文章目錄
- 主干網絡:
- Encoder:
- 不確定性最小Query選擇
- Decoder網絡:
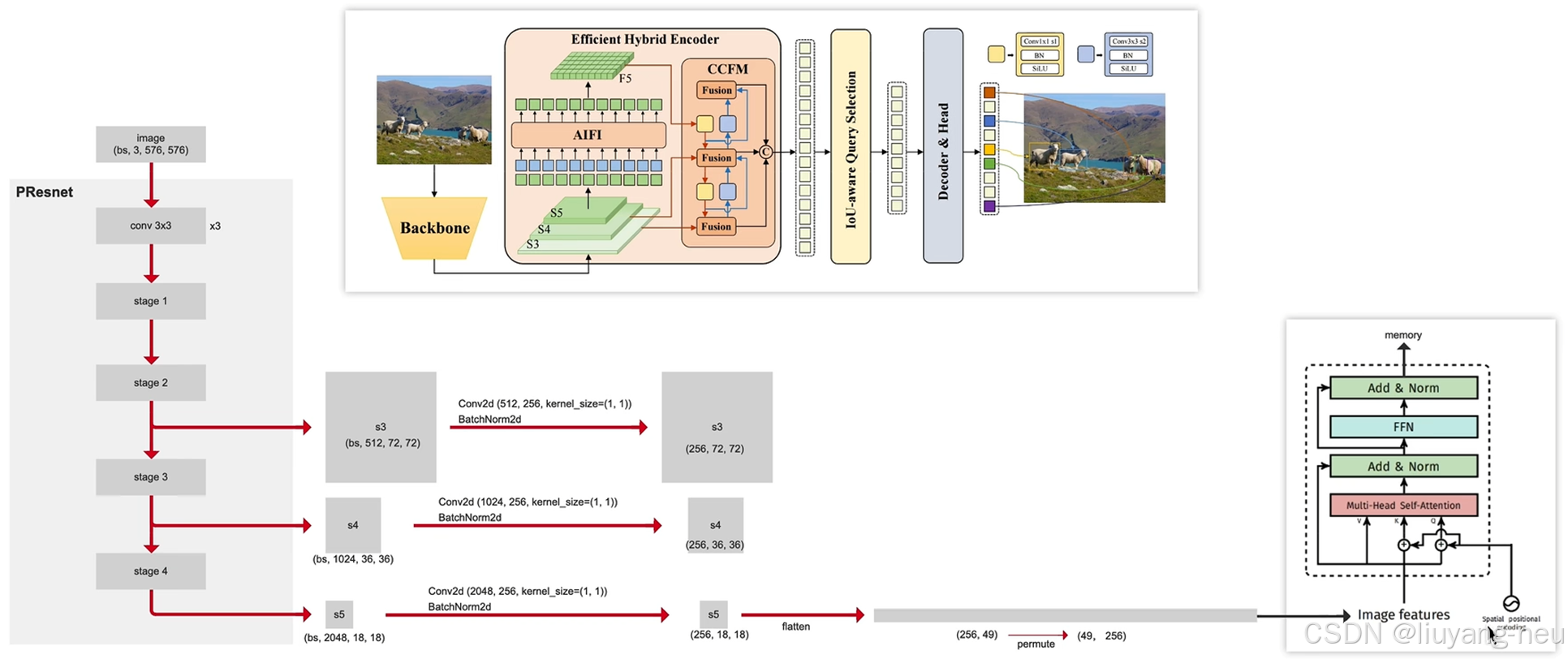
將DETR擴展到實時場景,提高了模型的檢測速度。網絡架構分為三部分組成:主干網絡、混合編碼器、帶有輔助預測頭的變換器編碼器。具體來說,先利用主干網絡的最后三個階段的輸出特征 {S3, S4,S5} 作為編碼器的輸入。混合編碼器通過內尺度交互(intra-scaleinteraction)和跨尺度融合(cross-scale fusion)將多尺度特征轉換成一系列圖像特征。隨后,采用loU感知查詢選擇(loU-aware query selection)從編碼器輸出序列中選擇一定數量的圖像特征,作為解碼器的輸入(初始對象查詢)。最后,帶有輔助預測頭的解碼器迭代優化對象查詢,以生成類別和方框。解碼器采用的是DINO的解碼器結構,由6層dcoder layer組成,每層decoder layer包含self-attention和cross attention兩部分。
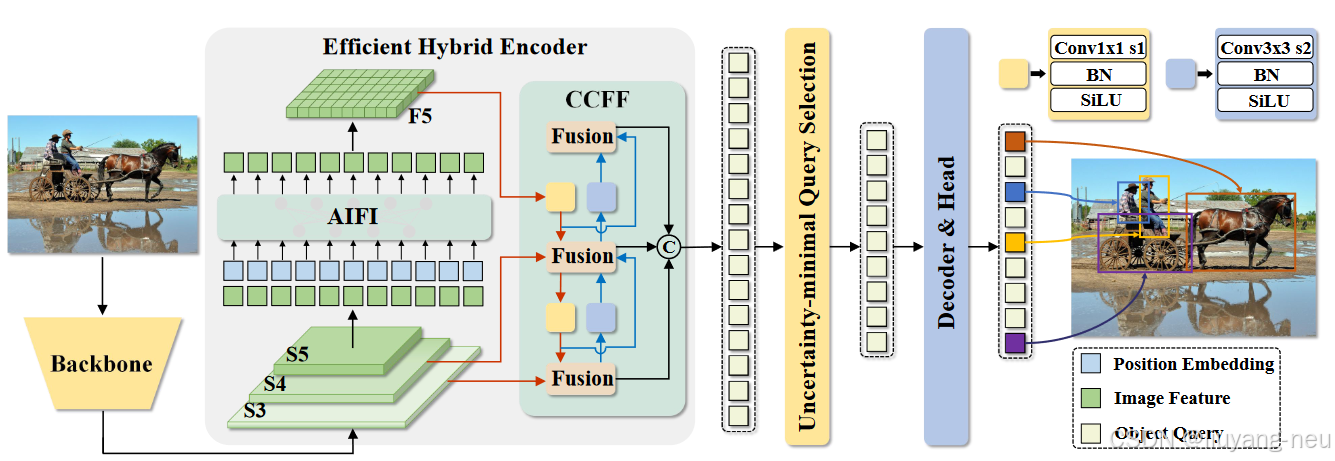
主干網絡:
