目錄
一、什么是事務:
二、事務的前置知識了解
引擎是否支持事務
事務的提交方式
事務操作的前置準備:
三、事務回滾:
四、事務崩潰:
原子性:
持久性:
五、自動提交和手動提交:
六、事務的隔離性:
怎么理解:
隔離級別示例:
讀未提交:
讀提交:
可重復讀:
串行化:
七、拓展知識:
數據庫的并發場景:
三個隱藏字段:
undo日志:
MVCC多版本控制:
周邊問題:
read view:
?RC VS RR:
一、什么是事務:
事務是由多條DML的SQL語句構成的,這些語句在邏輯上是相關聯的,比如進行轉賬操作,就需要有多條SQL語句:查詢賬戶,在此賬戶上減去指定金額,在別的賬戶上加上指定金額等等,這些操作是由多條語句構成的,但是這多條操作必須是原子的,也就是說要么轉賬失敗,要么轉賬成功,不能只進行一般(在我這賬戶里面扣了,但是在別人的賬戶那里卻沒有加上)
這樣一個在用戶角度看起來是原子性的操作在MySQL中就是一個事務,要把事務看做一個整體
在MySQL中,會有多個事務同時執行,而每個事務都有許多SQL語句,那么在MySQL中就會有很多SQL被同時執行,所以事務不僅僅只是由SQL語句的集合,其還要滿足一下屬性:
事務的四大屬性:
- 原子性:這個在之前的學習中了解過了,就是只有執行前和執行后,沒有正在執行,也就是一個事務只有其中的SQL語句全部完成和其中的SQL語句還未開始執行這兩個情況,不會在中間的某個環節結束
- 一致性:這個指的是,事務在執行前和執行后,用戶數據的正確性沒有被破壞,也就是說在執行前后數據的變化是可預期的,比如說在轉賬這個事務前后,我肯定能預期我的賬戶會減少,別人的賬戶會增多我減少的部分,在技術層面上,保證好原子性,隔離性,持久性就能夠保證一致性
- 隔離性:MySQL中允許多個事務同時執行數據,隔離性就是保證事務之間互不影響,隔離性又分許多等級包括讀未提交( Read uncommitted )讀提交( read committed )可重復讀( repeatable read)和串行化( Serializable ),兩個事務同時執行,兩個事務又是具有原子性的,這時當兩個事務并發執行的時候要體現出事務之間的隔離性
- 持久性:當事務執行結束后,對數據的修改是永久的,即便后面系統崩潰也不會丟失數據
以上四大屬性也被叫做ACID
二、事務的前置知識了解
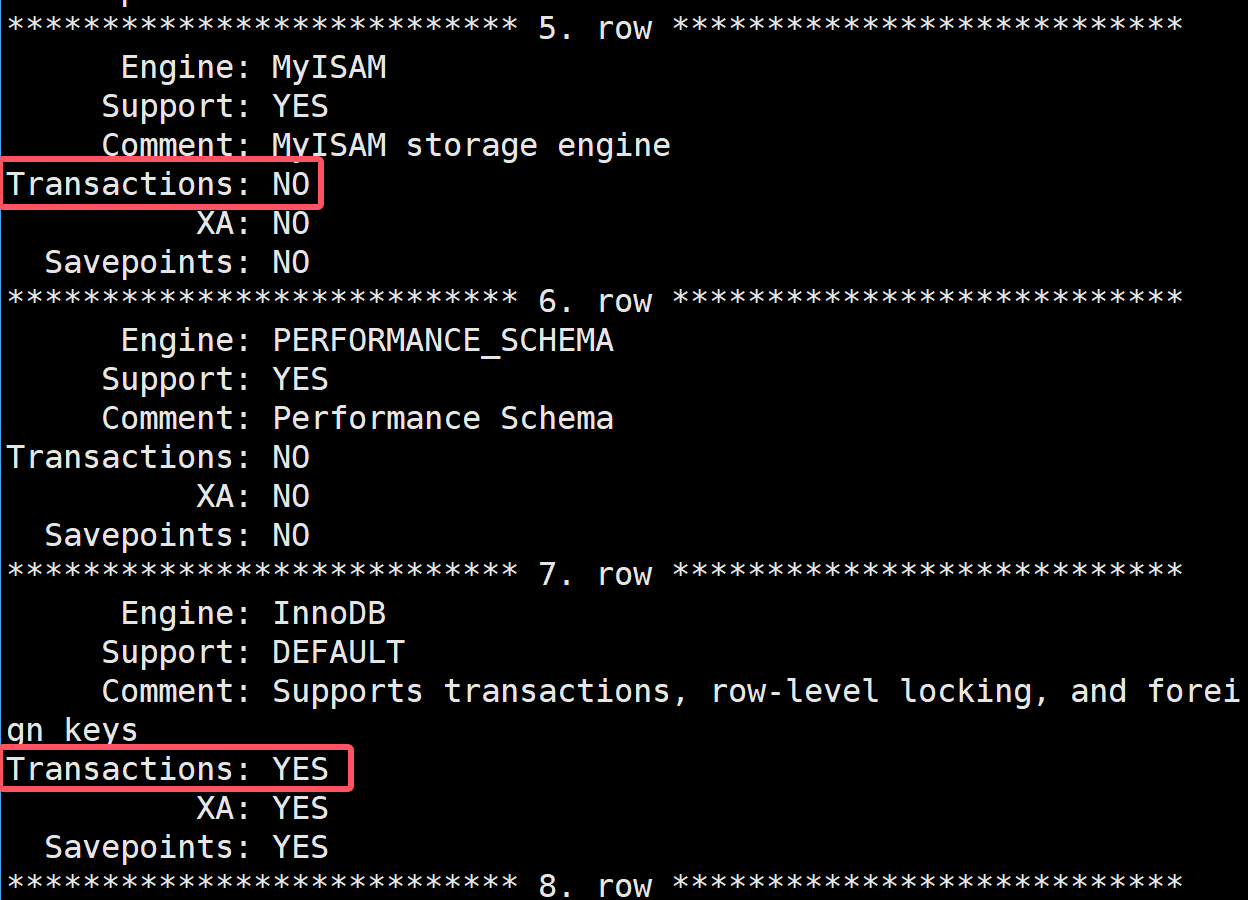
引擎是否支持事務
在MySQL中,MyISAM引擎是不支持事務的,InnoDB引擎是支持的,我們默認也是InnoDB引擎
事務的提交方式
查看事務的提交方式:
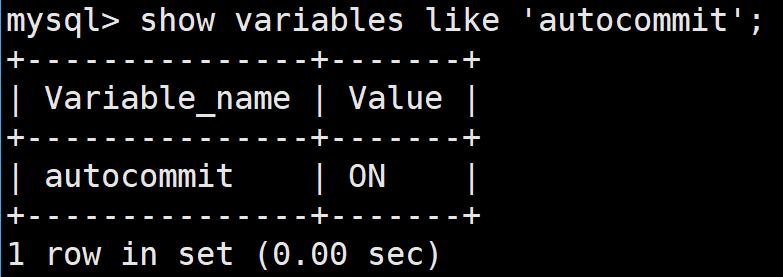
