前言
本將介紹最小生成樹以及普里姆算法(Prim)和克魯斯卡爾(Kruskal)
本人其他博客:https://blog.csdn.net/2401_86940607
圖的基本概念和存儲結構:【數據結構與算法】——圖(一)
源代碼見gitte: https://gitee.com/mozhengy
最小生成樹
- 前言
- 正文
- 1. 生成樹與最小生成樹
- 1.1 生成樹的概念
- 1.2 構造準則
- 1.3 生成樹與非連通圖
- 2. Prim算法
- 2.1 算法思想
- 2.2 算法步驟
- 2.3 示例圖解
- 2.4 代碼實現
- 2.5 時間復雜度
- 3. Kruskal算法
- 3.1 算法思想
- 3.2 算法步驟
- 3.3 示例圖解
- 3.4 代碼實現
- 3.4.1 基礎版
- 3.4.2 堆排序和并查集優化版(選擇)
- 3.5 時間復雜度
- 4. 算法對比
- 結語
正文
1. 生成樹與最小生成樹
1.1 生成樹的概念
- 定義:連通圖的生成樹是包含圖中所有頂點的極小連通子圖,具有以下特性:
- 包含全部 n n n 個頂點和 ( n ? 1 ) (n-1) (n?1) 條邊
- 添加任意一條邊會形成回路
- 邊數少于 ( n ? 1 ) (n-1) (n?1) 則為非連通圖
- 最小生成樹 (MST):帶權連通圖中邊權之和最小的生成樹。
