目錄
- vllm簡介
- vllm解決了哪些問題?
- 1. **瓶頸:KV 緩存內存管理低效**
- 2. **瓶頸:并行采樣和束搜索中的內存冗余**
- 3. **瓶頸:批處理請求中的內存碎片化**
- 快速開始
- 安裝vllm
- 開始使用
- 離線推理
- 啟動 vLLM 服務器
- 支持的模型
- 文本語言模型
- 生成模型(文本生成 (--task generate))
- 池化模型
- 文本嵌入 (--task embed)
- 獎勵建模 (--task reward)
- 分類 (--task classify)
- 句子對評分 (--task score)
- 多模態語言模型
- 生成模型(文本生成 (--task generate))
- 池化模型
- 文本嵌入 (--task embed)
- 轉錄 (--task transcription)
- 常用方法
- 生成模型
- Pooling 模型
- OpenAI 兼容服務器
- VLLM 與 Ollama:如何選擇合適的輕量級 LLM 框架?
- Tiny / Distil / Mini
vllm簡介
vLLM (Virtual Large Language Model) 是一款專為大語言模型推理加速而設計的框架,其依靠卓越的推理效率和資源優化能力在全球范圍內引發廣泛關注。來自加州大學伯克利分校 (UC Berkeley) 的研究團隊于 2023 年提出了開創性注意力算法 PagedAttention,其可以有效地管理注意力鍵和值。
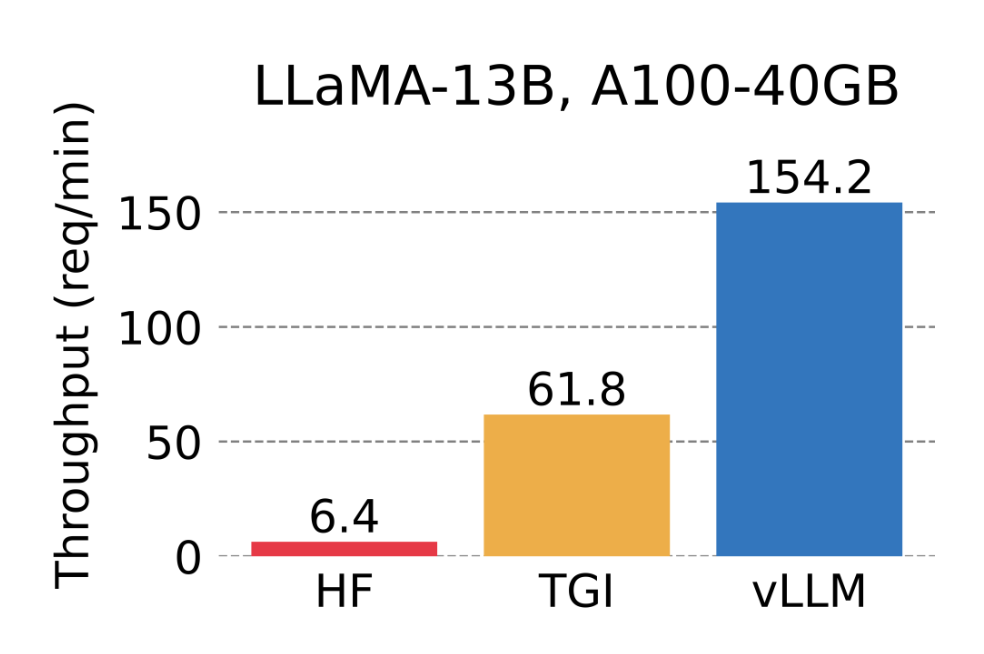
在此基礎上,研究人員構建了高吞吐量的分布式 LLM 服務引擎 vLLM,實現了 KV 緩存內存幾乎零浪費,解決了大語言模型推理中的內存管理瓶頸問題。與 Hugging Face Transformers 相比,其吞吐量提升了 24 倍,而且這一性能提升不需要對模型架構進行任何更改。
相關論文成果為「Efficient Memory Management for Large Language Model Serving with PagedAttention」
vllm解決了哪些問題?
