簡介

VITA-Audio 是一個由騰訊優圖實驗室(Tencent Youtu Lab)、南京大學和廈門大學的研究人員共同開發的項目,旨在解決現有語音模型在流式生成(streaming)場景下生成第一個音頻令牌(token)時的高延遲問題。這種延遲在實時應用中(如語音助手、實時語音翻譯)是一個顯著的瓶頸,限制了模型的部署和實際應用。
開發動機與目標
-
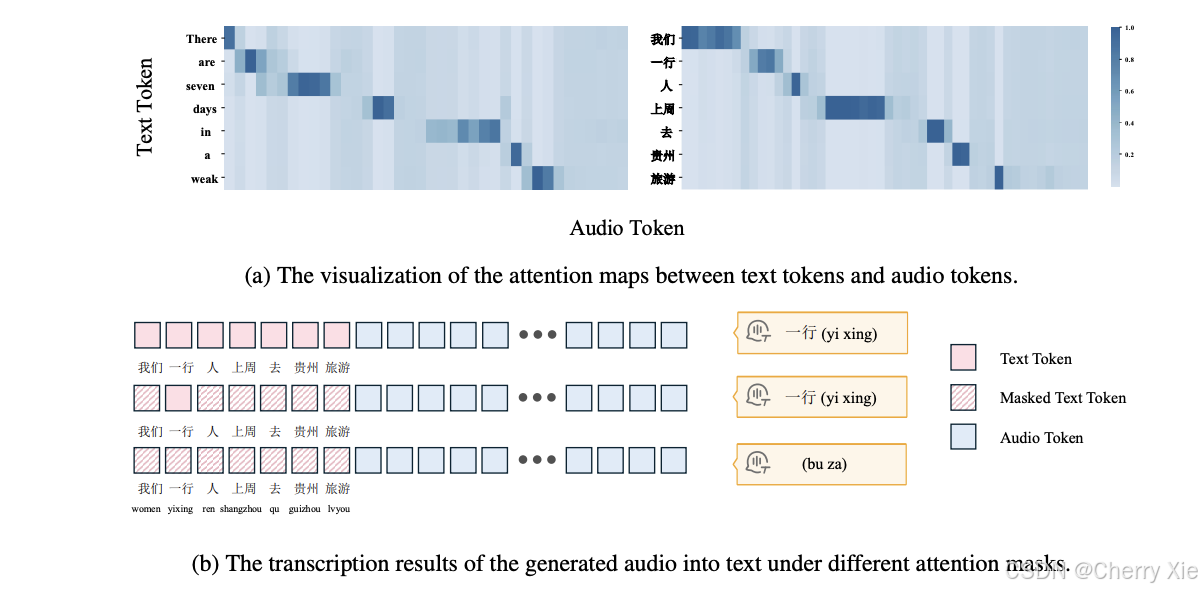
問題驅動:隨著自然人機交互需求的增長,語音作為日常交流的主要形式,其實時性變得越來越重要。然而,現有模型在流式生成時存在高延遲問題,特別是在生成第一個音頻令牌時,延遲可能達到數秒,影響用戶體驗 。
-
目標:VITA-Audio 旨在通過創新性地引入交叉模態令牌生成機制(Cross-Modal Token Generation),顯著降低生成延遲,同時保持語音質量的優異表現。其核心目標是實現高效的音頻-文本令牌生成,適合實時交互場景。
-
創新點:項目提出了一種輕量級的多模態令牌預測模塊(Multiple Cross-modal Token Prediction, MCTP),能夠在單次模型前向傳播中生成多個音頻令牌,從而加速推理并減少首個音頻令牌的生成延遲 。
-