1.2 構造準則
- 僅使用圖中的邊
- 恰好使用 ( n ? 1 ) (n-1) (n?1) 條邊
- 不允許產生回路
1.3 生成樹與非連通圖
在對無向圖進行遍歷時,
- 若是連通圖,僅需調用遍歷過程(DFS或BFS)一次,從圖中的任一頂點出發便可以遍歷圖中的各個頂點;
- 若是非連通圖,則需調用遍歷過程多次,每次調用得到的頂點集和相關的邊一起構成了圖的一個連通分量。
由深度優先遍歷得到的生成樹稱為深度優先生成樹(DFStree)。在深度優先遍歷中如果將每次“前進”(縱向)路過的(將被訪問)頂點和邊都記錄下來,就得到了一個子圖,該子圖為以出發點為根的樹,就是深度優先生成樹。相應地,由廣度優先遍歷得到的生成樹稱為廣度優先生成樹(BFS tree)。
這樣的生成樹由遍歷時訪問過的n個頂點和遍歷時經歷的(n一1)條邊組成。
對于非連通圖,每個連通分量中的頂點集和遍歷時走過的邊一起構成一顆生成樹,各個連通分量的生成樹組成非連通圖的生成森林
2. Prim算法
2.1 算法思想
從單一頂點逐步擴展生成樹,每次選擇連接當前生成樹與剩余頂點的最小權邊。
2.2 算法步驟
- 初始化頂點集合 U = { v } U = \{v\} U={v},候選邊為 v v v 到其他頂點的邊
- 重復 ( n ? 1 ) (n-1) (n?1) 次:
- 從候選邊中選擇權值最小的邊 ( k , j ) (k,j) (k,j),將 k k k 加入 U U U
- 更新候選邊:檢查 V ? U V-U V?U 中頂點到 U U U 的新最小邊
簡單的說
Prim算法是加邊
從起始點開始,每次從候選邊中挑選權值最小的邊加入生成樹
2.3 示例圖解
從頂點0出發的Prim算法過程:
帶權連通圖如下
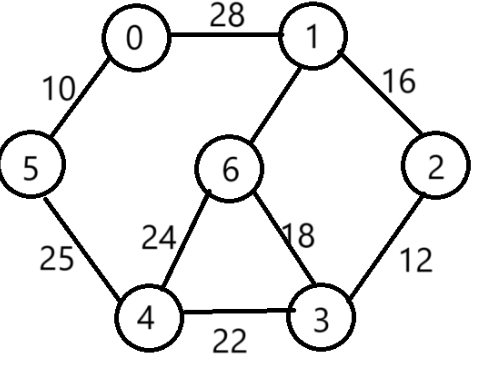
-
僅留下所有頂點
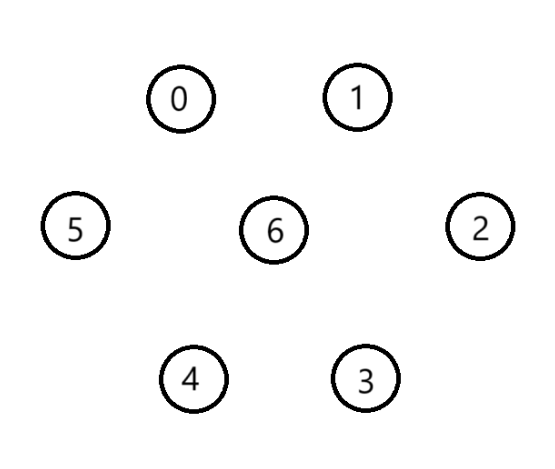
-
選擇與0相連權值最小的(0,5)
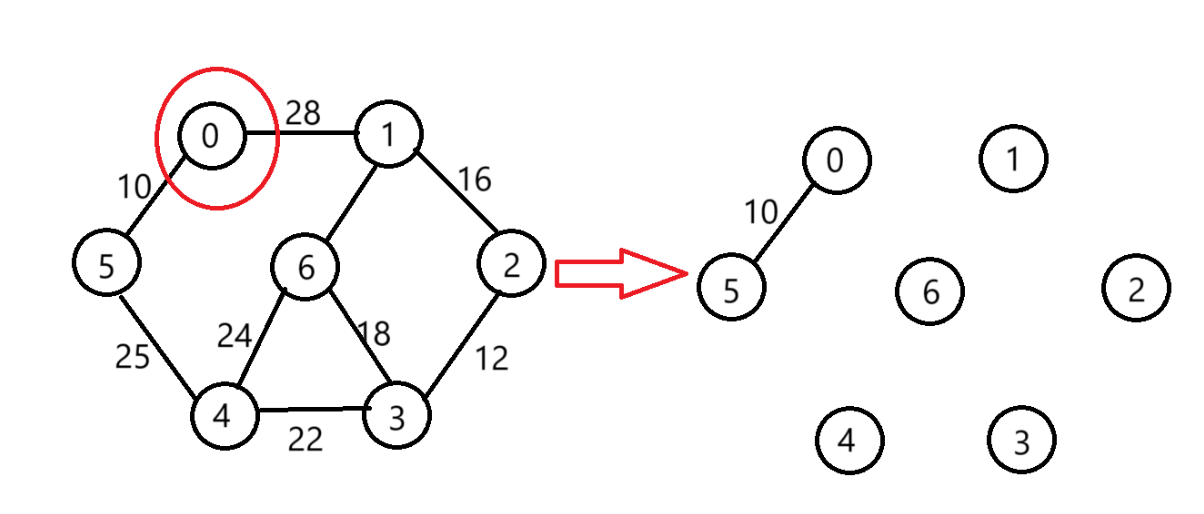
-
現在與0和5直接相連的邊中(5,4)權值更小選擇
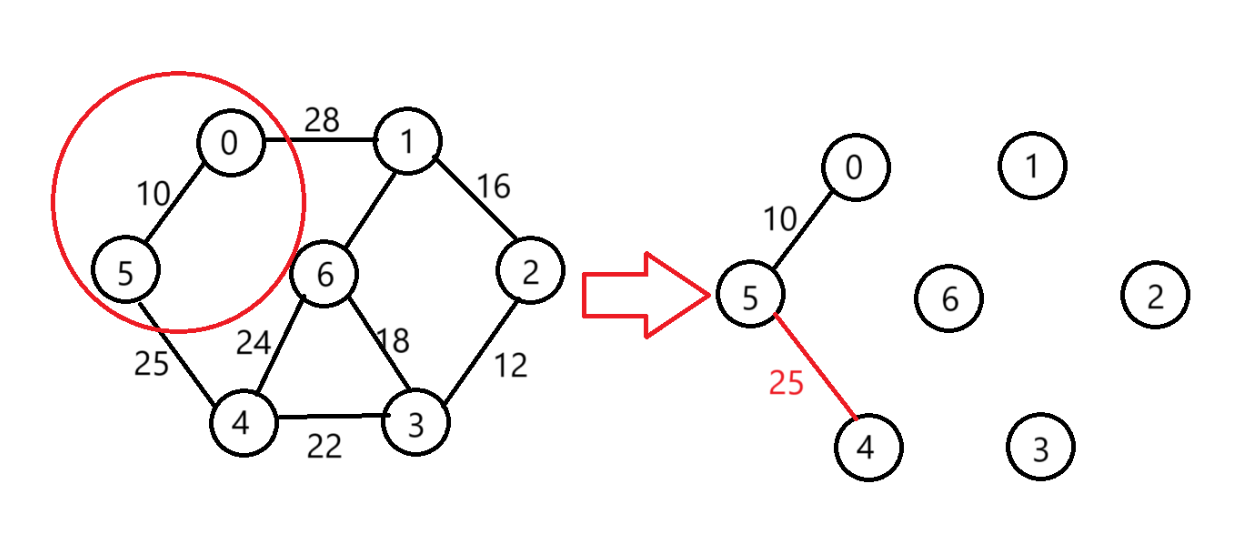
-
選擇權值更小的(4,3)
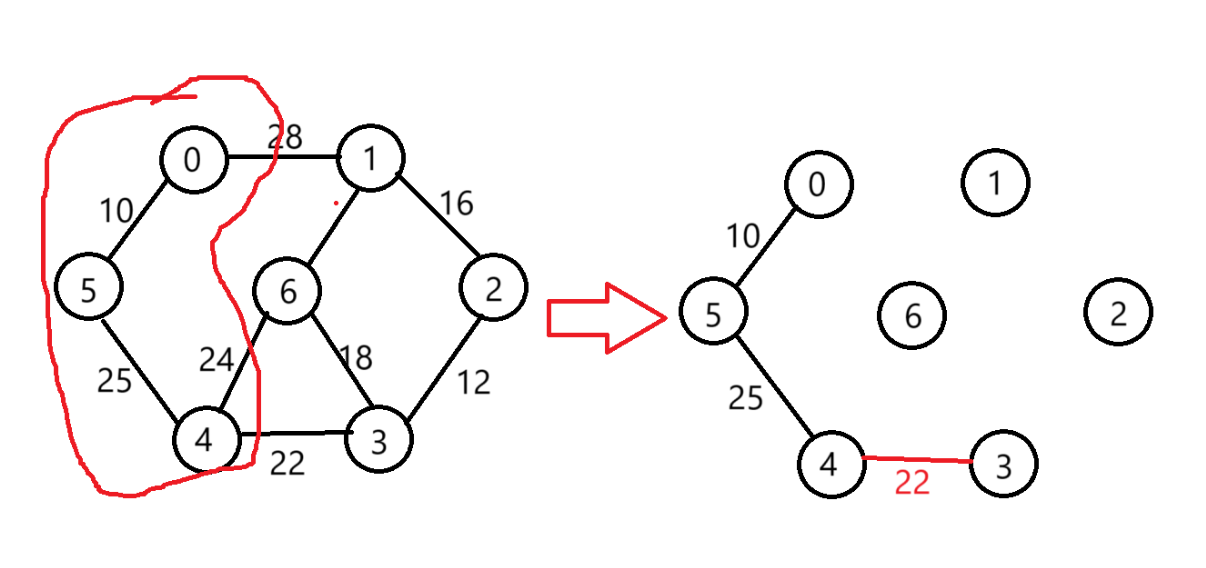
-
選擇(3,2)
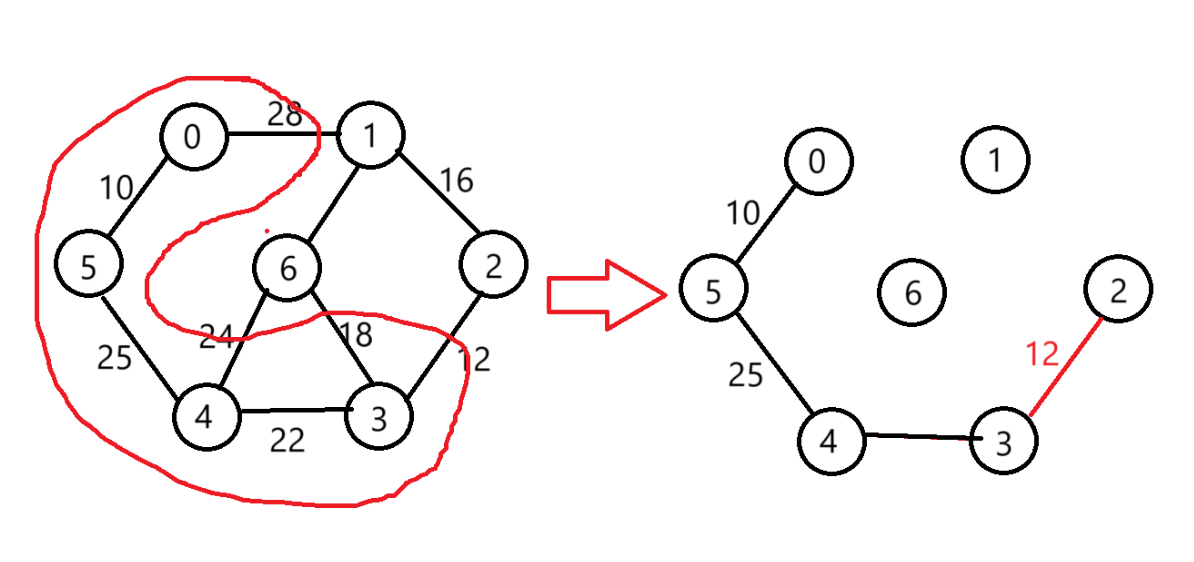
-
選擇(2,1)
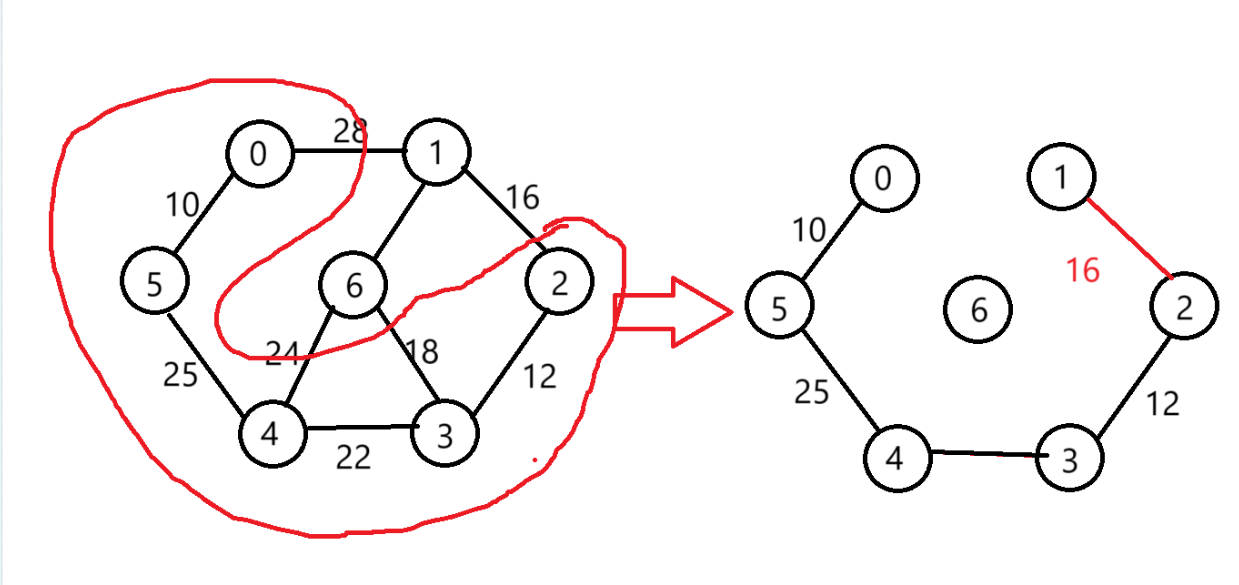
-
選擇(1,6)
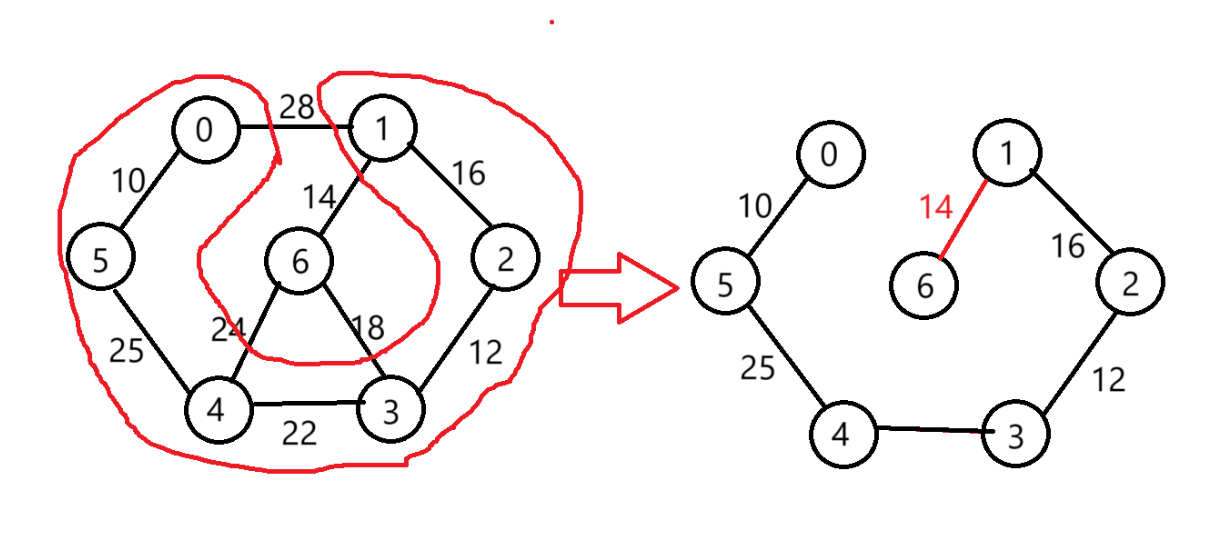
