本文為🔗365天深度學習訓練營內部文章
原作者:K同學啊
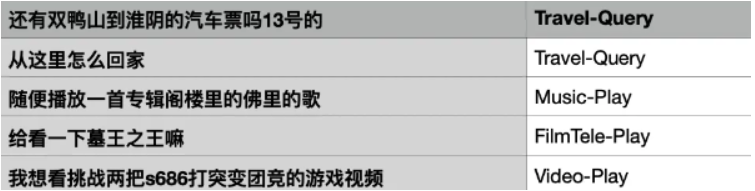
?將對中文文本進行分類,示例如下:
 ?
?
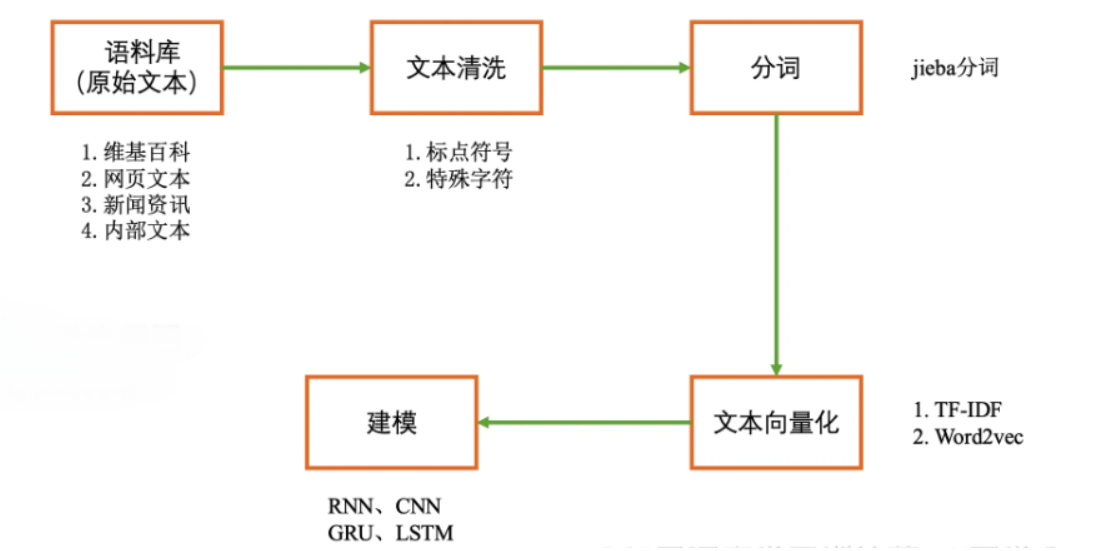
文本分類流程圖
?
 ?
?
1.加載數據?
import time
import pandas as pd
import torch
from torch.utils.data import DataLoader, random_split
import torch.nn as nn
import torchvision
from torchtext.data import to_map_style_dataset
from torchvision import transforms,datasets
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
import jieba
import warningswarnings.filterwarnings('ignore')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")'''
加載本地數據
'''
train_data = pd.read_csv('train.csv',sep='\t',header=None)
print(train_data.head())
# 構建數據集迭代器
def coustom_data_iter(texts,labels):for x,y in zip(texts,labels):yield x,y
# train_data[0]是第一列(通常是文本),train_data[1]是第二列(通常是標簽)
train_iter = coustom_data_iter(train_data[0].values[:],train_data[1].values[:])?
定義一個名為 coustom_data_iter 的函數,接收兩個參數:
-
texts:文本數據(通常是句子或單詞序列) -
labels:對應的標簽(分類任務中的目標值)
for x, y in zip(texts, labels):
-
zip(texts, labels):將texts和labels按元素配對,返回一個迭代器,每次迭代返回(text, label)的組合。 -
例如,如果
texts = ["hello", "world"],labels = [0, 1],那么zip(texts, labels)會生成("hello", 0)和("world", 1)。
yield x, y
-
yield使這個函數變成一個 生成器(generator),每次迭代返回(x, y)對,而不是一次性返回所有數據。 -
這種方式適合大數據集,因為它不會一次性加載所有數據到內存,而是按需生成。
2.數據預處理
1)構建詞典 ?
# 中文分詞方法
tokenizer = jieba.lcutdef yield_tokens(data_iter):for text,_ in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter),specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"]) # 設置默認索引,如果找不到單詞,則會選擇默認索引label_name = list(set(train_data[1].values[:])) # 將標簽去重,添加到label_name列表中
print(label_name)text_pipeline = lambda x:vocab(tokenizer(x))
label_pipeline = lambda x:label_name.index(x)?
