通過分割計算總概率
全概率公式用于計算事件A的概率,通過將樣本空間分割成互斥的事件B?, B?, …, B?,然后計算A在每個分割中的條件概率。
P ( A ) = ∑ i = 1 n P ( A ∣ B i ) × P ( B i ) P(A) = \sum_{i=1}^{n} P(A|B_i) \times P(B_i) P(A)=i=1∑n?P(A∣Bi?)×P(Bi?)
【例子與代碼】
(1)生活化例子:
某城市有三個區域,分別占總面積的50%、30%和20%。這三個區域下雨的概率分別為10%、20%和30%。求明天這個城市下雨的概率。
- 區域1:面積占比P(B?) = 0.5,下雨概率P(A|B?) = 0.1
- 區域2:面積占比P(B?) = 0.3,下雨概率P(A|B?) = 0.2
- 區域3:面積占比P(B?) = 0.2,下雨概率P(A|B?) = 0.3
- 全城下雨概率 = 0.5×0.1 + 0.3×0.2 + 0.2×0.3 = 0.05 + 0.06 + 0.06 = 0.17
(2)Python代碼實現:
# 全概率公式計算
area_proportions = [0.5, 0.3, 0.2] # 三個區域面積占比
rain_probabilities = [0.1, 0.2, 0.3] # 各區域下雨概率# 計算全城下雨概率
total_rain_probability = sum(p_area * p_rain for p_area, p_rain in zip(area_proportions, rain_probabilities))
print(f"全城下雨概率: {total_rain_probability}")
輸出:
全城下雨概率: 0.17
4.2 貝葉斯定理:逆向推理的利器
貝葉斯定理用于計算"逆向條件概率":已知結果,推測原因的概率。
P ( B ∣ A ) = P ( A ∣ B ) × P ( B ) P ( A ) P(B|A) = \frac{P(A|B) \times P(B)}{P(A)} P(B∣A)=P(A)P(A∣B)×P(B)?
其中,P(B|A)是已知A發生后B的概率,P(A|B)是已知B發生后A的概率,P(B)是B的先驗概率,P(A)是A的概率。
【例子與代碼】
(1)生活化例子:
某種疾病在人群中的發病率為0.1%。有一種檢測方法,對患病者的檢測準確率為99%(敏感性),對健康人的檢測準確率為98%(特異性)。如果某人檢測結果為陽性,他真正患病的概率是多少?
-
患病概率(先驗):P(D) = 0.001
-
健康概率:P(H) = 0.999
-
患病者檢測陽性概率:P(+|D) = 0.99
-
健康人檢測陽性概率:P(+|H) = 0.02(即1-特異性)
-
使用貝葉斯定理計算患病概率(后驗):
P ( D ∣ + ) = P ( + ∣ D ) × P ( D ) P ( + ∣ D ) × P ( D ) + P ( + ∣ H ) × P ( H ) P(D|+) = \frac{P(+|D) \times P(D)}{P(+|D) \times P(D) + P(+|H) \times P(H)} P(D∣+)=P(+∣D)×P(D)+P(+∣H)×P(H)P(+∣D)×P(D)?