1. 瓶頸:KV 緩存內存管理低效
-
問題描述:在大語言模型(LLM)推理過程中,每個輸入序列都會生成對應的鍵(Key)和值(Value)向量,這些向量被緩存以供后續生成使用,稱為 KV 緩存。傳統的內存管理方式要求這些緩存存儲在連續的內存空間中,導致內存碎片化和資源浪費。
-
技術解決方案:PagedAttention
-
核心思想:借鑒操作系統中的分頁機制,將 KV 緩存劃分為固定大小的塊(KV Blocks),允許這些塊存儲在非連續的物理內存中。
-
實現方式:通過維護一個塊表(Block Table),映射邏輯塊到物理塊,實現靈活的內存分配和管理。(CSDN博客)
-
效果:顯著減少內存浪費,提高內存利用率,允許更多的請求并行處理,從而提升系統吞吐量。
-
案例:在傳統系統中,處理一個長文本序列可能需要預留大量連續內存,而使用 PagedAttention 后,可以將該序列的 KV 緩存分散存儲,避免了內存碎片問題。
-
??PagedAttention實現??:包括CUDA內核優化、量化技術(如FP16)等,進一步減少內存占用。
在深度學習中,模型的權重和激活值通常以32位浮點數(FP32)表示,這種高精度表示雖然能提供良好的模型性能,但也導致了較大的內存占用和計算負擔。量化技術通過將這些高精度數值轉換為低精度表示(如16位浮點數FP16、8位整數INT8、甚至4位整數INT4),以達到以下目的:
- 減少模型大小:低精度表示占用更少的存儲空間。
- 降低內存帶寬需求:減少數據傳輸量,提高緩存利用率。
- 加速推理過程:低精度計算通常在硬件上執行更快。
- 降低功耗:特別適用于邊緣設備和移動設備。(DigitalOcean)
例如,將模型從FP32量化為INT8可以將模型大小減少約75%,同時在大多數情況下保持接近的模型精度。
2. 瓶頸:并行采樣和束搜索中的內存冗余
-
問題描述:在并行采樣(Parallel Sampling)和束搜索(Beam Search)等生成策略中,多個輸出序列可能共享相同的前綴,但傳統方法會為每個序列單獨存儲完整的 KV 緩存,導致內存冗余。(CSDN博客)
-
技術解決方案:KV 緩存共享機制
-
核心思想:利用 PagedAttention 的塊級管理特性,實現 KV 緩存的共享。對于共享前綴的序列,僅存儲一份 KV 緩存,其他序列通過引用該緩存實現共享。
-
實現方式:通過引用計數和寫時復制(Copy-on-Write)機制,確保共享緩存的安全性和一致性。(GitHub)
-
效果:減少內存使用,提高并行處理能力,降低生成延遲。
-
案例:在生成多個回復時,若它們共享相同的開頭部分,系統只需存儲一份該部分的 KV 緩存,節省了內存資源。
-
3. 瓶頸:批處理請求中的內存碎片化
-
問題描述:在批處理多個請求時,由于每個請求的長度和生成進度不同,傳統方法需要對齊序列長度,導致內存浪費和計算資源的低效利用。
-
技術解決方案:細粒度批處理與動態調度
-
核心思想:結合 PagedAttention 的靈活內存管理,允許在批處理過程中動態添加和移除請求,實現細粒度的批處理。(HobbitQia’s Notebook)
-
實現方式:在每次迭代后,系統會移除已完成的請求,并添加新的請求,無需等待整個批次完成。(HobbitQia’s Notebook)
-
效果:提高 GPU 利用率,減少等待時間,提升系統吞吐量。
-
案例:在處理多個用戶請求時,系統可以實時調整批處理隊列,確保資源的高效利用。
-
🧪 實際應用示例
假設你正在開發一個聊天機器人服務,使用大語言模型生成回復。傳統方法在處理多個用戶請求時,可能會遇到內存不足、響應延遲等問題。通過引入 vLLM 和 PagedAttention 技術,你可以:
-
高效管理內存:避免內存碎片化,支持更多并發請求。
-
提升響應速度:通過共享 KV 緩存和動態批處理,減少生成延遲。
-
降低資源成本:提高 GPU 利用率,減少硬件需求。
🧠 總結
| 瓶頸問題 | vLLM 技術解決方案 | 成果 |
|---|---|---|
| KV 緩存內存管理低效 | PagedAttention | 提高內存利用率,減少碎片 |
| 并行采樣和束搜索中的內存冗余 | KV 緩存共享機制 | 降低內存使用,提升并行能力 |
| 批處理請求中的內存碎片化 | 細粒度批處理與動態調度 | 提升吞吐量,減少延遲 |
快速開始
安裝vllm
vLLM 是一個 Python 庫,它還包含預編譯的 C++ 和 CUDA (12.1) 二進制文件。如果你正在使用 NVIDIA GPU,可以直接使用 pip 安裝 vLLM。
pip install vllm
請注意,vLLM 是使用 CUDA 12.1 編譯的,因此您需要確保機器運行的是該版本的 CUDA 。
檢查 CUDA 版本,運行:
nvcc --version
如果您的 CUDA 版本不是 12.1,您可以安裝與您當前 CUDA 版本兼容的 vLLM 版本(更多信息請參考安裝說明),或者安裝 CUDA 12.1 。
🖥? GPU 支持
-
NVIDIA CUDA:支持多種架構,包括 Volta(SM 7.0)、Turing(SM 7.5)、Ampere(SM 8.0/8.6)、Ada(SM 8.9)和 Hopper(SM 9.0) 。(vLLM)
-
AMD ROCm:支持 AMD GPU,通過 ROCm 平臺進行加速。
-
Intel XPU:支持 Intel 的異構計算平臺 XPU。
🧠 CPU 支持
-
Intel/AMD x86:支持主流的 x86 架構處理器。
-
ARM AArch64:支持 ARM 的 64 位架構,常見于移動設備和嵌入式系統。
-
Apple Silicon:支持 Apple 的自研芯片,如 M1、M2 系列。(vLLM)
-
IBM Z (S390X):支持 IBM 的大型主機架構 S390X。(DeepWiki)
? 其他 AI 加速器支持
-
Google TPU:支持 Google 的張量處理單元,用于大規模機器學習任務。
-
Intel Gaudi:支持 Intel 的 Gaudi 加速器,專為深度學習優化。
-
AWS Neuron:支持 AWS 的 Neuron 加速器,適用于云端部署。
有關更詳細的硬件支持和量化方法兼容性信息,建議查閱 vLLM 官方文檔中的兼容性矩陣:
-
Supported Hardware — vLLM
-
