在上一篇中,我們探索了線性代數如何幫助AI表示數據(向量、矩陣)和變換數據(矩陣乘法)。但AI的魅力遠不止于此,它最核心的能力是“學習”——從數據中自動調整自身,以做出越來越準確的預測或決策。這個“學習”過程的背后功臣,就是我們今天要深入探討的微積分 (Calculus)。
“微積分?是不是求導、積分,聽起來比線性代數還頭大!” 很多朋友可能會有這樣的印象。確實,微積分有其嚴謹的數學體系,但其核心思想卻非常直觀,并且與AI的“學習”機制緊密相連。我們將一起解開:
- 導數 (Derivatives):變化率的奧秘,AI如何感知參數微調的效果?
- 偏導數 (Partial Derivatives):多維世界中的導航,AI如何判斷哪個參數更值得調整?
- 梯度 (Gradient):最陡峭的路徑,AI如何找到最佳參數組合的方向?
- 鏈式法則 (Chain Rule):層層遞進的智慧,AI如何高效計算復雜模型的“學習信號”?
- Jacobian/Hessian 矩陣:高階的視角,AI如何更精細地分析和優化模型?
準備好了嗎?讓我們一起踏上微積分之旅,看看它是如何驅動AI模型不斷進化,變得越來越“聰明”的!
導數:洞察變化的瞬時魔法
想象一下你正在開車。你的速度是什么?它告訴你,在某一瞬間,你的位置相對于時間是如何變化的。如果速度是60公里/小時,意味著如果保持這個速度,一小時后你就會前進60公里。這個“速度”,在數學上就是導數 (Derivative) 的一個經典例子。
什么是導數?
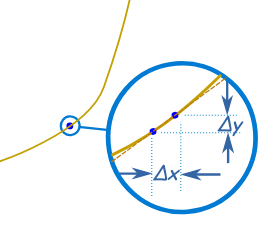
導數衡量的是一個函數 f ( x ) f(x) f(x) 在某一點 x 0 x_0 x0? 處,當自變量 x x x 發生極其微小的變化時,函數值 f ( x ) f(x) f(x) 相應變化的速率或趨勢。幾何上,它代表了函數曲線在該點切線的斜率。
如果函數 f ( x ) f(x) f(x) 在 x 0 x_0 x0? 點的導數是正數,說明當 x x x 略微增加時, f ( x ) f(x) f(x) 也傾向于增加(函數在該點“上升”)。
如果導數是負數,說明當 x x x 略微增加時, f ( x ) f(x) f(x) 傾向于減少(函數在該點“下降”)。
如果導數是零,說明函數在該點可能達到了一個平穩狀態(可能是局部最高點、最低點或平坦點)。
數學上,導數 f ′ ( x ) f'(x) f′(x) 或 d f d x \frac{df}{dx} dxdf? 定義為:
f ′ ( x ) = lim ? Δ x → 0 f ( x + Δ x ) ? f ( x ) Δ x f'(x) = \lim_{\Delta x \to 0} \frac{f(x + \Delta x) - f(x)}{\Delta x} f′(x)=limΔx→0?Δxf(x+Δx)?f(x)?
這個公式看起來有點嚇人,但它的意思就是:當 x x x 的變化量 Δ x \Delta x Δx 趨近于零時,函數值的變化量 f ( x + Δ x ) ? f ( x ) f(x + \Delta x) - f(x) f(x+Δx)?f(x) 與 Δ x \Delta x Δx 的比值。
在AI中的意義:損失函數的“敏感度”
在機器學習中,我們通常會定義一個損失函數 (Loss Function) L ( 參數 ) L(\text{參數}) L(參數)。這個函數用來衡量模型的預測結果與真實答案之間的“差距”或“錯誤程度”。我們的目標是調整模型的參數 (Parameters)(比如線性回歸中的權重 w w w 和偏置 b b b,或者神經網絡中的大量權重和偏置),使得損失函數的值盡可能小。
假設我們的模型只有一個參數 w w w,損失函數是 L ( w ) L(w) L(w)。那么, L ( w ) L(w) L(w) 關于 w w w 的導數 d L d w \frac{dL}{dw} dwdL? 就告訴我們:
當我稍微改變參數 w w w 一點點時,損失函數 L ( w ) L(w) L(w) 會如何變化?
- 如果 d L d w > 0 \frac{dL}{dw} > 0 dwdL?>0,意味著增加 w w w 會導致損失增加。所以,為了減小損失,我們應該減小 w w w。
- 如果 d L d w < 0 \frac{dL}{dw} < 0 dwdL?<0,意味著增加 w w w 會導致損失減小。所以,為了減小損失,我們應該增加 w w w。
- 如果 d L d w = 0 \frac{dL}{dw} = 0 dwdL?=0,意味著我們可能找到了一個損失函數的局部最小值(或者最大值、鞍點)。此時,微調 w w w 對損失的影響很小。
這種“敏感度分析”是AI模型學習和優化的核心。通過計算導數,AI模型知道應該朝哪個方向調整參數才能讓損失更小。
一個簡單的例子:
假設損失函數是 L ( w ) = w 2 L(w) = w^2 L(w)=w2。這是一個簡單的拋物線,在 w = 0 w=0 w=0 處取得最小值0。
它的導數是 d L d w = 2 w \frac{dL}{dw} = 2w dwdL?=2w。
- 當 w = 2 w=2 w=2 時, d L d w = 2 × 2 = 4 \frac{dL}{dw} = 2 \times 2 = 4 dwdL?=2×2=4 (正數)。這告訴我們,在 w = 2 w=2 w=2 的位置,如果增加 w w w,損失會增加。所以我們應該減小 w w w。
- 當 w = ? 3 w=-3 w=?3 時, d L d w = 2 × ( ? 3 ) = ? 6 \frac{dL}{dw} = 2 \times (-3) = -6 dwdL?=2×(?3)=?6 (負數)。這告訴我們,在 w = ? 3 w=-3 w=?3 的位置,如果增加 w w w,損失會減小。所以我們應該增加 w w w。
- 當 w = 0 w=0 w=0 時, d L d w = 2 × 0 = 0 \frac{dL}{dw} = 2 \times 0 = 0 dwdL?=2×0=0。我們到達了損失函數的最低點。
這就是最基本的優化思想:沿著導數指示的“相反”方向調整參數,就能逐步逼近損失函數的最小值。 這就是著名的梯度下降 (Gradient Descent) 算法的雛形。
小結:導數衡量函數在某一點的變化率或切線斜率。在AI中,損失函數關于模型參數的導數,指明了參數調整的方向,以使損失減小。
偏導數:多維參數空間的導航員
在上一節,我們討論了只有一個參數 w w w 的簡單情況。但現實中的AI模型,比如一個深度神經網絡,可能有數百萬甚至數十億個參數!損失函數 L L L 不再是 L ( w ) L(w) L(w),而是 L ( w 1 , w 2 , w 3 , . . . , w n ) L(w_1, w_2, w_3, ..., w_n) L(w1?,w2?,w3?,...,wn?),其中 w i w_i wi? 是模型的第 i i i 個參數。
這時,我們如何知道應該調整哪個參數,以及如何調整呢?這就需要偏導數 (Partial Derivative)。
什么是偏導數?
