前言
這兩天,小米的全新SOC玄戒O1橫空出世,引發了科技數碼圈的一次小地震,那么小米的這顆所謂的自研SOC,內部究竟有著什么不為人知的秘密呢?我們一起一探究竟。
目錄
- 前言
- 1 架構總覽
- 1.1 基本構成
- 1.2 SLC缺席的原因探索
- 2. CPU設計
- 2.1 不同核心之間的差異
- 2.2 多核任務調度策略
- 2.2.1 多核任務調度核心邏輯
- 2.2.2 完全公平調度器
- 2.2.3 能效感知調度
- 2.3 超大核的分支預測方案
- 2.3.1 自適應混合預測算法
- 2.3.2 硬件結構深度優化
- 2.3.3 推測執行與恢復機制
- 2.3.4 AI驅動的動態學習
- 3. 后記
1 架構總覽
1.1 基本構成
隨著諸多科技博主對玄戒O1進行了 “開膛破肚”,這顆芯片的神秘面紗,也被一點點揭開(圖片來自極客灣)。
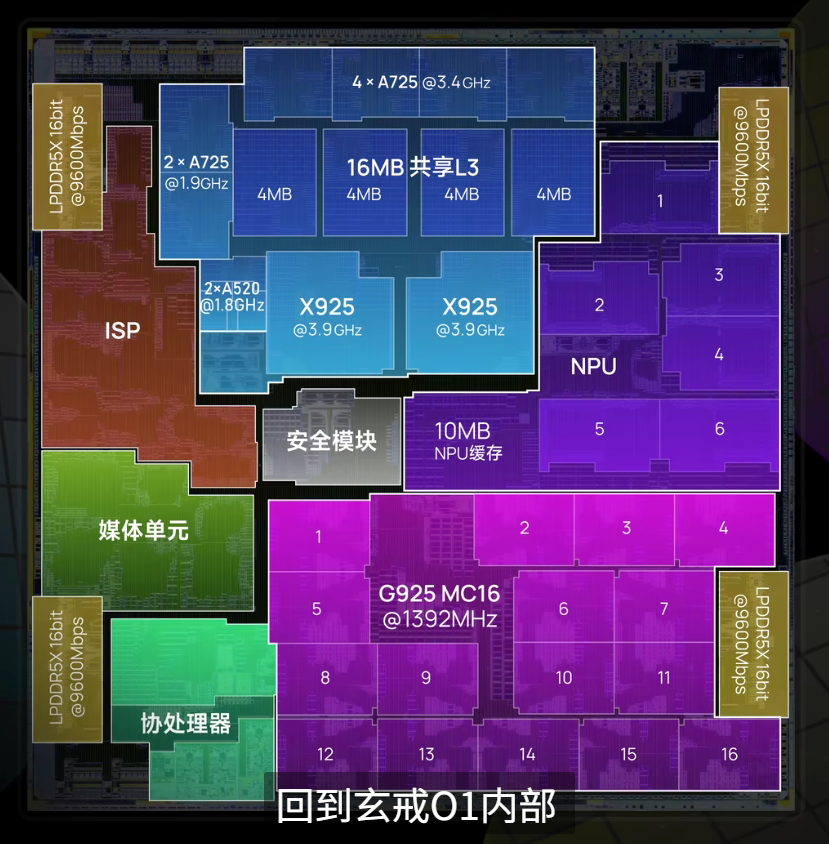
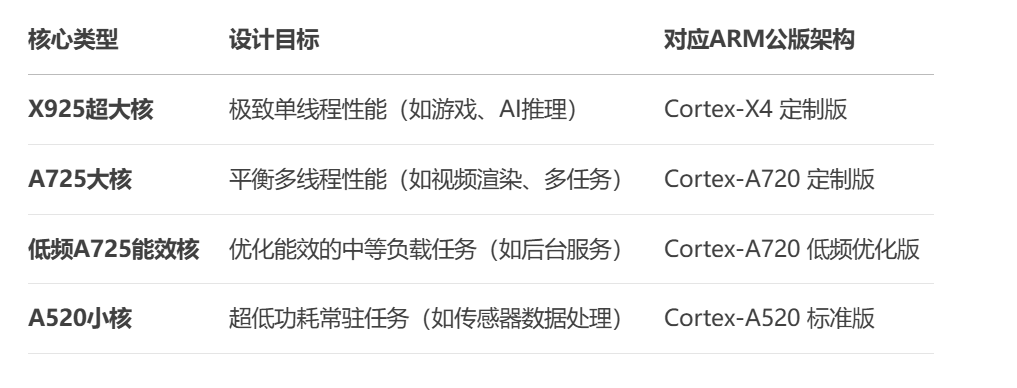
與宣傳一致,玄戒O1采用了先進的臺積電3nm N3E工藝,CPU方面采用了 “2+4+2+2” 十核四叢集架構(2顆X925超大核、4顆A725大核、2顆低頻A725能效核、2顆A520超低功耗核)。各個核心的基本情況如下:
SOC內部沒有分配SLC,而是直接采用了一個16M的L3緩存,外加各個核心專有的L2緩存(關于具體的緩存配置,會在第二章,也就是CPU部分詳細展開)。