中文文檔:https://docs.vllm.com.cn/en/latest/getting_started/installation.html
開始使用
默認情況下,vLLM 從 HuggingFace 下載模型。如果你想在以下示例中使用來自 ModelScope 的模型,請設置環境變量:
export VLLM_USE_MODELSCOPE=True
大多數主流模型都可以在 HuggingFace 上找到,vLLM 支持的模型列表請參見官方文檔: vllm-supported-models 。
離線推理
我們隨便從hf上拉取一個模型到本地:
git clone https://huggingface.co/Qwen/Qwen-1_8B-Chat
vLLM 作為一個開源項目,可以通過其 Python API 執行 LLM 推理。以下是一個簡單的示例,請將代碼保存為 offline_infer.py 文件:
from vllm import LLM, SamplingParams# 輸入幾個問題
prompts = ["你好,你是誰?","法國的首都在哪里?",
]# 設置初始化采樣參數
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=100)# 加載模型,確保路徑正確
llm = LLM(model="/input0/Qwen-1_8B-Chat/", trust_remote_code=True, max_model_len=4096)# 展示輸出結果
outputs = llm.generate(prompts, sampling_params)# 打印輸出結果
for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
然后運行腳本:
python offline_infer.py
模型加載后,您將看到以下輸出:
Processed prompts: 100%|██████████| 2/2 [00:00<00:00, 10.23it/s, est. speed input: 56.29 toks/s, output: 225.14 toks/s]
Prompt: '你好,你是誰?', Generated text: '我是來自阿里云的大規模語言模型,我叫通義千問。'
Prompt: '法國的首都在哪里?', Generated text: '法國的首都是巴黎。'
啟動 vLLM 服務器
要使用 vLLM 提供在線服務,您可以啟動一個 兼容 OpenAI API 的服務器。成功啟動后,您可以像使用 GPT 一樣使用部署的模型。
以下是啟動 vLLM 服務器時常用的一些參數說明:
| 參數 | 說明 |
|---|---|
--model | 要使用的 HuggingFace 模型名稱或路徑。 默認值: facebook/opt-125m |
--host 和 --port | 指定服務器地址和端口。 |
--dtype | 模型權重和激活的精度類型。 可選值: auto、half、float16、bfloat16、float、float32。默認值: auto |
--tokenizer | 要使用的 HuggingFace 分詞器名稱或路徑。 如果未指定,默認使用模型名稱或路徑。 |
--max-num-seqs | 每次迭代的最大序列數。 |
--max-model-len | 模型的上下文長度。 默認值自動從模型配置中獲取。 |
--tensor-parallel-size 或 -tp | 張量并行副本數量(僅針對 GPU)。 默認值: 1 |
--distributed-executor-backend | 指定分布式服務后端。 可能的值: ray、mp。默認值: ray(當使用多個 GPU 時會自動使用 ray) |
運行以下命令啟動一個兼容 OpenAI API 的服務:
python3 -m vllm.entrypoints.openai.api_server \--model /input0/Qwen-1_8B-Chat/ \--host 0.0.0.0 \--port 8080 \--dtype auto \--max-num-seqs 32 \--max-model-len 4096 \--tensor-parallel-size 1 \--trust-remote-code
啟動成功后,您會看到類似如下的輸出,并默認監聽地址為:
http://localhost:8080
您也可以通過 --host 和 --port 參數指定自定義地址與端口。
啟動 vLLM 服務后,可以通過 OpenAI 客戶端調用 API 。以下是一個簡單的示例:
# 注意:請先安裝 openai
# pip install openai
from openai import OpenAI# 設置 OpenAI API 密鑰和 API 基礎地址
openai_api_key = "EMPTY" # 請替換為您的 API 密鑰
openai_api_base = "http://localhost:8080/v1" # 本地服務地址client = OpenAI(api_key=openai_api_key, base_url=openai_api_base)models = client.models.list()
model = models.data[0].id
prompt = "描述一下北京的秋天"# Completion API 調用
completion= client.completions.create(model=model, prompt=prompt)
res = completion.choices[0].text.strip()
print(f"Prompt: {prompt}\nResponse: {res}")
執行命令:
python api_infer.py
您將看到如下輸出結果:

支持的模型
以下是使用代理從 Hugging Face 加載/下載模型的一些技巧:
-
為您的會話全局設置代理(或在配置文件中設置)
export http_proxy=http://your.proxy.server:port export https_proxy=http://your.proxy.server:port -
僅為當前命令設置代理