P ( D ∣ + ) = 0.99 × 0.001 0.99 × 0.001 + 0.02 × 0.999 ≈ 0.047 P(D|+) = \frac{0.99 \times 0.001}{0.99 \times 0.001 + 0.02 \times 0.999} \approx 0.047 P(D∣+)=0.99×0.001+0.02×0.9990.99×0.001?≈0.047
(2)Python代碼實現:
# 貝葉斯定理計算
p_disease = 0.001 # 疾病先驗概率
p_positive_given_disease = 0.99 # 患病者檢測陽性概率
p_positive_given_healthy = 0.02 # 健康人檢測陽性概率
p_healthy = 1 - p_disease # 健康概率# 計算檢測陽性后患病概率
numerator = p_positive_given_disease * p_disease
denominator = p_positive_given_disease * p_disease + p_positive_given_healthy * p_healthy
p_disease_given_positive = numerator / denominatorprint(f"檢測結果陽性時,真正患病的概率: {p_disease_given_positive:.4f}")# 貝葉斯定理可視化
import numpy as np
import matplotlib.pyplot as plt# 創建一個總人數為10000的模擬人群
total_population = 10000
disease_population = int(total_population * p_disease) # 患病人數
healthy_population = total_population - disease_population # 健康人數# 計算檢測結果
true_positives = int(disease_population * p_positive_given_disease) # 患病且檢測陽性
false_negatives = disease_population - true_positives # 患病但檢測陰性
false_positives = int(healthy_population * p_positive_given_healthy) # 健康但檢測陽性
true_negatives = healthy_population - false_positives # 健康且檢測陰性# 檢測陽性總人數
positive_tests = true_positives + false_positives# 創建柱狀圖數據
groups = ['患病人群', '健康人群', '檢測陽性人群']
values = [disease_population, healthy_population, positive_tests]
subgroups = {'患病 (10人)': [disease_population, 0, 0],'健康 (9990人)': [0, healthy_population, 0],'檢測陽性 (208人)': [0, 0, positive_tests],'真陽性 (9人)': [0, 0, true_positives],'假陽性 (199人)': [0, 0, false_positives]
