全面拆解 Transformer 架構:Encoder、Decoder 內部模塊解析(附流程圖小測驗)
關鍵詞:Transformer、Encoder、Decoder、Self-Attention、Masked Attention、位置編碼、殘差連接、多頭注意力機制
Transformer 自 2017 年誕生以來,已經成為深度學習中最具影響力的模型架構之一。無論是 GPT、BERT,還是今天的大模型 GPT-4、Claude、Gemini,它們的底層都離不開 Transformer 的基本框架。
今天我們就來全面拆解 Transformer 的 Encoder 與 Decoder 內部模塊結構,并附上一個動手小測驗:畫出 Transformer 的完整流程圖,幫助大家真正掌握這個強大的架構。
一、Transformer 總覽
Transformer 的核心是:自注意力機制(Self-Attention)+ 前饋神經網絡(Feed Forward Network),通過堆疊多層 Encoder 和 Decoder 實現序列建模。
整個模型可以分為兩個部分:
- Encoder:理解輸入序列
- Decoder:逐步生成輸出序列
每個部分都由多個重復的模塊(Layer)組成,每個 Layer 內部結構非常規范。
二、Encoder 模塊拆解
一個 Encoder Layer 通常包括以下結構:
輸入 Embedding → 位置編碼 → 多頭自注意力(Multi-Head Self-Attention)→ 殘差連接 + LayerNorm → 前饋全連接層(FFN)→ 殘差連接 + LayerNorm
1. 輸入 Embedding + 位置編碼
- 詞嵌入:將離散詞 token 轉化為連續向量
- 位置編碼(Positional Encoding):添加序列中 token 的位置信息,常用 sin/cos 形式
2. 多頭自注意力(Multi-Head Self-Attention)
- 每個位置都對所有位置的 token 做注意力計算
- 多頭機制可以并行學習不同語義空間的信息
3. 殘差連接 + LayerNorm
- 避免深層網絡梯度消失
- 加快收斂速度,提高訓練穩定性
4. 前饋神經網絡(FFN)
- 兩層全連接層,中間使用激活函數 ReLU 或 GELU
- 提高模型非線性表達能力
三、Decoder 模塊拆解
Decoder Layer 在結構上和 Encoder 類似,但多了一個關鍵模塊:Encoder-Decoder Attention,同時引入了Mask 機制來保證自回歸生成。
輸入 Embedding → 位置編碼 → Masked Multi-Head Self-Attention → 殘差連接 + LayerNorm
→ Encoder-Decoder Attention → 殘差連接 + LayerNorm
→ FFN → 殘差連接 + LayerNorm
1. Masked Multi-Head Self-Attention
- 為了防止"看見未來",只允許當前 token 看到它左邊的 token(即因果 Mask)
2. Encoder-Decoder Attention
- 允許 Decoder 訪問 Encoder 的輸出表示,用于對輸入序列進行上下文感知
- 本質也是注意力機制,只不過 Query 來自 Decoder,Key 和 Value 來自 Encoder 輸出
四、整體結構圖
建議自己畫一遍 Transformer 的流程圖,從輸入 token 到輸出結果,包括 Encoder 和 Decoder 各層之間的連接方式。
小提示可以參考以下流程(動手練習!):
[Input Embedding + Pos Encoding] → [N個Encoder Layer 堆疊] → Encoder輸出
↓
[Shifted Output Embedding + Pos Encoding] → [N個Decoder Layer 堆疊(含 Mask + Encoder-Decoder Attention)]
↓
[線性層 + Softmax] → 最終預測輸出
? 小測驗:請嘗試畫出這個結構圖,并標注出每個模塊的主要作用。
五、總結:你需要掌握的關鍵點
| 模塊 | 作用說明 |
|---|---|
| Self-Attention | 獲取上下文依賴 |
| Multi-Head Mechanism | 學習多種注意力表示 |
| Positional Encoding | 注入位置信息 |
| FFN | 增強模型表達能力 |
| Residual + LayerNorm | 穩定訓練、加快收斂 |
| Masking(Decoder) | 保證生成的因果性 |
| Encoder-Decoder Attention | 對輸入序列做條件建模 |
六、后續推薦閱讀
- 《Attention is All You Need》原論文
- BERT、GPT、T5 架構演化對比
- Transformer 變體(如:Linformer、Performer、Longformer)
希望這篇文章能幫助你真正"看懂" Transformer 的結構與邏輯。建議動手畫一畫,理解每一個模塊的輸入輸出關系,構建自己的知識圖譜。
你是否已經掌握 Transformer 的全部細節了?不妨挑戰一下自己,不看圖,能不能完整說出 Encoder 和 Decoder 每一層的結構?
