具身智能被廣泛認為是通用人工智能(AGI)的關鍵要素,因為它涉及控制具身智能體在物理世界中執行任務。在大語言模型和視覺語言模型成功的基礎上,一種新的多模態模型——視覺語言動作模型(VLA)已經出現,通過利用它們獨特的生成動作的能力來解決具身智能中的語言條件機器人任務。
近年來,業內開發了各類VLA,文章提出了第一個關于具身人工智能的VLA的調查。這項工作提供了VLA的詳細分類,分為三條主要的研究路線。第一條線關注VLA的各個組件、第二條線致力于開發擅長預測低級動作的控制策略、第三條線包括能夠將長期任務分解成子任務序列的高級任務規劃器,從而引導VLA遵循更通用的用戶指令。此外,文章還提供了相關資源的廣泛摘要,包括數據集、模擬器和基準。最后,我們-討論了VLA面臨的挑戰,并概述了具身智能的未來方向。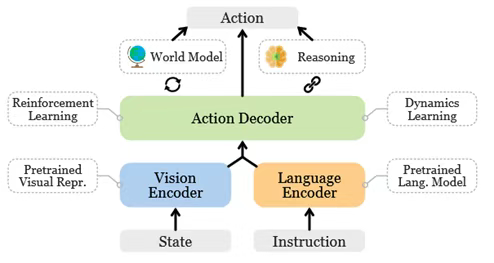
圖1:視覺-語言-動作模型的一般架構。重要的相關組件顯示在虛線框中。視覺-語言-動作模型(VLA)代表一類旨在處理多模態輸入的模型,結合視覺、語言和動作模態的信息。該術語最先由RT-2 提出。VLA模型被開發用于解決具身智能中的指令跟隨任務。與以ChatGPT為代表的聊天AI不同,具身智能需要控制物理實體并與環境交互。機器人是具身智能最突出的領域。在語言為條件的機器人任務中,策略必須具備1)理解語言指令、2)視覺感知環境、3)生成適當動作的能力,這就需要VLA的多模態能力。相比于早期的深度強化學習方法,基于VLA的策略在復雜環境中表現出更優越的多樣性、靈活性和泛化性。這使得VLA不僅適用于像工廠這樣的受控環境,還適用于日常生活任務。視覺-語言-動作模型 (VLA)是處理視覺和語言的多模態輸入并輸出機器人動作以完成具身任務的模型。它們是具身智能領域在機器人策略指令跟隨的基石。這些模型依賴于強大的視覺編碼器、語言編碼器和動作解碼器。在大型VLM的成功基礎上,VLA模型已經展示了其在應對復雜任務挑戰方面的潛力,如圖1所示。與VLM類似,VLA利用視覺基礎模型作為視覺編碼器來獲得當前環境狀態的預訓練視覺表示,例如對象類別、姿態和幾何形狀。VLA使用其大語言模型的令牌嵌入(token embeddings)對指令進行編碼,并采用各種策略來調整視覺和語言嵌入,包括BLIP-2和LLaVA等方法。通過對機器人數據進行微調,大語言模型可以充當解碼器來預測動作和執行語言條件機器人任務。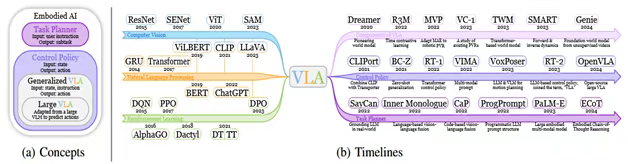
圖2:(a)概述本文討論的具身智能主要概念的維恩圖。(b)追蹤從單模態模型到視覺-語言-動作模型演變的時間線。VLA與三條工作線密切相關,如圖2b中的時間線和圖3中的分類法所示。一些方法側重于VLAs(III-A)的單個組件,如預訓練的視覺表示、動力學學習(dynamics learning)、世界模型和推理。與此同時,大量的研究致力于低級控制策略(III-B)。在這一類別中,語言指令和視覺感知被輸入到控制策略中,然后控制策略生成低級動作,如平移和旋轉,從而使VLAs成為控制策略的理想選擇。相比之下,另一類模型充當高級任務規劃器,負責任務分解(§IV)。這些模型將長期任務分解為一系列子任務,這些子任務反過來引導VLAs實現總體目標,如圖4所示。當前大多數機器人系統都采用這樣的分層框架,因為高級任務規劃器可以利用具有高容量的模型,而低級控制策略可以專注于速度和精度,類似于分層強化學習。為了更全面地概述具身智能的當前進展,提出了“VLA”的廣義定義,如圖2a所示。將VLA定義為任何能夠處理來自視覺和語言的多模態輸入以產生完成具體化任務的機器人動作的模型,通常遵循圖1中的架構。VLA的最初概念是指一種使VLM適應機器人任務的模型[2]。類似于大語言模型和更通用的語言模型之間的區別,我們將原始VLAs指定為“大型VLAs”(LVLAs),因為它們基于大語言模型或大型VLM。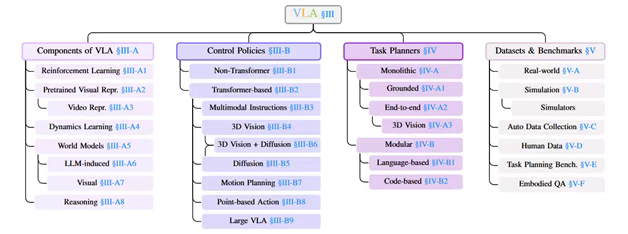