關于事務有兩種提交方式,分別是手動提交和自動提交,可以在命令行中用如下SQL進行查看自動提交是否打開:
show variables like 'autocommit';如下,就證明自動提交是打開的,如果value那一列是OFF的話就證明自動提交是關閉的,此時也就是手動提交
修改事務的提交方式:
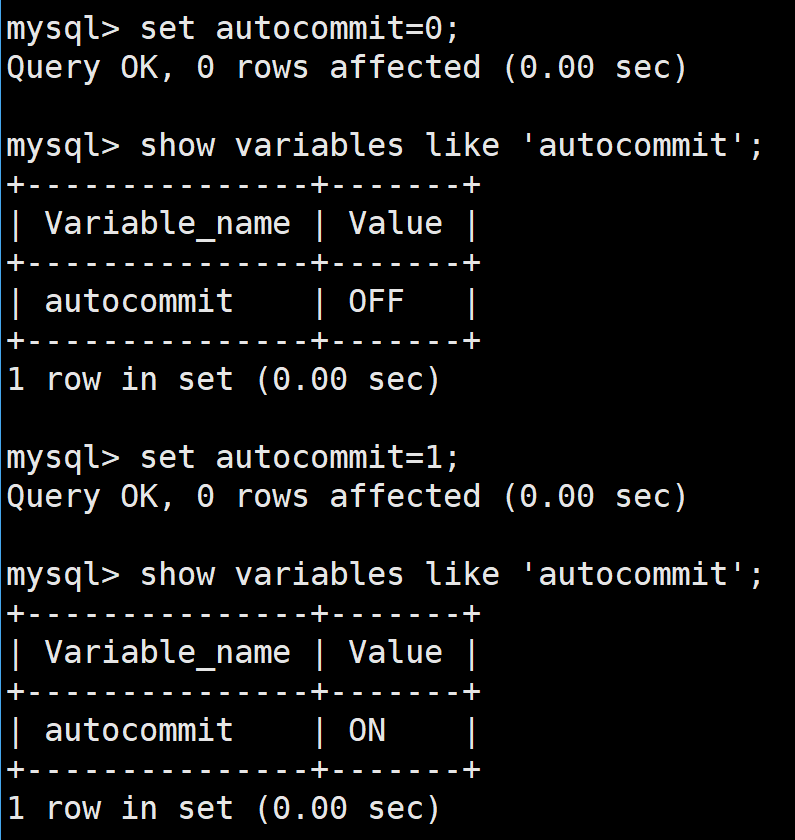
用set設置autocommit來進行事務的自動提交的打開或者關閉
0就是OFF,1就是ON
事務操作的前置準備:
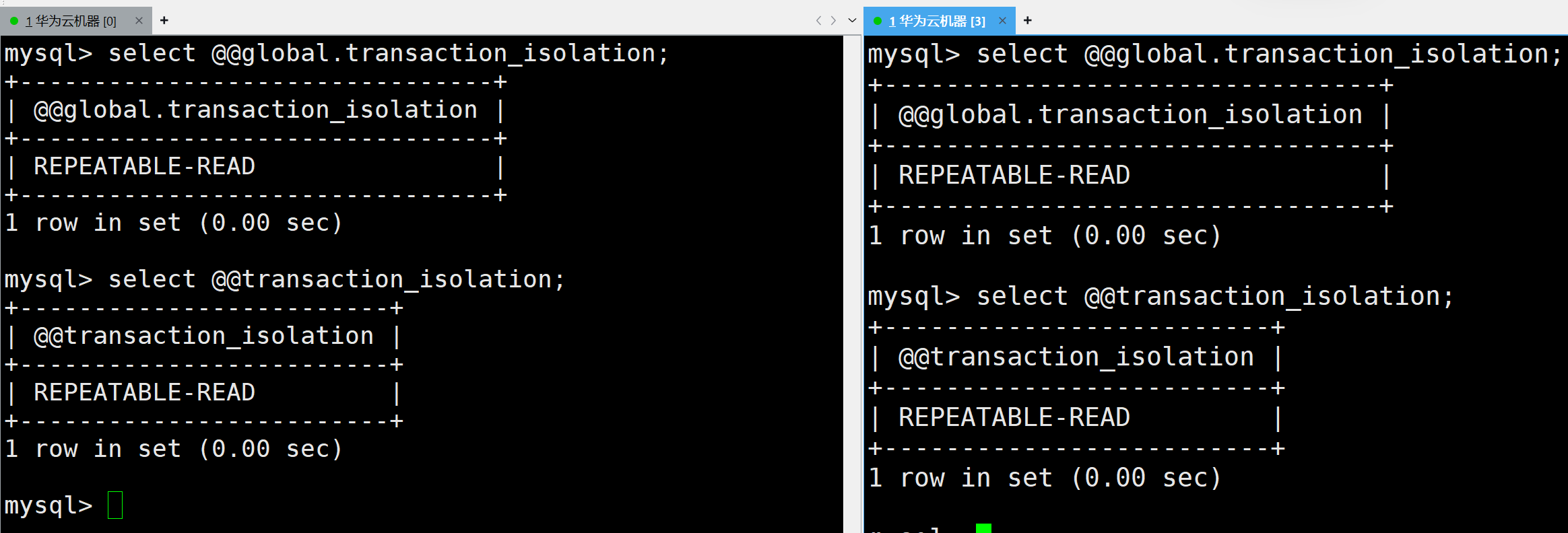
在接下來進行事務操作的時候,我們首先將隔離級別修改為讀未提交( Read uncommitted )這是最低的隔離級別,這樣在后面的操作中能夠方便查看,在了解完其他性質后,我們再來了解事務的隔離級別:
首先查看當前的隔離級別:
select @@transaction_isolation;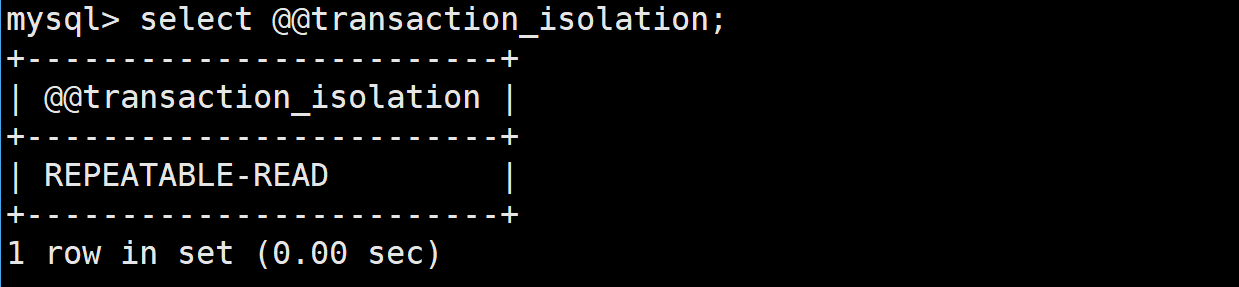
如上是可重復讀的隔離級別,我將其修改為讀未提交( Read uncommitted )
set global transaction isolation level read uncommitted;但是在修改后進行查看發現沒有改變,這是因為當前查看的是局部的隔離級別
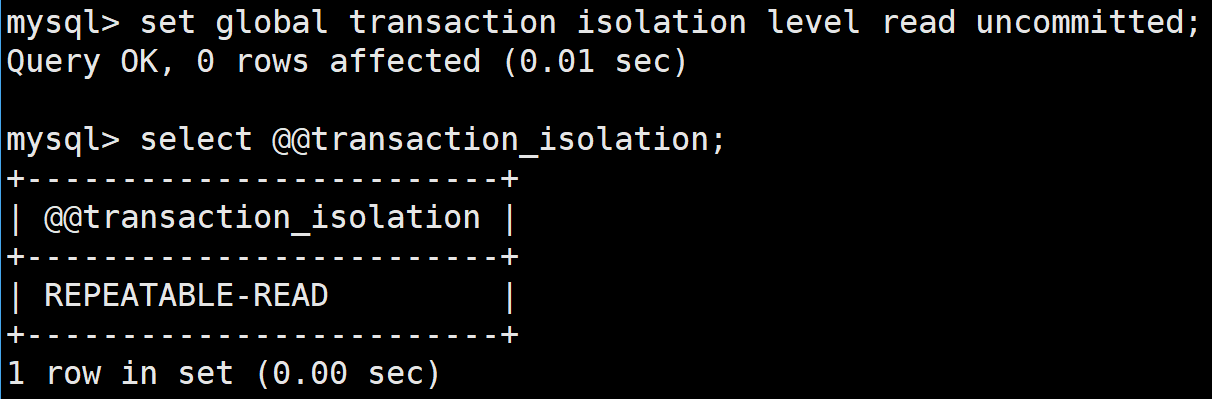
如上修改是修改的全局的,如果想查看全局的需要如下SQL:
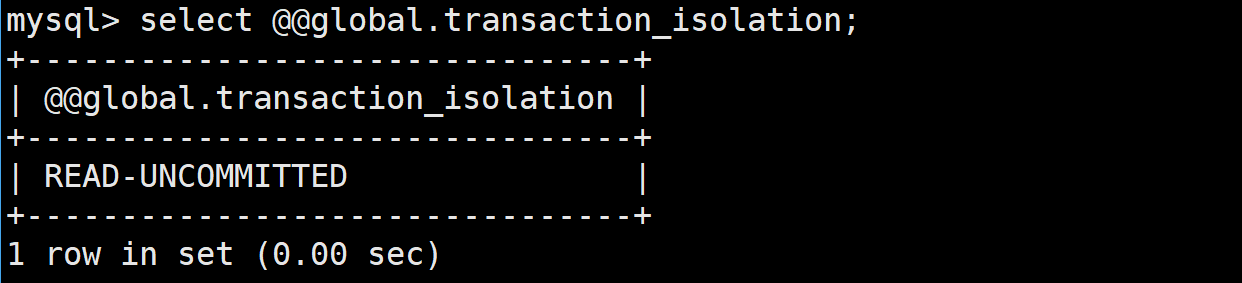
隔離這部分接下來會詳細講解的,可以在后面詳細了解
我們重新登錄一下MySQL就會把局部的也修改了
接下來準備一張測試表
這是一張員工表,其中包含了員工ID,員工姓名,員工工資
mysql> create table if not exists account(-> id int primary key,-> name varchar(50) not null default '',-> blance decimal(10, 2) not null default 0.0-> );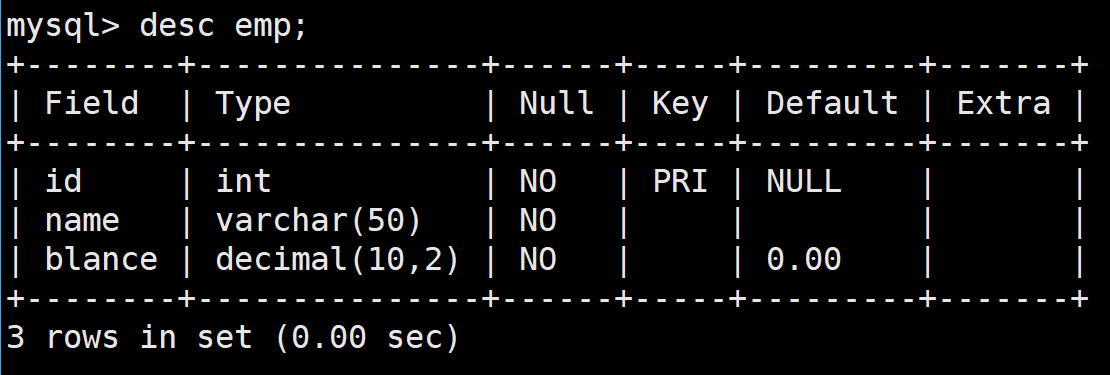
三、事務回滾:
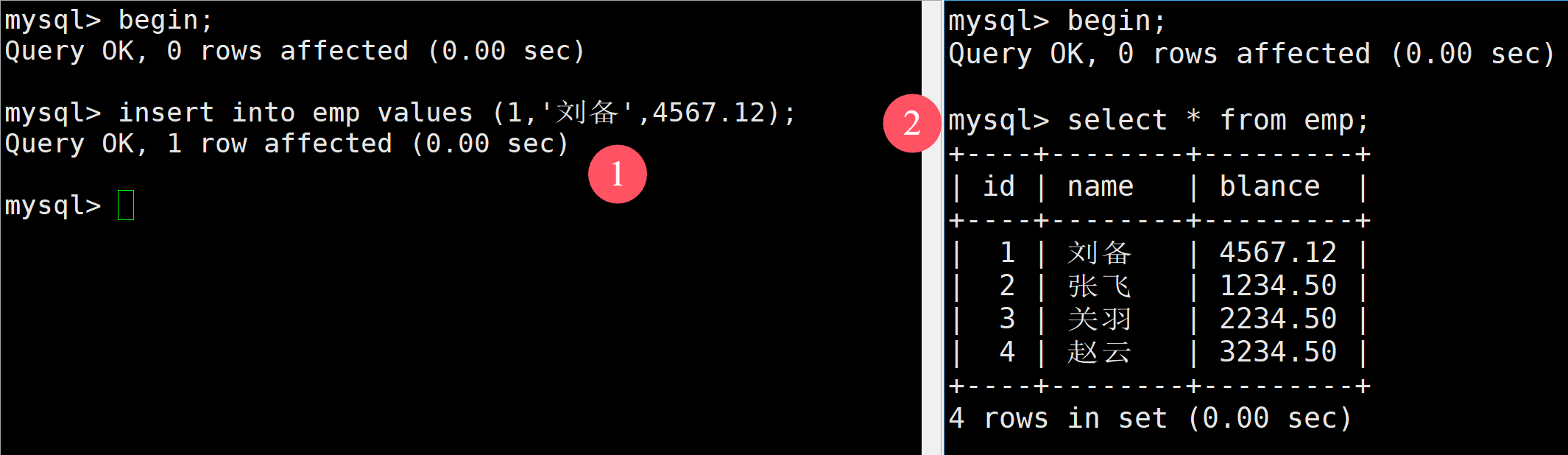
首先就是啟動一個事務,這里有兩種方法,begin和start transaction


等到后面commit為止這就是MySQL中的一個事務,在這期間的SQL語句是要看做一個整體的
