文章目錄
- 一、微調概述
- 1.1 微調步驟
- 1.2 微調場景
- 二、微調方法
- 2.1 三種方法
- 2.2 方法對比
- 2.3 關鍵結論
- 三、微調技術
- 3.1 微調依據
- 3.2 LoRA
- 3.2.1 原理
- 3.2.2 示例
- 3.3 QLoRA
- 3.4 適用場景
- 四、微調框架
- 4.1 LLaMA-Factory
- 4.2 Xtuner
- 4.3 對比
一、微調概述
微調(Fine-tuning)是深度學習中的一種常見方法,它通常用于在預訓練模型的基礎上進行進一步的訓練,以適應特定的任務。微調的主要目的是利用預訓練模型已經學習到的通用知識,從而提高模型在特定任務上的性能。常見的微調框架有 LLaMA-Factory 和 XTuner 等。
1.1 微調步驟
以微調 Bert 為例,微調通常包括以下幾個步驟:
- 加載預訓練的BERT模型。
- 修改模型結構,將最后一層全連接層的參數進行修改,以適應文本分類任務。
- 設置優化器和損失函數,例如Adam優化器和交叉熵損失函數。
- 訓練模型,使用微調技巧,如學習率調整、權重衰減、數據增強和早停。
- 評估模型性能,使用測試集進行評估,計算準確率、召回率等指標。
1.2 微調場景
微調通常用于以下場景:
- 修改模型的輸出層
- 修改模型的自我認知
- 改變模型的對話風格
二、微調方法
2.1 三種方法
微調模式主要分為三種:
- 增量微調:在預訓練模型的基礎上,僅對新增的附加參數(如Adapter層)進行訓練。這種方法可以顯著降低顯存和算力需求,適用于資源受限的環境。
- 局部微調:在預訓練模型的基礎上,對模型的局部層(如輸出層、注意力頭)進行訓練。這種方法可以在保證效果的同時,降低顯存和算力需求。
- 全量微調:在預訓練模型的基礎上,對模型的所有參數進行訓練。這種方法可以完全適配新數據,但需要較高的顯存和算力需求。
2.2 方法對比
| 對比維度 | 增量微調 | 局部微調 | 全量微調 |
|---|---|---|---|
| 參數調整范圍 | 僅新增的附加參數(如Adapter層) | 模型的部分層(如輸出層、注意力頭) | 模型全部參數 |
| 顯存/算力需求 | 極低(僅需訓練少量參數) | 中等(需訓練部分層梯度) | 極高(需更新所有參數) |
| 訓練速度 | 最快(參數少,反向傳播計算量小) | 較快(部分層參與更新) | 最慢(需全局梯度計算) |
| 效果 | 較弱(依賴新增參數的能力) | 穩定(平衡性能與資源) | 最佳(完全適配新數據) |
| 過擬合風險 | 低(原始參數固定) | 中(部分參數可能過擬合) | 高(所有參數可能過擬合) |
| 適用場景 | - 資源受限(如移動端) - 快速適配小樣本 | - 中等算力環境 - 任務特定層優化 | - 算力充足 - 數據分布與預訓練差異大 |
