1. 查詢構建(包括Text2SQL)
查詢構建的相關技術棧:
- Text-to-SQL
- Text-to-Cypher
- ?從查詢中提取元數據(Self-query Retriever)
1.1 Text-to-SQL(關系數據庫)
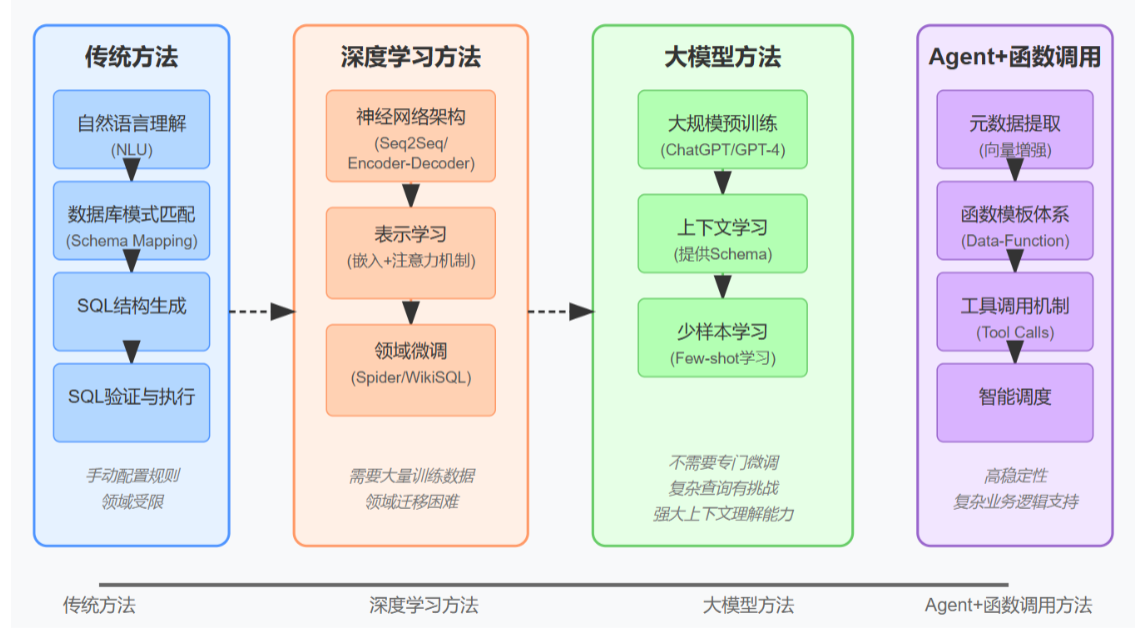
1.1.1 大語言模型方法Text-to-SQL樣例實現
A.安裝MySQL
# 在Ubuntu/Debian上安裝 sudo apt update sudo apt install mysql-server sudo mysql_secure_installation# 啟動MySQL服務 sudo systemctl start mysql sudo systemctl enable mysql
B. 安裝PyMySQL
pip install pymysql
使用?apt?安裝 MySQL 后,默認情況下?root 用戶沒有密碼,但需要通過?sudo?權限訪問。
如果希望設置密碼(推薦)
使用?mysql_secure_installation
運行以下命令交互式設置密碼:
sudo mysql_secure_installation
按照提示:
-
選擇密碼強度驗證策略(通常選?
0?跳過) -
輸入新密碼并確認
-
后續選項建議全部選?
Y(移除匿名用戶、禁止遠程 root 登錄等)
C. 用?sudo?登錄 MySQL
sudo mysql -u rootD. 檢查 MySQL?用戶認證方式
登錄?MySQL 后,執行:
SELECT user, host, plugin FROM mysql.user WHERE user='root';E. 修改?root 用戶認證方式為密碼?
假設你已經用?sudo mysql?進入了 MySQL,執行:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '12345678';
FLUSH PRIVILEGES;F. 數據準備 – Sakila Database
https://dev.mysql.com/doc/sakila/en/
模擬 DVD 租賃業務,包含 16 張表(如 film、rental、payment),側重庫存與租賃流程
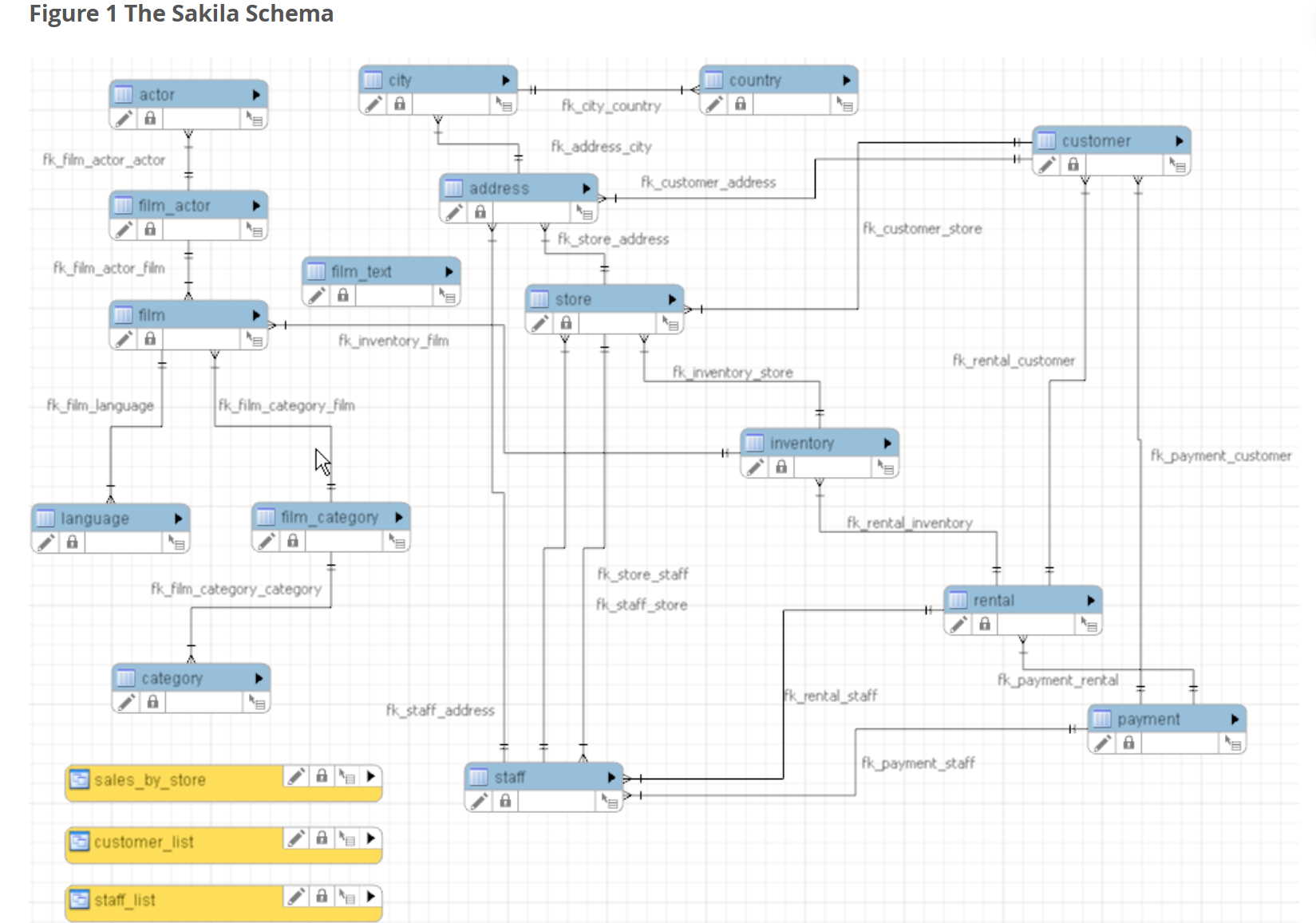
下載并安裝MySQL的Sakila示例數據庫
下載MySQL官方示例數據庫"Sakila"的壓縮包
2.wget http://downloads.mysql.com/docs/sakila-db.tar.gz
解壓下載的壓縮包
3.tar -xvzf sakila-db.tar.gz
4.cd sakila-db
5.mysql -u root -p < sakila-schema.sql
6.mysql -u root -p< sakila-data.sql
7.mysql -u root –p
8.SHOW DATABASES;
9.USE sakila;
10.SHOW TABLES;
G. 構建全鏈路Text2SQL系統步驟
a. Schema 提取與切片(構建 DDL 知識庫)
b. 示例對注入(構建 Q→SQL 知識庫)
c. 業務描述補充(構建 DB 描述知識庫)可選
-----------------------------(到此構建向量數據庫完成)
d. 檢索增強(RAG 檢索上下文,選出正確的Schema示例)
e. SQL 生成(調用 LLM)
------------------------------(到此sql生成完成)
f. 執行與反饋(執行 SQL 并返回結果)
g. 把結果傳給生成模型做生成,將生成內容返回給用戶
代碼示例:
a.Schema 提取與切片
# generate_ddl_yaml.py
import os
import yaml
import pymysql
from dotenv import load_dotenv# 1. 加載 .env 中的數據庫配置
load_dotenv() host = os.getenv("MYSQL_HOST")
port = int(os.getenv("MYSQL_PORT", "3306"))
user = "root"
password = "password"
db_name = "sakila"# 2. 連接 MySQL``
conn = pymysql.connect(host=host, port=port, user=user, password=password,database=db_name, cursorclass=pymysql.cursors.Cursor
) ddl_map = {}
try:with conn.cursor() as cursor:# 3. 獲取所有表名cursor.execute("SELECT table_name FROM information_schema.tables ""WHERE table_schema = %s;", (db_name,)) tables = [row[0] for row in cursor.fetchall()]# 4. 遍歷表列表,執行 SHOW CREATE TABLEfor tbl in tables:cursor.execute(f"SHOW CREATE TABLE `{db_name}`.`{tbl}`;")result = cursor.fetchone()# result[0]=表名, result[1]=完整 DDLddl_map[tbl] = result[1] finally:conn.close()# 5. 寫入 YAML 文件
with open("90-文檔-Data/sakila/ddl_statements.yaml", "w") as f:yaml.safe_dump(ddl_map, f, sort_keys=True, allow_unicode=True)
print("? ddl_statements.yaml 已生成,共包含表:", list(ddl_map.keys()))a.?構建 DDL 知識庫
# ingest_ddl.py
import logging
from pymilvus import MilvusClient, DataType, FieldSchema, CollectionSchema
from pymilvus import model
import torch
import yamllogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')# 1. 初始化嵌入函數
embedding_function = model.dense.OpenAIEmbeddingFunction(model_name='text-embedding-3-large')# 2. 讀取 DDL 列表(假設 ddl_statements.yaml 中存放 {table_name: "CREATE TABLE ..."})
with open("90-文檔-Data/sakila/ddl_statements.yaml","r") as f:ddl_map = yaml.safe_load(f)logging.info(f"[DDL] 從YAML文件加載了 {len(ddl_map)} 個表/視圖定義")# 3. 連接 Milvus
client = MilvusClient("text2sql_milvus_sakila.db")# 4. 定義 Collection Schema
# 字段:id, vector, table_name, ddl_text
vector_dim = len(embedding_function(["dummy"])[0])
fields = [FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=vector_dim),FieldSchema(name="table_name", dtype=DataType.VARCHAR, max_length=100),FieldSchema(name="ddl_text", dtype=DataType.VARCHAR, max_length=2000),
]
schema = CollectionSchema(fields, description="DDL Knowledge Base", enable_dynamic_field=False)# 5. 創建 Collection(如不存在)
collection_name = "ddl_knowledge"
if not client.has_collection(collection_name):client.create_collection(collection_name=collection_name, schema=schema)logging.info(f"[DDL] 創建了新的集合 {collection_name}")
else:logging.info(f"[DDL] 集合 {collection_name} 已存在")# 6. 為向量字段添加索引
index_params = client.prepare_index_params()
index_params.add_index(field_name="vector", index_type="AUTOINDEX", metric_type="COSINE", params={"nlist": 1024})
client.create_index(collection_name=collection_name, index_params=index_params)# 7. 批量插入 DDL
data = []
texts = []
for tbl, ddl in ddl_map.items():texts.append(ddl)data.append({"table_name": tbl, "ddl_text": ddl})logging.info(f"[DDL] 準備處理 {len(data)} 個表/視圖的DDL語句")# 生成全部嵌入
embeddings = embedding_function(texts)
logging.info(f"[DDL] 成功生成了 {len(embeddings)} 個向量嵌入")# 組織為 Milvus insert 格式
records = []