}# 繪制貝葉斯定理可視化圖
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falseplt.figure(figsize=(14, 8))
width = 0.5# 繪制主要人群
bottom = np.zeros(len(groups))
for label, height in subgroups.items():plt.bar(groups, height, width, label=label, bottom=bottom)bottom += height# 添加標題和標簽
plt.title('貝葉斯定理可視化: 檢測陽性時患病的概率', fontsize=16)
plt.ylabel('人數', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)# 調整文本位置和大小
plt.text(1.5, 7500, f"陽性預測值 = 真陽性/檢測陽性 = {true_positives}/{positive_tests} = {true_positives/positive_tests:.4f}", fontsize=14, bbox=dict(facecolor='white', alpha=0.8))# 調整圖例位置和大小
plt.legend(loc='upper right', bbox_to_anchor=(1.15, 1), fontsize=12)# 調整圖表邊距
plt.tight_layout()
plt.show()
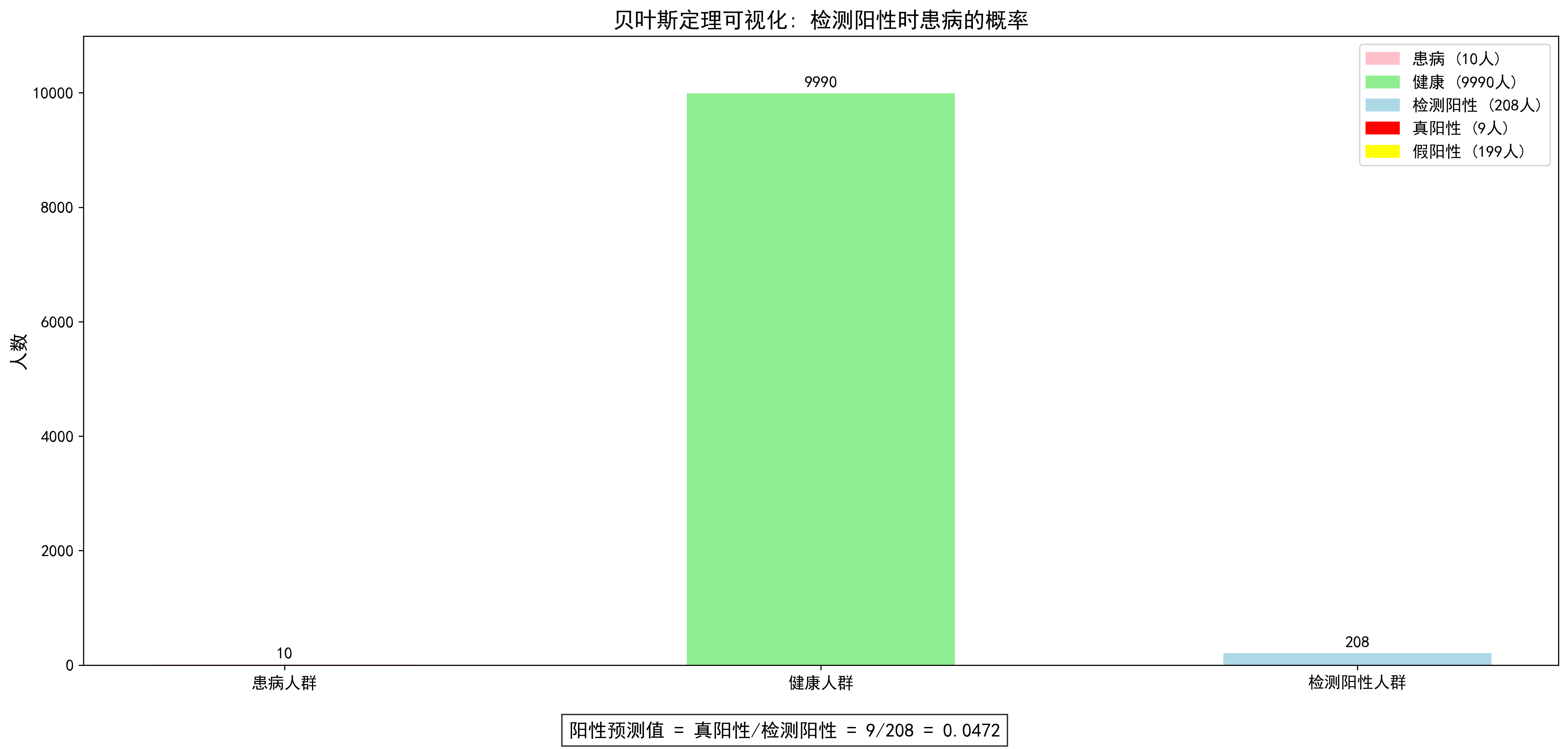
這個可視化圖展示了貝葉斯定理在醫學檢測中的應用。在一個10000人的假設人群中,只有10人患病(發病率0.1%),而檢測呈陽性的有208人。其中,真正患病且檢測陽性的僅有9人,占所有陽性結果的4.72%。這直觀地說明了為什么在罕見疾病的篩查中,即使是準確率很高的檢測,陽性結果的預測價值也可能很低。這就是所謂的"基礎概率謬誤",提醒我們在解讀檢測結果時必須考慮疾病的基礎發生率。
這個結果可能會讓人驚訝:即使檢測結果為陽性,真正患病的概率只有4.7%左右!這就是所謂的"基礎概率謬誤",我們會在后面的誤區部分詳細討論。
5. 概率分布:隨機變量的行為模式
5.1 隨機變量與概率分布
隨機變量是取決于隨機試驗結果的變量,可以是離散的(如骰子點數)或連續的(如身高)。概率分布描述了隨機變量可能取值的概率。
常見的離散概率分布:
- 伯努利分布:描述單次試驗成功或失敗的概率分布
- 二項分布:描述n次獨立重復試驗中成功次數的概率分布
- 泊松分布:描述單位時間內隨機事件發生次數的概率分布
常見的連續概率分布:
- 均勻分布:在給定區間內取值概率相等
- 正態分布:鐘形曲線,自然界中最常見的分布
- 指數分布:描述事件之間等待時間的概率分布
5.2 二項分布示例
二項分布描述了n次獨立重復試驗中,成功次數k的概率分布。其概率質量函數為:
P ( X = k ) = ( n k ) p k ( 1 ? p ) n ? k P(X=k) = \binom{n}{k} p^k (1-p)^{n-k} P(X=k)=(kn?)pk(1?p)n?k
其中,p是單次試驗成功的概率, ( n k ) \binom{n}{k} (kn?)是組合數。
【例子與代碼】
(1)生活化例子:
投籃命中率為40%的球員,投10次球,恰好命中4次的概率是多少?
