AI 數據采集實戰指南:基于Bright Data快速獲取招標訊息
在招標行業中,快速、準確地獲取招標公告、項目詳情、投標截止日期和其他關鍵招標信息,是投標企業提高競標成功率的核心競爭力。然而,招標信息往往分散在不同的平臺和網頁,數據格式復雜多變,且常常面臨反爬機制如 IP 限制、驗證碼挑戰,人工收集效率低、成本高。

在實際業務中,假設有一家企業希望及時監測主流招標網站上的最新公告和項目信息,如項目名稱、預算金額、截止日期等關鍵內容。然而,由于這些平臺普遍設置了反爬機制,包括 IP 限制、驗證碼驗證以及動態頁面加載等傳統數據采集技術難以攻克的問題,企業在實際數據采集中往往面臨較大的技術挑戰。
常見網絡爬蟲挑戰及 亮數據 的技術解決方案
在進行大規模網絡數據抓取時,經常會遇到 IP 地址限制、驗證碼攔截以及目標網站數據結構復雜等難題。下面針對這些常見問題,以技術角度介紹亮數據平臺提供的解決方案和相關特性。
IP 限制與頻繁封禁
許多網站針對來自單一 IP 地址的異常流量會實施頻率限制或直接封禁,這使傳統使用固定 IP 或單一代理的爬蟲方案容易失效。
**亮數據的解決方案:**亮數據提供了自動 IP 輪換功能(IP Rotation)。該平臺通過其全球分布的代理節點網絡,在連續的請求之間自動切換不同的 IP 地址,使每次請求看起來來自不同來源,從而降低被目標網站識別為爬蟲的風險。這種代理池輪換機制有效緩解了頻繁封禁的問題,開發者無需手動管理代理列表,即可提高爬取的穩定性。
驗證碼與反爬機制
很多目標網站使用驗證碼(包括圖形驗證碼、滑動驗證等)和其他反爬蟲機制來阻止自動腳本訪問。這些機制會要求復雜的人機驗證步驟,給爬蟲腳本帶來極大挑戰。
**亮數據的解決方案:**亮數據集成了自動驗證碼識別和處理功能,能夠在無需人工干預的情況下繞過各類驗證碼挑戰。例如,當遇到圖形驗證碼或 reCAPTCHA 時,Bright Data 的爬取引擎可以自動識別并提交正確的驗證響應,使數據抓取流程不中斷。此外,該平臺支持對動態網頁的 JavaScript 渲染。這意味著 Bright Data 的爬蟲能夠像瀏覽器一樣執行頁面中的 JavaScript 腳本,拿到渲染后的完整內容,再提取所需數據。借助這些功能,Bright Data 可以應對復雜的反爬措施,確保動態加載的內容也能夠順利獲取。
數據結構復雜
不同網站往往有各自獨特且復雜的頁面結構和數據格式。手工針對每個站點編寫解析代碼不僅耗時低效,也容易出錯,難以適應頁面結構的變化。