接著準備兩個終端,一個進行插入操作,并設置保存點,另一個進行查看操作
設置保存點的方法:
savepoint 名稱;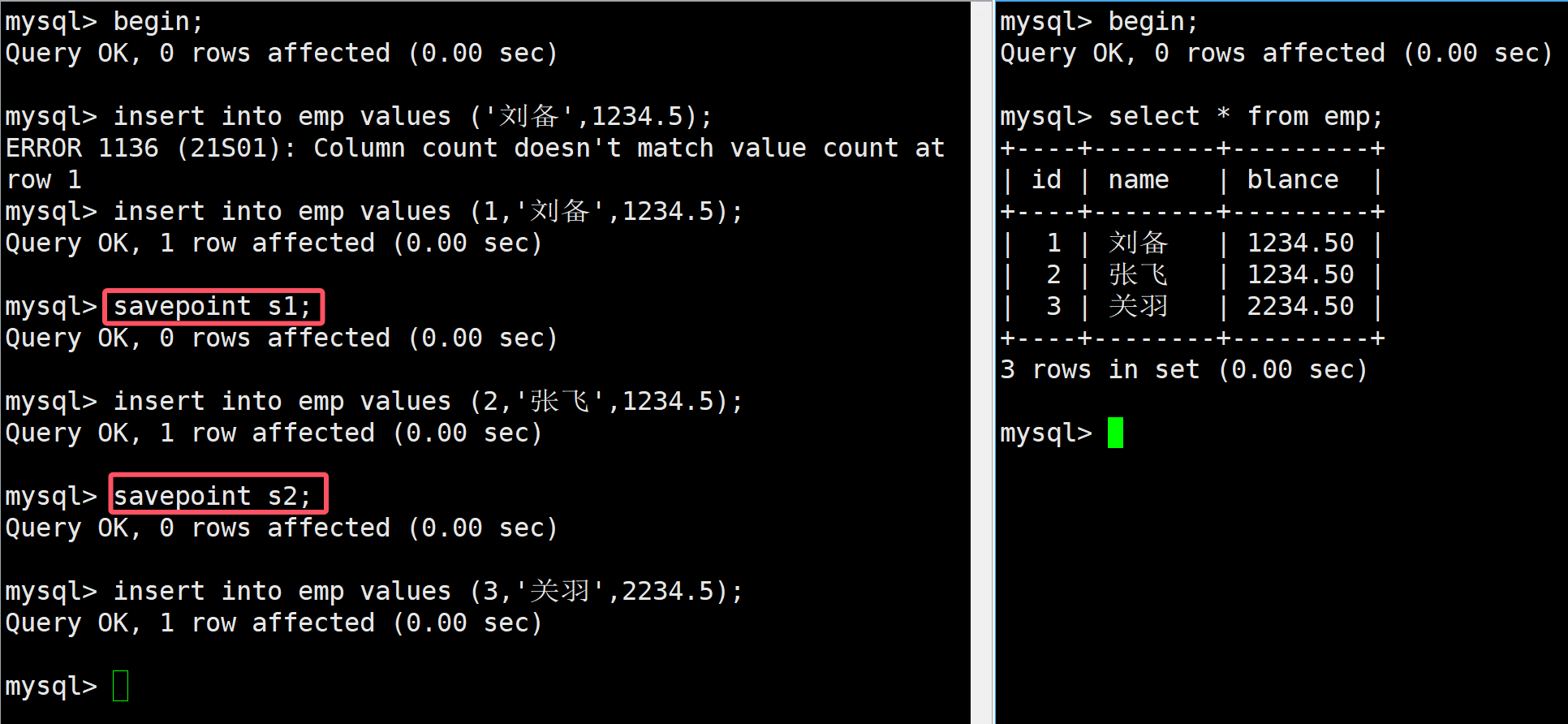
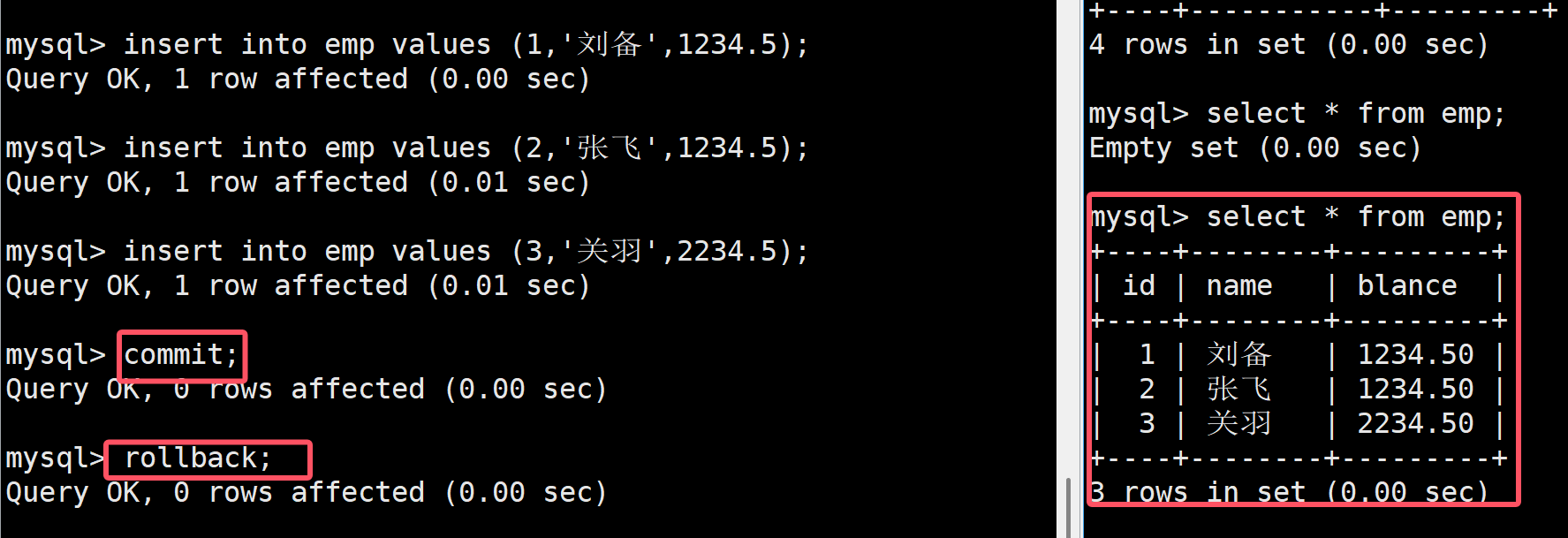
如上,這是首先對emp員工表進行插入,每插入一條數據就設置一個保存點,當三條語句全部插入后再右邊可以進行查看
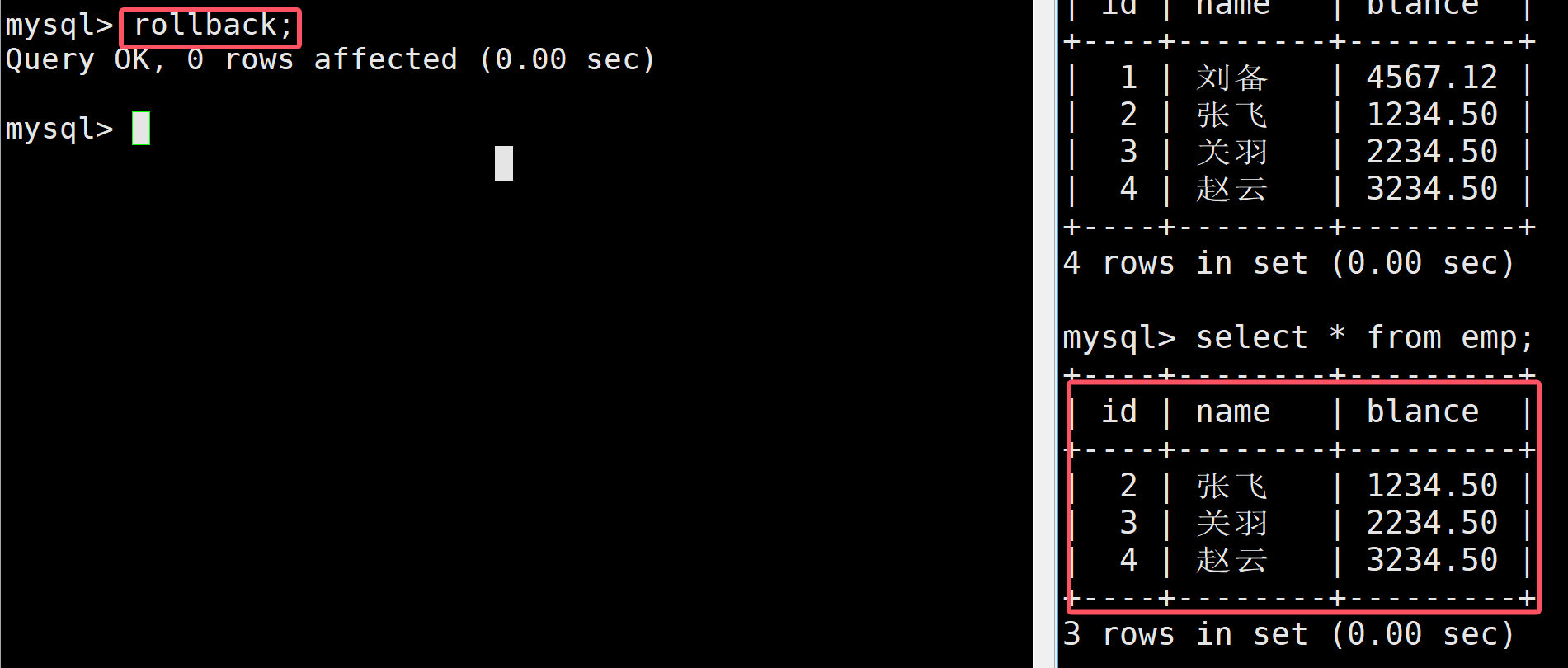
這個時候,如果我后悔插入關羽這條消息了,就可以使用事務回滾,如下SQL語句進行回滾到s2
rollback to 名稱;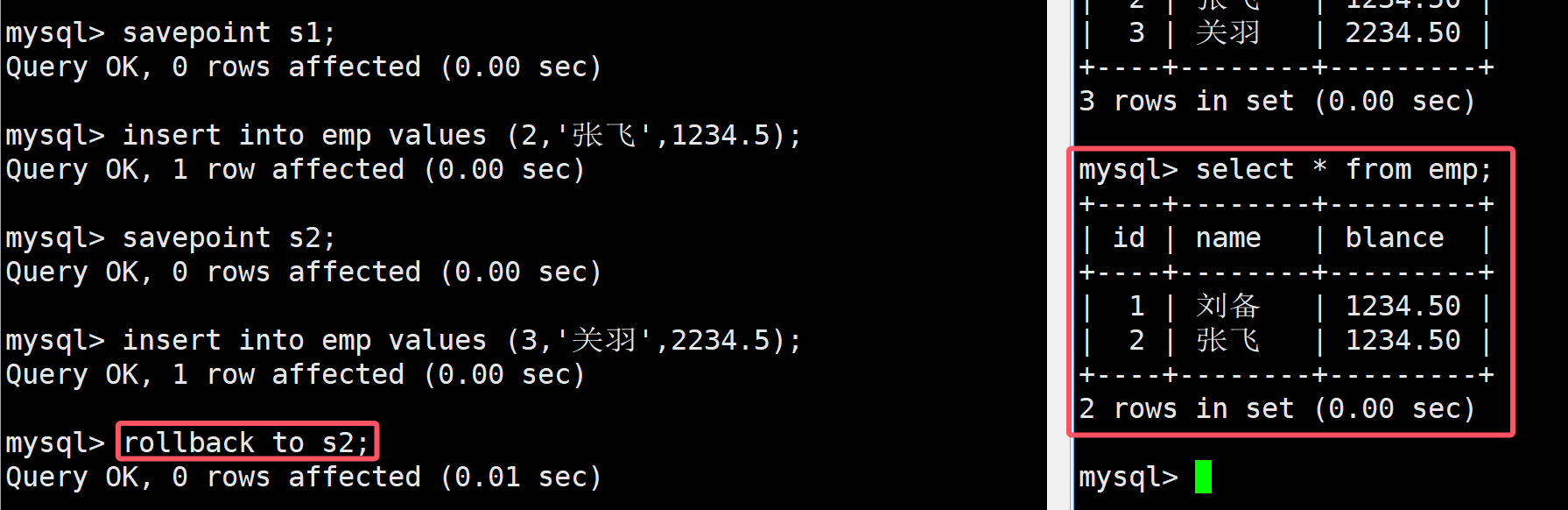
此時在進行查看就會發現關羽這條消息不見了
也可以回滾到s1讓張飛也不見
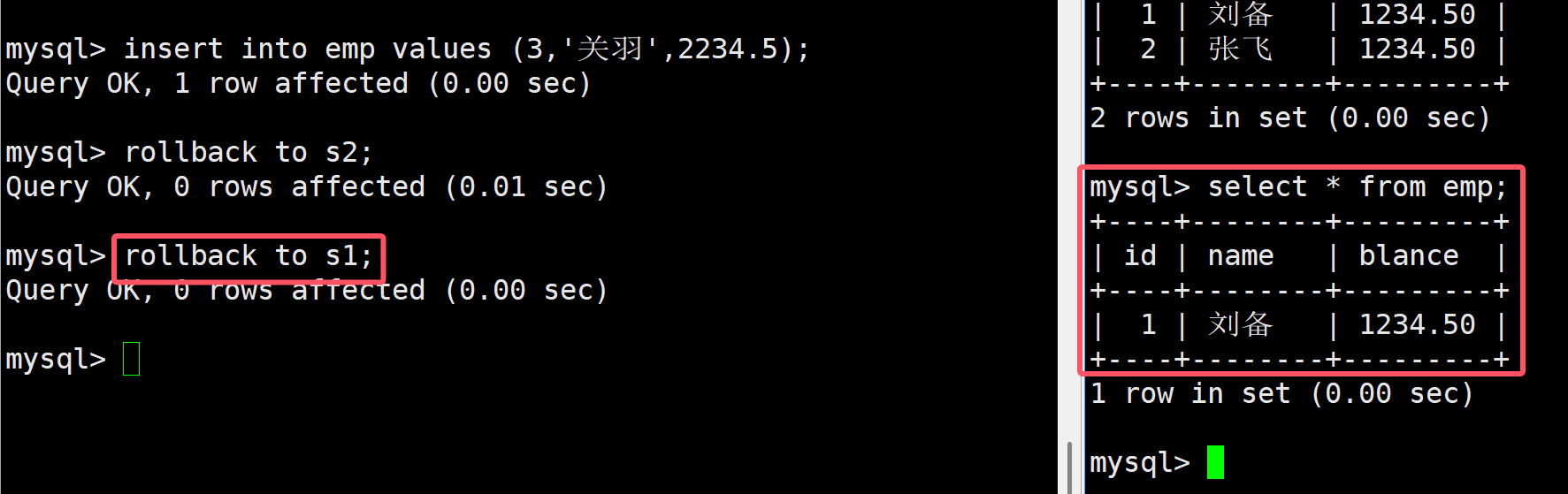
接著我們在進行插入
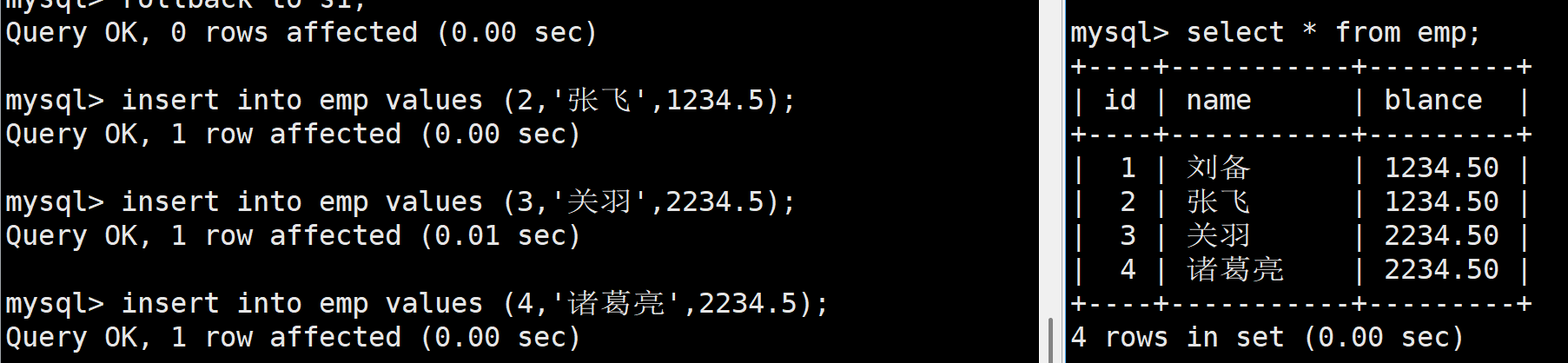
如果想一次性回滾到最開始可以使用rollback,這樣就在右側看不到任何記錄了

接著我們在進行插入數據,這個時候直接commit提交數據,這個時候盡管在進行回滾在右邊仍然能看到數據,此時左邊的事務就是完成了,其修改就是永久了的,這就是事務的持久性,就不能進行事務回滾了
綜上所述:
- 使用begin/start transaction啟動一個事務
- 使用commi提交一個事務
- 使用savepoint設置一個保存點
- 使用rollback to 回到指定一個保存點
- 使用rollback回滾到最開始
四、事務崩潰:
原子性:
首先在員工表中是存在如下信息的,接著啟動一個事務進行測試:
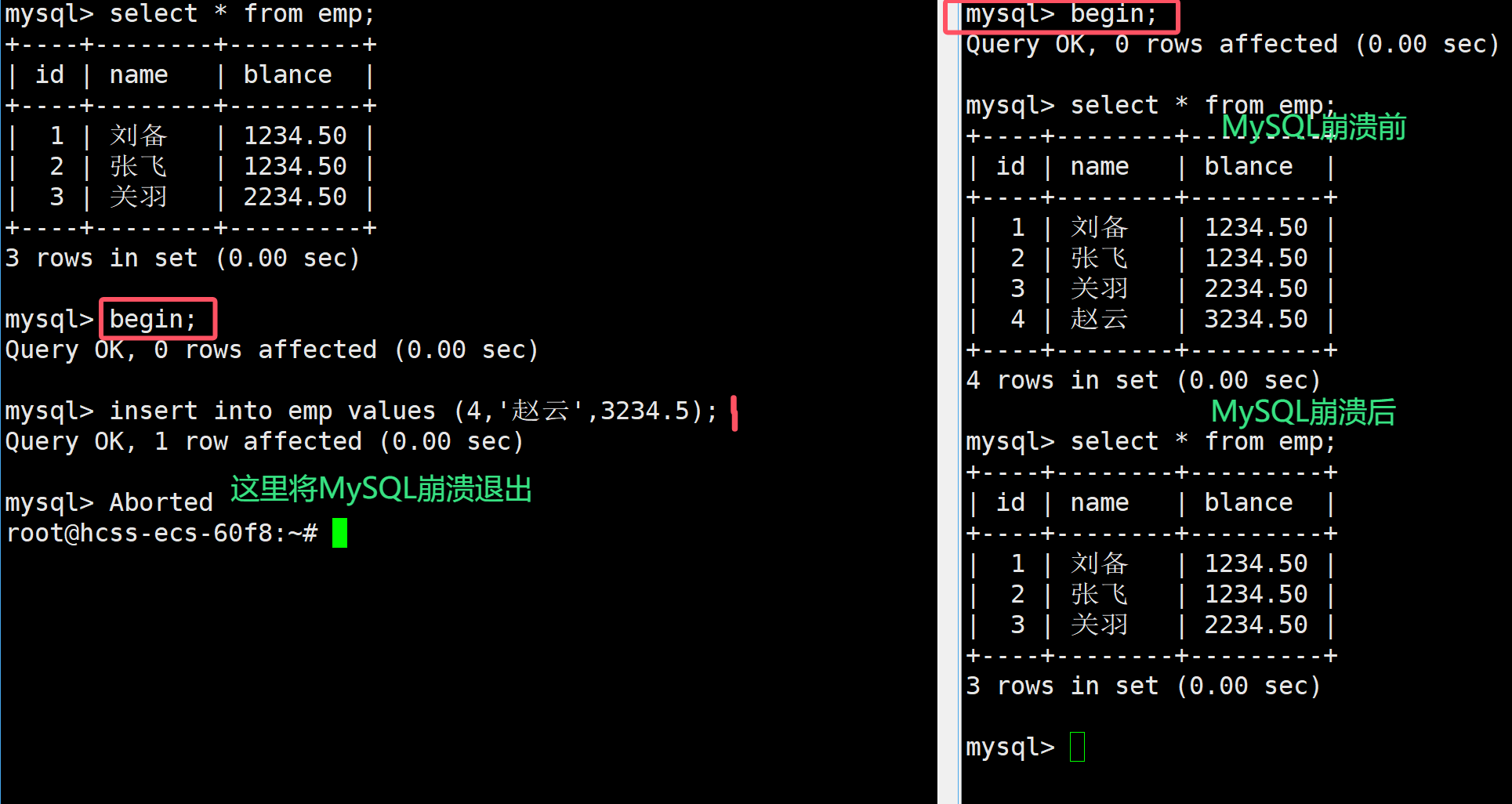
如上,首先在左側事務進行插入一個數據,在右側是能夠看到的,此時是處于讀未提交的隔離性中,但是在左側的MySQL崩潰后,沒有及時的進行commit提交,這個時候會回滾到當前事務的最開始,此時在右側進行查詢就會查詢不到新插入的語句,這也保證了事務的原子性
持久性:
那么如果在事務崩潰前進行commit提交了呢?
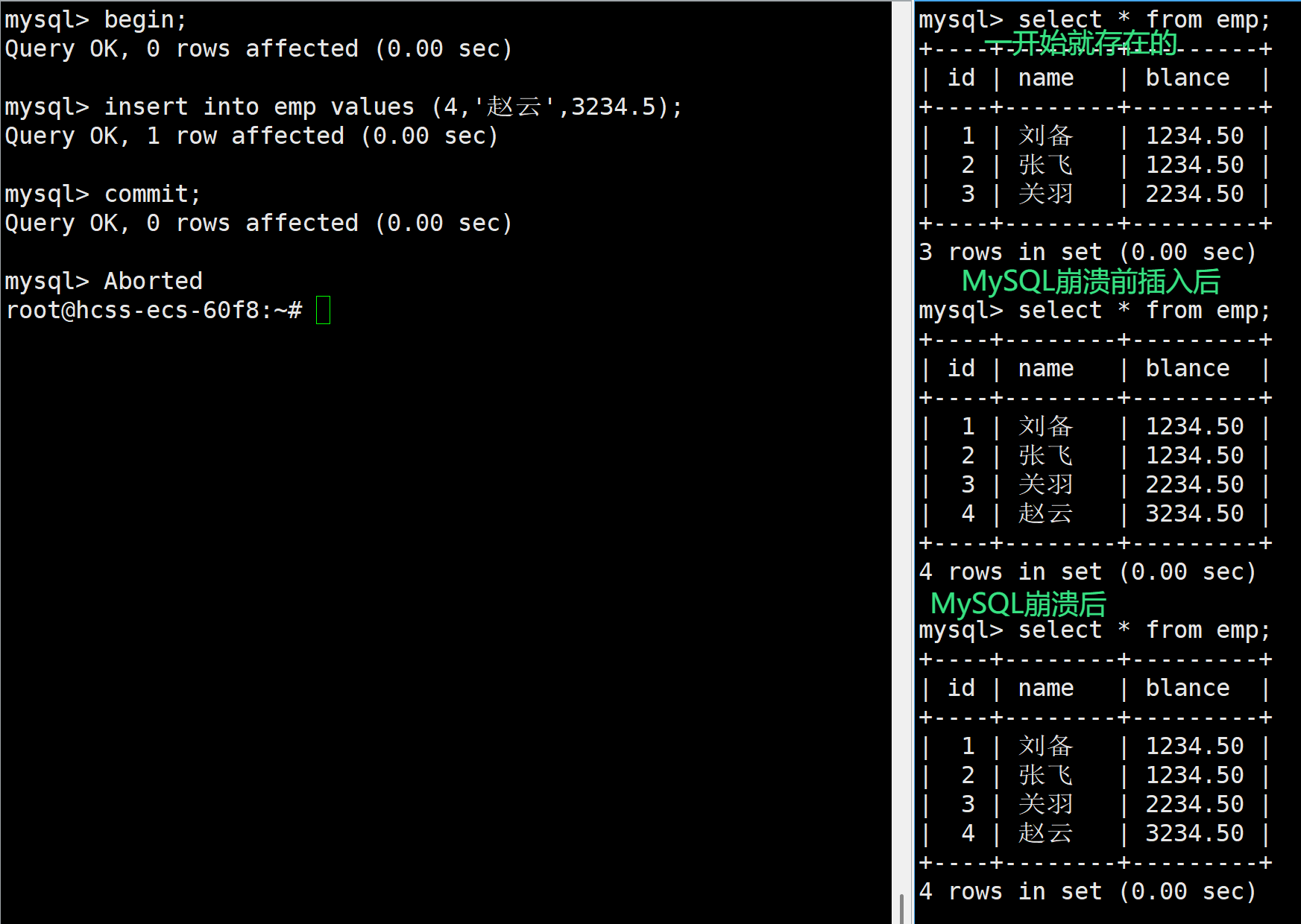
如上,在MySQL崩潰前進行commit提交后,盡管MySQL崩潰了,但是依然能夠看到上一個事務進行插入的數據,這正是因為事務的持久性,如果事務提交后,其修改的數據是永久的
五、自動提交和手動提交:
這里的自動提交和begin的啟動事務是無關的,事務必須使用commit命令進行手動提交,數據才會被持久化
那么自動提交和手動提交有什么區別呢?