-
def yield_tokens(data_iter):定義一個生成器函數yield_tokens,接收一個數據迭代器data_iter(通常是(text, label)格式的迭代器)。 -
for text, _ in data_iter:-
data_iter每次返回(text, label),這里用_忽略標簽(因為我們只需要文本)。 -
例如,如果
data_iter是[("hello world", 0), ("good morning", 1)],則text依次是"hello world"和"good morning"。
-
-
yield tokenizer(text)-
tokenizer(text):對文本text進行分詞(如拆分成單詞列表)。 -
yield返回分詞后的結果(如["hello", "world"]和["good", "morning"]),逐步生成數據流。
-
-
build_vocab_from_iterator-
是 PyTorch 的
torchtext.vocab提供的函數,用于從迭代器構建詞匯表。 -
輸入:
yield_tokens(data_iter)生成的分詞結果(如["hello", "world"],["good", "morning"])。 -
輸出:一個
Vocab對象,包含所有單詞到索引的映射。
-
-
specials=["<unk>"]-
指定特殊符號
<unk>(unknown token),用于處理詞匯表中不存在的單詞。 -
其他常見的特殊符號:
-
"<pad>":填充符號(用于統一序列長度)。 -
"<sos>":句子開始符。 -
"<eos>":句子結束符。
-
-
lambda 表達式的語法為:lambda arguments:expression 其中 arguments 是函數的參數,可以有多個參數,用逗號分隔。expression 是一個表達式,它定義了函數的返回值。 text_pipeline函數:將原始文本數據轉換為整數列表,使用了之前構建的vocab詞表和tokenizer分詞器函數。具體來說,它接受一個字符串x作為輸入,首先使用tokenizer將其分詞,然后將每個詞在vocab詞表中的索引放入一個列表中返回。 label pipeline函數:將原始標簽數據轉換為整數,它接受一個字符串x作為輸入,并使用 label_name.index(x)方法獲取x在label name 列表中的索引作為輸出。
2)生成數據批次和迭代器 ?
# 2.生成數據批次和迭代器
def collate_batch(batch):label_list,text_list,offsets = [],[],[0]for (_text,_label) in batch:# 標簽列表label_list.append(label_pipeline(_label))# 文本列表processed_text = torch.tensor(text_pipeline(_text),dtype=torch.int64)text_list.append(processed_text)# 偏移量,即語句的總詞匯量offsets.append(processed_text.size(0))label_list = torch.tensor(label_list,dtype=torch.int64)text_list = torch.cat(text_list)offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) # 返回維度dim中輸入元素的累計和return text_list.to(device),label_list.to(device),offsets.to(device)# 數據加載器
dataloader = DataLoader(train_iter,batch_size=8,shuffle=False,collate_fn=collate_batch)-
輸入:
batch是一個列表,其中每個元素是(_text, _label)對(來自train_iter)。 -
初始化:
-
label_list:存儲批次的標簽。 -
text_list:存儲分詞后的文本(轉換為整數索引)。 -
offsets:存儲每個文本的長度(用于后續拼接),初始值為[0]
-
-
offsets的用途:-
記錄每個文本的累計長度,用于后續將多個文本拼接成一個一維張量時定位每個樣本的起始位置。
-
-
label_list:-
將標簽列表轉換為 PyTorch 張量(形狀為
[batch_size])。
-
-
text_list:-
torch.cat(text_list):將所有文本的索引拼接成一個一維張量。-
例如,如果有兩個文本
[1, 2]和[3, 4, 5],結果為[1, 2, 3, 4, 5]。
-
-
-
offsets:-
offsets[:-1]:去掉初始的[0],保留每個文本的長度(如[2, 3])。 -
.cumsum(dim=0):計算累計和,得到每個文本在text_list中的起始位置。-
例如,
[2, 3]→[2, 5],表示:-
第一個文本在
text_list中的位置是0:2。 -
第二個文本的位置是
2:5。
-
-
-
3.構建模型
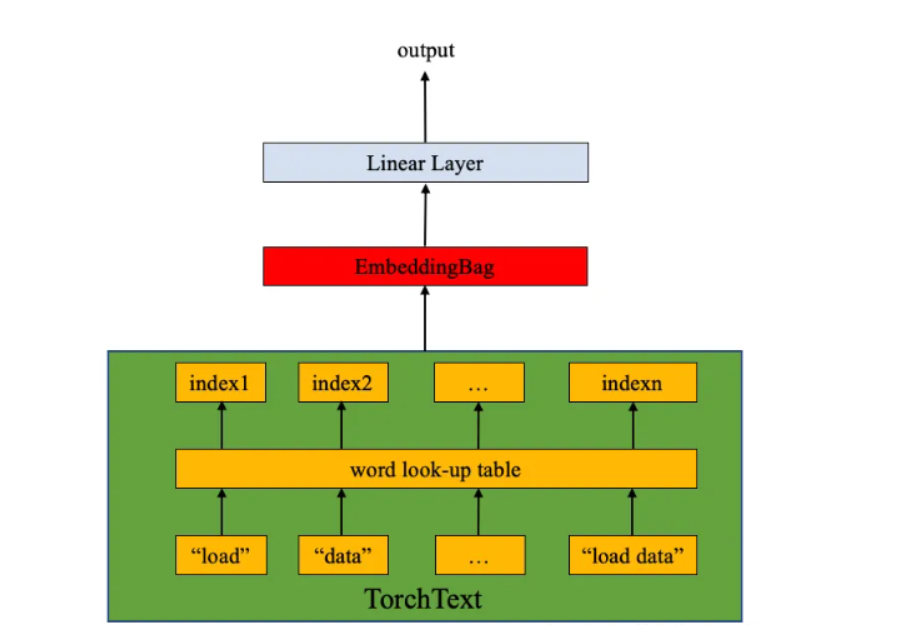
首先對文本進行嵌入,然后對句子進行嵌入之后的結果進行均值整合
模型圖如下:
?
?