https_proxy=http://your.proxy.server:port huggingface-cli download <model_name># or use vllm cmd directly https_proxy=http://your.proxy.server:port vllm serve <model_name> --disable-log-requests -
在 Python 解釋器中設置代理
import osos.environ['http_proxy'] = 'http://your.proxy.server:port' os.environ['https_proxy'] = 'http://your.proxy.server:port'
vLLM 支持跨各種任務的生成模型和池化模型。 如果一個模型支持多個任務,您可以通過 --task 參數設置任務。
from vllm import LLM
llm = LLM(model=..., task="generate", trust_remote_code=True) # Name or path of your model
llm.apply_model(lambda model: print(model.__class__))
要使用來自 ModelScope 而不是 Hugging Face Hub 的模型,請設置一個環境變量
export VLLM_USE_MODELSCOPE=True
并與 trust_remote_code=True 一起使用。
from vllm import LLMllm = LLM(model=..., revision=..., task=..., trust_remote_code=True)# For generative models (task=generate) only
output = llm.generate("Hello, my name is")
print(output)# For pooling models (task={embed,classify,reward,score}) only
output = llm.encode("Hello, my name is")
print(output)
文本語言模型
生成模型(文本生成 (–task generate))
架構 | 模型 | 示例 HF 模型 | LoRA | PP |
|---|---|---|---|---|
| Aquila, Aquila2 |
| ?? | ?? |
| Arctic |
| ?? | |
| Baichuan2, Baichuan |
| ?? | ?? |
| Bamba |
| ||
| BLOOM, BLOOMZ, BLOOMChat |
| ?? | |
| BART |
| ||
| ChatGLM |
| ?? | ?? |
| Command-R |
| ?? | ?? |
| DBRX |
| ?? | |
| DeciLM |
| ?? | |
| DeepSeek |
| ?? | |
| DeepSeek-V2 |
| ?? | |
| DeepSeek-V3 |
| ?? | |
| EXAONE-3 |
| ?? | ?? |
| Falcon |
| ?? | |
| FalconMamba |
| ?? | ?? |
| Gemma |
| ?? | ?? |
| Gemma 2 |
| ?? | ?? |
| Gemma 3 |
| ?? | ?? |
| GLM-4 |
| ?? | ?? |
| GLM-4-0414 |
| ?? | ?? |
| GPT-2 |
| ?? | |
| StarCoder, SantaCoder, WizardCoder |
| ?? | ?? |
| GPT-J |
| ?? | |
| GPT-NeoX, Pythia, OpenAssistant, Dolly V2, StableLM |
| ?? | |
| Granite 3.0, Granite 3.1, PowerLM |
| ?? | ?? |
| Granite 3.0 MoE, PowerMoE |
| ?? | ?? |
| Granite MoE Shared |
| ?? | ?? |
| GritLM |
| ?? | ?? |
| Grok1 |
| ?? | ?? |
| InternLM |
| ?? | ?? |
| InternLM2 |
| ?? | ?? |
| InternLM3 |
| ?? | ?? |
| Jais |
| ?? | |
| Jamba |
| ?? | ?? |
| Llama 3.1, Llama 3, Llama 2, LLaMA, Yi |
| ?? | ?? |
| Mamba |
| ?? | |
| MiniCPM |
| ?? | ?? |
| MiniCPM3 |
| ?? | ?? |
| Mistral, Mistral-Instruct |
| ?? | ?? |
| Mixtral-8x7B, Mixtral-8x7B-Instruct |
| ?? | ?? |
| MPT, MPT-Instruct, MPT-Chat, MPT-StoryWriter |
| ?? | |
| Nemotron-3, Nemotron-4, Minitron |
| ?? | ?? |
| OLMo |
| ?? | |
| OLMo2 |
| ?? | |
| OLMoE |
| ?? | ?? |
| OPT, OPT-IML |
| ?? | |
| Orion |
| ?? | |
| Phi |
| ?? | ?? |
| Phi-4, Phi-3 |
| ?? | ?? |
| Phi-3-Small |
| ?? | |
| Phi-3.5-MoE |
| ?? | ?? |
| Persimmon |
| ?? | |
| Qwen |
| ?? | ?? |
| QwQ, Qwen2 |
| ?? | ?? |
| Qwen2MoE |
| ?? | |
| Qwen3 |
| ?? | ?? |
| Qwen3MoE |
| ?? | ?? |
| StableLM |
| ?? | |
| Starcoder2 |
| ?? | |
| Solar Pro |
| ?? | ?? |
| TeleChat2 |
| ?? | ?? |