訓練策略:采用四階段漸進式訓練策略(Four-Stage Progressive Training),確保模型在加速的同時保持高質量輸出,訓練基于大規模開源語音數據集,確保多語言和多風格的泛化能力 。
-
應用場景:VITA-Audio 適用于需要低延遲的語音生成任務,如實時語音助手、語音翻譯、語音合成等,特別適合資源受限的設備部署 。
-
開源與社區:項目已開源,采用開放許可,GitHub 倉庫提供推理代碼、訓練代碼和模型權重,鼓勵社區貢獻和使用,截至 2025 年 5 月 14 日,已吸引開發者關注 。
模型結構
VITA-Audio 的模型結構設計緊湊且高效,專為實時語音生成優化。
整體架構
-
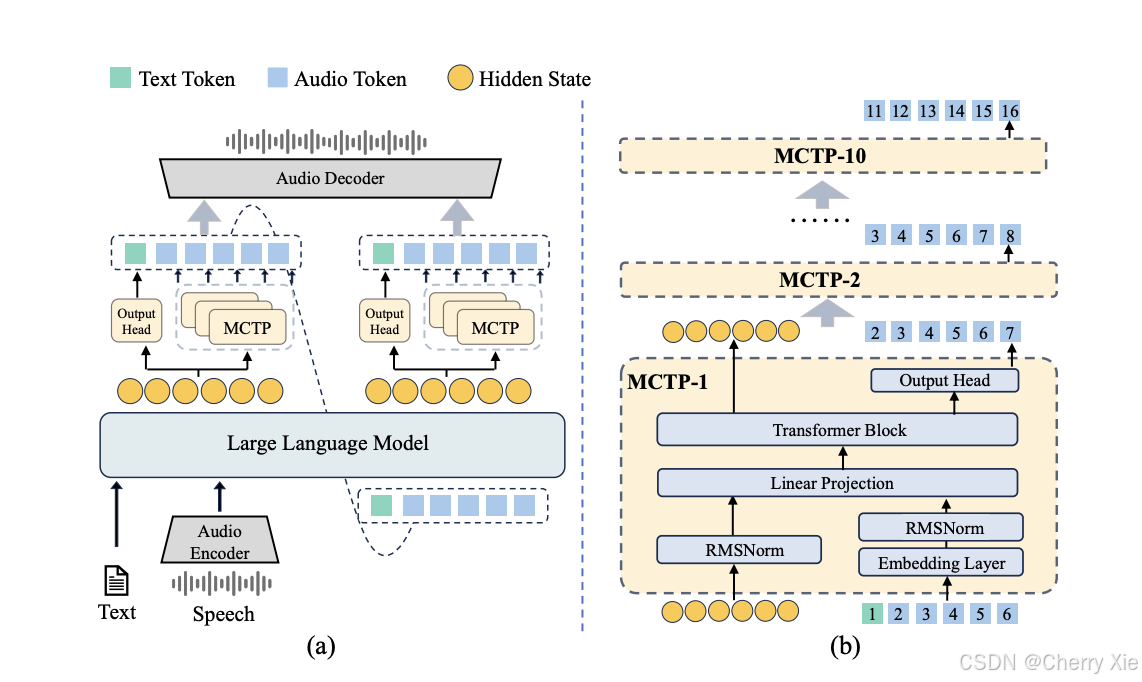
VITA-Audio 是一個端到端的大型語音模型(Large Speech-Language Model),支持音頻和文本的交叉模態生成,核心目標是實現快速的音頻-文本令牌生成 。
-
模型基于變分推理和對抗學習(Variational Inference with Adversarial Learning),結合了語音合成和語言模型的優點,適合端到端的語音任務。
關鍵模塊
-
Multiple Cross-modal Token Prediction (MCTP) 模塊
- 這是 VITA-Audio 的核心創新,允許模型在單次前向傳播中生成多個音頻令牌,從而顯著減少生成第一個音頻令牌的延遲 。