當一個函數依賴于多個自變量時,比如 f ( x , y ) f(x, y) f(x,y),我們想知道當其中一個自變量(比如 x x x)發生微小變化,而保持其他自變量(比如 y y y)不變的情況下,函數值 f ( x , y ) f(x, y) f(x,y) 如何變化。這個變化率就是 f ( x , y ) f(x, y) f(x,y) 關于 x x x 的偏導數,記作 ? f ? x \frac{\partial f}{\partial x} ?x?f? 或 f x f_x fx?。
同理, f ( x , y ) f(x, y) f(x,y) 關于 y y y 的偏導數 ? f ? y \frac{\partial f}{\partial y} ?y?f? 或 f y f_y fy?,是保持 x x x 不變, y y y 發生微小變化時,函數值的變化率。
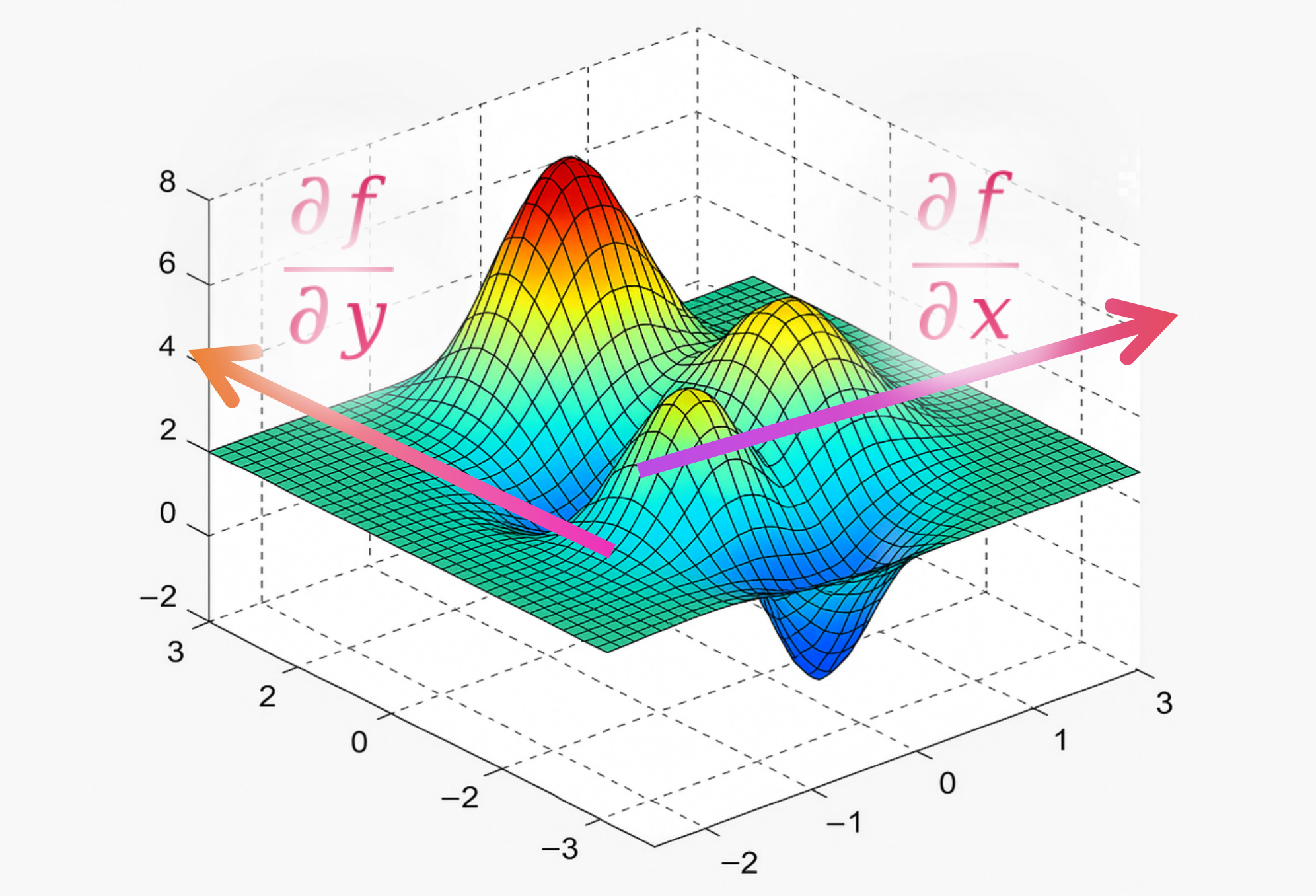
幾何直觀:想象一個三維空間中的曲面 z = f ( x , y ) z = f(x, y) z=f(x,y)(比如一座山)。
? f ? x \frac{\partial f}{\partial x} ?x?f? 表示如果你站在山上的某一點 ( x 0 , y 0 ) (x_0, y_0) (x0?,y0?),只沿著 x x x 軸方向(東西方向)移動一小步,你的高度會如何變化(坡度)。
? f ? y \frac{\partial f}{\partial y} ?y?f? 表示如果你只沿著 y y y 軸方向(南北方向)移動一小步,你的高度會如何變化。
計算偏導數:計算一個變量的偏導數時,只需將其他變量視為常數,然后按照普通單變量函數的求導法則進行即可。
例子:
假設損失函數 L ( w 1 , w 2 ) = w 1 2 + 3 w 1 w 2 + 2 w 2 2 L(w_1, w_2) = w_1^2 + 3w_1w_2 + 2w_2^2 L(w1?,w2?)=w12?+3w1?w2?+2w22?。
計算關于 w 1 w_1 w1? 的偏導數 ? L ? w 1 \frac{\partial L}{\partial w_1} ?w1??L?:
把 w 2 w_2 w2? 看作常數。
? L ? w 1 = ? ? w 1 ( w 1 2 ) + ? ? w 1 ( 3 w 1 w 2 ) + ? ? w 1 ( 2 w 2 2 ) \frac{\partial L}{\partial w_1} = \frac{\partial}{\partial w_1}(w_1^2) + \frac{\partial}{\partial w_1}(3w_1w_2) + \frac{\partial}{\partial w_1}(2w_2^2) ?w1??L?=?w1???(w12?)+?w1???(3w1?w2?)+?w1???(2w22?)
= 2 w 1 + 3 w 2 × ? ? w 1 ( w 1 ) + 0 = 2w_1 + 3w_2 \times \frac{\partial}{\partial w_1}(w_1) + 0 =2w1?+3w2?×?w1???(w1?)+0 (因為 2 w 2 2 2w_2^2 2w22? 相對于 w 1 w_1 w1? 是常數)
= 2 w 1 + 3 w 2 = 2w_1 + 3w_2 =2w1?+3w2?
