Brep2Seq: a dataset and hierarchical deep learning network for reconstruction and generation of computer-aided design models | Journal of Computational Design and Engineering | Oxford Academic






?


 ?
?

 ?
?
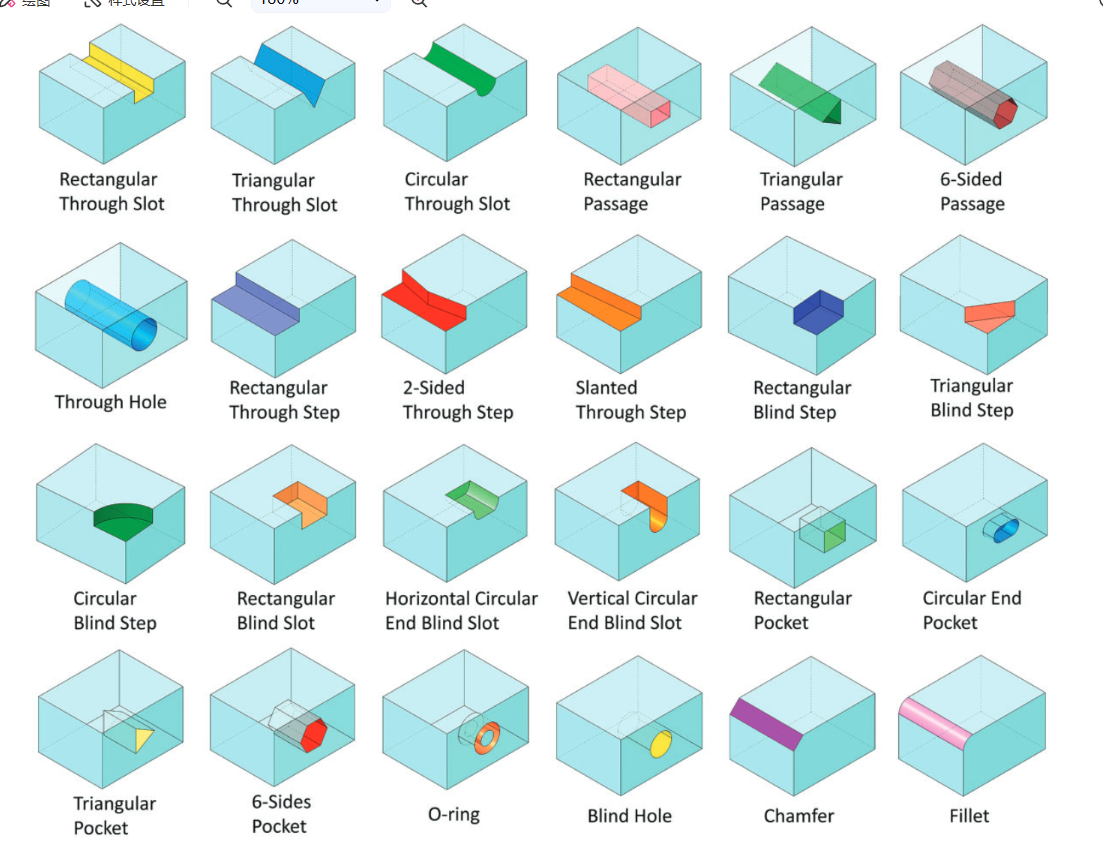
