Understanding the Robustness of 3D Object Detection with Bird’s-Eye-View Representations in Autonomous Driving
這篇文章是發表在CVPR上的一篇文章,針對基于BEV的目標檢測算法進行了兩類可靠性分析,即惡劣自然條件以及敵對攻擊。同時也提出了一種進行仿真實驗的方法-3D相關貼圖攻擊。
Natural Robustness
自然條件方面,作者進行了三組測試。首先是最簡單的噪聲、模糊以及數字干擾。在這組測試中,基于BEV的目標檢測有著更好的抗干擾能力。其次是天氣和光照條件,作者使用白天、晚上、晴天、雨天四種條件進行測試,結果證明弱光條件幾乎對所有的目標檢測算法都產生了嚴重影響,雖然整體都產生了下降,但是基于BEV的方法依然表現較好。最后作者測試了部分相機失效的情況,所有算法都產生了不同程度的下降,但是由于BEV全局感知的特點,下降的幅度還要比其它算法稍微好一點點。
Adversarial Robustness
敵對攻擊方面,作者也進行了三組測試。首先是對圖像增加擾動,這里對應的是那種完全無法在現實中進行部署的對整個圖像的擾動,作者使用FGSM和PGD兩種方法進行擾動。結果來看,擾動對于不同模型有著不同程度的影響,對BEVFusion這種多傳感器融合的方法影響較小,對基于BEV的方法有著很嚴重的干擾,作者進一步驗證了為什么會出現這個現象,原因在于BEV的投影過程出現了問題,多個視角下的擾動會在BEV中進行更加復雜的疊加,從而大幅度干擾模型的效果。這部分,作者對多傳感器融合的方法進行了額外驗證,發現只有點云被攻擊時,BEVFusion的效果也是較好的,因為圖像部分被用于補充點云,一定程度上增加了抗干擾能力。