計算關于 w 2 w_2 w2? 的偏導數 ? L ? w 2 \frac{\partial L}{\partial w_2} ?w2??L?:
把 w 1 w_1 w1? 看作常數。
? L ? w 2 = ? ? w 2 ( w 1 2 ) + ? ? w 2 ( 3 w 1 w 2 ) + ? ? w 2 ( 2 w 2 2 ) \frac{\partial L}{\partial w_2} = \frac{\partial}{\partial w_2}(w_1^2) + \frac{\partial}{\partial w_2}(3w_1w_2) + \frac{\partial}{\partial w_2}(2w_2^2) ?w2??L?=?w2???(w12?)+?w2???(3w1?w2?)+?w2???(2w22?)
= 0 + 3 w 1 × ? ? w 2 ( w 2 ) + 4 w 2 = 0 + 3w_1 \times \frac{\partial}{\partial w_2}(w_2) + 4w_2 =0+3w1?×?w2???(w2?)+4w2? (因為 w 1 2 w_1^2 w12? 相對于 w 2 w_2 w2? 是常數)
= 3 w 1 + 4 w 2 = 3w_1 + 4w_2 =3w1?+4w2?
在AI中的意義:分別考察每個參數的影響
對于一個擁有多個參數 w 1 , w 2 , . . . , w n w_1, w_2, ..., w_n w1?,w2?,...,wn? 的AI模型,損失函數 L ( w 1 , . . . , w n ) L(w_1, ..., w_n) L(w1?,...,wn?) 關于每個參數 w i w_i wi? 的偏導數 ? L ? w i \frac{\partial L}{\partial w_i} ?wi??L? 告訴我們:
如果我只微調參數 w i w_i wi? 一點點,同時保持其他所有參數 w j ( j ≠ i ) w_j (j \neq i) wj?(j=i) 不變,那么損失函數 L L L 會如何變化?
這個信息至關重要,因為它讓我們能夠獨立地評估每個參數對整體損失的“貢獻”或“敏感度”。如果 ? L ? w i \frac{\partial L}{\partial w_i} ?wi??L? 的絕對值很大,說明參數 w i w_i wi? 對損失的影響比較顯著,調整它可能會帶來較大的損失變化。
小結:偏導數衡量多變量函數在某一點沿著某個坐標軸方向的變化率。在AI中,損失函數關于各個模型參數的偏導數,為我們指明了單獨調整每個參數時損失的變化趨勢。
梯度:下降最快的方向盤
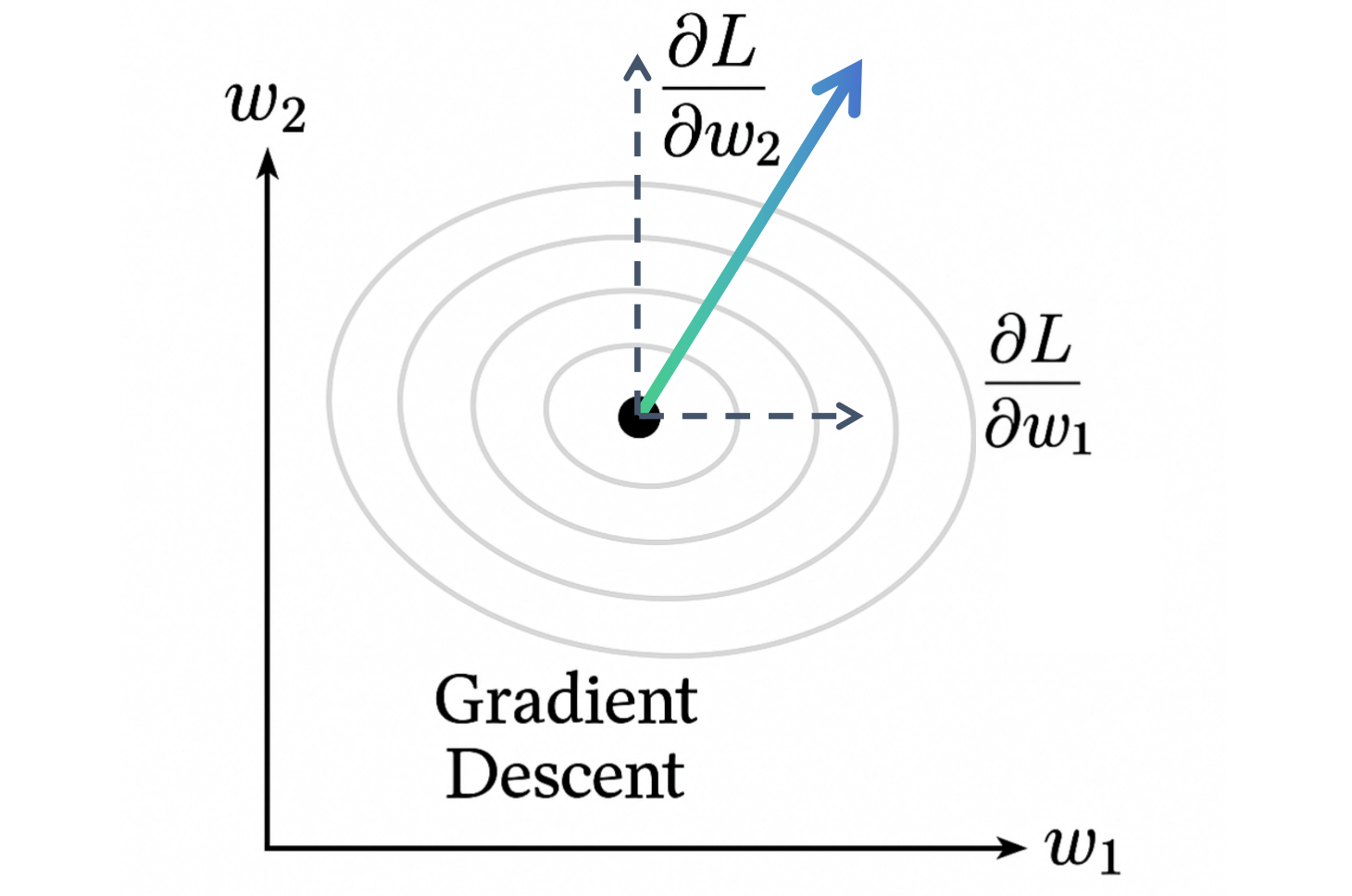
我們已經知道了如何計算損失函數 L L L 關于每一個參數 w i w_i wi? 的偏導數 ? L ? w i \frac{\partial L}{\partial w_i} ?wi??L?。這些偏導數各自描述了在一個特定參數維度上的變化趨勢。但我們如何把這些信息整合起來,找到一個讓損失函數 L L L 整體下降最快的方向呢?答案就是梯度 (Gradient)。
什么是梯度?