GPU配置方面也是相當豪華,搭載了16核ARM G925 GPU(也就是16個計算單元),每個CU包含128個FP32 ALU,總計 16 CU × 128 ALU = 2048個流處理器,按照慣例,還配有紋理單元和光柵化單元,此外共搭載4MB L2緩存。

我們來橫向對比一下這款芯片與“友商”的產品
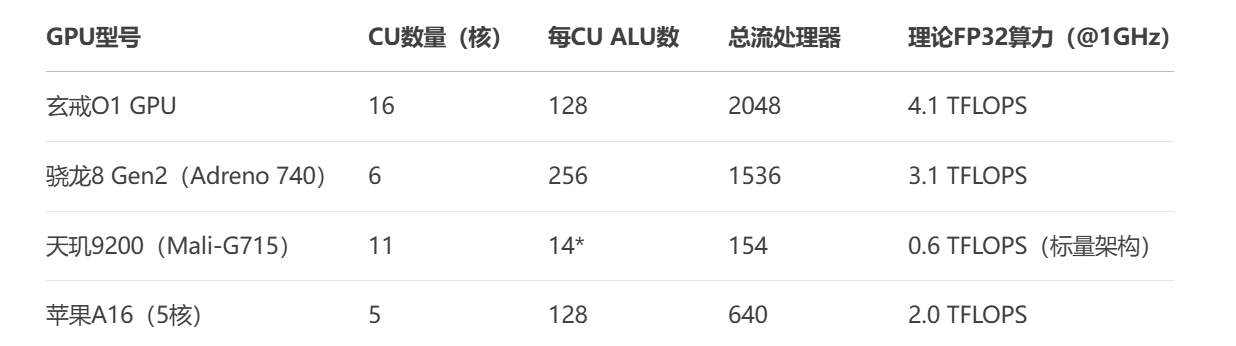
如此對比下來,理論上GPU的性能要比“友商”的產品強出不少。
那么,為什么小米選擇了堆CU數量,而不是堆每CU的ALU數呢?分析下來有以下幾點原因:
- 并行效率優化
任務劃分更靈活:16個CU可獨立處理不同渲染階段(如幾何、像素、計算),降低資源爭搶。
適合移動端負載:手游多為多線程小任務(如粒子效果、后處理),而非單指令大規模計算。
- 功耗與面積平衡
面積成本:每增加1個CU需額外約1.2mm2(4nm工藝),16 CU總面積約19.2mm2。
功耗控制:多CU可動態關閉閑置單元(如關閉8個CU處理UI渲染),比高頻少CU方案更省電。
- 驅動與生態適配
開發者友好:主流圖形API(如Vulkan)更適應多CU的任務分發模式。
工具鏈成熟:高通Adreno架構的調試工具鏈可直接適配,減少開發成本。
玄戒O1的NPU(神經網絡處理單元)是其自研芯片的核心模塊之一,基于小米多年積累的 MACE(Mobile AI Compute Engine)框架演進而來。由6核心外加10MB緩存構成。作為首款完全自研的AI加速器,玄戒O1的NPU在架構設計、能效比和軟硬協同上展現了獨特創新。
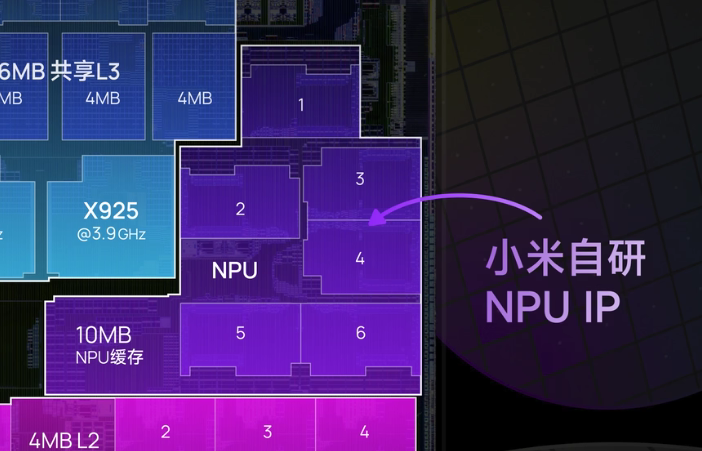