在使用攻擊貼圖的實驗中,作者沒有直接在2d圖像上貼圖,而是先在3d包圍框中確定貼圖位置,之后利用相機的內外參,將端點投影在不同視角下的圖像上,從而得到更加準確的貼圖位置。通過不斷調整貼圖的比例,作者發現基于BEV的方法性能下降更多。最后作者也驗證了特定類別攻擊,即不同類別的攻擊對應不同的貼圖,結果也是相同的,多傳感器融合的方法更加穩定,基于BEV的方法更容易被干擾。
3D Consistent Patch Attack
為了設計一個更加準確的貼圖方法,作者提供了這個3d一致性貼圖攻擊。簡單來說就是利用bounding box的真值,在3d的包圍框中確定貼圖的位置,之后根據相機參數和位置關系,計算貼圖的端點會被投影在不同視角下的哪個位置,之后再進行貼圖就能讓貼的位置更加準確。基于這種方法,作者設計了多相機攻擊和時序攻擊,也就是在連續的幀中都利用這個真值信息進行3d-2d的貼圖計算,結果發現依然是多傳感器融合的方法更加穩定。
老實說這篇文章真沒干啥,可能是作者背景太厲害才能中CVPR,反正就是證明了BEVFormer雖然效果好,但是也容易受干擾。多傳感器融合的方法要比純相機的方法穩定。比較有價值的是計算貼圖位置的這個方法。
Physically Realizable Adversarial Creating Attack Against Vision-Based BEV Space 3D Object Detection