**亮數據的解決方案:**亮數據提供了自動數據發現(Data Discovery)功能,用于智能解析頁面結構并提取數據。具體而言,該功能會自動檢測網頁中的數據模式和層次結構,定位所需的信息字段,然后將其提取為結構化的數據格式(如 JSON、CSV)。開發者無需手動編寫復雜的 DOM 解析和選擇器邏輯,就能獲取到所需的數據。這種智能提取機制不僅提高了開發效率,也減少了因為頁面布局改變而導致爬蟲失效的維護工作。
亮數據IDE
亮數據還提供了可視化 IDE(網頁抓取工具 IDE),該 IDE 集成了預置爬蟲模板、交互式預覽和內置調試工具,使得開發者可以在瀏覽器中可視化地構建和測試爬蟲腳本。同時,官方也支持主流編程語言(如 Python、JavaScript、Java 等)調用 API,提高了開發靈活性。Bright Data
核心功能方面,亮數據網頁抓取 API 提供了豐富的企業級能力:自動IP輪換、驗證碼解決、用戶代理輪換、JS渲染、數據解析和驗證 等功能一應俱全。例如,它可以自動處理常見的反爬機制——無論是動態渲染頁面還是出現滑動驗證碼,都能夠自動繞過;同時支持一次性批量請求數千條 URL、并發抓取任務無限制。Bright Data 的爬蟲 API 能夠將結果以結構化的 JSON、NDJSON 或 CSV 格式返回,極大地簡化了數據后續處理。通過后臺還支持 Webhook 將數據推送到外部存儲(如 S3、GCS 等),靈活嵌入現有流水線中。
##實際使用場景示例
步驟一
通過 官網注冊賬戶并獲取 API 密鑰,設置所需的權限,例如 IP 自動輪換和驗證碼解決。
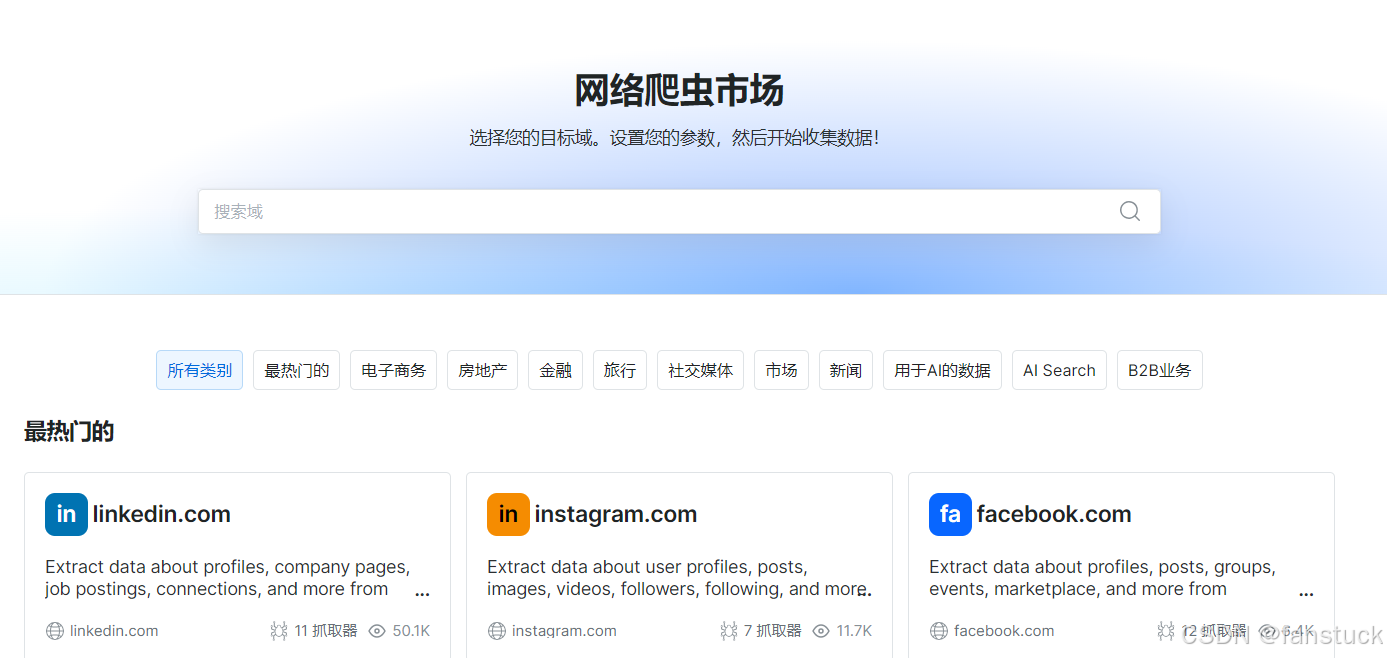
步驟二:確定監測目標
明確需要抓取的招標網站,整理出 URL 列表,如果沒有目標網站可以在網絡爬蟲市場獲取到相關領域的URL提供參考:
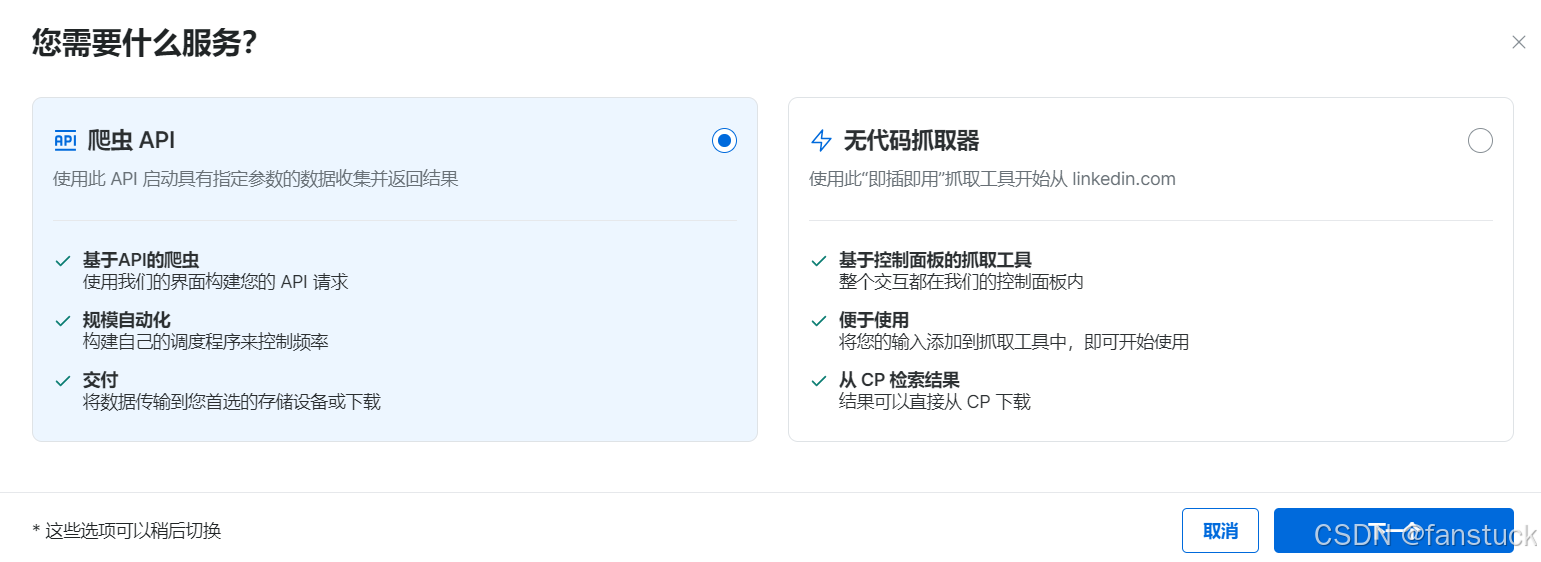
如果有目標的網站直接點擊即可獲取到服務:
步驟三:調用 Bright Data API 抓取數據
使用 Python 編寫請求腳本啟動數據抓取:
import requestsurl = "https://api.brightdata.com/request"payload = {"zone": "default","url": target_url,"format": "json","method": "GET","country": "CN","dns": "local"