# 1.定義模型
class TextClassificationModel(nn.Module):def __init__(self,vocab_size,embed_dim,num_class):super(TextClassificationModel,self).__init__()self.embedding = nn.EmbeddingBag(vocab_size, # 詞典大小embed_dim, # 嵌入維度sparse=False)self.fc = nn.Linear(embed_dim,num_class)self.init_weights()def init_weights(self):initrange = 0.5self.embedding.weight.data.uniform_(-initrange,initrange)self.fc.weight.data.uniform_(-initrange,initrange)self.fc.bias.data.zero_()def forward(self,text,offsets):embedded = self.embedding(text,offsets)return self.fc(embedded)?
self.embedding.weight.data.uniform_(-initrange,initrange)這段代碼是在 PyTorch 框架下用于初始化神經網絡的詞嵌入層(embedding layer)權重的一種方法。這里使用了均勻分布的隨機值來初始化權重,具體來說,其作用如下: self.embedding:這是神經網絡中的詞嵌入層(embeddinglayer)。詞嵌入層的作用是將離散的單詞表示(通常為整數索引)映射為固定大小的連續向量。這些向量捕捉了單詞之間的語義關系,并作為網絡的輸入。 self.embedding.weight:這是詞嵌入層的權重矩陣,它的形狀為(vocab size,embedding _dim),其中 vocab size 是詞匯表的大小,embedding dim 是嵌入向量的維度。
self.embedding.weight.data:這是權重矩陣的數據部分,我們可以在這里直接操作其底層的張量。 .uniform(-initrange,initrange):這是一個原地操作(in-place operation),用于將權重矩陣的值用一個均勻分布進行初始化。均勻分布的范圍為[-initrange,initrange],其中 initrange 是一個正數。 通過這種方式初始化詞嵌入層的權重,可以使得模型在訓練開始時具有一定的隨機性,有助于避免梯度消失或梯度爆炸等問題。在訓練過程中,這些權重將通過優化算法不斷更新,以捕捉到更好的單詞表示。
# 2.定義實例
num_class = len(label_name)
vocab_size = len(vocab)
em_size = 64
model = TextClassificationModel(vocab_size,em_size,num_class).to(device)# 3.定義訓練函數和評估函數
def train(dataloader):model.train()total_acc,train_loss,total_count = 0,0,0log_interval = 50start_time = time.time()for idx,(text,label,offsets) in enumerate(dataloader):predicted_label = model(text,offsets)optimzer.zero_grad() # grad屬性歸零loss = criterion(predicted_label,label) # 計算網絡輸出和真實值之間的差距loss.backward() # 反向傳播nn.utils.clip_grad_norm(model.parameters(),0.1) # 梯度裁剪optimzer.step() # 每一步自動更新# 記錄acc與Losstotal_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:1d} | {:4d}/{:4d} batches ''| train_acc {:4.3f} train_loss {:4.5f}'.format(epoch,idx,len(dataloader),total_acc/total_count,train_loss/total_count))total_acc,train_loss,total_count = 0,0,0start_time = time.time()def evaluate(dataloader):model.eval()total_acc, train_loss, total_count = 0, 0, 0with torch.no_grad():for idx, (text,label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)loss = criterion(predicted_label, label) # 計算網絡輸出和真實值之間的差距# 記錄acc與Losstotal_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)return total_acc/total_count,train_loss/total_count?torch.nn.utils.clip_grad_norm_(model.parameters(),0.1)是一個PyTorch函數,用于在訓練神經網絡時限制梯度的大小。這種操作被稱為梯度裁剪(gradient clipping),可以防止梯度爆炸問題,從而提高神經網絡的穩定性和性能。 在這個函數中: model.parameters()表示模型的所有參數。對于一個神經網絡,參數通常包括權重和偏置項。0.1是一個指定的閾值,表示梯度的最大范數(L2范數)。如果計算出的梯度范數超過這個閾值,梯度會被縮放,使其范數等于閾值。 梯度裁剪的主要日的是防止梯度爆炸。梯度爆炸通常發生在訓練深度神經網絡時,尤其是在處理長序列數據的循環神經網絡(RNN)中。當梯度爆炸時,參數更新可能會變得非常大,導致模型無法收斂或出現數值不穩定。通過限制梯度的大小,梯度裁剪有助于解決這些問題,使模型訓練變得更加穩定。