在軟件生態上,同時兼容ONNX、TensorFlow Lite、PyTorch Mobile等神經網絡架構,為軟硬件協同開發提供了有利條件。
較之于所謂的CPU、GPU和NPU,一般的ISP并不會顯得那么吸睛,玄戒O1的ISP(圖像信號處理器)是其影像能力的核心引擎,通過自研架構和軟硬協同優化,實現了從傳感器原始數據到高質量成像的全流程突破。事實上,小米在很多年前,就已經在自研ISP了,最開始是在2017年,搭載在了小米5C上面。后又經幾番迭代,日趨成熟。
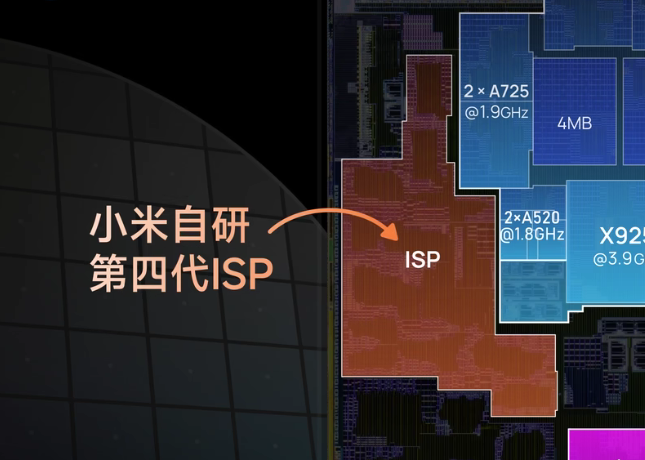
小米的ISP發展,大致可分為一下幾個發展階段:

那么,什么是3A加速呢?
3A分別指的是自動對焦(AF)、自動曝光(AE)、自動白平衡(AWB),它們是成像質量的核心控制參數。澎湃C1芯片的3A加速 指通過專用硬件電路(而非傳統軟件算法)實現這三大功能的超低延遲、高精度處理。
關于語義分割和多幀合成就更復雜了,有時間再說😊。
1.2 SLC缺席的原因探索
首先我們先捋清楚概念,什么是SLC緩存,與普通的緩存有什么不同?
SLC(系統級緩存): 一種共享緩存,通常被多個處理單元(如CPU、GPU、NPU)共同訪問,用于減少對主存的依賴,降低延遲和功耗。例如,高通的驍龍芯片通常集成6-8MB的SLC,供所有核心共享。

獨立緩存(單元級緩存):
每個處理單元(如CPU核心、GPU模塊、NPU加速器)擁有自己的專用緩存(如L2/L3緩存),獨立管理,不與其他單元共享數據。
那么,該如何理解極客灣所說的:“最終去掉SLC,增加各個單元各自的巨大緩存,應該是為了規避低功耗區間翻車的風險”?
