簡介
LangGraph 是一個強大的對話流程編排框架,而 Mem0 則是一個高效的記憶系統。本教程將介紹如何將兩者結合,創建一個具有記憶能力的客服助手系統。
環境準備
首先安裝必要的依賴:
pip install langgraph mem0 langchain openai
基礎配置
1. 導入必要的模塊
from openai import OpenAI
from mem0 import Memory
from mem0.configs.base import MemoryConfig
from mem0.embeddings.configs import EmbedderConfig
from mem0.llms.configs import LlmConfig
from typing import Annotated, TypedDict, List
from langgraph.graph import StateGraph, START
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
2. 配置基礎參數
# 集中管理配置
API_KEY = "your-api-key"
BASE_URL = "your-base-url"# 配置 LLM
llm = ChatOpenAI(temperature=0,openai_api_key=API_KEY,openai_api_base=BASE_URL,model="qwen-turbo"
)# 配置 Mem0
config = MemoryConfig(llm = LlmConfig(provider="openai",config={"model": "qwen-turbo","api_key": API_KEY,"openai_base_url": BASE_URL}),embedder = EmbedderConfig(provider="openai",config={"embedding_dims": 1536,"model": "text-embedding-v2","api_key": API_KEY,"openai_base_url": BASE_URL})
)
核心概念解析
1. 狀態定義
在 LangGraph 中,我們需要定義對話狀態:
class State(TypedDict):messages: Annotated[List[HumanMessage | AIMessage], add_messages]mem0_user_id: str
這個狀態包含:
messages:當前對話的消息列表mem0_user_id:用戶標識,用于 Mem0 記憶檢索
2. 對話節點實現
def chatbot(state: State):messages = state["messages"]user_id = state["mem0_user_id"]# 檢索相關記憶memories = mem0.search(messages[-1].content, user_id=user_id)context = "\n".join([f"- {memory['memory']}" for memory in memories["results"]])# 構建系統提示system_prompt = f"""You are a helpful customer support assistant. Use the provided context to personalize your responses and remember user preferences and past interactions.
Relevant information from previous conversations:
{context}"""# 生成回復并存儲記憶response = llm.invoke([SystemMessage(content=system_prompt)] + messages)mem0.add(f"User: {messages[-1].content}\nAssistant: {response.content}", user_id=user_id)return {"messages": [response]}
3. 圖結構構建
graph = StateGraph(State)
graph.add_node("chatbot", chatbot)
graph.add_edge(START, "chatbot")
graph.add_edge("chatbot", "chatbot")
compiled_graph = graph.compile()
工作流程解析
-
狀態初始化:
- 創建初始狀態,包含用戶消息和用戶ID
- 狀態通過圖結構傳遞給對話節點
-
記憶檢索:
- 使用 Mem0 的 search 方法檢索相關歷史記憶
- 根據語義相似度返回最相關的記憶
-
上下文整合:
- 將檢索到的記憶整合到系統提示中
- 確保 AI 能夠理解歷史上下文
-
響應生成:
- 使用 LLM 生成回復
- 將新的對話內容存儲到 Mem0 中
運行對話
def run_conversation(user_input: str, mem0_user_id: str):config = {"configurable": {"thread_id": mem0_user_id}}state = {"messages": [HumanMessage(content=user_input)], "mem0_user_id": mem0_user_id}for event in compiled_graph.stream(state, config):for value in event.values():if value.get("messages"):print("Customer Support:", value["messages"][-1].content)return
主程序示例
if __name__ == "__main__":mem0_user_id = "customer_123"print("Welcome to Customer Support! How can I assist you today?")while (user_input := input("You: ").lower()) not in ['quit', 'exit', 'bye']:run_conversation(user_input, mem0_user_id)
關鍵特性
-
狀態管理:
- LangGraph 提供了清晰的狀態管理機制
- 支持復雜的對話流程控制
-
記憶檢索:
- Mem0 提供語義化的記憶檢索
- 支持多用戶隔離
-
流程編排:
- 通過圖結構定義對話流程
- 支持靈活的節點擴展
完整代碼與示例