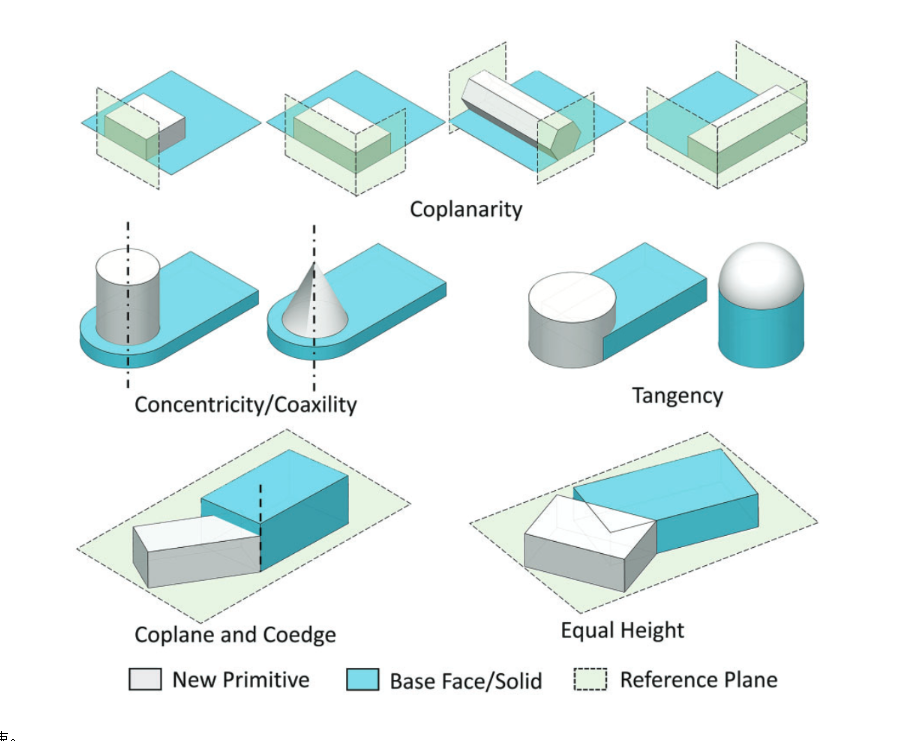
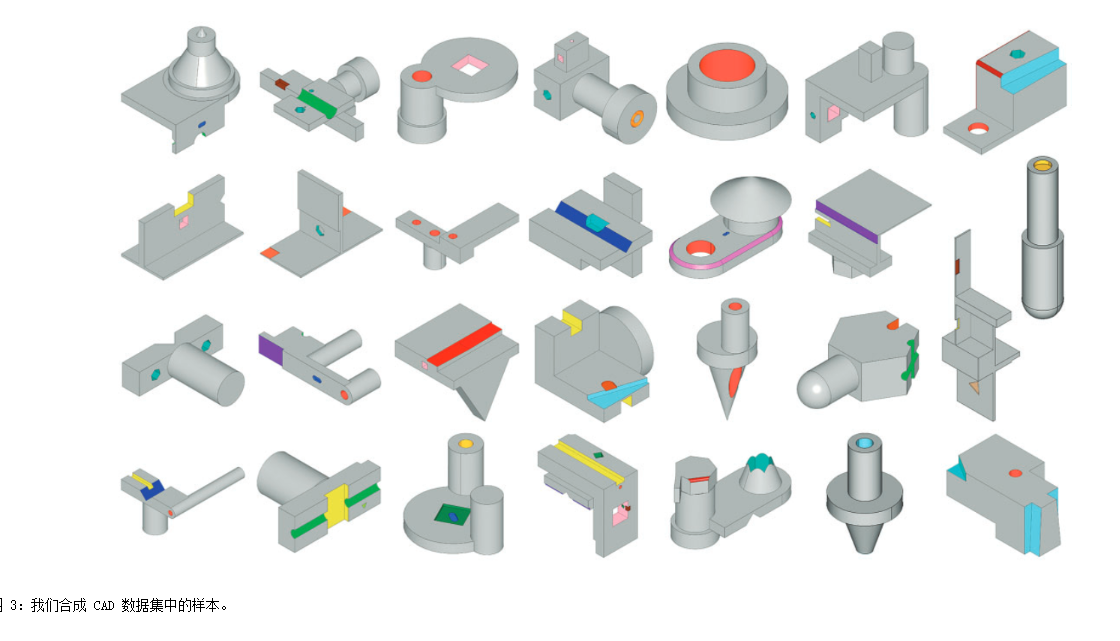
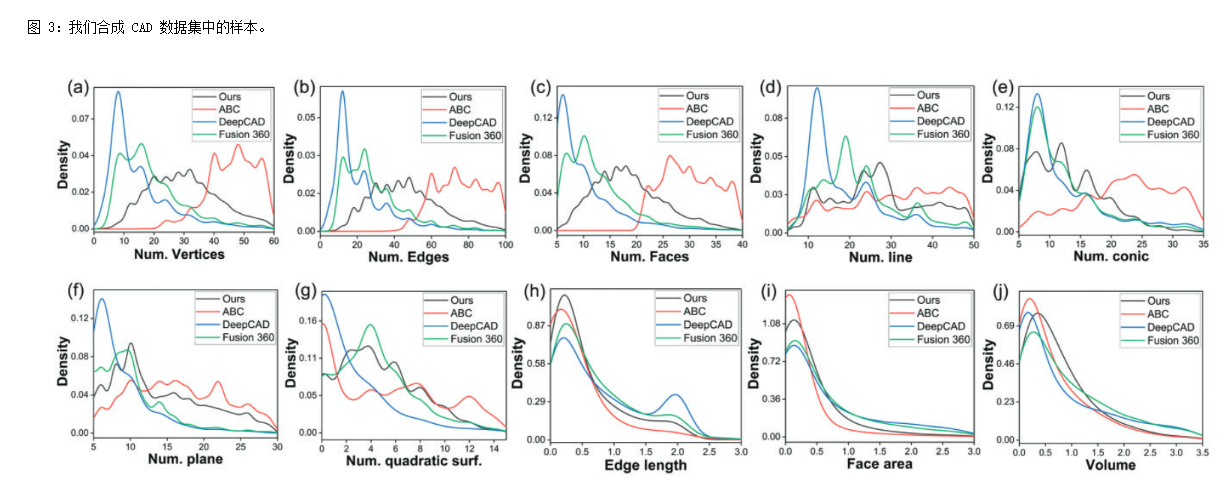