需要我生成一張配套的 Transformer 流程圖嗎?
七、核心公式與直觀解釋
1. 自注意力機制(Self-Attention)
-
公式:
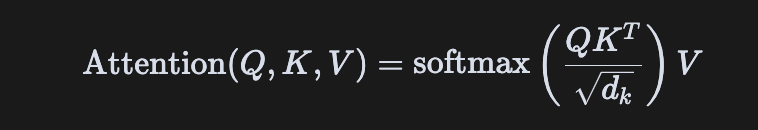
-
直觀理解:每個 token 通過 Query 與所有 token 的 Key 計算相關性分數,Softmax 后加權 Value,動態聚合全局信息。
2. 前饋神經網絡(FFN)
- 結構:兩層全連接,常用激活函數 ReLU/GELU
- 作用:提升模型的非線性表達能力
3. Mask 機制
- Decoder Masked Attention:用上三角 Mask 保證自回歸生成,防止信息泄露
4. Encoder-Decoder Attention
- 作用:讓 Decoder 能"讀"到 Encoder 的輸出,做條件生成
- 本質:Query 來自 Decoder,Key/Value 來自 Encoder
八、配套流程圖與交互式可視化代碼(Streamlit Demo)
1. 結構流程圖建議
建議動手畫一遍 Transformer 的流程圖,幫助理解各模塊的輸入輸出關系。參考流程如下:
[Input Embedding + Pos Encoding] → [N個Encoder Layer 堆疊] → Encoder輸出
↓
[Shifted Output Embedding + Pos Encoding] → [N個Decoder Layer 堆疊(含 Mask + Encoder-Decoder Attention)]
↓
[線性層 + Softmax] → 最終預測輸出
你可以用 draw.io、ProcessOn、Visio 等工具繪制,也可以參考下方 Streamlit Demo 的可視化。
2. Streamlit 交互式可視化 Demo 代碼
將以下代碼保存為 streamlit_transformer_demo.py,在命令行運行 streamlit run streamlit_transformer_demo.py 即可體驗:
import streamlit as st
import numpy as np
import matplotlib.pyplot as pltst.set_page_config(page_title="Transformer Encoder/Decoder 可視化拆解", layout="wide")st.title("Transformer Encoder/Decoder 結構交互式拆解")
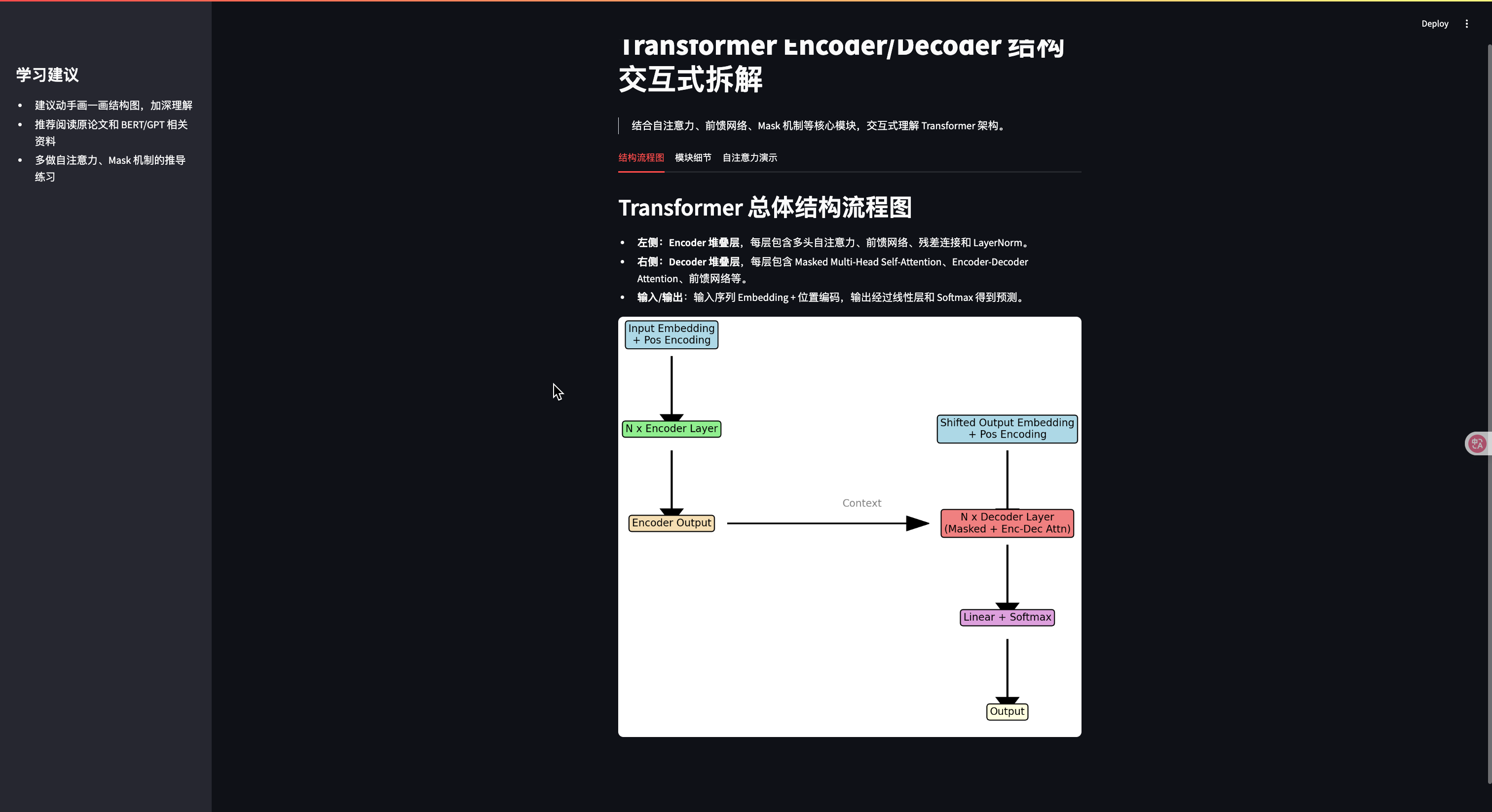
st.markdown("""
> 結合自注意力、前饋網絡、Mask 機制等核心模塊,交互式理解 Transformer 架構。
""")tab1, tab2, tab3 = st.tabs(["結構流程圖", "模塊細節", "自注意力演示"])with tab1:st.header("Transformer 總體結構流程圖")st.markdown("""- **左側:Encoder 堆疊層**,每層包含多頭自注意力、前饋網絡、殘差連接和 LayerNorm。- **右側:Decoder 堆疊層**,每層包含 Masked Multi-Head Self-Attention、Encoder-Decoder Attention、前饋網絡等。- **輸入/輸出**:輸入序列 Embedding + 位置編碼,輸出經過線性層和 Softmax 得到預測。""")