一.特征
從 Base64 的核心特性入手,比如它的編碼原理(將二進制數據轉換為 ASCII 字符集)和字符集的組成(A-Z、a-z、0-9、+、/ 和 =)。這是 Base64 最基礎的特點,幾乎每個回答都應該包括這些內容。基于 64 個字符 :Base64 使用 64 個可打印的 ASCII 字符(包括大小寫英文字母、數字以及 “+” 和 “/”)來表示二進制數據。這 64 個字符可以組合成各種序列,從而表示任意的二進制數據。長度被四整除,不夠被四整除后補零。
一.常規版base64加解密,直接編碼即可
python實現
import base64def base64_encode(input_string):# 將字符串轉換為字節input_bytes = input_string.encode('utf-8')# 進行 Base64 編碼encoded_bytes = base64.b64encode(input_bytes)# 將結果轉換為字符串encoded_string = encoded_bytes.decode('utf-8')return encoded_stringinput_string = "Hello, World!"
encoded_string = base64_encode(input_string)
print(f"Base64 Encoded: {encoded_string}")
def base64_decode(encoded_string):# 將字符串轉換為字節encoded_bytes = encoded_string.encode('utf-8')# 進行 Base64 解碼decoded_bytes = base64.b64decode(encoded_bytes)# 將結果轉換為字符串decoded_string = decoded_bytes.decode('utf-8')return decoded_string# 示例
decoded_string = base64_decode(encoded_string)
print(f"Base64 Decoded: {decoded_string}")
爬蟲遇到不規范base64,有的還需要映射值。今天總結兩種不規范base64解碼。
2.映射值
有一次提取一個網站詳情,采購供應商門戶翻頁加解密出來了,接口為
https://ebuy.spdb.com.cn/app/noticeManagement/findSupplierCollect
這個網站可以當作爬蟲逆向練習的網站,挺好的
但響應加密,解密出來還有密文我推斷是base64加密(有+號,\號,末尾還要=號)

后面解密出來的密文是詳情,我用常規base64解出來?,直接報這個錯誤
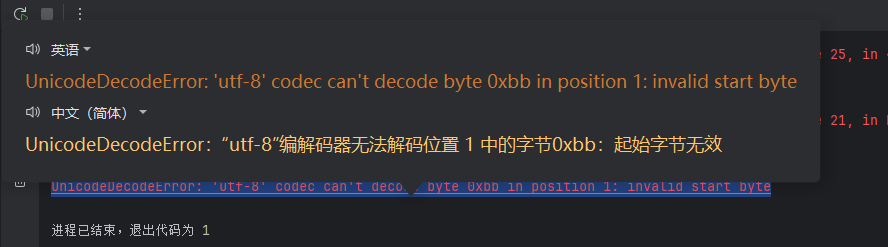
后面查了網頁JS代碼,接口在
https://ebuy.spdb.com.cn/assets/Base64-2f4ca03a.js
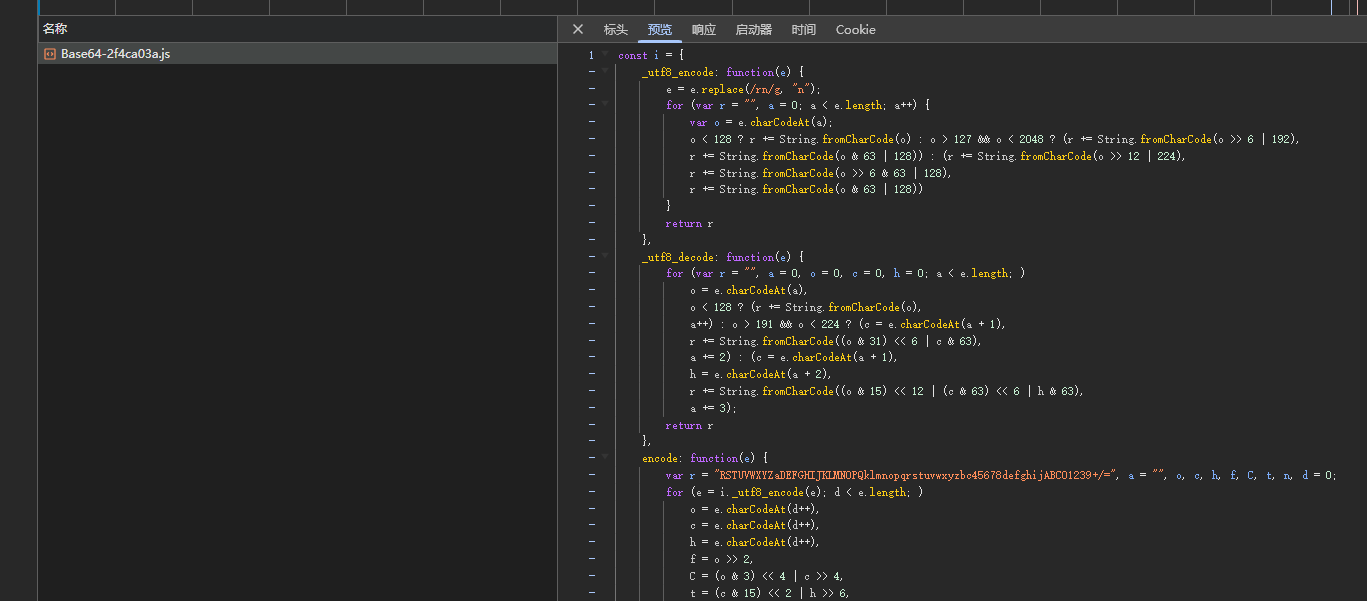
發現個映射值?