對于一個多變量函數 L ( w 1 , w 2 , . . . , w n ) L(w_1, w_2, ..., w_n) L(w1?,w2?,...,wn?),它的梯度是一個向量,由該函數關于所有自變量的偏導數構成:
? L = grad ( L ) = [ ? L ? w 1 , ? L ? w 2 , . . . , ? L ? w n ] \nabla L = \text{grad}(L) = \left[ \frac{\partial L}{\partial w_1}, \frac{\partial L}{\partial w_2}, ..., \frac{\partial L}{\partial w_n} \right] ?L=grad(L)=[?w1??L?,?w2??L?,...,?wn??L?]
這里的 ? \nabla ? (nabla) 符號是梯度的標準表示。
梯度的關鍵特性:
在函數定義域內的任意一點,梯度向量指向該點函數值增長最快的方向。
相應地,負梯度向量 ( ? ? L -\nabla L ??L ) 指向該點函數值減小最快的方向。
幾何直觀:再次想象那座山 z = L ( w 1 , w 2 ) z = L(w_1, w_2) z=L(w1?,w2?)(這里 w 1 , w 2 w_1, w_2 w1?,w2? 是平面坐標)。你在山上的某一點,想盡快下到山谷(損失最小的地方)。
- ? L ? w 1 \frac{\partial L}{\partial w_1} ?w1??L? 告訴你東西方向的坡度。
- ? L ? w 2 \frac{\partial L}{\partial w_2} ?w2??L? 告訴你南北方向的坡度。
- 梯度 ? L = [ ? L ? w 1 , ? L ? w 2 ] \nabla L = [\frac{\partial L}{\partial w_1}, \frac{\partial L}{\partial w_2}] ?L=[?w1??L?,?w2??L?] 是一個二維向量,它指向山上坡度最陡峭的上坡方向。
- 那么, ? ? L = [ ? ? L ? w 1 , ? ? L ? w 2 ] -\nabla L = [-\frac{\partial L}{\partial w_1}, -\frac{\partial L}{\partial w_2}] ??L=[??w1??L?,??w2??L?] 就指向坡度最陡峭的下坡方向。
梯度下降算法 (Gradient Descent)
梯度下降是AI中最核心、最常用的優化算法之一。它的思想非常樸素和直觀:為了最小化損失函數 L L L,我們從一個隨機的參數點 W 0 = [ w 1 ( 0 ) , w 2 ( 0 ) , . . . , w n ( 0 ) ] W_0 = [w_1^{(0)}, w_2^{(0)}, ..., w_n^{(0)}] W0?=[w1(0)?,w2(0)?,...,wn(0)?] 開始,然后迭代地沿著負梯度方向更新參數:
W t + 1 = W t ? η ? L ( W t ) W_{t+1} = W_t - \eta \nabla L(W_t) Wt+1?=Wt??η?L(Wt?)
這里的符號解釋:
- W t W_t Wt?:第 t t t 次迭代時的參數向量。
- ? L ( W t ) \nabla L(W_t) ?L(Wt?):在點 W t W_t Wt? 處計算的損失函數的梯度。
- η \eta η (eta):稱為學習率 (Learning Rate)。它是一個很小的正數(比如0.01, 0.001),控制著每一步沿著負梯度方向前進的“步長”。
- 如果 η \eta η 太小,收斂到最小值的速度會很慢。
- 如果 η \eta η 太大,可能會在最小值附近來回震蕩,甚至越過最小值導致發散。選擇合適的學習率非常重要。
- W t + 1 W_{t+1} Wt+1?:更新后的參數向量。
這個過程就像是一個盲人下山:他不知道山谷在哪,但他可以感知腳下哪個方向坡度最陡峭(負梯度),然后朝那個方向邁一小步(由學習率控制步長)。不斷重復這個過程,他就能一步步走到山谷。
梯度下降的步驟:
- 初始化參數 W W W (隨機值或預設值)。
- 循環迭代直到滿足停止條件(比如達到最大迭代次數,或者損失變化很小):
a. 計算梯度:在當前參數 W t W_t Wt? 下,計算損失函數 L L L 關于 W t W_t Wt? 的梯度 ? L ( W t ) \nabla L(W_t) ?L(Wt?)。
b. 更新參數: W t + 1 = W t ? η ? L ( W t ) W_{t+1} = W_t - \eta \nabla L(W_t) Wt+1?=Wt??η?L(Wt?)。
AI模型的“學習”過程:
當我們說一個AI模型在“學習”時,很多情況下指的就是它在用梯度下降(或其變種,如隨機梯度下降SGD、Adam等)來調整內部參數,以最小化在訓練數據上的損失函數。
- 模型做出預測。
- 計算預測與真實標簽之間的損失。
- 計算損失函數關于模型所有參數的梯度。
- 根據梯度和學習率更新參數。
- 重復以上步驟,直到模型性能不再顯著提升。
小結:梯度是由所有偏導數組成的向量,指向函數值增長最快的方向。負梯度則指向下降最快的方向。梯度下降算法利用負梯度來迭代更新模型參數,從而最小化損失函數,這是AI模型學習的核心機制。
鏈式法則:解開復雜依賴的鑰匙
現代AI模型,尤其是深度神經網絡,其結構非常復雜。它們通常是由許多層函數嵌套構成的。例如,一個簡單的兩層神經網絡,其輸出可能是這樣的形式:
Output = f 2 ( W 2 ? f 1 ( W 1 ? Input + b 1 ) + b 2 ) \text{Output} = f_2(W_2 \cdot f_1(W_1 \cdot \text{Input} + b_1) + b_2) Output=f2?(W2??f1?(W1??Input+b1?)+b2?)
這里 f 1 , f 2 f_1, f_2 f1?,f2? 是激活函數, W 1 , b 1 , W 2 , b 2 W_1, b_1, W_2, b_2 W1?,b1?,W2?,b2? 是模型的參數。損失函數 L L L 是基于這個Output和真實標簽計算的。
我們想知道損失 L L L 關于 W 1 W_1 W1? 或 b 1 b_1 b1? 這些深層參數的梯度,以便用梯度下降來更新它們。但是 W 1 W_1 W1? 是深深嵌套在里面的,損失 L L L 并不是直接由 W 1 W_1 W1? 決定的,而是通過一系列中間變量(比如 f 1 f_1 f1? 的輸出,以及 f 2 f_2 f2? 的輸入)間接影響的。這時,鏈式法則 (Chain Rule) 就派上用場了。
什么是鏈式法則?
鏈式法則用于計算復合函數 (Composite Function) 的導數。
如果一個變量 y y y 是變量 u u u 的函數,即 y = f ( u ) y = f(u) y=f(u),而 u u u 又是變量 x x x 的函數,即 u = g ( x ) u = g(x) u=g(x),那么 y y y 最終也是 x x x 的函數 y = f ( g ( x ) ) y = f(g(x)) y=f(g(x))。
鏈式法則告訴我們如何計算 y y y 關于 x x x 的導數 d y d x \frac{dy}{dx} dxdy?:
d y d x = d y d u ? d u d x \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} dxdy?=dudy??dxdu?