| 典型技術 | LoRA、Adapter、Prefix-Tuning | 凍結部分層(如BERT的前N層) | 標準反向傳播(全部參數更新) |
| 是否修改原模型 | 否(新增獨立參數) | 是(修改部分原參數) | 是(修改全部參數) |
| 部署復雜度 | 低(僅需加載附加模塊) | 中(需兼容部分修改層) | 高(需替換整個模型) |
2.3 關鍵結論
- 資源優先級:
- 算力有限 → 增量微調(如QLoRA)。
- 效果優先 → 全量微調(需4090級GPU)。
- 任務適配性:
- 小樣本/領域適配 → 局部微調(如僅調整分類頭)。
- 數據分布巨變 → 全量微調(如醫療文本→法律文本)。
- 技術趨勢:
- 增量微調(如LoRA)因高效性成為主流,尤其適合大模型輕量化部署。
三、微調技術
3.1 微調依據
研究發現,大模型在微調時的權重變化往往集中在一個 低秩子空間 中。也就是說,雖然模型有上億參數,但實際需要調整的參數是少量的。
3.2 LoRA
LoRA(Low-Rank Adaptation)是一種用于微調大型預訓練語言模型的輕量級方法。通過引入低秩矩陣來更新預訓練模型的權重,將權重更新矩陣 ΔW 表示為兩個較小矩陣 A 和 B 的乘積,只訓練這些低秩矩陣,減少需要調整的參數數量,降低計算成本和防止過擬合。
W = W_0 + \Delta W = W_0 + B \cdot A
其中:
W?是預訓練模型的原始權重(凍結,不更新)。ΔW是微調過程中需要更新的權重B和A是低秩矩陣,它們的秩遠小于原始矩陣的秩
3.2.1 原理
- 訓練時,輸入分別與原始權重和兩個低秩矩陣進行計算,得到最終結果,優化則僅優化
A和B; - 訓練完成后,將兩個低秩矩陣與原始模型中的權重進行合并, 合并后的模型與原始模型無異。
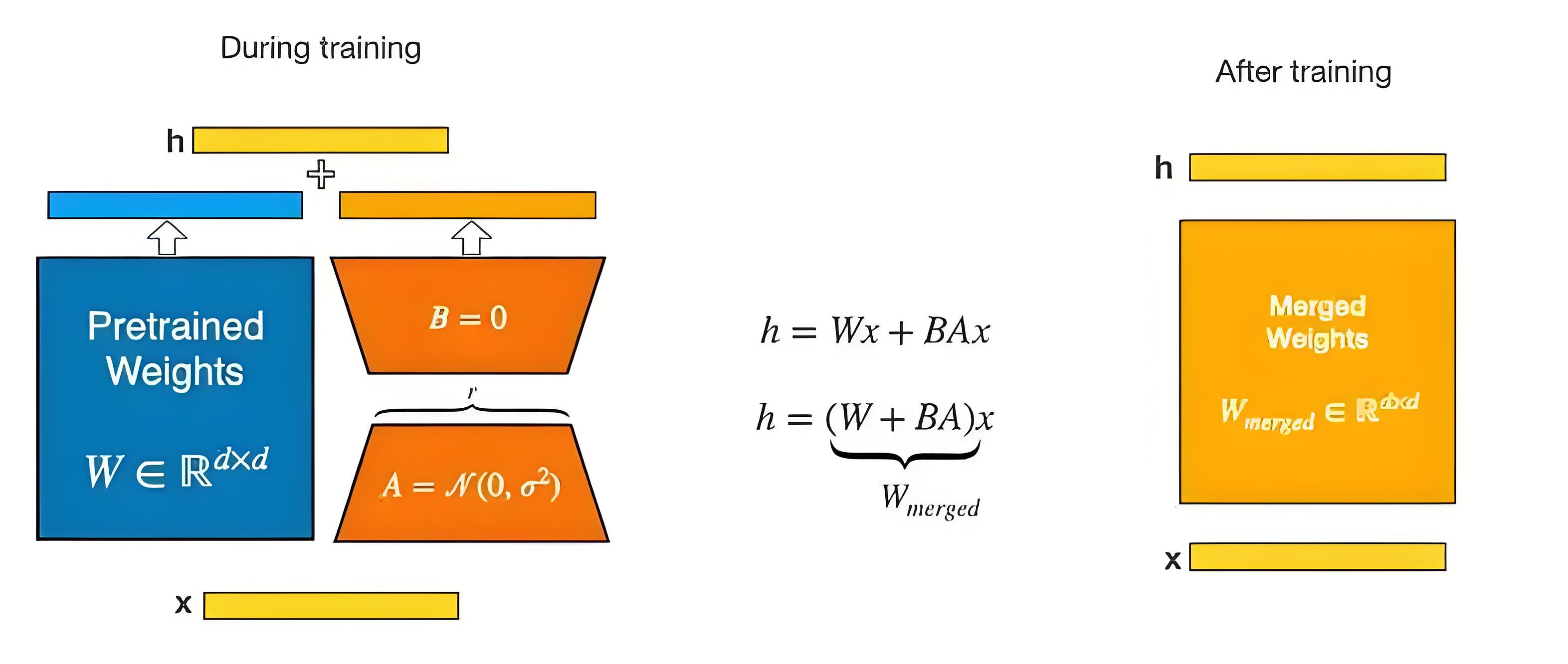
3.2.2 示例
假設原始權重 W? 是 1024×1024 矩陣(約100萬參數)
- 全量微調:需更新100萬參數。
- LoRA微調:如果
秩(r)=8,則僅更新 B(1024×8) + A(8×1024) = 16,384參數(近似減少98%)。
3.3 QLoRA
QLoRA(Quantized LoRA)在 LoRA 基礎上引入量化技術,不僅對模型引入低秩矩陣,還將低秩矩陣進行 量化,例如使用 4-bit NormalFloat(NF4) 數據類型,進一步減少內存占用和存儲需求。同時,采用 Double Quantization 對量化常數進行量化,節省更多內存。
3.4 適用場景
- LoRA:適用于資源有限但對模型精度要求較高,且希望微調速度相對較快的場景,在大規模預訓練模型的微調中能有效減少計算和存儲開銷。