- n = 10(投球次數)
- p = 0.4(單次命中概率)
- k = 4(命中次數)
- P ( X = 4 ) = ( 10 4 ) 0.4 4 ( 1 ? 0.4 ) 10 ? 4 ≈ 0.25 P(X=4) = \binom{10}{4} 0.4^4 (1-0.4)^{10-4}\approx 0.25 P(X=4)=(410?)0.44(1?0.4)10?4≈0.25
(2)Python代碼實現:
import numpy as np
from scipy import stats# 二項分布計算
n = 10 # 投球次數
p = 0.4 # 單次命中概率
k = 4 # 命中次數# 使用scipy計算二項分布概率
probability = stats.binom.pmf(k, n, p)
print(f"投10次球恰好命中4次的概率: {probability:.4f}")# 繪制二項分布概率質量函數
import matplotlib.pyplot as plt# 設置中文顯示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsex = np.arange(0, n+1)
pmf = stats.binom.pmf(x, n, p)plt.figure(figsize=(12, 7))
plt.bar(x, pmf, alpha=0.7, width=0.6)
plt.plot(x, pmf, 'ro-', alpha=0.7, markersize=8)
plt.title(f'二項分布 (n={n}, p={p})', fontsize=16)
plt.xlabel('成功次數', fontsize=14)
plt.ylabel('概率', fontsize=14)
plt.xticks(x, fontsize=12)
plt.yticks(fontsize=12)
plt.grid(alpha=0.3)# 標記最大概率點
max_prob_idx = np.argmax(pmf)
plt.text(max_prob_idx-0.5, pmf[max_prob_idx]+0.02, f"P(X={max_prob_idx})={pmf[max_prob_idx]:.4f}", fontsize=14, bbox=dict(facecolor='white', alpha=0.8))# 調整圖表邊距
plt.tight_layout()
plt.show()
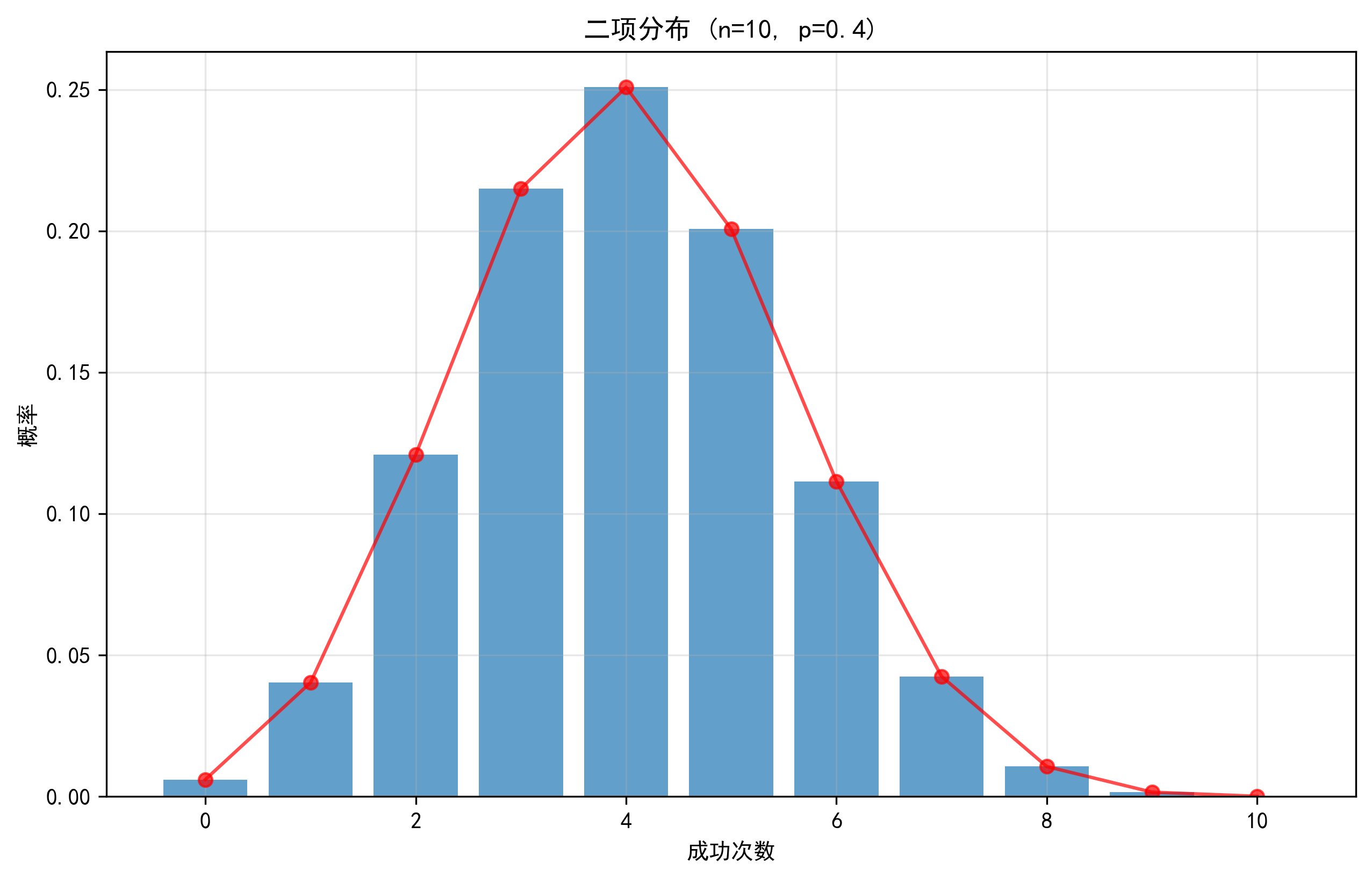
這個圖展示了投10次球,命中次數的概率分布。可以看到,命中4次的概率約為0.251,是最可能發生的情況。
5.3 正態分布示例
正態分布(也稱高斯分布)是連續型隨機變量最重要的分布之一,其概率密度函數為:
f ( x ) = 1 σ 2 π e ? ( x ? μ ) 2 2 σ 2 f(x) = \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}} f(x)=σ2π?1?e?2σ2(x?μ)2?