首先查看當前事務的提交方式:
show variables like'autocommit';
這是自動提交的,并且此時有著如下的一張表:
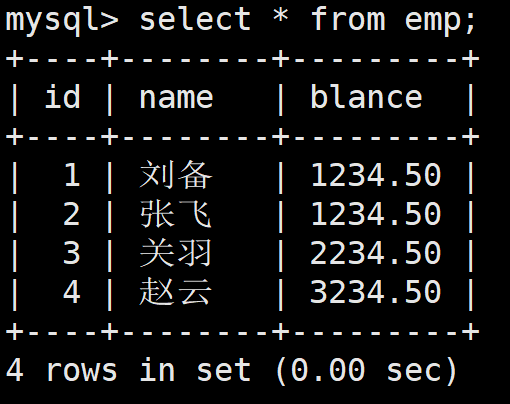
接著在左側進行刪除表中的數據,然后將左側的客戶端崩潰,發現該員工表中的對應數據被刪除了
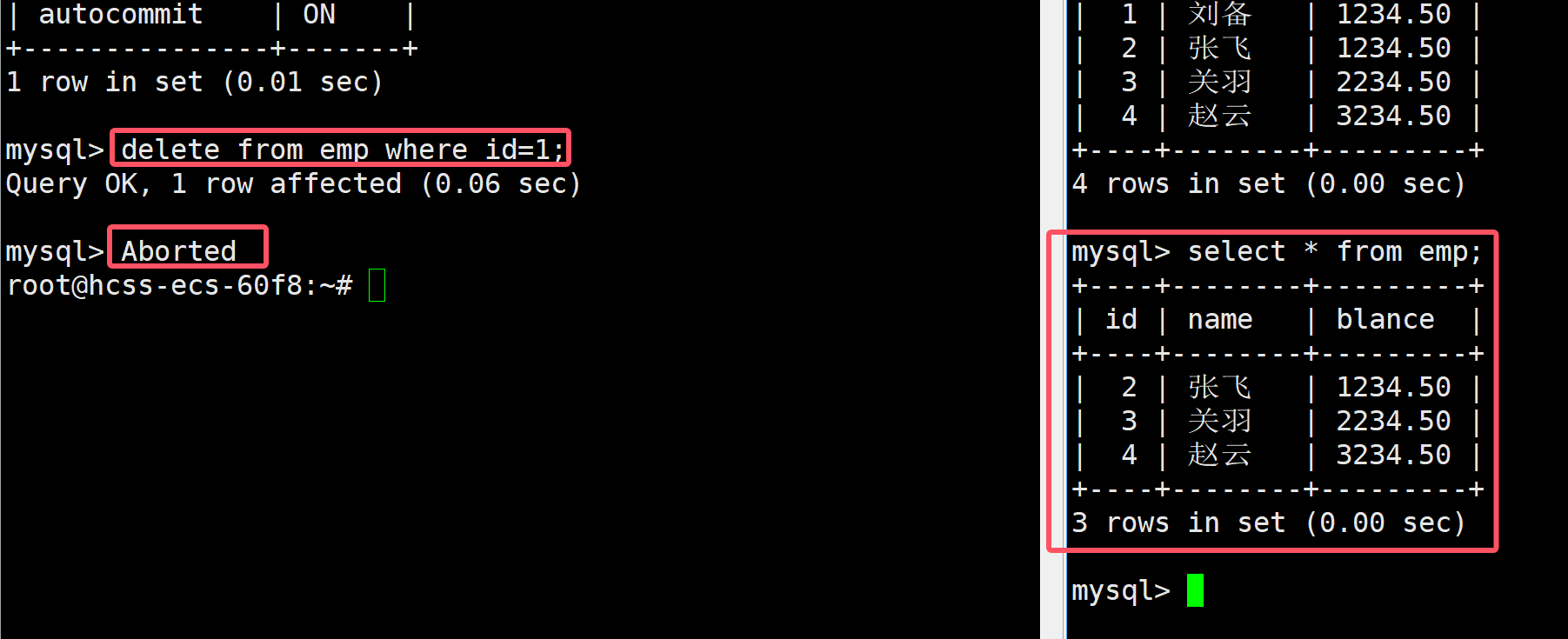
接著僅僅將提交方式改為手動提交,其余動作不變
set autocommit=0;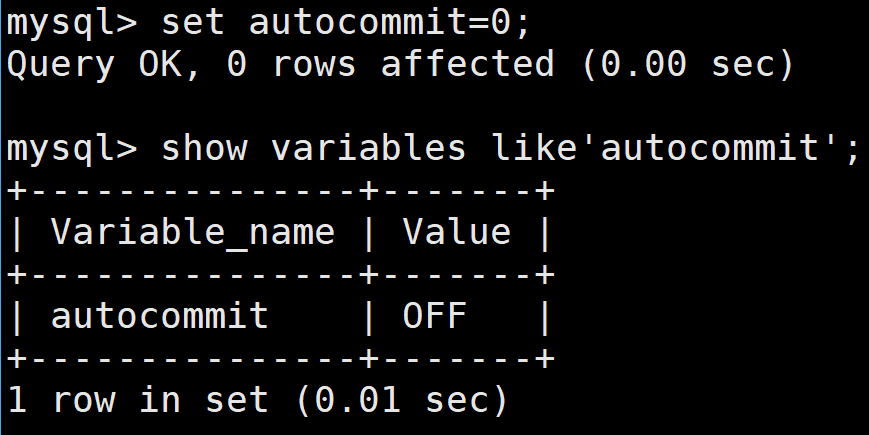
接著在左側進行刪除表中的數據,然后將左側的客戶端崩潰,發現該員工表中的對應數據并沒有被刪除
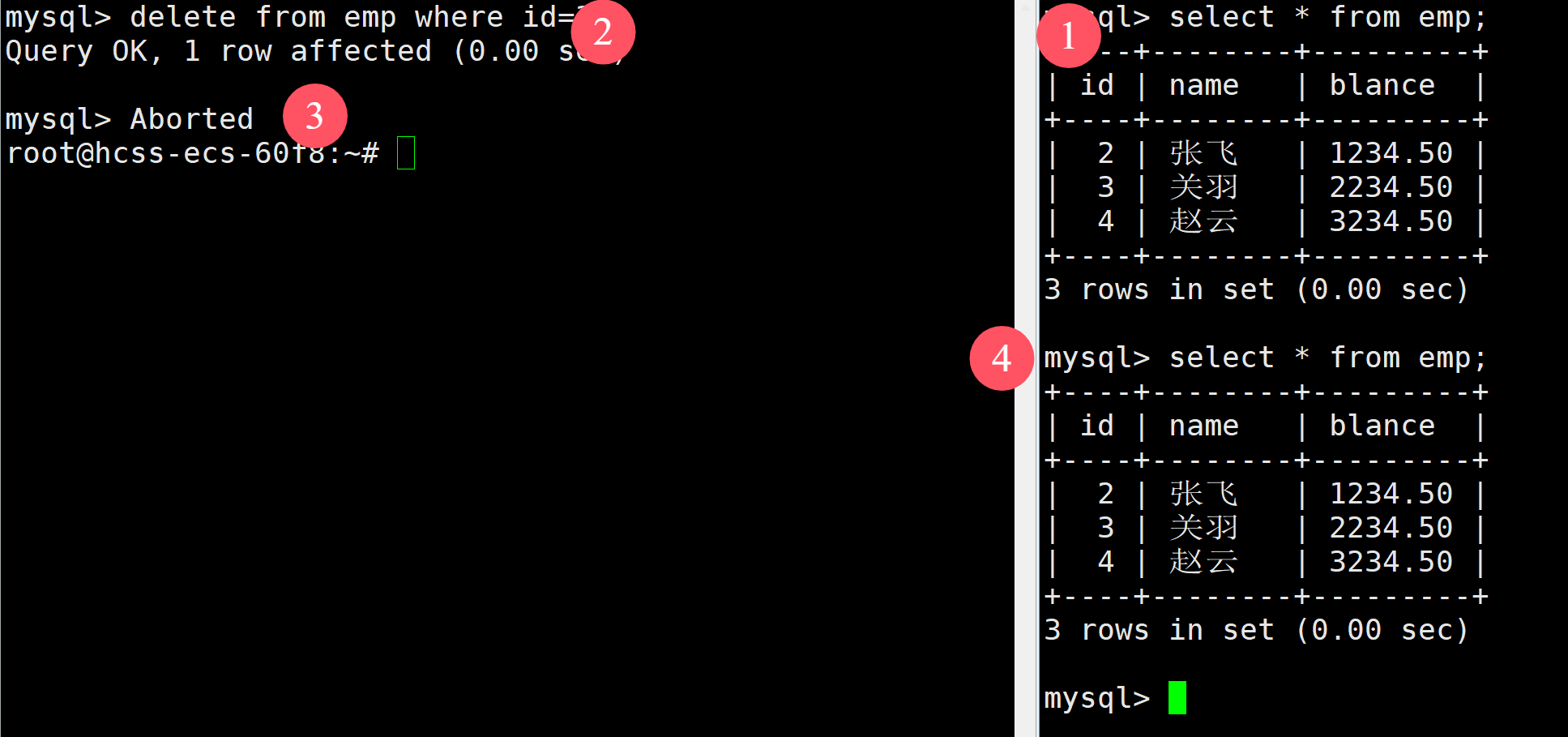
綜上所述:
全局變量autocommit影響的是單SQL語句,在InnoDB中,一條SQL語句會被封裝成一個事務,這個事務就需要根據autocommit的大小來進行自動提交或者手動提交
六、事務的隔離性:
怎么理解:
MySQL在啟動后,可能會被多個客戶(進程或者線程)進行訪問,都是以事務為單位進行訪問的,一個事務又是由多條SQL語句組成的,那么這些SQL語句在執行的時候可能會訪問同一張表,那么MySQL為了保證在執行的過程中一個事務不被其他事務所干擾,于是就有了事務的隔離性,與隔離級別
隔離級別有以下四種:
READ UNCOMMITTED(讀未提交):讀到了別人未提交的數據,在這個級別下,事務中的修改,即使沒有提交,對其他事務也是可見的,這個級別會導致臟讀,即一個事務可以讀取到另一個事務未提交的數據
READ COMMITTED(提交讀):讀別人提交了的數據,在這個級別下,一個事務只能看見已經提交事務所做的修改,這可以防止臟讀,但是仍然可能發生不可重復讀,不可重復讀是指在同一個事務中,多次讀取同一數據集合時,由于其他事務的介入,導致前后兩次讀取結果不一致
REPEATABLE READ(可重復讀):無論別的事務是否提交修改后的數據,只有當前事務也提交后才能夠看到之前別的事務所修改的數據,這是MySQL的默認事務隔離級別。在這個級別下,保證在同一個事務中多次讀取同樣記錄的結果是一致的,因此解決了不可重復讀的問題。但是,仍可以發生幻讀,即當某個事務在處理某個范圍內的記錄時,另一個事務插入了新的記錄,導致原本的查詢結果集發生了變化
SERIALIZABLE(可串行化):這是最高的隔離級別,所有CURD必須按照到來的順序一個一個執行,在SERIALIZABLE級別下,事務的執行會通過鎖定參與事務的所有數據來實現,從而完全避免臟讀,不可重復讀以及幻讀的問題,這意味著事務的執行會像順序執行一樣,一個接一個地串行化執行,從而保證了數據的一致性,但是,這種級別的性能開銷最大,因為它需要對所有相關的數據行加鎖
