引言
在一些大數據分析場景比如電商大數據營銷中,我們需要快速分析存儲海量用戶行為數據(如瀏覽、加購、下單),以進行用戶行為分析,優化營銷策略。傳統方法依賴 Spark/Presto 集群或 Redshift 查詢 S3 上的 Parquet/ORC 文件,這對于需要快速迭代、按需執行的分析來說,成本高、運維復雜且響應不夠敏捷。
本文將介紹一種現代化的 Serverless 解決方案:利用 S3 Tables(內置優化的 Apache Iceberg 支持)作為存儲基礎,并結合 PyIceberg 的便捷性與 DuckDB 的高性能嵌入式分析能力,直接在 AWS Lambda 等環境中實現對 S3 數據的低成本、高效率即時查詢,徹底擺脫集群運維的負擔,加速您的用戶行為分析。關鍵工具及技術點:
- S3 Tables:在 S3 上為表格數據(采用內建優化的 Apache Iceberg 格式)設計的、具備自動性能優化的智能對象存儲。
- Lambda:提供按需運行代碼的無服務器計算能力
- PyIceberg:Iceberg 官方開源項目,提供簡潔的 Python API 來操作 Iceberg 表
- DuckDB:高性能嵌入式分析引擎,支持 Iceberg rest catalog 接口
|
|
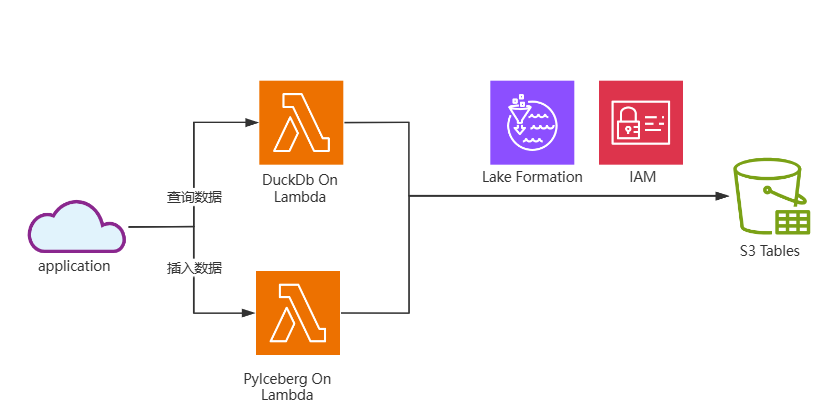
核心實踐
使用 PyIceberg 創建和插入 S3 Tables
首先,安裝 python 依賴
pip install pyiceberg[s3fs, pyarrow]創建表和插入表的核心代碼如下,通過 pyiceberg 對接 S3 Tables 的 rest catalog api 來實現 catalog 的獲取,從而實現表的創建、列出,以及數據的插入等操作。
from pyiceberg.catalog import load_catalog
import pyarrow as pa
rest_catalog = load_catalog("catalog_name",**{"type": "rest","warehouse": "arn:aws:s3tables:us-west-2:${awsAccountId}:bucket/testtable","uri": "https://s3tables.us-west-2.amazonaws.com/iceberg","rest.sigv4-enabled": "true","rest.signing-name": "s3tables","rest.signing-region": "us-west-2","py-io-impl": "pyiceberg.io.fsspec.FsspecFileIO"}
)
# 新建namespace
rest_catalog.create_namespace("namespace_example")
# 新建表
rest_catalog.create_table("namespace_example.test_table",schema=pa.schema([("id", pa.int32()),("data", pa.string()),])
)
# 打印表列表
tables_list = rest_catalog.list_tables("namespace_example")
print(tables_list)
# 獲取表對象
table = rest_catalog.load_table("namespace_example.test_table")
df = pa.Table.from_pylist([{"id": 303, "data": 'test insert icb'}], schema=table.schema().as_arrow()
)
#插入表
table.append(df)
# 讀取表并打印
for row in table.scan().to_arrow().to_pylist():
print(row)
可以先通過本地配置 AWS CLI 權限然后運行代碼進行測試,然后通過 docker 的方式部署 Lambda。
參考 Dockerfile:
FROM public.ecr.aws/lambda/python:3.12
COPY requirements.txt ${LAMBDA_TASK_ROOT}
RUN pip install -r requirements.txt
COPY lambda_function.py ${LAMBDA_TASK_ROOT}
CMD [ "lambda_function.handler" ]
使用 DuckDB 在 S3 Tables 進行復雜數據分析查詢
這里使用 1.2.1 版本的 DuckDB,通過 pip install duckdb==1.2.1 來安裝,DuckDB 最新的夜間版本插件支持了 Apache Iceberg REST 目錄,而 S3 Tables 也有 REST 目錄接口。可以通過在 Lambda 上部署 DuckDB 來讀取查詢分析 S3 Tables 里面的數據。也可以把 DuckDB 嵌入到您的應用程序中直接查詢 S3 Tables。
DuckDB 的 Lambda 實現代碼如下,結合了 boto3 的 S3 Tables 客戶端,通過 api 把 S3 Tables 里面的桶加載到 DuckDB 的 catalog 中,后續就可以直接通過 sql 來進行查詢了。Lambda 的入口函數接收 sql,然后返回 sql 的執行結果,示例 sql: Select * from bucketname.namespace.tablename 就可以直接查詢出對應桶里面的表的數據了,需要注意的是在 DuckDB 里面一般通過 DETACH 和 ATTACH 來獲取最新的 catalog 表元數據。
import os
import duckdb
import boto3
os.environ['HOME'] = '/tmp'
con = duckdb.connect(database=':memory:', config={'memory_limit': '9GB','worker_threads': 5,'temp_directory':'/tmp/file/overmem'})
# 驗證設置
con.execute("""
FORCE INSTALL aws FROM core_nightly;
FORCE INSTALL httpfs FROM core_nightly;
FORCE INSTALL iceberg FROM core_nightly;
CREATE SECRET (TYPE s3,PROVIDER credential_chain
);
""")
s3tables = boto3.client('s3tables')
table_buckets = s3tables.list_table_buckets(maxBuckets=1000)['tableBuckets']