其中,μ是均值,σ是標準差。
【例子與代碼】
(1)生活化例子:
某城市成年男性身高服從正態分布,均值μ=175cm,標準差σ=6cm。求身高超過185cm的男性比例。
(2)Python代碼實現:
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt# 正態分布計算
mu = 175 # 均值
sigma = 6 # 標準差
x = 185 # 身高閾值# 計算超過185cm的比例
proportion = 1 - stats.norm.cdf(x, mu, sigma)
print(f"身高超過185cm的男性比例: {proportion:.4f}")# 繪制正態分布概率密度函數
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsex_range = np.linspace(mu - 4*sigma, mu + 4*sigma, 1000)
pdf = stats.norm.pdf(x_range, mu, sigma)plt.figure(figsize=(12, 7))
plt.plot(x_range, pdf, 'b-', linewidth=2)
plt.fill_between(x_range[x_range > 185], stats.norm.pdf(x_range[x_range > 185], mu, sigma), color='red', alpha=0.3)
plt.axvline(x=mu, color='green', linestyle='--', alpha=0.7, label=f'均值 μ={mu}')
plt.axvline(x=x, color='red', linestyle='--', alpha=0.7, label=f'閾值 x={x}')
plt.title(f'正態分布 (μ={mu}, σ={sigma})', fontsize=16)
plt.xlabel('身高 (cm)', fontsize=14)
plt.ylabel('概率密度', fontsize=14)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.grid(alpha=0.3)# 添加文本說明
plt.text(160, 0.055, f"超過185cm的比例: {proportion:.4%}", fontsize=14, bbox=dict(facecolor='white', alpha=0.8))# 調整圖例位置和大小
