模型可視化與推理
知識點回顧:
- 三種不同的模型可視化方法:推薦torchinfo打印summary+權重分布可視化
- 進度條功能:手動和自動寫法,讓打印結果更加美觀
- 推理的寫法:評估模式
作業:調整模型定義時的超參數,對比下效果。
# nn.Module 的內置功能,直接輸出模型結構
print(model)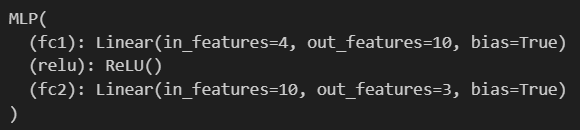
簡單來說,你看到的是一個神經網絡模型的“內部結構清單”,就像拆開一臺機器后看到的零件列表。咱們用生活中的例子來理解:
假設你要做一個“判斷水果類型”的模型(比如區分蘋果、香蕉、橘子),輸入可能是水果的4個特征(比如重量、顏色、表皮光滑度、大小),輸出是3種水果的概率。這個MLP模型的結構就像一條“數據加工流水線”:
-
第一關(fc1層):有個“4轉10的轉換器”。它拿到輸入的4個特征數據后,會做一些數學計算(比如加權求和+偏移),把這4個數據“變”成10個新的數據。就像把4種原材料加工成10種中間產物。
-
激活關(relu層):這一步會“過濾掉沒用的中間產物”。比如如果某個中間產物算出來是負數(可能代表“沒用的信息”),它就會直接變成0(相當于丟棄),只保留正數的部分。這樣能讓模型更“聰明”,只關注有用的信息。
-
第二關(fc2層):有個“10轉3的轉換器”。它拿到前面過濾后的10個數據,再做一次數學計算,最終把它們“濃縮”成3個結果。這3個結果就對應你要判斷的3種水果的概率(比如哪個數值大,就更可能是對應的水果)。
所以整體看,這個模型就是通過兩層“數據轉換器”+一層“過濾無用信息”的步驟,把輸入的4個特征,一步步處理成3個最終結果。
?
?
# nn.Module 的內置功能,返回模型的可訓練參數迭代器
for name, param in model.named_parameters():print(f"Parameter name: {name}, Shape: {param.shape}")
這些是神經網絡模型中各個層的可學習參數(權重和偏置)的信息,用大白話解釋就是模型“內部用來做計算的規則”。我們一個一個看:
1.?fc1.weight(形狀 [10, 4])
這是第一個全連接層(fc1)的“權重矩陣”。
- 作用:負責把輸入的4維數據“轉換”成10維數據。
- 形狀含義:10行(對應輸出的10個維度),4列(對應輸入的4個維度)。可以理解為:每個輸出維度(共10個)需要和輸入的4個維度“一一配對”計算,所以需要10×4個“小規則”(即權重參數)。
2.?fc1.bias(形狀 [10])
這是第一個全連接層的“偏置參數”。
- 作用:給每個輸出維度的計算結果加一個“偏移量”(類似數學里的?
y = kx + b?中的?b),讓模型能擬合更復雜的規律。 - 形狀含義:因為fc1輸出是10維,所以需要10個偏置參數(每個輸出維度對應1個)。
3.?fc2.weight(形狀 [3, 10])
這是第二個全連接層(fc2)的“權重矩陣”。
- 作用:負責把前一層(fc1)輸出的10維數據“轉換”成最終的3維結果。
- 形狀含義:3行(對應最終輸出的3個維度),10列(對應前一層輸入的10個維度)。每個輸出維度(共3個)需要和前一層的10個維度“配對”計算,所以需要3×10個權重參數。
4.?fc2.bias(形狀 [3])
這是第二個全連接層的“偏置參數”。
- 作用:給最終輸出的每個維度加一個“偏移量”。
- 形狀含義:因為最終輸出是3維,所以需要3個偏置參數(每個輸出維度對應1個)。
總結
這些參數是模型在訓練過程中自動學習的(比如通過調整這些參數的值,讓模型預測更準)。簡單說,它們就像模型內部的“計算器”,輸入數據經過這些參數的計算后,最終得到你想要的結果(比如分類、回歸等)。
?