圖3:VLA模型的分類。VLA的組成部分視覺語言具身智能(Vision-Language-Action, VLA)模型的發展依賴于多個關鍵組件的協同優化。這些組件從感知、決策到世界建模和推理,共同推動了具身智能的進步。以下是各核心組件的詳細介紹:強化學習(Reinforcement Learning, RL)強化學習在VLA模型中扮演關鍵角色,其狀態-動作-獎勵序列與序列建模問題高度契合,使得Transformer能夠有效處理RL任務。Decision Transformer(DT)和Trajectory Transformer(TT)率先將RL問題轉化為序列預測任務,利用Transformer的自回歸特性優化策略學習。Gato進一步擴展了這一范式,支持多模態輸入和跨任務泛化。此外,基于人類反饋的強化學習(RLHF)已成為大語言模型(LLM)訓練的重要組成部分,例如SEED通過結合技能RL和人類反饋解決長周期任務的稀疏獎勵問題。Reflexion則創新性地用語言反饋替代傳統RL的權重更新機制,使模型能夠通過自然語言交互優化策略。預訓練視覺表征(Pretrained Visual Representations, PVRs)視覺編碼器的質量直接影響VLA模型的性能,因為它決定了機器人對環境的理解能力。CLIP通過大規模圖像-文本對比學習訓練,成為機器人領域廣泛采用的視覺編碼器。R3M提出時間對比學習和視頻-語言對齊兩個目標,分別增強時序一致性和語義相關性。MVP借鑒計算機視覺中的掩碼自編碼(MAE)方法,在機器人數據集上進行視覺重建預訓練。Voltron在MAE基礎上引入語言條件生成,提升視覺與語言模態的對齊能力。DINOv2采用自蒸餾框架,結合多裁剪增強策略,在像素和圖像級別同時學習表征。I-JEPA通過聯合嵌入預測架構,專注于局部圖像特征的建模。Theia則通過蒸餾多個視覺基礎模型(如分割、深度估計)構建輕量且高性能的單一模型。視頻表征(Video Representations)視頻數據不僅包含單幀圖像信息,還蘊含豐富的時序和3D結構信息。傳統方法通過逐幀提取PVRs拼接成視頻表征,但新興技術如NeRF和3D高斯潑濺(3D-GS)能夠直接從視頻中重建3D場景,為機器人提供更豐富的環境理解。例如,F3RM和3D-LLM利用NeRF提取3D幾何信息,而PhysGaussian和UniGS則基于3D高斯潑濺實現動態場景建模。此外,視頻中的音頻信息(如環境聲音)也可作為機器人策略的重要輸入,增強多模態感知能力。動力學學習(Dynamics Learning)動力學學習旨在讓模型掌握環境的狀態轉移規律,包括前向動力學(預測下一狀態)和逆向動力學(預測動作)。Vi-PRoM通過對比學習和偽標簽分類預訓練視頻模型,提升時序動態建模能力。MIDAS專注于逆向動力學預測,將觀測序列轉化為動作序列。SMART結合前向、逆向動力學和隨機掩碼 hindsight 控制,同時建模局部和全局時序依賴。MaskDP采用掩碼決策預測任務,聯合學習狀態和動作的重建。PACT通過自回歸預測狀態-動作序列,構建通用動力學模型,適用于導航等下游任務。VPT利用半監督模仿學習,基于少量標注數據預訓練Minecraft基礎模型,最終實現人類水平性能。世界模型(World Models)世界模型能夠編碼常識知識并預測未來狀態,支持基于模型的規劃和想象訓練。Dreamer系列工作通過潛在動力學模型(包含狀態編碼、轉移和獎勵預測模塊)實現高效想象優化。IRIS采用類似GPT的自回歸Transformer作為世界模型基礎,結合VQ-VAE視覺編碼器生成想象軌跡。TWM探索了純Transformer架構在世界建模中的應用。