- MCTP 模塊通過交叉模態學習(Cross-Modal Learning)實現音頻和文本之間的協同生成,確保生成的音頻與文本提示保持一致,適合實時交互 。
- 其輕量級設計降低了計算開銷,適合資源受限的設備部署。
-
語音編碼器(Voice Encoder)
-
從參考音頻中提取語音特征(如音色、節奏、語調等),用于克隆目標語音 。
-
可能使用基于卷積或變換器的編碼器,捕獲音頻的時頻特征,確保音質的高保真度。
-
-
文本編碼器(Text Encoder)
-
處理輸入文本,生成語音合成的條件,可能是基于 Transformer 架構,支持多語言輸入 。
-
確保文本和音頻的語義一致性,適合跨語言生成任務。
-
-
生成器(Generator)
-
結合文本編碼器和語音編碼器的輸出,生成目標語音,使用對抗學習確保生成語音的真實性,減少偽影 。
-
生成器可能采用 U-Net 架構,結合條件生成網絡(Conditional GAN)實現高保真語音輸出。
-
-
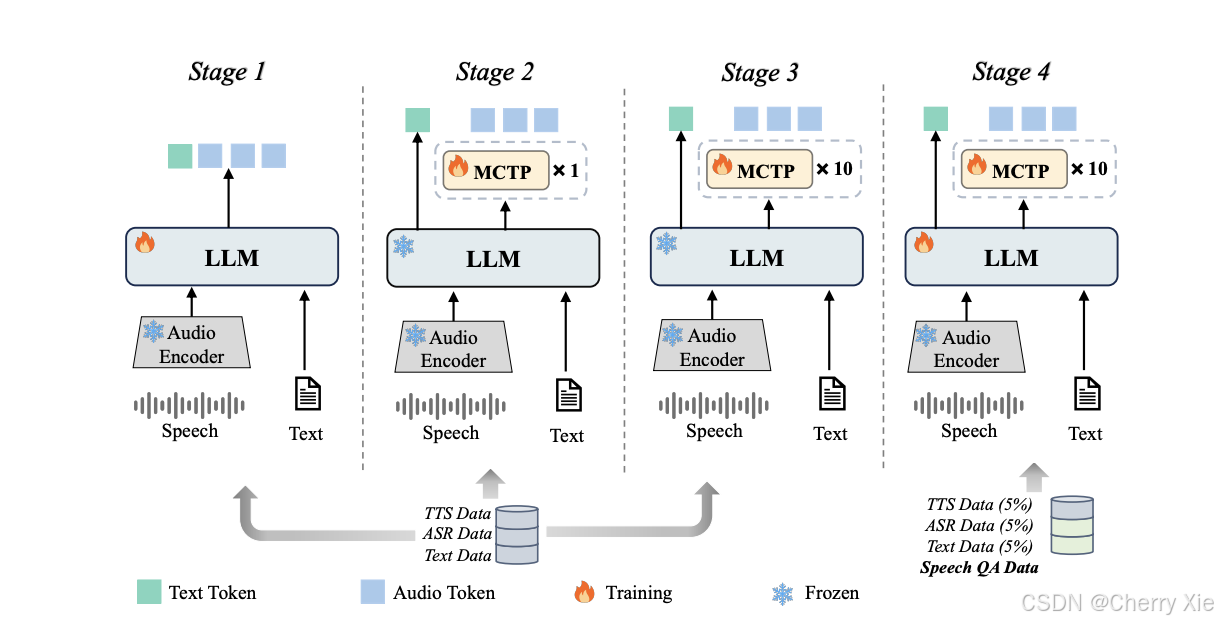
四階段漸進式訓練策略
-
模型采用四階段訓練策略,逐步增加訓練難度和數據復雜度,確保模型在加速的同時保持高質量輸出 。
-
可能包括預訓練(Pre-training)、微調(Fine-tuning)、多模態對齊(Multimodal Alignment)和優化(Optimization)階段。