| TeleFLM |
| ?? | ?? |
| XVERSE |
| ?? | ?? |
| MiniMax-Text |
| ?? | |
| Zamba2 |
|
池化模型
文本嵌入 (–task embed)
架構 | 模型 | 示例 HF 模型 | LoRA | PP |
|---|---|---|---|---|
| 基于 BERT |
| ||
| 基于 Gemma 2 |
| ?? | |
| GritLM |
| ?? | ?? |
| 基于 Llama |
| ?? | ?? |
| 基于 Qwen2 |
| ?? | ?? |
| 基于 RoBERTa |
| ||
| 基于 XLM-RoBERTa |
|
獎勵建模 (–task reward)
架構 | 模型 | 示例 HF 模型 | LoRA | PP |
|---|---|---|---|---|
| 基于 InternLM2 |
| ?? | ?? |
| 基于 Llama |
| ?? | ?? |
| 基于 Qwen2 |
| ?? | ?? |
| 基于 Qwen2 |
| ?? | ?? |
分類 (–task classify)
架構 | 模型 | 示例 HF 模型 | LoRA | PP |
|---|---|---|---|---|
| Jamba |
| ?? | ?? |
| 基于 Qwen2 |
| ?? | ?? |
句子對評分 (–task score)
架構 | 模型 | 示例 HF 模型 | LoRA | PP |
|---|---|---|---|---|
| 基于 BERT |
| ||
| 基于 RoBERTa |
| ||
| 基于 XLM-RoBERTa |
|
多模態語言模型
要為每個文本提示啟用多個多模態項目,您必須設置 limit_mm_per_prompt(離線推理)或 --limit-mm-per-prompt(在線服務)。例如,要啟用每個文本提示最多傳遞 4 張圖像:
離線推理
llm = LLM(model="Qwen/Qwen2-VL-7B-Instruct",limit_mm_per_prompt={"image": 4},
)在線服務
vllm serve Qwen/Qwen2-VL-7B-Instruct --limit-mm-per-prompt image=4
以下模態取決于模型而支持
-
文本 (Text)
-
圖像 (Image)
-
視頻 (Video)
-
音頻 (Audio)
支持由 + 連接的任何模態組合。例如:T + I 表示該模型支持僅文本、僅圖像以及文本與圖像結合的輸入。
另一方面,由 / 分隔的模態是互斥的。例如:T / I 表示該模型支持僅文本和僅圖像輸入,但不支持文本與圖像結合的輸入。
生成模型(文本生成 (–task generate))
架構 | 模型 | 輸入 | 示例 HF 模型 | LoRA | PP | V1 |
|---|---|---|---|---|---|---|
| Aria | T + I+ |
| ?? | ?? | |
| Aya Vision | T + I+ |
| ?? | ?? | |
| BLIP-2 | T + IE |
| ?? | ?? | |
| Chameleon | T + I |
| ?? | ?? | |
| DeepSeek-VL2 | T + I+ |
| ?? | ?? | |
| Florence-2 | T + I |
| |||
| Fuyu | T + I |
| ?? | ?? | |
| Gemma 3 | T + I+ |
| ?? | ?? | ?? |
| GLM-4V | T + I |
| ?? | ?? | ?? |
| H2OVL | T + IE+ |
| ?? | ??* | |
| Idefics3 | T + I |
| ?? | ?? | |
| InternVideo 2.5, InternVL 2.5, Mono-InternVL, InternVL 2.0 | T + IE+ |
| ?? | ?? | |
| Llama-4-17B-Omni-Instruct | T + I+ |
| ?? | ?? | |
| LLaVA-1.5 | T + IE+ |
| ?? | ?? | |
| LLaVA-NeXT | T + IE+ |
| ?? | ?? | |
| LLaVA-NeXT-Video | T + V |
| ?? | ?? | |
| LLaVA-Onevision | T + I+ + V+ |
| ?? | ?? | |
| MiniCPM-O | T + IE+ + VE+ + AE+ |
| ?? | ?? | ?? |
| MiniCPM-V | T + IE+ + VE+ |
| ?? | ?? | ?? |
| Mistral3 | T + I+ |
| ?? | ?? | |
| Llama 3.2 | T + I+ |
| |||
| Molmo | T + I+ |
| ?? | ?? | ?? |
| NVLM-D 1.0 | T + I+ |
| ?? | ?? | |
| PaliGemma, PaliGemma 2 | T + IE |
| ?? | ?? | |
| Phi-3-Vision, Phi-3.5-Vision | T + IE+ |
| ?? | ?? | |
| Phi-4-multimodal | T + I+ / T + A+ / I+ + A+ |
| ?? | ||
| Pixtral | T + I+ |
| ?? | ?? | |
| Qwen-VL | T + IE+ |
| ?? | ?? | ?? |
| Qwen2-Audio | T + A+ |
| ?? | ?? | |
| QVQ, Qwen2-VL | T + IE+ + VE+ |
| ?? | ?? | ?? |
| Qwen2.5-VL | T + IE+ + VE+ |
| ?? | ?? | ?? |
| Skywork-R1V-38B | T + I |
| ?? | ?? | |
| SmolVLM2 | T + I |
| ?? | ?? | |
| Ultravox | T + AE+ |
| ?? | ?? | ?? |
需要通過 --hf-overrides 設置架構名稱,以匹配 vLLM 中的架構名稱。例如,要使用 DeepSeek-VL2 系列模型