}
headers = {"Authorization": "Bearer YOUR_API_KEY","Content-Type": "application/json"
}response = requests.request("POST", url, json=payload, headers=headers)
data = response.json()
步驟四:下載和處理抓取的數據
獲取的數據已結構化為 JSON 格式,便于后續分析。
import pandas as pd# 轉換為 DataFrame
results = pd.json_normalize(data)
如果需要存儲更多數據集,推薦直接進入數據集市獲取數據樣本:
步驟五:數據存儲及分析應用
將數據存儲于企業內部數據庫或導出為 CSV,用于進一步的數據分析和業務決策支持:
results.to_csv('bidding_data.csv', index=False)

開發者可以在本地代碼中快速編寫請求腳本并觸發爬蟲任務。Bright Data 將返回一個 snapshot_id,表示異步抓取任務已開始。隨后,我們可以使用此 ID 拉取結果數據:
# 等待任務完成后,下載結果數據
download_url = f"https://api.brightdata.com/datasets/v3/result/{snapshot_id}"
res = requests.get(download_url, headers=headers)
data = res.json() # 結構化的抓取結果返回的數據為 JSON 格式(也可選 CSV/NDJSON),包含了職位名稱、公司、描述等字段。我們可遍歷 data["items"] 等字段,將內容保存或導入數據庫。
任務調度: 對于大規模數據采集,可將上述腳本部署到服務器并使用 定時任務(如 Linux crontab、Apache Airflow、Celery 等) 定期運行。例如,每天凌晨抓取一次最新職位信息,確保訓練數據的時效性。此外,Bright Data 還支持通過 Webhook 自動將結果推送到指定存儲(如 Amazon S3、Google Cloud Storage 等),方便與數據管道集成。