?








 ?
?


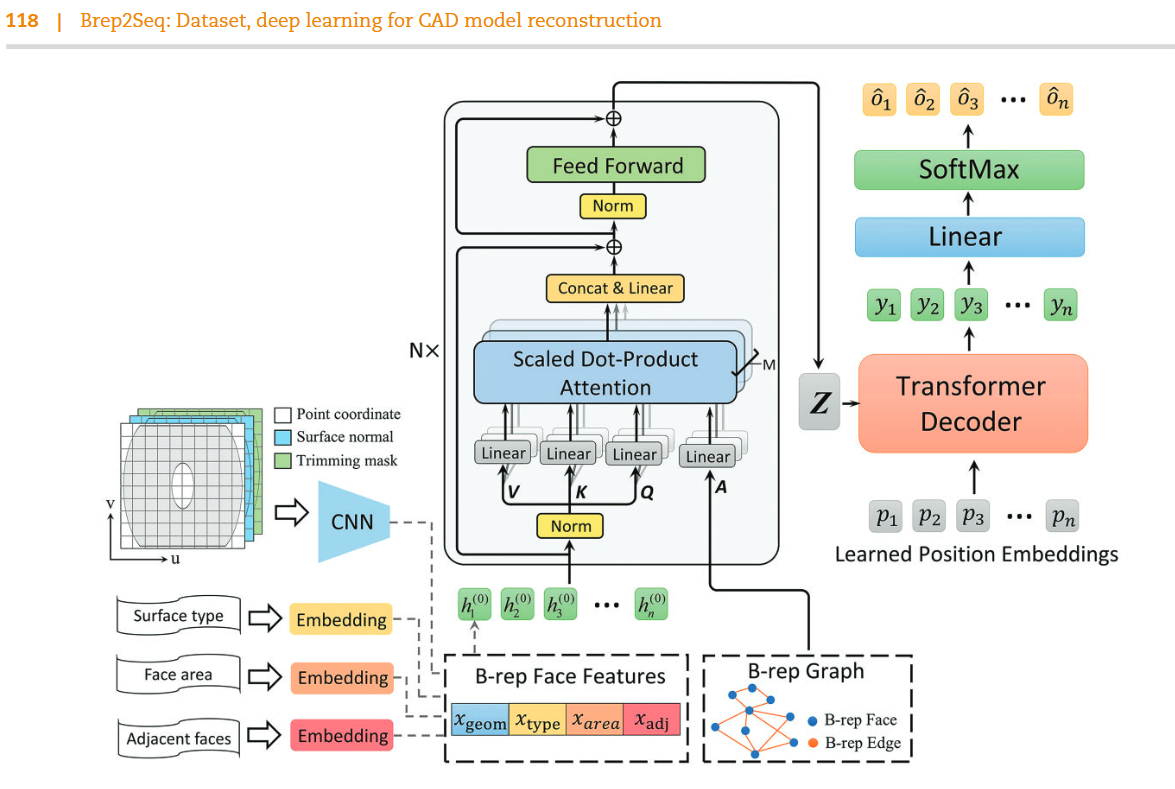
這段文本描述了一個多頭自注意力機制(MultiHead Attention)的實現細節,該機制是Transformer架構中的核心組件之一。以下是公式(14)和(15)及其相關概念的詳細解釋:
公式(14)解析
MultiHead (H): 多頭自注意力機制的輸出。
Concat(head_1, ..., head_M): 將M個獨立的自注意力頭(heads)的輸出進行拼接(concatenation)。每個自注意力頭都會生成一個單獨的特征表示,通過拼接這些表示,可以得到一個更豐富的綜合特征。
W^O: 一個線性變換矩陣,用于將拼接后的特征向量映射到最終的輸出維度。
公式(15)解析
1. head_m = self-att(H, A_1, A_2, A_3):
這部分定義了第m個自注意力頭的計算過程,它依賴于輸入隱藏狀態H以及三個額外的矩陣A_1、A_2和A_3,這些矩陣可能包含了關于節點間關系的特定信息。
2. softmax(...):
計算注意力分數的過程使用了softmax函數,以確保所有注意力分數加起來等于1,從而形成一個有效的概率分布。
注意力分數由以下幾部分組成:
Q_mK_m^T / √d_k: 這是標準的自注意力機制中的點積注意力(Dot-product attention),其中Q_m和K_m分別是查詢(Query)和鍵(Key)矩陣,d_k是它們的維度。這個部分用于衡量不同位置之間的相似度。
A_1(W_a1^m)^T + A_2(W_a2^m)^T + A_3(W_a3^m)^T: 這些項引入了額外的偏置或權重,它們與A_1、A_2和A_3矩陣相乘,并與查詢和鍵的點積結果相加。這可能是為了融入圖結構或其他先驗知識到注意力機制中。
3. V_m:
V_m是值(Value)矩陣,它與注意力分數相乘,以生成最終的輸出特征向量。
4. Q_m, K_m, V_m 的計算:
對于每一個自注意力頭m,查詢Q_m、鍵K_m和值V_m都是通過輸入隱藏狀態H與相應的權重矩陣W_q^m、W_k^m和W_v^m相乘得到的。
總結
每個自注意力頭獨立地計算注意力分數和輸出特征,然后將這些特征拼接在一起并通過一個線性變換層得到最終的多頭自注意力輸出。
通過引入額外的矩陣A_1、A_2和A_3,該機制能夠更好地捕捉和利用輸入數據中的結構化信息,如圖結構中的邊和面的關系。
這種設計使得模型能夠在處理復雜的數據結構時,更加靈活和高效地提取和整合信息。



















等等研究這篇3D CAD model retrieval based on sketch and unsupervised variational autoencoder - ScienceDirect

 out of order)
-資源映射)
Java/python/JavaScript/C/C++/GO最佳實現)
)




| 字符串(線性結構))




:十核異構設計與緩存層次詳解)

)