-
性能優化
-
低延遲:通過 MCTP 模塊,VITA-Audio 在流式生成場景下顯著降低了生成第一個音頻令牌的延遲,提升了實時性,適合語音助手等應用 。
-
高效性:模型設計輕量級,適合在資源受限的設備上部署,同時保持高質量的語音輸出,社區反饋顯示在 RTX 4090 上生成速度比 RTX 3090 快 50%-70% 。
交互性
-
非喚醒式交互(Non-awakening Interaction):用戶無需通過喚醒詞或按鈕即可與模型進行語音交互,適合自然交互場景 。
-
音頻中斷交互(Audio Interrupt Interaction):用戶可以在模型生成過程中隨時提出新問題,模型會根據新問題及時響應,適合實時對話 。
性能對比

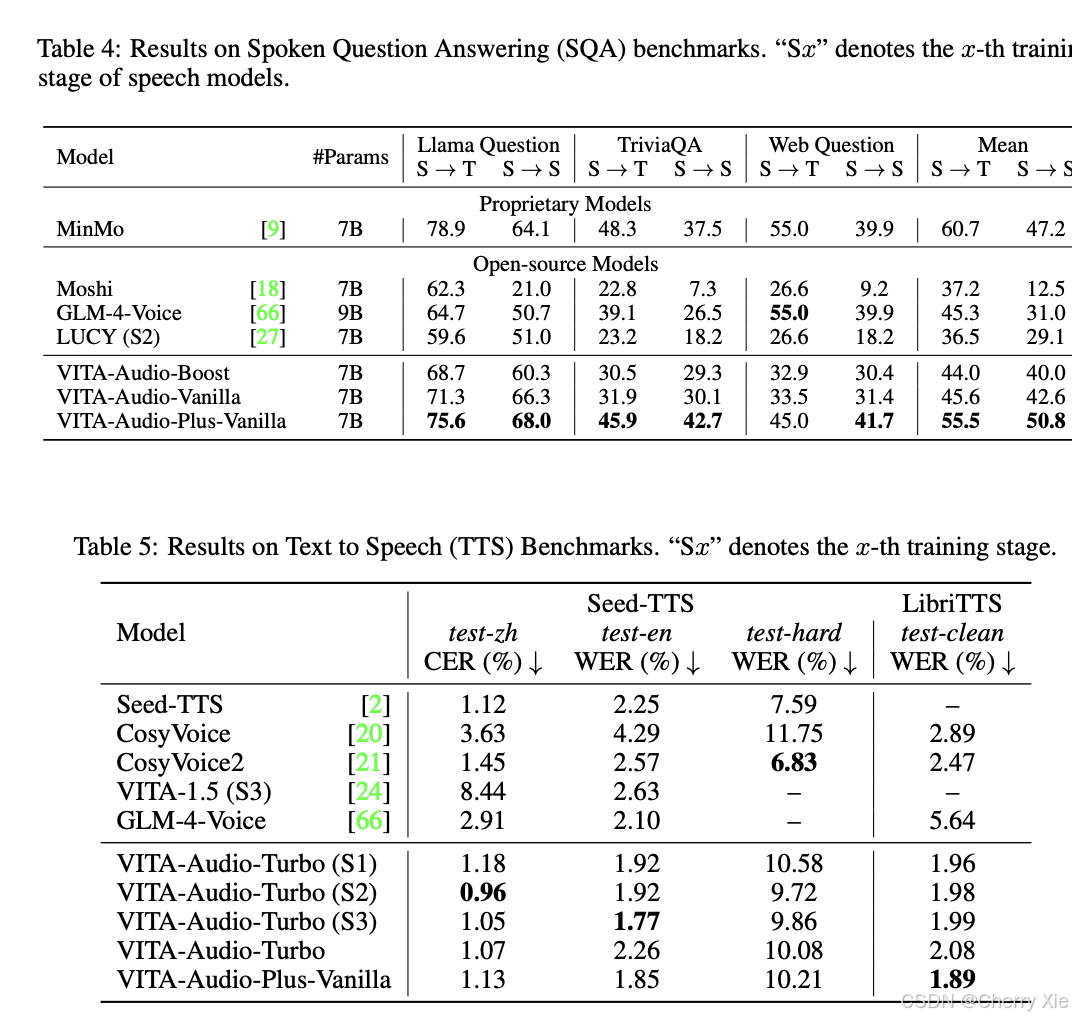
看看效果
相關文獻
github地址:https://github.com/VITA-MLLM/VITA-Audio#
技術報告:https://arxiv.org/pdf/2505.03739
模型下載:https://huggingface.co/collections/VITA-MLLM/vita-audio-680f036c174441e7cdf02575












)




:logging模塊)