?
# 提取權重數據
import numpy as np
weight_data = {}
for name, param in model.named_parameters():if 'weight' in name:weight_data[name] = param.detach().cpu().numpy()# 可視化權重分布
fig, axes = plt.subplots(1, len(weight_data), figsize=(15, 5))
fig.suptitle('Weight Distribution of Layers')for i, (name, weights) in enumerate(weight_data.items()):# 展平權重張量為一維數組weights_flat = weights.flatten()# 繪制直方圖axes[i].hist(weights_flat, bins=50, alpha=0.7)axes[i].set_title(name)axes[i].set_xlabel('Weight Value')axes[i].set_ylabel('Frequency')axes[i].grid(True, linestyle='--', alpha=0.7)plt.tight_layout()
plt.subplots_adjust(top=0.85)
plt.show()# 計算并打印每層權重的統計信息
print("\n=== 權重統計信息 ===")
for name, weights in weight_data.items():mean = np.mean(weights)std = np.std(weights)min_val = np.min(weights)max_val = np.max(weights)print(f"{name}:")print(f" 均值: {mean:.6f}")print(f" 標準差: {std:.6f}")print(f" 最小值: {min_val:.6f}")print(f" 最大值: {max_val:.6f}")print("-" * 30)?
這里的“每層權重”指的是神經網絡中每個可學習層(比如全連接層)內部的“核心參數”,也就是模型通過訓練自動調整的“規則數值”。咱們結合你的代碼和神經網絡的工作原理,用大白話解釋:
1. 什么是“權重”?
簡單說,權重是神經網絡里神經元之間的“連接強度”。就像你做數學題時的“計算公式”——比如輸入4個特征(x1, x2, x3, x4),輸出10個中間結果(y1~y10),每個y的計算可能是:
y1 = x1*w11 + x2*w12 + x3*w13 + x4*w14
這里的w11、w12、w13、w14就是“權重”(weight),它們決定了輸入特征對輸出結果的影響程度。
2. “每層權重”具體指什么?
你的代碼里,model.named_parameters()會遍歷模型所有可訓練參數(包括權重和偏置),而if 'weight' in name篩選出了屬于“權重”的參數。例如:
- 如果模型有
fc1(第一個全連接層),對應的權重是fc1.weight; - 如果有
fc2(第二個全連接層),對應的權重是fc2.weight;
這些就是代碼中“每層權重”的具體對象。
3. 代碼在“提取”和“分析”它們的什么?
你的代碼做了兩件關鍵的事:
(1)提取權重數據
把模型中每個層的權重參數(比如fc1.weight和fc2.weight)從PyTorch的張量(Tensor)轉成numpy數組,存到weight_data字典里。這樣后續可以用numpy和matplotlib分析。
(2)可視化+統計分析
- 直方圖:把每個層的權重值“攤平”成一維數組(比如
fc1.weight是10×4的矩陣,攤平后是40個數值),然后統計這些數值的分布(比如大部分權重是0附近的小數?還是有很多大的正數/負數?)。 - 統計信息:計算每個層權重的均值、標準差、最小/最大值。這些數值能幫你快速判斷:
- 權重是否初始化合理(比如均值是否接近0,標準差是否太小/太大);
- 訓練是否正常(比如訓練后權重是否有明顯變化,是否出現梯度消失/爆炸)。
總結
“每層權重”就是模型中每個層(比如全連接層)里用于“計算輸入→輸出”的核心參數。你的代碼在“檢查”這些參數的分布和統計特征,就像給模型做“體檢”——通過它們的數值表現,你可以判斷模型是否訓練正常、參數初始化是否合理,甚至定位訓練中的問題(比如權重全為0可能是初始化錯誤)。
?
from torchsummary import summary
# 打印模型摘要,可以放置在模型定義后面
summary(model, input_size=(4,))?