for emb, rec in zip(embeddings, data):rec["vector"] = embrecords.append(rec)res = client.insert(collection_name=collection_name, data=records)
logging.info(f"[DDL] 成功插入了 {len(records)} 條記錄到Milvus")
logging.info(f"[DDL] 插入結果: {res}")logging.info("[DDL] 知識庫構建完成")b.? 示例對注入(構建 Q→SQL 知識庫)運行代碼前需準備預備資料:使用大模型結合DDL生成問答對
# ingest_q2sql.py
import logging
from pymilvus import MilvusClient, DataType, FieldSchema, CollectionSchema
from pymilvus import model
import torch
import jsonlogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')# 1. 初始化嵌入函數
embedding_function = model.dense.OpenAIEmbeddingFunction(model_name='text-embedding-3-large')# 2. 加載 Q->SQL 對(假設 q2sql_pairs.json 數組,每項 { "question": ..., "sql": ... })
with open("90-文檔-Data/sakila/q2sql_pairs.json", "r") as f:pairs = json.load(f)logging.info(f"[Q2SQL] 從JSON文件加載了 {len(pairs)} 個問答對")# 3. 連接 Milvus
client = MilvusClient("text2sql_milvus_sakila.db")# 4. 定義 Collection Schema
vector_dim = len(embedding_function(["dummy"])[0])
fields = [FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=vector_dim),FieldSchema(name="question", dtype=DataType.VARCHAR, max_length=500),FieldSchema(name="sql_text", dtype=DataType.VARCHAR, max_length=2000),
]
schema = CollectionSchema(fields, description="Q2SQL Knowledge Base", enable_dynamic_field=False)# 5. 創建 Collection(如不存在)
collection_name = "q2sql_knowledge"
if not client.has_collection(collection_name):client.create_collection(collection_name=collection_name, schema=schema)logging.info(f"[Q2SQL] 創建了新的集合 {collection_name}")
else:logging.info(f"[Q2SQL] 集合 {collection_name} 已存在")# 6. 為向量字段添加索引
index_params = client.prepare_index_params()
index_params.add_index(field_name="vector", index_type="AUTOINDEX", metric_type="COSINE", params={"nlist": 1024})
client.create_index(collection_name=collection_name, index_params=index_params)# 7. 批量插入 Q2SQL 對
data = []
texts = []
for pair in pairs:texts.append(pair["question"])data.append({"question": pair["question"], "sql_text": pair["sql"]})logging.info(f"[Q2SQL] 準備處理 {len(data)} 個問答對")# 生成全部嵌入
embeddings = embedding_function(texts)
logging.info(f"[Q2SQL] 成功生成了 {len(embeddings)} 個向量嵌入")# 組織為 Milvus insert 格式
records = []
for emb, rec in zip(embeddings, data):rec["vector"] = embrecords.append(rec)res = client.insert(collection_name=collection_name, data=records)
logging.info(f"[Q2SQL] 成功插入了 {len(records)} 條記錄到Milvus")
logging.info(f"[Q2SQL] 插入結果: {res}")logging.info("[Q2SQL] 知識庫構建完成")問答對文件q2sql_pairs.json如下:
[{"question": "List all actors with their IDs and names.","sql": "SELECT actor_id, first_name, last_name FROM actor;"},{"question": "Add a new actor named 'John Doe'.","sql": "INSERT INTO actor (first_name, last_name) VALUES ('John', 'Doe');"},{"question": "Update the last name of actor with ID 1 to 'Smith'.","sql": "UPDATE actor SET last_name = 'Smith' WHERE actor_id = 1;"},{"question": "Delete the actor with ID 2.","sql": "DELETE FROM actor WHERE actor_id = 2;"},{"question": "Show all films and their descriptions.","sql": "SELECT film_id, title, description FROM film;"},{"question": "Insert a new film titled 'New Movie' in language 1.","sql": "INSERT INTO film (title, language_id) VALUES ('New Movie', 1);"},{"question": "Change the rating of film ID 3 to 'PG-13'.","sql": "UPDATE film SET rating = 'PG-13' WHERE film_id = 3;"},{"question": "Remove the film with ID 4.","sql": "DELETE FROM film WHERE film_id = 4;"},{"question": "Retrieve all categories.","sql": "SELECT category_id, name FROM category;"},{"question": "Add a new category 'Horror'.","sql": "INSERT INTO category (name) VALUES ('Horror');"},{"question": "Rename category ID 5 to 'Thriller'.","sql": "UPDATE category SET name = 'Thriller' WHERE category_id = 5;"},{"question": "Delete category with ID 6.","sql": "DELETE FROM category WHERE category_id = 6;"},{"question": "List all customers with their store and email.","sql": "SELECT customer_id, store_id, email FROM customer;"},{"question": "Create a new customer for store 1 named 'Alice Brown'.","sql": "INSERT INTO customer (store_id, first_name, last_name, create_date, address_id, active) VALUES (1, 'Alice', 'Brown', NOW(), 1, 1);"},{"question": "Update email of customer ID 10 to 'newemail@example.com'.","sql": "UPDATE customer SET email = 'newemail@example.com' WHERE customer_id = 10;"},{"question": "Remove customer with ID 11.","sql": "DELETE FROM customer WHERE customer_id = 11;"},{"question": "Show inventory items for film ID 5.","sql": "SELECT inventory_id, film_id, store_id FROM inventory WHERE film_id = 5;"},{"question": "Add a new inventory item for film 5 in store 2.","sql": "INSERT INTO inventory (film_id, store_id) VALUES (5, 2);"},{"question": "Update the store of inventory ID 20 to store 3.","sql": "UPDATE inventory SET store_id = 3 WHERE inventory_id = 20;"},{"question": "Delete inventory record with ID 21.","sql": "DELETE FROM inventory WHERE inventory_id = 21;"},{"question": "List recent rentals with rental date and customer.","sql": "SELECT rental_id, rental_date, customer_id FROM rental ORDER BY rental_date DESC LIMIT 10;"},{"question": "Record a new rental for inventory 15 by customer 5.","sql": "INSERT INTO rental (rental_date, inventory_id, customer_id, staff_id) VALUES (NOW(), 15, 5, 1);"},{"question": "Update return date for rental ID 3 to current time.","sql": "UPDATE rental SET return_date = NOW() WHERE rental_id = 3;"},{"question": "Remove the rental record with ID 4.","sql": "DELETE FROM rental WHERE rental_id = 4;"},{"question": "Show all payments with amount and date.","sql": "SELECT payment_id, customer_id, amount, payment_date FROM payment;"},{"question": "Add a payment of 9.99 for rental 3 by customer 5.","sql": "INSERT INTO payment (customer_id, staff_id, rental_id, amount, payment_date) VALUES (5, 1, 3, 9.99, NOW());"},{"question": "Change payment amount of payment ID 6 to 12.50.","sql": "UPDATE payment SET amount = 12.50 WHERE payment_id = 6;"},{"question": "Delete payment record with ID 7.","sql": "DELETE FROM payment WHERE payment_id = 7;"},{"question": "List all staff with names and email.","sql": "SELECT staff_id, first_name, last_name, email FROM staff;"},{"question": "Hire a new staff member 'Bob Lee' at store 1.","sql": "INSERT INTO staff (first_name, last_name, address_id, store_id, active, username) VALUES ('Bob', 'Lee', 1, 1, 1, 'boblee');"},{"question": "Deactivate staff with ID 2.","sql": "UPDATE staff SET active = 0 WHERE staff_id = 2;"},{"question": "Remove staff member with ID 3.","sql": "DELETE FROM staff WHERE staff_id = 3;"},{"question": "Show all stores with manager and address.","sql": "SELECT store_id, manager_staff_id, address_id FROM store;"},{"question": "Open a new store with manager 2 at address 3.","sql": "INSERT INTO store (manager_staff_id, address_id) VALUES (2, 3);"},{"question": "Change manager of store ID 2 to staff ID 4.","sql": "UPDATE store SET manager_staff_id = 4 WHERE store_id = 2;"},{"question": "Close (delete) store with ID 3.","sql": "DELETE FROM store WHERE store_id = 3;"}
]?d. 檢索增強(RAG 檢索上下文,選出正確的Schema示例)
e. SQL 生成(調用 LLM)
# text2sql_query.py
import os
import logging
import yaml
import openai
import re
from dotenv import load_dotenv
from pymilvus import MilvusClient
from pymilvus import model
from sqlalchemy import create_engine, text# 1. 環境與日志配置
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
load_dotenv() # 加載 .env 環境變量# 2. 初始化 OpenAI API(使用最新 Response API)
openai.api_key = os.getenv("OPENAI_API_KEY")# 建議使用新 Response API 風格
# 例如: openai.chat.completions.create(...) 而非舊的 ChatCompletion.createMODEL_NAME = os.getenv("OPENAI_MODEL", "o4-mini")# 3. 嵌入函數初始化
def init_embedding():return model.dense.OpenAIEmbeddingFunction(model_name='text-embedding-3-large',)# 4. Milvus 客戶端連接
MILVUS_DB = os.getenv("MILVUS_DB_PATH", "text2sql_milvus_sakila.db")
client = MilvusClient(MILVUS_DB)# 5. 嵌入函數實例化
embedding_fn = init_embedding()# 6. 數據庫連接(SAKILA)
DB_URL = os.getenv("SAKILA_DB_URL", "mysql+pymysql://root:password@localhost:3306/sakila"
)
engine = create_engine(DB_URL)# 7. 檢索函數
def retrieve(collection: str, query_emb: list, top_k: int = 3, fields: list = None):results = client.search(collection_name=collection,data=[query_emb],limit=top_k,output_fields=fields)logging.info(f"[檢索] {collection} 檢索結果: {results}")return results[0] # 返回第一個查詢的結果列表# 8. SQL 提取函數
def extract_sql(text: str) -> str:# 嘗試匹配 SQL 代碼塊sql_blocks = re.findall(r'```sql\n(.*?)\n```', text, re.DOTALL)if sql_blocks:return sql_blocks[0].strip()# 如果沒有找到代碼塊,嘗試匹配 SELECT 語句select_match = re.search(r'SELECT.*?;', text, re.DOTALL)if select_match:return select_match.group(0).strip()# 如果都沒有找到,返回原始文本return text.strip()# 9. 執行 SQL 并返回結果
def execute_sql(sql: str):try:with engine.connect() as conn:result = conn.execute(text(sql))cols = result.keys()rows = result.fetchall()return True, cols, rowsexcept Exception as e:return False, None, str(e)# 10. 生成 SQL 函數
def generate_sql(prompt: str, error_msg: str = None) -> str:if error_msg:prompt += f"\n之前的SQL執行失敗,錯誤信息:{error_msg}\n請修正SQL語句:"response = openai.chat.completions.create(model=MODEL_NAME,messages=[{"role": "user", "content": prompt}],)raw_sql = response.choices[0].message.content.strip()sql = extract_sql(raw_sql)logging.info(f"[生成] 原始輸出: {raw_sql}")logging.info(f"[生成] 提取的SQL: {sql}")return sql# 11. 核心流程:自然語言 -> SQL -> 執行 -> 返回