直觀理解:想象一串多米諾骨牌。
- d u d x \frac{du}{dx} dxdu?:第一塊骨牌 x x x 倒下時,推動第二塊骨牌 u u u 倒下的“效率”( x x x 的小變化導致 u u u 的變化率)。
- d y d u \frac{dy}{du} dudy?:第二塊骨牌 u u u 倒下時,推動第三塊骨牌 y y y 倒下的“效率”( u u u 的小變化導致 y y y 的變化率)。
- d y d x \frac{dy}{dx} dxdy?:第一塊骨牌 x x x 倒下時,最終導致第三塊骨牌 y y y 倒下的“總效率”。這個總效率就是各環節效率的乘積。
推廣到多變量和多層嵌套:
鏈式法則可以推廣到多個中間變量和更深的函數嵌套。對于多變量函數,它涉及到偏導數和雅可比矩陣(后面會提到)。
例如,如果 L L L 是 a a a 的函數, a a a 是 z z z 的函數, z z z 是 w w w 的函數 ( L → a → z → w L \rightarrow a \rightarrow z \rightarrow w L→a→z→w),那么:
? L ? w = ? L ? a ? ? a ? z ? ? z ? w \frac{\partial L}{\partial w} = \frac{\partial L}{\partial a} \cdot \frac{\partial a}{\partial z} \cdot \frac{\partial z}{\partial w} ?w?L?=?a?L???z?a???w?z?
AI中的核心:反向傳播算法 (Backpropagation)
在深度學習中,反向傳播 (Backpropagation) 算法就是鏈式法則在神經網絡中的系統性應用。它是計算損失函數關于網絡中所有參數(權重和偏置)梯度的標準方法。
反向傳播的核心思想:
- 前向傳播 (Forward Pass):輸入數據通過網絡,逐層計算,直到得到最終的輸出,然后計算損失 L L L。
- 反向傳播 (Backward Pass):
- 從損失 L L L 開始,首先計算 L L L 關于網絡最后一層輸出的梯度。
- 然后,利用鏈式法則,將這個梯度“反向傳播”到前一層,計算 L L L 關于前一層輸出(或激活值)的梯度。
- 同時,計算 L L L 關于當前層參數(權重和偏置)的梯度。
- 重復這個過程,一層一層向后,直到計算出 L L L 關于網絡第一層參數的梯度。
例如,對于上面那個簡單的兩層網絡,我們要計算 ? L ? W 1 \frac{\partial L}{\partial W_1} ?W1??L?:
假設中間變量是:
z 1 = W 1 ? Input + b 1 z_1 = W_1 \cdot \text{Input} + b_1 z1?=W1??Input+b1? (第一層線性輸出)
a 1 = f 1 ( z 1 ) a_1 = f_1(z_1) a1?=f1?(z1?) (第一層激活輸出)
z 2 = W 2 ? a 1 + b 2 z_2 = W_2 \cdot a_1 + b_2 z2?=W2??a1?+b2? (第二層線性輸出)
Output = a 2 = f 2 ( z 2 ) \text{Output} = a_2 = f_2(z_2) Output=a2?=f2?(z2?) (第二層激活輸出,即模型最終輸出)
L = LossFunction ( a 2 , TrueLabel ) L = \text{LossFunction}(a_2, \text{TrueLabel}) L=LossFunction(a2?,TrueLabel)
那么, ? L ? W 1 \frac{\partial L}{\partial W_1} ?W1??L? 可以通過鏈式法則分解為:
? L ? W 1 = ? L ? a 2 ? ? a 2 ? z 2 ? ? z 2 ? a 1 ? ? a 1 ? z 1 ? ? z 1 ? W 1 \frac{\partial L}{\partial W_1} = \frac{\partial L}{\partial a_2} \cdot \frac{\partial a_2}{\partial z_2} \cdot \frac{\partial z_2}{\partial a_1} \cdot \frac{\partial a_1}{\partial z_1} \cdot \frac{\partial z_1}{\partial W_1} ?W1??L?=?a2??L???z2??a2????a1??z2????z1??a1????W1??z1??
這里每一項的偏導數通常都比較容易計算:
- ? L ? a 2 \frac{\partial L}{\partial a_2} ?a2??L?: 損失函數對網絡輸出的導數。
- ? a 2 ? z 2 \frac{\partial a_2}{\partial z_2} ?z2??a2??: 第二層激活函數 f 2 f_2 f2? 對其輸入的導數。
- ? z 2 ? a 1 \frac{\partial z_2}{\partial a_1} ?a1??z2??: 等于 W 2 T W_2^T W2T? (需要矩陣求導知識,但直觀上是 a 1 a_1 a1? 對 z 2 z_2 z2? 的貢獻,由 W 2 W_2 W2? 決定)。
- ? a 1 ? z 1 \frac{\partial a_1}{\partial z_1} ?z1??a1??: 第一層激活函數 f 1 f_1 f1? 對其輸入的導數。
- ? z 1 ? W 1 \frac{\partial z_1}{\partial W_1} ?W1??z1??: 等于 Input T \text{Input}^T InputT (直觀上是 W 1 W_1 W1? 對 z 1 z_1 z1? 的貢獻,由 Input \text{Input} Input 決定)。
反向傳播算法的美妙之處在于,它提供了一種高效計算這些鏈式乘積的方法,避免了對每個參數都從頭推導整個鏈條。它從后往前,逐層計算和存儲中間梯度,使得整個計算過程非常模塊化和高效。現代深度學習框架(TensorFlow, PyTorch)都內置了自動微分(Autograd)功能,它們會自動構建計算圖并應用鏈式法則(即反向傳播)來計算所有參數的梯度。
小結:鏈式法則用于計算復合函數的導數,即一個變量通過一系列中間變量間接影響另一個變量時的變化率。在AI中,反向傳播算法是鏈式法則在神經網絡上的巧妙應用,它能夠高效地計算損失函數關于網絡中所有參數的梯度,是深度學習模型訓練的基石。
Jacobian 和 Hessian 矩陣:高階的洞察力 (進階預覽)
到目前為止,我們主要關注的是損失函數(一個標量輸出)關于參數(向量輸入)的一階導數(梯度)。但在更高級的優化算法或模型分析中,我們可能需要更高階的導數信息。這里簡單介紹兩個重要的概念:Jacobian矩陣和Hessian矩陣。對于初學者,了解它們的存在和大致用途即可。
Jacobian 矩陣 (雅可比矩陣)
當我們的函數是一個向量值函數時,即函數的輸入是向量,輸出也是向量,比如 F : R n → R m F: \mathbb{R}^n \to \mathbb{R}^m F:Rn→Rm,其中 F ( x ) = [ f 1 ( x ) , f 2 ( x ) , . . . , f m ( x ) ] F(x) = [f_1(x), f_2(x), ..., f_m(x)] F(x)=[f1?(x),f2?(x),...,fm?(x)],而 x = [ x 1 , x 2 , . . . , x n ] x = [x_1, x_2, ..., x_n] x=[x1?,x2?,...,xn?]。
Jacobian 矩陣 J F J_F JF? 是一個 m × n m \times n m×n 的矩陣,包含了 F F F 的所有一階偏導數:
J F = ( ? f 1 ? x 1 ? f 1 ? x 2 … ? f 1 ? x n ? f 2 ? x 1 ? f 2 ? x 2 … ? f 2 ? x n ? ? ? ? ? f m ? x 1 ? f m ? x 2 … ? f m ? x n ) J_F = \begin{pmatrix} \frac{\partial f_1}{\partial x_1} & \frac{\partial f_1}{\partial x_2} & \dots & \frac{\partial f_1}{\partial x_n} \\ \frac{\partial f_2}{\partial x_1} & \frac{\partial f_2}{\partial x_2} & \dots & \frac{\partial f_2}{\partial x_n} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial f_m}{\partial x_1} & \frac{\partial f_m}{\partial x_2} & \dots & \frac{\partial f_m}{\partial x_n} \end{pmatrix} JF?= ??x1??f1???x1??f2????x1??fm????x2??f1???x2??f2????x2??fm???……?…??xn??f1???xn??f2????xn??fm??? ?