這是用?torchsummary?工具打印的模型“詳細體檢報告”,幫你快速看清模型每一層的“輸出尺寸”和“參數數量”。咱們逐行用大白話解釋:
第一部分:各層的具體信息(表格)
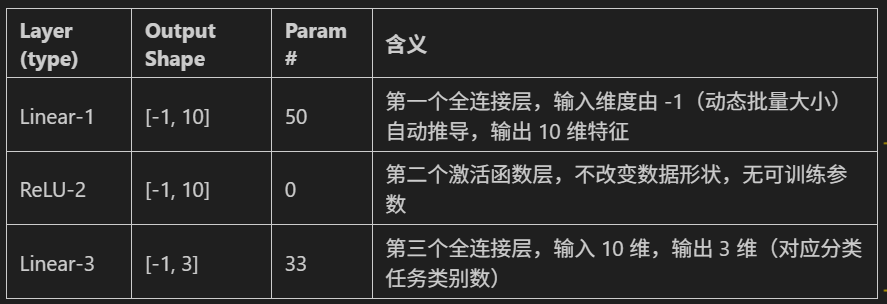
表格里的具體行:
-
Linear-1(第一個全連接層)- Output Shape?
[-1, 10]:不管輸入多少個樣本(-1?代表批量大小),每個樣本經過這層后會變成10個特征的數據。 - Param # 50:這層有50個參數。計算方式是:輸入4個特征,輸出10個特征 → 權重參數是?
10×4=40(類似“4轉10的轉換規則”),再加上10個偏置參數(每個輸出特征一個),總共?40+10=50。
- Output Shape?
-
ReLU-2(激活函數層)- Output Shape?
[-1, 10]:激活函數不會改變數據的特征數量,所以輸出還是10個特征。 - Param # 0:ReLU激活函數(比如?
max(0, x))沒有需要學習的參數,只是單純的數學運算,所以參數數為0。
- Output Shape?
-
Linear-3(第二個全連接層)- Output Shape?
[-1, 3]:每個樣本經過這層后會變成3個特征的數據(比如對應3分類任務的結果)。 - Param # 33:輸入是前一層的10個特征,輸出3個特征 → 權重參數是?
3×10=30,加上3個偏置參數,總共?30+3=33。
- Output Shape?
第二部分:模型整體統計(表格下方)
- Total params: 83:整個模型所有層的參數總和(
50+0+33=83)。 - Trainable params: 83:所有參數都可以被訓練(比如用數據調整這些參數的值)。
- Non-trainable params: 0:沒有“凍結”的參數(有些模型會固定部分參數不訓練,這里沒有這種情況)。
第三部分:內存占用估計(最下方)
這部分是模型運行時的內存消耗估算(輸入數據、計算過程、參數本身占用的內存)。這里顯示?0.00?可能是因為輸入數據的尺寸太小(比如輸入是4維的小數),實際項目中如果輸入數據很大(如圖像),這里會顯示具體數值。
總結:這個摘要是模型的“透明化報告”,讓你一眼看清每一層怎么“加工數據”,以及模型總共需要學多少參數(參數越多,模型“記憶能力”越強,但可能越容易過擬合)。
?
該方法不顯示輸入層的尺寸,因為輸入的神經網是自己設置的,所以不需要顯示輸入層的尺寸。但是在使用該方法時,input size=(4,)參數是必需的,因為PyTorch需要知道輸入數據的形狀才能推斷模型各層的輸出形狀和參數數量。
這是因為PyTorch的模型在定義時是動態的,它不會預先知道輸入數據的具體形狀。nn.Linear(4,10)只定義了"輸入維度是4,輸出維度是10”,但不知道輸入的批量大小和其他維度,比如卷積層需要知道輸入的通道數、高度、寬度等信息。-并非所有輸入數據都是結構化數據
因此,要生成模型摘要(如每層的輸出形狀、參數數量),必須提供一個示例輸入形狀,讓PyTorch"運行”一次模型,從而推斷出各層的信息。
summary函數的核心邏輯是:
- 創建一個與input size形狀匹配的虛擬輸入張量(通常填充零)
- 將虛擬輸入傳遞給模型,執行一次前向傳播(但不計算梯度)
- 記錄每一層的輸入和輸出形狀,以及參數數量
- 生成可讀的摘要報告

構建神經網絡的時候
- 輸入層不需要寫:x多少個特征輸入層就有多少神經元
- 隱藏層需要寫,從第一個隱藏層可以看出特征的個數
- 輸出層的神經元和任務有關,比如分類任務,輸出層有3個神經元,一個對應每個類別
?