所謂的低功耗時候的風險,指的是當芯片處于低功耗模式(如手機待機、輕度任務處理)時,若共享資源(如SLC)的設計無法高效協調多單元訪問,可能導致兩個問題:
性能波動:緩存爭用導致響應延遲增加。
功耗反彈:頻繁喚醒主存或維護緩存一致性,反而增加功耗。
也就是說,在輕度負載的應用場景,SLC還在工作,而如果將這部分直接“舍棄”,那么對于玄戒O1來說,可直接利用小核自帶的緩存去應付,這樣就節省了部分功耗。
2. CPU設計
玄戒O1的CPU核心并非均質化設計,而是按 性能/功耗比 嚴格分級:
X925超大核(3.9GHz):基于ARM Cortex-X4定制,專攻瞬時高負載(如游戲啟動、AI推理);
A725大核(3.4GHz):處理中度多線程任務(如視頻編碼、多應用切換);
低頻A725(1.89GHz):優化能效的輕量計算(如后臺服務);
A520小核(1.8GHz):負責低功耗常駐任務(如傳感器數據采集)。
這種設計源自 ARM的DynamIQ技術,允許不同架構核心共享L3緩存和內存控制器,但每個叢集可獨立調節電壓/頻率(DVFS)。這樣一來,對于降低整機功耗非常有利。
2.1 不同核心之間的差異
上面對大小核有了簡單的介紹,接下來我們詳細介紹一下這些核之間的差異。

可以看到,更大的核心,意味著擁有更深的流水線深度,以及更加豐富的分支預測預測單元和更多的ALU和重排序緩沖區(什么是流水線,以及什么是分支預測,可以參考我的這篇文章CPU流水線技術全面解讀)。
簡單來說:
- X925 通過更深的流水線和更大的ROB提升單線程性能,但功耗較高。
- A725 在性能與能效間平衡,適合多線程任務。
- A520 簡化執行單元,減少面積和功耗,適合低負載場景。
關于緩存分配方面,為了方便數據的讀寫,當然是越大的核,配越大的緩存。超大核每個配置了2M的L2緩存,大核和能效核每個配置了1M的L2緩存,小核共用512k L2緩存,這些核共用16M L3緩存。