其中,第 i i i 行是第 i i i 個輸出函數 f i f_i fi? 的梯度 ? f i T \nabla f_i^T ?fiT?。
特殊情況:
- 如果 m = 1 m=1 m=1 (函數輸出是標量,比如損失函數 L ( W ) L(W) L(W)),那么Jacobian矩陣就退化為一個 1 × n 1 \times n 1×n 的行向量,即梯度向量的轉置 ? L T \nabla L^T ?LT。
- 如果 n = 1 n=1 n=1 (函數輸入是標量),Jacobian矩陣就退化為一個 m × 1 m \times 1 m×1 的列向量,包含了各個輸出函數 f i f_i fi? 關于輸入 x x x 的普通導數。
AI中的應用:
- 鏈式法則的推廣:當復合函數中的某個環節是向量到向量的映射時,鏈式法則需要用到Jacobian矩陣。例如,如果 y = F ( u ) y=F(u) y=F(u) 且 u = G ( x ) u=G(x) u=G(x),那么 d y d x \frac{dy}{dx} dxdy? (這里表示的是Jacobian) 等于 J F ( G ( x ) ) ? J G ( x ) J_F(G(x)) \cdot J_G(x) JF?(G(x))?JG?(x) (矩陣乘法)。反向傳播在計算梯度時,隱式地處理了這些Jacobian向量積。
- 某些高級優化算法。
- 敏感性分析:分析輸出的各個分量對輸入的各個分量的敏感程度。
Hessian 矩陣 (海森矩陣)
Hessian矩陣描述了標量值函數 L ( W ) L(W) L(W) 的二階偏導數信息,即梯度的梯度。對于一個有 n n n 個參數 W = [ w 1 , . . . , w n ] W=[w_1, ..., w_n] W=[w1?,...,wn?] 的損失函數 L ( W ) L(W) L(W),其Hessian矩陣 H L H_L HL? 是一個 n × n n \times n n×n 的對稱矩陣:
H L = ( ? 2 L ? w 1 2 ? 2 L ? w 1 ? w 2 … ? 2 L ? w 1 ? w n ? 2 L ? w 2 ? w 1 ? 2 L ? w 2 2 … ? 2 L ? w 2 ? w n ? ? ? ? ? 2 L ? w n ? w 1 ? 2 L ? w n ? w 2 … ? 2 L ? w n 2 ) H_L = \begin{pmatrix} \frac{\partial^2 L}{\partial w_1^2} & \frac{\partial^2 L}{\partial w_1 \partial w_2} & \dots & \frac{\partial^2 L}{\partial w_1 \partial w_n} \\ \frac{\partial^2 L}{\partial w_2 \partial w_1} & \frac{\partial^2 L}{\partial w_2^2} & \dots & \frac{\partial^2 L}{\partial w_2 \partial w_n} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^2 L}{\partial w_n \partial w_1} & \frac{\partial^2 L}{\partial w_n \partial w_2} & \dots & \frac{\partial^2 L}{\partial w_n^2} \end{pmatrix} HL?= ??w12??2L??w2??w1??2L???wn??w1??2L???w1??w2??2L??w22??2L???wn??w2??2L??……?…??w1??wn??2L??w2??wn??2L???wn2??2L?? ?
其中 ( H L ) i j = ? 2 L ? w i ? w j (H_L)_{ij} = \frac{\partial^2 L}{\partial w_i \partial w_j} (HL?)ij?=?wi??wj??2L?。如果函數 L L L 的二階偏導數連續,則 H L H_L HL? 是對稱的,即 ? 2 L ? w i ? w j = ? 2 L ? w j ? w i \frac{\partial^2 L}{\partial w_i \partial w_j} = \frac{\partial^2 L}{\partial w_j \partial w_i} ?wi??wj??2L?=?wj??wi??2L?。
Hessian矩陣的意義:
Hessian矩陣描述了損失函數在某一點附近的曲率 (curvature)。
- 如果在一個臨界點(梯度為零的點),Hessian矩陣是正定的(所有特征值都為正),那么該點是一個局部最小值。
- 如果Hessian矩陣是負定的(所有特征值都為負),該點是一個局部最大值。
- 如果Hessian矩陣的特征值有正有負,該點是一個鞍點 (Saddle Point)。在深度學習中,高維損失函數的鞍點遠比局部最小值更常見,這是優化的一大挑戰。
AI中的應用:
- 二階優化算法:像牛頓法 (Newton’s Method) 及其變種就利用Hessian矩陣來進行參數更新,它們通常能比一階方法(如梯度下降)更快地收斂,尤其是在接近最優點時。更新規則類似于 W t + 1 = W t ? η [ H L ( W t ) ] ? 1 ? L ( W t ) W_{t+1} = W_t - \eta [H_L(W_t)]^{-1} \nabla L(W_t) Wt+1?=Wt??η[HL?(Wt?)]?1?L(Wt?)。然而,計算和存儲Hessian矩陣(及其逆)對于參數量巨大的現代神經網絡來說代價高昂( O ( n 2 ) O(n^2) O(n2) 存儲, O ( n 3 ) O(n^3) O(n3) 求逆),所以實際應用中更多采用近似Hessian的方法(如L-BFGS)。
- 分析損失函數的幾何形狀:幫助理解優化過程中的難點,如鞍點、平坦區域等。
- 確定學習率:Hessian的特征值可以用來指導學習率的選擇。
小結:Jacobian矩陣是一階偏導數對向量值函數的推廣,是鏈式法則在多維情況下表達的關鍵。Hessian矩陣是標量值函數的二階偏導數矩陣,描述了函數的局部曲率,可用于二階優化算法和分析臨界點性質。它們為AI提供了更深層次的優化和分析工具。
總結:微積分,驅動AI學習的引擎
我們今天一起探索了微積分的核心概念——導數、偏導數、梯度、鏈式法則,以及簡要了解了Jacobian和Hessian矩陣。希望你現在能理解,微積分并非只是抽象的數學公式,而是AI模型能夠“學習”和“優化”自身的關鍵所在:
- 導數和偏導數讓模型感知到單個參數微調對整體性能(損失)的影響。
- 梯度整合了所有參數的影響,為模型指明了“變得更好”(損失減小)的最快方向。
- 梯度下降算法則是模型沿著梯度方向小步快跑,不斷迭代調整參數,以達到最佳性能的過程。
- **鏈式法則(反向傳播)**是高效計算復雜模型(如深度神經網絡)中所有參數梯度的“總調度師”,使得大規模模型的訓練成為可能。
- Jacobian和Hessian則為更精細的分析和更高級的優化算法提供了數學工具。
如果說線性代數為AI提供了表示和操作數據的“骨架”,那么微積分就為AI注入了學習和進化的“引擎”和“導航系統”。正是因為有了微積分,AI模型才能從數據中總結規律,自動調整參數,最終實現各種令人驚嘆的功能。
理解這些數學原理,不僅能幫助你更深入地理解AI的工作方式,也能讓你在未來學習更高級的AI技術時更有底氣。數學是AI的基石,也是創新的源泉。讓我們繼續這座奇妙的數學之旅吧!