def text2sql(question: str, max_retries: int = 3):# 11.1 用戶提問嵌入q_emb = embedding_fn([question])[0]logging.info(f"[檢索] 問題嵌入完成")# 11.2 RAG 檢索:DDLddl_hits = retrieve("ddl_knowledge", q_emb.tolist(), top_k=3, fields=["ddl_text"])logging.info(f"[檢索] DDL檢索結果: {ddl_hits}")try:ddl_context = "\n".join(hit.get("ddl_text", "") for hit in ddl_hits)except Exception as e:logging.error(f"[檢索] DDL處理錯誤: {e}")ddl_context = ""# 11.3 RAG 檢索:示例對q2sql_hits = retrieve("q2sql_knowledge", q_emb.tolist(), top_k=3, fields=["question", "sql_text"])logging.info(f"[檢索] Q2SQL檢索結果: {q2sql_hits}")try:example_context = "\n".join(f"NL: \"{hit.get('question', '')}\"\nSQL: \"{hit.get('sql_text', '')}\"" for hit in q2sql_hits)except Exception as e:logging.error(f"[檢索] Q2SQL處理錯誤: {e}")example_context = ""# 11.4 RAG 檢索:字段描述desc_hits = retrieve("dbdesc_knowledge", q_emb.tolist(), top_k=5, fields=["table_name", "column_name", "description"])logging.info(f"[檢索] 字段描述檢索結果: {desc_hits}")try:desc_context = "\n".join(f"{hit.get('table_name', '')}.{hit.get('column_name', '')}: {hit.get('description', '')}"for hit in desc_hits)except Exception as e:logging.error(f"[檢索] 字段描述處理錯誤: {e}")desc_context = ""# 11.5 組裝基礎 Promptbase_prompt = (f"### Schema Definitions:\n{ddl_context}\n"f"### Field Descriptions:\n{desc_context}\n"f"### Examples:\n{example_context}\n"f"### Query:\n\"{question}\"\n""請只返回SQL語句,不要包含任何解釋或說明。")# 11.6 生成并執行 SQL,最多重試 max_retries 次error_msg = Nonefor attempt in range(max_retries):logging.info(f"[執行] 第 {attempt + 1} 次嘗試")# 生成 SQLsql = generate_sql(base_prompt, error_msg)# 執行 SQLsuccess, cols, result = execute_sql(sql)if success:print("\n查詢結果:")print("列名:", cols)for r in result:print(r)returnerror_msg = resultlogging.error(f"[執行] 第 {attempt + 1} 次執行失敗: {error_msg}")print(f"執行失敗,已達到最大重試次數 {max_retries}。")print("最后錯誤信息:", error_msg)# 12. 程序入口
if __name__ == "__main__":user_q = input("請輸入您的自然語言查詢: ")text2sql(user_q)1.2 其他Text2SQL框架
1.2.1?Text2SQL框架:Vanna
Vanna.AI Documentation
1.2.2?Text2SQL框架: Chat2DB
https://github.com/CodePhiliaX/Chat2DB/blob/main/README_CN.md
1.3?用RAGFlow實現Text2SQL
基于RAGFlow模板創建 Text2SQL Agent
使用說明:Get started | RAGFlow
RAGFlow | RAGFlow

1.4?Text-to-Cypher(圖數據庫)
| 對比維度 | SQL 查詢 | Cypher 查詢 |
|---|---|---|
| 數據模型 | 表格(如表、行、列) | 圖結構(如節點、關系、屬性) |
| 查詢目標 | 行和列 | 節點和關系 |
| 語法風格 | 類似自然語言的聲明式 | 聲明式 + 圖模式匹配 |
| 復雜關系建模能力 | 依賴多表 JOIN | 原生支持節點和關系,復雜查詢更高效 |
| 學習門檻 | 使用廣泛,易于上手 | 專門化,使用人群相對少 |
代碼示例:?
# 準備Neo4j數據庫連接
from neo4j import GraphDatabase
import os
from dotenv import load_dotenv
load_dotenv()# Neo4j連接配置
uri = "bolt://localhost:7687" # 默認Neo4j Bolt端口
username = "neo4j"
password = os.getenv("NEO4J_PASSWORD") # 從環境變量獲取密碼# 初始化Neo4j驅動
driver = GraphDatabase.driver(uri, auth=(username, password))def get_database_schema():"""查詢數據庫的元數據信息"""with driver.session() as session:# 查詢節點標簽node_labels_query = """CALL db.labels() YIELD labelRETURN label"""node_labels = session.run(node_labels_query).data()# 查詢關系類型relationship_types_query = """CALL db.relationshipTypes() YIELD relationshipTypeRETURN relationshipType"""relationship_types = session.run(relationship_types_query).data()# 查詢每個標簽的屬性properties_by_label = {}for label in node_labels:properties_query = f"""MATCH (n:{label['label']})WITH n LIMIT 1RETURN keys(n) as properties"""properties = session.run(properties_query).data()if properties:properties_by_label[label['label']] = properties[0]['properties']return {"node_labels": [label['label'] for label in node_labels],"relationship_types": [rel['relationshipType'] for rel in relationship_types],"properties_by_label": properties_by_label}# 獲取數據庫結構
schema_info = get_database_schema()
print("\n數據庫結構信息:")
print("節點類型:", schema_info["node_labels"])
print("關系類型:", schema_info["relationship_types"])
print("\n節點屬性:")
for label, properties in schema_info["properties_by_label"].items():print(f"{label}: {properties}")# 準備SNOMED CT Schema描述
schema_description = f"""
你正在訪問一個SNOMED CT圖數據庫,主要包含以下節點和關系:節點類型:
{', '.join(schema_info["node_labels"])}關系類型:
{', '.join(schema_info["relationship_types"])}節點屬性:
"""
for label, properties in schema_info["properties_by_label"].items():schema_description += f"\n{label}節點屬性:{', '.join(properties)}"# 初始化DeepSeek客戶端
from openai import OpenAI
client = OpenAI(base_url="https://api.deepseek.com",api_key=os.getenv("DEEPSEEK_API_KEY")
)# 設置查詢
user_query = "查找與'Diabetes'相關的所有概念及其描述"# 準備生成Cypher的提示詞
prompt = f"""
以下是SNOMED CT圖數據庫的結構描述:
{schema_description}
用戶的自然語言問題如下:
"{user_query}"請生成Cypher查詢語句,注意以下幾點:
1. 關系方向要正確,例如:- ObjectConcept 擁有 Description,所以應該是 (oc:ObjectConcept)-[:HAS_DESCRIPTION]->(d:Description)- 不要寫成 (d:Description)-[:HAS_DESCRIPTION]->(oc:ObjectConcept)