fig, ax = plt.subplots(figsize=(7, 7))ax.axis('off')# Encoder部分ax.text(0.5, 0.95, "Input Embedding\n+ Pos Encoding", ha='center', va='center', bbox=dict(boxstyle="round", fc="lightblue"))ax.arrow(0.5, 0.92, 0, -0.08, head_width=0.02, head_length=0.02, fc='k', ec='k')ax.text(0.5, 0.82, "N x Encoder Layer", ha='center', va='center', bbox=dict(boxstyle="round", fc="lightgreen"))ax.arrow(0.5, 0.79, 0, -0.08, head_width=0.02, head_length=0.02, fc='k', ec='k')ax.text(0.5, 0.69, "Encoder Output", ha='center', va='center', bbox=dict(boxstyle="round", fc="wheat"))# Decoder部分ax.text(0.8, 0.82, "Shifted Output Embedding\n+ Pos Encoding", ha='center', va='center', bbox=dict(boxstyle="round", fc="lightblue"))ax.arrow(0.8, 0.79, 0, -0.08, head_width=0.02, head_length=0.02, fc='k', ec='k')ax.text(0.8, 0.69, "N x Decoder Layer\n(Masked + Enc-Dec Attn)", ha='center', va='center', bbox=dict(boxstyle="round", fc="lightcoral"))ax.arrow(0.8, 0.66, 0, -0.08, head_width=0.02, head_length=0.02, fc='k', ec='k')ax.text(0.8, 0.56, "Linear + Softmax", ha='center', va='center', bbox=dict(boxstyle="round", fc="plum"))ax.arrow(0.8, 0.53, 0, -0.08, head_width=0.02, head_length=0.02, fc='k', ec='k')ax.text(0.8, 0.43, "Output", ha='center', va='center', bbox=dict(boxstyle="round", fc="lightyellow"))# Encoder Output 到 Decoder Layer 的橫向箭頭ax.arrow(0.55, 0.69, 0.18, 0, head_width=0.02, head_length=0.02, fc='k', ec='k', length_includes_head=True)ax.text(0.67, 0.71, "Context", ha='center', va='bottom', fontsize=10, color='gray')st.pyplot(fig)with tab2:st.header("模塊細節與原理")st.markdown("""### Encoder Layer- **多頭自注意力(Multi-Head Self-Attention)**:每個 token 能關注全局,捕捉長距離依賴。