【1】引言
pytorch是深度學習常用的包,顧名思義,就是python適用的torch包,在python里面使用時直接import torch就可以調用。
需要注意的是,pytorch包與電腦配置、python版本有很大關系,一定要仔細閱讀安裝要求、找到教程后再安裝。由于已經有很多詳細指導教程,這里就不再班門弄斧。
本文的寫作目的是記錄pytorch的基本運算、以備不時之需,歡迎大家一起學習和討論。
大家也可以到pytorch的官網教程地址自主學習:Learning PyTorch with Examples — PyTorch Tutorials 2.7.0+cu126 documentation
【2】基本運算
【2.1】導入包
導入包的操作非常簡單,和其他包的導入一模一樣:
# 導入包
import torch【2.2】生成隨機張量
pytorch支持生成隨機張量,和numpy包的操作一樣,代碼:
# 導入包
import torch
# 定義隨機量
x=torch.randn(3,4)
# 打印
print(x)這里定義了一個3行4列且符合標準正態分布的隨機矩陣,運算后的結果為:
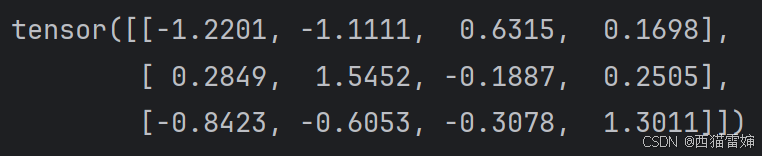
圖1 torch.randn(3,4)?
關于torch.randn()函數的說明,可以通過官網教程進一步加深理解:
torch.randn — PyTorch 2.7 documentation
torch.randn(*size, *, generator=None, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False, pin_memory=False) → Tensor
torch.randn()函數的?具體參數:
- size,隨機數矩陣/張量的行列尺寸
- generator=None,隨機數生成器,一般無需設置
- out=None,輸出張量,默認為沒有,一般無需設置
- dtype=None,生成隨機數矩陣/張量的數據類型,一般無需設置,會默認跟隨全局數據類型自動調整
- layout=torch.strided,輸出矩陣/張量的布局形式,一般默認即可,都是大家熟悉的矩陣樣式
- device=None,和電腦配置相關,一般無需設置
- requires_grad=False,grad是求導操作,只要要求導的時候才會用
- pin_memory=False,在內存中給張量分配空間,僅適用CPU張量,一般無需設置
【2.3】生成多維張量
pytorch支持生成多維張量,代碼:
# 導入包
import torch
# 生成多為維張量
y=torch.tensor([[1,2,3,4],[5,6,7,8],[1,3,5,7]])
#打印
print('y=',y)
# 生成空張量
z=torch.tensor([])
#打印
print('z=',z)這里只調用了一個函數torch.tensor(),在函數中使用方括號“[]”可以直接定義張量,運算后的結果為:

?圖2 torch.tensor([]
關于torch.tensor()函數的說明,可以通過官網教程進一步加深理解:
torch.tensor — PyTorch 2.7 documentation
torch.tensor(data, *, dtype=None, device=None, requires_grad=False, pin_memory=False) → Tensor?
torch.tensor()函數的?具體參數:
- data,張量的初始數據。可以是列表、元組、NumPy ndarray、標量和其他類型
- dtype=None,生成隨機數矩陣/張量的數據類型,一般無需設置,會默認跟隨全局數據類型自動調整
- device=None,和電腦配置相關,一般無需設置
- requires_grad=False,grad是求導操作,只要要求導的時候才會用
- pin_memory=False,在內存中給張量分配空間,僅適用CPU張量,一般無需設置
【2.4】張量變形
pytorch支持張量變形運算,代碼:
# 導入包
import torch
# 生成多為維張量
y=torch.tensor([[1,2,3,4],[5,6,7,8],[1,3,5,7]])
#打印
print('y=',y)
# 變形
y=y.reshape(2,6)
# 打印
print('y=',y)這里只調用了一個函數reshape(),原始張量是3行4列,reshape之后變化成2行6列,運算后的結果為:
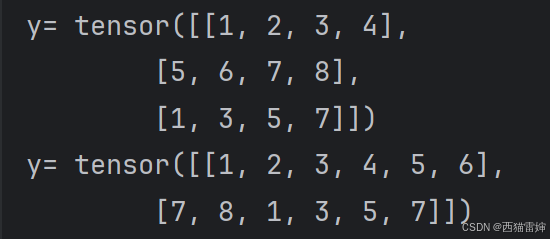
?圖3 reshape()
這里使用的reshape()函數是通過張量加點的形式直接調用,torch包也允許通過torch.reshape()的形式進行變形,官網鏈接為:
torch.reshape — PyTorch 2.7 documentation
這里的調用形式為:
torch.reshape(input, shape) → Tensor
?input,待變形的張量
shape,張量變形后的尺寸
可以依據這個形式重寫上述代碼,最后運行效果一樣:
# 導入包
import torch
# 生成多為維張量
y=torch.tensor([[1,2,3,4],[5,6,7,8],[1,3,5,7]])
#打印
print('y=',y)
# 變形
y=torch.reshape(y,(2,6))
# 打印
print('y=',y)【2.5】張量加減
pytorch支持不同張量在同一位置進行加減運算,代碼:
import torch
# 生成多為維張量
a=torch.tensor([[1,2,3,4],[5,6,7,8],[1,3,5,7]])
b=torch.tensor([[1,2,2,3],[5,6,2,8],[1,3,8,7]])
# 打印
print('a',a)
print('b',b)
# 張量加減法
y=a+b
z=a-b
# 打印
print(y)
print(z)代碼運行后:
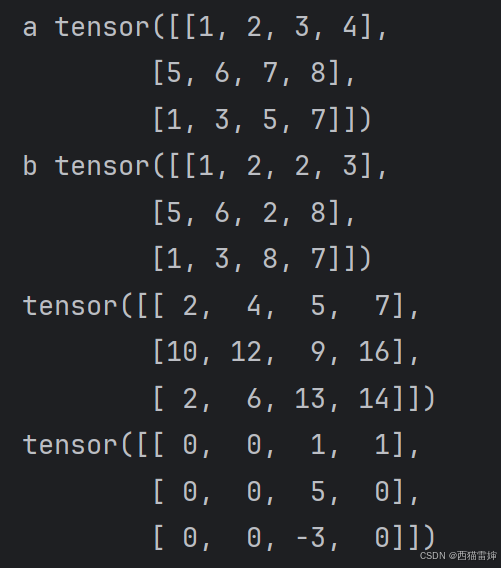
??圖4 加減法
張量加減是在同一位置上進行的,需要提前準備好各個位置上的元素。
如果兩個張量大小不一致,pytorch也能進行加減運算,這就是廣播機制。
【2.6】張量廣播運算?
pytorch支持張量廣播運算,代碼:
# 導入包
import torch
# 生成多為維張量
y=torch.tensor([1,2,3])
z=torch.tensor([[3],[2],[1]
])
#打印
print('y=',y)
print('z=',z)
#
a=y+z
print('a=',a)代碼非常清楚,y是行向量,z是列向量,這兩個張量形式上完全不一樣,所以直接看運算效果來反推pytorch是如何廣播的:
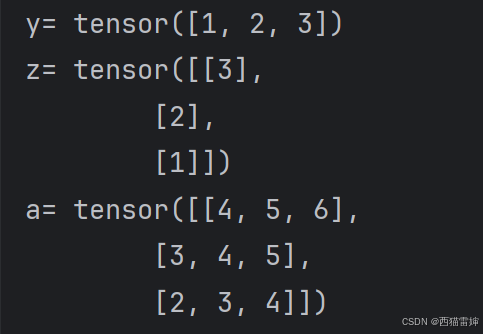
?圖5 廣播-加法
計算結果表明,行向量y按照行廣播,列向量z按照列廣播,廣播后變成同等大小的張量,然后對相同位置的各個元素進行疊加。
可以使用以下代碼測試:
# 導入包
import torch
# 生成多為維張量
y=torch.tensor([[1,2,3],[1,2,3],[1,2,3]])
z=torch.tensor([[3,3,3],[2,2,2],[1,1,1]
])
#打印
print('y=',y)
print('z=',z)
#
a=y+z
print('a=',a)代碼運行效果:

?圖6 加法?
對比圖5和圖6,運算效果一致。
在張量尺寸大小不一致時,pytorch進行加減法運算時自動執行廣播運算,在保證兩個張量外形尺寸一致后,再對同一位置的元素進行加減運算。
【3】總結
探索了部分pytorch的基本運算。?

第5章析因設計引導5.7節思考題5.11 R語言解題)















![[網頁五子棋][用戶模塊]客戶端開發(登錄功能和注冊功能)](http://pic.xiahunao.cn/[網頁五子棋][用戶模塊]客戶端開發(登錄功能和注冊功能))

)