這些模型使機器人能夠在執行真實動作前,通過內部模擬搜索最優策略。LLM誘導的世界模型(LLM-induced World Models)大語言模型(LLM)蘊含豐富的常識知識,可被轉化為符號化世界模型。DECKARD利用LLM生成抽象世界模型(AWM),指導Minecraft中的物品合成任務。LLM-DM將LLM轉化為規劃域定義語言(PDDL)的生成器,構建符號化仿真器輔助規劃。RAP將LLM同時作為策略和世界模型,結合蒙特卡洛樹搜索(MCTS)實現結構化推理。LLM-MCTS進一步擴展至部分可觀測環境(POMDPs),利用LLM的常識知識縮小搜索空間。視覺世界模型(Visual World Models)與文本世界模型不同,視覺世界模型能夠生成未來狀態的圖像、視頻或3D場景。Genie提出生成式交互環境框架,通過無監督視頻訓練實現幀級交互模擬。3D-VLA利用擴散模型生成目標圖像或點云,指導機器人完成任務。UniSim基于真實交互視頻構建生成模型,模擬高低層級動作的視覺結果。這些模型能夠生成逼真的環境交互數據,為機器人提供豐富的訓練經驗。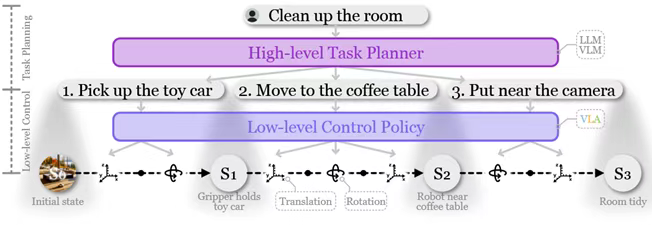
圖4:分層機器人策略的圖示。高級任務規劃器將用戶指令分解為子任務,然后由低級控制策略逐步執行。低層控制策略(Low-level Control Policies)非Transformer控制策略在Transformer架構普及之前,研究者們已經探索了多種基于傳統神經網絡架構的低層控制策略。CLIPort是這一時期的代表性工作,它創造性地將CLIP的視覺語言編碼能力與Transporter網絡的空間推理能力相結合,形成了一個雙流處理架構。其中語義流通過CLIP提取圖像的高級語義特征,空間流則利用Transporter網絡處理RGB-D數據以精確定位物體空間位置。這種分離處理的方式使得系統能夠同時理解"要操作什么"和"在哪里操作",最終輸出精確的抓取和放置位姿。BC-Z則采用了不同的技術路線,通過FiLM(Feature-wise Linear Modulation)層實現語言指令與視覺特征的深度融合,這種條件調節機制使模型能夠將抽象的語言指令轉化為具體的動作策略,展現出強大的零樣本泛化能力。MCIL突破了傳統任務ID或目標圖像的條件限制,開創性地支持自由形式的自然語言指令輸入,其關鍵創新在于設計了一個共享的編碼空間,使得語言目標和視覺目標可以相互轉換,從而能夠充分利用大量未標注的演示數據。HULC系列工作則提出了更為復雜的層次化架構,將高層規劃與底層控制解耦,其中頂層的Transformer負責長時程任務分解,底層網絡處理即時動作生成,同時引入視覺語言對比學習損失來增強多模態對齊。這些早期探索為后續Transformer-based控制策略的發展奠定了重要基礎。Transformer-based控制策略隨著Transformer在序列建模中的優勢得到驗證,控制策略設計逐漸向Transformer架構收斂。Interactive Language系統展示了語言實時引導的強大能力,其核心在于構建了規模空前多樣的語言指令數據集,使Transformer策略能夠精準理解并執行復雜的長時程重排列任務。Hiveformer則進一步強調了多視角觀測和歷史信息的重要性,相比傳統單幀輸入的方法,其設計的時空注意力機制能夠更好地捕捉場景動態變化。Gato作為里程碑式的工作,首次實現了單一模型在Atari游戲、圖像描述和積木堆疊等多個領域的通用控制,其突破點在于設計了統一的分詞方案,將不同模態和任務的輸入輸出都轉化為標準化的token序列。RoboCat在Gato基礎上引入了自我改進機制,通過迭代式微調和自動數據生成,僅需100條演示就能快速適應新任務,其創新的未來觀測預測目標顯著提升了樣本效率。