- QLoRA:更適合對內存要求極為苛刻的場景,如在邊緣設備、移動設備或顯存較小的 GPU上運行大型預訓練模型,以及需要處理大規模數據但內存資源緊張的情況。
四、微調框架
4.1 LLaMA-Factory
- 核心特點:
- 定位:專注于LLaMA系列模型(如LLaMA-2、Chinese-LLaMA)的高效微調。
- 關鍵技術:
- 支持 LoRA/QLoRA 低秩微調,顯存占用降低50%+。
- 集成 Gradient Checkpointing(梯度檢查點),支持大批次訓練。
- 提供 對話模板對齊 工具,解決微調后輸出格式混亂問題。
- 優勢:
- 界面友好,支持一鍵啟動微調任務。
- 針對中文優化,內置中文詞表擴展和指令數據集(如Alpaca-CN)。
- 支持快速部署到消費級GPU(如RTX 3090 24GB微調7B模型)。
- 適用場景:
- 輕量化微調中文LLaMA模型。
- 小樣本場景下的領域適配(如醫療、法律)。
詳情可查看 大模型微調指南之 LLaMA-Factory 篇:一鍵啟動LLaMA系列模型高效微調
4.2 Xtuner
- 核心特點:
- 定位:通用大模型微調框架,支持多種架構(LLaMA、ChatGLM、InternLM等)。
- 關鍵技術:
- 全參數/增量微調 靈活切換,支持 PyTorch FSDP(多卡分布式訓練)。
- 內置 數據預處理流水線(自動處理文本/多模態數據)。
- 提供 量化訓練(GPTQ/AWQ)和 模型壓縮 工具鏈。
- 優勢:
- 模塊化設計,輕松適配新模型架構。
- 與OpenMMLab生態集成(如MMDeploy一鍵模型導出)。
- 適用場景:
- 全參數微調大規模模型(需A100/H100集群)。
- 工業級部署需求(如API服務、端側推理)。
詳情請查看 大模型微調指南之 Xtuner 篇:3步實現Qwen1.5中文對話模型優化
4.3 對比
| 維度 | LlaMA-Factory | Xtuner |
|---|---|---|
| 核心優勢 | 輕量化中文微調,低資源需求 | 多架構支持,工業級部署 |
| 微調方式 | 主打LoRA/QLoRA | 全參數/增量/量化訓練全覆蓋 |
| 硬件要求 | 消費級GPU(如RTX 3090) | 需高性能GPU(如A100) |
| 典型用戶 | 研究者/中小團隊 | 企業級開發/云服務商 |
| 生態整合 | 中文社區活躍 | 與OpenMMLab工具鏈深度集成 |


)



)
![SierraNet協議分析使用指導[RDMA]| 如何設置 NVMe QP 端口以進行正確解碼](http://pic.xiahunao.cn/SierraNet協議分析使用指導[RDMA]| 如何設置 NVMe QP 端口以進行正確解碼)

——09.softmax回歸+圖像分類數據集+從零實現+簡潔實現)