對于主干網絡,RT-DETR采用CNN網絡,如流行的ResNet系列,或者百度自家研發的HGNet。當然也可以采用如Vit系列的主干網絡,雖然精度可能更高,但是速度不行CNN架構無疑是快于ViT架構的。因此,從實時性的角度出發,選擇CNN架構來做特征提取還是有助于提高DETR系列的實時性,進而提升實用性——毫無疑問,這是階段性的措施,不難想象,未來一定會有新架構全面——不論是性能還是推理速度——取代CNN架構。
和以往的檢測器一樣,RT-DETR也是從主干網絡中抽取三個尺度的輸出,其輸出步長分別為8、16和32(輸出步長output stride通常指的是網絡中特征圖的空間尺寸相對于輸入圖像的縮小比例)
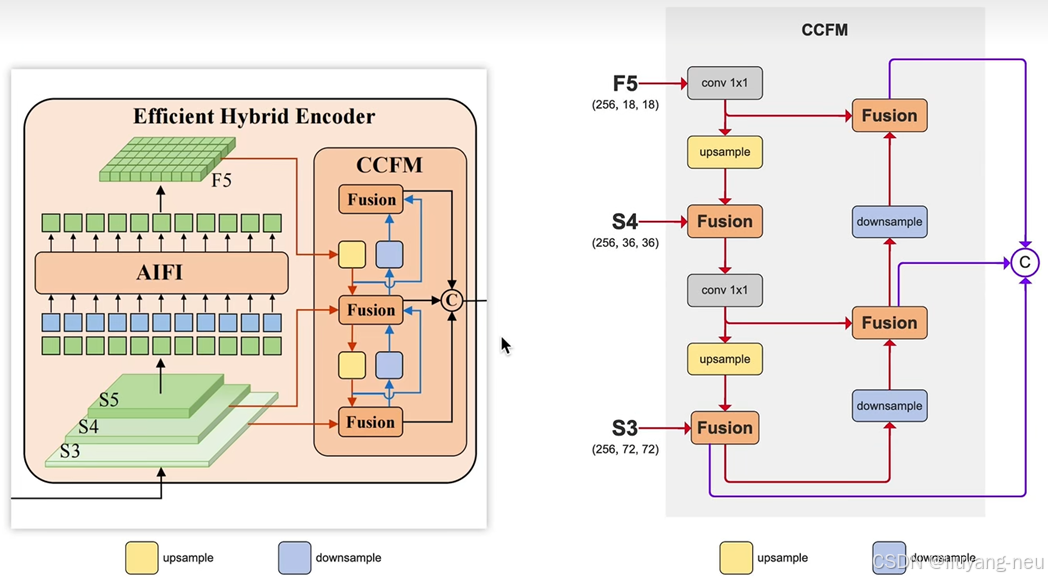
Encoder:
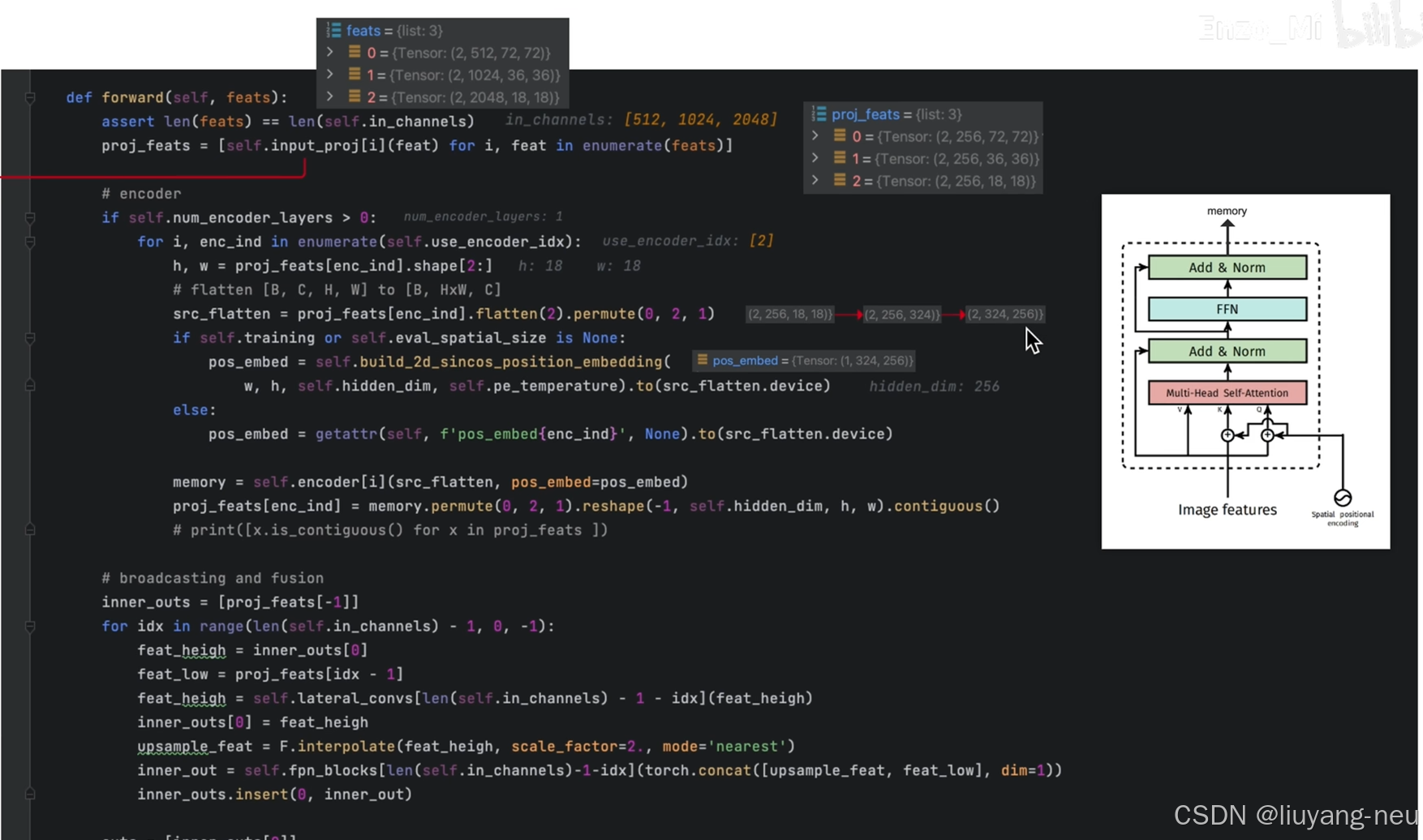
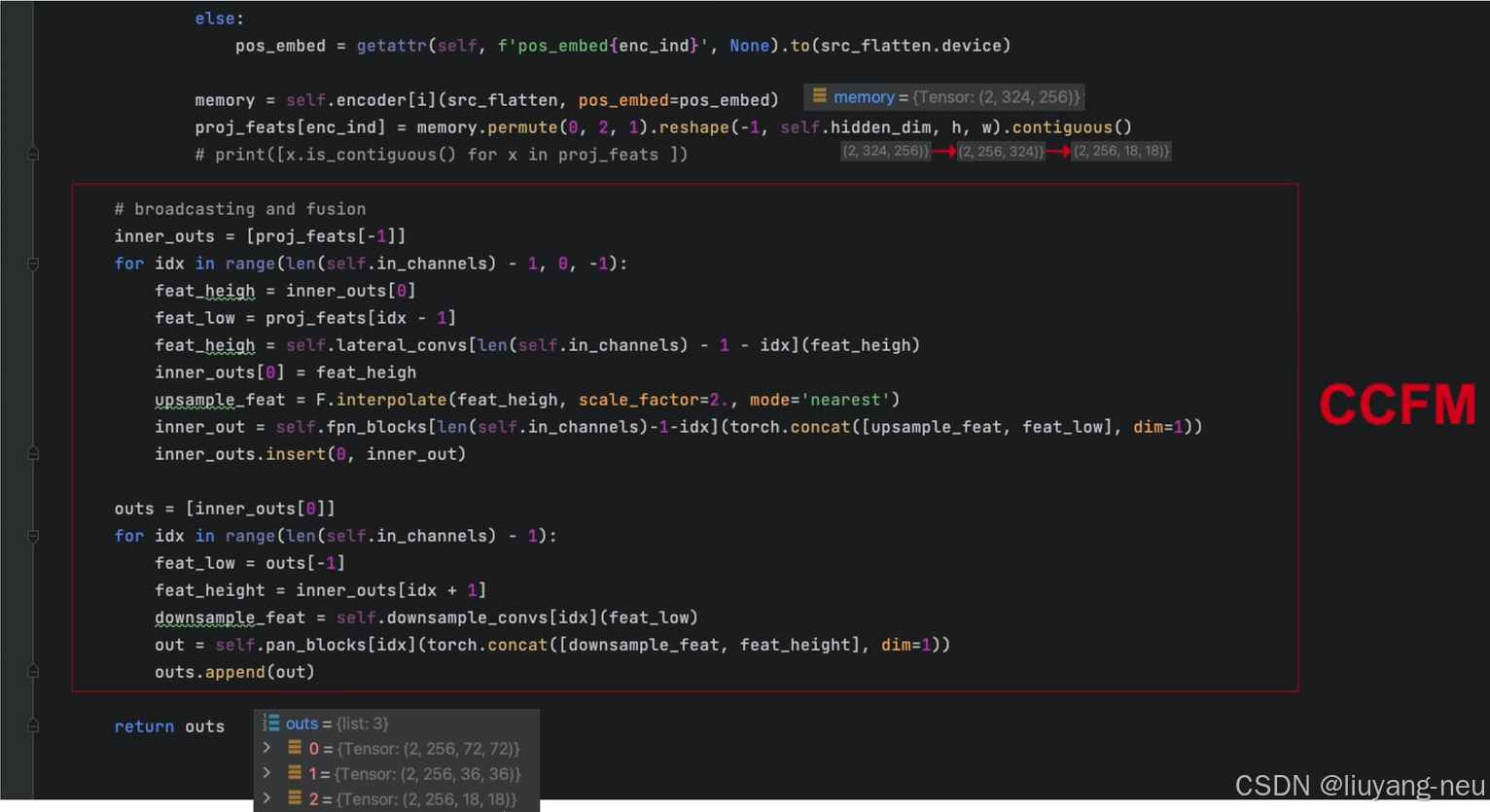
對于頸部網絡,RT-DETR采用了一層Transformer的Encoder,只處理主干網絡輸出的 S5 特征,即AIFI(Attention-based Intra-scale Feature Interaction)模塊。
首先,我們將二維的S5 特征拉成向量,然后交給AIFI模塊處理,其數學過程就是多頭自注意力與FFN,隨后,我們再將輸出調整回二維,記作 F5 ,以便去完成后續的所謂的“跨尺度特征融合。