plt.legend(loc='upper right', fontsize=12)# 調整圖表邊距
plt.tight_layout()
plt.show()
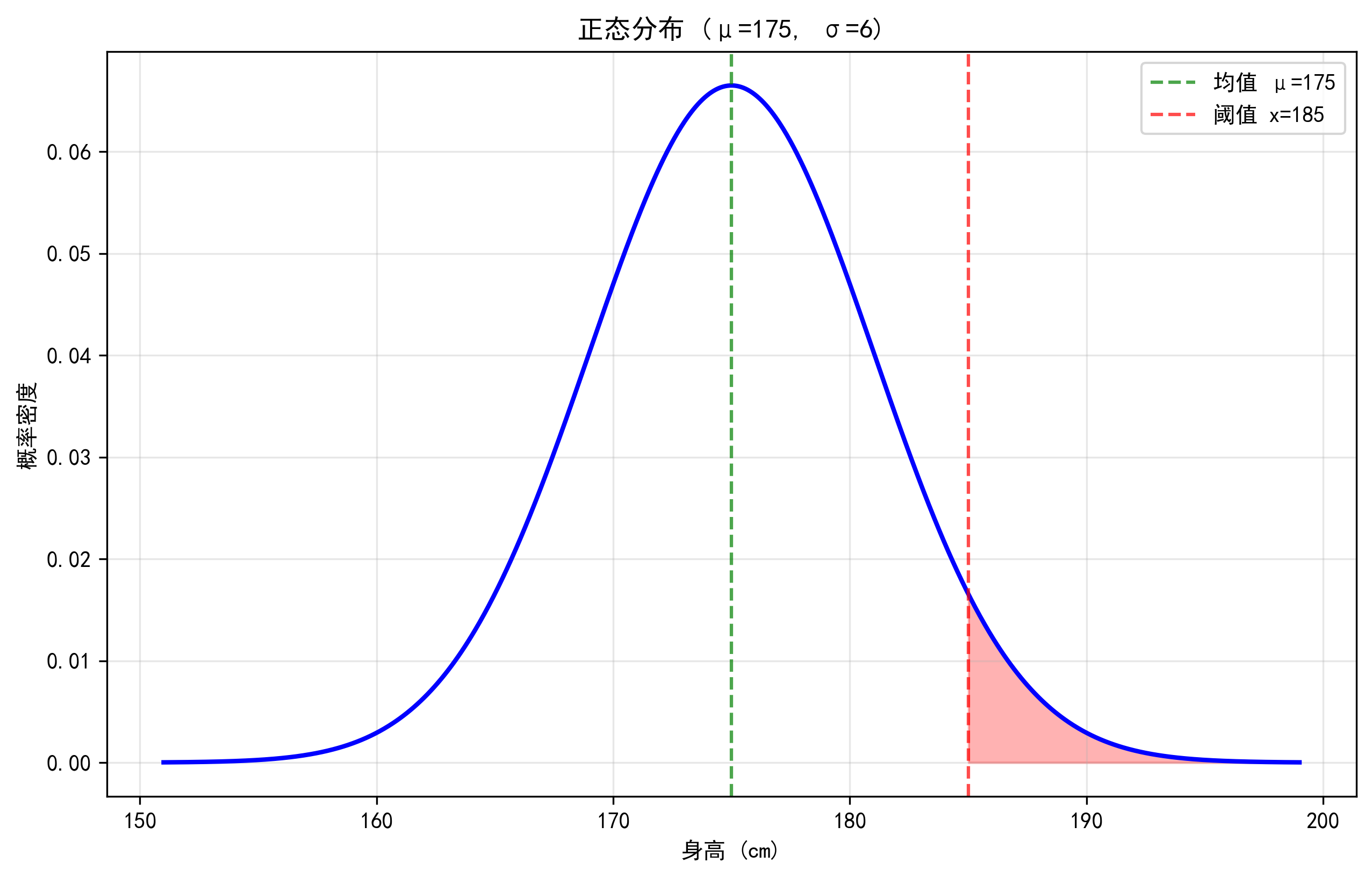
紅色陰影部分表示身高超過185cm的比例,約為4.78%。
6. 別被這些誤區騙了
? 誤區1:賭徒謬誤(Gambler’s Fallacy)
真相:在獨立事件序列中,過去的結果不會影響未來事件的概率。這是由事件獨立性的數學定義決定的。例如,公平硬幣連續拋出9次正面后,第10次仍然有50%的概率是正面。這種誤解源于人類對隨機性的錯誤認知,即期望短期內的結果符合長期的概率分布,而忽視了隨機波動的存在。
? 誤區2:基礎概率謬誤(Base Rate Fallacy)
真相:在評估條件概率時,忽略先驗概率(基礎發生率)會導致嚴重的判斷錯誤。如前面貝葉斯定理例子所示,對于罕見疾病(低基礎發生率),即使檢測準確性很高,陽性結果的預測價值仍然可能很低。這是因為根據貝葉斯定理,后驗概率不僅取決于檢測的靈敏度和特異性,還受基礎發生率的顯著影響。醫學診斷、司法判決等領域尤其需要注意這一點。
? 誤區3:代表性啟發式偏誤(Representativeness Heuristic Bias)
真相:人們傾向于基于對象與某類別的相似程度(代表性)來判斷其屬于該類別的概率,而忽略了先驗概率和樣本大小的影響。例如,描述一個"內向、細心、有條理"的人時,許多人會認為此人是圖書管理員的概率高于農民,盡管農民在人口中的比例遠高于圖書管理員。這種判斷違反了貝葉斯定理和概率的基本原則,因為它沒有考慮基礎概率(職業在人口中的分布比例)。
? 誤區4:小數定律(Law of Small Numbers)
真相:小樣本數據通常表現出較大的隨機波動,其統計特性可能與大樣本顯著不同。根據大數定律,只有當樣本量足夠大時,樣本統計量才會穩定地接近總體參數。例如,投擲硬幣10次可能得到7次正面,這與理論概率0.5有明顯偏差,但這屬于正常的隨機波動范圍,不能據此推斷硬幣有問題。在科學研究和數據分析中,需要合理設定樣本量并謹慎解讀小樣本結果。
? 誤區5:概率混淆(Probability Confusion)
真相:條件概率P(A|B)與其逆條件概率P(B|A)是完全不同的概念,在數值上通常也不相等。例如,“患病者檢測呈陽性的概率”(檢測靈敏度)與"檢測呈陽性者患病的概率"(檢測陽性預測值)是不同的。前者是P(陽性|患病),后者是P(患病|陽性),兩者之間的關系需通過貝葉斯定理轉換,且受基礎發生率影響。這種混淆在醫學診斷、法庭證據評估等領域尤為常見且危險。
7. 實際應用建議
7.1 在日常決策中應用概率思維