隔離級別示例:
隔離級別在MySQL中的表現有兩種,分別是全局隔離級別和會話隔離級別
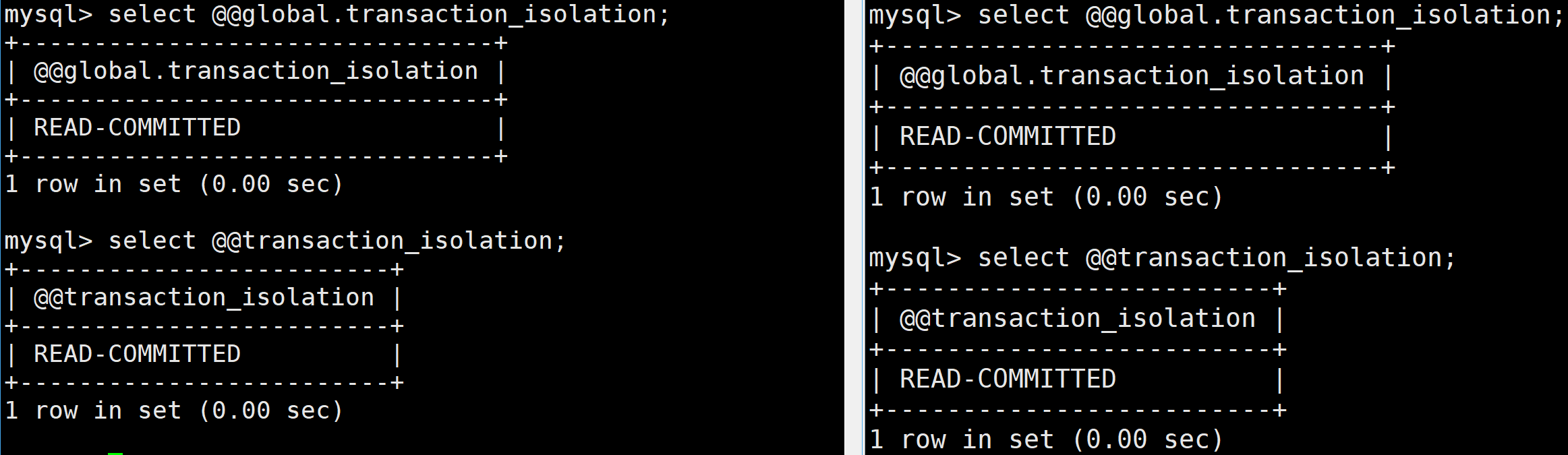
查看全局隔離級別:
查詢全局事務隔離級別,即MySQL服務啟動后所有新會話的默認隔離級別
select @@global.transaction_isolation;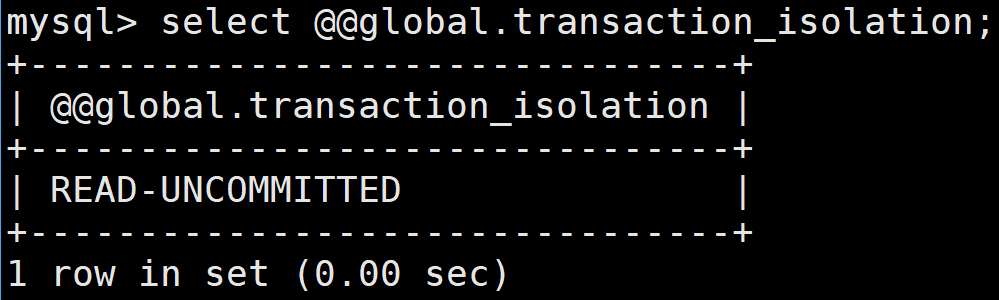
查看會話隔離級別:
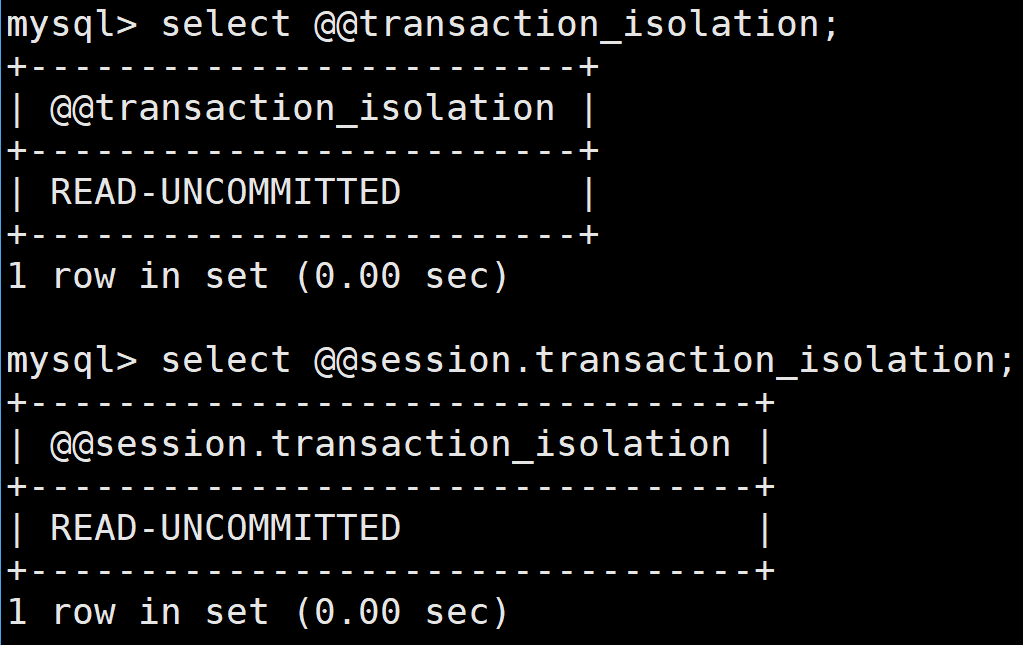
select @@transaction_isolation;
// 或者
select @@session.transaction_isolation;查詢當前會話的事務隔離級別,若會話未主動修改過隔離級別,則繼承全局值
設置隔離級別:
set [session | global] transaction isolation level {read uncommitted | read committed | repeatable read | serializable}如上,其中session表示設置會話隔離級別,global表示設置全局隔離級別
后面的{ }中,在四個中選一個作為設置后的隔離級別
注意:
- 設置會話的隔離級別只會影響當前會話,新起的會話依舊采用全局隔離級
- 設置全局隔離級別會影響后續的新會話,但當前會話的隔離級別沒有發生變化,如果要讓當前會話的隔離級別也改變,則需要重啟MySQL
讀未提交:
如下兩個終端中,均是讀未提交,并且有如下數據的員工表
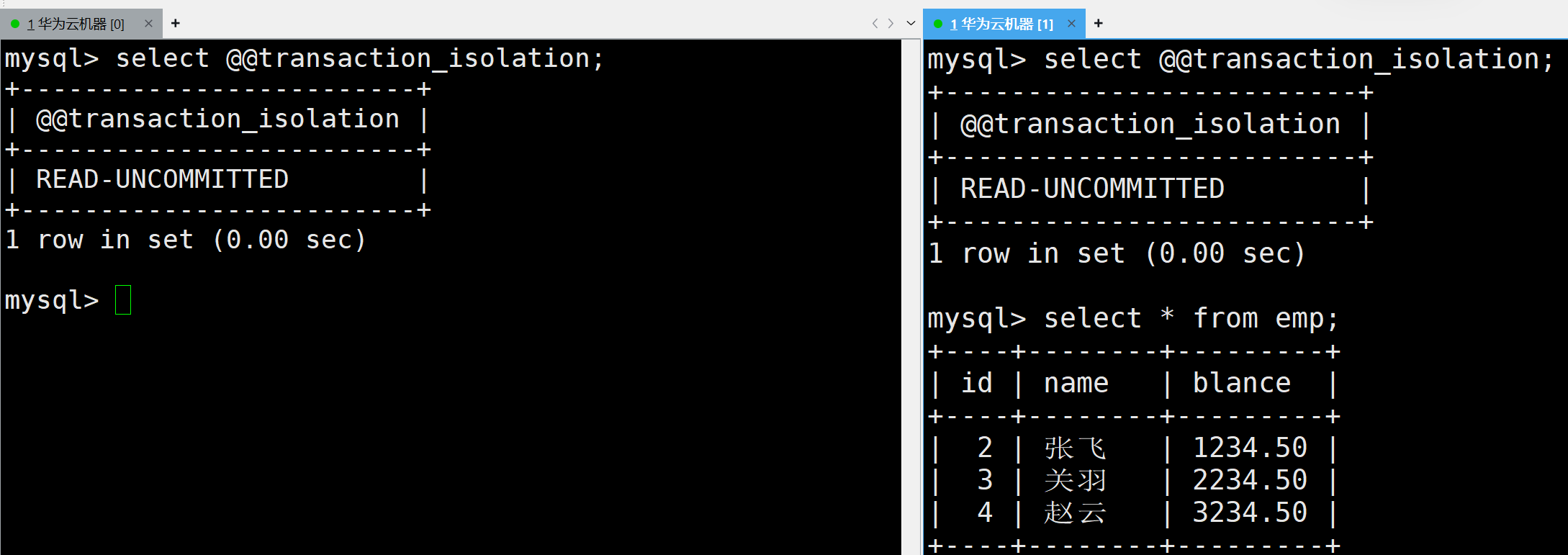
那么在左右兩邊開啟事務,并且先進行插入一條數據,并沒有進行提交,在右邊是能夠看到的,這就是讀到了別的事務未提交的數據,這種情況叫做臟讀,是不合理的
并且此時rollback回滾后發現所讀到的數據也回滾了
讀提交:
先將隔離級別修改為讀提交
接著做和上一個步驟一樣的,觀察結果:
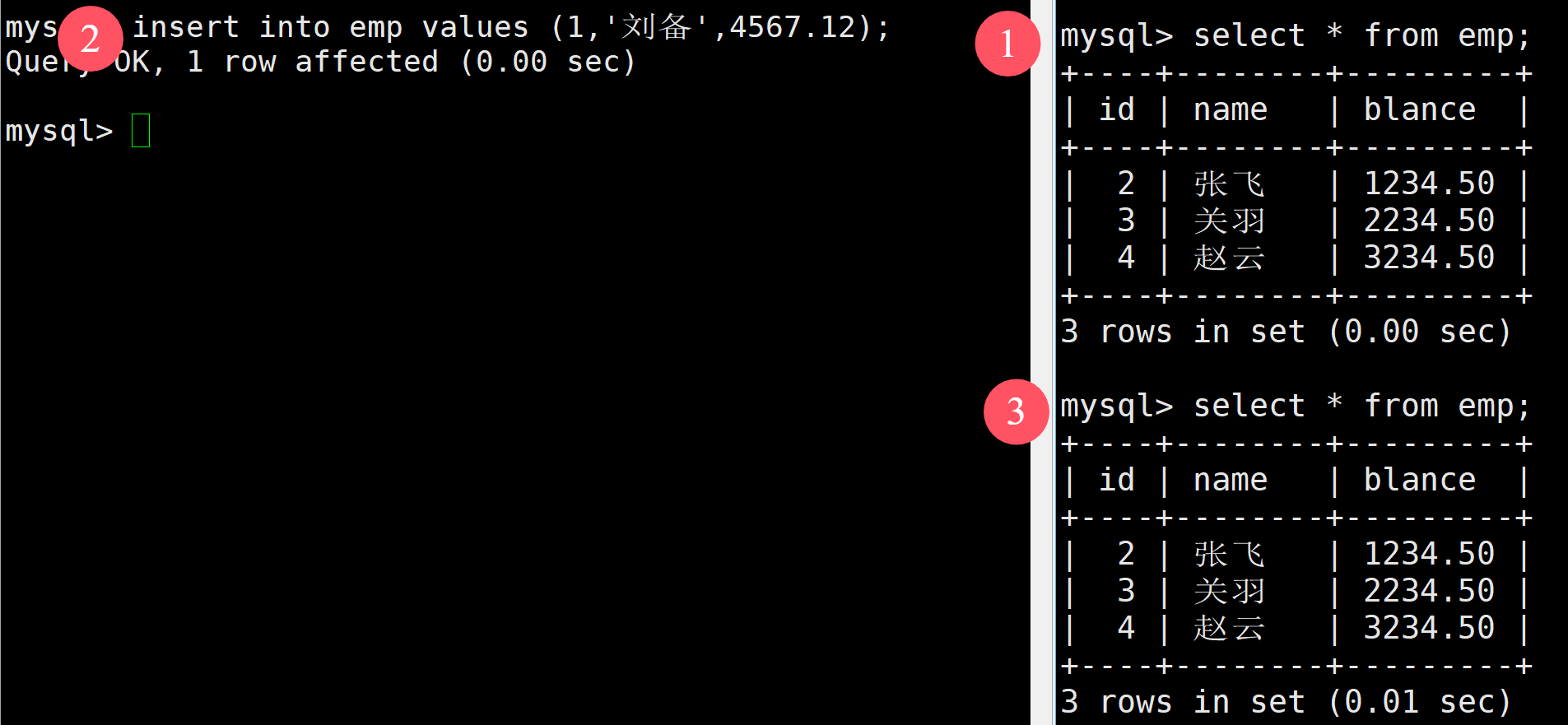
如上,當進行插入后,發現在右邊并未查到,但是像下面那樣,將左邊的事務提交后,發現此時就能夠看到了
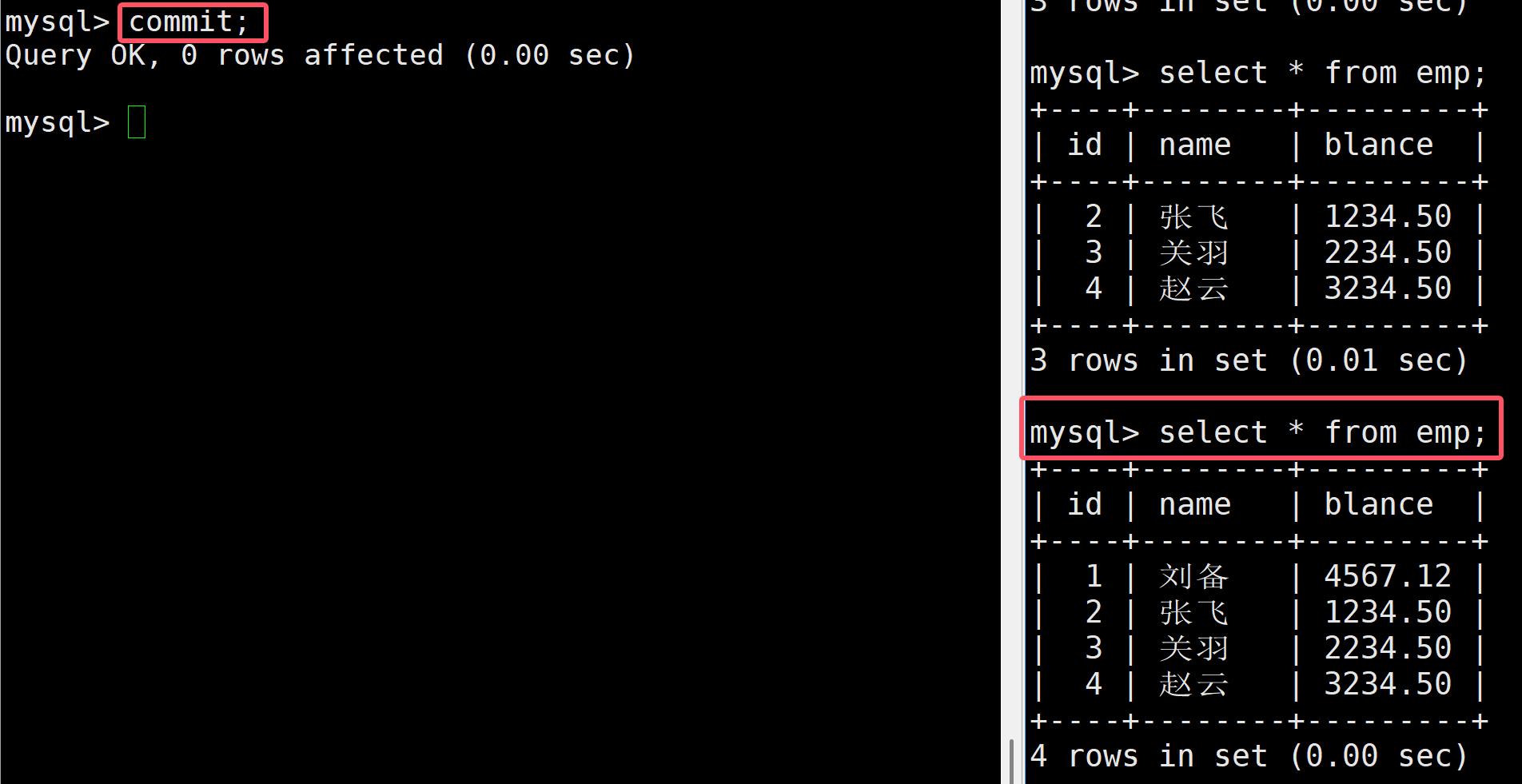
這就是讀別人提交后的數據,這就解決了臟讀的問題,但是又出現了不可重復讀的問題,也就是右邊在一直查詢,這樣會在某個查詢前后出現查詢不一致問題,這就導致了右邊的事務不可重復讀
在實際應用中,這個不可重復讀會存在問題的,比如在一個公司中發年終獎前后,如果一個員工在統計工資區間中,另一個員工突然又經過老板同意給公司的某個員工加上薪資,此時就可能會存在同一個員工在獎品區間中出現兩次,這是不合理的