創建映射表
def decode_custom_b64(self, enc_str):custom_b64 = "RSTUVWXYZaDEFGHIJKLMNOPQklmnopqrstuvwxyzbc45678defghijABC01239+/="std_b64 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="# 創建轉換映射表trans_table = str.maketrans(custom_b64, std_b64)# 轉換到標準Base64std_str = enc_str.translate(trans_table)# 標準Base64解碼decoded_bytes = base64.b64decode(std_str)# UTF-8解碼return decoded_bytes.decode('utf-8')?完整案例:
import requests
import subprocess
from functools import partial
import base64subprocess.Popen = partial(subprocess.Popen, encoding="utf-8")
def get_js_code():return '''var CryptoJS =require('crypto-js')function vr(F) {const z = CryptoJS.enc.Utf8.parse(F);if (z.sigBytes < 16) {const d = Q.lib.WordArray.random(16 - z.sigBytes);z.concat(d), z.sigBytes = 16} else z.sigBytes > 16 && (z.sigBytes = 16, z.words = z.words.slice(0, 4));return z
}function Bx(F, z) {let d = z + "39457352";return CryptoJS.AES.decrypt(F, vr(d), {mode: CryptoJS.mode.ECB, padding: CryptoJS.pad.Pkcs7}).toString(CryptoJS.enc.Utf8)
}
d = {"page": 1, "rows": 10, "startDate": "", "endDate": "", "noticeStatus": 9, "validFlag": 1, "orderRule": 1
}function iv2(e = 8) {for (var t = ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z"], n = "", l = 0; l < e; l++) {var i = Math.ceil(Math.random() * 35);n += t[i]}return n
}function Ce(F) {let z = {uuid: iv2(16), userId: ""}, d = "nppszdcfw339457352";return {visa: CryptoJS.AES.encrypt(JSON.stringify(z), vr(d), {mode: CryptoJS.mode.ECB, padding: CryptoJS.pad.Pkcs7}).toString(), params: F}
}f = "/noticeManagement/findPurchaseNotice"function pe(F, z) {return F && true ? false ? lx(F) : Ce(F) : {visa: "", params: F}
}function get_data(encode, f) {txt = JSON.parse(Bx(encode, f))return txt
}function get_headers(d,f) {f = "/noticeManagement/findPurchaseNotice"return pe(d, f)['visa']
}d = {"page": 1, "rows": 10, "startDate": "", "endDate": "", "noticeStatus": 9, "validFlag": 1, "orderRule": 1
}'''
import requests
import execjsheaders = {"Accept": "application/json, text/plain, */*","Accept-Language": "zh-CN,zh;q=0.9","Authorization": "null","Cache-Control": "no-cache","Connection": "keep-alive","Content-Type": "application/x-www-form-urlencoded;charset:utf-8","Content-Visa": "qsNpoek2BvNXOt353QRp7BsZ6/OchE6IkSFG/UK+nKiXWqgzyVBe3+pZjB7+YsME","Origin": "https://ebuy.spdb.com.cn","Pragma": "no-cache","Referer": "https://ebuy.spdb.com.cn/","Sec-Fetch-Dest": "empty","Sec-Fetch-Mode": "cors","Sec-Fetch-Site": "same-origin","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36","X-CSRF-TOKEN": "ab9dfd31-fec3-4f26-872f-6650269027a1","sec-ch-ua": "\"Google Chrome\";v=\"137\", \"Chromium\";v=\"137\", \"Not/A)Brand\";v=\"24\"","sec-ch-ua-mobile": "?0","sec-ch-ua-platform": "\"Windows\""
}
cookies = {"SESSION": "ZjM1NTFkY2MtNjgyZi00NWZhLWIxNTQtNGZlN2FhNjEzNDA3"
}
url = "https://ebuy.spdb.com.cn/app/noticeManagement/findSupplierCollect"
data = {"page": "2","rows": "10","noticeType": "00100010","startDate": "","endDate": "","noticeStatus": "9","validFlag": "1","orderRule": "1"
}
response = requests.post(url, headers=headers, cookies=cookies, data=data)
url = "https://ebuy.spdb.com.cn/app/csrf/getToken"
js = execjs.compile(get_js_code())
response1 = requests.get(url, headers=headers,)
data = js.call('get_data', response1.json()['data'], response1.headers['content-visa'])
headers['x-csrf-token'] = data['token']
json_obj = js.call('get_data', response.json()['data'], response.headers['content-visa'])import base64def decode_custom_b64(enc_str):custom_b64 = "RSTUVWXYZaDEFGHIJKLMNOPQklmnopqrstuvwxyzbc45678defghijABC01239+/="std_b64 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="# 創建轉換映射表trans_table = str.maketrans(custom_b64, std_b64)# 轉換到標準Base64std_str = enc_str.translate(trans_table)# 標準Base64解碼decoded_bytes = base64.b64decode(std_str)# UTF-8解碼return decoded_bytes.decode('utf-8')# 示例
for i in json_obj['rows']:print(i['content'])decoded_string = decode_custom_b64(i['content'])print(decoded_string)最后結果得出網頁源代碼
3.轉為標準base64.