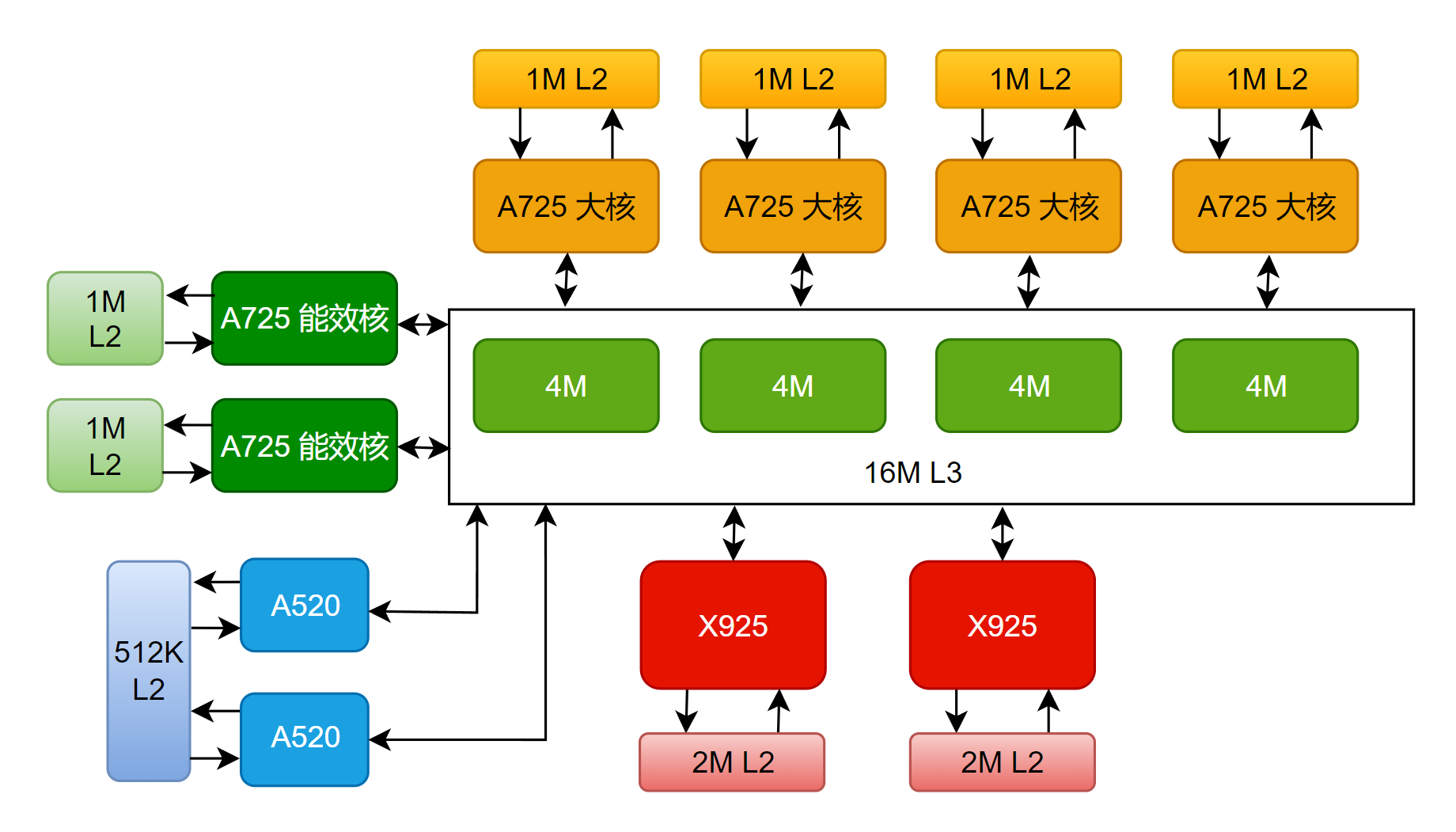
L1緩存一般集成在了各個核內部,從下面這張圖可以看出來(圖片來自ARM官網,相關技術手冊)。

除此之外,不同的核,電源與工藝也不一樣。

可見,超大核和大核由于功耗較高,可以根據任務的不同而選擇睡眠或工作,而小核處于常開狀態,從而在整體上控制可功耗,當然多核的調度策略遠遠沒有這么簡單,在下面章節中我們將重點討論。
2.2 多核任務調度策略
2.2.1 多核任務調度核心邏輯
(1) 任務分類與優先級映射
- 實時性任務(如觸控響應、音頻處理)→ 由 X925超大核 處理,確保低延遲;
- 計算密集型任務(如游戲渲染、視頻導出)→ 分配至 X925+A725大核,利用多線程并行;
- 能效敏感型任務(如后臺同步、消息推送)→ 交由 A520小核,減少喚醒大核的功耗。
(2) 調度器算法(Linux CFS + 小米定制優化)
玄戒O1基于 Linux內核的完全公平調度器(CFS: completely Fair scheduler),但小米做了以下深度優化:
負載預測模型:通過歷史使用數據(如APP啟動模式)預判任務類型,提前分配核心;
能效感知調度(EAS):結合芯片的 能量模型(EM),計算每個任務在不同核心的 功耗/性能比,選擇最優解;
線程遷移成本控制:避免頻繁跨叢集遷移線程(如從X925切到A520),減少緩存失效帶來的性能損失。
(3) 硬件級調度輔助(PMU與IPC監控)
性能監控單元(PMU):實時監測各核心的 IPC(每周期指令數)、緩存命中率,動態調整調度策略;
中斷負載均衡:硬件中斷(如網絡數據包到達)會優先路由到空閑小核,避免打斷大核的關鍵任務。
以上的內容,其他的都比較好理解,那么什么是完全公平調度器(CFS),什么又是能效感知調度(EAS)呢?