RT-1對BC-Z架構進行了全面升級,采用更高效的EfficientNet視覺編碼器,并將MLP動作解碼器替換為Transformer解碼器,通過注意力機制整合歷史觀測,在真實機器人任務中展現出卓越性能。Q-Transformer則開創性地將Q-learning引入Transformer策略,通過自回歸Q函數和保守正則化,能夠同時利用成功和失敗的演示數據。RT-Trajectory提出了軌跡草圖條件控制的新范式,將傳統語言指令擴展為直觀的空間軌跡指導,大幅提升了新物體和新任務的泛化能力。ACT及其改進版本MT-ACT采用條件VAE框架,通過動作分塊預測和時間集成技術增強動作序列的連貫性。RoboFlamingo則證明已有視覺語言大模型(如Flamingo)只需添加簡單的LSTM策略頭就能有效遷移到機器人控制任務。多模態指令控制策略多模態指令控制策略突破了純文本指令的限制,開創了更豐富的人機交互方式。VIMA系統是這一方向的先驅,它設計了包括物體操作、視覺目標達成、新概念理解、單次視頻模仿等在內的多模態提示體系,通過專門的VIMA-Bench評測平臺系統評估了模型在位置泛化、組合泛化、新物體泛化和新任務泛化四個層級的表現。其核心創新在于構建了統一的提示編碼器,能夠同時處理語言、圖像、視頻等多種形式的任務描述。MOO在RT-1基礎上擴展了多模態指令處理能力,通過集成OWLViT圖像編碼器,系統能夠理解基于指向動作、GUI點擊等非語言形式的指令輸入。這類方法的關鍵挑戰在于建立跨模態的共享表征空間,使得不同形式的指令都能映射到統一的控制策略空間。最新研究還探索了如何將觸覺反饋、語音指令等更多模態融入控制系統,進一步豐富人機交互的維度。3D視覺控制策略3D視覺控制策略致力于利用三維場景表征提升控制精度和魯棒性。PerAct是該領域的突破性工作,它采用3D體素作為統一表征,通過多視角RGB-D重建構建場景的立體幾何結構,將動作預測轉化為目標體素選擇問題,這種顯式的結構先驗使模型僅需少量演示就能學會復雜操作。Act3D則提出連續分辨率3D特征場,通過自適應分辨率平衡計算效率和表征精度。RoboUniView通過UVFormer模塊將多視角圖像轉化為3D占據信息,顯著提升了抓取成功率。VER在視覺語言導航任務中驗證了由粗到細的體素化策略的有效性。RVT系列工作另辟蹊徑,采用虛擬重渲染技術從場景點云生成新穎視角圖像,避免了直接處理3D數據的復雜性。這些方法共同面臨的挑戰是如何在計算開銷和表征豐富度之間取得平衡,以及如何處理動態場景的實時更新問題。最新趨勢是將神經輻射場(NeRF)和3D高斯潑濺等先進三維重建技術融入控制框架,以獲取更精確的場景幾何和語義信息。擴散控制策略擴散控制策略將圖像生成領域的擴散模型成功遷移到動作預測領域。Diffusion Policy是開創性工作,它將機器人策略建模為去噪擴散過程,采用DDPM框架并結合滾動時域控制、視覺條件化和時序擴散Transformer等技術,有效解決了多模態動作分布、高維動作空間的挑戰。SUDD構建了LLM引導的數據生成和蒸餾框架,通過組合基礎機器人原語(如抓取采樣器和運動規劃器)生成高質量訓練數據,再蒸餾到擴散策略中。Octo設計了模塊化的Transformer擴散架構,支持靈活接入不同任務編碼器和觀測編碼器,在Open X-Embodiment大規模數據集上驗證了跨機器人的知識遷移能力。MDT將視覺領域的DiT模型引入動作預測,配合掩碼生成預測和對比潛在對齊兩個輔助目標,性能超越傳統U-Net架構。RDT-1B專注于雙手操作任務,通過統一動作格式實現跨機器人數據集預訓練,其10億參數規模的模型展現出強大的零樣本泛化能力。這些方法的核心優勢在于能夠自然地表征多峰動作分布,但實時推理速度仍是實際部署的主要瓶頸。運動規劃控制策略運動規劃控制策略專注于將高層任務分解為滿足約束的可行軌跡。