習題
來幾道練習題,檢驗一下今天的學習成果!
1. 理解導數
假設一個AI模型的損失函數關于某個權重參數 w w w 的關系是 L ( w ) = ( w ? 3 ) 2 + 5 L(w) = (w-3)^2 + 5 L(w)=(w?3)2+5。
(a) 當 w = 1 w=1 w=1 時,損失 L ( w ) L(w) L(w) 關于 w w w 的導數 d L d w \frac{dL}{dw} dwdL? 是多少?
(b) 根據這個導數值,為了減小損失,我們應該增加 w w w 還是減小 w w w?
2. 計算偏導數
一個簡單的損失函數依賴于兩個參數 w 1 w_1 w1? 和 w 2 w_2 w2?: L ( w 1 , w 2 ) = 2 w 1 2 ? 3 w 1 w 2 + w 2 3 L(w_1, w_2) = 2w_1^2 - 3w_1w_2 + w_2^3 L(w1?,w2?)=2w12??3w1?w2?+w23?。
請計算:
(a) ? L ? w 1 \frac{\partial L}{\partial w_1} ?w1??L? (損失函數關于 w 1 w_1 w1? 的偏導數)
(b) ? L ? w 2 \frac{\partial L}{\partial w_2} ?w2??L? (損失函數關于 w 2 w_2 w2? 的偏導數)
3. 梯度與梯度下降
對于上一題的損失函數 L ( w 1 , w 2 ) = 2 w 1 2 ? 3 w 1 w 2 + w 2 3 L(w_1, w_2) = 2w_1^2 - 3w_1w_2 + w_2^3 L(w1?,w2?)=2w12??3w1?w2?+w23?。
(a) 寫出其梯度向量 ? L ( w 1 , w 2 ) \nabla L(w_1, w_2) ?L(w1?,w2?)。
(b) 假設當前參數為 ( w 1 , w 2 ) = ( 1 , 1 ) (w_1, w_2) = (1, 1) (w1?,w2?)=(1,1),學習率為 η = 0.1 \eta = 0.1 η=0.1。應用一步梯度下降,新的參數 ( w 1 ′ , w 2 ′ ) (w_1', w_2') (w1′?,w2′?) 是多少?
4. 理解鏈式法則
假設一個簡單的模型: y = u 2 y = u^2 y=u2,其中 u = 2 x + 1 u = 2x + 1 u=2x+1。損失函數 L = ( y ? 10 ) 2 L = (y-10)^2 L=(y?10)2。我們想求損失 L L L 關于參數 x x x 的導數 d L d x \frac{dL}{dx} dxdL?。
請用鏈式法則逐步寫出計算過程(即 d L d x = d L d y ? d y d u ? d u d x \frac{dL}{dx} = \frac{dL}{dy} \cdot \frac{dy}{du} \cdot \frac{du}{dx} dxdL?=dydL??dudy??dxdu? 的每一項)。
5. Jacobian 與 Hessian (概念)
(a) 如果一個神經網絡的某個層將一個10維的輸入向量映射到一個5維的輸出向量,描述這個層變換的Jacobian矩陣的維度是多少?
(b) Hessian矩陣的對角線元素 ? 2 L ? w i 2 \frac{\partial^2 L}{\partial w_i^2} ?wi2??2L? 在直觀上告訴我們關于損失函數在 w i w_i wi? 方向上的什么信息?(提示:考慮單變量函數的二階導數)
答案
1. 理解導數
L ( w ) = ( w ? 3 ) 2 + 5 = w 2 ? 6 w + 9 + 5 = w 2 ? 6 w + 14 L(w) = (w-3)^2 + 5 = w^2 - 6w + 9 + 5 = w^2 - 6w + 14 L(w)=(w?3)2+5=w2?6w+9+5=w2?6w+14
(a) d L d w = 2 w ? 6 \frac{dL}{dw} = 2w - 6 dwdL?=2w?6。
當 w = 1 w=1 w=1 時, d L d w = 2 ( 1 ) ? 6 = 2 ? 6 = ? 4 \frac{dL}{dw} = 2(1) - 6 = 2 - 6 = -4 dwdL?=2(1)?6=2?6=?4。
(b) 導數值為-4(負數),這意味著如果增加 w w w,損失會減小。所以,為了減小損失,我們應該增加 w w w。
2. 計算偏導數
L ( w 1 , w 2 ) = 2 w 1 2 ? 3 w 1 w 2 + w 2 3 L(w_1, w_2) = 2w_1^2 - 3w_1w_2 + w_2^3 L(w1?,w2?)=2w12??3w1?w2?+w23?
(a) ? L ? w 1 = ? ? w 1 ( 2 w 1 2 ) ? ? ? w 1 ( 3 w 1 w 2 ) + ? ? w 1 ( w 2 3 ) = 4 w 1 ? 3 w 2 + 0 = 4 w 1 ? 3 w 2 \frac{\partial L}{\partial w_1} = \frac{\partial}{\partial w_1}(2w_1^2) - \frac{\partial}{\partial w_1}(3w_1w_2) + \frac{\partial}{\partial w_1}(w_2^3) = 4w_1 - 3w_2 + 0 = 4w_1 - 3w_2 ?w1??L?=?w1???(2w12?)??w1???(3w1?w2?)+?w1???(w23?)=4w1??3w2?+0=4w1??3w2?
