深入理解Transformer架構:從原理到實踐
引言
Transformer架構自2017年由Google在論文《Attention Is All You Need》中提出以來,已經徹底改變了自然語言處理(NLP)領域,并逐漸擴展到計算機視覺、語音識別等多個領域。本文將深入解析Transformer的核心原理、關鍵組件以及現代變體,幫助讀者全面理解這一革命性架構。
一、Transformer誕生的背景
在Transformer出現之前,自然語言處理主要依賴以下架構:
- RNN(循環神經網絡):處理序列數據,但難以并行化且存在長程依賴問題
- LSTM/GRU:改進的RNN,緩解梯度消失問題,但仍無法完全解決長序列建模
- CNN(卷積神經網絡):可以并行處理,但難以捕獲全局依賴關系
Transformer的創新在于:
- 完全基于注意力機制,摒棄了傳統的循環和卷積結構
- 實現了高效的并行計算
- 能夠直接建模任意距離的依賴關系
二、Transformer核心架構
1. 整體架構概覽
Transformer采用編碼器-解碼器結構(也可單獨使用):
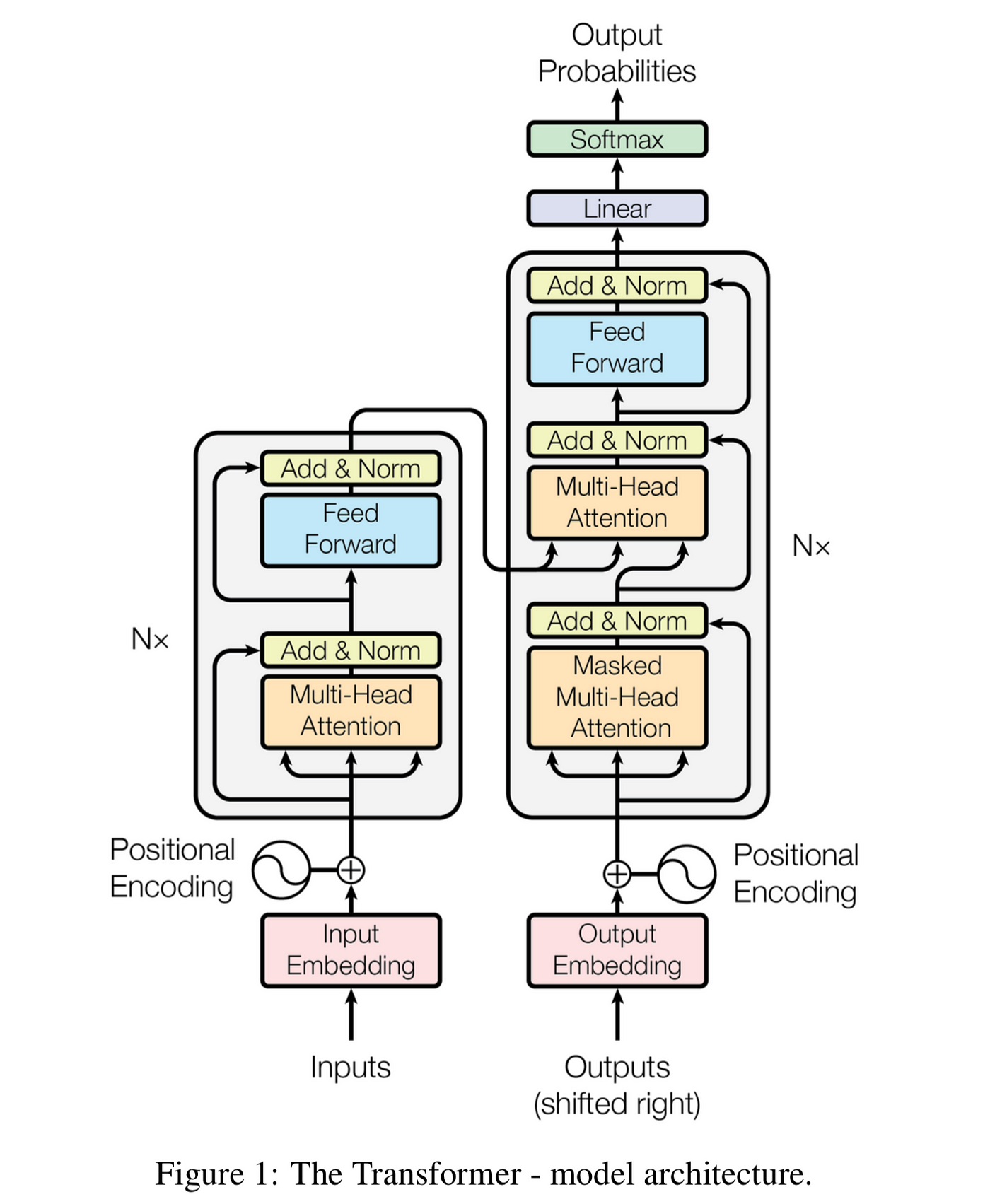
主要組件:
- 輸入嵌入(Input Embedding)
- 位置編碼(Positional Encoding)
- 多頭注意力機制(Multi-Head Attention)
- 前饋網絡(Feed Forward Network)
- 殘差連接(Residual Connection)和層歸一化(Layer Normalization)
2. 關鍵組件詳解
2.1 自注意力機制(Self-Attention)
自注意力是Transformer的核心,計算過程可分為三步:
1. 計算Q、K、V矩陣:
Q = X * W_Q # 查詢(Query)
K = X * W_K # 鍵(Key)
V = X * W_V # 值(Value)
2. 計算注意力分數:
scores = Q * K^T / sqrt(d_k) # d_k是key的維度
3. 應用softmax和加權求和:
attention = softmax(scores) * V
數學表達:
[ Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V ]
2.2 多頭注意力(Multi-Head Attention)
將自注意力機制并行執行多次,增強模型捕捉不同位置關系的能力:
MultiHead(Q,K,V) = Concat(head_1,...,head_h)W^O
where head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)
優勢:
- 允許模型共同關注來自不同位置的不同表示子空間的信息
- 提高模型的表達能力
2.3 位置編碼(Positional Encoding)
由于Transformer沒有循環或卷積結構,需要顯式注入位置信息:
[ PE_{(pos,2i)} = sin(pos/10000^{2i/d_{model}}) ]
[ PE_{(pos,2i+1)} = cos(pos/10000^{2i/d_{model}}) ]
特點:
- 可以表示絕對和相對位置
- 可以擴展到比訓練時更長的序列
2.4 前饋網絡(Feed Forward Network)
由兩個線性變換和一個ReLU激活組成:
[ FFN(x) = max(0, xW_1 + b_1)W_2 + b_2 ]
2.5 殘差連接和層歸一化
每個子層都有殘差連接和層歸一化:
[ LayerNorm(x + Sublayer(x)) ]
作用:
- 緩解梯度消失問題
- 加速模型訓練
- 提高模型穩定性
三、Transformer工作流程
1. 編碼器(Encoder)流程
- 輸入序列經過輸入嵌入層
- 加上位置編碼
- 通過N個相同的編碼器層(每層包含:
- 多頭自注意力
- 前饋網絡
- 殘差連接和層歸一化)
- 輸出上下文相關的表示
2. 解碼器(Decoder)流程
- 目標序列經過輸出嵌入層
- 加上位置編碼
- 通過N個相同的解碼器層(每層包含:
- 帶掩碼的多頭自注意力(防止看到未來信息)
- 多頭編碼器-解碼器注意力
- 前饋網絡
- 殘差連接和層歸一化)
- 通過線性層和softmax生成輸出概率
四、Transformer的現代變體
1. BERT (Bidirectional Encoder Representations)
特點:
- 僅使用編碼器
- 雙向上下文建模
- 使用掩碼語言模型(MLM)和下一句預測(NSP)預訓練
2. GPT (Generative Pre-trained Transformer)
特點:
- 僅使用解碼器
- 自回歸生成
- 使用單向上下文建模
3. Vision Transformer (ViT)
特點:
- 將圖像分割為patch序列
- 應用標準Transformer編碼器
- 在計算機視覺任務中表現優異
4. Transformer-XH
改進:
- 相對位置編碼
- 更高效處理長序列
5. Efficient Transformers
包括:
- Reformer (局部敏感哈希注意力)
- Linformer (低秩投影)
- Performer (基于核的注意力近似)
五、Transformer的優勢與局限
優勢:
- 強大的序列建模能力
- 高效的并行計算
- 可擴展性強(模型大小、數據量)
- 靈活的架構設計
局限:
- 計算復雜度高(O(n2)的注意力計算)
- 內存消耗大
- 對位置編碼的依賴
- 小數據集上容易過擬合
六、實踐建議
-
預訓練模型選擇:
- 文本分類:BERT
- 文本生成:GPT
- 跨模態任務:UNITER、VL-BERT
-
處理長序列:
- 使用稀疏注意力變體
- 分塊處理
- 內存優化技術
-
訓練技巧:
- 學習率預熱
- 梯度裁剪
- 標簽平滑
-
部署優化:
- 模型量化
- 知識蒸餾
- 模型剪枝
七、未來發展方向
- 更高效的注意力機制
- 多模態統一架構
- 更強的記憶和推理能力
- 與神經符號系統的結合
- 更綠色的AI(減少計算資源消耗)
結語
Transformer架構已經成為現代AI的基礎構建塊,理解其核心原理和變體對于從事AI研究和應用開發至關重要。隨著技術的不斷發展,Transformer家族仍在快速進化,持續推動著人工智能的邊界。掌握這一架構不僅能幫助你在當前任務中獲得更好表現,也為理解和適應未來的模型發展奠定了基礎。
希望本文能幫助你建立起對Transformer架構的系統性理解。在實際應用中,建議從經典實現開始,逐步探索更高級的變體和優化技術。




![[網頁五子棋][用戶模塊]客戶端開發(登錄功能和注冊功能)](http://pic.xiahunao.cn/[網頁五子棋][用戶模塊]客戶端開發(登錄功能和注冊功能))

)



)
)







