prometheus實戰之三:告警規則_驗證prometheus告警規則-CSDN博客
Prometheus是一款開源的系統監控和告警工具,其告警功能是保障系統穩定運行的重要部分。以下將從告警的整體架構、核心概念、規則配置以及具體的通知流程等方面對Prometheus中的告警進行介紹。
告警架構
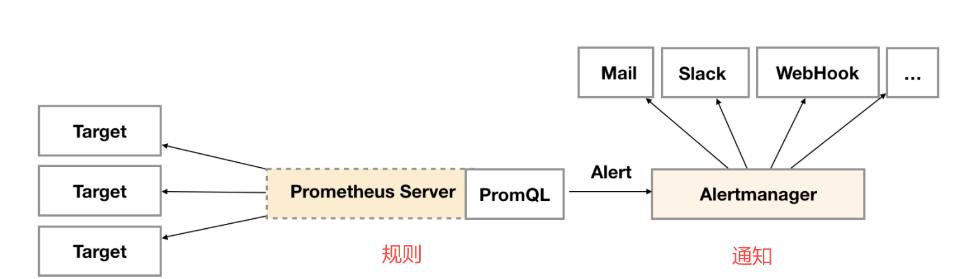
Prometheus的告警管理分為兩部分。首先,在Prometheus服務端設置告警規則,Prometheus服務器端會基于這些規則對采集到的監控數據進行評估,當滿足告警條件時,就會向Alertmanager發送告警。然后,由Alertmanager負責管理這些告警,包括靜默、抑制、聚合以及通過電子郵件、PagerDuty和HipChat等方法發送通知。
核心概念
- 分組(Grouping):分組是將類似性質的告警分類為單個通知的機制。在大型中斷期間,例如網絡分區導致許多服務實例無法訪問數據庫,Prometheus中針對每個服務實例的告警規則會被觸發,數百個告警發送到Alertmanager。此時,可將Alertmanager配置為按群集和alertname對警報進行分組,這樣用戶就能收到單個緊湊通知,同時確切了解哪些服務實例受到影響。通知的接收器通過配置文件中的路由樹來配置告警分組,并定時進行分組通知。
- 抑制(Inhibition):如果某些特定的告警已經觸發,那么可以配置Alertmanager抑制其他相關告警。例如,當某個告警觸發表示無法訪問整個集群時,可讓Alertmanager在該特定告警觸發時,將與該集群有關的所有其他告警靜音,防止收到數百或數千個與實際問題無關的告警通知。
- 靜默(Silences):靜默是在給定時間內簡單地靜音告警的方法。基于匹配器配置靜默,就像路由樹一樣。檢查告警是否匹配或者正則表達式匹配靜默,如果匹配,則不會發送該告警的通知。可以在Alertmanager的Web界面中配置靜默。
global:resolve_timeout: 5m # 告警解決后等待5分鐘標記為已解決route:receiver: 'default-receiver'group_by: ['alertname']group_wait: 30sgroup_interval: 5mrepeat_interval: 12hreceivers:
- name: 'default-receiver'email_configs:- to: 'ops@example.com'inhibit_rules:
- source_match:alertname: 'ClusterCritical'target_match:cluster: '{{ .labels.cluster }}'equal: ['cluster']# 預定義靜默(可選,通常通過Web界面動態管理)
silences:
- matchers:- name: 'env'value: 'staging'startsAt: '2023-10-05T09:00:00Z'endsAt: '2023-10-05T18:00:00Z'comment: 'Staging environment maintenance'
關鍵說明
- 分組(Grouping):通過
group_by標簽組合告警,減少通知數量;group_wait和group_interval控制合并策略。 - 抑制(Inhibition):通過父子告警關系屏蔽次要信息,需確保
source_match和target_match的標簽關聯。 - 靜默(Silences):臨時屏蔽告警,支持動態配置(Web 界面)和靜態配置(文件),適合計劃內維護或臨時故障屏蔽。
告警規則配置
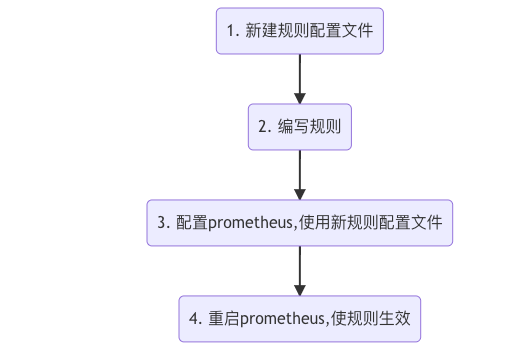
一條告警規則主要由以下幾部分組成:
- alert:告警規則的名稱,用于唯一標識該告警規則。
- expr:用于進行報警規則的PromQL查詢語句,通過該語句定義告警觸發的條件。例如,設定CPU利用率、內存使用量等性能指標的閾值,當指標在某個時間段內多次觸發該閾值時,視為滿足告警條件。
- for:評估等待時間(Pending Duration),表示只有當觸發條件持續一段時間后才發送告警,在等待期間新產生的告警狀態為pending。
- labels:自定義標簽,允許用戶指定額外的標簽列表,把它們附加在告警上,用于對告警進行分類和標識。
- annotations:指定了另一組標簽,它們不被當做告警實例的身份標識,通常用于存儲一些額外的信息,如告警的描述、解決方法等,用于報警信息的展示。
告警通知流程
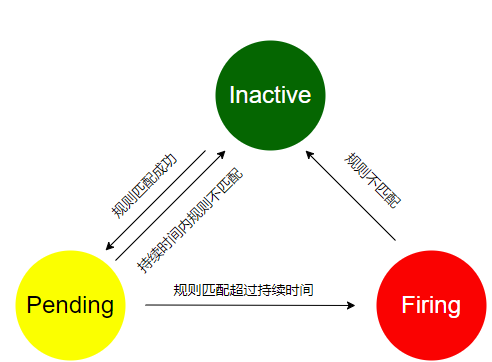