(b) ? L ? w 2 = ? ? w 2 ( 2 w 1 2 ) ? ? ? w 2 ( 3 w 1 w 2 ) + ? ? w 2 ( w 2 3 ) = 0 ? 3 w 1 + 3 w 2 2 = ? 3 w 1 + 3 w 2 2 \frac{\partial L}{\partial w_2} = \frac{\partial}{\partial w_2}(2w_1^2) - \frac{\partial}{\partial w_2}(3w_1w_2) + \frac{\partial}{\partial w_2}(w_2^3) = 0 - 3w_1 + 3w_2^2 = -3w_1 + 3w_2^2 ?w2??L?=?w2???(2w12?)??w2???(3w1?w2?)+?w2???(w23?)=0?3w1?+3w22?=?3w1?+3w22?
3. 梯度與梯度下降
(a) 梯度向量 ? L ( w 1 , w 2 ) = [ ? L ? w 1 , ? L ? w 2 ] = [ 4 w 1 ? 3 w 2 , ? 3 w 1 + 3 w 2 2 ] \nabla L(w_1, w_2) = \left[ \frac{\partial L}{\partial w_1}, \frac{\partial L}{\partial w_2} \right] = [4w_1 - 3w_2, -3w_1 + 3w_2^2] ?L(w1?,w2?)=[?w1??L?,?w2??L?]=[4w1??3w2?,?3w1?+3w22?]
(b) 當前參數 ( w 1 , w 2 ) = ( 1 , 1 ) (w_1, w_2) = (1, 1) (w1?,w2?)=(1,1)。
梯度 ? L ( 1 , 1 ) = [ 4 ( 1 ) ? 3 ( 1 ) , ? 3 ( 1 ) + 3 ( 1 ) 2 ] = [ 4 ? 3 , ? 3 + 3 ] = [ 1 , 0 ] \nabla L(1, 1) = [4(1) - 3(1), -3(1) + 3(1)^2] = [4 - 3, -3 + 3] = [1, 0] ?L(1,1)=[4(1)?3(1),?3(1)+3(1)2]=[4?3,?3+3]=[1,0]。
學習率 η = 0.1 \eta = 0.1 η=0.1。
新的參數 ( w 1 ′ , w 2 ′ ) (w_1', w_2') (w1′?,w2′?):
w 1 ′ = w 1 ? η ? ? L ? w 1 ( 1 , 1 ) = 1 ? 0.1 ? 1 = 1 ? 0.1 = 0.9 w_1' = w_1 - \eta \cdot \frac{\partial L}{\partial w_1}(1,1) = 1 - 0.1 \cdot 1 = 1 - 0.1 = 0.9 w1′?=w1??η??w1??L?(1,1)=1?0.1?1=1?0.1=0.9
w 2 ′ = w 2 ? η ? ? L ? w 2 ( 1 , 1 ) = 1 ? 0.1 ? 0 = 1 ? 0 = 1 w_2' = w_2 - \eta \cdot \frac{\partial L}{\partial w_2}(1,1) = 1 - 0.1 \cdot 0 = 1 - 0 = 1 w2′?=w2??η??w2??L?(1,1)=1?0.1?0=1?0=1
所以,新的參數為 ( w 1 ′ , w 2 ′ ) = ( 0.9 , 1 ) (w_1', w_2') = (0.9, 1) (w1′?,w2′?)=(0.9,1)。
4. 理解鏈式法則
L = ( y ? 10 ) 2 L = (y-10)^2 L=(y?10)2, y = u 2 y = u^2 y=u2, u = 2 x + 1 u = 2x + 1 u=2x+1.
d L d x = d L d y ? d y d u ? d u d x \frac{dL}{dx} = \frac{dL}{dy} \cdot \frac{dy}{du} \cdot \frac{du}{dx} dxdL?=dydL??dudy??dxdu?
- d L d y = 2 ( y ? 10 ) ? d d y ( y ? 10 ) = 2 ( y ? 10 ) ? 1 = 2 ( y ? 10 ) \frac{dL}{dy} = 2(y-10) \cdot \frac{d}{dy}(y-10) = 2(y-10) \cdot 1 = 2(y-10) dydL?=2(y?10)?dyd?(y?10)=2(y?10)?1=2(y?10)
- d y d u = d d u ( u 2 ) = 2 u \frac{dy}{du} = \frac{d}{du}(u^2) = 2u dudy?=dud?(u2)=2u
- d u d x = d d x ( 2 x + 1 ) = 2 \frac{du}{dx} = \frac{d}{dx}(2x+1) = 2 dxdu?=dxd?(2x+1)=2
所以, d L d x = 2 ( y ? 10 ) ? 2 u ? 2 = 8 u ( y ? 10 ) \frac{dL}{dx} = 2(y-10) \cdot 2u \cdot 2 = 8u(y-10) dxdL?=2(y?10)?2u?2=8u(y?10)。
如果需要完全用 x x x 表示,可以將 u = 2 x + 1 u=2x+1 u=2x+1 和 y = u 2 = ( 2 x + 1 ) 2 y=u^2=(2x+1)^2 y=u2=(2x+1)2 代入:
d L d x = 8 ( 2 x + 1 ) ( ( 2 x + 1 ) 2 ? 10 ) \frac{dL}{dx} = 8(2x+1)((2x+1)^2 - 10) dxdL?=8(2x+1)((2x+1)2?10)
5. Jacobian 與 Hessian (概念)
(a) Jacobian矩陣的維度是 (輸出維度) × \times × (輸入維度)。所以,這個Jacobian矩陣的維度是 5 × 10 5 \times 10 5×10。
(b) Hessian矩陣的對角線元素 ? 2 L ? w i 2 \frac{\partial^2 L}{\partial w_i^2} ?wi2??2L? 是損失函數 L L L 關于參數 w i w_i wi? 的二階偏導數(保持其他參數不變)。類似于單變量函數的二階導數,它描述了損失函數在 w i w_i wi? 方向上的曲率或“彎曲程度”。
* 如果 ? 2 L ? w i 2 > 0 \frac{\partial^2 L}{\partial w_i^2} > 0 ?wi2??2L?>0,表示在 w i w_i wi? 方向上,損失函數的圖像是向上凹的(像碗一樣)。
* 如果 ? 2 L ? w i 2 < 0 \frac{\partial^2 L}{\partial w_i^2} < 0 ?wi2??2L?<0,表示在 w i w_i wi? 方向上,損失函數的圖像是向下凹的(像帽子一樣)。
* 如果 ? 2 L ? w i 2 = 0 \frac{\partial^2 L}{\partial w_i^2} = 0 ?wi2??2L?=0,表示在 w i w_i wi? 方向上,曲率可能是平坦的(需要更高階導數判斷)。
這對于判斷一個臨界點是局部最小值、最大值還是鞍點的一部分信息很有用。

![[架構之美]從PDMan一鍵生成數據庫設計文檔:Word導出全流程詳解(二十)](http://pic.xiahunao.cn/[架構之美]從PDMan一鍵生成數據庫設計文檔:Word導出全流程詳解(二十))

)

)



)



)
——最小生成樹)