2.4 代碼實現
圖的基本實現見圖的基本概念和存儲結構:【數據結構與算法】——圖(一)
#define MAXV 100
#define INF 0x3f3f3f3fvoid Prim(MatGraph g, int v) {int lowcost[MAXV], closest[MAXV];for (int i=0; i<g.n; i++) {lowcost[i] = g.edges[v][i];closest[i] = v;}lowcost[v] = 0;for (int i=1; i<g.n; i++) {int min = INF, k = -1;for (int j=0; j<g.n; j++) {if (lowcost[j] != 0 && lowcost[j] < min) {min = lowcost[j];k = j;}}printf("邊(%d,%d) 權:%d\n", closest[k], k, min);lowcost[k] = 0;for (int j=0; j<g.n; j++) {if (g.edges[k][j] < lowcost[j]) {lowcost[j] = g.edges[k][j];closest[j] = k;}}}
}
2.5 時間復雜度
- 復雜度: O ( n 2 ) O(n^2) O(n2),適合稠密圖
3. Kruskal算法
3.1 算法思想
按邊權遞增順序選擇邊,確保不形成回路。
3.2 算法步驟
- 初始化所有頂點為獨立連通分量
- 按邊權排序
- 依次選擇最小邊:
- 若邊的兩個頂點屬于不同連通分量,則加入生成樹
- 合并兩個連通分量
3.3 示例圖解
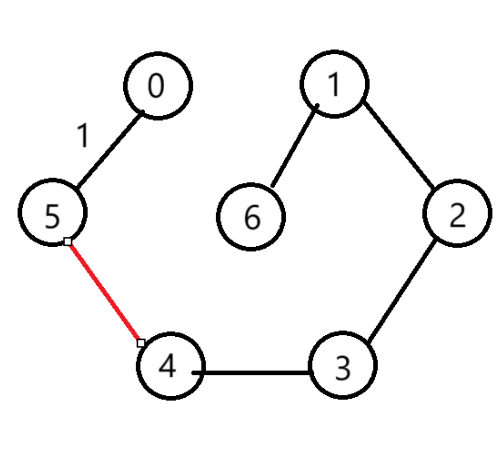
Kruskal過程:以此圖為例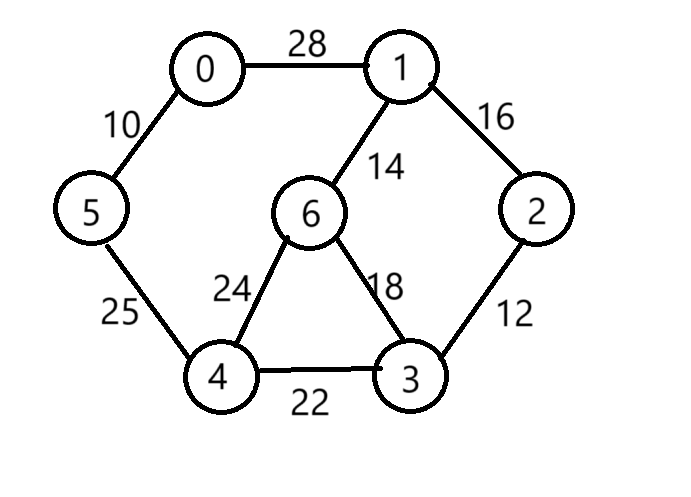
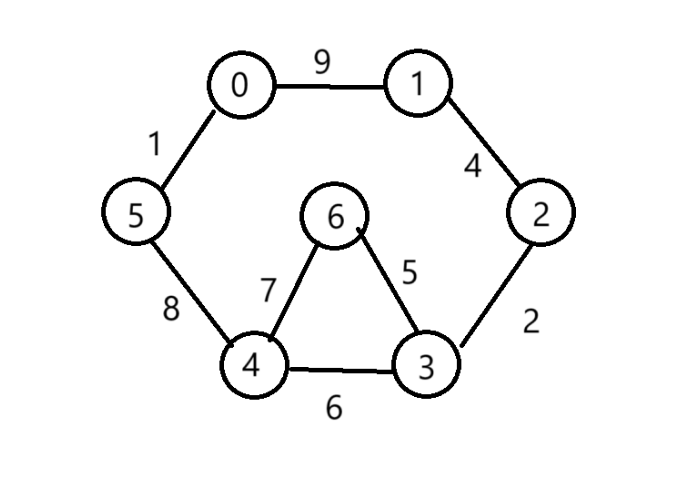
(1)按照權值遞增排序結果
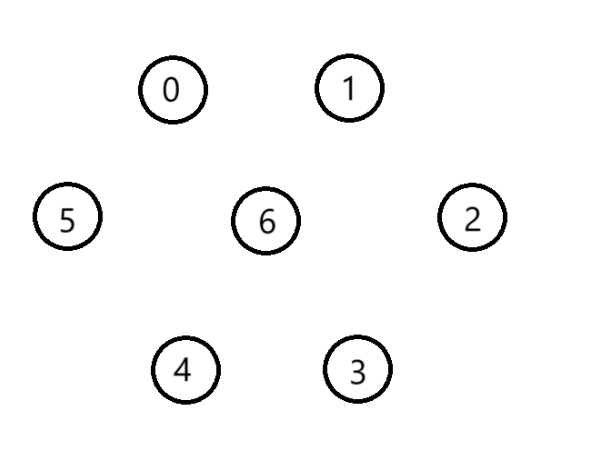
(2)僅包含所有頂點
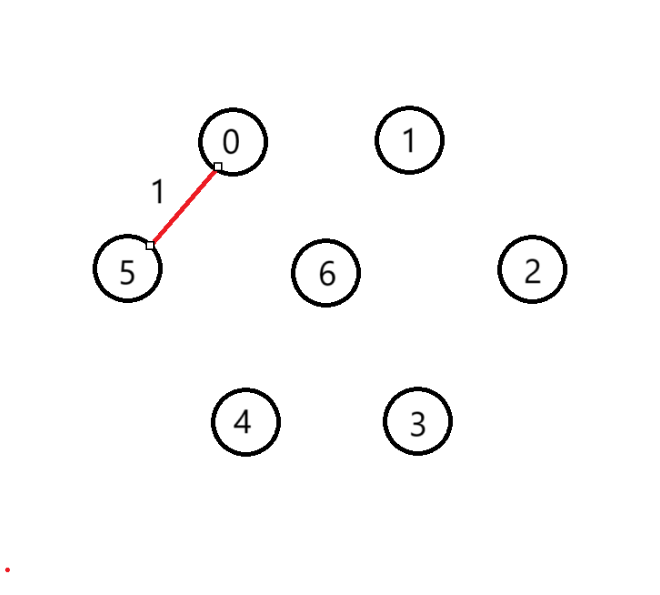
(3)選擇第1條邊
(4)選擇第2條邊
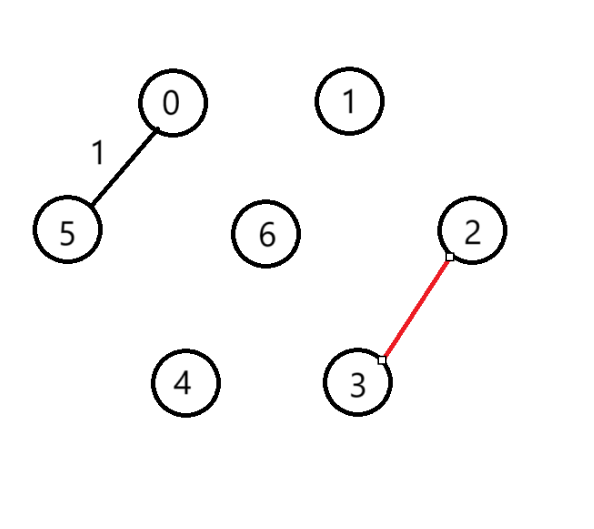
(5)選擇第3條邊
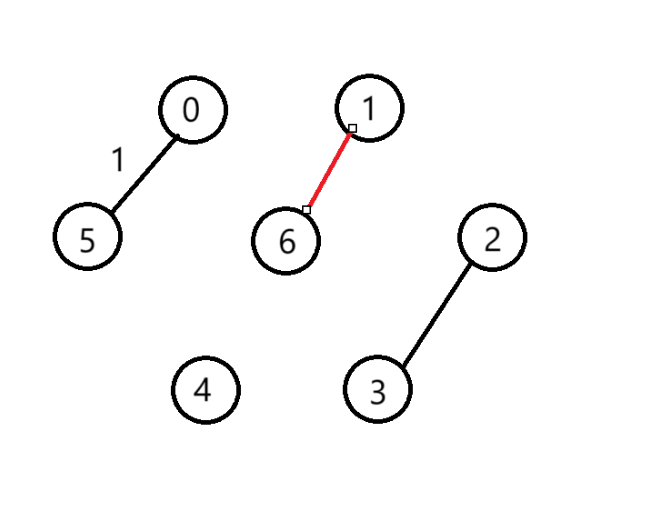
(6)選擇第4條邊
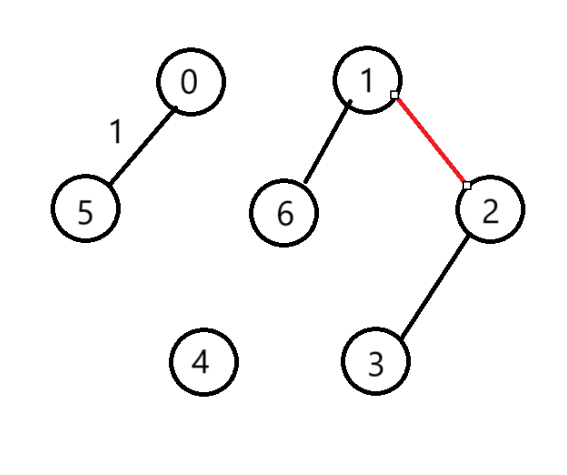
(7)選擇第5條邊