- 考慮基礎概率:在評估風險時,先了解事件的基礎發生率
- 警惕小樣本:不要從少量觀察中得出結論
- 區分相關與因果:兩個事件相關不一定有因果關系
- 量化不確定性:用概率表達不確定性,而不是簡單的"會/不會"
7.2 在數據分析中正確使用概率
- 選擇合適的概率模型:根據數據特性選擇合適的概率分布
- 考慮條件概率:分析事件間的依賴關系
- 應用貝葉斯思想:結合先驗知識和新證據,不斷更新認知
- 警惕幸存者偏差:數據可能只來自"幸存"的樣本,忽略了失敗案例
8. 練習一下
基礎題
- 從一副撲克牌中隨機抽一張,求抽到黑桃A的概率。
- 投擲兩個骰子,求點數之和為7的概率。
- 袋子里有5個紅球和3個藍球,隨機取出2個球,求恰好取出1個紅球和1個藍球的概率。
思考題
- 一個家庭有兩個孩子,已知其中至少有一個是女孩,求另一個也是女孩的概率。
- 某種疾病的發病率為1%,檢測的敏感性為90%,特異性為95%。如果一個人檢測結果為陽性,他真正患病的概率是多少?
- 為什么很多人對"檢測陽性后患病概率"的直覺判斷會出錯?
動手題
- 用Python模擬投擲硬幣1000次,驗證正面朝上的概率是否接近0.5。
- 用Python生成并可視化二項分布和正態分布,觀察參數變化對分布形狀的影響。
- 實現一個簡單的貝葉斯分類器,用于垃圾郵件過濾。
9. 重點回顧
- 概率基礎:概率是對事件發生可能性的度量,取值范圍為[0,1]
- 條件概率:P(A|B)表示在B發生的條件下A發生的概率
- 獨立性:如果P(A∩B) = P(A)×P(B),則事件A和B是獨立的
- 全概率公式:通過分割樣本空間計算總概率
- 貝葉斯定理:結合先驗概率和條件概率,計算后驗概率
- 概率分布:描述隨機變量可能取值的概率規律
- 常見誤區:警惕賭徒謬誤、基礎概率謬誤等認知陷阱
10. 下期預告
下一篇我們將深入探討"隨機變量:概率的載體"。你將學到:
- 隨機變量的定義與類型
- 離散型隨機變量的分布律與數字特征
- 連續型隨機變量的概率密度函數與分布函數
- 隨機變量的期望、方差及其性質
隨機變量是連接概率論與統計學的橋梁,敬請期待!
📚 參考資料
- 盛驟等著《概率論與數理統計》,高等教育出版社
- 陳希孺著《概率論與數理統計》,中國科學技術大學出版社
- Sheldon Ross著《概率論基礎》,人民郵電出版社
- 吳喜之著《統計學:從數據到結論》,中國統計出版社
寫在最后:概率論是統計學的理論基礎,也是理解不確定性世界的強大工具。希望這篇文章能幫助你建立概率思維,在充滿不確定性的世界中做出更明智的決策。如果你有任何問題或想法,歡迎在評論區留言交流!讓我們一起探索概率的奧秘!📊
)

詳解)






)
)



)