- **殘差連接 + LayerNorm**:防止梯度消失,加快收斂。- **前饋神經網絡(FFN)**:提升非線性表達能力。### Decoder Layer- **Masked Multi-Head Self-Attention**:保證生成時不"偷看"未來 token。- **Encoder-Decoder Attention**:讓 Decoder 能訪問 Encoder 輸出,實現條件生成。- **殘差連接 + LayerNorm、FFN**:同 Encoder。### 位置編碼(Positional Encoding)- 注入序列順序信息,常用 sin/cos 公式。### Mask 機制- Decoder 中用上三角 Mask,防止信息泄露。---**自注意力公式**:
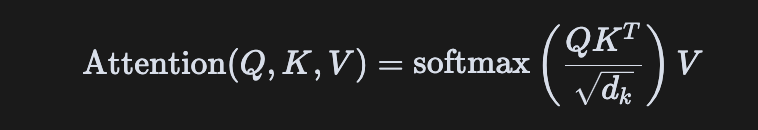with tab3:st.header("自注意力分數計算演示")st.markdown("""下面你可以輸入一組簡單的 token 向量,體驗自注意力分數的計算過程。""")st.markdown("**假設有3個token,每個維度為2**")tokens = st.text_area("輸入token向量(每行一個token,用逗號分隔)", "1,0\n0,1\n1,1")try:X = np.array([list(map(float, line.split(','))) for line in tokens.strip().split('\n')])d_k = X.shape[1]Q = XK = XV = Xattn_scores = Q @ K.T / np.sqrt(d_k)attn_weights = np.exp(attn_scores) / np.exp(attn_scores).sum(axis=1, keepdims=True)output = attn_weights @ Vst.write("**Attention 分數矩陣**")st.dataframe(attn_scores)st.write("**Softmax 后的權重**")st.dataframe(attn_weights)st.write("**輸出向量(加權和)**")st.dataframe(output)except Exception as e:st.error(f"輸入格式有誤: {e}")st.sidebar.title("學習建議")
st.sidebar.markdown("""
- 建議動手畫一畫結構圖,加深理解
- 推薦閱讀原論文和 BERT/GPT 相關資料
- 多做自注意力、Mask 機制的推導練習
""")---




)



:移情階段評分體系構建與實戰案例解析)



:[macOS 64bit App開發]: 注意“回車換行“的跨平臺使用.](http://pic.xiahunao.cn/[原創](現代Delphi 12指南):[macOS 64bit App開發]: 注意“回車換行“的跨平臺使用.)