在工作中要求提取文件鏈接
https://scut.gzebid.cn/#/noticeDetail?id=cd7f555d3ce78b3f09027ce07a50f6f6&tenderMode=zb¬iceType=8&categoryId=130000
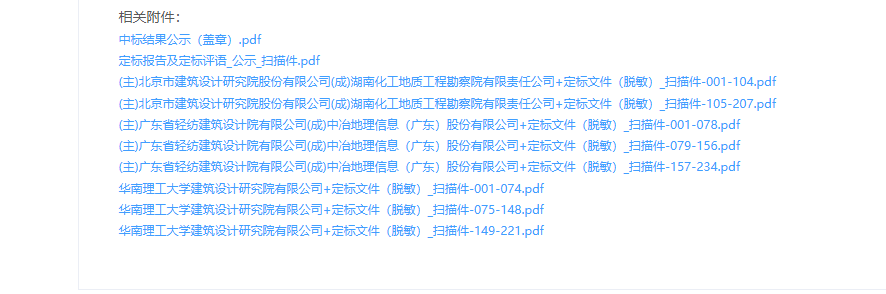
抓包分析,發現數據是加密的?
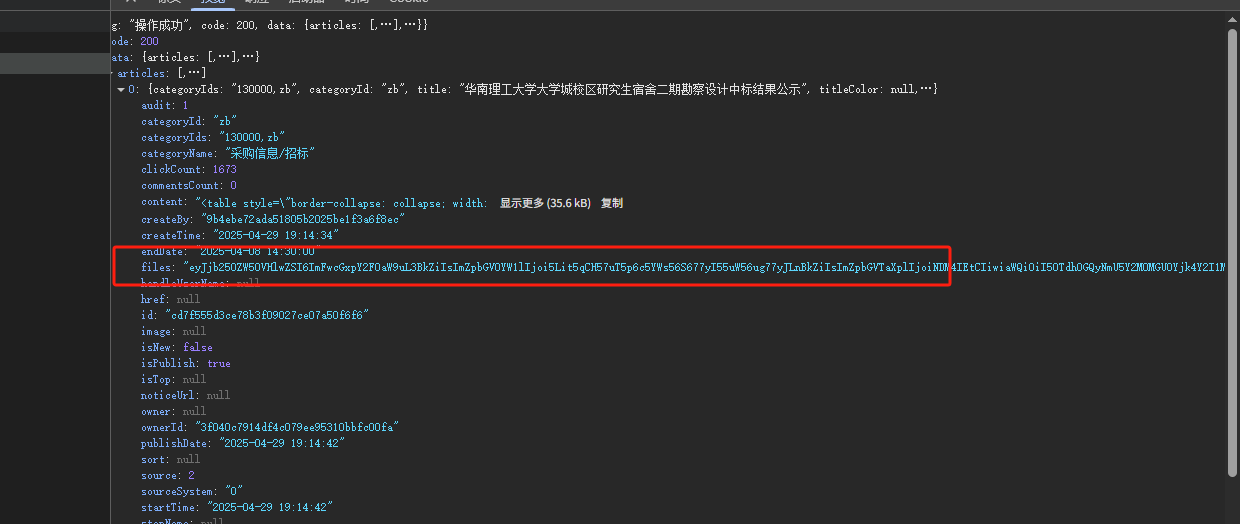

遇到這個數據很坑,首先|分為兩個base64編碼,解碼為幾個json。然后base64沒有減號,沒有_號,數據里把加號變成減號,把/變為_.要轉換過來。base編碼長度被四整除,不整除后面補等于號=。真是奇葩的加密數據。而且有些不能被四整除,就很麻煩。
最后詳細處理如下,
encoded_str2 = encoded_str.replace('-', '+').replace('_', '/').strip()
# 長度被四整除,不整除后補‘=’
padding_needed = len(encoded_str) % 4
if padding_needed != 0:encoded_str2 += '=' * (4 - padding_needed)
try:decoded_bytes = base64.b64decode(encoded_str2)decoded_str = decoded_bytes.decode('utf-8')json_obj = json.loads(decoded_str)print(json_obj)
except Exception as e:print(e)完整案例
import requests
import json
import base64
headers = {"Accept": "application/json, text/plain, */*","Accept-Language": "zh-CN,zh;q=0.9","Cache-Control": "no-cache","Connection": "keep-alive","Pragma": "no-cache","Referer": "https://scut.gzebid.cn/","Sec-Fetch-Dest": "empty","Sec-Fetch-Mode": "cors","Sec-Fetch-Site": "same-origin","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36","sec-ch-ua": "\"Google