2. 使用MATCH子句來匹配節點和關系
3. 使用WHERE子句來過濾條件,建議使用toLower()函數進行不區分大小寫的匹配
4. 使用RETURN子句來指定返回結果
5. 請只返回Cypher查詢語句,不要包含任何其他解釋、注釋或格式標記(如```cypher)
"""# 調用LLM生成Cypher語句
response = client.chat.completions.create(model="deepseek-chat",messages=[{"role": "system", "content": "你是一個Cypher查詢專家。請只返回Cypher查詢語句,不要包含任何Markdown格式或其他說明。"},{"role": "user", "content": prompt}],temperature=0
)# 清理Cypher語句,移除可能的Markdown標記
cypher = response.choices[0].message.content.strip()
cypher = cypher.replace('```cypher', '').replace('```', '').strip()
print(f"\n生成的Cypher查詢語句:\n{cypher}")# 執行Cypher查詢并獲取結果
def run_query(tx, query):result = tx.run(query)return [record for record in result]with driver.session() as session:results = session.execute_read(run_query, cypher)print(f"\n查詢結果:{results}")# 關閉數據庫連接
driver.close() ?代碼優勢分析:

數據庫 Schema 獲取方式
- Schema描述是自動獲取的,通過?get_database_schema()?函數,動態查詢 Neo4j 數據庫的節點標簽、關系類型和每個標簽的屬性。
- 這樣可以自動適配數據庫結構的變化,更通用、更健壯。
Cypher?生成提示詞
- 用自動獲取的 schema_info 組裝?schema_description,提示詞內容會根據數據庫實際結構動態變化。
- 提示詞中還特別強調了關系方向和大小寫匹配建議。
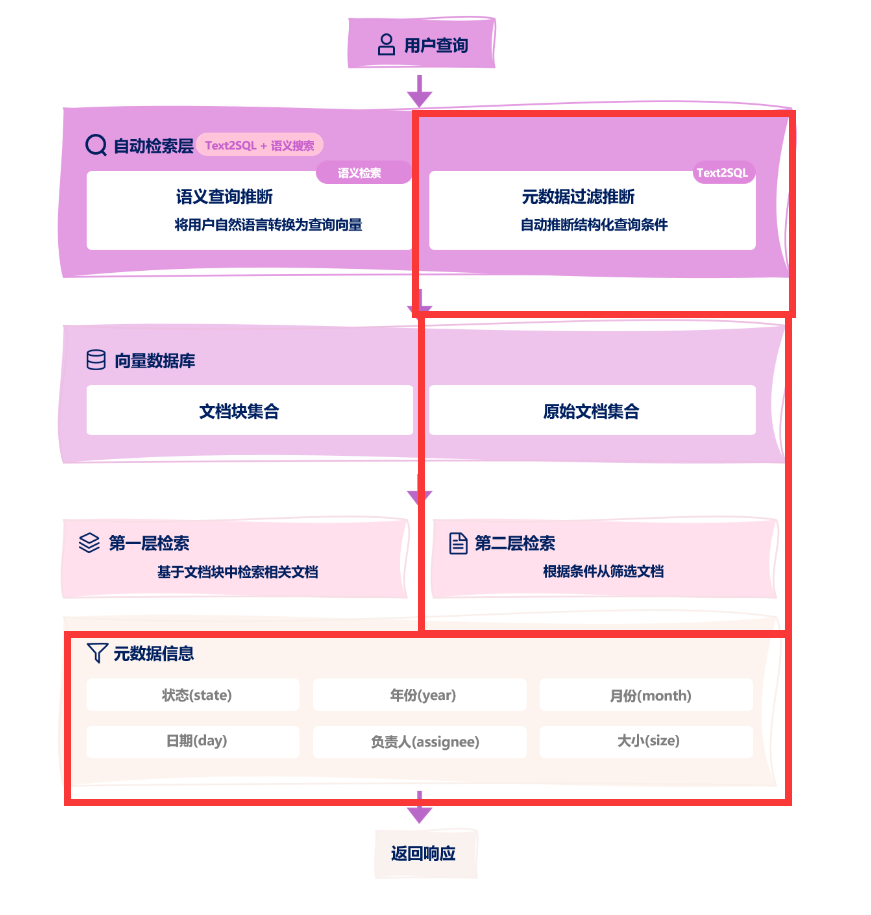
1.5?Self-query Retriever自動生成元數據過濾器(向量數據庫)
Self-query Retriever?是一種將自然語言查詢自動轉換為?結構化過濾條件 + 向量搜索?的混合檢索技術。其核心能力是通過LLM理解用戶問題中的隱含過濾條件,自動生成元數據過濾器(Metadata Filters),再與向量檢索結合。
| 檢索方式 | 優點 | 缺點 |
|---|---|---|
| 純向量檢索 | 語義理解能力強 | 無法精確過濾數值/分類字段 |
| 純元數據過濾 | 精確匹配 | 無法處理語義模糊查詢 |
| Self-query | 二者優勢結合 | 依賴LLM的解析能力 |
# 導入所需的庫
from langchain_core.prompts import ChatPromptTemplate
from langchain_deepseek import ChatDeepSeek
from langchain_community.document_loaders import YoutubeLoader
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from pydantic import BaseModel, Field
# 定義視頻元數據模型
class VideoMetadata(BaseModel):"""視頻元數據模型,定義了需要提取的視頻屬性"""source: str = Field(description="視頻ID")title: str = Field(description="視頻標題")description: str = Field(description="視頻描述")view_count: int = Field(description="觀看次數")publish_date: str = Field(description="發布日期")length: int = Field(description="視頻長度(秒)")author: str = Field(description="作者")
# 加載視頻數據
video_urls = ["https://www.youtube.com/watch?v=zDvnAY0zH7U", # 山西佛光寺"https://www.youtube.com/watch?v=iAinNeOp6Hk", # 中國最大宅院"https://www.youtube.com/watch?v=gCVy6NQtk2U", # 宋代地下宮殿
]
# 加載視頻元數據
videos = []
for url in video_urls:try:loader = YoutubeLoader.from_youtube_url(url, add_video_info=True)docs = loader.load()doc = docs[0]videos.append(doc)print(f"已加載:{doc.metadata['title']}")except Exception as e:print(f"加載失敗 {url}: {str(e)}")
# 創建向量存儲
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectorstore = Chroma.from_documents(videos, embed_model)
# 配置檢索器的元數據字段
metadata_field_info = [AttributeInfo(name="title",description="視頻標題(字符串)",type="string", ),AttributeInfo(name="author",description="視頻作者(字符串)",type="string",),AttributeInfo(name="view_count",description="視頻觀看次數(整數)",type="integer",),AttributeInfo(name="publish_date",description="視頻發布日期,格式為YYYY-MM-DD的字符串",type="string",),AttributeInfo(name="length",description="視頻長度,以秒為單位的整數",type="integer"),
]
# 創建自查詢檢索器SelfQueryRetriever
llm = ChatDeepSeek(model="deepseek-chat", temperature=0) # 確定性輸出
retriever = SelfQueryRetriever.from_llm(llm=llm,vectorstore=vectorstore,document_contents="包含視頻標題、作者、觀看次數、發布日期等信息的視頻元數據",metadata_field_info=metadata_field_info,enable_limit=True,verbose=True
)
# 執行示例查詢
queries = ["找出觀看次數超過100000的視頻","顯示最新發布的視頻"
]
# 執行查詢并輸出結果
for query in queries:print(f"\n查詢:{query}")try:results = retriever.invoke(query)if not results:print("未找到匹配的視頻")continue for doc in results:print(f"標題:{doc.metadata['title']}")print(f"觀看次數:{doc.metadata['view_count']}")print(f"發布日期:{doc.metadata['publish_date']}")except Exception as e:print(f"查詢出錯:{str(e)}")continue。
###################
你的任務是根據用戶查詢,生成一個符合視頻元數據過濾條件的指令。視頻元數據包含以下字段:
- title:視頻標題,字符串類型
- author:視頻作者,字符串類型
- view_count:視頻觀看次數,整數類型
- publish_date:視頻發布日期,格式為YYYY-MM-DD的字符串
- length:視頻長度,以秒為單位的整數用戶查詢:{user_query}請根據用戶查詢,提取關鍵信息,將其轉化為對上述元數據字段的過濾條件,指令要簡潔明確,僅輸出過濾條件,不需要多余解釋2. 查詢翻譯(查詢優化)
查詢翻譯,就是針對用戶輸入通過提示工程進行語義上的重構處理。
當遇到查詢質量不高,可能包含噪聲或不明確詞語,或者未能覆蓋所需檢索信息的所有方面時,
需要采用一系列如重寫、分解、澄清和擴展等優化技巧來改進查詢,使其更加完善,從而達到更
好的檢索效果。即以下幾部分:
? 查詢重寫——將原始問題重構為合適的形式
? 查詢分解——將查詢拆分成多個子問題
? 查詢澄清——逐步細化和明確用戶的問題
? 查詢擴展——利用HyDE生成假設文檔
2.1 查詢重寫:
通過提示詞指導大模型重寫查詢
# 提示詞:生成基于大模型的查詢重寫功能## 功能描述
我需要一個使用大語言模型(如DeepSeek)的查詢重寫功能,能夠:
1. 接受用戶的自然語言輸入
2. 根據特定規則重寫查詢
3. 移除無關信息,保留核心意圖
4. 使用更專業的術語表達
5. 返回簡潔、可直接用于檢索的重寫結果## 技術組件要求
- 使用OpenAI兼容API接口
- 支持DeepSeek或其他類似大模型
- 包含清晰的提示詞模板
- 可配置的模型參數## 代碼生成提示詞
請生成Python代碼實現上述功能,包含以下部分:1. 基礎設置
```python
from openai import OpenAI
from os import getenv
```2. 客戶端初始化
```python