Language Costs提出基于語言代價函數的規劃框架,通過將自然語言指令轉化為代價圖來指導運動規劃,支持用戶通過語言交互實時修正目標。VoxPoser創新性地將LLM的編程能力與VLM的感知能力結合,無需訓練即可生成滿足語言指令的可行軌跡,其核心是構建3D體素化的操作可行域和約束域表示。RoboTAP通過TAPIR算法從演示視頻中提取關鍵點軌跡,構建分階段的視覺伺服控制策略。這類方法的關鍵挑戰在于如何將抽象的語言約束準確轉化為數學形式的運動約束,以及如何處理復雜環境下的實時規劃問題。最新進展探索如何將基于采樣的傳統規劃算法與學習型策略相結合,在保證安全性的同時提升規劃效率。基于點的控制策略基于點的控制策略探索輕量化的動作表征方式。PIVOT將機器人任務重構為視覺問答問題,通過VLM在圖像關鍵點上進行迭代選擇,大幅降低了動作預測的復雜度。RoboPoint通過微調VLM實現空間可行域預測,將2D圖像點映射為3D動作。ReKep提出基于3D關鍵點的約束優化框架,將復雜任務分解為一系列關鍵點約束的求解問題。這些方法的優勢在于能夠直接復用現有視覺語言模型,實現零樣本或少樣本的控制策略生成,但通常需要額外的運動規劃模塊來實現精確控制。當前研究重點是如何提升點預測的精度和穩定性,以及如何將離散點選擇與連續動作優化更好地結合。大規模視覺語言動作模型大規模視覺語言動作模型(LVLA)代表了當前最前沿的研究方向。RT-2通過聯合微調互聯網規模VQA數據和機器人數據,使模型涌現出符號推理和語義理解等高級能力。RT-H引入語言動作中間層,構建"指令-語言動作-底層動作"的三層架構,既改善了任務間的知識共享,又支持語言級錯誤修正。RT-X系列通過Open X-Embodiment大規模數據集訓練,驗證了跨機器人知識遷移的可行性。OpenVLA作為開源替代方案,探索了LoRA和量化等高效微調技術。π-0采用流匹配架構將預訓練VLM擴展為VLA,通過混合專家框架平衡通用知識和專業技能。這些大型模型雖然展現出驚人的泛化能力,但也面臨計算成本高、推理延遲大等實際挑戰,催生了TinyVLA等輕量化解決方案的研究。未來發展方向包括更高效的架構設計、更靈活的任務適應機制,以及更可靠的安全保障體系。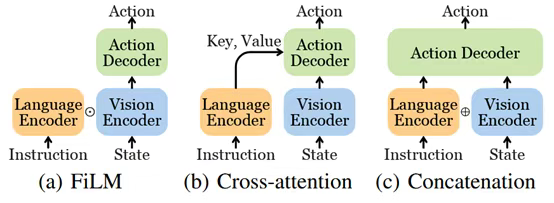
圖5:基于Transformer的控制策略的三種常見視覺語言融合方法。FiLM層(Hadamard product⊙)用于RT-1模型中。有人利用交叉注意力來調節指令。級聯(⊕)是LVLAs中的主要方法。任務規劃器(Task Planners)整體式任務規劃器(Monolithic Task Planners):單個大語言模型或多模態大語言模型(MLLM)通常可以通過采用定制的框架或通過對包含的數據集進行微調來生成任務計劃。我們將這些稱為整體模型。基于落地的任務規劃器(Grounded Task Planners)基于落地的任務規劃器專注于將抽象任務分解為可執行子任務,同時考慮低層控制策略的實際可行性。SayCan提出了開創性的任務落地框架,通過結合LLM的語義規劃能力("說"出可能技能)和低層策略的可行性評估("能"執行程度),實現了高層指令到具體動作的可靠轉換。Translated ?LM?采用獨特的雙階段規劃機制,先由生成式LLM產生自然語言動作描述,再通過掩碼語言模型將其映射為具體可執行動作,并創新性地引入"重新提示"策略來處理執行過程中的前提條件錯誤。(SL)3算法通過分段、標記和參數更新的迭代學習過程,從稀疏語言標注中自動發現可重用技能模塊,構建了層次化的策略表示。這類方法的核心價值在于建立了語義規劃與物理執行之間的可靠橋梁,其技術挑戰主要來自動態環境下可行性評估的準確性,以及多步任務分解的長期一致性維護。端到端任務規劃器(End-to-end Task Planners)端到端任務規劃器利用大規模多模態語言模型的涌現能力,直接實現從指令到計劃的端到端生成。