4.訓練模型
1)拆分數據集運行模型
?
EPOCHS = 10
LR = 5
BATCH_SIZE = 64criterion = torch.nn.CrossEntropyLoss()
optimzer = torch.optim.SGD(model.parameters(),lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimzer,1.0,gamma=0.1)
total_accu = None# 構建數據集
train_iter = coustom_data_iter(train_data[0].values[:],train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)
split_train_,split_valid_ = random_split(train_dataset,[int(len(train_dataset)*0.8),int(len(train_dataset)*0.2)])
train_dataloader = DataLoader(split_train_,batch_size=BATCH_SIZE,shuffle=True,collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid_,batch_size=BATCH_SIZE,shuffle=True,collate_fn=collate_batch)for epoch in range(1,EPOCHS+1):epoch_start_time = time.time()train(train_dataloader)val_acc,val_loss = evaluate(valid_dataloader)# 獲取當前的學習率lr = optimzer.state_dict()['param_groups'][0]['lr']if total_accu is not None and total_accu > val_acc:scheduler.step()else:total_accu = val_accprint('-'*69)print('| epoch {:1d} | time:{:4.2f}s | ''valid_acc {:4.3f} valid_loss {:4.3f}'.format(epoch,time.time()-epoch_start_time,val_acc,val_loss))print('-'*69)?torchtext.data.functional.to_map_style_dataset 函數的作用是將一個迭代式的數據集(lterable-style dataset)轉換為映射式的數據集(Map-style dataset)。這個轉換使得我們可以通過索引(例如:整數)更方便地訪問數據集中的元素。 在 PyTorch 中,數據集可以分為兩種類型:lterable-style和 Map-style。lterable-style 數據集實現了iter_()方法,可以迭代訪問數據集中的元素,但不支持通過索引訪問。而 Map-style 數據集實現了__getitem()和1en()方法,可以直接通過索引訪問特定元素,并能獲取數據集的大小。 TorchText 是 PyTorch 的一個擴展庫,專注于處理文本數據。torchtext.data.functional 中的to map style dataset 函數可以幫助我們將一個 lterable-style 數據集轉換為一個易于操作的 Map-style數據集。這樣,我們可以通過索引直接訪問數據集中的特定樣本,從而簡化了訓練、驗證和測試過程中的數據處理。
# 2.使用測試數據集評估模型
print('Checking the results of test dataset.')
test_acc,test_loss = evaluate(valid_dataloader)
print('test accuracy {:8.3f}'.format(test_acc))# 3.測試指定數據
def predict(text,text_pipeline):with torch.no_grad():text = torch.tensor(text_pipeline(text))output = model(text,torch.tensor([0]))return output.argmax(1).item()ex_text = "隨便播放一首陳奕迅的歌"
model = model.to("cpu")
print('該文本的類別是:%s'%label_name[predict(ex_text,text_pipeline)])?
教程 | 小程序UI設計進階(三)讓界面動起來,實操講透“聚焦”事件)

)




控制實時突發)





)

)


:吃糖果2(題目及解析))