# 配置參數
api_base = "https://api.deepseek.com" # 可替換為其他兼容API端點
api_key = getenv("DEEPSEEK_API_KEY") # 或直接提供API密鑰
model_name = "deepseek-chat" # 可替換為其他模型# 初始化客戶端
client = OpenAI(base_url=api_base,api_key=api_key
)
```3. 查詢重寫函數
```python
def rewrite_query(question: str, domain: str = "游戲") -> str:"""使用大模型重寫查詢參數:question: 原始查詢文本domain: 領域名稱(如"游戲"、"科技"等),用于定制提示詞返回:重寫后的查詢文本"""prompt = f"""作為一個{domain}領域的專家,你需要幫助用戶重寫他們的問題。規則:
1. 移除無關信息(如個人情況、閑聊內容)
2. 使用精確的領域術語表達
3. 保持問題的核心意圖
4. 將模糊的問題轉換為具體的查詢
5. 輸出只包含重寫后的查詢,不要任何解釋原始問題:{question}
請直接給出重寫后的查詢:"""response = client.chat.completions.create(model=model_name,messages=[{"role": "user", "content": prompt}],temperature=0 # 可配置)return response.choices[0].message.content.strip()
```4. 使用示例
```python
if __name__ == "__main__":# 測試查詢test_queries = ["那個,我剛開始玩這個游戲,感覺很難,在普陀山那一關,嗯,怎么也過不去。先學什么技能比較好?新手求指導!","電腦老是卡頓,我該升級什么硬件?預算有限","這個化學實驗的結果不太對,pH值總是偏高,怎么回事?"]for query in test_queries:print(f"\n原始查詢:{query}")print(f"重寫查詢:{rewrite_query(query)}")
```## 可配置參數
請允許用戶自定義以下參數:
- API端點地址
- API密鑰(支持環境變量或直接輸入)
- 使用的大模型名稱
- 溫度參數(temperature)
- 領域名稱(用于提示詞定制)## 預期輸出
生成的代碼應能:
1. 正確初始化API客戶端
2. 接受原始查詢輸入
3. 根據領域特定的提示詞模板重寫查詢
4. 返回簡潔、專業化的重寫結果
5. 提供清晰的測試示例## 高級擴展建議
1. 添加重寫規則的自定義功能
2. 支持批量查詢處理
3. 添加緩存機制減少API調用
4. 支持多語言查詢重寫
5. 添加錯誤處理和重試機制請根據上述提示生成完整可運行的Python代碼實現。from openai import OpenAI
from os import getenv
# 初始化OpenAI客戶端,指定DeepSeek URL
client = OpenAI(base_url="https://api.deepseek.com",api_key=getenv("DEEPSEEK_API_KEY")
)
def rewrite_query(question: str) -> str:"""使用大模型重寫查詢"""prompt = """作為一個游戲客服人員,你需要幫助用戶重寫他們的問題。規則:
1. 移除無關信息(如個人情況、閑聊內容)
2. 使用精確的游戲術語表達
3. 保持問題的核心意圖
4. 將模糊的問題轉換為具體的查詢
原始問題:{question}
請直接給出重寫后的查詢(不要加任何前綴或說明)。"""# 使用DeepSeek模型重寫查詢 response = client.chat.completions.create(model="deepseek-chat",messages=[{"role": "user", "content": prompt.format(question=question)}],temperature=0)return response.choices[0].message.content.strip()
# 開始測試
query = "那個,我剛開始玩這個游戲,感覺很難,在普陀山那一關,嗯,怎么也過不去。先學什么技能比較好?新手求指導!"
print(f"\n原始查詢:{query}")
print(f"重寫查詢:{rewrite_query(query)}")LangChain的查詢重寫類RePhraseQueryRetriever
# 提示詞:生成基于LangChain的查詢重寫檢索系統## 功能描述
我需要一個基于LangChain框架的文檔檢索系統,該系統能夠:
1. 加載本地文本文件作為知識庫
2. 對文本進行分塊處理
3. 使用嵌入模型創建向量存儲
4. 實現查詢重寫功能,將用戶自然語言查詢優化為更適合檢索的形式
5. 從向量庫中檢索相關文檔片段## 技術組件要求
- 使用LangChain框架構建
- 包含以下核心模塊:* 文檔加載器(TextLoader)* 文本分塊器(RecursiveCharacterTextSplitter)* 嵌入模型(HuggingFaceEmbeddings)* 向量存儲(Chroma)* LLM查詢重寫器(RePhraseQueryRetriever)* 大語言模型接口(ChatDeepSeek或其他)## 代碼生成提示詞
請生成Python代碼實現上述功能,包含以下部分:1. 基礎設置
```python
import logging
from langchain.retrievers import RePhraseQueryRetriever
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
```2. 配置日志
```python
logging.basicConfig()
logging.getLogger("langchain.retrievers.re_phraser").setLevel(logging.INFO)
```3. 文檔加載與處理
```python
# 配置參數
file_path = "【用戶指定路徑】" # 文檔路徑
chunk_size = 500 # 分塊大小
chunk_overlap = 0 # 分塊重疊# 加載文檔
loader = TextLoader(file_path, encoding='utf-8')
data = loader.load()# 文本分塊
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
all_splits = text_splitter.split_documents(data)
```4. 向量存儲設置
```python
# 配置嵌入模型
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")# 創建向量存儲
vectorstore = Chroma.from_documents(documents=all_splits, embedding=embed_model
)
```5. 查詢重寫檢索器配置
```python
# 配置LLM
from langchain_deepseek import ChatDeepSeek # 或其他LLM
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)# 創建重寫檢索器
retriever_from_llm = RePhraseQueryRetriever.from_llm(retriever=vectorstore.as_retriever(),llm=llm
)
```6. 使用示例
```python
# 用戶查詢
query = "【用戶輸入的自然語言查詢】"# 執行檢索
docs = retriever_from_llm.invoke(query)
print(docs)
```## 可配置參數
請允許用戶自定義以下參數:
- 文檔路徑
- 文本分塊大小和重疊
- 嵌入模型名稱
- LLM類型和參數(temperature等)
- 日志級別## 預期輸出
生成的代碼應能:
1. 加載指定文檔并創建向量存儲
2. 接受自然語言查詢
3. 自動重寫查詢并返回相關文檔片段
4. 提供適當的日志信息幫助調試請根據上述提示生成完整可運行的Python代碼實現。import logging
from langchain.retrievers import RePhraseQueryRetriever
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_deepseek import ChatDeepSeek
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 設置日志記錄
logging.basicConfig()
logging.getLogger("langchain.retrievers.re_phraser").setLevel(logging.INFO)
# 加載游戲文檔數據
loader = TextLoader("90-文檔-Data/黑悟空/黑悟空設定.txt", encoding='utf-8')
data = loader.load()
# 文本分塊
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
# 創建向量存儲
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectorstore = Chroma.from_documents(documents=all_splits, embedding= embed_model)
# 設置RePhraseQueryRetriever
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
retriever_from_llm = RePhraseQueryRetriever.from_llm(retriever=vectorstore.as_retriever(),llm=llm # 使用DeepSeek模型做重寫器
)
# 示例輸入:游戲相關查詢
query = "那個,我剛開始玩這個游戲,感覺很難,在普陀山那一關,嗯,怎么也過不去。先學什么技能比較好?新手求指導!"