--hf-overrides '{"architectures": ["DeepseekVLV2ForCausalLM"]}'
池化模型
文本嵌入 (–task embed)
架構 | 模型 | 輸入 | 示例 HF 模型 | LoRA | PP |
|---|---|---|---|---|---|
| 基于 LLaVA-NeXT | T / I |
| ?? | |
| 基于 Phi-3-Vision | T + I |
| 🚧 | ?? |
| 基于 Qwen2-VL | T + I |
| ?? |
轉錄 (–task transcription)
架構 | 模型 | 示例 HF 模型 | LoRA | PP |
|---|---|---|---|---|
| 基于 Whisper |
| 🚧 | 🚧 |
常用方法
生成模型
vLLM 為生成模型提供一流的支持,涵蓋了大多數 LLM。
在 vLLM 中,生成模型實現了 VllmModelForTextGeneration 接口。基于輸入的最終隱藏狀態,這些模型輸出要生成的 token 的對數概率,然后這些概率通過 Sampler 傳遞以獲得最終文本。
對于生成模型,唯一支持的 --task 選項是 “generate”。通常,這是自動推斷的,因此您不必指定它。
LLM.generate 方法適用于 vLLM 中的所有生成模型。
from vllm import LLM, SamplingParamsllm = LLM(model="facebook/opt-125m")
params = SamplingParams(temperature=0)
outputs = llm.generate("Hello, my name is", params)for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
LLM.chat方法在 generate 之上實現了聊天功能。特別是,它接受類似于 OpenAI Chat Completions API 的輸入,并自動應用模型的 聊天模板來格式化提示。
from vllm import LLMllm = LLM(model="meta-llama/Meta-Llama-3-8B-Instruct")
conversation = [{"role": "system","content": "You are a helpful assistant"},{"role": "user","content": "Hello"},{"role": "assistant","content": "Hello! How can I assist you today?"},{"role": "user","content": "Write an essay about the importance of higher education.",},
]
outputs = llm.chat(conversation)for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
Pooling 模型
在 vLLM 中,Pooling 模型實現了 VllmModelForPooling 接口。這些模型使用 Pooler 來提取輸入的最終隱藏狀態,然后再返回它們。
LLM.encode 方法適用于 vLLM 中的所有 Pooling 模型。它直接返回提取的隱藏狀態,這對于獎勵模型很有用。
from vllm import LLMllm = LLM(model="Qwen/Qwen2.5-Math-RM-72B", task="reward")
(output,) = llm.encode("Hello, my name is")data = output.outputs.data
print(f"Data: {data!r}")
LLM.embed 方法為每個 prompt 輸出一個嵌入向量。它主要為嵌入模型設計。
from vllm import LLMllm = LLM(model="intfloat/e5-mistral-7b-instruct", task="embed")
(output,) = llm.embed("Hello, my name is")embeds = output.outputs.embedding
print(f"Embeddings: {embeds!r} (size={len(embeds)})")
代碼示例可以在這里找到: examples/offline_inference/basic/embed.py
LLM.classify 方法為每個 prompt 輸出一個概率向量。它主要為分類模型設計。
from vllm import LLMllm = LLM(model="jason9693/Qwen2.5-1.5B-apeach", task="classify")
(output,) = llm.classify("Hello, my name is")probs = output.outputs.probs
print(f"Class Probabilities: {probs!r} (size={len(probs)})")
LLM.score 方法輸出句子對之間的相似度評分。它專為嵌入模型和交叉編碼器模型設計。嵌入模型使用余弦相似度,而 交叉編碼器模型 在 RAG 系統中充當候選查詢-文檔對之間的重排序器。
vLLM 只能執行 RAG 的模型推理組件(例如,嵌入、重排序)。要在更高級別處理 RAG,您應該使用集成框架,例如 LangChain。
from vllm import LLMllm = LLM(model="BAAI/bge-reranker-v2-m3", task="score")
(output,) = llm.score("What is the capital of France?","The capital of Brazil is Brasilia.")score = output.outputs.score
print(f"Score: {score}")
OpenAI 兼容服務器
vLLM 提供了一個 HTTP 服務器,實現了 OpenAI 的 Completions API、Chat API 以及更多功能!