所以這個不可重復讀,在實際應用中會存在問題的
可重復讀:
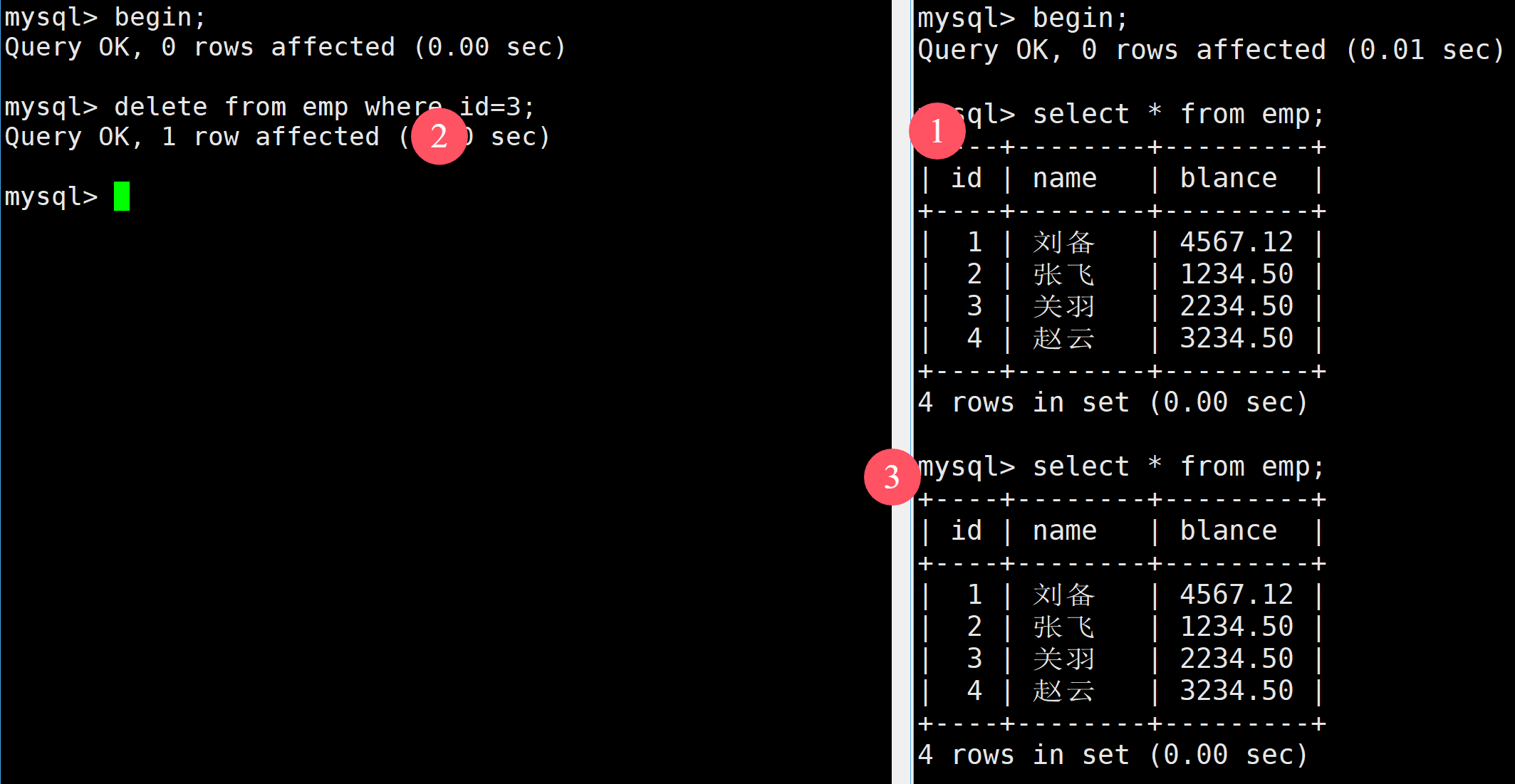
首先將隔離級別修改為可重復度
接著啟動事務,然后在左邊進行表的修改,當執行完后在右邊再次進行查看,發現右邊沒有被修改
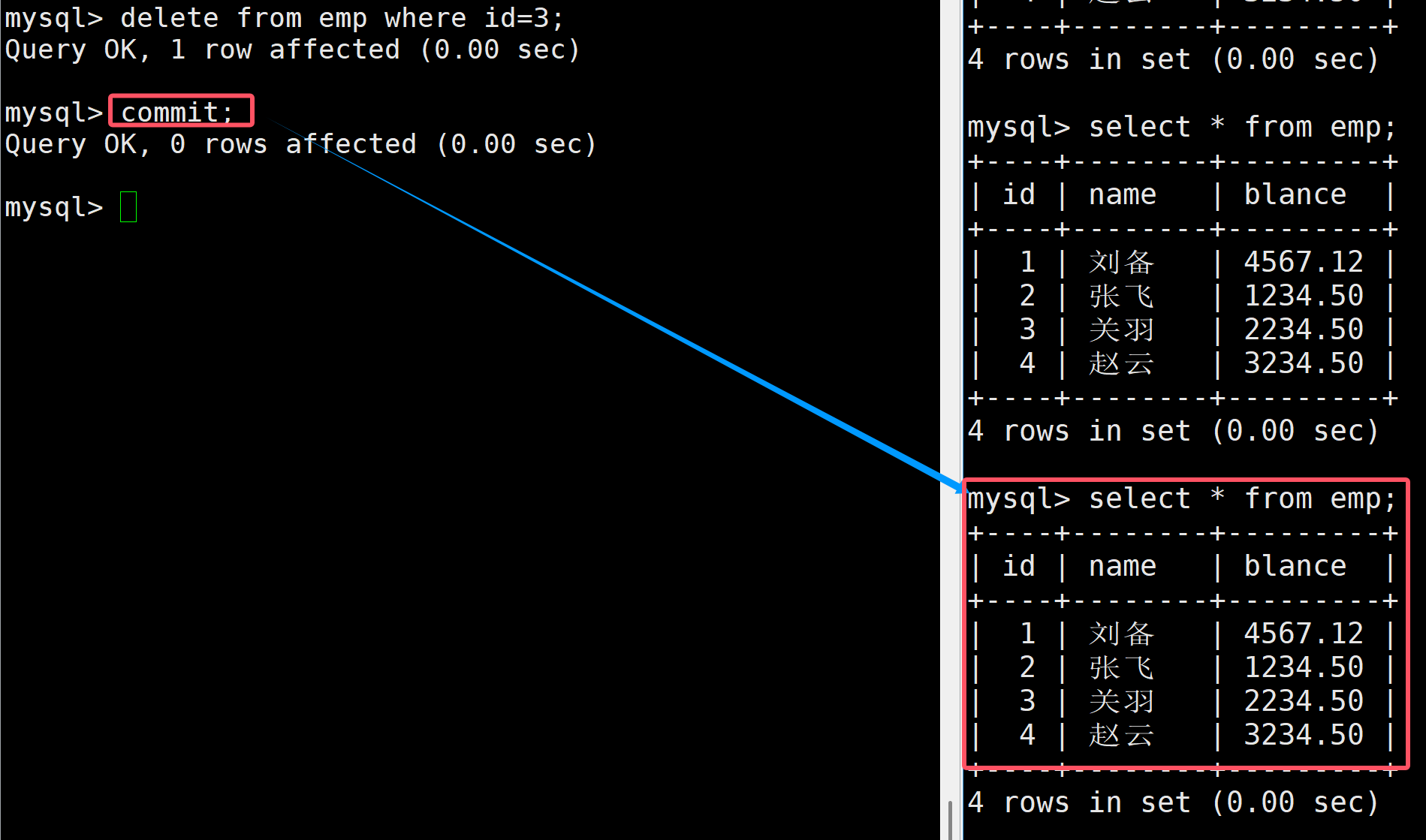
接著將左邊的事務進行提交,此時在進行查看發現右邊的表依然沒有被修改
最后將右邊的事務也提交了,此時在進行查詢就能夠看得見了
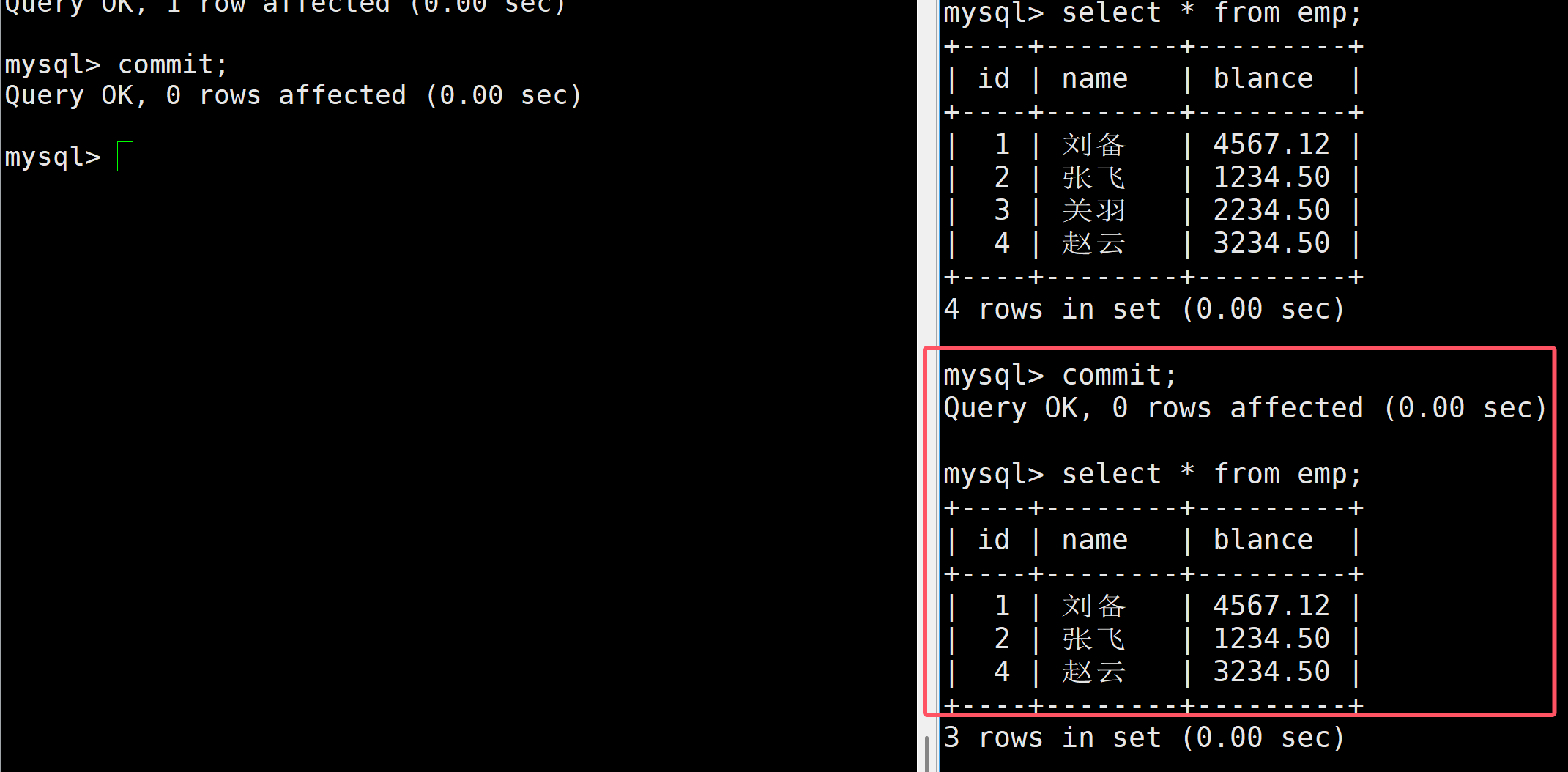
像上邊這種,在一個事務中,一直進行查詢讀,盡管別的事務對同一張表后進行修改,此時依然是看不到這個修改的,直到當前事務也被提交后才能進行看到,也就是說,在可重復讀的條件下,在一個事務中進行查詢的結果總是一致的
這種隔離級別是MySQL默認的,也是最常使用的
一般的數據庫在可重復讀隔離級別下,update數據是滿足可重復讀的,但insert數據會存在幻讀問題,因為隔離性是通過對數據加鎖完成的,而新插入的數據原本是不存在的,因此一般的加鎖無法屏蔽這類問題,但是在MySQL中是解決了這類問題的
幻讀:一個事務在執行過程中,相同的select查詢得到了新的數據,這種現象叫做幻讀
串行化:
首先依然是將隔離級別修改為串行化:
然后啟動事務,然后在兩邊都進行查操作,發現都能夠進行查看
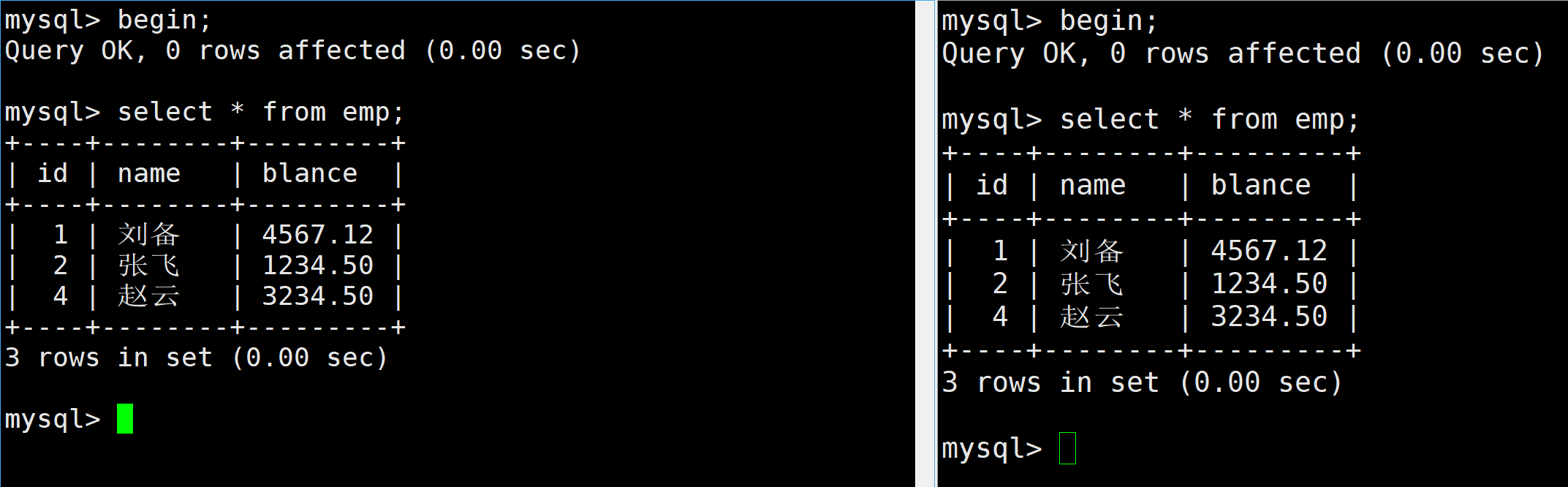
但是此時如果有一方進行修改表的操作,會被阻塞

如果長時間沒有響應就會報錯,如果在阻塞中,另一個事務提交了,此時就不會阻塞了
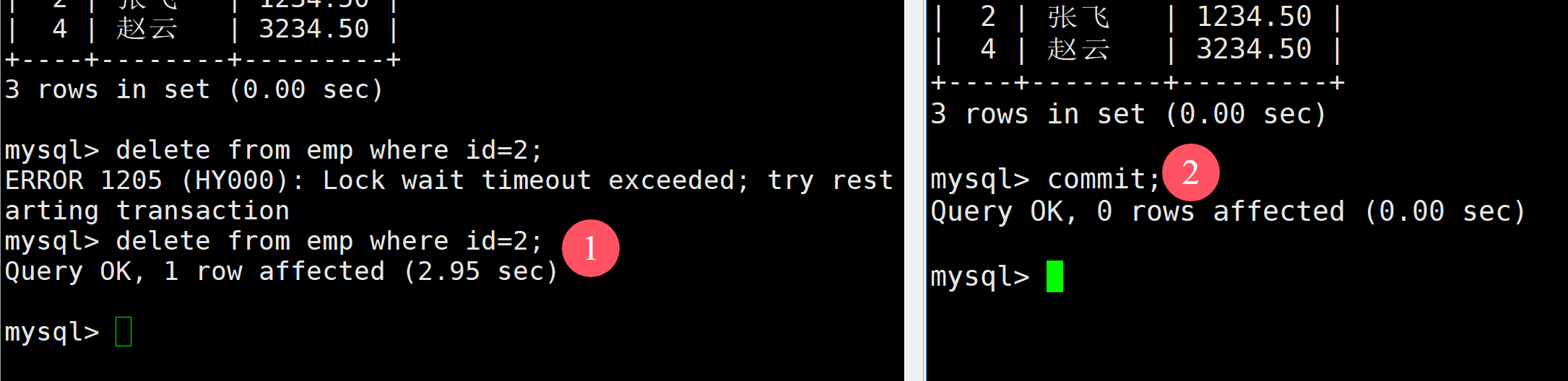
但是兩邊查詢的結果不一樣,直到左邊的事務也提交
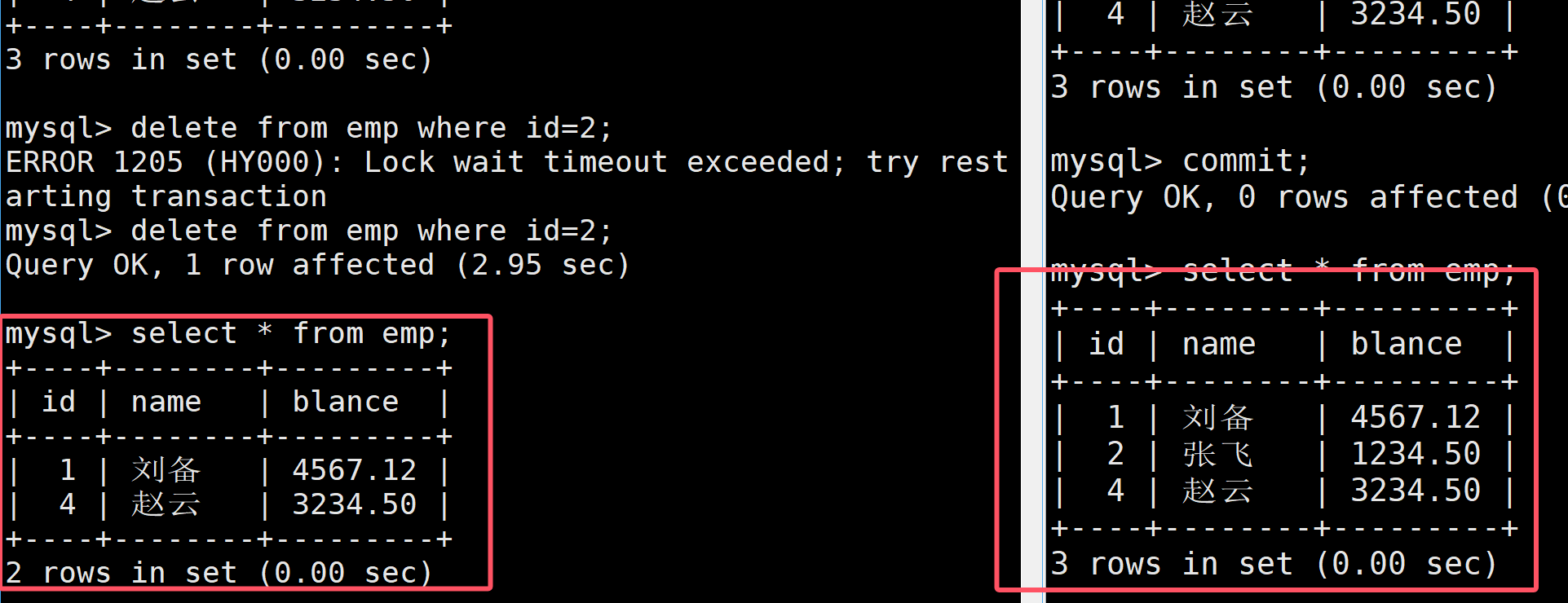

對于串行化,其效率非常低,在開發中幾乎不會使用
對于隔離級別:隔離級別越嚴格,安全性越高,但數據庫的并發性能也就越低,在選擇隔離級別時往往需要在兩者之間找一個平衡點
七、拓展知識:
數據庫的并發場景:
- 讀-讀并發:不存在任何問題,不需要并發控制
- 讀-寫并發:有線程安全問題,可能會存在事務隔離性問題,可能遇到臟讀 幻讀 不可重復讀
- 寫-寫并發:有線程安全問題,可能存在更新丟失問題,第一類更新丟失,第二類更新丟失
這里最值得討論的是讀-寫并發,讀-寫并發是數據庫當中最高頻的場景,在解決讀-寫并發時不僅需要考慮線程安全問題,還需要考慮并發的性能問題
接下來要了解事務的隔離是怎么做到的,RC和RR的底層區別在哪?事務回滾又是怎么做到的,接下來需要知道些前置知識:
當一個事務啟動的時候,MySQL會為其設置事務ID,每個事務都要有自己的事務ID,可以根據事務的大小,來決定事務到來的先后順序