上圖只是幫助你理解,和上述架構不同,每條線記錄權重w,在每個神經元內計算并且輸出Relu(w*x+b)
可以看做,線記錄權重,神經元記錄偏置和損失函數
可學習參數計算
- Linear-1對應self.fc1=nn.Linear(4,10),表明前一層有4個神經元,這一層有10個神經元,每2個神經元之間靠著線相連,所有有4*10個權重參數+10個偏置參數=50個參數
- rlu層不涉及可學習參數,可以把它和前一個線性層看成一層,圖上也是這個含義
- Linear-3層對應代碼self.fc2=nn.Linear(10,3),10*3個權重參數+3個偏置=33個參數
總參數83個,占用內存幾乎為0
?torchinfo是提供比torchsummary更詳細的模型摘要信息,包括每層的輸入輸出形狀、參數數量、計算量等。
torchinfo是提供比torchsummary更詳細的模型摘要信息,包括每層的輸入輸出形狀、參數數
量、計算量等。
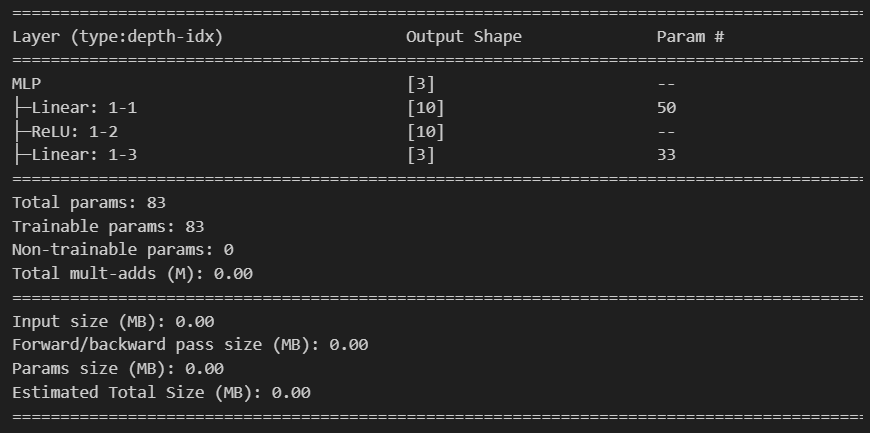
進度條功能:
我們介紹下tgdm這個庫,他非常適合用在循環中觀察進度。尤其在深度學習這種訓練是循環的場景中。他最核心的邏輯如下:
- 創建一個進度條對象,并傳入總迭代次數。一般用wth語句創建對象,這樣對象會在with語句結束后自動銷毀,保證資源釋放。wth是常見的上下文管理器,這樣的使用方式還有用with打開文件,結束后會自動關閉文件。
- 更新進度條,通過pbar.update(n)指定每次前進的步數n(適用于非固定步長的循環)。
手動更新:
from tqdm import tqdm # 先導入tqdm庫
import time # 用于模擬耗時操作# 創建一個總步數為10的進度條
with tqdm(total=10) as pbar: # pbar是進度條對象的變量名# pbar 是 progress bar(進度條)的縮寫,約定俗成的命名習慣。for i in range(10): # 循環10次(對應進度條的10步)time.sleep(0.5) # 模擬每次循環耗時0.5秒pbar.update(1) # 每次循環后,進度條前進1步?![]()
from tqdm import tqdm
import time# 創建進度條時添加描述(desc)和單位(unit)
with tqdm(total=5, desc="下載文件", unit="個") as pbar:# 進度條這個對象,可以設置描述和單位# desc是描述,在左側顯示# unit是單位,在進度條右側顯示for i in range(5):time.sleep(1)pbar.update(1) # 每次循環進度+1?![]()
unit參數的核心作用是明確進度條中每個進度單位的含義,使可視化信息更具可讀性。在深度學習訓練中,常用的單位包括:
- epoch:訓練輪次(遍歷整個數據集一次)。
- batch:批次(每次梯度更新處理的樣本組)。
- sample:樣本(單個數據點)
自動更新:
from tqdm import tqdm
import time# 直接將range(3)傳給tqdm,自動生成進度條
# 這個寫法我覺得是有點神奇的,直接可以給這個對象內部傳入一個可迭代對象,然后自動生成進度條
for i in tqdm(range(3), desc="處理任務", unit="epoch"):time.sleep(1)
?![]()
for i in tqdm(range(3),desc="處理任務",unit="個")這個寫法則不需要在循環中調用update()方法,更加簡潔
實際上這2種寫法都隨意選取,這里都介紹下?
# 用tqdm的set_postfix方法在進度條右側顯示實時數據(如當前循環的數值、計算結果等):
from tqdm import tqdm
import timetotal = 0 # 初始化總和
with tqdm(total=10, desc="累加進度") as pbar:for i in range(1, 11):time.sleep(0.3)total += i # 累加1+2+3+...+10pbar.update(1) # 進度+1pbar.set_postfix({"當前總和": total}) # 顯示實時總和?![]()
