(一)maven打包
MapReduce是一個分布式運算程序的編程框架,是用戶開發“基于Hadoop的數據分析應用”的核心框架。
MapReduce核心功能是將用戶編寫的業務邏輯代碼和自帶默認組件整合成一個完整的分布式運算程序(例如:jar包),并發運行在一個Hadoop集群上。
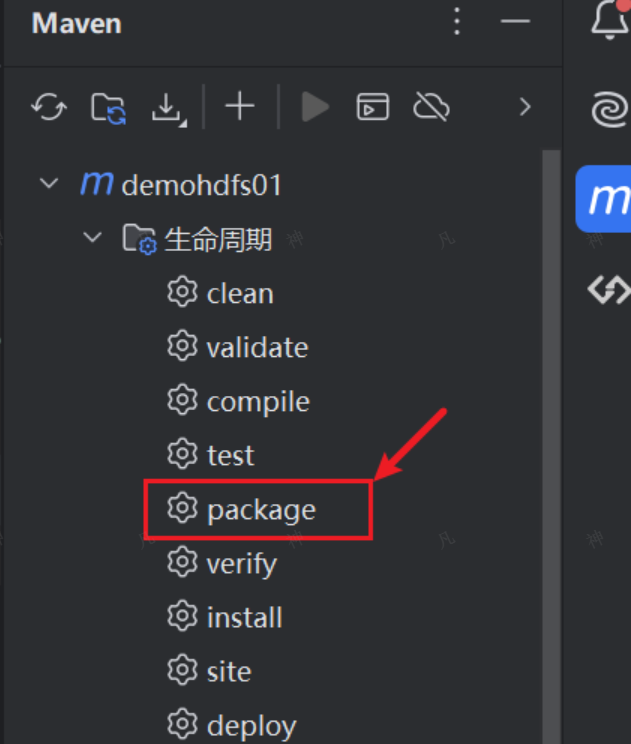
在pom.xml中,補充如下配置,它用來設置打包的java 版本。
<properties>
????<maven.compiler.source>1.8</maven.compiler.source>
????<maven.compiler.target>1.8</maven.compiler.target>
????<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
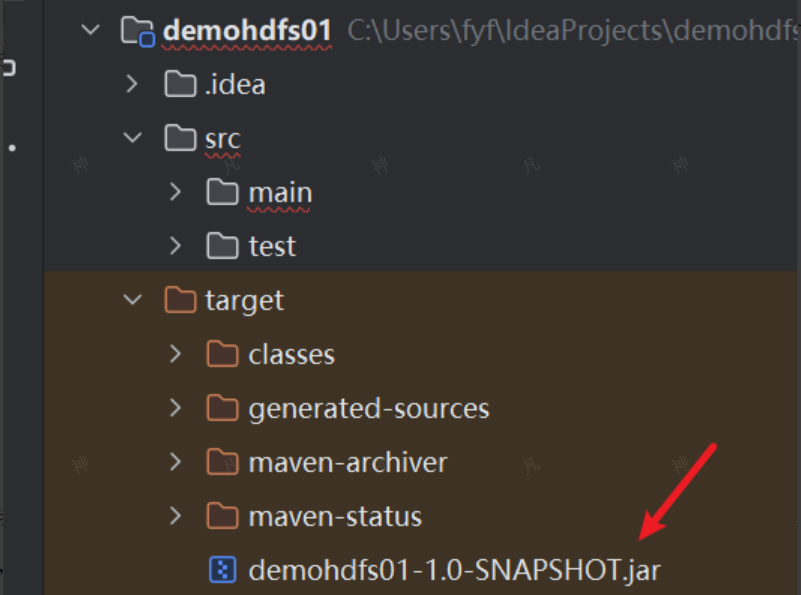
打包成功之后的效果如下:
(二)設置編譯版本
我們集群上安裝的java環境是1.8的,那么我們生成的代碼也必須是這個版本的,否則,就會無法運行。
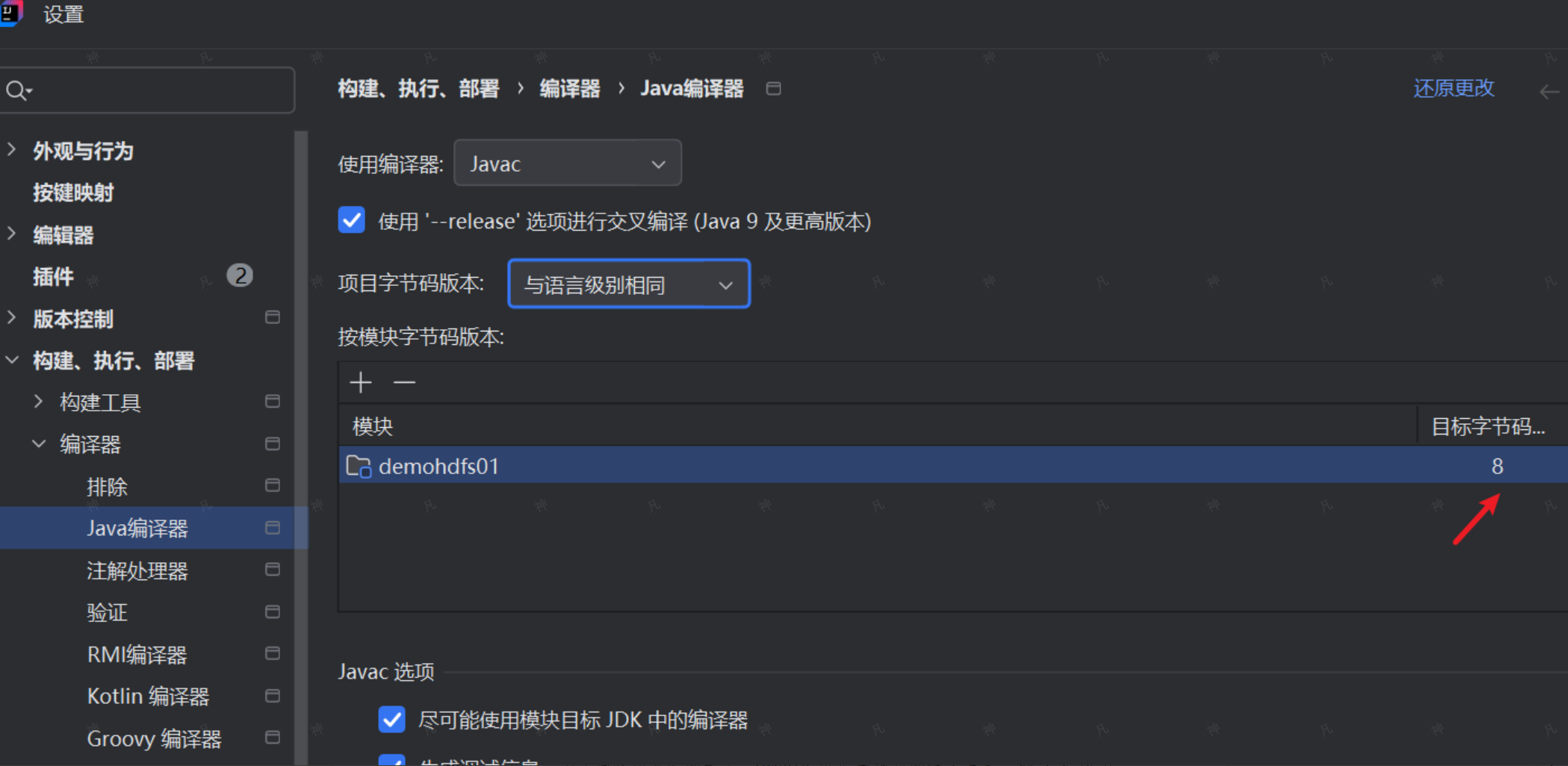
關于java版本的說明如下:
在 Java 7 之前,Java 的版本命名一直是 1.x 的形式,例如 1.6、1.7。從 Java 7 開始,為了簡化版本號的表示,Oracle 開始采用新的命名方式,將 1.x 改為 x。所以Java 8 和 1.8 是同一個版本,只是命名方式不同。
從 Java 9 開始,版本號的命名方式完全統一為 x,例如 Java 9、Java 11、Java 17 等,不再使用 1.x 的形式。
如果你看到 Java 8 或 1.8,它們指的是同一個版本,沒有任何區別。
(三)修改代碼,設置執行環境和文件路徑