from openai import OpenAI
from mem0 import Memory
from mem0.configs.base import MemoryConfig
from mem0.embeddings.configs import EmbedderConfig
from mem0.llms.configs import LlmConfigfrom langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from typing import List, DictAPI_KEY = "your api key"
BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1"openai_client = OpenAI(api_key=API_KEY,base_url=BASE_URL,
)llm = ChatOpenAI(temperature=0,openai_api_key=API_KEY,openai_api_base=BASE_URL,model="qwen-turbo"
)config = MemoryConfig(llm = LlmConfig(provider="openai",config={"model": "qwen-turbo","api_key": API_KEY,"openai_base_url": BASE_URL}),embedder = EmbedderConfig(provider="openai",config={"embedding_dims": 1536,"model": "text-embedding-v2","api_key": API_KEY,"openai_base_url": BASE_URL})
)mem0 = Memory(config=config)prompt = ChatPromptTemplate.from_messages([SystemMessage(content="""You are a helpful travel agent AI. Use the provided context to personalize your responses and remember user preferences and past interactions. Provide travel recommendations, itinerary suggestions, and answer questions about destinations. If you don't have specific information, you can make general suggestions based on common travel knowledge."""),MessagesPlaceholder(variable_name="context"),HumanMessage(content="{input}")
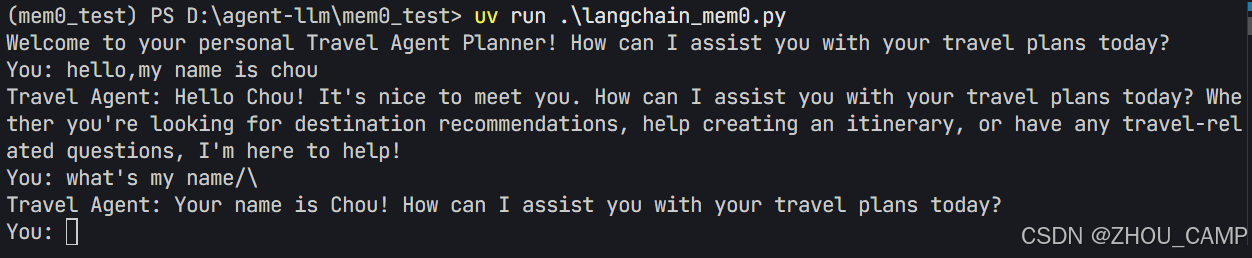
])def retrieve_context(query: str, user_id: str) -> List[Dict]:"""Retrieve relevant context from Mem0"""memories = mem0.search(query, user_id=user_id)seralized_memories = ' '.join([mem["memory"] for mem in memories["results"]])context = [{"role": "system", "content": f"Relevant information: {seralized_memories}"},{"role": "user","content": query}]return contextdef generate_response(input: str, context: List[Dict]) -> str:"""Generate a response using the language model"""chain = prompt | llmresponse = chain.invoke({"context": context,"input": input})return response.contentdef save_interaction(user_id: str, user_input: str, assistant_response: str):"""Save the interaction to Mem0"""interaction = [{"role": "user","content": user_input},{"role": "assistant","content": assistant_response}]mem0.add(interaction, user_id=user_id)def chat_turn(user_input: str, user_id: str) -> str:# Retrieve contextcontext = retrieve_context(user_input, user_id)# Generate responseresponse = generate_response(user_input, context)# Save interactionsave_interaction(user_id, user_input, response)return responseif __name__ == "__main__":print("Welcome to your personal Travel Agent Planner! How can I assist you with your travel plans today?")user_id = "john"while True:user_input = input("You: ")if user_input.lower() in ['quit', 'exit', 'bye']:print("Travel Agent: Thank you for using our travel planning service. Have a great trip!")breakresponse = chat_turn(user_input, user_id)print(f"Travel Agent: {response}")
 out of order)
-資源映射)
Java/python/JavaScript/C/C++/GO最佳實現)
)




| 字符串(線性結構))




:十核異構設計與緩存層次詳解)

)