def handler(event, context):for table_bucket in table_buckets:name = table_bucket['name']arn = table_bucket['arn']try:con.execute(f"DETACH {name};")except:passcon.execute(f"""ATTACH '{arn}' AS {name} (TYPE iceberg,ENDPOINT_TYPE s3_tables);""")sql = event.get("sql")try:result = con.execute(sql).fetchall()return {"statusCode": 200,"result": result}except Exception as e:return {"statusCode": 500,"error": str(e)}
Dockerfile 可以參考插入部分的 Dockerfile,通過鏡像部署到 Lambda,并設置好對應的 IAM 角色權限以及 Lambda 的超時以及內存設置。這里代碼通過 duckdb.connect(database=’:memory:’, config={‘memory_limit’: ‘9GB’,’worker_threads’: 5,’temp_directory’:’/tmp/file/overmem’})來設置最大內存的使用和工作的線程數,這個可以根據實際的需要來調整
數據分析實踐
測試數據集:電商用戶行為數據,總量 13 億數據,字段如下:
user_id??? ???????????STRING?? ? ??‘用戶ID(非真實ID),經抽樣&字段脫敏處理后得到’
item_id??? ???????????STRING? ?? ??‘商品ID(非真實ID),經抽樣&字段脫敏處理后得到’
item_category??? STRING?? ? ??‘商品類別ID(非真實ID),經抽樣&字段脫敏處理后得到’
behavior_type??? STRING??? ???‘用戶對商品的行為類型,包括瀏覽、收藏、加購物車、購買,pv,fav,cart,buy)’
behavior_time??? STRING?? ? ??‘行為時間,精確到小時級別’
測試 sql:用戶行為數據漏斗分析
WITH user_behavior_counts AS (SELECTuser_id,SUM(CASE WHEN behavior_type = 'pv' THEN 1 ELSE 0 END) AS view_count,SUM(CASE WHEN behavior_type = 'fav' THEN 1 ELSE 0 END) AS favorite_count,SUM(CASE WHEN behavior_type = 'cart' THEN 1 ELSE 0 END) AS cart_count,SUM(CASE WHEN behavior_type = 'buy' THEN 1 ELSE 0 END) AS purchase_countFROM testtable.testdb.commerce_shoppingGROUP BY user_id
),
funnel_stages AS (SELECTCOUNT(DISTINCT user_id) AS total_users,COUNT(DISTINCT CASE WHEN view_count > 0 THEN user_id END) AS users_with_views,COUNT(DISTINCT CASE WHEN favorite_count > 0 THEN user_id END) AS users_with_favorites,COUNT(DISTINCT CASE WHEN cart_count > 0 THEN user_id END) AS users_with_cart_adds,COUNT(DISTINCT CASE WHEN purchase_count > 0 THEN user_id END) AS users_with_purchasesFROM user_behavior_counts
)
SELECTtotal_users,users_with_views,users_with_favorites,users_with_cart_adds,users_with_purchases,ROUND(100.0 * users_with_views / total_users, 2) AS view_rate,ROUND(100.0 * users_with_favorites / users_with_views, 2) AS view_to_favorite_rate,ROUND(100.0 * users_with_cart_adds / users_with_favorites, 2) AS favorite_to_cart_rate,ROUND(100.0 * users_with_purchases / users_with_cart_adds, 2) AS cart_to_purchase_rate,ROUND(100.0 * users_with_purchases / total_users, 2) AS overall_conversion_rate
FROM funnel_stages;
Lambda 測試結果:消耗內存 1934M
用時:37s
關鍵優勢
將 PyIceberg 和 DuckDB 運行在 AWS Lambda 上來訪問 S3 上的 Iceberg 表,這種 Serverless 數據湖模式主要的優勢如下:
- 低門檻:主要依賴 python 和 sql,這兩種是數據開發領域最常見的技能,大大降低了學習和使用的門檻,同時基礎設施 0 依賴且易于部署,不需要投入基礎設施運維。
- 高性價比:Lambda 按實際計算時間付費且自動伸縮,而 S3 的存儲成本也較為低廉。加上 DuckDB 高性能的特性,這意味著更短的 Lambda 執行時間,進一步降低成本。
- 開源與靈活性:核心組件 Apache Iceberg、DuckDB 和 PyIceberg 均為廣泛應用的開源項目。受益于活躍的開源社區支持,可以獲得持續的功能更新、問題修復和豐富的學習資源。
典型應用場景
- 低成本海量分析負載:對于需要控制成本,但仍需進行有效數據分析的場景,如中小型企業或特定項目預算有限的情況。
- 非頻繁或突發性查詢:如定期的報表生成、臨時的業務數據洞察、偶爾進行的數據探索等,這些場景下按需付費的 Lambda + DuckDB 極具優勢。
- 事件驅動的數據處理:由 S3 事件觸發 Lambda (PyIceberg) 進行數據驗證、轉換和加載到 Iceberg 表,后續可由另一個 Lambda (DuckDB) 進行即時查詢或聚合。
- 交互式查詢接口后端:通過 API Gateway 暴露一個 Lambda (DuckDB) 端點,為內部用戶或應用提供一個低成本的 SQL 查詢接口,用于查詢特定范圍的數據。
- 快速原型驗證:在開發或研究階段,快速搭建一個功能完備的數據湖查詢環境,用于驗證想法或進行小規模實驗。

)



)

)





)
)



)