我們集群上安裝的java環境是1.8的,那么我們生成的代碼也必須是這個版本的,否則,就會無法運行。
打開代碼,找到driver類,并修改如下:
conf.set("fs.defaultFS", "hdfs://hadoop100:8020");?// 新增加一句
FileInputFormat.setInputPaths(job, new Path("/wcinput"));?// 修改
FileOutputFormat.setOutputPath(job, new Path("/output1"));
確保集群中有/wcinput目錄,并且下面有記事本文件中的單詞。
確保集群中沒有output1這個目錄,因為它應該是要被動態創建出來的。
(四)上傳到節點運行
使用finalshell上到任意節點,例如hadoop100上的/opt下,。
然后通過命令來執行執行WordCount程序,注意要寫Driver類的全名
$ hadoop jar ?/opt/wc.jarcom.root.mapreduce.wordcount.WordCountDriver
運行結束之后,在ui中查看yarn運行效果。
第二課時
(五)修改執行參數
在上面的代碼中,我們的程序只能完成固定目錄下的功能。現在希望它能處理不同的目錄。
修改代碼,讓程序能指定要執行的輸入目錄和要保存結果的輸出目錄。
修改driver類的代碼,更新輸入和輸入路徑。
// 6. 設置輸入和輸出路徑
????????路徑為程序的第一個參數,第二個參數
????????FileInputFormat.setInputPaths(job, new Path(args[0]));
????????FileOutputFormat.setOutputPath(job, new Path(args[1]));
這里的args[0]和args[1]是程序運行時的兩個參數。
改完代碼之后,要重新打包,并上傳到某臺節點上運行。








)



)




)
)