Prometheus以scrape_interval(默認為1m)的規則周期從監控目標上收集信息,并將監控信息持久存儲在其本地存儲上。然后以evaluation_interval(默認為1m)的規則周期對告警規則做定期計算。當表達式為真時,告警狀態切換到pending,若在下個計算周期表達式仍為真,且符合for持續時間,告警狀態變更為active,并將告警從Prometheus發送給Alertmanager。Alertmanager接收告警后,根據配置的路由規則、抑制規則和靜默規則等對告警進行處理,最終將告警通過配置好的通知方式發送給相關人員。
例子
以下是一些Prometheus告警規則的例子:
- 實例宕機告警
- alert: InstanceDownexpr: up == 0for: 1mlabels:serverity: pageannotations:summary: "Instance {{ $labels.instance }} down"description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minute."
- **規則內容**:
- **解釋**:用于檢測job的狀態,當持續1分鐘獲取不到指標數據(即 `up == 0`)時,觸發告警,將告警發送給Alertmanager。
- CPU使用率過高告警
- name: docker_alertsrules:- alert: HighCPUUsageexpr: sum(rate(container_cpu_usage_seconds_total{image!=""}[1m])) / sum(machine_cpu_cores) > 0.9labels:severity: criticalannotations:description: "The container {{ $labels.container_name }} is using more than 90% of CPU for over 1 minute."
- **規則內容**:
- **解釋**:通過計算容器的CPU使用率,當容器的CPU使用率超過90%并持續1分鐘時,觸發 `HighCPUUsage` 告警。
- 內存使用率過高告警
- alert: MemoryUsageHighexpr: ((node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes) * 100 > 80labels:severity: warningannotations:summary: "Memory usage is high"description: "Memory usage on {{ $labels.instance }} is above 80%."
- **規則內容**:
- **解釋**:計算主機的內存使用率,當內存使用率超過80%時觸發告警。
- 接口請求異常告警
- alert: InterfaceRequestExceptionexpr: http_server_requests_seconds_count{exception!="", job="<app_name>", method="<method>", uri="<uri>"} > 0for: 5mlabels:severity: errorannotations:summary: "Interface request exception"description: "There is an exception in the interface request of job {{ $labels.job }}, method {{ $labels.method }}, uri {{ $labels.uri }}."
- **規則內容**:
- **解釋**:當指定應用(`<app_name>`)、指定方法(`<method>`)和指定接口地址(`<uri>`)的請求出現異常,且異常持續5分鐘時觸發告警。
總結
Prometheus中的告警機制通過靈活的規則配置和強大的Alertmanager組件,能夠幫助用戶及時發現系統中的問題,并有效地管理和處理告警信息,從而保障系統的穩定運行。
詳解)
在AI中的應用)


![[學習]C語言指針函數與函數指針詳解(代碼示例)](http://pic.xiahunao.cn/[學習]C語言指針函數與函數指針詳解(代碼示例))



 out of order)
-資源映射)
Java/python/JavaScript/C/C++/GO最佳實現)
)




| 字符串(線性結構))