這篇文章是發在CV頂刊TIP的一篇文章,主要是利用一種放在地面上的貼片,來讓基于BEV的目標檢測算法產生前面有物體的錯覺。對于3d目標檢測的攻擊,根據目標其實可以分為兩類:創造一個假的物體(FP)和隱藏一個真實物體(FN),這篇文章對應的就是FP。現有的攻擊有兩方面不足,一方面是貼圖無法模擬十分復雜的場景,另一方面是貼圖的深度信息不好在仿真中調整。所以作者提出了一種針對BEV目標檢測的攻擊方法,主要針對如何準確地貼圖以及如何有效地調整參數進行了設計。

作者提出的攻擊具有三個優勢:在不同場景下都有效果,在不同視角下都有效果,對不同模型都有效果。為了準確地計算貼圖的位置,作者采用了和前面文章相同的方法,在3d場景中貼圖,然后根據投影關系轉換到2d圖像上。由于文章的貼圖是放在地面上的,所以在確定攻擊貼圖的包圍框時,作者進行了一系列的約束。貼圖被放置在前后兩個鏡頭的范圍內,只在地面放置,包圍框的底部以周圍其它物體中最低點為標準,最后可以得到參數化的攻擊貼圖的包圍框的位置,利用這個位置,可以結合相機的內外參進行投影,得到更加準確的2d攻擊圖像位置,確定端點位置后,可以根據2d的位置反投影回原本的3d貼圖,利用插值就可以確定2d平面上這個位置的像素該顯示什么內容。
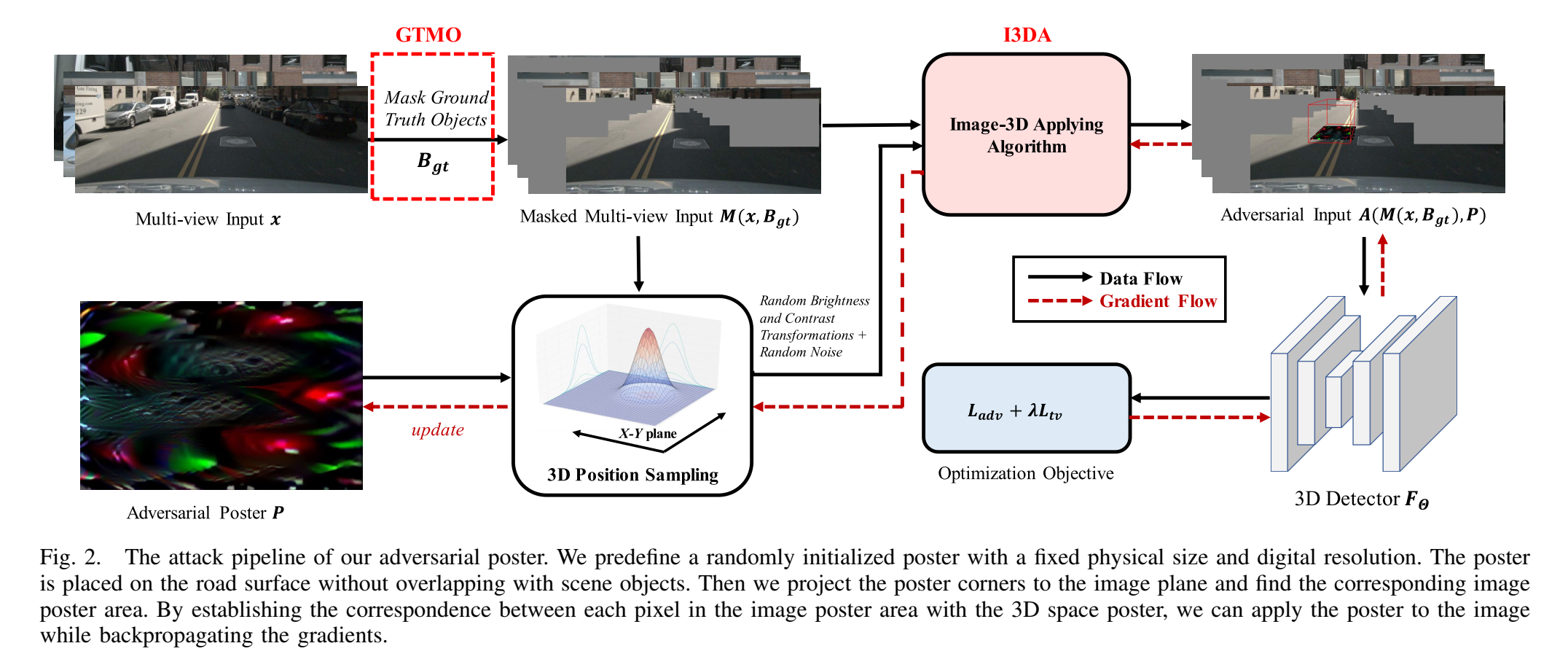
為了更加高效地調整貼圖的內容,作者設計了真值掩碼優化。我們的目標是注入一個原本不存在的物體,從模型準確度的角度來看,場景中原來就存在一些物體,這些物體本身的正確估計會讓我們的攻擊不明顯,為了讓貼圖能夠被更加準確地優化,作者訓練時利用包圍框真值去掉了場景中的其它物體,讓模型能夠直接對貼圖產生反應。整體的優化過程依然是老一套,最大化攻擊效果以及附加的一些平滑度損失。為了提高攻擊的普適性,作者同樣調整了貼圖的角度、光照、對比度等外界條件,從而使最終產生的貼圖有更優的效果。