PaLM-E通過深度融合ViT視覺編碼器和PaLM語言模型,構建了統一的多模態推理架構,既能處理常規的視覺問答任務,又能生成可指導機器人執行的詳細計劃,并具備根據環境觀測實時調整的動態重規劃能力。EmbodiedGPT創新設計了具身變形器模塊,通過聯合優化視覺特征提取和規劃信息生成,輸出包含空間上下文的任務實例特征,為低層策略提供豐富的執行上下文。這類方法的顯著優勢是避免了傳統流水線式系統的信息損失,但其成功高度依賴互聯網規模的多模態預訓練數據,且存在計算成本高、決策過程可解釋性弱等實際問題。當前研究前沿集中在模型輕量化、物理約束注入和可解釋性增強等方向。支持3D視覺的端到端規劃器(End-to-end Task Planners with 3D Vision)支持3D視覺的端到端規劃器通過擴展傳統視覺語言模型架構,顯著提升了空間理解和三維交互能力。LEO采用創新的兩階段訓練范式,先通過3D視覺語言對齊學習建立幾何理解基礎,再經指令微調階段獲得精確的動作規劃能力,在復雜操作和導航任務中展現出卓越表現。3D-LLM構建了靈活的多模態3D特征接口,支持點云、神經輻射場等多種三維表征的融合處理,使語言模型首次具備真正的三維空間推理能力。MultiPLY突破性地將感知模態擴展到觸覺、音頻等物理交互信號,建立了以物體為中心的具身認知框架。ShapeLLM則通過創新的ReCon++編碼器架構,實現了從多視角視覺教師到點云表征的知識蒸餾,在其提出的3D MM-Vet基準測試中刷新了性能記錄。這些技術的突破性在于將離散的語言指令與連續的三維動作空間建立了直接關聯,但面臨3D數據獲取成本高、實時計算負載大等工程挑戰,未來發展重點包括高效3D表征學習、跨模態對齊優化和增量式場景理解等技術方向。模塊化任務規劃器(Modular Task Planners):在嵌入數據上微調端到端模型可能是昂貴的,并且有一些方法通過將現成的大語言模型和VLM組裝到任務規劃器中來采用模塊化設計。基于語言的任務規劃器(Language-based Task Planners)基于語言的模塊化任務規劃器通過自然語言描述實現多模態信息交換,構建了靈活可擴展的規劃系統。Inner Monologue創新性地在高層指令和低層策略間建立閉環規劃機制,利用LLM生成可執行語言指令并根據策略反饋動態調整,其反饋系統整合了任務成功狀態、物體場景變化和人工輸入等多源信息,全部以文本形式實現無需額外訓練。ReAct采用類似的交替執行推理與動作的框架,通過語言空間實現多模態對齊。LLM-Planner進一步提出分層規劃架構,高層LLM生成自然語言計劃后由低層規劃器轉化為原始動作,并引入動態重規劃機制解決執行卡頓問題。LID通過主動數據收集(ADG)和事后重標記技術最大化利用失敗軌跡數據,其語言模型策略展現出強大的組合泛化能力。Socratic Models突破性地構建了無需微調的模塊化系統,通過多模態提示技術實現預訓練模型間的即插即用協作,將非語言輸入統一轉化為語言描述進行規劃,在機器人感知和規劃任務中表現出獨特優勢。這些方法的共同特點是通過自然語言這一通用接口降低模塊間耦合度,但需要精心設計提示工程來確保生成計劃與低層策略的兼容性。基于代碼的任務規劃器(Code-based Task Planners)基于代碼的任務規劃器充分利用大模型的程序生成能力,將任務規劃轉化為可執行代碼的編寫過程。ProgPrompt開創性地采用類程序規范提示LLM生成家務任務計劃,通過程序斷言機制整合環境反饋,實現少量示例引導的規劃。ChatGPT for Robotics構建了"用戶在環"的控制范式,通過定義物體檢測、抓取等API接口,引導模型生成可調試的控制代碼,結合仿真環境和用戶反饋迭代優化。