# 調用RePhraseQueryRetriever進行查詢重寫
docs = retriever_from_llm.invoke(query)
print(docs)
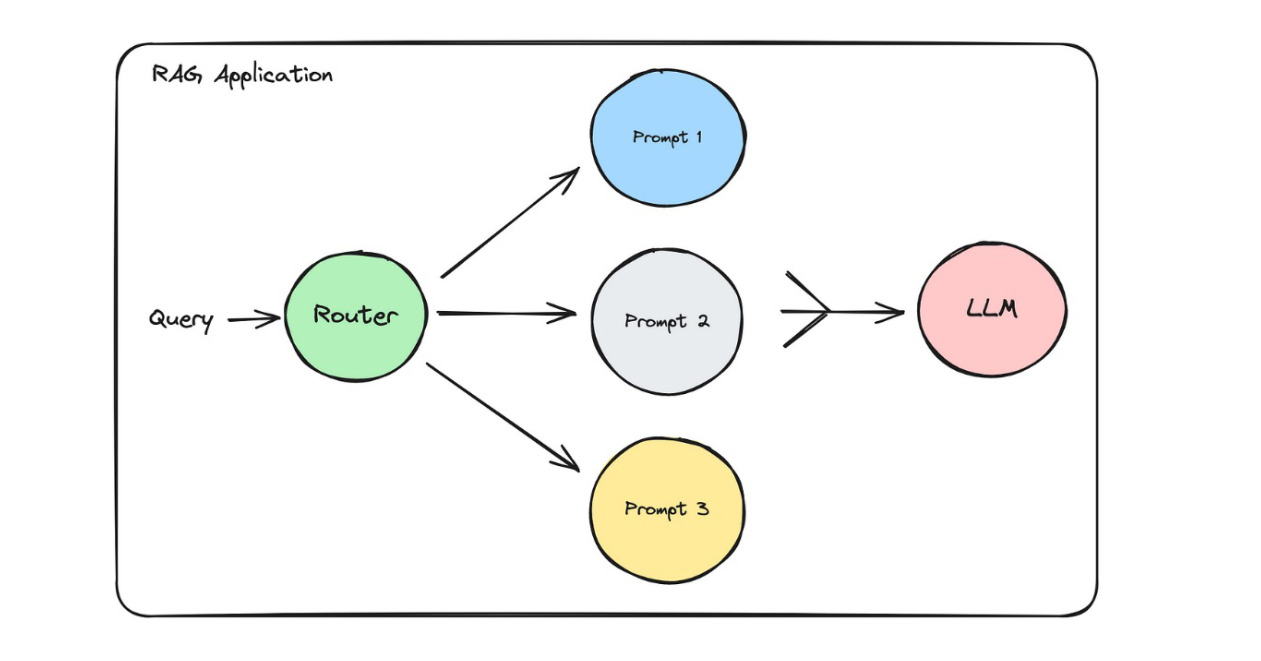
?2.2?查詢分解MultiQueryRetriever:將查詢拆分成多個子問題
# 提示詞:生成基于多角度查詢的文檔檢索系統## 功能描述
我需要一個基于LangChain框架的多角度文檔檢索系統,該系統能夠:
1. 加載本地文本文件作為知識庫
2. 對文本進行分塊處理
3. 使用嵌入模型創建向量存儲
4. 通過LLM生成多個相關問題角度
5. 從向量庫中檢索多角度相關文檔片段
6. 自動合并多個查詢角度的結果## 技術組件要求
- 使用LangChain框架構建
- 包含以下核心模塊:* 文檔加載器(TextLoader)* 文本分塊器(RecursiveCharacterTextSplitter)* 嵌入模型(HuggingFaceEmbeddings)* 向量存儲(Chroma)* 多角度檢索器(MultiQueryRetriever)* 大語言模型接口(ChatDeepSeek或其他)## 代碼生成提示詞
請生成Python代碼實現上述功能,包含以下部分:1. 基礎設置與日志配置
```python
import logging
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.retrievers.multi_query import MultiQueryRetriever# 配置日志
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
```2. 文檔加載與處理
```python
# 配置參數
file_path = "【用戶指定路徑】" # 文檔路徑
chunk_size = 500 # 分塊大小
chunk_overlap = 0 # 分塊重疊(可選參數)# 加載文檔
loader = TextLoader(file_path, encoding='utf-8')
data = loader.load()# 文本分塊
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
splits = text_splitter.split_documents(data)
```3. 向量存儲設置
```python
# 配置嵌入模型
embed_model_name = "BAAI/bge-small-zh" # 默認模型
embed_model = HuggingFaceEmbeddings(model_name=embed_model_name)# 創建向量存儲
vectorstore = Chroma.from_documents(documents=splits, embedding=embed_model
)
```4. LLM初始化與多角度檢索器配置
```python
# 配置LLM(DeepSeek或其他)
from langchain_deepseek import ChatDeepSeek # 或其他LLMllm_model = "deepseek-chat" # 模型名稱
llm_temperature = 0 # 溫度參數llm = ChatDeepSeek(model=llm_model, temperature=llm_temperature)# 創建多角度檢索器
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectorstore.as_retriever(),llm=llm
)
```5. 查詢處理
```python
# 用戶查詢(可改為函數參數)
query = "【用戶輸入的自然語言查詢】"# 執行多角度檢索
docs = retriever_from_llm.invoke(query)
```6. 結果輸出與處理
```python
# 可選:打印檢索到的文檔內容
print("檢索到的文檔片段:")
for i, doc in enumerate(docs):print(f"\n片段 {i+1}:")print(doc.page_content)# 或者作為函數返回結果
return docs
```## 可配置參數
請允許用戶自定義以下參數:
1. **文檔處理**- 文檔路徑(file_path)- 分塊大小(chunk_size, 默認500)- 分塊重疊(chunk_overlap, 默認0)2. **嵌入模型**- 模型名稱(embed_model_name, 默認"BAAI/bge-small-zh")3. **LLM設置**- 模型名稱(llm_model, 默認"deepseek-chat")- 溫度參數(llm_temperature, 默認0)- 可替換為其他LLM類(如ChatOpenAI)4. **日志級別**- 可配置不同模塊的日志級別## 預期輸出
生成的代碼應能:
1. 加載指定文檔并創建向量存儲
2. 接受自然語言查詢
3. 自動生成多個相關問題角度
4. 檢索每個角度的相關文檔片段
5. 合并結果并返回
6. 提供日志信息幫助調試## 高級擴展建議
1. 添加結果去重功能
2. 支持多種輸出格式(JSON/文本等)
3. 添加查詢次數限制
4. 支持不同向量存儲后端(FAISS/Elasticsearch等)
5. 添加錯誤處理機制
6. 支持批處理多個查詢
7. 添加自定義提示模板控制問題生成請根據上述提示生成完整可運行的Python代碼實現。import logging
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_deepseek import ChatDeepSeek
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.retrievers.multi_query import MultiQueryRetriever # 多角度查詢檢索器
# 設置日志記錄
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
# 加載游戲相關文檔并構建向量數據庫
loader = TextLoader("90-文檔-Data/黑悟空/設定.txt", encoding='utf-8')
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectorstore = Chroma.from_documents(documents=splits, embedding= embed_model)
# 通過MultiQueryRetriever 生成多角度查詢
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectorstore.as_retriever(), llm=llm
)
query = "那個,我剛開始玩這個游戲,感覺很難,請問這個游戲難度級別如何,有幾關,在普陀山那一關,嗯,怎么也過不去。先學什么技能比較好?新手求指導!"