文章依然屬于“調整參數化貼圖讓目標模型性能下降”的研究,其中比較有意思的是GTMO的部分,相當于擴大了貼圖對目標檢測性能的干擾。采用的貼圖方法和前面文章的貼圖方法一樣,也是先利用3d確定位置之后再轉換到2d平面上。
A Unified Framework for Adversarial Patch Attacks Against Visual 3D Object Detection in Autonomous Driving
與上一篇論文同樣的作者,不光是一作一樣,貌似是三個作者都一樣,內容也很像,讓人有一稿多投的嫌疑。
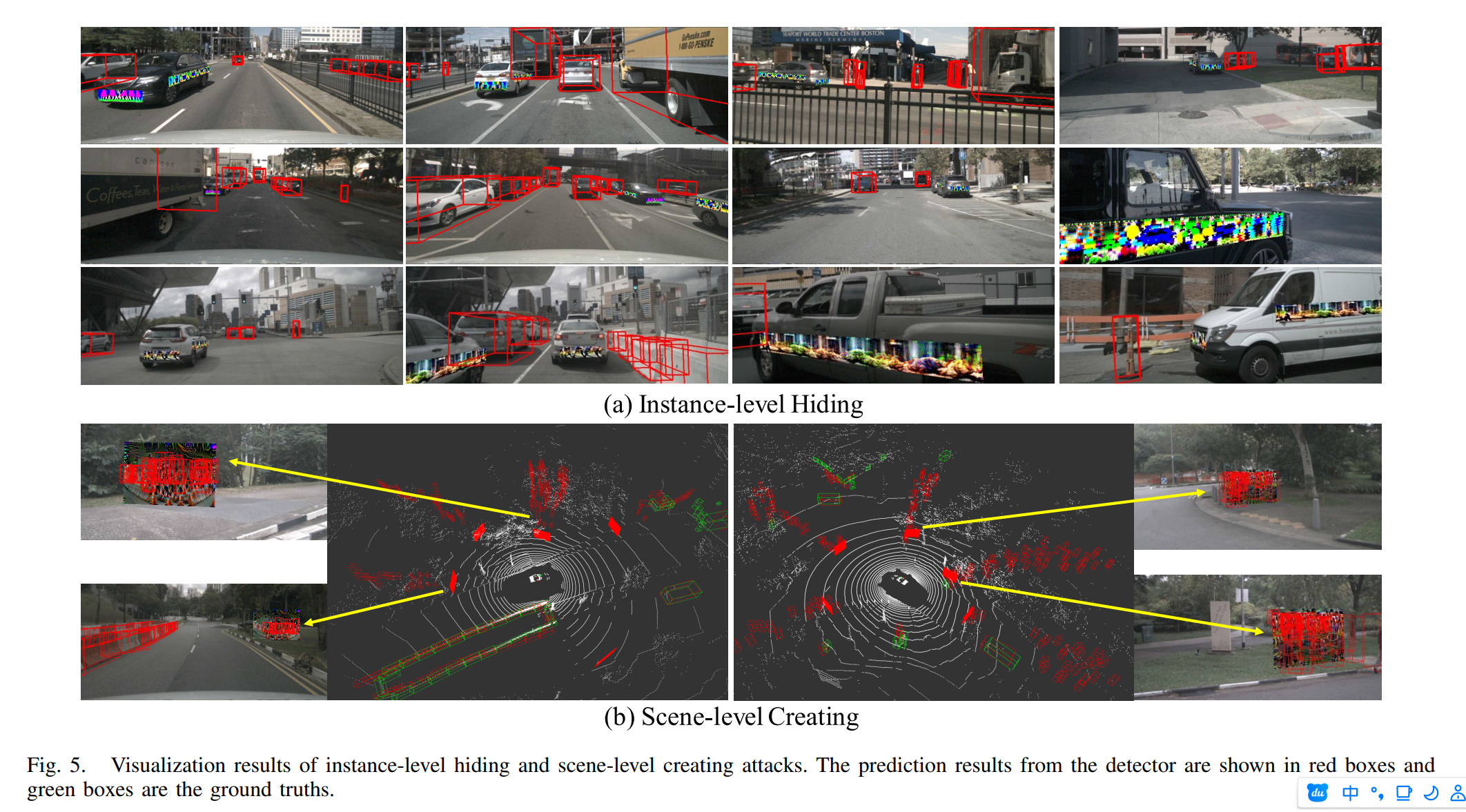
這篇文章主要的目標是讓基于BEV的目標檢測算法產生錯覺,認為一個物體消失了(前面的那一篇文章是在路面上貼圖讓目標檢測檢測算法誤以為有物體)。相同地,作者也使用了3d貼圖的方法,首先將貼圖貼在3d的包圍框上,之后利用內外參計算出觀測結果,之后反向計算像素對應的貼圖的內容。作者認為,不同于2d目標檢測中的稠密貼圖的方法,3d目標檢測由于存在前后景的遮擋問題,所以不能夠采用這種密集貼圖的策略,這會導致貼圖不能被穩定觀測,從而降低貼圖的內容調整。所以作者提出了SOSS策略,每個時刻的多個視角下的圖像中,每個圖像中只選擇一個最接近自車的目標對象,在該對象表面稀疏地渲染補丁,用于訓練隱藏攻擊的對抗補丁。同時作者也使用距離進行了過濾,只將敵對貼圖貼在較近的物體上,從而保證貼圖能夠被穩定優化。