Code as Policies(CaP)深入挖掘GPT-3和Codex的代碼生成潛力,創建可直接調用感知模塊和控制原語的策略代碼,在空間幾何推理和新指令泛化方面表現突出,其升級版COME-robot通過GPT-4V的多模態能力消除了獨立感知API的需求。DEPS提出"描述-解釋-規劃-選擇"四步框架,不僅生成計劃還能對失敗進行自我解釋式重規劃,并創新性地引入可訓練的子目標選擇器優化執行路徑。ConceptGraphs將觀測序列轉化為開放詞匯的3D場景圖,通過2D分割模型和VLM標注構建富含語義空間關系的JSON描述,為代碼生成提供結構化環境表征。這類方法的核心價值在于將規劃過程程序化,既保留了傳統代碼的精確可控優勢,又獲得了LLM的語義理解能力,但性能受限于模型編程能力且需要預先封裝完備的API文檔體系。技術特性與權衡模塊化任務規劃器通過組合現成LLM和VLM構建,相比整體式規劃器具有更低部署成本。基于語言的方案天然適配大模型的文本處理優勢,Inner Monologue和ReAct等通過精巧的反饋機制實現閉環規劃,但需要額外轉換層對接低層策略。基于代碼的方案如ProgPrompt和CaP雖然需要預先封裝API,但能直接生成可調試的執行代碼,DEPS的自我解釋機制進一步提升了系統可靠性。ConceptGraphs創新的3D場景圖表示彌補了純文本描述的空間信息缺失。當前挑戰集中在如何平衡模塊化帶來的靈活性損失,以及如何構建更高效的跨模態接口。最新趨勢是結合語言和代碼的雙重優勢,如COME-robot通過多模態大模型消除獨立感知模塊,或探索視覺程序生成等混合表征方式。未來突破可能來自動態模塊組合機制和神經符號結合的新型架構。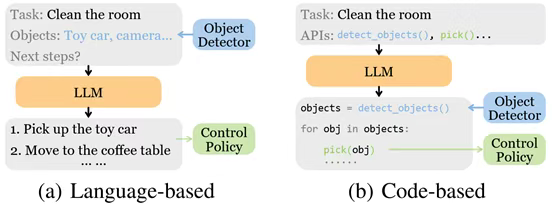
圖6:在模塊化任務規劃器中將大語言模型連接到多模態模塊的不同方法。數據集與基準測試(Datasets and Benchmarks)真實機器人數據集與基準測試真實世界機器人數據收集面臨三重核心挑戰:硬件成本與時間投入構成第一道門檻,從機器人設備采購到專家演示數據采集需要大量資源投入;跨平臺異構性帶來第二重障礙,不同機器人的傳感器配置、控制模式和末端執行器差異導致數據難以統一;6D位姿標注與實驗可復現性則是第三大技術瓶頸。當前主流數據集如Bridge V2和RT-1-X通過多機器人協作緩解數據規模問題,而Open X-Embodiment通過標準化數據格式促進跨平臺知識遷移。值得注意的是,真實場景評估必須依賴人工評判,這導致評測成本居高不下,MetaWorld等基準通過定義細粒度任務分解指標部分緩解該問題,但動態環境中的長期任務評估仍具挑戰性。
仿真環境與模擬數據集仿真技術通過虛擬環境突破物理限制,Gazebo和Isaac Sim等平臺支持大規模并行數據采集,但仿真與現實間的領域差距形成顯著障礙。該差距源自三重因素:圖形渲染保真度不足導致視覺域差異,物理引擎精度限制影響動力學建模,以及物體參數化建模誤差引入系統偏差。為解決這些問題,NVIDIA Omniverse等平臺采用實時光線追蹤提升視覺真實度,PyBullet則通過GPU加速提高物理仿真精度。TDW和ThreeDWorld創新性地引入非剛性物體模擬能力,而SAPIEN專注于可操作物體的精確物理特性建模。仿真基準測試如BEHAVIOR和VirtualHome的優勢在于提供自動化評估指標,支持精確的實驗復現和公平比較,但如何建立有效的仿真到現實遷移評估體系仍是開放問題。自動化數據收集技術自動化數據采集系統通過算法生成替代人工干預,RoboGen采用生成式仿真范式自動設計訓練課程,其三步循環包含技能提案、環境生成和策略優化,顯著提升數據多樣性。AutoRT構建LLM驅動的機器人編排框架,通過任務生成、可行性過濾和混合執行(自主策略與人工遙操作結合)實現閉環數據生產。DIAL專注于語言指令增強,利用VLM對現有數據集進行語義擴展,而RoboPoint通過程序化生成隨機3D場景解決特定任務數據匱乏問題。