數據存儲與結構化輸出: 亮數據 輸出的數據已是結構化格式,可直接加載到數據處理流程中。例如,我們可以將 JSON 結果轉為 Pandas DataFrame,清洗后導出 CSV 供機器學習使用。數據字段已經分列(職位名、公司名、地點、發布時間、職位描述等),無需額外解析,大幅縮減了后處理工作量。
技術特性與適用能力分析
反封鎖機制支持
亮數據提供了基于全球代理池的 IP 和用戶代理輪換機制,用于降低被目標網站識別為自動訪問的風險。平臺集成了驗證碼識別功能,在應對滑動驗證、圖形驗證碼等交互式攔截機制時,具備自動處理能力,適用于反爬策略較為復雜的網站。
任務擴展與穩定性支持
其 API 設計支持高并發請求處理,能夠在一次任務中批量抓取大量頁面數據。平臺具備可擴展基礎設施,可根據流量需求自動擴容抓取任務,適用于大規模數據采集應用場景。根據公開說明,系統穩定性達到高可用標準,適合對抓取成功率有較高要求的任務部署。
解析與運維成本優化
亮數據支持自動化的數據字段識別與結構化提取功能,開發者可減少手動編寫 DOM 提取邏輯的工作量。此外,平臺為云端托管架構,省去了構建代理池、瀏覽器渲染環境等底層組件配置的需求,適合資源有限或希望快速集成數據采集能力的團隊使用。
結構化數據輸出與合規性說明
返回數據經過結構化處理,支持標準格式如 JSON、CSV 輸出,便于后續集成至數據處理流程中。根據平臺披露,其服務遵循包括 GDPR、CCPA 在內的主要隱私合規要求,并在相關法律爭議中獲得了對其抓取合法性的認可。開發者在數據合規處理方面可參考其合規文檔與實踐建議。
適用場景示例
亮數據的爬蟲服務可應用于多種場景,如招聘信息采集、市場行情監控、評論情感分析、價格變動追蹤等。其腳本結構可復用,通過修改目標 URL 即可切換任務類型,適用于構建靈活的通用數據采集工具鏈。
Bright Data
綜上所述,亮數據的網頁抓取工具憑借全面的特性和高可用性,為開發者提供了一站式的爬蟲解決方案。實際使用中,我們體驗到開發效率顯著提升,很多繁瑣的反爬對策都由平臺自動完成。它解決了傳統爬蟲中常見的 IP 封鎖、反爬墻、復雜結構解析 等難題,同時保持高度的擴展性和合規性。對于需要快速構建訓練數據管道和開展數據驅動業務的團隊來說,Bright Data Web Scraper 是一個值得嘗試的利器。







——基于雙dq坐標系的六相/雙三相PMSM驅動控制)


)


)


詳解)
在AI中的應用)