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm # 導入tqdm庫用于進度條顯示# 設置GPU設備
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")# 加載鳶尾花數據集
iris = load_iris()
X = iris.data # 特征數據
y = iris.target # 標簽數據# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 歸一化數據
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 將數據轉換為PyTorch張量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 輸入層到隱藏層self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隱藏層到輸出層def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 實例化模型并移至GPU
model = MLP().to(device)# 分類問題使用交叉熵損失函數
criterion = nn.CrossEntropyLoss()# 使用隨機梯度下降優化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 訓練模型
num_epochs = 20000 # 訓練的輪數# 用于存儲每100個epoch的損失值和對應的epoch數
losses = []
epochs = []start_time = time.time() # 記錄開始時間# 創建tqdm進度條
with tqdm(total=num_epochs, desc="訓練進度", unit="epoch") as pbar:# 訓練模型for epoch in range(num_epochs):# 前向傳播outputs = model(X_train) # 隱式調用forward函數loss = criterion(outputs, y_train)# 反向傳播和優化optimizer.zero_grad()loss.backward()optimizer.step()# 記錄損失值并更新進度條if (epoch + 1) % 200 == 0:losses.append(loss.item())epochs.append(epoch + 1)# 更新進度條的描述信息pbar.set_postfix({'Loss': f'{loss.item():.4f}'})# 每1000個epoch更新一次進度條if (epoch + 1) % 1000 == 0:pbar.update(1000) # 更新進度條# 確保進度條達到100%if pbar.n < num_epochs:pbar.update(num_epochs - pbar.n) # 計算剩余的進度并更新time_all = time.time() - start_time # 計算訓練時間
print(f'Training time: {time_all:.2f} seconds')# # 可視化損失曲線
# plt.figure(figsize=(10, 6))
# plt.plot(epochs, losses)
# plt.xlabel('Epoch')
# plt.ylabel('Loss')
# plt.title('Training Loss over Epochs')
# plt.grid(True)
# plt.show()

?
?
模型的推理:
之前我們說完了訓練模型,那么現在我們來測試模型。測試這個詞在大模型領域叫做推理(inference),意味著把數據輸入到訓練好的模型的過程。
?
注意損失和優化器在訓練階段。?