2.2.2 完全公平調度器
-
核心目標
公平性:確保所有任務按權重(優先級)公平分享CPU時間,避免饑餓。
低延遲:通過細粒度時間片分配(最小調度周期約1ms),快速響應交互任務。
普適性:適用于同構多核系統,不依賴特定硬件特性。 -
實現原理
虛擬運行時間(vruntime):
每個任務維護一個vruntime,表示其已消耗的“虛擬CPU時間”。CFS優先調度vruntime最小的任務,保證長期公平。
紅黑樹管理:
所有可運行任務按vruntime排序存入紅黑樹,調度器每次選擇最左側(最小vruntime)任務執行。
負載均衡:
定期檢查各CPU負載,通過任務遷移平衡負載,但不感知能效差異。 -
局限性😟
異構核盲視:
將大核(高性能高功耗)與小核(低性能低功耗)視為等同,可能將輕量任務錯誤分配到大核,導致能效低下。
能耗不敏感:
調度決策僅基于CPU時間公平性,無法優化整體系統功耗。
鑒于以上的局限性,有了又來的能效感知調度策略。
2.2.3 能效感知調度
-
核心目標
能效優化:在滿足性能需求的前提下,最小化系統功耗。
異構核適配:根據大核/小核的功耗特性,智能分配任務。
動態調節:結合CPU頻率(DVFS)與任務需求,實現精細化控制。 -
實現原理
能量模型(Energy Model, EM):
預置每個CPU核心在不同頻率下的功耗曲線(如X925@3.9GHz功耗4.2W,A520@1.8GHz功耗0.1W)。
能效成本函數:
計算任務在候選核心的 能效得分 = 性能需求 / 預期功耗,選擇得分最高的目標核心。
與CFS的集成:
繼承CFS的vruntime和紅黑樹機制,維持公平性基礎。
負載均衡增強:在任務遷移時,優先考慮能效而非單純負載均衡。 -
關鍵創新
CPU容量感知:
定義每個核心的“計算容量”(如X925容量=1024,A520=256),任務負載按容量歸一化。
能效導向的喚醒決策:
喚醒空閑核心時,選擇能效比最高的候選(而非默認的最小負載核心)。
2.3 超大核的分支預測方案
核心越大,流水線深度越深,則在預測失敗后進行相關處理的成本越大。那設計一個優秀的分支預測算法就顯得尤為重要。所以我們在此僅對該SOC超大核X925的分支預測原理進行分析(具體的分支預測方案這屬于技術機密,我們不得而知,但是可以根據目前已知的一些分支預測方案做出合理推測)。
下圖是一種常見的五級流水線內部結構圖,作為參考:
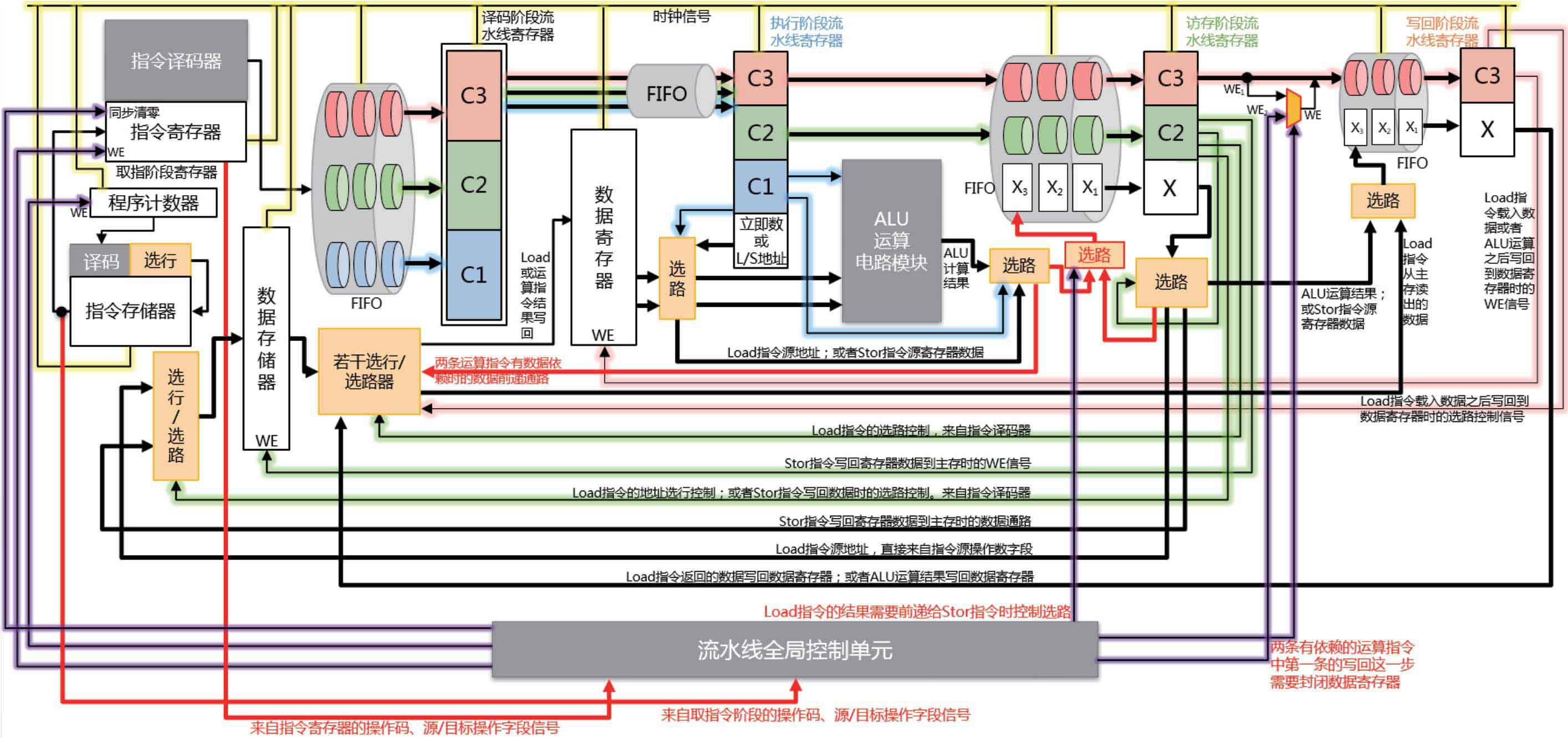
可能的分支預測解決方案有以下幾個:
2.3.1 自適應混合預測算法
TAGE-SC-L 預測器:
采用多歷史長度組合的預測機制,動態選擇最佳歷史深度(如4-bit至128-bit歷史記錄),通過幾何級數分布的歷史表覆蓋不同分支模式(循環、條件跳轉等)。
示例:對于頻繁跳轉的循環體(如for(i=0; i<N; i++)),短歷史長度快速捕捉規律;對嵌套條件分支(如if(A && B || C)),長歷史記錄分析上下文依賴。
感知局部性增強:
引入分支地址哈希優化,減少BTB(Branch Target Buffer)沖突。例如,玄戒O1可能使用XOR折疊算法對分支指令地址進行哈希處理,分散到不同預測表項,降低別名(Aliasing)導致的誤判。
2.3.2 硬件結構深度優化
分層式BTB設計:
L1 BTB:小容量、低延遲(1周期訪問),緩存最近高頻分支目標(如4K條目)。
L2 BTB:大容量、稍高延遲(3-4周期),存儲低頻但重要的分支(如16K條目),通過預取機制提前加載可能需要的條目。
使得CPU可以在較短時間內讀取高頻分支目標,提升整體處理效率。
分支目標預計算:
在指令解碼階段,對間接跳轉(如switch-case、虛函數調用)的目標地址進行硬件加速計算,利用專用電路快速解析跳轉表或寄存器值,減少目標查找延遲。
采用專用電路縮減跳轉時間。
2.3.3 推測執行與恢復機制
誤預測快速回滾:
采用Checkpoint寄存器堆,在分支預測時保存關鍵寄存器狀態,誤判時直接回滾至檢查點,而非完全清空流水線,將恢復時間從20+周期縮短至5周期內。
動態推測深度調整:
根據工作負載特征(如高分支誤判率時),自動限制推測執行的指令窗口大小(如從200條縮減至50條),避免因深度推測浪費能耗。
這也屬于一種自我優化機制,去掉了部分高分支誤判率的指令窗口,理論上就可以降低誤判率。
2.3.4 AI驅動的動態學習
運行時行為建模:
集成輕量級神經網絡協處理器,實時分析分支歷史模式(如周期性、隨機性),動態調整預測器權重。例如,檢測到某分支近期誤判率升高,自動切換至備選預測策略。
相當于一種自適應的分支預測,當然,這個神經網絡不能設計得過于復雜,不然本身的功耗就不小,估計也就是哥多層感知機。

編譯器反饋優化:
與定制化編譯器(如玄鐵LLVM)協作,通過__builtin_expect等指令標記高概率分支路徑,輔助硬件預測器初始化歷史狀態。
3. 后記
總覺得還有很多東西可以寫,比方說多核調度策略和分支預測很多細節沒有寫到。而且GPU, NPU和ISP部分沒有單獨作為一個章節進行展開。但我覺得可以將玄戒O1的分析做個系列文章。歡迎繼續關注后續更新。
參考資料:
- 嗶哩嗶哩up主極客灣的視頻小米自研玄戒O1芯片深度評測:直逼8 Elite!
- 《大話計算機》
- ARM官網數據手冊

)

