mysqld可能會面臨處理多個事務的情況,事務也有自己的生命周期,mysqld要對事務進行管理,先描述,再組織,所以事務在mysqld中一定是對應的一個或者一套結構體對象
三個隱藏字段:
MySQL在給我們建表的時候,除了我們在SQL語句中自主創建的字段,還會有三個默認隱藏的字段的
DB_TRX_ID :6 byte,表示最后一次對這個表進行操作的事務ID
DB_ROLL_PTR : 7 byte,在MySQL中,進行修改數據并不是簡簡單單的修改就行了,還需要將這個數據進行保存,這樣在進行事務回滾的時候能夠找到歷史數據,這就是指向上一個版本的指針
DB_ROW_ID : 6 byte,隱含的自增ID(隱藏主鍵),如果數據表沒有主鍵, InnoDB 會自動以DB_ROW_ID 產生一個聚簇索引
undo日志:
這是回滾日志,用于對已經執行的操作進行回滾,MySQL會為undo日志開辟對應的緩沖區,用于存儲日志相關的信息,必要時會將緩沖區中的數據刷新到磁盤
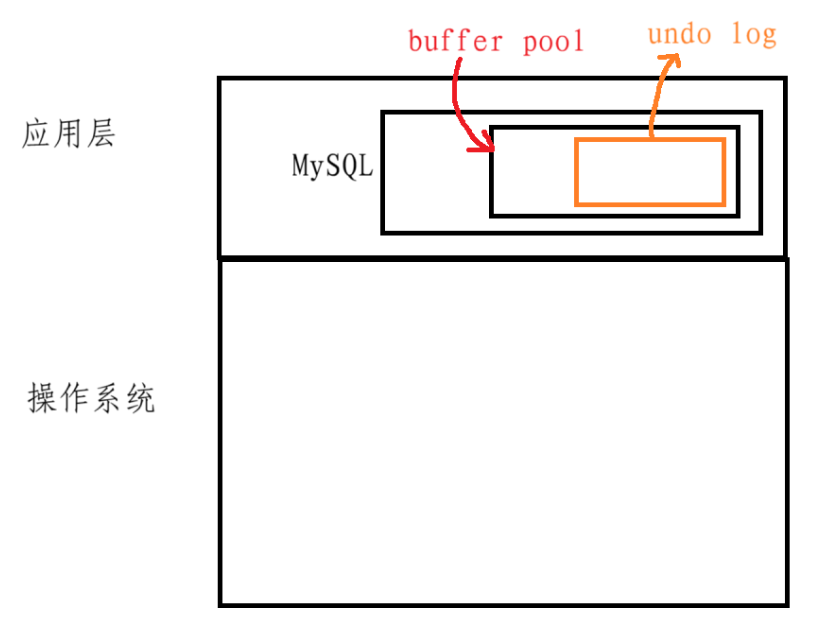
關于上圖,操作系統之上是應用層,然后在應用層上的MySQL中有一個buffer pool空間,在這個空間里面就有我們的undo日志
事實上,undo log就是MySQL中的一段緩沖區,用來記錄MySQL中事務回滾的操作的
MVCC多版本控制:
首先我們有如下一串數據
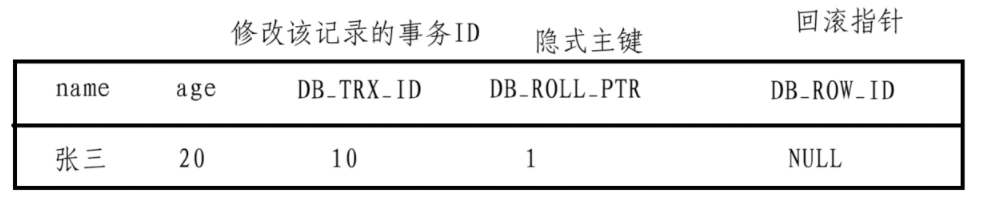
這串數據我們創建之后,就是在B+樹中的葉子結點中的,我們又知道這個葉子節點是被加載到buffer pool中的,此時后來的一個事務到來,將該數據的age修改為18
這個時候不是簡單的修改,
1、要先對訪問這條記錄進行加鎖,
2、將這個原本的記錄復制一份到undo log中,
3、將表中的數據進行修改,將age改為18,
4、此時盡管是只修改了一個字段,但是后面隱藏的字段中修改該記錄的事務ID也要被修改為新到來的事務ID,這里假設為11,并且回滾指針也不在指向空,要指向undo log中被復制的原本數據
5、最后提交事務,釋放鎖即可
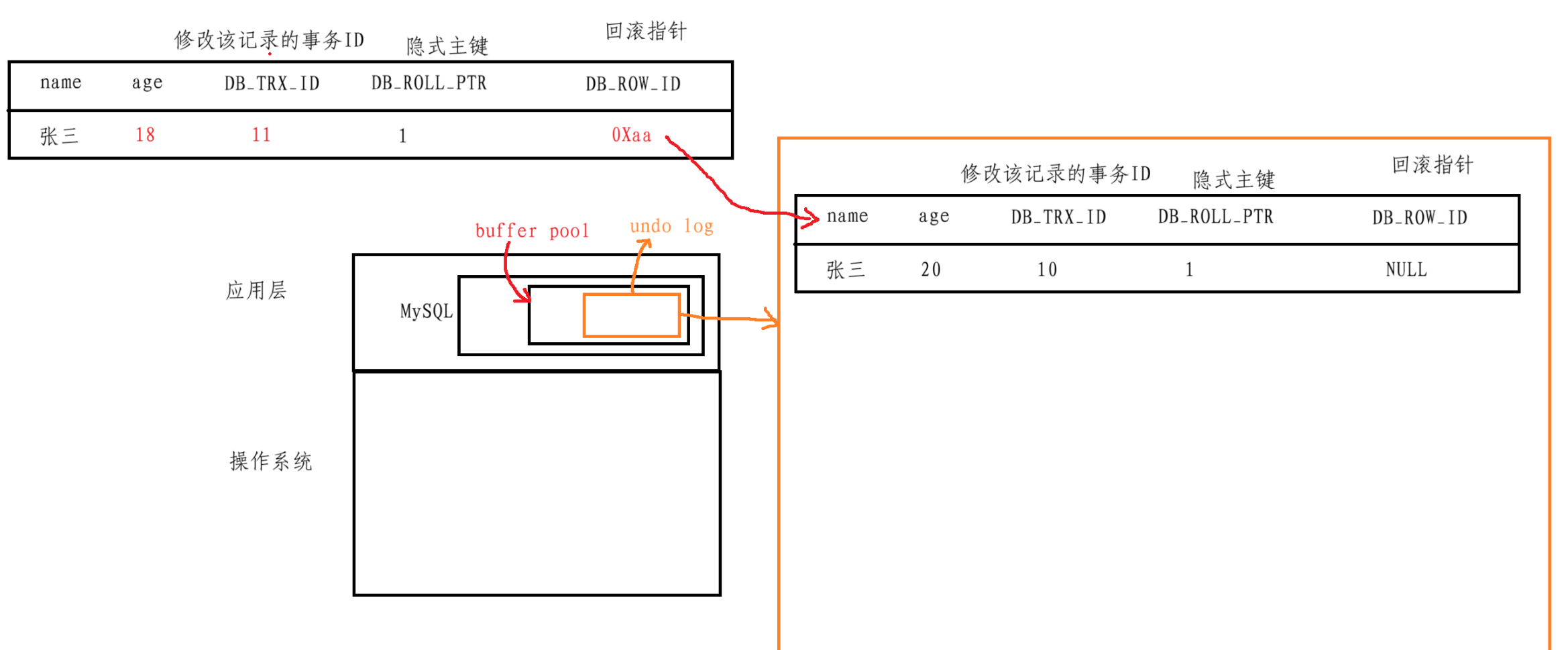
同樣的道理,又來了一個事務,將name改為李四
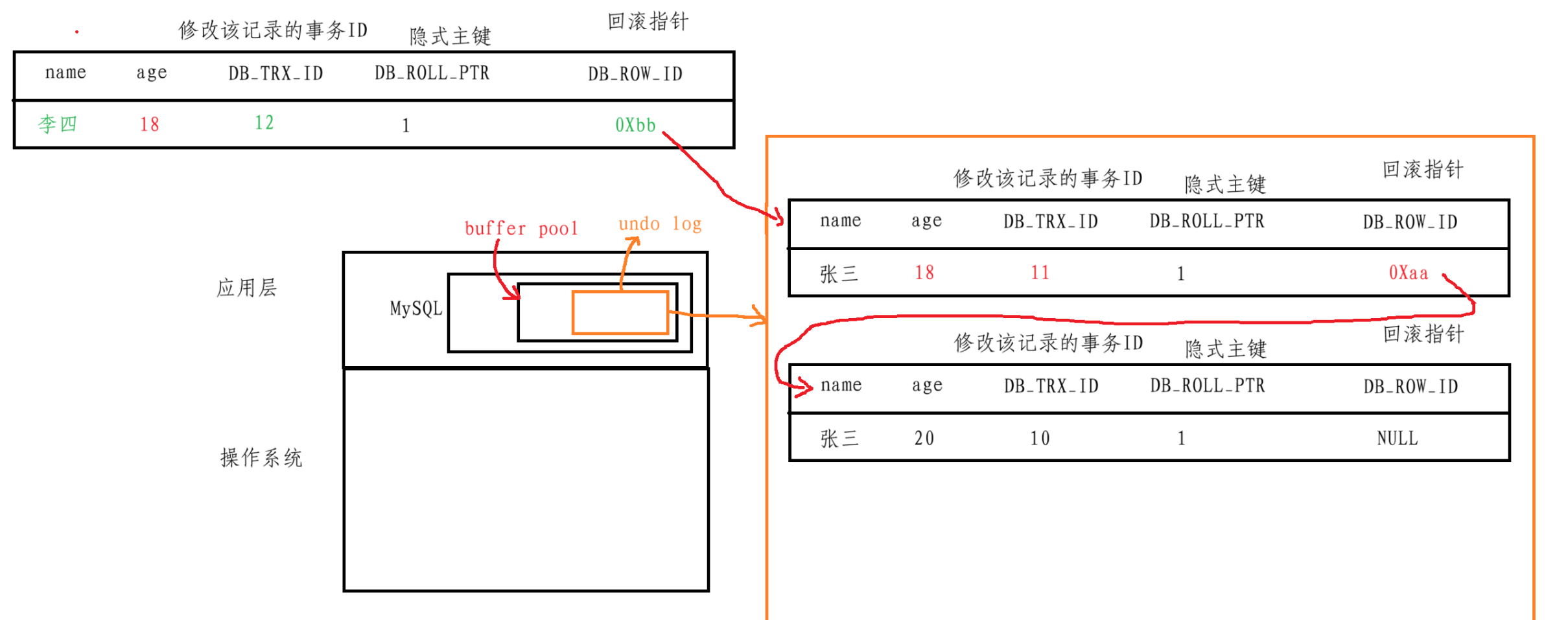
這樣,這些歷史數據就像鏈表一樣串起來,就有了一個版本鏈,當進行事務回滾的時候,需要回滾到哪個版本,就能夠通過這個版本鏈找到對應的版本了,直接找到版本后覆蓋當前數據即可,所謂的創建保存點就可以理解為給某些版本做標記,方便查找回滾
這種多版本控制就叫做MVCC多版本控制,并且在undo log中的一個個的歷史版本就稱為一個個的快照
周邊問題:
那么上述都是修改才有的版本鏈,那么Delete和INSERT呢?