針對不同的任務,作者提出了兩種損失函數。一種是實例級的隱藏貼圖,就是希望目標檢測算法檢測不到被貼圖的物體,為了突出貼圖帶來的影響,作者提出了POAO策略,其實就是上一篇文章中GTMO,通過對其它物體進行遮擋,從而提高patch對最終結果的影響,進而讓patch的優化更加有效。通過調整參數化的貼圖內容,讓模型的輸出檢測出空物體的概率最大化。
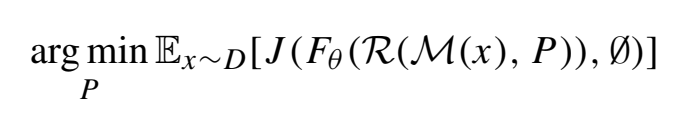
另一種損失函數是場景級的貼圖創建,它的目標是讓目標檢測算法誤認為場景中存在有大量的物體,本質上是讓目標檢測算法在貼圖區域檢測出盡可能多的物體。
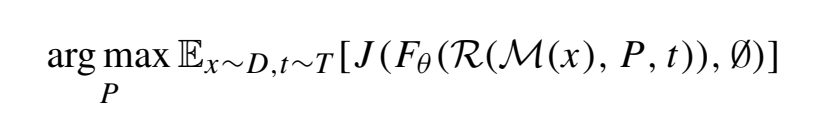
帶有貼圖的物體會被放置在場景中,從實驗中的插圖來看,攻擊的效果是在貼圖的區域產生檢測到了多個物體,這些物體都是在貼圖的區域內,而不是在場景中有均勻分布的物體。
Adv3D: Generating 3D Adversarial Examples in Driving Scenarios with NeRF
和前面的文章不太一樣,這篇文章使用了一個叫做神經輻射場NeRF的技術,簡單來說,NeRF就是利用多個圖像輸入,轉換為一個3d的模型,有點像視覺重建的意思,這篇文章依然是通過調整參數化的攻擊來讓目標模型最差,但是很大的一個區別在于,他使用了NeRF來生成一個帶有攻擊的車輛。
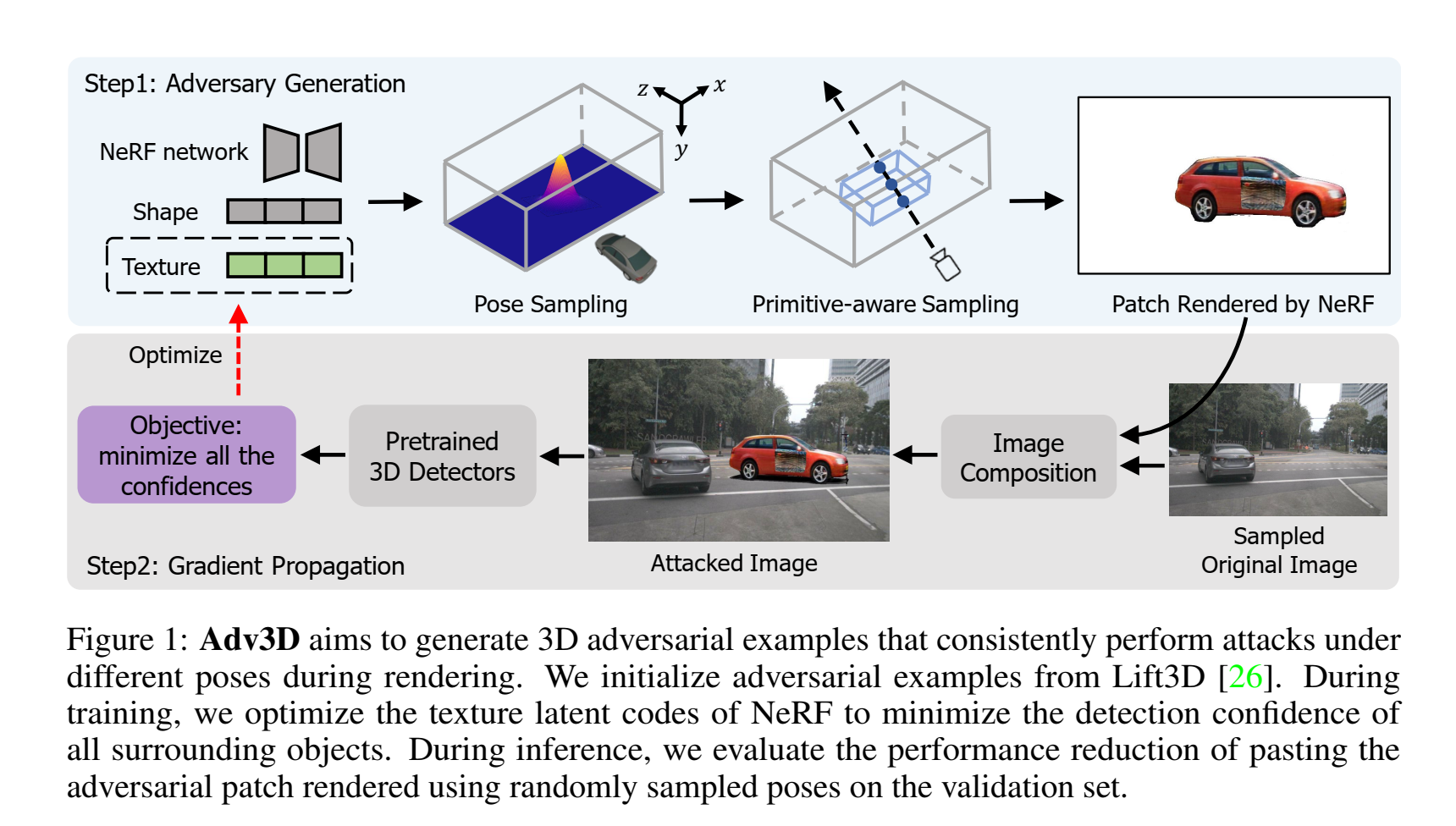