“注意損失和優化器在訓練階段”是指:在深度學習模型的訓練階段(而非測試/評估階段),損失函數(Loss Function)和優化器(Optimizer)是核心組件,用于更新模型參數;而在測試/評估階段不需要這兩個組件。
具體解釋如下:
1. 損失函數(Loss Function)的作用
損失函數用于衡量模型預測值與真實值之間的誤差。在訓練階段,我們需要通過損失函數計算當前模型的“錯誤程度”(例如分類任務常用交叉熵損失)。這個損失值會作為信號,指導優化器調整模型參數。
2. 優化器(Optimizer)的作用
優化器根據損失函數計算出的誤差,通過反向傳播(Backward Propagation)更新模型的權重參數(例如SGD、Adam等優化器)。訓練的核心目標就是通過優化器不斷調整參數,使得損失值逐漸降低,模型性能提升。
3. 為什么測試階段不需要損失和優化器?
測試/評估階段的目標是驗證模型在未見過數據上的表現(如你提供的代碼中的model.eval()和torch.no_grad())。此時模型參數已經固定(通過訓練階段優化完成),只需前向傳播得到預測結果(如outputs = model(X_test)),不需要計算損失(因為不關心“誤差多大”,只關心“預測是否正確”),也不需要優化器(因為不更新參數)。
與你當前代碼的關系
提供的代碼是測試階段的評估邏輯,因此沒有出現損失函數和優化器的代碼。但在訓練階段(例如for epoch in range(num_epochs)的循環中),一定會包含類似以下邏輯:
# 訓練階段示例代碼(非修改你的原代碼)
model.train() # 開啟訓練模式
optimizer.zero_grad() # 清空優化器梯度
outputs = model(X_train) # 前向傳播
loss = criterion(outputs, y_train) # 計算損失(criterion是損失函數)
loss.backward() # 反向傳播計算梯度
optimizer.step() # 優化器更新參數# 在測試集上評估模型,此時model內部已經是訓練好的參數了
# 評估模型
model.eval() # 設置模型為評估模式
with torch.no_grad(): # torch.no_grad()的作用是禁用梯度計算,可以提高模型推理速度outputs = model(X_test) # 對測試數據進行前向傳播,獲得預測結果_, predicted = torch.max(outputs, 1) # torch.max(outputs, 1)返回每行的最大值和對應的索引#這個函數返回2個值,分別是最大值和對應索引,參數1是在第1維度(行)上找最大值,_ 是Python的約定,表示忽略這個返回值,所以這個寫法是找到每一行最大值的下標# 此時outputs是一個tensor,p每一行是一個樣本,每一行有3個值,分別是屬于3個類別的概率,取最大值的下標就是預測的類別# predicted == y_test判斷預測值和真實值是否相等,返回一個tensor,1表示相等,0表示不等,然后求和,再除以y_test.size(0)得到準確率# 因為這個時候數據是tensor,所以需要用item()方法將tensor轉化為Python的標量# 之所以不用sklearn的accuracy_score函數,是因為這個函數是在CPU上運行的,需要將數據轉移到CPU上,這樣會慢一些# size(0)獲取第0維的長度,即樣本數量correct = (predicted == y_test).sum().item() # 計算預測正確的樣本數accuracy = correct / y_test.size(0)print(f'測試集準確率: {accuracy * 100:.2f}%')![]()
模型的評估模式簡單來說就是評估階段會關閉一些訓練相關的操作和策略,比如更新參數正則化等操作,確保模型輸出結果的穩定性和一致性。
為什么評估模式不關閉梯度計算,推理不是不需要更新參數么?
主要還是因為在某些場景下,評估階段可能需要計算梯度(雖然不更新參數)。例如:計算梯度用于可視化(如CAM熱力圖,主要用于cnn相關)。所以為了避免這種需求不被滿足,還是需要手動關閉梯度計算。
?@浙大疏錦行
從零實現用MobileFaceNet算法進行實時人臉識別(三)用yolov5-face算法實現人臉檢測)




 C++)




詳細解讀)