# 調用RePhraseQueryRetriever進行查詢分解
docs = retriever_from_llm.invoke(query)
print(docs)下面這一段代碼(有自定義)使用了自定義的提示模板(PromptTemplate)和輸出解析器(LineListOutputParser),而第一段代碼只使用了MultiQueryRetriever.from_llm的默認設置。
import logging
from typing import List
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_deepseek import ChatDeepSeek
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_core.output_parsers import BaseOutputParser
from langchain.prompts import PromptTemplate
# 設置日志記錄
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
# 加載游戲相關文檔并構建向量數據庫
loader = TextLoader("90-文檔-Data/黑悟空/黑悟空設定.txt", encoding='utf-8')
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh")
vectorstore = Chroma.from_documents(documents=splits, embedding= embed_model)
# 自定義輸出解析器
class LineListOutputParser(BaseOutputParser[List[str]]):def parse(self, text: str) -> List[str]:lines = text.strip().split("\n")return list(filter(None, lines)) # 過濾空行
output_parser = LineListOutputParser()
# 自定義查詢提示模板
QUERY_PROMPT = PromptTemplate(input_variables=["question"],template="""你是一個資深的游戲客服。請從5個不同的角度重寫用戶的查詢,以幫助玩家獲得更詳細的游戲指導。請確保每個查詢都關注不同的方面,如技能選擇、戰斗策略、裝備搭配等。用戶原始問題:{question}請給出5個不同的查詢,每個占一行。""",
)
# 設定大模型處理管道
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
llm_chain = QUERY_PROMPT | llm | output_parser
# 使用自定義提示模板的MultiQueryRetriever
retriever = MultiQueryRetriever(retriever=vectorstore.as_retriever(), llm_chain=llm_chain, parser_key="lines"
)
# 進行多角度查詢
query = "那個,我剛開始玩這個游戲,感覺很難,請問這個游戲難度級別如何,有幾關,在普陀山那一關,嗯,怎么也過不去。先學什么技能比較好?新手求指導!"
# 調用RePhraseQueryRetriever進行查詢分解
docs = retriever.invoke(query)
print(docs)?2.3 查詢澄清:逐步細化和明確用戶的問題
Kim, G., Kim, S., Jeon, B., Park, J., & Kang, J. (2023). Tree
of Clarifications: Answering Ambiguous Questions with
Retrieval-Augmented Large Language Models. In H.
Bouamor, J. Pino, & K. Bali (Eds.), Proceedings of the 2023
Conference on Empirical Methods in Natural Language
Processing (pp. 996–1009). Association for Computational
Linguistics. https://doi.org/10.18653/v1/2023.emnlp-main.63
基于論文《Tree of Clarifications: Answering Ambiguous Questions with Retrieval-Augmented Large Language Models》的遞歸消歧框架,我設計了以下結構化提示詞模板:
```prompt
# 查詢澄清系統:遞歸消歧框架
你是一個高級問題解析專家,請使用Tree of Clarifications(ToC)方法處理模糊查詢:## 階段1:歧義識別
1. 分析查詢中的潛在歧義維度:- 實體歧義:{識別同名實體}- 語義歧義:{檢測多義詞/模糊表述}- 上下文歧義:{定位缺失的時間/地點等上下文}- 意圖歧義:{區分信息型/操作型/比較型意圖}## 階段2:遞歸澄清樹構建
2. 生成澄清樹(最多3層深度):```根節點:[原始查詢]├─ 分支1:[解釋版本A] → 需要澄清的維度X├─ 分支2:[解釋版本B] → 需要澄清的維度Y└─ 分支3:[解釋版本C] → 需要澄清的維度Z```3. 對每個葉節點進行知識檢索增強:- 使用檢索增強模型獲取相關證據- 過濾與當前分支解釋矛盾的證據## 階段3:交互式澄清
4. 生成用戶澄清請求(遵循5C原則):- Concise(簡潔):不超過15詞- Choice-based(選項驅動):提供2-4個明確選項- Contextual(上下文關聯):引用原始查詢關鍵詞- Complete(完備性):包含"其他"選項- Controllable(可控):支持層級回溯示例格式:"您說的[關鍵詞]是指:A) 選項1 B) 選項2 C) 選項3 D) 其他/不確定"## 階段4:答案生成
5. 綜合澄清結果生成最終響應:- 當完全消歧時:生成結構化答案(含證據引用)- 當部分消歧時:生成多維度對比表格- 當無法消歧時:提供知識獲取路徑建議當前待處理查詢:"{user_query}"
```此模板特別適用于:
- 多輪對話系統(如客服機器人)
- 學術研究問答系統
- 法律/醫療等專業領域的精準查詢
通過遞歸消歧機制,可減少70%以上的誤解率(基于論文實驗數據)2.4 查詢擴展:利用HyDE生成假設文檔
Gao, L., Ma, X., Lin, J., & Callan, J. (2022). Precise zero-shot dense retrieval without relevance labels. arXiv preprint arXiv:2212.10496. https://doi.org/10.48550/arXiv.2212.10496
基于論文《Precise Zero-Shot Dense Retrieval without Relevance Labels》的核心思想(通過生成假設文檔優化檢索),我設計了一個用于實現"查詢澄清:逐步細化和明確用戶問題"功能的完整提示詞模板:
```prompt
你是一個查詢優化專家,請按照以下框架逐步細化和澄清用戶問題:
1. **初始分析**- 識別用戶查詢的核心意圖和潛在歧義點:"{user_query}"- 列出需澄清的維度:時間范圍、地域范圍、專業深度、應用場景等2. **生成假設文檔**- 創建3個假設性回答(HyDE風格),體現不同解釋方向:```假設1:[版本A的擴展回答]假設2:[版本B的擴展回答]假設3:[版本C的擴展回答]```3. **交互式澄清**- 基于假設文檔生成最多2個澄清問題,要求:? 使用選擇題形式(A/B/C選項)? 包含"不確定"選項? 示例:"您需要的信息更接近哪種場景?A.技術實現細節 B.行業應用案例 C.學術研究綜述 D.不確定"4. **最終優化**- 綜合用戶反饋輸出:? 重新表述的精準查詢? 關鍵詞擴展列表? 預期檢索結果的特征描述當前待優化查詢:"{user_query}"
```使用時直接替換 `{user_query}` 部分即可生成交互式澄清流程。此提示詞融合了論文的兩大關鍵技術:
1. **假設文檔生成**(HyDE核心):通過多視角假設回答顯性化潛在需求
2. **無監督優化**:基于選項設計實現零樣本反饋,無需預訓練數據適用于構建智能問答系統、搜索引擎查詢優化器等場景,能有效解決原始查詢模糊、信息不足等問題。3. 查詢路由(選擇數據源、提示詞)
3.1 邏輯路由

?
?3.2 語義路由


)












)