NeRF中,對于一張圖像的每個像素,我們首先以光心為原點,做一條射線穿過這個像素,在一定范圍內,均勻地提取k個點,這k個點的坐標會被作為輸入送入NeRF模型中,輸出的是該點的色彩c和密度𝜏,之后對其積分,就可以得到該像素最終的顏色。在攻擊的過程中,首先我們有許多已經訓練好的NeRF對象,我們可以將其視為許多個3d物體,之后我們需要先確定物體的位姿,這會影響到我們的車輛會觀測到哪個角度下的攻擊車輛,之后根據這個位姿,生成該視角下我們能觀測到的這個車的圖像,在生成的過程中,NeRF會有紋理、形狀兩個參數,這里我們固定形狀只調整紋理,這樣做是為了保證不改變車輛的形狀,只調整車輛貼圖的紋理。為了讓貼圖的位置更加可靠,作者引入了一定的語義約束,簡單來說就是只選擇標記為車窗的點進行紋理的改變,這樣子可以實現更加可行的貼圖位置。最終得到的帶有攻擊的觀測圖像會被疊加在原圖上,之后送入被攻擊模型得到一個結果,通過不斷調整參數化的攻擊(在這里是NeRF的紋理參數)從而實現攻擊效果的最大化。
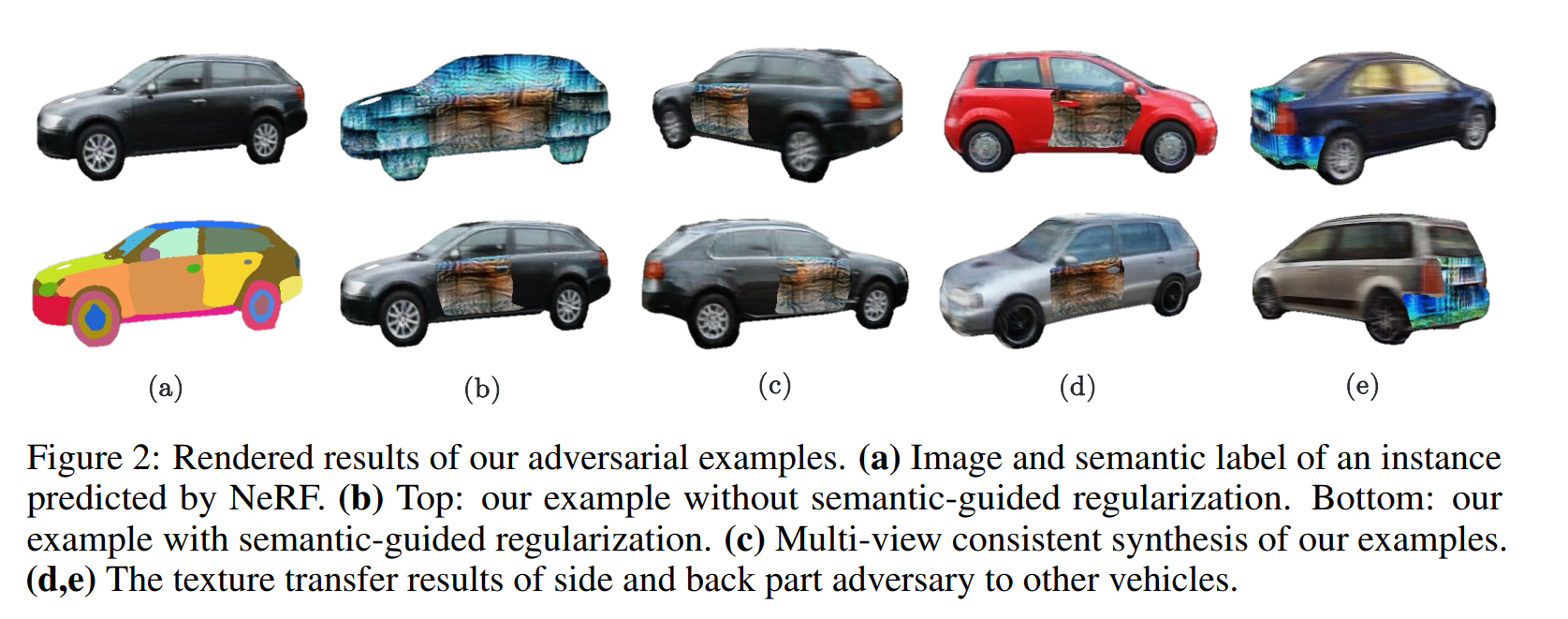
雖然使用NeRF能夠提供一個多角度下的攻擊注入,但是本質上注入的攻擊依然無法反應采集圖像時場景中的光照的特點,依然屬于貼圖的范圍。但是總的來說,引入NeRF技術確實是一個很好的方法。





)


深度學習---計算機視覺基礎)


![[服務器備份教程] Rclone實戰:自動備份數據到阿里云OSS/騰訊云COS等對象存儲](http://pic.xiahunao.cn/[服務器備份教程] Rclone實戰:自動備份數據到阿里云OSS/騰訊云COS等對象存儲)


)