之所以RT-DETR的AIFI只處理最后的S5 特征,是出于兩點考慮:
- 一方面,以往的DETR,如Deformable DETR是將多尺度的特征展平成序列( RB×C×H×W→RB×N×C ),然后拼接到一起,構成一個序列很長的向量,隨后再交給核心為self attention技術的Transformer encoder去做多尺度之間的特征交互,但這無疑會造成巨大的計算資源的消耗,畢竟self attention技術的平方計算復雜度一直是其廣受詬病的缺陷之一;
- 另一方面,RT-DETR認為相較于較淺的S3 特征和S4 特征,S5 特征擁有更深、更高級、更豐富的語義特征,而self attention機制可能更關注特征的語義性,而非空間局部細節等,因此,作者團隊認為不必讓多尺度特征都放到一個籃子中去。
綜上,作者團隊認為只需將Encoder作用在空間尺寸不太大,信息語義程度有很高的S5 特征上即可,以此來平衡性能和速度——既可以大幅度地減小計算量、提高計算速度,又不會損傷到模型的性能。作者團隊設計了若干對照組驗證了這一點。
不確定性最小Query選擇
Uncertainty-minimal Query Selection:
關于 Query Selection(查詢向量選擇),大家應該并不陌生,這個方法可謂在DETR領域大殺四方,如DAB-DETR對查詢向量進行重構理解,將其解釋為Anchor,DN-DETR通過查詢降噪來應對匈牙利匹配的二義性所導致的訓練時間長的問題,DINO提出從Encoder中選擇Top-k特征進行學習等一系列方法,這都無疑向我們證明,查詢向量很重要,選擇好的Query能夠讓我們事半功倍。
在RT-DETR中,Query selection 的作用是從 Encoder 輸出的特征序列中選擇固定數量的特征作為 object queries ,其經過 Decoder 后由預測頭映射為置信度和邊界框。
DETR中的對象查詢是一組可學習的嵌入,由解碼器優化并由預測頭映射到分類分數和邊界框。然而,這些對象查詢難以解釋和優化,因為它們沒有明確的物理含義。后續工作改進了對象查詢的初始化,并將其擴展到內容查詢和位置查詢(錨點)。其中,提出了查詢選擇方案,它們共同的特點是利用分類分數從編碼器中選擇排名靠前的K個特征來初始化對象查詢(或僅位置查詢)。然而,由于分類分數和位置置信度的分布不一致,一些預測框雖有高分類分數,但與真實框(GT)不接近,這導致選擇了分類分數高但loU分數低的框,而丟棄了分類分數低但loU分數高的框。這降低了檢測器的性能。為了解決這個問題,我們提出了loU感知查詢選擇,通過在訓練期間對模型施加約束,使其對loU分數高的特征產生高分類分數,對loU分數低的特征產生低分類分數。因此,模型根據分類分數選擇的排名靠前的K個編碼器特征的預測框,既有高分類分數又有高loU分數。我們重新制定了檢測器的優化目標如下:
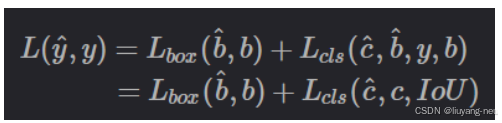
之所以使用IoU軟標簽,是因為按照以往的one-hot方式,完全有可能出現“當定位還不夠準確的時候,類別就已經先學好了”的“未對齊”的情況,畢竟類別的標簽非0即1。但如果將IoU作為類別的標簽,那么類別的學習就要受到回歸的調制,只有當回歸學得也足夠好的時候,類別才會學得足夠好,否則,類別不會過快地先學得比回歸好,因此后者顯式地制約著前者。在使用了這個技巧后,顯然訓練過程中,類別的標簽不再是此前的0和1離散值,而是0~1的連續值。
Decoder網絡:
RT-DETR選擇了基于cross attention的Transformer decoder,并連接若干MLP作為檢測頭,因此,RT-DETR無疑是DETR架構。具體來說,RT-DETR選擇DINO的decoder,使用了具體線性復雜度的deformable attention,同時,在訓練階段,使用到了DINO的“去噪思想”來提升雙邊匹配的樣本質量,加快訓練的收斂速度。整體來看,RT-DETR的檢測頭幾乎就是把DINO的照搬了過來,當然,其中的一些邊邊角角的操作給抹掉了,盡可能達到“精簡”的目的。
部分圖片截取自b站 Enzo_Mi



