Delete的數據也會形成版本鏈的,在MySQL中Delete刪除不是真的刪了,本質是通過修改數據中的某個比特位將其置為刪除,此時就相當于將這行數據進行刪除了,如果回滾就是將表示存在還是不存在的比特位修改即可,這樣是能夠形成版本鏈的
INSERT操作本身不會形成版本鏈,但它為后續的UPDATE或DELETE操作提供了初始版本,版本鏈的形成必須依賴對同一行的多次修改,因此,INSERT是版本鏈的起點,但非版本鏈本身
當前讀與快照讀
當前讀:讀取最新的記錄,就是當前讀,增刪改,都叫做當前讀,select也可能當前讀
快照讀:讀取歷史版本,就叫做快照讀
對數據進行CURD的時候的加鎖問題
當對表進行CURD的時候,此時有兩種情況,一個是對當前數據進行修改,一個是對歷史數據進行修改,當對當前數據進行修改的時候,可能是CURD中的任意一種情況,此時就需要進行加鎖保護,但是對歷史數據修改的時候只可能是select,為快照讀,就不需要加鎖,畢竟歷史版本不會被修改,也就是可能并發執行,提高效率
undo log中的版本鏈何時才會被清除?
unod log存在的意義是進行回滾操作和進行快照讀,所以當事務提交后,且所有依賴該版本的事務已完成此時才會將undo log中的版本鏈清除
read view:
當我們某個事務執行快照讀的時候,會對該記錄創建一個Read View讀視圖,記錄并維護系統當前活躍事務的ID,read view是一個類,與事務的關系就類似于進程地址空間和PCB,根據這個Read View來判斷,當前事務能夠看到該記錄的哪個版本的數據
Read View是一個數據結構,記錄當前事務執行一致性讀時的可見性上下文,它決定了哪些數據版本對當前事務是可見的,從而避免臟讀,不可重復讀等問題
Read View主要由下述字段組成
| 字段名 | 含義說明 |
|---|---|
creator_trx_id | 創建該Read View的事務ID(即當前事務ID) |
up_limit_id | 最小活躍事務ID(即當前系統中最小的未提交事務ID) |
low_limit_id | 當前系統最大事務ID + 1(即系統中尚未分配的事務ID) |
m_ids | 當前系統中所有活躍事務(未提交事務)的ID列表 |
m_low_limit_no | 最小的Undo Log編號(用于InnoDB的Purge機制) |
注意:
Read View是事務可見性的一個類,不是事務創建出來,就會有Read View,而是當這個已經存在的事務首次進行快照讀的時候,MySQL形成的Read View
事務ID是依次增大的
當進行一次快照讀的時候,此時可以將事務ID分為三種情況
事務ID小于up_limit_id,up_limit_id已經是當前系統中最小的未提交事務ID,如果事務ID比它還要小就證明此刻生成Read View時,該事務一定是提交了的
事務ID大于low_limit_id,low_limit_id是系統中尚未分配的事務ID,所以當事務ID大于low_limit_id時,該事務是生成Read View時還未啟動的事務ID
事務ID在這兩者之間,這些事務就需要通過判斷m_ids來進行判斷是否提交,注意:這里的快照事務ID不一定是連續的,畢竟事務的時間長短是不一樣的,有可能提前啟動的事務,結束得晚,后啟動的事務結束得早或晚都有可能
一個事務在進行讀操作時,只應該看到自己或已經提交的事務所作的修改,因此我們可以根據Read View來判斷當前事務能否看到另一個事務所作的修改
?RC VS RR:
關于RC和RR,他們本質區別就是:
RC在每一次查詢的時候都會生成一次Read View,每次select都是快照讀,因此每次快照讀時都能讀取到被提交了的最新的數據
RR只有在第一次select的時候才會生成一次Read View,之后的select都用這個Read View,因此當前事務看不到第一次快照讀之后其他事務所作的修改
RR級別下快照讀只會創建一次Read View,所以RR級別是可重復讀的,而RC級別下每次快照讀都會創建新的Read View,所以RC級別是不可重復讀的
接下來通過兩個實驗理解理解:
首先將事務隔離級別設置成可重復度
在第一個實驗中,我們先讓二者都進行快照讀,然后在左邊進行修改提交,再在右邊進行查看
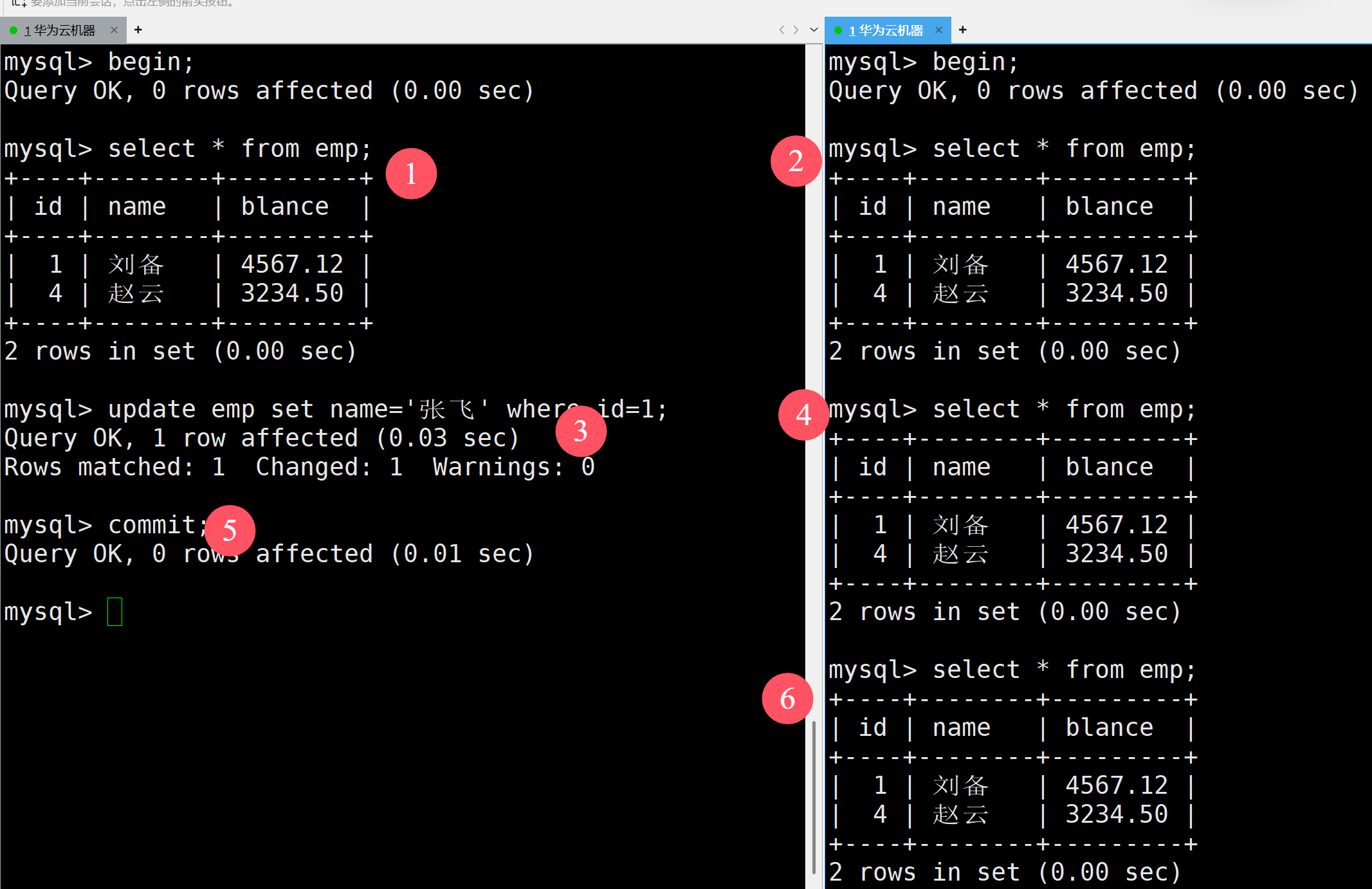
如上,無論怎么進行查看都是看不見修改的,這也符合可重復讀的特性
在第二個實驗中,我們先在左邊進行修改提交,再在右邊進行查看
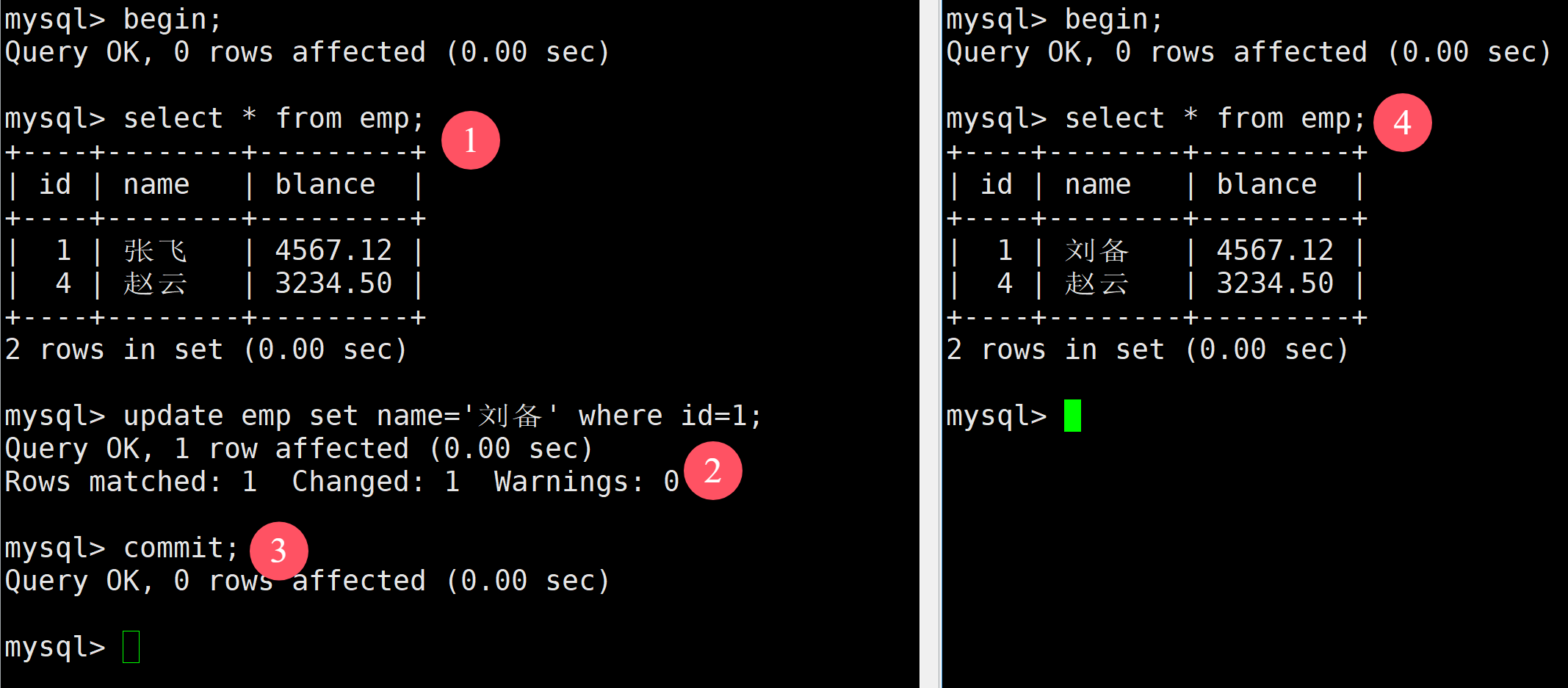
這時發現右邊能夠查看到左邊的修改了
為什么呢?
實驗一中,在最開始就進行了快照讀,此時左右都屬于活躍事務,都是在中間的,那么無論左邊怎么修改,右邊的都看不到
實驗二中,左邊先進行修改后提交,右邊在進行快照讀,此時左邊的事務ID就小于最小活躍事務ID,右邊事務中快照讀生成的Read View中的m_ids就一定沒有左邊的事務ID,此時左邊的事務ID就比右邊事務的up_limit_id還要小,或者是在up_limit_id和low_limit_id之間但是沒在m_ids里面,無論那種情況都能夠被右邊的事務所看到
那么RC呢?
RC和RR的本質區別就在于RC在每次進行快照讀的時候,都是生成新的快照了,那么low_limit_id就是當前系統下最大的事務ID,所以就能保證只要其他事務commit了, 其他事務就不是活躍事務了, 那么就只剩下了在up_limit_id和low_limit_id之間但是沒在m_ids里面這種情況,也就一定能看到了別的事務的修改了














)



)