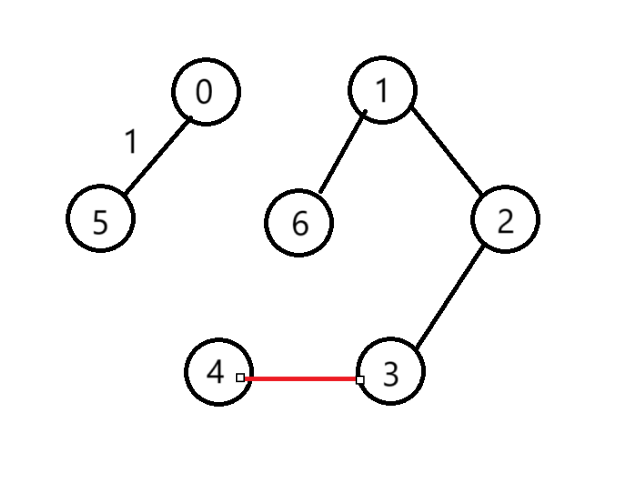
(8)選擇第6條邊
3.4 代碼實現
3.4.1 基礎版
/*--- 原始Kruskal算法(直接插入排序) ---*/
typedef struct {int u; // 邊的起始頂點int v; // 邊的終止頂點int w; // 邊的權值
} Edge;void Kruskal(MatGraph g) {int i, j, u1, v1, sn1, sn2, k;int vset[MAXV];Edge E[MaxSize];k = 0;// 生成邊集數組 Efor (i = 0; i < g.n; i++) {for (j = 0; j <= i; j++) { // 僅處理下三角避免重復if (g.edges[i][j] != 0 && g.edges[i][j] != INF) {E[k].u = i;E[k].v = j;E[k].w = g.edges[i][j];k++;}}}InsertSort(E, k); // 對 E 按權值直接插入排序// 初始化頂點集合for (i = 0; i < g.n; i++) vset[i] = i;j = 0; // E 數組下標k = 1; // 已選邊數while (k < g.n) { // 需選 n-1 條邊u1 = E[j].u;v1 = E[j].v;sn1 = vset[u1];sn2 = vset[v1];if (sn1 != sn2) {printf("(%d,%d):%d\n", u1, v1, E[j].w);k++;// 合并兩個集合for (i = 0; i < g.n; i++) {if (vset[i] == sn2) vset[i] = sn1; // 修正賦值操作符}}j++;}
}3.4.2 堆排序和并查集優化版(選擇)
#include "UFSTree.h" // 假設并查集實現已包含void ImprovedKruskal(MatGraph g) {Edge E[MaxSize];UFSTree S[MaxSize];int i, j, k = 0;// 生成邊集數組 Efor (i = 0; i < g.n; i++) {for (j = 0; j < i; j++) { // 僅處理下三角if (g.edges[i][j] != 0 && g.edges[i][j] != INF) {E[k].u = i;E[k].v = j;E[k].w = g.edges[i][j];k++;}}}HeapSort(E, k); // 堆排序優化Init(S, g.n); // 并查集初始化int edgeCount = 0; // 已選邊數j = 0; // E 數組下標while (edgeCount < g.n - 1) {int u1 = E[j].u;int v1 = E[j].v;int sn1 = Find(S, u1);int sn2 = Find(S, v1);if (sn1 != sn2) {printf("(%d,%d):%d\n", u1, v1, E[j].w);Union(S, u1, v1); // 并查集合并edgeCount++;}j++;}
}
3.5 時間復雜度
- 基礎實現: O ( e 2 ) O(e^2) O(e2)
- 優化版(堆排序+并查集): O ( e log ? e ) O(e \log e) O(eloge),適合稀疏圖
4. 算法對比
| 特性 | Prim算法 | Kruskal算法 |
|---|---|---|
| 適用圖類型 | 稠密圖 | 稀疏圖 |
| 時間復雜度 | O ( n 2 ) O(n^2) O(n2) | O ( e log ? e ) O(e \log e) O(eloge) |
| 存儲結構 | 鄰接矩陣 | 邊集數組 |
| 思想核心 | 頂點擴展 | 邊篩選+并查集 |
結語
這部分是圖的重要內容,工科學習中有重要作業,由于未學習離散數學,如有錯誤還望多多指正,寫作耗時還望三連支持



