您可以通過 vllm serve 命令或通過 Docker 啟動服務器
vllm serve NousResearch/Meta-Llama-3-8B-Instruct --dtype auto --api-key token-abc123
要調用服務器,您可以使用 官方 OpenAI Python 客戶端,或任何其他 HTTP 客戶端。
from openai import OpenAI
client = OpenAI(base_url="https://127.0.0.1:8000/v1",api_key="token-abc123",
)completion = client.chat.completions.create(model="NousResearch/Meta-Llama-3-8B-Instruct",messages=[{"role": "user", "content": "Hello!"}]
)print(completion.choices[0].message)
vLLM 支持一些 OpenAI 不支持的參數,例如 top_k。您可以使用 OpenAI 客戶端在請求的 extra_body 參數中將這些參數傳遞給 vLLM,例如 extra_body={"top_k": 50} 代表 top_k。
vLLM 支持以下 OpenAI 兼容 API 和 自定義擴展 API,
| 接口路徑 | 功能 | 適用模型 | 注意事項 |
|---|---|---|---|
/v1/completions | 文本補全 | 文本生成模型(--task generate) | 不支持 suffix 參數 |
/v1/chat/completions | 聊天對話生成 | 具備聊天模板的文本生成模型(--task generate) | 忽略 parallel_tool_calls 和 user 參數 |
/v1/embeddings | 文本向量嵌入 | 嵌入模型(--task embed) | - |
/v1/audio/transcriptions | 音頻轉文字 | 自動語音識別(如 Whisper)(--task generate) | - |
| 接口路徑 | 功能 | 適用模型 | 說明 |
|---|---|---|---|
/tokenize / /detokenize | 分詞與反分詞 | 任意含分詞器的模型 | 提供分詞調試能力 |
/pooling | 池化處理 | 所有池化模型 | 用于聚合 token 向量 |
/score | 打分(如相關性) | 嵌入模型、交叉編碼器(--task score) | 適合排序、打分任務 |
/rerank, /v1/rerank, /v2/rerank | 文本重排序 | 交叉編碼器(--task score) | 兼容 Jina/Cohere,Jina 響應更詳細 |
具體文檔參考:
- 中文文檔1:https://docs.vllm.com.cn/en/latest/serving/openai_compatible_server.html
- 中文文檔2:https://docs.vllm.com.cn/en/latest/serving/openai_compatible_server.html#chat-api
VLLM 與 Ollama:如何選擇合適的輕量級 LLM 框架?
🔍 vLLM vs Ollama 對比一覽
| 對比維度 | vLLM | Ollama |
|---|---|---|
| 核心定位 | 企業級高性能推理框架,支持高并發、低延遲,適用于生產環境。 | 輕量級本地部署工具,適合個人開發者和小型項目,強調易用性和快速部署。 |
| 硬件支持 | 主要依賴 NVIDIA GPU,支持 FP16/BF16 精度,顯存占用較高。 | 支持 CPU 和 GPU,默認使用 int4 量化模型,顯存占用低,適合資源有限的設備。 |
| 部署難度 | 需配置 Python 環境、CUDA 驅動,適合有一定技術背景的用戶。 | 一鍵安裝,開箱即用,無需復雜配置,適合沒有技術背景的用戶。 |
| 并發能力 | 支持動態批處理和千級并發請求,吞吐量高,適合處理大量并發請求。 | 單次推理速度快,但并發處理能力較弱,適合處理少量請求。 |
| 模型支持 | 需手動下載原始模型文件(如 HuggingFace 格式),支持更廣泛的模型,兼容多種解碼算法。 | 內置預訓練模型庫,自動下載量化版本(int4 為主),支持的模型相對較少。 |
| 并行策略 | 多進程方式,每個 GPU 一個進程,支持張量并行和流水線并行,適合分布式部署。 | 單進程方式,通過線程管理多 GPU,適合單機本地化場景,多 GPU 并行支持有限。 |
| 資源管理 | 顯存占用固定,需預留資源應對峰值負載。 | 靈活調整資源占用,空閑時自動釋放顯存,資源管理更高效。 |
| 安全性 | 支持 API Key 授權,適合生產環境的安全需求。 | 不支持 API Key 授權,安全性相對較弱。 |
| 文檔支持 | 提供全面的技術文檔,包括詳細的 API 參考和指南,GitHub 維護良好,開發者響應迅速。 | 文檔簡單且適合初學者,但缺乏技術深度,GitHub 討論區部分問題未得到解答。 |