Chrome\";v=\"137\", \"Chromium\";v=\"137\", \"Not/A)Brand\";v=\"24\"","sec-ch-ua-mobile": "?0","sec-ch-ua-platform": "\"Windows\"","tenantId": "d2c7335ee6754bdbbc1ad0b9b83207b3"
}
cookies = {"acw_tc": "0a47308517495382118966853e00691d9c985fa1bc61d123ece31e2b39b71c"
}
url = "https://scut.gzebid.cn/api/bid/share/api/platform/articleNew/cd7f555d3ce78b3f09027ce07a50f6f6/zb/8"
response = requests.get(url, headers=headers, cookies=cookies)
encoded_str = response.json()['data']['articles'][0]['files']
# 多個文件,用‘|’分割
encoded_str_list = encoded_str.split('|')
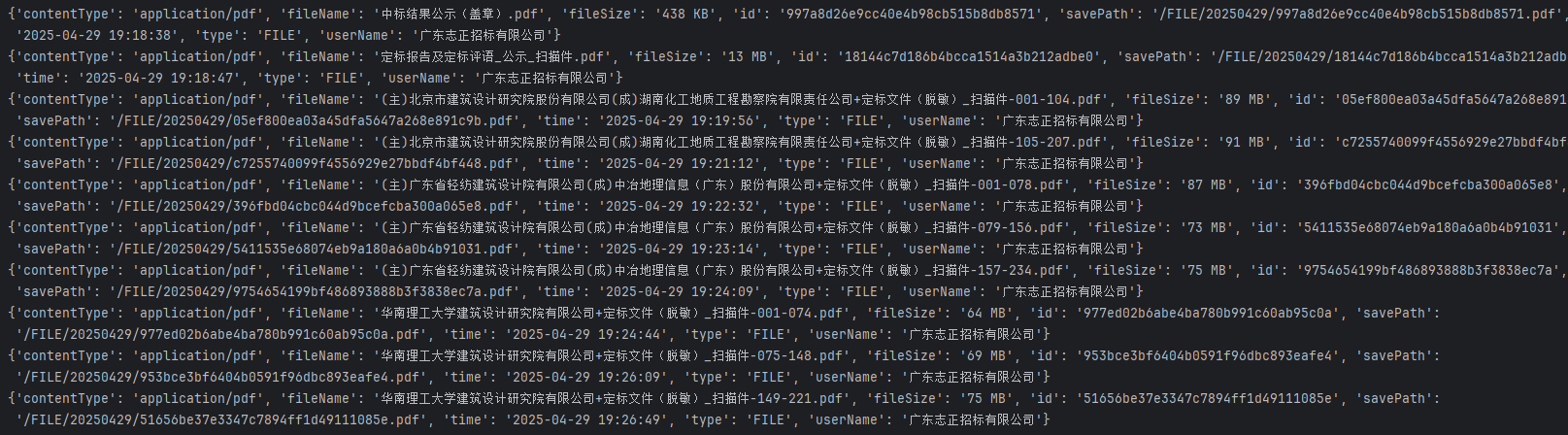
for encoded_str in encoded_str_list:# 轉為標準base64編碼encoded_str2 = encoded_str.replace('-', '+').replace('_', '/').strip()# 長度被四整除,不整除后補‘=’padding_needed = len(encoded_str) % 4if padding_needed != 0:encoded_str2 += '=' * (4 - padding_needed)try:decoded_bytes = base64.b64decode(encoded_str2)decoded_str = decoded_bytes.decode('utf-8')json_obj = json.loads(decoded_str)print(json_obj)except Exception as e:print(e)結果如下:
鏈接,名稱,所有數據都出來了

詳解)






)
)



)