這些技術的共同突破是建立了數據生產的自主進化機制,但生成數據的質量監控和偏差控制仍需深入研究。人類行為數據集人類演示數據因其靈巧性和多樣性成為重要補充,但存在三大應用瓶頸:運動捕捉系統難以精確轉換人體 kinematics 到機器人形態,Kinect等設備采集的第三方視角數據與機器人第一視角存在表征差異,且原始數據包含大量無關動作需要清洗。UMI通過手持式夾爪設備采集人體操作數據,在保持演示自然性的同時解決形態差異問題。大規模數據集如Something-Something和Epic-Kitchens提供豐富的日常活動記錄,但需要復雜的預處理才能轉化為可用訓練數據。當前研究前沿集中在運動重定向算法開發和跨形態技能遷移技術上。任務規劃基準測試任務規劃評估體系呈現多維度發展趨勢,EgoPlan-Bench通過人工標注實現真實場景細粒度評估,但擴展性受限。PlanBench創新性地建立多維評估框架,從成本最優性、計劃驗證到動態重規劃能力進行全面測評。LoTa-Bench將規劃執行環節納入評估,通過模擬器運行生成計劃計算成功率,而EAI提出模塊化接口標準,支持對LLM決策過程的細粒度診斷。這些基準共同推動規劃系統從靜態評估向閉環驗證演進,但如何平衡評估復雜度和可擴展性仍是挑戰。具身問答基準測試具身問答(EQA)基準測試開創性地將主動探索引入評估體系,EmbodiedQA和IQUAD奠定基礎框架,要求智能體在回答前通過導航探索環境。MT-EQA擴展至多目標復合問題,MP3D-EQA將視覺輸入升級為點云數據以測試3D推理能力。EgoVQA和EgoTaskQA聚焦第一人稱視角,分別強化時空推理和因果關系理解。EQA-MX突破性地引入非語言模態(如視線注視和指向手勢),OpenEQA則構建七維評估體系涵蓋從功能推理到世界知識的全面測評。這類基準的核心價值在于評估物理常識和空間推理等基礎能力,但當前仍受限于模擬器環境,真實場景的主動探索評估體系尚待建立。總結當前,視覺語言動作(VLA)模型在具身智能領域取得了顯著進展,但仍面臨諸多關鍵挑戰。安全性始終是機器人系統的核心考量,需要結合常識推理、風險評估和人機交互協議構建可靠的安全保障體系。數據集與基準測試的擴展性、多樣性以及細粒度評估能力仍需提升,以支持更全面的模型診斷與優化。基礎模型的泛化能力仍落后于NLP領域的LLMs,如何構建適應多樣化任務、環境和具身形態的通用機器人基礎模型(RFM)是未來重要方向。多模態融合技術雖已取得突破,但如何高效對齊視覺、語言、觸覺、音頻等模態,并實現動態環境下的自適應推理仍待探索。長時程任務的端到端規劃框架、實時響應能力的優化、多智能體協作系統的通信與調度機制,以及倫理與社會影響的規范化研究,都是推動VLA技術落地的關鍵課題。未來,隨著醫療護理、工業自動化等新應用場景的拓展,VLA模型需結合領域知識(如醫學圖像分析)和隱私保護技術(如聯邦學習),構建更安全、可靠、高效的智能系統。跨學科協作與技術創新將共同推動具身智能從實驗室走向現實世界,最終實現與人類社會的無縫融合。論文:Ma, Y.; Song, Z.; Zhuang, Y.; Hao, J.; King, I. A Survey on Vision-Language-Action Models for Embodied AI. arXiv March 4, 2025. https://doi.org/10.48550/arXiv.2405.14093.原文鏈接:https://arxiv.org/pdf/2405.14093v3
:Mybatis)






 2-5 GB/T 25070—2019《信息安全技術 網絡安全等級保護安全設計技術要求》-2019-05-10發布【現行】)







)


——4.9多協議標簽交換MPLS)