| 適用場景 | 企業級 API 服務、高并發批量推理(如智能客服、文檔處理)、需要高精度模型輸出或定制化參數調整的場景。 | 個人開發者快速驗證模型效果、低配置硬件(如僅有 16GB 內存的筆記本電腦)、需要快速交互式對話或原型開發的場景。 |
在并發性能測試中,vLLM 和 Ollama 均表現出較高的穩定性(無失敗請求),但在性能表現上存在顯著差異:(CSDN 博客)
-
低并發場景(并發數 1 和 5):
-
Ollama 的平均響應時間和響應時間中位數顯著優于 vLLM。(CSDN 博客)
-
vLLM 的吞吐量略高于 Ollama。(博客園)
-
-
高并發場景(并發數 10 和 20):
-
vLLM 的平均響應時間和響應時間中位數顯著優于 Ollama。(CSDN 博客)
-
vLLM 的吞吐量顯著高于 Ollama。(博客園)
-
vLLM 的最大響應時間在高并發場景下更穩定,表明其在高負載下的性能表現更優。(CSDN 博客)
-
例如,在并發數為 20 的情況下,vLLM 的平均響應時間約為 10,319.91 ms,而 Ollama 的平均響應時間約為 16,845.03 ms。(CSDN 博客)
🧠 模型精度與顯存占用
-
模型精度:
-
vLLM 使用原始模型(如 FP16/BF16),保持了模型的高精度輸出。(博客園)
-
Ollama 使用量化模型(如 int4),可能導致模型精度下降,生成內容質量或指令遵循能力降低。(博客園)
-
-
顯存占用:
- 以 Qwen2.5-14B 模型為例,vLLM 運行需要約 39GB 顯存,而 Ollama 僅需約 11GB 顯存。(博客園)
🧩 總結建議
-
選擇 Ollama:
-
適合個人開發者、小型項目或需要快速部署的場景。(博客園)
-
適合資源有限的設備和個人用戶。(博客園)
-
適合對響應速度要求較高的低負載場景。(CSDN 博客)
-
-
選擇 vLLM:
-
適合企業級應用和需要高效推理的場景。(博客園)
-
適合處理大規模并發請求的應用場景。(CSDN 博客)
-
適合需要高精度模型輸出或定制化參數調整的場景。(博客園)
-
而ollma也提供api訪問:
import requests
response = requests.post("http://localhost:11434/api/generate", json={"model": "mistral", "prompt": "Tell me a joke"})
print(response.json())
Tiny / Distil / Mini
模型蒸餾(Knowledge Distillation)是一種 模型壓縮技術,其核心思想是:
用一個大模型(教師模型)訓練出一個小模型(學生模型),讓小模型盡量模仿大模型的行為,從而在保留大部分性能的前提下大幅減少模型體積和推理開銷。
vLLM 是推理引擎,不是訓練框架,它專注于高性能地“運行模型”(特別是 LLM 的聊天推理),而不是訓練或蒸餾模型。
常用的蒸餾框架如下:
| 框架 | 特點 | 適合用途 |
|---|---|---|
| Hugging Face Transformers + Trainer | 通用、生態好,有 Distillation 示例 | 微調 + 蒸餾 |
| Hugging Face + 🤗 Datasets | 批量數據處理配套方便 | 大規模數據上做蒸餾 |
| OpenKD(by THU) | 專門為 NLP 蒸餾設計 | 各類蒸餾方式齊全(task distillation、layer distillation等) |
| TextBrewer | 結構靈活、適用于 BERT、RoBERTa 等 | 更精細控制 loss 和中間層 |
| Fairseq / DeepSpeed / Megatron-LM | 面向超大模型蒸餾 | 大規模并行蒸餾場景 |
TinyBERT / DistilBERT / MiniLM 有什么區別?這些都是對 BERT 模型做蒸餾壓縮 后的產物,但它們采用的策略不同,適用場景也不一樣:
| 名稱 | 提出機構 | 參數量 | 蒸餾策略 | 特點 | 應用場景 |
|---|---|---|---|---|---|
| DistilBERT | Hugging Face | ~66M | 只對 logits 蒸餾(output distillation) | 簡單、穩定 | 文本分類、語義匹配 |
| TinyBERT | Huawei Noah’s Ark Lab | ~14M / ~66M | 包括中間層蒸餾(intermediate layer distillation) | 更復雜,性能更接近原始 BERT | 文本理解、QA |
| MiniLM | Microsoft | ~22M | 注意力分布和表示的蒸餾(attention + value distillation) | 超輕量但強大 | 向量生成、檢索嵌入 |
| MobileBERT | ~25M | 架構微調 + 蒸餾 | 有專門的 Bottleneck 架構 | 移動設備部署 | |
| ALBERT | 參數共享,不是蒸餾 | 提前結構壓縮 | 節省參數,不減性能 | 學術研究多 |



)
)

)







)




